« Performance critique » ne veut pas dire « agréable d'être rapide ». Cela signifie que l'expérience se dégrade lorsque l'application est même légèrement lente, incohérente ou retardée. Les utilisateurs ne remarquent pas seulement le lag — ils perdent un instant, manquent un événement, ou font des erreurs.
Quelques types d'applications rendent cela évident :
- Appareil photo et vidéo : on appuie sur le déclencheur et on s'attend à capturer immédiatement. Les retards peuvent faire manquer le moment. Le prévisualisation saccadée, la mise au point lente, ou les images perdues rendent l'app peu fiable.
- Cartes et navigation : le point bleu doit bouger en douceur, les recalculs d'itinéraire doivent paraître instantanés, et l'UI doit rester réactive pendant que GPS, chargement de données et rendu s'exécutent en parallèle.
- Trading et finance : une cotation mise à jour en retard, un bouton qui n'enregistre l'action qu'après un délai, ou un écran qui se fige en période de volatilité peuvent affecter directement les résultats.
- Jeux : les chutes de frame et la latence d'entrée ne font pas que « donner une mauvaise sensation » — elles changent le gameplay. Un pacing d'images cohérent compte autant que le FPS brut.
Dans tous ces cas, la performance n'est pas une métrique technique cachée. Elle est visible, ressentie et jugée en quelques secondes.
Que signifie « frameworks natifs » (sans les mots à la mode)
Quand on parle de frameworks natifs, on entend utiliser les outils de première classe sur chaque plateforme :
- iOS : Swift/Objective‑C avec les SDK iOS d'Apple (par ex. UIKit ou SwiftUI, plus les frameworks système)
- Android : Kotlin/Java avec les SDK Android (par ex. Jetpack, Views/Compose, plus les APIs plateforme)
Natif ne veut pas automatiquement dire « meilleure ingénierie ». Cela signifie que votre app parle directement le langage de la plateforme — particulièrement important quand vous poussez l'appareil à fond.
Les frameworks cross-platform peuvent être un excellent choix pour beaucoup de produits, surtout quand la vitesse de développement et le partage de code comptent plus que chaque milliseconde. Cet article ne soutient pas que « natif toujours ». Il soutient que lorsque l'app est vraiment critique pour la performance, les frameworks natifs suppriment souvent des catégories entières de surcoût et de limitations.
Les dimensions qui décident en général
Nous évaluerons les besoins critiques en performance selon quelques dimensions pratiques :
- Latence : réponse au toucher, saisie, interactions temps réel, sync audio/vidéo
- Rendu : défilement fluide, animations, pacing des frames, UI pilotée par GPU
- Batterie et chaleur : efficience soutenue sur de longues sessions
- Accès matériel/OS : pipelines caméra, capteurs, Bluetooth, exécution en arrière-plan, ML sur appareil
Ce sont les domaines où les utilisateurs sentent la différence — et où les frameworks natifs ont tendance à briller.
Les frameworks cross-platform peuvent paraître « presque natifs » quand vous construisez des écrans typiques, des formulaires et des flux pilotés par le réseau. La différence apparaît généralement quand une app est sensible à de petits délais, a besoin d'un pacing d'images cohérent, ou doit pousser l'appareil longtemps.
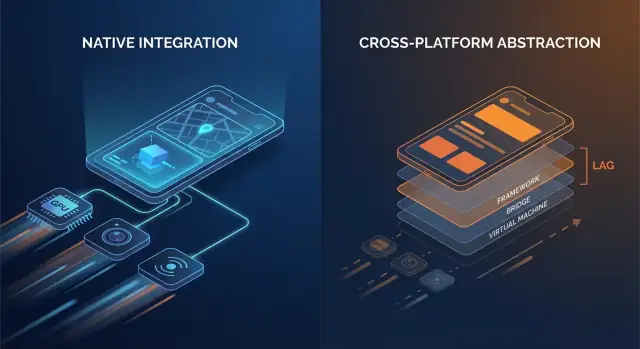
Les couches supplémentaires qui s'additionnent
Le code natif parle généralement aux APIs OS directement. Beaucoup de stacks cross-platform ajoutent une ou plusieurs couches de traduction entre votre logique applicative et ce que le téléphone finit par rendre.
