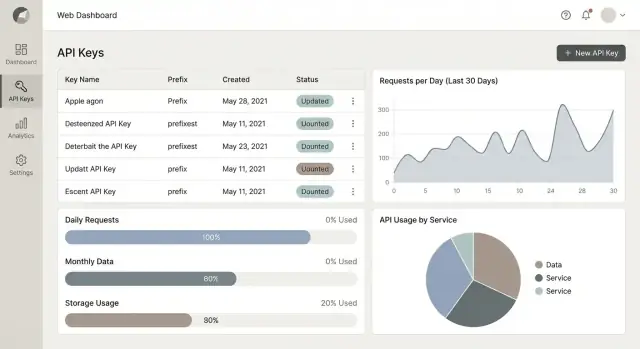
Ce que vous construisez et pour qui
Vous créez une application web qui se situe entre votre API et ceux qui la consomment. Son rôle est d'émettre des clés API, contrôler comment ces clés peuvent être utilisées, et expliquer ce qui s'est passé — d'une manière suffisamment claire pour les développeurs comme pour les non-développeurs.
Au minimum, elle répond à trois questions pratiques :
- Qui appelle l'API ? (Quel client, quelle application, quelle clé)
- Combien sont-ils autorisés à utiliser ? (Quotas, limites de débit, règles du plan)
- Combien ont-ils réellement utilisé ? (Mesure et analytics fiables)
Si vous voulez avancer vite sur le portail et l'interface admin, des outils comme Koder.ai peuvent vous aider à prototyper et livrer une base prête pour la production rapidement (frontend React + backend Go + PostgreSQL), tout en gardant le contrôle via l'export du code source, les snapshots/rollback et le déploiement/hosting.
Qui l'utilise
Une application de gestion de clés n'est pas uniquement pour les ingénieurs. Différents rôles y viennent avec des objectifs différents :
- Admins / propriétaires de plateforme veulent créer des politiques (limites, niveaux d'accès), résoudre les incidents rapidement et garder le contrôle sur de nombreux clients.
- Développeurs (vos clients ou équipes internes) veulent la création de clés en libre-service, une documentation simple et des réponses rapides quand quelque chose casse (« Pourquoi je reçois des 429 ? »).
- Finance et support veulent l'historique d'utilisation, des résumés par client et des données exploitables pour factures, crédits ou montées en gamme — sans lire des logs bruts.
Modules centraux dont vous aurez probablement besoin
La plupart des implémentations à succès convergent vers quelques modules centraux :
- Clés : créer des clés, les nommer/tagger, définir des permissions, faire des rotations, révoquer et voir la dernière utilisation.
- Quotas et limitation de débit : définir des limites par clé, par client, par endpoint et les appliquer de manière cohérente.
- Mesure d'utilisation : capturer les événements de requête (ou des résumés), puis les agréger en usage journalier/mensuel.
- Analytics : tableaux de bord qui expliquent les tendances d'utilisation, les endpoints principaux, les erreurs et la mise en throttling.
- Alertes : notifier quand l'utilisation grimpe, les quotas approchent du maximum, une clé est détournée ou les erreurs augmentent.
Portée : commencez simple, puis étendez
Un MVP solide se concentre sur l'émission de clés + limites basiques + rapports d'utilisation clairs. Les fonctionnalités avancées — comme les montées en gamme automatiques, workflows de facturation, proration et les termes contractuels complexes — peuvent venir plus tard une fois que vous avez confiance en votre mesure et votre application des règles.
Une « étoile du nord » pratique pour la première version : rendre simple pour quelqu'un la création d'une clé, la compréhension de ses limites et la visualisation de son usage sans ouvrir un ticket de support.
Checklist des exigences (MVP vs plus tard)
Avant d'écrire du code, décidez ce que signifie « terminé » pour la première release. Ce type de système grandit vite : la facturation, les audits et la sécurité entreprise arrivent plus tôt que prévu. Un MVP clair vous garde en livraison continue.
