03 avr. 2025·8 min
Gérer l'état entre frontend et backend dans les applications d'IA
Apprenez comment l'état (UI, session, données, modèle) circule entre frontend et backend dans les apps IA, avec des patterns pratiques pour synchroniser, persister, mettre en cache et sécuriser.
Ce que signifie « état » dans une application bâtie autour de l'IA
« État » désigne tout ce dont votre application a besoin pour se comporter correctement d'un instant à l'autre.
Si un utilisateur clique sur Envoyer dans une interface de chat, l'application ne doit pas oublier ce qu'il a tapé, ce que l'assistant a déjà répondu, si une requête est en cours d'exécution, ou quelles options (ton, modèle, outils) sont activées. Tout cela fait partie de l'état.
L'état, en termes simples
Une façon utile de penser l'état : la vérité courante de l'application — des valeurs qui influent sur ce que l'utilisateur voit et sur ce que le système fait ensuite. Cela inclut des éléments évidents comme les champs de formulaire, mais aussi des faits « invisibles » comme :
- Dans quelle conversation se trouve l'utilisateur
- Si la dernière réponse est en streaming ou terminée
- La liste des messages et leur ordre
- Les appels d'outils et leurs résultats (résultats de recherche, requêtes en base, extractions de fichiers)
- Les erreurs, les tentatives de reprise et les périodes d'attente liées au rate-limit
Pourquoi les applications d'IA ont plus d'éléments en mouvement
Les applications traditionnelles lisent souvent des données, les affichent et enregistrent les mises à jour. Les apps IA ajoutent des étapes et des sorties intermédiaires :
- Une seule action utilisateur peut déclencher plusieurs opérations backend (appel LLM, appel d'outil, nouvel appel LLM).
- Les réponses peuvent arriver de manière incrémentale (tokens en streaming), donc l'UI doit gérer un état partiel.
- Le contexte compte : le système peut devoir garder une mémoire de conversation, des sorties d'outils et des réglages de modèle cohérents entre les requêtes.
Cette complexité supplémentaire explique pourquoi la gestion d'état est souvent la complexité cachée des applications IA.
Ce que couvre ce guide
Dans les sections suivantes, nous découperons l'état en catégories pratiques (état UI, état de session, données persistées et état modèle/runtime) et montrerons où chaque élément doit vivre (frontend vs. backend). Nous aborderons aussi la synchronisation, le caching, les jobs longue durée, les mises à jour en streaming et la sécurité — car l'état n'est utile que s'il est correct et protégé.
Exemple rapide
Imaginez une application de chat où un utilisateur demande : « Résume les factures du mois dernier et signale les anomalies. » Le backend pourrait (1) récupérer les factures, (2) lancer un outil d'analyse, (3) streamer un résumé vers l'UI, et (4) sauvegarder le rapport final.
Pour que cela paraisse fluide, l'application doit suivre les messages, les résultats d'outils, la progression et la sortie sauvegardée — sans mélanger les conversations ni fuiter des données entre utilisateurs.
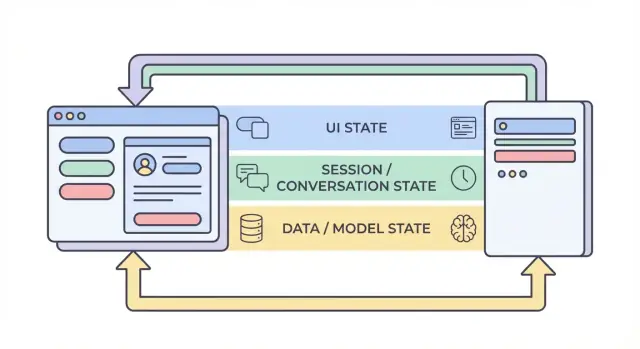
Les quatre couches d'état : UI, session, données et modèle
Quand on parle d'« état » dans une app IA, on mélange souvent des choses très différentes. Séparer l'état en quatre couches — UI, session, données et modèle/runtime — facilite la décision de où quelque chose doit être stocké, qui peut le modifier et comment il doit être conservé.
1) État UI (ce que l'utilisateur fait en ce moment)
L'état UI est l'état vivant, au moment présent, dans le navigateur ou l'application mobile : champs de texte, bascules, éléments sélectionnés, onglet ouvert et si un bouton est désactivé.