Points d'overhead courants :
- Appels bridge et changements de contexte : si votre couche UI et votre logique métier vivent dans des runtimes différents (par ex. un runtime managé ou moteur de scripts plus le natif), chaque interaction peut exiger un passage de frontière.
- Sérialisation et copies : les données transmises peuvent devoir être converties (payloads type JSON, maps typées, buffers). Ce travail de conversion peut apparaître sur des chemins chauds comme le scrolling ou la saisie.
- Hiérarchies de vues supplémentaires : certains frameworks créent leur propre arbre UI puis le mappent sur des vues natives (ou rendent sur un canvas). La reconciliation et le layout peuvent devenir plus coûteux qu'une mise à jour directe de vues natives.
Aucun de ces coûts n'est énorme isolément. Le problème, c'est la répétition : ils peuvent survenir à chaque geste, à chaque tick d'animation et pour chaque élément d'une liste.
Temps de démarrage et « jank » d'exécution
La surcharge ne concerne pas seulement la vitesse brute ; elle concerne aussi quand le travail s'exécute.
- Le temps de démarrage peut augmenter quand l'app doit initialiser un runtime additionnel, charger des assets embarqués, chauffer un moteur UI ou reconstruire l'état avant que le premier écran soit interactif.
- Le jank à l'exécution vient souvent de pauses imprévisibles : garbage collection, backpressure du bridge, diffing coûteux, ou une tâche longue qui bloque le thread principal juste quand l'UI doit atteindre sa prochaine frame.
Les apps natives peuvent aussi rencontrer ces problèmes — mais il y a moins de pièces mobiles, donc moins d'endroits où les surprises peuvent se cacher.
Un modèle mental simple
Pensez : moins de couches = moins de surprises. Chaque couche ajoutée peut être bien conçue, mais elle introduit tout de même plus de complexité d'ordonnancement, plus de pression mémoire et plus de travail de traduction.
Quand la surcharge est acceptable — et quand elle ne l'est pas
Pour beaucoup d'apps, la surcharge est acceptable et le gain de productivité est réel. Mais pour les apps critiques pour la performance — flux à défilement rapide, animations lourdes, collaboration temps réel, traitement audio/vidéo, ou tout ce qui est sensible à la latence — ces coûts « petits » deviennent vite visibles par l'utilisateur.
Fluidité de l'UI : frames, jank et chemins de rendu natifs
La fluidité de l'UI n'est pas qu'un « plus agréable » — c'est un signal direct de qualité. Sur un écran 60 Hz, votre app a environ 16,7 ms pour produire chaque frame. Sur des appareils 120 Hz, ce budget tombe à 8,3 ms. Quand vous manquez cette fenêtre, l'utilisateur voit du stutter (jank) : un scroll qui « accroche », des transitions qui hesitent, ou un geste qui semble désynchronisé.
Pourquoi les frames manquées sont si faciles à remarquer
Les gens ne comptent pas consciemment les frames, mais ils remarquent l'incohérence. Une frame perdue pendant un fondu lent peut être tolérable ; quelques frames perdues pendant un scroll rapide sont immédiatement évidentes. Les écrans à haute fréquence élèvent aussi les attentes — une fois que les utilisateurs ont expérimenté la fluidité 120 Hz, un rendu incohérent paraît plus mauvais qu'à 60 Hz.
Le thread principal est le goulot habituel
La plupart des frameworks UI reposent encore sur un thread principal/UI pour coordonner l'entrée, le layout et le dessin. Le jank apparaît souvent quand ce thread fait trop de travail en une frame :
- Passes de layout lourdes : hiérarchies de vues complexes, conteneurs imbriqués, ou relayouts fréquents déclenchés par des contraintes/taille changeantes.
- Animations gourmandes : animer des propriétés qui forcent le re-layout ou la re-rasterisation au lieu de laisser le GPU gérer des transforms.
- Travail synchrone dans les callbacks UI : parsing JSON, formatage de longs blocs de texte, ou exécution de logique métier pendant des événements de scroll/gesture.
Les frameworks natifs ont tendance à disposer de pipelines bien optimisés et de meilleures pratiques claires pour garder le travail hors du thread principal, minimiser les invalidations de layout et utiliser des animations compatibles GPU.