MVP : le minimum qui crée de la valeur
Au minimum, les utilisateurs doivent pouvoir :
- Créer et révoquer des clés API (avec un nom/label et une expiration optionnelle)
- Définir des quotas (par ex. requêtes/jour ou requêtes/mois) par clé ou par projet
- Faire appliquer des limites de débit (par ex. requêtes/min) pour protéger votre API
- Voir des graphiques d'utilisation (totaux journaliers simples, clés principales et taux d'erreur)
- Suivre des événements d'audit basiques (clé créée/révoquée, quota changé) pour le support et la responsabilité
Si vous ne pouvez pas émettre une clé en toute sécurité, la limiter et prouver ce qu'elle a fait, ce n'est pas prêt.
Besoins non-fonctionnels à décider d'emblée
- Performance : quel est le pic de requêtes/sec que vous devez mesurer sans perdre d'événements ?
- Fiabilité : avez-vous besoin de « ne jamais perdre d'événements d'utilisation », ou une « justesse finale » est-elle acceptable ?
- Rétention des données : combien de temps conservez-vous les événements bruts vs les totaux agrégés (ex. 7 jours bruts, 13 mois agrégés) ?
Modèle de locataire : organisation unique vs multi-tenant
Choisissez tôt :
- Organisation unique : plus rapide à construire, moins de cas d'usage pour les rôles/permissions.
- SaaS multi-locataire : nécessite isolation des tenants, quotas par tenant et rôles admin dès le départ.
Fonctionnalités « plus tard » utiles à planifier
Flux de rotation, notifications webhook, exports de facturation, SSO/SAML, quotas par endpoint, détection d'anomalies et journaux d'audit enrichis.
Mesures de succès (rendre mesurable)
- Temps pour émettre une clé : ex. moins de 2 minutes du signup à la première clé
- Précision de la mesure : ex. <0.5% d'écart entre les comptes de la gateway et les agrégats
- Charge du support : moins de tickets « pourquoi ai-je été bloqué ? » ; explications claires des quotas/limits
Options d'architecture de haut niveau
Votre choix d'architecture devrait partir d'une question : où appliquez-vous l'accès et les limites ? Cette décision affecte la latence, la fiabilité et la rapidité de livraison.
Option 1 : appliquer au niveau de l'API gateway
Une API gateway (managée ou auto-hébergée) peut valider les clés API, appliquer les limites de débit et émettre des événements d'utilisation avant que les requêtes n'atteignent vos services.
C'est un bon choix lorsque vous avez plusieurs services backend, besoin de politiques cohérentes, ou voulez garder l'enforcement hors du code applicatif. L'inconvénient : la configuration de la gateway peut devenir un « produit » à part entière, et le débogage nécessite un bon traçage.
Option 2 : appliquer au niveau du reverse proxy
Un reverse proxy (ex. NGINX/Envoy) peut gérer les vérifications de clés et la limitation de débit via des plugins ou des hooks d'auth externes.
C'est adapté quand vous voulez une couche d'edge légère, mais il peut être plus difficile de modéliser des règles métiers complexes (plans, quotas par tenant, cas particuliers) sans services de soutien.
Option 3 : appliquer dans le middleware de l'application
Mettre les vérifications dans votre application API (middleware) est souvent le plus rapide pour un MVP : une seule base de code, un seul déploiement, tests locaux plus simples.
Cela peut devenir compliqué à mesure que vous ajoutez des services — dérive de politique et duplication de logique sont courantes — donc planifiez une extraction éventuelle vers un composant partagé ou une couche d'edge.
Séparez les préoccupations tôt
Même si vous commencez petit, gardez des frontières claires :
- Auth (la clé est-elle valide ?), quota/limite (est-ce permis maintenant ?), mesure (enregistrer ce qui s'est passé), UI analytics (l'afficher).