Les apps IA ajoutent des détails UI spécifiques :
- Indicateurs de chargement et états de « réflexion »
- Tokens en streaming (texte partiel s'affichant au fur et à mesure)
- Brouillons locaux (avant envoi)
L'état UI doit être simple à réinitialiser et sans conséquence si on le perd. Si l'utilisateur rafraîchit la page, vous pouvez le perdre — et c'est souvent acceptable.
2) État de session / conversation (contexte partagé d'un flux utilisateur)
L'état de session relie un utilisateur à une interaction en cours : identité, conversation_id et une vue cohérente de l'historique des messages.
Dans les apps IA, cela inclut souvent :
- L'historique des messages (ou des références vers celui-ci)
- Les traces d'outils (quels outils/fonctions ont été appelés et avec quels résultats)
- Un « ensemble de travail » comme le projet/document courant, le modèle sélectionné ou l'espace de travail
Cette couche s'étend souvent sur le frontend et le backend : le frontend garde des identifiants légers, tandis que le backend fait autorité pour la continuité de session et le contrôle d'accès.
3) État des données (enregistrements durables en stockage)
L'état des données est ce que vous conservez intentionnellement dans une base : projets, documents, embeddings, préférences, logs d'audit, événements de facturation et transcriptions de conversation sauvegardées.
Contrairement à l'état UI et de session, l'état des données doit être :
- Durable (survivre aux redémarrages)
- Interrogeable (recherchable/filtrable)
- Auditable (on peut comprendre ce qui s'est passé ensuite)
4) État modèle / runtime (comment l'IA est configurée maintenant)
L'état modèle/runtime est la configuration opérationnelle utilisée pour produire une réponse : prompts systèmes, outils activés, température/max tokens, réglages de sécurité, limites de débit et caches temporaires.
Une partie est de la configuration (valeurs par défaut stables) ; une autre est éphémère (caches à courte durée ou budgets de tokens par requête). La plupart doit rester côté backend pour garantir un contrôle cohérent et ne pas être exposée inutilement.
Pourquoi la séparation réduit les bugs
Quand ces couches se confondent, on obtient des erreurs classiques : l'UI affiche du texte qui n'a pas été sauvegardé, le backend utilise des prompts différents de ce que l'UI attend, ou la mémoire de conversation fuit entre utilisateurs. Des frontières claires créent des sources de vérité évidentes — et permettent de savoir ce qui doit persister, ce qui peut être recalculé et ce qui doit être protégé.
Ce qui vit sur le frontend vs. le backend (et pourquoi)
Une façon fiable de réduire les bugs dans les apps IA est de décider, pour chaque élément d'état, où il doit vivre : dans le navigateur (frontend), sur le serveur (backend) ou dans les deux. Ce choix affecte la fiabilité, la sécurité et la façon dont l'app se comporte lors d'un rafraîchissement, de l'ouverture d'un nouvel onglet ou d'une perte réseau.
État frontend : rapide, temporaire et piloté par l'utilisateur
L'état frontend est adapté aux éléments qui changent rapidement et n'ont pas besoin de survivre à un rafraîchissement. Le garder local rend l'UI réactive et évite des appels API inutiles.
Exemples courants frontend-only :
- Texte de brouillon que l'utilisateur tape
- Filtres locaux et ordre de tri dans un tableau
- État ouvert/fermé d'un modal, onglet sélectionné, états hover
Perdre cet état au rafraîchissement est généralement acceptable.
État backend : faisant autorité, sensible et partagé
Le backend doit stocker tout ce qui doit être fiable, auditable ou appliqué de manière cohérente. Cela inclut l'état que d'autres appareils/onglets doivent voir ou qui doit rester correct même si le client est modifié.
Exemples backend-only :
- Permissions et rôles
- Statut d'abonnement et limites d'utilisation
- Jobs longue durée et leur statut (indexation, exports, fine-tune)
Règle pratique : si un état incorrect peut coûter de l'argent, divulguer des données ou casser un contrôle d'accès, il doit être sur le backend.
État partagé : coordonné, mais avec une source de vérité
Certains états sont naturellement partagés :
- Titre de conversation
- Sources de connaissances sélectionnées pour un chat
- Champs de profil utilisateur utilisés sur plusieurs appareils
Même partagés, choisissez une « source de vérité ». Généralement, le backend fait autorité et le frontend met en cache une copie pour la rapidité.