Composants natifs vs UI rendue sur-mesure
Une différence clé est le chemin de rendu :
- Composants natifs se mappent en général directement sur des widgets optimisés par l'OS et des systèmes de compositing.
- Approches à rendu personnalisé (courantes dans les stacks cross-platform) peuvent ajouter un arbre de rendu séparé, des uploads de textures supplémentaires, ou un travail de reconciliation supplémentaire. Cela peut aller tant que votre écran devient lourd en animations ou en listes et que l'overhead commence à rivaliser avec un budget de frame serré.
Où vous le ressentez : exemples d'écran réels
Les listes complexes sont le test de charge classique : défilement rapide + chargement d'images + hauteurs de cellules dynamiques peuvent créer du churn de layout et une pression GC/mémoire.
Les transitions peuvent révéler des inefficacités de pipeline : animations d'éléments partagés, flous d'arrière-plan et ombres superposées sont riches visuellement mais peuvent faire monter le coût GPU et l'overdraw.
Les écrans à gestes intensifs (drag-to-reorder, cartes à swiper, scrubbers) sont impitoyables car l'UI doit répondre en continu. Quand les frames arrivent en retard, l'UI ne semble plus « attachée » au doigt de l'utilisateur — exactement ce que les apps haute performance évitent.
Faible latence : toucher, saisie, audio et UX temps réel
La latence est le temps entre une action utilisateur et la réponse de l'app. Ce n'est pas la « vitesse » globale, mais l'écart que vous ressentez quand vous tapez, faites glisser, dessinez ou jouez une note.
Entrée→réponse : quand « rapide » devient « naturel »
Règles empiriques :
- 0–50 ms : paraît instantané. Taps et saisie semblent directement connectés au doigt.
- 50–100 ms : généralement acceptable, mais on perçoit un « flou », surtout lors de drags.
- 100–200 ms : lag perceptible. La saisie paraît en retard ; un trait dessiné « poursuit » le stylet.
- 200 ms+ : frustrant. Les utilisateurs ralentissent pour compenser.
Les apps critiques vivent et meurent selon ces écarts.
Boucles d'événements, ordonnancement et « thread hops »
La plupart des frameworks traitent l'entrée sur un thread, exécutent la logique applicative ailleurs, puis demandent à l'UI de mettre à jour. Quand ce chemin est long ou incohérent, la latence explose.
Les couches cross-platform peuvent ajouter des étapes :
- L'entrée arrive → traduite en événements du framework
- La logique s'exécute dans un runtime séparé (souvent avec sa propre boucle d'événements)
- Les changements d'état sont sérialisés et renvoyés
- Les mises à jour UI sont planifiées plus tard, manquant parfois la frame suivante
Chaque transfert (un « thread hop ») ajoute de l'overhead et, plus important, du jitter — la variance de la latence — ce qui donne souvent une pire sensation qu'un retard constant.
Les frameworks natifs tendent à avoir un chemin plus court et plus prévisible du toucher → mise à jour UI parce qu'ils s'alignent étroitement sur l'ordonnanceur OS, le système d'entrée et le pipeline de rendu.
UX temps réel : audio, vidéo et collaboration live
Certaines scenarios ont des limites strictes :
- Monitoring audio/instruments : la latence aller‑retour doit souvent rester sous ~20 ms pour être jouable.
- Appels voix/vidéo : on peut bufferiser pour masquer le réseau, mais les contrôles UI (mute, haut‑parleur, sous‑titres) doivent répondre immédiatement.
- Collaboration live (docs, tableaux blancs) : les éditions locales doivent apparaître instantanément, même si la synchronisation distante prend plus de temps.
Les implémentations natives facilitent le raccourcissement du « chemin critique » — en priorisant l'entrée et le rendu sur le travail d'arrière-plan — pour que les interactions temps réel restent serrées et fiables.
Fonctionnalités matérielles et OS : natif d'abord, toujours
Lancez avec un domaine personnalisé
Hébergez votre app sur Koder.ai et ajoutez un domaine personnalisé quand elle est prête.