Tracking synchrone vs asynchrone
Pour la mesure, décidez ce qui doit arriver dans le chemin de requête :
- Synchrone : incrémenter les compteurs avant de répondre (enforcement précis, latence plus élevée).
- Asynchrone : émettre des événements vers une queue/log pour agrégation (requêtes plus rapides, cohérence éventuelle des rapports).
Planifiez l'échelle : chemins chauds vs froids
Les vérifications de taux sont le chemin chaud (optimiser pour faible latence, en mémoire/Redis). Les rapports et tableaux de bord sont le chemin froid (optimiser pour requêtes flexibles et agrégations batch).
Modèle de données pour clés, quotas et usage
Un bon modèle sépare trois préoccupations : qui possède l'accès, quelles limites s'appliquent, et ce qui s'est réellement passé. Si cela est bien fait, tout le reste — rotation, tableaux de bord, facturation — devient plus simple.
Entités principales (ce dont vous avez besoin le jour 1)
Au minimum, modélisez ces tables (ou collections) :
- Organization : frontière du tenant (propriétaire de facturation, membres).
- Project/App : conteneur pour les clés et les paramètres (souvent correspondant à un client API).
- API Key : métadonnées sur un credential (nom, statut, created_at, last_used_at).
- Plan : un ensemble de limites et de fonctionnalités (ex. Free, Pro).
- Quota : règles de limite spécifiques (ex. 10k requêtes/jour, 60 req/min).
- Usage Event : enregistrement brut d'utilisation (timestamp, project_id, endpoint, code de statut, unités).
Stocker les métadonnées séparément des secrets
Ne stockez jamais les tokens bruts. Stockez uniquement :
- Un préfixe de clé (6–8 premiers chars) pour affichage/recherche.
- Un verifier pour le token (typiquement SHA-256 ou HMAC-SHA-256 avec un pepper côté serveur sur un secret aléatoire de 32–64 bytes) pour la vérification.
- Optionnel : scopes, environnement (prod/sandbox) et expires_at.
Cela vous permet d'afficher « Key: ab12cd… » tout en gardant le secret irrécupérable.
Auditabilité : ce n'est pas optionnel
Ajoutez des tables d'audit tôt : KeyAudit et AdminAudit (ou un seul AuditLog) capturant :
- actor_id (utilisateur/service), action, target_type/id
- before/after (pour les edits de quota)
- ip/user_agent, timestamp
Quand un client demande « qui a révoqué ma clé ? », vous aurez la réponse.
Fenêtres temporelles et compteurs
Modélisez les quotas avec des fenêtres explicites : per_minute, per_hour, per_day, per_month.
Stockez les compteurs dans une table séparée comme UsageCounter indexée par (project_id, window_start, window_type, metric). Cela rend les remises à zéro prévisibles et accélère les requêtes analytiques.
Pour les vues du portail, vous pouvez agréger les Usage Events en rollups journaliers et lier vers /blog/usage-metering pour plus de détails.
Authentification, autorisations et rôles
Si votre produit gère des clés API et l'usage, l'accès à votre application doit être plus strict qu'un tableau CRUD classique. Un modèle de rôles clair garde les équipes productives tout en évitant le glissement « tout le monde est admin ».
Conception des rôles qui correspondent aux équipes réelles
Commencez par un petit ensemble de rôles par organisation (tenant) :
- Owner : contrôle total, propriété de la facturation, peut gérer les paramètres org et supprimer l'org.
- Admin : gère utilisateurs, projets, clés, quotas et paramètres de sécurité.
- Developer : peut créer/faire tourner des clés pour les projets assignés, voir l'utilisation, mais ne peut pas changer la facturation ou la sécurité org-wide.
- Read-only : peut voir les clés (masquées), quotas et analytics.
- Finance : peut voir factures/rapports de coûts d'utilisation, exporter des données, mais ne gère pas les clés.