Règle générale (et anti-pattern fréquent)
Garder l'état le plus proche possible de l'endroit où il est nécessaire, mais persister ce qui doit survivre aux rafraîchissements, changements d'appareil ou interruptions.
Évitez l'anti-pattern qui consiste à stocker de l'état sensible ou faisant autorité uniquement dans le navigateur (par exemple, traiter un drapeau client-side isAdmin, le niveau d'abonnement ou l'état d'achèvement d'un job comme une vérité). L'UI peut afficher ces valeurs, mais le backend doit les vérifier.
Cycle de vie typique d'une requête IA : du clic à la complétion
Une fonctionnalité IA donne l'impression d'une « action unique », mais c'est en réalité une chaîne de transitions d'état partagées entre le navigateur et le serveur. Comprendre ce cycle facilite l'évitement d'une UI décalée, d'un contexte manquant et de charges en double.
1) Action utilisateur → le frontend prépare l'intention
Un utilisateur clique sur Envoyer. L'UI met à jour l'état local immédiatement : elle peut ajouter une bulle de message « en attente », désactiver le bouton d'envoi et capturer les entrées courantes (texte, pièces jointes, outils sélectionnés).
À ce stade, le frontend doit générer ou attacher des identifiants de corrélation :
conversation_id: le fil auquel cela appartientmessage_id: l'ID client pour le nouveau message utilisateurrequest_id: unique par tentative (utile pour les retries)
Ces IDs permettent aux deux côtés de parler du même événement même lorsque les réponses arrivent en retard ou en double.
2) Appel API → le serveur valide et persiste
Le frontend envoie une requête API avec le message utilisateur et les IDs. Le serveur valide les permissions, les limites de débit et la forme du payload, puis persiste le message utilisateur (ou au moins un log immuable) indexé par conversation_id et message_id.
Cette persistance empêche une « histoire fantôme » si l'utilisateur rafraîchit en plein milieu d'une requête.
3) Le serveur reconstruit le contexte
Pour appeler le modèle, le serveur reconstruit le contexte depuis sa source de vérité :
- Récupérer les messages récents pour le
conversation_id - Tirer les enregistrements liés (documents, préférences, sorties d'outils)
- Appliquer les politiques de conversation (prompts système, règles de mémoire, troncature)
Idée clé : ne comptez pas sur le client pour fournir l'historique complet. Le client peut être obsolète.
4) Exécution modèle/outil → état intermédiaire
Le serveur peut appeler des outils (recherche, requête DB) avant ou pendant la génération. Chaque appel d'outil produit un état intermédiaire qui doit être suivi par request_id pour pouvoir être audité et relancé en toute sécurité.
5) Réponse (streaming ou non) → complétion UI
Avec le streaming, le serveur envoie des tokens/événements partiels. L'UI met à jour incrémentalement le message assistant en attente, mais le considère toujours « en cours » jusqu'à ce qu'un événement final marque la complétion.
6) Points de défaillance à prévoir
Retries, soumissions en double et réponses hors ordre arrivent. Utilisez request_id pour dédupliquer côté serveur, et message_id pour concilier côté UI (ignorer les morceaux tardifs qui ne correspondent pas à la requête active). Affichez toujours un état « échoué » clair avec une reprise sûre qui n'engendre pas de messages dupliqués.
Sessions et mémoire de conversation : garder le contexte sans chaos
Évitez les doublons de réessai
Faites en sorte que Koder.ai intègre des IDs de requête et des clés d'idempotence dans vos endpoints.
Une session est le « fil » qui lie les actions d'un utilisateur : quel workspace il utilise, ce qu'il a recherché en dernier, quel brouillon il éditait et à quelle conversation une réponse IA doit s'inscrire. Un bon état de session rend l'app continue entre les pages — et idéalement entre les appareils — sans transformer votre backend en dépôt de tout ce que l'utilisateur a dit.
Objectifs de l'état de session
Visez : (1) la continuité (un utilisateur peut partir et revenir), (2) la justesse (l'IA utilise le bon contexte pour la bonne conversation) et (3) l'isolation (une session ne fuit pas dans une autre). Si vous supportez plusieurs appareils, traitez les sessions comme scoped par utilisateur + appareil : « même compte » n'implique pas forcément « même espace ouvert ».