La performance n'est pas seulement vitesse CPU ou taux d'images. Pour beaucoup d'apps, les moments décisifs surviennent à la périphérie — là où votre code touche la caméra, les capteurs, les radios et les services système. Ces capacités sont conçues et livrées d'abord via des APIs natives, et cette réalité façonne ce qui est faisable (et la stabilité) dans les stacks cross-platform.
L'accès matériel n'est rarement générique
Des fonctionnalités comme les pipelines caméra, l'AR, le BLE, le NFC et les capteurs requièrent souvent une intégration étroite avec des frameworks spécifiques aux appareils. Les wrappers cross-platform peuvent couvrir les cas courants, mais les scénarios avancés exposent des lacunes.
Exemples où les APIs natives comptent :
- Contrôles avancés de la caméra : mise au point et exposition manuelles, capture RAW, vidéo haute fréquence, réglages HDR, basculement multi‑caméras (grand‑angle/télé), données de profondeur et comportement en faible luminosité.
- Expériences AR : les capacités d'ARKit/ARCore évoluent vite (occlusion, détection de plans, reconstruction de scène).
- BLE et modes arrière‑plan : scan, comportement de reconnexion et « fonctionne écran éteint » dépendent souvent des règles d'exécution en arrière‑plan de la plateforme.
- NFC : accès à l'élément sécurisé, limites d'émulation de carte et gestion des sessions lecteur sont très spécifiques à la plateforme.
- Données santé : permissions HealthKit/Google Fit, types de données et livraison en arrière‑plan peuvent être nuancées et nécessiter une gestion native.
Les mises à jour OS arrivent d'abord en natif
Quand iOS ou Android publient de nouvelles fonctionnalités, les APIs officielles sont immédiatement disponibles dans les SDK natifs. Les couches cross-platform peuvent nécessiter des semaines (ou plus) pour ajouter des bindings, mettre à jour des plugins et résoudre les cas limites.
Ce délai n'est pas seulement gênant — il peut créer un risque de fiabilité. Si un wrapper n'a pas été mis à jour pour une nouvelle version d'OS, vous pouvez voir :
- des flux d'autorisations qui cassent,
- des tâches d'arrière‑plan restreintes,
- des crashs déclenchés par de nouveaux comportements système,
- des régressions qui n'apparaissent que sur certains modèles.
Pour les apps critiques, les frameworks natifs réduisent le problème « d'attendre le wrapper » et permettent aux équipes d'adopter les capacités OS dès le jour 1 — souvent la différence entre sortir une fonctionnalité ce trimestre ou le suivant.
La vitesse dans une démo rapide n'est que la moitié de l'histoire. La performance que les utilisateurs retiennent est celle qui tient après 20 minutes d'utilisation — quand le téléphone est chaud, la batterie baisse et l'app a été en arrière‑plan plusieurs fois.
D'où vient vraiment la consommation batterie
La plupart des « consommations mystérieuses » sont auto‑infligées :
- Wake locks et timers incontrôlés empêchent le CPU de dormir, même écran éteint.
- Travail d'arrière‑plan qui ne s'arrête jamais vraiment (polling, vérifications de localisation fréquentes, retries réseau répétés) s'additionne vite.
- Redraws excessifs — reconstruire l'UI ou rerendre des animations plus souvent que nécessaire — maintient CPU/GPU actifs.
Les frameworks natifs proposent en général des outils plus clairs et prévisibles pour ordonnancer le travail (tâches d'arrière‑plan, job scheduling, refresh géré par l'OS), ce qui permet d'en faire moins et au meilleur moment.
Pression mémoire : la source cachée des saccades
La mémoire n'affecte pas seulement les crashes — elle affecte la fluidité.
Beaucoup de stacks cross-platform reposent sur un runtime managé avec garbage collection (GC). Quand la mémoire s'accumule, le GC peut suspendre l'app brièvement pour nettoyer les objets non utilisés. Pas besoin de connaître les détails internes pour le ressentir : micro‑gelées occasionnelles pendant le scroll, la saisie ou les transitions.
Les apps natives suivent souvent les patterns plateforme (comme l'ARC sur Apple), qui répartissent le travail de nettoyage plus régulièrement. Le résultat peut être moins de pauses surprises — surtout sous forte contrainte mémoire.