Gardez les permissions explicites (ex. keys:rotate, quotas:update) pour ajouter des fonctionnalités sans réinventer les rôles.
Connexion sécurisée pour les humains
Utilisez username/password uniquement si nécessaire ; sinon supportez OAuth/OIDC. SSO est optionnel, mais MFA doit être requis pour les owners/admins et fortement conseillé pour tous.
Ajoutez des protections de session : tokens d'accès courte durée, rotation des refresh tokens et gestion des appareils/sessions.
Authentification pour les APIs que vous protégez
Proposez une clé API par défaut dans un en-tête (ex. Authorization: Bearer <key> ou X-API-Key). Pour les clients avancés, ajoutez l'option HMAC signing (prévenir les replays/manipulations) ou JWT (bon pour l'accès court-terme et scoppé). Documentez-les clairement dans votre portail développeur.
Isolation des tenants : non négociable
Faites respecter l'isolation à chaque requête : org_id partout. N'utilisez pas seulement le filtrage UI — appliquez org_id dans les contraintes DB, les politiques de niveau de ligne (si disponibles) et les vérifications côté service, et écrivez des tests qui tentent des accès inter-tenant.
Cycle de vie des clés API : création, rotation, révocation
Intégrez l'auditabilité
Mettez en place des journaux d'audit pour les actions sur les clés et les changements de quota dès le départ, afin que le support ait des réponses.
Un bon cycle de vie garde les clients productifs tout en vous donnant des moyens rapides de réduire le risque. Concevez l'UI et l'API pour que le « chemin heureux » soit évident, et que les options plus sûres (rotation, expiration) soient par défaut.
Création : capter l'intention, pas juste une chaîne
Dans le flux de création, demandez un nom (ex. « Prod server », « Local dev ») et les scopes/permissions pour que la clé soit en moindre privilège dès le départ.
Si pertinent, ajoutez des restrictions optionnelles comme origines autorisées (pour usage navigateur) ou IP/CIDR autorisés (pour serveur à serveur). Gardez-les optionnelles avec des avertissements clairs sur les risques de verrouillage.
Après création, affichez la clé brute une seule fois. Fournissez un gros bouton « Copier » et des conseils succincts : « Stockez dans un gestionnaire de secrets. Nous ne pouvons pas la réafficher. » Liez directement vers les instructions d'installation comme /docs/auth.
Rotation : faites-en une routine, pas un incident
La rotation doit suivre un schéma prévisible :
- Créez une nouvelle clé avec les mêmes scopes et restrictions.
- Déployez/mettez à jour l'intégration pour utiliser la nouvelle clé.
- Vérifiez que le trafic fonctionne.
- Révoquez l'ancienne clé.
Dans l'UI, fournissez une action « Rotate » qui crée une clé de remplacement et marque l'ancienne comme « Pending revoke » pour encourager le nettoyage.
Révocation et expiration : immédiates et planifiées
La révocation doit désactiver la clé immédiatement et enregistrer qui l'a fait et pourquoi.
Supportez aussi l'expiration programmée (ex. 30/60/90 jours) et les dates « expires on » pour les contractors temporaires ou essais. Les clés expirées doivent échouer de manière prédictible avec une erreur d'auth claire pour que les développeurs sachent quoi corriger.
Les limites de débit et les quotas résolvent des problèmes différents, et les confondre est une source fréquente de tickets « pourquoi ai-je été bloqué ? ».
Rate limits vs quotas
Les rate limits contrôlent les rafales (ex. « pas plus de 50 requêtes par seconde »). Elles protègent votre infrastructure et empêchent un client bruyant de dégrader les autres.
Les quotas plafonnent la consommation totale sur une période (ex. « 100 000 requêtes par mois »). Elles concernent l'application des plans et la facturation.
Beaucoup de produits utilisent les deux : un quota mensuel pour l'équité et un rate limit par seconde/minute pour la stabilité.
