21 août 2025·8 min
Créer une application Web pour gérer les dépréciations de fonctionnalités et les migrations
Planifiez, construisez et déployez une appli web qui suit les dépréciations de fonctionnalités, guide les migrations utilisateurs, automatise les notifications et mesure l'adoption en toute sécurité.
Ce qu'une application de gestion des dépréciations résout
Une dépréciation de fonctionnalité est tout changement planifié où quelque chose sur lequel les utilisateurs comptent est réduit, remplacé ou supprimé. Cela peut signifier :
- Une fonctionnalité d'UI qui disparaît ou est déplacée (boutons, tableaux de bord, paramètres)
- Un endpoint d'API qui est retiré, versionné ou dont le comportement change
- Un changement de plan ou d'attribution (limites réduites, addon fusionné, niveau tarifaire retiré)
Même quand l'orientation produit est la bonne, les dépréciations échouent lorsqu'elles sont traitées comme une annonce ponctuelle plutôt que comme un workflow de dépréciation géré.
Modes d'échec courants
Les suppressions surprises sont l'exemple évident, mais les vrais dégâts apparaissent souvent ailleurs : intégrations cassées, docs de migration incomplètes, messages incohérents entre les canaux et pics de support juste après une release.
Les équipes perdent aussi la trace de « qui est affecté » et « qui a approuvé quoi ». Sans piste d'audit, il est difficile de répondre à des questions basiques : quels comptes utilisent encore l'ancien flag ? Quels clients ont été notifiés ? Quelle date avait-on promise ?
Pourquoi une application dédiée aide
Une appli de gestion des dépréciations centralise la planification des retraits, de sorte que chaque dépréciation a un propriétaire clair, un calendrier et un statut. Elle impose des communications cohérentes (email, notifications in-app, automatisation des notes de version), suit la progression de la migration des utilisateurs et crée de la responsabilité via des approbations et une piste d'audit.
Au lieu de documents et feuilles de calcul dispersés, vous obtenez une source unique de vérité pour la détection d'impact, les modèles de messages et l'analyse d'adoption.
Qui l'utilise
Les product managers coordonnent la portée et les dates. L'ingénierie relie les changements aux feature flags et aux releases. Le support et Customer Success s'appuient sur des listes de clients et des scripts précis. Compliance et Sécurité peuvent exiger des approbations, la conservation des notifications et la preuve que les clients ont été informés.
Objectifs, périmètre et non-objectifs
Une application de gestion des dépréciations doit réduire le chaos, pas ajouter un autre endroit à « vérifier ». Avant de concevoir des écrans ou des modèles de données, mettez-vous d'accord sur ce à quoi ressemble le succès et ce qui est explicitement hors-scope.
Objectifs (ce pour quoi vous optimisez)
Commencez par des résultats pertinents pour le Produit, le Support et l'Ingénierie :
- Moins de tickets et d'escalades liés aux changements cassants (mesure : volume de tickets tagués pour la dépréciation).
- Plus de migrations complètes avant la date butoir (mesure : % migrés par cohorte/plan).
- Moins de réversions de dernière minute parce que des risques ont été découverts tard (mesure : nombre d'extensions de délai ou de rollbacks).
Convertissez ces objectifs en métriques claires et niveaux de service :
- Temps depuis l'annonce → première action client
- Temps depuis l'annonce → 80% migré
- % migré à la date butoir (global et par comptes prioritaires)
- SLA pour les communications : par ex. « Les clients reçoivent au moins 30 jours de préavis pour les suppressions majeures. »
Périmètre (ce que l'app gère)
Soyez précis sur l'objet de la dépréciation. Vous pouvez commencer étroit et élargir :
- Fonctionnalités produit (comportement UI, paramètres)
- Endpoints/champs API
- Intégrations (webhooks, connecteurs tiers)
- Plans/niveaux (attributions, limites)
- Ou un modèle unifié de « changement » capable de représenter tout cela
Définissez aussi ce que « migration » signifie dans votre contexte : activer une nouvelle fonctionnalité, changer d'endpoint, installer une nouvelle intégration ou compléter une checklist.