La chaleur, c'est la performance. À mesure que l'appareil chauffe, l'OS peut brider les vitesses CPU/GPU pour protéger le matériel, et les FPS chutent. C'est courant dans les workloads soutenus comme les jeux, la navigation active, la caméra + filtres ou l'audio temps réel.
Le code natif peut être plus économe dans ces scénarios car il utilise des APIs accélérées matériellement et ajustées par l'OS pour les tâches lourdes — pipelines vidéo natifs, échantillonnage efficace des capteurs, codecs média plateforme — réduisant le travail gaspillé qui devient chaleur. Quand « rapide » signifie aussi « frais et stable », le natif a souvent un avantage.
Profilage et débogage : voir les véritables goulots
Exportez le code quand vous êtes prêt
Commencez dans Koder.ai, exportez le code source et déplacez plus tard les points chauds de performance vers du natif.
Les travaux de performance réussissent ou échouent selon la visibilité. Les frameworks natifs fournissent généralement les hooks les plus profonds dans l'OS, le runtime et le pipeline de rendu — parce qu'ils sont faits par les mêmes fournisseurs qui définissent ces couches.
Les apps natives peuvent attacher des profileurs aux frontières où les délais sont introduits : le thread principal, le render thread, le compositeur système, la pile audio, les sous-systèmes réseau et stockage. Quand vous poursuivez un jank qui survient une fois toutes les 30 secondes, ou une consommation batterie qui n'apparaît que sur certains appareils, ces traces « en dessous du framework » sont souvent la seule façon d'obtenir une réponse définitive.
Outils natifs courants (les habitués)
Pas besoin de tout mémoriser, mais il est utile de savoir ce qui existe :
- Xcode Instruments (Time Profiler, Allocations, Leaks, Core Animation, Energy Log)
- Débogueur Xcode (inspection de threads, graphe mémoire, breakpoints symboliques)
- Android Studio Profiler (CPU, Mémoire, Réseau, Énergie)
- Perfetto / System Trace (tracing système sur Android)
- Outils GPU comme les outils Metal d'Xcode ou les inspecteurs GPU des fournisseurs (pour diagnostiquer overdraw, coût des shaders, pacing des frames)
Ces outils répondent à des questions concrètes : « Quelle fonction est chaude ? », « Quel objet n'est jamais libéré ? », « Quelle frame a manqué sa deadline, et pourquoi ? »
Les bugs des « derniers 5 % » : gels, fuites et chutes de frame
Les problèmes de performance les plus difficiles se cachent souvent dans des cas limites : un deadlock rare de synchronisation, un parse JSON lent sur le main thread, une vue unique qui déclenche un layout coûteux, ou une fuite mémoire n'apparaissant qu'après 20 minutes d'utilisation.
Le profilage natif permet de corréler symptômes (un freeze ou un jank) avec des causes (une pile d'appels précise, un pattern d'allocation, ou un pic GPU) au lieu de dépendre d'essais/erreurs.
Corrections plus rapides pour les problèmes à fort impact
Une meilleure visibilité réduit le temps de correction car elle transforme des débats en preuves. Les équipes peuvent capturer une trace, la partager et s'accorder rapidement sur le goulot — souvent en réduisant des jours de spéculations en un patch ciblé et une mesure avant/après.
Fiabilité à grande échelle : appareils, mises à jour OS et cas limites
La performance n'est pas la seule chose qui casse quand vous déployez sur des millions de téléphones — la consistance aussi. La même app peut se comporter différemment selon les versions OS, les personnalisations OEM et même les drivers GPU du fournisseur. La fiabilité à grande échelle, c'est la capacité à garder votre app prévisible quand l'écosystème ne l'est pas.
Pourquoi « même Android/iOS » n'est pas vraiment le même
Sur Android, les skins OEM peuvent modifier les limites d'arrière‑plan, les notifications, les pickers de fichiers et la gestion d'énergie. Deux appareils sur la même version Android peuvent différer parce que les fournisseurs embarquent des composants système différents.