Choisir un algorithme d'enforcement
Pour la limitation en temps réel, choisissez un algorithme explicable et fiable :
- Token bucket : des jetons sont reconstitués dans le temps ; chaque requête consomme un jeton. Idéal pour permettre de petites rafales tout en gardant un rythme moyen.
- Leaky bucket : les requêtes « s'écoulent » à un rythme constant. Bon pour lisser le trafic mais peut sembler plus strict.
Le token bucket est généralement le meilleur choix par défaut pour des APIs destinées aux développeurs car il est prévisible et indulgent.
Choisir où stocker les compteurs
Vous aurez généralement besoin de deux magasins :
- Redis (ou équivalent) pour des vérifications rapides, atomiques et en temps réel à la gateway/edge.
- Votre base de données pour un reporting durable et l'historique de facturation.
Redis répond à « cette requête peut-elle s'exécuter maintenant ? ». La base de données répond à « combien ont-ils utilisé ce mois-ci ? ».
Définir ce qui compte comme utilisation
Soyez explicite par produit et par endpoint. Mètres courants : requêtes, tokens, octets transférés, poids par endpoint, ou temps CPU.
Si vous utilisez des endpoints pondérés, publiez les poids dans la doc et le portail.
Rendre les réponses d'erreur exploitables
Lors d'un blocage, retournez des erreurs claires et cohérentes :
- 429 Too Many Requests pour la limitation de débit. Incluez
Retry-After et éventuellement des en-têtes comme X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Reset.
- 402 Payment Required (ou 403) pour l'accès hors-quota sur des plans payants. Incluez l'utilisation de la période courante, la limite et un lien vers /billing ou /pricing.
De bons messages réduisent le churn : les développeurs peuvent faire un backoff, ajouter des retries ou upgrader sans deviner.
Mesure d'utilisation : collecte et agrégation des événements
La mesure d'utilisation est la « source de vérité » pour les quotas, les factures et la confiance client. L'objectif est simple : compter ce qui s'est passé, de manière cohérente, sans ralentir l'API.
Que logger par requête (et quoi éviter)
Pour chaque requête, capturez un petit payload d'événement prévisible :
- timestamp (heure serveur)
- key_id (ou identifiant du token)
- endpoint (nom de route, pas URL complète)
- status (ex. 200, 401, 429)
- units (combien compter : 1 requête, tokens, octets, etc.)
Évitez de logger les bodies request/response. Redactez les en-têtes sensibles par défaut (Authorization, cookies) et traitez les PII comme « opt-in avec besoin fort ». Si vous devez logger quelque chose pour le debugging, stockez-le séparément avec une rétention courte et des contrôles d'accès stricts.
Garder l'API rapide avec un pipeline d'événements
N'agrégez pas en ligne pendant la requête. Au lieu de cela :
- L'API écrit un événement dans une queue/stream (ou une table append-only légère).
- Un worker consomme les événements et met à jour les agrégats journaliers/horaire.
Cela maintient une latence stable même en cas de pics de trafic.
Idempotence, retries et double-comptage
Les queues peuvent livrer des messages plusieurs fois. Ajoutez un event_id unique et appliquez la déduplication (contrainte unique ou cache “seen” avec TTL). Les workers doivent être retry-safe pour qu'un crash n'altère pas les totaux.
Rétention : bruts court-terme, agrégats long-terme
Conservez les événements bruts brièvement (jours/semaines) pour audit et investigation. Gardez les métriques agrégées beaucoup plus longtemps (mois/années) pour les tendances, l'application des quotas et la facturation.
Tableaux de bord analytics que les gens utilisent vraiment
Réduisez les coûts de développement
Obtenez des crédits en créant du contenu sur Koder.ai ou en recommandant Koder.ai à des coéquipiers pour qu'ils l'essayent.