Contraintes (règles à respecter)
Contraintes communes qui façonnent la conception :
- Confidentialité & conformité : quelles données utilisateur/compte peuvent être stockées et affichées
- Rétention des données : durée de la piste d'audit, besoins d'export, politiques de suppression
- Exigences multi-tenant : segmentation par workspace/org, hébergement régional
- Approbations : qui peut publier des calendriers, envoyer des messages clients ou modifier des dates
Non-objectifs (ce qu'il ne faut pas construire)
Pour éviter le scope creep, décidez tôt de ce que l'app ne fera pas — au moins pour la v1 :
- Remplacer votre helpdesk, site de docs ou CRM complet
- Agir comme un outil général de gestion de projet
- Migrer automatiquement les clients sans garde-fous explicites et propritété
Des objectifs et limites clairs facilitent l'alignement futur sur workflow, permissions et notifications.
Cycle de vie de la dépréciation et étapes du workflow
Une application de gestion des dépréciations doit rendre le cycle de vie explicite afin que tout le monde sache ce qu'est le « bon » comportement et ce qui doit se produire avant d'avancer. Commencez par cartographier votre processus actuel de bout en bout : annonce initiale, rappels programmés, playbooks support et suppression finale. Le workflow de l'app doit d'abord refléter la réalité, puis la standardiser progressivement.
Un modèle d'étapes simple et faisable
Un défaut pratique est :
Proposé → Approuvé → Annoncé → Migration → Suppression → Terminé
Chaque étape doit avoir une définition claire, des critères de sortie et un propriétaire. Par exemple, « Annoncé » ne doit pas signifier « quelqu'un a posté un message une fois » ; cela doit signifier que l'annonce a été livrée via les canaux convenus et que les suivis sont planifiés.
Points de contrôle qui empêchent le chaos de dernière minute
Ajoutez des points de contrôle requis qui doivent être complétés (et enregistrés) avant qu'une étape puisse être marquée complète :
- Revue juridique/comm pour le libellé, les dates et les implications contractuelles
- Documentation mise à jour (docs, FAQ, notes de version, runbooks internes)
- Plan de rollback ou d'atténuation prêt, incluant qui décide et comment exécuter
- Préparation du support, y compris macros/scripts et chemins d'escalade
Considérez ces éléments comme de première classe : checklists avec assignés, dates d'échéance et preuves (liens vers tickets ou docs).
Propriété et validations
Les dépréciations échouent quand la responsabilité est vague. Définissez qui possède chaque étape (Produit, Ingénierie, Support, Docs) et exigez des validations lorsque le risque est élevé — en particulier pour la transition Approuvé → Annoncé et Migration → Suppression.
L'objectif est un workflow léger au quotidien, mais strict aux points où les erreurs sont coûteuses.
Modèle de données : entités et relations
Un modèle de données clair évite que les dépréciations se transforment en docs dispersés, messages ad-hoc et propriétaires flous. Commencez par un petit jeu d'objets premiers, puis ajoutez des champs uniquement lorsqu'ils servent des décisions.
Entités principales
Feature est la chose que vit l'utilisateur (un réglage, un endpoint API, un rapport, un workflow).
Deprecation est un événement de changement borné dans le temps pour une feature : quand il est annoncé, restreint puis désactivé.
Migration Plan décrit comment les utilisateurs doivent passer au remplacement et comment vous mesurerez la progression.
Audience Segment définit qui est affecté (par ex. « comptes sur le Plan X utilisant la Feature Y dans les 30 derniers jours »).
Message capture ce que vous enverrez, où et quand (email, in-app, bannière, macro de support).
Champs requis (ce que vous regretterez de ne pas avoir)
Pour Deprecation et Migration Plan, considérez ces éléments comme obligatoires :
- Calendriers : date d'annonce, date de fin douce (avertissements/restrictions), date de fin ferme (suppression), plus timezone.
- Surfaces impactées : zones UI, routes API, pages de docs, intégrations, facturation/attributions.
- Chemin de remplacement : lien vers la nouvelle feature, notes de migration étape par étape et limitations connues.
- Niveau de risque : faible/moyen/élevé avec une courte justification (ex. « casse l'automatisation pour les power users »).
Relations (comment tout se connecte)
Modélisez la hiérarchie réelle :
- Une Feature → plusieurs Deprecations (plusieurs suppressions dans le temps, rollouts régionaux ou changements pilotés par des règles)
- Une Deprecation → un Migration Plan (habituellement), et plusieurs Audience Segments (différents messages et dates limites)
- Une Deprecation → plusieurs Messages (canaux et étapes), chacun éventuellement ciblé sur un Audience Segment spécifique.