Les GPUs ajoutent une autre variable. Les drivers (Adreno, Mali, PowerVR) divergent en précision des shaders, formats de textures et optimisations. Un chemin de rendu correct sur un GPU peut montrer des scintillements, du banding ou des crashs rares sur un autre — surtout autour de la vidéo, la caméra et le graphisme personnalisé.
iOS est plus contraint, mais les mises à jour OS modifient néanmoins le comportement : flux d'autorisations, particularités du clavier/autofill, règles de session audio et politiques de tâches d'arrière‑plan peuvent changer subtilement entre versions mineures.
Pourquoi le natif gère souvent mieux les cas limites
Les plateformes natives exposent d'abord les vraies APIs. Quand l'OS change, les SDKs natifs et la documentation reflètent généralement ces changements immédiatement, et les outils plateforme (Xcode/Android Studio, logs système, symboles de crash) s'alignent sur ce qui tourne sur les appareils.
Les stacks cross-platform ajoutent une couche de traduction : le framework, son runtime/renderer et les plugins. Quand un cas limite apparaît, vous déboguez à la fois votre app et le bridge.
Risque de dépendances : mises à jour, breaking changes et qualité des plugins
Les mises à jour de framework peuvent introduire des changements runtime (threading, rendu, saisie texte, gestion des gestes) qui ne se manifestent que sur certains appareils. Les plugins peuvent être pires : certains sont de simples wrappers ; d'autres embarquent du code natif lourd avec une maintenance inégale.
Checklist : évaluer les bibliothèques tierces dans les chemins critiques
- Maintenance : releases récentes, triage actif des issues, responsabilité claire.
- Parité native : utilise les APIs officielles de la plateforme (pas des hooks privés/non supportés).
- Performance : benchmarks, évite les copies/allocation superflues, minimalise les passages de bridge.
- Modes de défaillance : fallback gracieux, timeouts et reporting d'erreurs.
- Compatibilité : testé sur versions OS, appareils OEM et fournisseurs GPU.
- Observabilité : logs, symboles de crash et cas de test reproductibles.
- Sécurité de mise à jour : discipline semver, changelogs, notes de migration.
À grande échelle, la fiabilité n'est presque jamais une question d'un bug — c'est réduire le nombre de couches où des surprises peuvent se cacher.
Graphismes, média et ML : quand le natif est clairement avantageux
Fixez des budgets de performance dès le départ
Lancez rapidement un MVP, puis profilez de vrais appareils avec des objectifs clairs de latence et d'images par seconde.
Certains workloads punissent même de petits surcoûts. Si votre app a besoin d'un FPS soutenu élevé, d'un travail GPU lourd, ou d'un contrôle serré sur le décodage et les buffers, les frameworks natifs gagnent généralement car ils peuvent piloter directement les chemins les plus rapides de la plateforme.
Workloads favorisant fortement le natif
Le natif est un choix clair pour scènes 3D, expériences AR, jeux à haute fréquence, montage vidéo et apps centrées sur la caméra avec filtres temps réel. Ces cas ne sont pas seulement « lourds en calcul » — ils sont lourds en pipeline : vous déplacez de grandes textures et images entre CPU, GPU, caméra et encodeurs des dizaines de fois par seconde.
Copies supplémentaires, frames tardives ou synchronisations manquantes se traduisent immédiatement par frames perdues, surchauffe ou contrôles saccadés.
Accès direct aux APIs GPU, codecs et accélération
Sur iOS, le code natif peut parler Metal et à la pile média système sans couches intermédiaires. Sur Android, il peut accéder à Vulkan/OpenGL et aux codecs plateforme via le NDK et les APIs média.
Ceci importe parce que la soumission de commandes GPU, la compilation de shaders et la gestion des textures sont sensibles à la façon dont l'app ordonne le travail.
Pipelines de rendu et uploads de textures (haut niveau)
Un pipeline temps réel typique : capture ou chargement de frames → conversion de format → upload de textures → exécution de shaders GPU → composition UI → présentation.
Le code natif peut réduire l'overhead en conservant les données dans des formats GPU‑friendly plus longtemps, en regroupant les draw calls et en évitant des uploads de texture répétés. Même une conversion inutile par frame (ex. RGBA ↔ YUV) peut ajouter un coût suffisant pour briser la lecture fluide.