Cookies vs tokens vs sessions serveur
Généralement, vous choisirez une de ces méthodes pour identifier la session :
- Cookies : les plus simples pour le web car le navigateur les envoie automatiquement. Idéal pour les sessions traditionnelles, mais vous devez définir les flags sécurisés (
HttpOnly,Secure,SameSite) et gérer le CSRF. - Tokens (ex. JWT) : bien pour les APIs et apps mobiles car le client les attache explicitement. Ils scalent bien, mais la révocation et la rotation demandent du design (et vous ne devez pas stocker d'état sensible dedans).
- Sessions serveur : le serveur conserve les données de session (souvent dans Redis) et le client n'a qu'un ID opaque. Facile à révoquer et mettre à jour, mais il faut exploiter et scaler le magasin de sessions.
Stratégies de mémoire de conversation
La « mémoire » n'est que l'état que vous choisissez de renvoyer au modèle.
- Historique complet : le plus précis, mais coûteux et peut exposer du contenu sensible ancien.
- Historique résumé : garder un résumé courant plus quelques tours récents ; moins cher et souvent suffisant.
- Contexte fenêtré : seulement les N derniers messages ; le plus simple, mais peut perdre des décisions importantes antérieures.
Un pattern pratique : résumé + fenêtre — c'est prévisible et évite des comportements surprises du modèle.
Appels d'outils : répétables et audités
Si l'IA utilise des outils (recherche, requêtes DB, lectures de fichiers), stockez chaque appel d'outil avec : entrées, timestamps, version de l'outil et sortie retournée (ou référence). Cela permet d'expliquer « pourquoi l'IA a dit ça », de rejouer des runs pour le debug et de détecter quand un résultat a changé parce que l'outil ou le dataset a évolué.
Garde-fous vie privée
Ne stockez pas de mémoire longue durée par défaut. Conservez seulement ce qui est nécessaire pour la continuité (IDs de conversation, résumés, logs d'outils), définissez des durées de rétention et évitez de persister le texte brut utilisateur sauf s'il y a une raison produit claire et le consentement utilisateur.
Synchroniser l'état en toute sécurité : sources de vérité et gestion des conflits
L'état devient risqué quand la même « chose » peut être éditée à plusieurs endroits — votre UI, un deuxième onglet, ou un job en arrière-plan. La solution tient moins du code astucieux que d'une propriété claire de possession.
Définir les sources de vérité
Décidez quel système est autoritaire pour chaque morceau d'état. Dans la plupart des applications IA, le backend doit posséder l'enregistrement canonique des éléments qui doivent être corrects : paramètres de conversation, permissions d'outils, historique des messages, limites de facturation et statut des jobs. Le frontend peut cacher et dériver un état pour la rapidité (onglet sélectionné, texte de brouillon, indicateurs « en train de taper ») mais doit considérer le backend comme correct en cas de désaccord.
Règle pratique : si vous seriez contrarié de le perdre au rafraîchissement, ça appartient probablement au backend.
Mises à jour optimistes (à utiliser avec précaution)
Les updates optimistes rendent l'app instantanée : basculez un réglage, mettez à jour l'UI immédiatement, puis confirmez côté serveur. Cela marche bien pour des actions peu risquées et réversibles (épingler une conversation).
Ça cause de la confusion quand le serveur peut rejeter ou transformer le changement (vérifs de permission, quotas, validation, valeurs par défaut serveur). Dans ces cas, affichez un état « en cours d'enregistrement… » et mettez à jour l'UI après confirmation.
Gérer les conflits (deux onglets, une conversation)
Les conflits surviennent quand deux clients mettent à jour le même enregistrement à partir de versions différentes. Exemple : l'onglet A et l'onglet B changent la température du modèle.
Utilisez un versionnage léger pour que le backend détecte les écritures obsolètes :
updated_attimestamps (simple et lisible)- ETags / en-têtes
If-Match(native HTTP) - Numéros de révision incrémentaux (détection explicite de conflit)
Si la version ne correspond pas, renvoyez une réponse de conflit (souvent HTTP 409) et renvoyez l'objet serveur le plus récent.
Concevoir des APIs pour réduire les décalages
Après chaque écriture, faites en sorte que l'API retourne l'objet sauvegardé tel que persisté (y compris les valeurs par défaut serveur, champs normalisés et nouvelle version). Le frontend peut ainsi remplacer sa copie mise en cache immédiatement — une mise à jour de la source de vérité au lieu de deviner ce qui a changé.