Champs d'audit et gouvernance
Ajoutez des champs d'audit partout : created_by, approved_by, created_at, updated_at, approved_at, plus un historique des changements (qui a modifié quoi et pourquoi). Cela permet une piste d'audit précise quand le support, le juridique ou la direction demandent « quand avons-nous décidé cela ? »
Rôles, permissions et approbations
Des rôles clairs et des approbations légères évitent deux échecs fréquents : « tout le monde peut tout changer » et « rien ne se publie parce que personne ne sait qui décide ». Concevez l'app pour que la responsabilité soit explicite et que chaque action visible externe ait un propriétaire.
Rôles principaux
- Admin : gère les paramètres workspace, les rôles, les templates globaux et les règles de conformité.
- Product Manager (PM) : possède le plan de dépréciation, les calendriers, les audiences cibles et l'intention des messages.
- Ingénieur : exécute les étapes techniques, valide la readiness et met à jour le statut de migration.
- Support : surveille l'impact client, contribue aux FAQ/macros et escalade les blocages.
- Lecture seule : peut voir statuts, calendriers et rapports sans modifier.
Permissions par action
Modélisez les permissions autour d'actions clés plutôt que d'écrans :
- Créer/Éditer éléments de dépréciation (PM, Admin), avec champs limités modifiables après approbation.
- Approuver le plan, les dates et les changements à fort impact (Admin, approbateurs désignés).
- Envoyer des messages (PM/Support avec approbation) et éditer les templates (Admin).
- Modifier les calendriers (PM) avec approbation requise pour les changements majeurs.
- Clôturer (PM + validation Ingénieur) une fois les seuils de migration atteints.
Flux d'approbation pour changements à risque
Exigez des approbations quand un changement affecte beaucoup d'utilisateurs, des clients régulés ou des workflows critiques. Points courants : approbation du plan initial, « prêt à annoncer » et confirmation finale « suppression/désactivation ». Les communications externes (email, bannière in-app, mise à jour du help center) doivent être soumises à approbation.
Exigences du journal d'audit
Maintenez une piste d'audit immuable : qui a modifié quoi, quand et pourquoi (y compris le contenu des messages, la définition des audiences et les modifications de calendrier). Ajoutez des liens vers tickets/incidents pour accélérer postmortems et revues de conformité.
UX : écrans clés et architecture de l'information
Rédigez les communications dans l'application
Créez des modèles et des notifications planifiées comme partie du flux de travail, pas une étape finale.
Une application de gestion des dépréciations réussit ou échoue sur la clarté. Les utilisateurs doivent pouvoir répondre à trois questions rapidement : Qu'est-ce qui change ? Qui est affecté ? Que doit-on faire ensuite ? L'architecture de l'information doit suivre ce flux, en langage clair et avec des motifs cohérents.
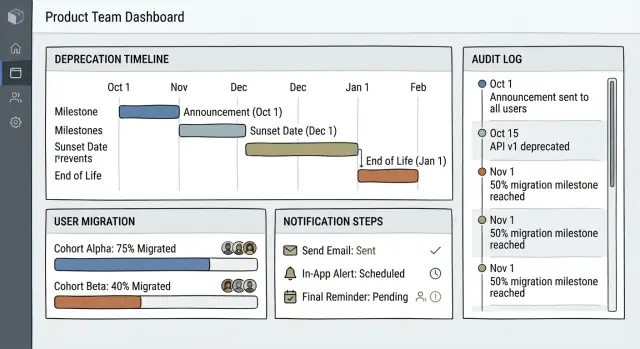
Tableau de bord : la « salle de contrôle »
Le tableau de bord doit être lisible en moins d'une minute. Concentrez-vous sur le travail actif et le risque, pas sur un inventaire long.
Afficher :
- Dépréciations actives avec l'étape courante (Annoncé → Migration → Suppression)
- Dates limites à venir (7/14/30 jours) avec un label « jours restants »
- Éléments à haut risque : large audience impactée, faible taux de migration ou approbations manquantes
Gardez les filtres simples : Statut, Responsable, Zone produit, Fenêtre de date. Évitez le jargon comme « état de sunset » ; préférez « Suppression programmée ».
Page de détail de la dépréciation : source unique de vérité
Chaque dépréciation a besoin d'une page canonique en laquelle les équipes ont confiance pendant l'exécution.
Structurez-la comme une timeline avec les décisions importantes et les prochaines actions en avant :
- Résumé en en-tête : nom, responsable, étape courante, date de suppression, liens vers le remplacement
- Chronologie : date d'annonce, début de migration, cutoff, suppression (avec jalons modifiables)
- Utilisateurs impactés : principaux segments, comptes, et méthode de détection
- Messages & docs : notifications in-app, templates email, extrait pour notes de version et liens de documentation
Utilisez des libellés courts et directs : « Fonction de remplacement », « Qui est affecté », « Ce que doivent faire les utilisateurs ».