Un tableau d'utilisation ne doit pas être une « jolie page de graphiques ». Il doit répondre rapidement à deux questions : qu'est-ce qui a changé ? et que dois-je faire ensuite ? Concevez autour des décisions — debugging des pics, prévention des dépassements et démonstration de valeur à un client.
Vues de base à livrer en premier
Commencez par quatre panneaux qui correspondent aux besoins quotidiens :
- Utilisation dans le temps (requêtes/jour ou requêtes/min), avec une comparaison claire à la période précédente.
- Endpoints principaux (par volume et par coût/poids si vous avez des quotas pondérés).
- Taux d'erreur (4xx vs 5xx) pour séparer erreurs clients et problèmes de service.
- Latence (optionnel) p50/p95 ; incluez-le seulement si vous pouvez le mesurer de façon fiable.
Rendre actionnable, pas décoratif
Chaque graphique doit être relié à une étape suivante. Affichez :
- Quota restant pour le cycle en cours (ex. 18 200 sur 50 000 restants)
- Projection d'utilisation au rythme actuel, avec un simple indicateur « dépassera / restera en dessous »
Quand une probabilité de dépassement est détectée, liez directement vers le chemin de montée en gamme : /plans (ou /pricing).
Filtres qui correspondent à la manière dont les gens travaillent
Ajoutez des filtres qui facilitent l'investigation sans forcer les utilisateurs dans des builders de requêtes complexes :
- Plage temporelle (24h, 7j, 30j, personnalisé)
- Clé API, projet, environnement (prod/staging)
- Endpoint et famille de codes de statut
Export et accès API
Incluez un téléchargement CSV pour la finance et le support, et fournissez une API métrique légère (ex. GET /api/metrics/usage?from=...&to=...&key_id=...) pour que les clients tirent les données dans leurs propres outils BI.
Alertes, notifications et préparation à la facturation
Les alertes sont la différence entre « nous avons remarqué un problème » et « les clients l'ont remarqué en premier ». Concevez-les autour des questions posées sous pression : Que s'est-il passé ? Qui est affecté ? Que dois-je faire ensuite ?
Sur quoi alerter (et quand)
Commencez par des seuils prévisibles liés aux quotas. Un schéma simple qui marche bien : 50% / 80% / 100% d'utilisation du quota dans une période de facturation.
Ajoutez quelques alertes comportementales à fort signal :
- Pics inhabituels : utilisation s'écartant fortement de la baseline récente d'un tenant (ex. ×3 la moyenne horaire)
- Échecs d'authentification : augmentation soudaine d'utilisation de clés invalides ou d'erreurs de signature
- Pression sur les rate-limits : événements de throttling soutenus indiquant un client mal configuré
Rendez les alertes actionnables : incluez tenant, clé/app, groupe d'endpoints (si dispo), fenêtre temporelle et un lien vers la vue pertinente du portail (ex. /dashboard/usage).
Canaux de notification
L'email est le socle car tout le monde l'a. Ajoutez des webhooks pour les équipes qui veulent router les alertes vers leurs systèmes. Si vous supportez Slack, traitez-le comme optionnel et gardez la configuration légère.
Règle pratique : fournissez une politique de notification par tenant — qui reçoit quelles alertes et selon quel niveau de sévérité.
Rapports d'utilisation simples que les gens lisent
Proposez un résumé quotidien/hebdomadaire mettant en avant requêtes totales, endpoints principaux, erreurs, throttles et « variation vs période précédente ». Les parties prenantes veulent des tendances, pas des logs bruts.
Préparation à la facturation sans s'engager tout de suite
Même si la facturation est « plus tard », stockez :
- Historique des plans (quel plan un tenant avait et quand)
- Dates d'effet des tarifs (pour des recalculs cohérents)
Cela vous permet de reconstituer des factures ou des aperçus sans réécrire le modèle de données.
Modèle simple de message
Chaque message doit indiquer : ce qui s'est passé, l'impact, et la prochaine étape (faire tourner la clé, upgrader le plan, investiguer le client ou contacter le support via /support).