Caching et performance : accélérer sans état obsolète
Le caching est l'un des moyens les plus rapides pour rendre une app IA instantanée, mais il crée aussi une seconde copie d'état. Si vous mettez en cache la mauvaise chose — ou au mauvais endroit — vous livrerez une UI rapide mais déroutante.
Que mettre en cache côté client
Les caches côté client doivent privilégier l'expérience, pas l'autorité. Bons candidats : aperçus récents de conversations (titres, extrait du dernier message), préférences UI (thème, modèle sélectionné, état de la barre latérale) et état optimiste (messages « en envoi »).
Gardez le cache client petit et jetable : si on le vide, l'app doit pouvoir refetcher depuis le serveur.
Que mettre en cache côté serveur
Les caches serveur doivent cibler le travail coûteux ou fréquemment répété :
- Résultats d'outils réutilisables (ex. météo d'une même ville pendant 5 minutes)
- Recherches par embeddings et résultats de recherche vectorielle pour requêtes répétées (souvent avec TTL courts)
- État de rate-limit et compteurs de throttling (pour protéger l'API et les coûts)
C'est aussi l'endroit pour mettre en cache des états dérivés : comptage de tokens, décisions de modération, sorties de parsing de documents — tout ce qui est déterministe et coûteux.
Principes basiques d'invalidation (sans complexité excessive)
Trois règles pratiques :
- Utilisez des clés de cache explicites qui encodent les entrées (
user_id, modèle, paramètres d'outil, version du document). - Fixez des TTLs selon la vitesse de changement des données. Un TTL court vaut mieux qu'une logique compliquée.
- Contournez le cache quand la justesse prime sur la vitesse : après mise à jour d'un document, changement de permissions ou requête de rafraîchissement.
Si vous ne pouvez pas expliquer quand une entrée de cache devient invalide, ne la mettez pas en cache.
Ne pas mettre en cache les secrets ou données personnelles dans des caches partagés
Évitez de placer des clés API, tokens d'auth, prompts contenant du texte sensible ou du contenu user-specific dans des couches partagées comme un CDN. Si vous devez mettre en cache des données utilisateur, isolez par utilisateur et chiffrez au repos — ou stockez-les dans la base principale.
Mesurez l'impact : vitesse vs UI obsolète
Le caching doit être prouvé, pas supposé. Suivez la latence p95 avant/après, le hit rate du cache et les erreurs visibles par l'utilisateur comme « message mis à jour après affichage ». Une réponse rapide qui contredit ensuite l'UI est souvent pire qu'une réponse un peu plus lente et cohérente.
Persistance et travaux longue durée : jobs, queues et état de statut
Ajoutez des tâches d'arrière-plan proprement
Modélisez les flux en file d'attente, en cours et réussis, et affichez la progression fiable dans l'UI.
Certaines fonctionnalités IA se terminent en une seconde. D'autres prennent des minutes : uploader et parser un PDF, créer des embeddings et indexer une base de connaissances, ou lancer un workflow multi-étapes d'outils. Pour ces cas, l'« état » n'est pas que ce qui est affiché — c'est ce qui survit aux rafraîchissements, retries et au temps.
Que persister (et pourquoi)
Persistez seulement ce qui apporte une vraie valeur produit.
Historique de conversation : messages, timestamps, identité utilisateur et (souvent) quel modèle/outillage a été utilisé. Cela permet de « reprendre plus tard », des traces d'audit et un meilleur support.
Paramètres utilisateur et workspace : modèle préféré, températures par défaut, toggles de fonctionnalité, prompts système et préférences UI doivent vivre en base.
Fichiers et artefacts (uploads, texte extrait, rapports générés) vont généralement en stockage d'objets avec des enregistrements DB pointant vers eux. La DB contient les métadonnées (propriétaire, taille, type) et l'état de traitement ; le blob store contient les octets.
Jobs en arrière-plan pour tâches longues
Si une requête ne peut pas finir dans un timeout HTTP normal, basculez le travail vers une queue.
Pattern typique :
- Frontend appelle
POST /jobsavec les entrées (file id, conversation id, paramètres). - Backend enfile un job (extraction, indexation, runs batch d'outils) et retourne immédiatement un
job_id. - Des workers traitent les jobs asynchrones et écrivent les résultats en stockage persistant.