Cohérence via des templates
Réduisez les erreurs en fournissant des templates pour :
- Calendriers standard (ex. plans 30/60/90 jours)
- Checklists (approbations, comms envoyées, support briefé, docs mis à jour)
- Étapes de migration (ce qui change pour les utilisateurs, prompts FAQ)
Les templates doivent être sélectionnables à la création et rester visibles comme checklist sur la page de détail.
Accessibilité et clarté par défaut
Visez une charge cognitive minimale :
- Rédigez en langage clair ; évitez les acronymes internes
- Utilisez des pastilles de statut à fort contraste et des formats de date lisibles
- Assurez la navigation au clavier et des titres signifiants pour les lecteurs d'écran
Une bonne UX rend le workflow évident : l'action suivante est toujours claire et la page raconte la même histoire au produit, à l'ingénierie, au support et aux clients.
Segmentation d'audience et détection d'impact
Les dépréciations échouent quand vous notifiez tout le monde de la même manière. Une application de gestion des dépréciations doit d'abord répondre à deux questions : qui est affecté et à quel degré. La segmentation et la détection d'impact rendent les messages précis, réduisent le bruit pour le support et aident les équipes à prioriser les migrations.
Sources de segmentation (d'où vient l'« audience »)
Commencez par des segments qui correspondent à la façon dont les clients achètent, utilisent et opèrent :
- Plan / niveau contractuel (Free, Pro, Enterprise)
- Niveau d'utilisation (power users vs utilisateurs occasionnels)
- Type d'intégration (API-only, UI-only, connecteur spécifique)
- Région / résidence des données (important pour la synchronisation et contraintes légales)
- Ancienneté du compte (les nouveaux clients n'ont peut-être jamais utilisé l'ancienne feature)
Traitez les segments comme des filtres combinables (ex. « Enterprise + UE + utilise l'API »). Stockez la définition du segment pour qu'elle soit auditable ultérieurement.
Calculer « impacté » (quels signaux utiliser)
L'impact doit être calculé à partir de signaux concrets, typiquement :
- Logs d'utilisation (feature toggles, visites de pages, clics)
- Appels d'API (endpoints liés à la capacité dépréciée)
- Événements UI (workflows spécifiques indiquant dépendance)
Utilisez une fenêtre temporelle (« utilisé dans les 30/90 derniers jours ») et un seuil (« ≥10 événements ») pour séparer la dépendance active du bruit historique.
Cas limites à gérer
Les environnements partagés créent des faux positifs à moins d'être modélisés :
- Comptes partagés / utilisateurs de service : attribuez l'utilisation API au workspace ou à la clé d'intégration, pas à une personne
- Multiples workspaces : un utilisateur peut être impacté dans un workspace et pas dans un autre
- Admins vs utilisateurs finaux : les admins ont besoin d'avis précoces et détaillés ; les utilisateurs finaux d'instructions axées tâches
Aperçu avant envoi
Avant tout email ou notification in-app, fournissez une étape de prévisualisation montrant un échantillon des comptes/utilisateurs impactés, pourquoi ils ont été signalés (principaux signaux) et la portée projetée par segment. Cette « simulation sèche » évite les envois embarrassants et augmente la confiance dans le workflow.
Notifications, messages et templates
Les dépréciations échouent le plus souvent quand les utilisateurs ne sont pas informés (ou trop tard). Traitez la messagerie comme un actif de workflow : planifié, auditable et adapté à l'audience impactée.
Canaux pour la livraison réelle
Couvrez plusieurs chemins de diffusion pour rencontrer les utilisateurs là où ils font attention :
- Bannière in-app pour les utilisateurs actifs au moment opportun
- Email pour une portée plus large et des instructions longues
- Webhooks pour pousser des événements vers des systèmes internes
- Slack (ou équivalent) pour les alertes parties prenantes internes
- Lien vers la page de statut (optionnel) lorsque le changement affecte la disponibilité
Chaque notification doit référencer l'enregistrement de dépréciation spécifique, afin que les destinataires et équipes puissent tracer « qu'est-ce qui a été envoyé, à qui et pourquoi ».