Lancez un environnement réel
Déployez et hébergez votre portail, puis ajoutez un domaine personnalisé quand vous êtes prêt.
La sécurité pour une appli de gestion de clés API tient moins aux fonctionnalités tape-à-l'œil qu'aux choix par défaut prudents. Traitez chaque clé comme un credential et supposez qu'elle finira par être copiée au mauvais endroit.
Protéger les clés API
Ne stockez jamais les clés en clair. Conservez un verifier dérivé du secret (généralement SHA-256 ou HMAC-SHA-256 avec un pepper côté serveur) et n'affichez la valeur complète à l'utilisateur qu'au moment de la création.
Dans l'UI et les logs, n'affichez qu'un préfixe non sensible (par ex. ak_live_9F3K…) pour identifier une clé sans l'exposer.
Fournissez des conseils pratiques de « secret scanning » : rappelez aux utilisateurs de ne pas committer de clés sur Git et liez vers leurs outils (par ex. la détection GitHub) dans la doc du portail /docs.
Protections admin (souvent négligées)
Les attaquants visent les endpoints admin car ils peuvent créer des clés, augmenter des quotas ou désactiver des limites. Appliquez des limites de débit aussi aux APIs admin, et envisagez une allowlist IP pour l'accès admin (utile pour les équipes internes).
Utilisez le principe du moindre privilège : séparez les rôles (viewer vs admin) et restreignez qui peut changer les quotas ou faire tourner des clés.
Journaux d'audit et rétention
Enregistrez les événements d'audit pour création/rotation/révocation de clés, tentatives de connexion et modifications de quota. Conservez les logs résistants à la falsification (stockage append-only, accès en écriture restreint, sauvegardes régulières).
Adoptez tôt des bases de conformité : minimisation des données (ne stockez que ce qui est nécessaire), contrôles de rétention clairs (suppression automatique des vieux logs) et règles d'accès documentées.
Scénarios de menace à anticiper
Fuite de clés, abus par replay, scraping du portail, et tenants « bruyants » consommant la capacité partagée. Concevez des mitigations (hashing/verifiers, tokens courts quand possible, limites de débit et quotas par tenant) autour de ces réalités.
UX Admin et Portail développeur
Un excellent portail rend le « chemin sûr » le plus simple : les admins peuvent réduire le risque rapidement, et les développeurs obtiennent une clé fonctionnelle et un appel de test sans écrire au support.
UX Admin : rapidité, contrôle et confiance
Les admins arrivent souvent avec une tâche urgente (« révoquer cette clé maintenant », « qui a créé ceci ? », « pourquoi l'usage a-t-il spike ? »). Conception pour l'analyse rapide et l'action décisive.
Utilisez une recherche rapide qui fonctionne sur les préfixes d'ID de clé, noms d'app, utilisateurs et noms de workspace/tenant. Associez-la à des indicateurs d'état clairs (Active, Expired, Revoked, Compromised, Rotating) et des timestamps comme « last used » et « created by ». Ces deux champs prévient beaucoup de révocations accidentelles.
Pour les opérations à grand volume, ajoutez des actions en masse avec des protections : révocation en masse, rotation en masse, changement de palier de quota en masse. Affichez toujours un écran de confirmation avec le compte et un résumé d'impact (« 38 clés seront révoquées ; 12 ont été utilisées au cours des 24 dernières heures »).
Fournissez un panneau détail audit-friendly pour chaque clé : scopes, application associée, IPs autorisées (si présentes), palier de quota et erreurs récentes.
UX Développeur : rendre le succès immédiat
Les développeurs veulent copier, coller et passer à autre chose. Placez la doc claire à côté du flux de création de clé, pas enfouie ailleurs. Proposez des exemples curl copiable et un sélecteur de langage (curl, JS, Python) si possible.