Inférence ML : débit, latence et puissance
Le ML embarqué dépend souvent de délégués/backends (Neural Engine, GPU, DSP/NPU). L'intégration native tend à exposer ces options plus tôt et avec plus de possibilités de tuning — important quand vous vous souciez à la fois de la latence d'inférence et de la batterie.
Stratégie hybride : modules natifs pour les hotspots
Vous n'avez pas toujours besoin d'une app entièrement native. Beaucoup d'équipes gardent une UI cross-platform pour la majorité des écrans, puis ajoutent des modules natifs pour les hotspots : pipelines caméra, renderers personnalisés, moteurs audio ou inférence ML.
Cela peut fournir des performances proches du natif là où c'est nécessaire, sans tout réécrire.
Choisir un framework n'est pas une question d'idéologie mais d'adéquation entre les attentes utilisateur et ce que l'appareil doit faire. Si votre app paraît instantanée, reste fraîche et fluide sous stress, les utilisateurs demandent rarement de quoi elle est faite.
Matrice de décision pratique
Posez ces questions pour réduire rapidement les choix :
- Attentes utilisateur : s'agit‑il d'une app « utilitaire » où des hiccups sont tolérables, ou d'une expérience où le stutter brise la confiance (banque, navigation, collaboration live, outils créateurs) ?
- Besoins matériels : avez‑vous besoin du pipeline caméra, de périphériques Bluetooth, de capteurs, d'exécution en arrière‑plan, d'audio basse latence, d'AR ou d'un travail GPU lourd ? Plus vous vous rapprochez du matériel, plus le natif rapporte.
- Délais et vitesse d'itération : le cross-platform réduit le time‑to‑market pour des UI simples et des flux partagés. Le natif peut être plus rapide pour le tuning de performance car vous travaillez directement avec les outils et APIs plateforme.
- Compétences d'équipe et recrutement : une équipe iOS/Android solide sortira un code natif de meilleure qualité plus vite. Une petite équipe avec expérience web atteindra un MVP plus vite en cross‑platform — si les contraintes de performance sont modérées.
Si vous prototypez plusieurs directions, validez rapidement les flux produits avant d'investir dans l'optimisation native profonde. Par exemple, des équipes utilisent parfois Koder.ai pour générer une web app fonctionnelle (React + Go + PostgreSQL) via chat, tester l'UX et le modèle de données, puis s'engager sur une build mobile native ou hybride une fois les écrans critiques identifiés.
Ce que « hybride » signifie vraiment (et pourquoi ça gagne souvent)
Hybride ne veut pas forcément dire « web dans une app ». Pour les produits critiques en perf, hybride signifie généralement :
- Noyau natif + logique métier partagée : garder le networking, l'état et la logique domaine partagés, tandis que l'UI et les parties sensibles à la performance restent natives.
- Coquille native + UI partagée là où c'est sûr : utiliser l'UI partagée pour des écrans statiques ou basés sur des formulaires, et garder natif pour les vues riches en animations ou temps réel.
Cette approche limite le risque : vous pouvez optimiser les chemins chauds sans tout réécrire.
Mesurer d'abord, puis décider
Avant de vous engager, construisez un petit prototype de l'écran le plus dur (ex. flux live, timeline d'éditeur, carte + overlays). Mesurez la stabilité des frames, la latence, la mémoire et la batterie sur 10–15 minutes. Utilisez ces données — pas des suppositions — pour choisir.
Si vous utilisez un outil assisté par IA comme Koder.ai pour les premières itérations, traitez‑le comme un multiplicateur de vitesse pour explorer l'architecture et l'UX — pas comme un substitut au profilage sur appareil. Une fois que vous visez une expérience critique pour la performance, la même règle s'applique : mesurez sur des appareils réels, fixez des budgets de performance et maintenez les chemins critiques (rendu, entrée, média) aussi proches du natif que l'exigent vos besoins.
Éviter l'optimisation prématurée
Commencez par rendre l'app correcte et observable (profilage basique, logs, budgets de performance). N'optimisez que quand vous pouvez pointer un goulot que les utilisateurs ressentiront. Cela évite de passer des semaines à rogner des millisecondes qui ne sont pas sur le chemin critique.