Cadence : du préavis à la date limite
Intégrez un calendrier par défaut que les équipes peuvent ajuster par dépréciation :
- Annonce : ce qui change et pourquoi, plus le chemin de remplacement
- Rappels : en fonction des jours restants et de l'activité utilisateur (ex. toujours utiliser l'ancienne feature)
- Avertissement de date limite : date/heure exacte, impact et options de support
- Avis final : confirmation de la bascule et où aller ensuite
Templates avec variables
Fournissez des templates avec champs variables et prévisualisation :
- Feature :
{{feature_name}} - Date limite :
{{deadline}} - Remplacement :
{{replacement_link}}(ex. /docs/migrate/new-api) - CTA :
{{cta_text}}et{{cta_url}}
Contrôles de sécurité
Ajoutez des garde-fous pour éviter les envois accidentels :
- Envois test vers des comptes internes et des segments de test
- Limites de débit et plafonds par client
- Plages silencieuses par timezone
- Gestion des désinscriptions le cas échéant (et solutions de repli si utilisateurs optent-out)
Suivi de migration et assistance utilisateur
Créez votre MVP de dépréciation
Décrivez votre flux de dépréciation dans le chat et obtenez rapidement une ossature d'application fonctionnelle.
Un plan de dépréciation réussit quand les utilisateurs voient précisément quoi faire ensuite — et quand votre équipe peut confirmer qui est réellement passé. Traitez la migration comme un ensemble d'étapes concrètes et traçables, pas comme un vague « merci de mettre à jour ».
Étapes de migration en checklist
Modélisez chaque migration comme une petite checklist avec des résultats clairs (pas seulement des instructions). Par exemple : « Créer une nouvelle clé API », « Changer l'initialisation du SDK », « Supprimer les appels legacy », « Vérifier la signature webhook ». Chaque étape devrait inclure :
- Une courte description et des critères « terminé »
- Des liens vers l'endroit exact pour réaliser l'action (page des paramètres, assistant, doc)
- Une validation optionnelle (ex. nouveau endpoint détecté)
Gardez la checklist visible sur la page de dépréciation et dans toute bannière in-app pour que l'utilisateur puisse reprendre là où il s'est arrêté.
Migration guidée (aide, pas devoir)
Ajoutez un panneau de « migration guidée » qui regroupe tout ce que les utilisateurs cherchent :
- Pages de docs pertinentes (ex.
/docs/migrations/legacy-to-v2) - Points d'entrée du wizard (ex.
/settings/integrations/new-setup) - Exemples de configurations et snippets à copier-coller
- FAQ courte couvrant les échecs courants et comment revenir en arrière en sécurité
Ce n'est pas que du contenu : c'est de la navigation. Les migrations les plus rapides arrivent quand l'app guide les gens vers l'écran exact dont ils ont besoin.
Suivi de complétion au bon niveau
Suivez la complétion par compte, workspace et intégration (le cas échéant). Beaucoup d'équipes migrent d'abord un workspace, puis poussent graduellement le changement.
Conservez la progression sous forme d'événements et d'état : statut des étapes, timestamps, acteur et signaux détectés (ex. « endpoints v2 vus dans les dernières 24h »). Fournissez un indicateur « % complété » et un drill-down sur les blocages.
Passage au support avec contexte automatique
Quand les utilisateurs bloquent, facilitez l'escalade : un bouton « Contacter le support » doit créer un ticket, assigner un CSM (ou une file) et joindre automatiquement le contexte — identifiants de compte, étape en cours, messages d'erreur, type d'intégration et activité récente de migration. Cela évite les allers-retours et raccourcit le temps de résolution.
Analytique et rapports pour l'adoption
Les projets de dépréciation échouent silencieusement quand vous ne voyez pas qui est affecté, qui avance et qui risque de partir. L'analytique doit répondre à ces questions en un coup d'œil et rendre les chiffres suffisamment fiables pour être partagés avec la direction, le support et le Customer Success.
Les métriques d'adoption de base
Commencez par un petit ensemble de métriques difficiles à mal interpréter :
- Utilisateurs exposés : comptes/utilisateurs encore sur l'ancienne feature (ou appelant l'ancien endpoint) dans une fenêtre définie.
- Migration démarrée : utilisateurs ayant entamé le flux de mise à jour (ex. activé la feature de remplacement, créé les réglages requis, installé la nouvelle intégration).
- Migration complétée : utilisateurs ayant atteint vos critères « terminé » (usage du remplacement au-dessus d'un seuil, usage déprécié à zéro, checklist complétée).
- Signaux de risque de churn : hausse des tickets liés à la feature, événements d'erreur répétés, chute d'utilisation, tentatives de migration échouées ou tags NPS négatifs liés au changement.