Affichez la clé une fois avec un bouton « copier », plus un rappel court sur le stockage. Guidez-les ensuite via un pas « Appeler le test » qui exécute une vraie requête contre un sandbox ou un endpoint à faible risque. Si ça échoue, fournissez des explications d'erreur en anglais simple, incluant des corrections courantes :
- « Invalid key » → vérifiez le nom de l'en-tête et les espaces
- « Forbidden » → scope/role manquant
- « Rate limited » → comment voir les quotas et le retry-after
Onboarding en self-serve en quelques minutes
Un chemin simple marche le mieux : Créer la première clé → faire un appel de test → voir l'utilisation. Même un petit graphique d'usage (« 15 dernières minutes ») renforce la confiance que la mesure fonctionne.
Liez directement les pages pertinentes avec des routes relatives comme /docs, /keys, et /usage.
Accessibilité et clarté
Utilisez des labels simples (« Requêtes par minute », « Requêtes mensuelles ») et gardez les unités cohérentes. Ajoutez des tooltips pour des termes comme « scope » et « burst ». Assurez la navigation clavier, des états de focus visibles et un contraste suffisant — en particulier sur les badges d'état et les bannières d'erreur.
Déploiement, monitoring et tests
Mettre ce type de système en production tient surtout à la discipline : déploiements prévisibles, visibilité claire en cas de panne et tests focalisés sur les chemins chauds (auth, vérifs de limites et mesure).
Configuration de déploiement (secrets, vars d'env, migrations)
Gardez la configuration explicite. Stockez les paramètres non sensibles dans des variables d'environnement (ex. defaults de rate-limit, noms de queues, fenêtres de rétention) et placez les secrets dans un store géré (AWS Secrets Manager, GCP Secret Manager, Vault). Évitez d'encapsuler des clés dans les images.
Exécutez les migrations DB comme une étape de pipeline de première classe. Préférez une stratégie « migrer puis déployer » pour des changements rétrocompatibles, et planifiez des rollbacks sûrs (les feature flags aident). Si vous êtes multi-tenant, ajoutez des contrôles pour éviter des migrations qui scannent toutes les tables de tenant.
Si vous construisez le système sur Koder.ai, les snapshots et rollback peuvent être un filet de sécurité pratique pour ces itérations initiales (surtout pendant l'affinage de la logique d'enforcement et des schémas).
Observabilité qui répond aux vraies questions
Vous avez besoin de trois signaux : logs, métriques et traces. Instrumentez la limitation de débit et l'application des quotas avec des métriques telles que :
- Requêtes autorisées vs rejetées (par clé API, endpoint et tenant)
- « Codes raisons » des rejets (rate limit, quota dépassé, clé invalide)
- Latence du pipeline de mesure (ingest d'événements → délai d'agrégation)
Créez un tableau dédié aux rejets pour support afin que l'équipe puisse répondre à « pourquoi mon trafic échoue ? » sans deviner. Le tracing aide à repérer les dépendances lentes sur le chemin critique (lookups DB pour le statut de clé, misses cache, etc.).
Sauvegardes et priorités de récupération
Traitez les données de config (clés, quotas, rôles) comme haute-priorité et les événements d'usage comme haut-volume. Sauvegardez la configuration fréquemment avec récupération point-in-time.
Pour les données d'usage, concentrez-vous sur la durabilité et la possibilité de rejouer : un write-ahead log/queue plus une ré-agrégation est souvent plus pratique que des sauvegardes complètes fréquentes.
Plan de tests et de déploiement progressif
Tests unitaires pour la logique des limites (cas limites : bordures de fenêtres, requêtes concurrentes, rotation de clés). Load-testez les chemins les plus chauds : validation de clé + mises à jour de compteurs.
Puis déployez par étapes : utilisateurs internes → beta limitée (tenants sélectionnés) → GA, avec un kill switch pour désactiver l'enforcement si nécessaire.