Définissez chaque métrique dans l'UI avec une infobulle courte et un lien vers « Comment nous calculons ça ». Si les définitions changent en cours de projet, enregistrez le changement dans la piste d'audit.
Chronologies qui matchent le cycle de vie
Un bon rapport se lit comme le plan de dépréciation :
- Courbes de progression dans le temps pour exposés/débutés/complétés
- Marqueurs verticaux pour dates clés : annonce, rappel, avis final, suppression
- Indicateur « rythme vers l'objectif » (ex. tendance de complétion vs vitesse requise pour finir avant la suppression)
Cela montre immédiatement si des rappels supplémentaires, des améliorations outils ou un ajustement de la date sont nécessaires.
Découpages qui déclenchent une action
Les agrégats sont utiles, mais les décisions se prennent par segment. Fournissez des drill-downs par :
- Segment d'audience (persona ou cas d'usage)
- Niveau de plan (free vs payant)
- Région (fuseaux et fêtes locales impactent les réponses)
- Type d'intégration (clients API, connecteurs partenaires, self-built vs marketplace)
Chaque découpage devrait lier directement à la liste de comptes affectés pour que les équipes agissent sans export préalable.
Exports et rapports planifiés
Soutenez le partage léger :
- Export CSV pour listes de comptes et rollups
- Résumés programmés par email/Slack aux parties prenantes
- Un rapport hebdo « à risque avant la suppression » mettant en avant les segments et comptes prioritaires à contacter
Pour l'automatisation et du BI plus poussé, exposez les mêmes données via un endpoint API (et maintenez sa stabilité entre projets de dépréciation).
Intégrations : feature flags, analytics, docs et outils support
Planifiez clairement le cycle de vie
Utilisez le mode Planification pour cartographier les étapes, les approbations et les listes de contrôle avant d'écrire du code.
Une appli de dépréciation est plus utile lorsqu'elle devient la « source de vérité » que les autres systèmes peuvent consommer. Les intégrations permettent de passer des mises à jour manuelles à du gating, du mesurage et des workflows de support automatisés.
Feature flags : contrôler et vérifier le comportement
Connectez-vous à votre fournisseur de feature flags pour que chaque dépréciation puisse référencer un ou plusieurs flags (ancienne expérience, nouvelle expérience, rollback). Cela permet :
- Gating par environnement (dev/stage/prod) et par segment d'audience
- Vérifications automatisées (ex. « nouveau flux activé pour 90% des comptes éligibles »)
- Rollbacks plus sûrs liés à l'enregistrement de dépréciation, pas à une feuille de calcul séparée
Stockez les clés de flag et l'« état attendu » par étape, plus un job de sync léger pour lire le statut courant.
Analytics + entrepôt : mesurer l'adoption, pas les opinions
Raccordez l'app à l'analytics produit pour que chaque dépréciation ait une métrique de succès claire : événements « utilisé ancienne feature », « utilisé nouvelle feature » et « migration complétée ». Récupérez des comptes agrégés pour montrer la progression par segment.
Optionnellement, streammez les mêmes métriques vers un entrepôt de données pour un slicing plus profond (plan, région, ancienneté du compte). Gardez cela optionnel pour ne pas bloquer les petites équipes.
Docs et notes de version : un clic depuis l'enregistrement
Chaque dépréciation doit lier le contenu d'aide canonique et les annonces, en utilisant des routes internes telles que :
- /docs/migrations/new-checkout
- /release-notes/2026-01
Cela réduit les incohérences : le support et les PM réfèrent toujours aux mêmes pages.
Webhooks et APIs : automatiser le travail aval
Exposez des webhooks (et une petite API REST) pour les événements de cycle de vie comme « programmé », « email envoyé », « flag basculé » et « suppression terminée ». Consommateurs courants : CRM, helpdesk et fournisseurs de messagerie — ainsi les clients reçoivent un guidage cohérent et à temps sans copier les mises à jour entre outils.
Architecture et plan d'implémentation
Considérez la première version comme une appli CRUD focalisée : créer des dépréciations, définir des dates, assigner des propriétaires, lister les audiences impactées et suivre le statut. Commencez par ce que votre équipe peut livrer rapidement, puis ajoutez l'automatisation (ingestion d'événements, messagerie, intégrations) une fois le workflow éprouvé.
Stack : choisissez ce que votre équipe connaît déjà
Un stack typique et peu risqué est une appli web server-rendered ou un SPA simple avec une API (Rails/Django/Laravel/Node). L'important est la fiabilité : bonnes migrations, écrans d'administration simples et jobs en arrière-plan robustes. Si vous avez déjà du SSO (Okta/Auth0), utilisez-le ; sinon ajoutez du passwordless (magic links) pour les utilisateurs internes.
Si vous souhaitez accélérer la première version fonctionnelle (surtout pour un outil interne), envisagez de prototyper avec Koder.ai. C'est une plateforme où vous décrivez le workflow en conversation, itérez en « mode planning » et générez une appli React avec backend Go et PostgreSQL — puis exportez le code source si vous voulez internaliser. Les snapshots et rollback sont utiles pendant que vous peaufinez les étapes, permissions et règles de notification.
Briques de base à construire
Vous aurez besoin de :
- Auth + autorisation pour propriétaires, réviseurs et lecteurs
- Base relationnelle (Postgres/MySQL) pour les enregistrements de dépréciation, tâches, approbations et piste d'audit
- Jobs en arrière-plan pour notifications planifiées, rappels et génération de rapports
- Envoi d'email + messagerie basée sur webhooks (ex. Slack/Teams) derrière un « service message » unique
- Endpoint d'ingestion d'événements pour recevoir les événements d'usage produit qui alimentent les tableaux d'impact et d'adoption
Stockage des données : workflow vs usage
Gardez le workflow comme système de référence dans une base relationnelle. Pour l'usage, commencez par stocker des agrégats journaliers en Postgres ; si le volume augmente, poussez les événements bruts vers un event store ou un entrepôt et interrogez des tables résumées depuis l'app.
Indispensables opérationnels
Rendez les jobs idempotents (sécurisés au retry), utilisez des clés de déduplication pour les messages sortants et ajoutez des politiques de retry avec backoff. Loggez chaque tentative de livraison et alertez sur les échecs. Une surveillance basique (profondeur des queues, taux d'erreur, échecs de webhooks) évite des communications manquées en silence.
Tests, lancement et exploitation continue
Une application de dépréciation intervient sur la messagerie, les permissions et l'expérience client — donc les tests doivent se concentrer sur les modes d'échec autant que sur les chemins heureux.
Testez les workflows qui comptent
Commencez par des scénarios end-to-end qui reflètent de vraies dépréciations : rédaction, approbations, modifications de calendrier, envoi de messages et rollbacks. Incluez des cas limites : « prolonger la date après envois » ou « changer le remplacement en cours de route », et vérifier que l'UI reflète clairement ce qui a changé.
Testez aussi les approbations sous pression : réviseurs parallèles, refus d'approbation, ré-approbation après édition et ce qui arrive quand le rôle d'un approbateur change.
Validez la segmentation et la détection d'impact
Les erreurs de segmentation coûtent cher. Utilisez un jeu d'exemples de comptes (et des « golden users » connus) pour valider que les bonnes audiences sont sélectionnées. Combinez contrôles automatiques et vérifications manuelles : prenez des comptes aléatoires et confirmez que le calcul d'impact correspond à la réalité produit.
Si vos règles dépendent d'analytics ou de feature flags, testez avec des événements retardés ou manquants pour voir comment le système se comporte quand les données sont incomplètes.
Vérifications de sécurité et préparation à l'audit
Exécutez des tests de permissions par rôle : qui peut voir des segments sensibles, qui peut éditer des calendriers, qui peut envoyer des messages. Confirmez que les logs d'audit capturent le « qui/quoi/quand » des modifications et enregistrez le moins de PII possible — préférez des IDs stables aux emails quand c'est pertinent.
Plan de déploiement et exploitation
Déployez progressivement : pilote interne, petit ensemble de dépréciations à faible risque, puis usage plus large. Pendant le déploiement, définissez un on-call ou un « responsable de la semaine » pour les édit urgent, les rebonds ou les segmentations erronées.
Enfin, fixez un rythme opérationnel léger : revues mensuelles des dépréciations terminées, qualité des templates et métriques d'adoption. Cela maintient la confiance dans l'app et évite qu'elle devienne un outil ponctuel délaissé.
FAQ
Qu'est-ce qu'une application de gestion des dépréciations (et quel problème cela résout) ?
Une application de gestion des dépréciations est un système de workflow unique pour les suppressions ou remplacements planifiés (fonctionnalités d'interface, endpoints d'API, plans/niveaux). Elle centralise les responsables, les calendriers, les audiences impactées, les messages, le suivi des migrations, les approbations et l'historique d'audit afin que les dépréciations ne soient pas gérées comme une série d'annonces isolées.
Quelles sont les façons les plus courantes dont les dépréciations échouent sans un workflow dédié ?
Les échecs courants incluent :
- Ne pas savoir qui est affecté (absence de détection d'impact fiable)
- Communications incohérentes entre email, in-app, notes de version et scripts de support
- Documents de migration manquants ou obsolètes
- Absence de responsable, de stade ou de critères de sortie clairs
- Aucun historique d'audit indiquant « qui a approuvé quoi » et « quelle date a été promise »
Quelles étapes de workflow devrait inclure le cycle de vie d'une dépréciation ?
Un cycle de vie simple et applicable est :
- Proposé → Approuvé → Annoncé → Migration → Suppression → Terminé
Donnez à chaque étape un responsable et des critères de sortie (par exemple, « Annoncé » signifie que les messages ont été diffusés via les canaux convenus et que les suivis sont planifiés, pas seulement rédigés).
Quels points de contrôle empêchent le chaos de dernière minute avant l'annonce ou la suppression ?
Utilisez des points de contrôle devant être achevés (et enregistrés) avant d'avancer :
- Revue juridique/comm pour le libellé et les dates
- Docs à jour (docs publiques + runbooks internes)
- Plan de rollback/mitigation défini (avec propriétaire décisionnel)
- Préparation du support (macros/scripts + chemin d'escalade)
Considérez ces éléments comme des cases de checklist avec des assignés, des dates d'échéance et des liens vers des preuves (tickets/docs).
Quelles entités de base devrait inclure le modèle de données ?
Commencez avec un petit ensemble d'objets :
- Feature (ce dont les utilisateurs dépendent)
- Deprecation (l'événement de changement borné dans le temps)
- Migration Plan (chemin de remplacement + comment définir « terminé »)
- Audience Segment (qui est affecté et pourquoi)
Quels champs deviennent problématiques si vous ne les capturez pas tôt ?
Au minimum, rendez ces champs obligatoires :
- Dates : annonce, fin douce, fin ferme (avec timezone)
- Surfaces impactées : zones UI, routes API, intégrations, facturation/attributions
- Chemin de remplacement : étapes + liens (ex.
/docs/migrations/legacy-to-v2) - Niveau de risque avec une courte justification
Ces champs réduisent les oublis (« on a oublié de prévenir pour X ») et rendent les calendriers défendables plus tard.
Comment détecter qui est impacté et construire des segments d'audience fiables ?
Calculez l'impact à partir de signaux concrets :
- Logs d'utilisation (feature toggles, événements de page)
- Appels d'API (endpoints/champs dépréciés)
- Événements UI liés à des workflows critiques
Utilisez une fenêtre claire et un seuil (par ex. « utilisé dans les 30/90 jours » et « ≥10 événements ») et enregistrez la définition du segment pour pouvoir expliquer plus tard pourquoi quelqu'un a été inclus.
Comment l'application doit-elle gérer les notifications et les messages en toute sécurité ?
Considérez les messages comme un workflow planifié et auditable :
- Annonce (quoi/Pourquoi + chemin de remplacement)
- Rappels (en fonction du temps restant et de l'utilisation continue)
- Avertissement de date limite (date/heure exactes + conséquences)
- Avis final (confirmation de la bascule + étapes suivantes)
Ajoutez des garde-fous : envois de test, limites de débit, plages silencieuses, plafonds par locataire et communications externes soumises à approbation.
Comment suivre la progression de migration de façon que les équipes puissent faire confiance aux données ?
Suivez la migration comme des étapes-checklist avec vérification, pas un statut vague :
- Définitions des étapes avec critères « terminé »
- Liens vers l'écran exact ou la doc pour réaliser l'étape
- Signaux de validation optionnels (ex. nouveau endpoint vu dans les 24h)
Suivez la progression au bon niveau (compte/espace de travail/intégration) et fournissez un bouton de passage au support qui ouvre un ticket avec le contexte joint.
Quel périmètre MVP pratique et quelles intégrations importent le plus ensuite ?
Un MVP pratique peut être une application CRUD + workflow focalisée :
- Auth/rôles, enregistrements de dépréciation, propriétaires, dates, étapes
- Définition d'audience + comptages d'impact basiques
- Modèles de messages + planification
- Approbations + journal d'audit immuable
Ajoutez ensuite des intégrations : feature flags (état attendu par étape), ingestion analytics pour les métriques d'adoption, et webhooks/APIs pour les systèmes aval (desk support, CRM, Slack).