Cela garde l'UI réactive et rend les retries plus sûrs.
État de statut que l'UI peut faire confiance
Rendez l'état des jobs explicite et interrogeable : queued → running → succeeded/failed (optionnellement canceled). Stockez ces transitions côté serveur avec timestamps et détails d'erreur.
Côté frontend, reflétez le statut clairement :
- Queued/running : affichez un spinner et désactivez les actions duplicatives.
- Failed : affichez une erreur concise et un bouton Retry.
- Succeeded : chargez l'artefact résultant ou mettez à jour la conversation.
Exposez GET /jobs/{id} (polling) ou diffusez les mises à jour (SSE/WebSocket) pour que l'UI ne devine jamais.
Clés d'idempotence : retries sans écritures dupliquées
Les timeouts réseau arrivent. Si le frontend retente un POST /jobs, vous ne voulez pas deux jobs identiques (et deux factures).
Exigez une Idempotency-Key par action logique. Le backend stocke la clé avec le job_id/la réponse et renvoie le même résultat pour les requêtes répétées.
Politiques de nettoyage et d'expiration
Les apps IA accumulent vite des données. Définissez des règles de rétention tôt :
- Expirez les anciennes conversations après N jours (ou laissez l'utilisateur configurer).
- Supprimez les artefacts dérivés quand la source est supprimée.
- Purgez périodiquement les jobs échoués et les fichiers intermédiaires.
Considérez le nettoyage comme une part de la gestion d'état : ça réduit le risque, le coût et la confusion.
Réponses en streaming et mises à jour temps réel : gérer l'état partiel
Le streaming complique l'état parce que la « réponse » n'est plus un seul bloc. On manipule des tokens partiels (texte qui arrive mot par mot) et parfois du travail d'outil partiel (une recherche commence puis finit après). L'UI et le backend doivent convenir de ce qui est temporaire ou final.
Backend : stream d'événements typés, pas seulement du texte
Un pattern propre est de streamer une séquence d'événements petits, chacun avec un type et un payload. Par exemple :
token: texte incrémental (ou petit chunk)tool_start: un appel d'outil a commencé (ex. « Recherche… », avec un id)tool_result: la sortie d'outil est prête (même id)done: le message assistant est completerror: erreur (inclure un message utilisateur-friendly et un debug id)
Cette file d'événements est plus facile à versionner et à debugger que du streaming brut de texte, car le frontend peut rendre précisément la progression (et afficher l'état des outils) sans deviner.
Frontend : mises à jour append-only, puis commit final
Côté client, traitez le streaming comme append-only : créez un message assistant « brouillon » et étendez-le à mesure que les événements token arrivent. Quand vous recevez done, effectuez un commit : marquez le message comme final, persistez-le (si vous le stockez localement) et débloquez les actions (copier, noter, régénérer).
Cela évite de réécrire l'historique en plein stream et maintient l'UI prévisible.
Gérer les interruptions (annulation, coupures, timeouts)
Le streaming augmente le risque de travail à moitié fait :
- Annulation utilisateur : envoyez un signal cancel ; arrêtez d'afficher des tokens ; gardez le brouillon visible comme annulé.
- Coupure réseau : stoppez le flux ; affichez « reconnexion… » et ne supposez pas la complétion.
- Timeouts/erreurs serveur : finalisez le brouillon comme échoué et proposez un retry qui démarre une nouvelle requête (ne pas fusionner silencieusement des streams).
Rehydratation : recharger et reconstruire l'état stable
Si la page se recharge en plein stream, reconstruisez depuis le dernier état stable : derniers messages commités plus tout méta-brouillon stocké (message id, texte accumulé, statuts d'outils). Si vous ne pouvez pas reprendre le stream, affichez le brouillon comme interrompu et laissez l'utilisateur relancer, plutôt que de faire semblant qu'il est terminé.
Sécurité et confidentialité : protéger l'état de bout en bout
Déployez sans configuration supplémentaire
Passez du chat à des builds web et backend hébergés sans gérer une pipeline complète.
L'état n'est pas juste « des données stockées » — ce sont les prompts utilisateurs, les uploads, préférences, sorties générées et les métadonnées qui relient le tout. Dans les apps IA, cet état peut être particulièrement sensible (infos personnelles, docs propriétaires, décisions internes), donc la sécurité doit être pensée à chaque couche.
Gardez les secrets côté serveur
Tout ce qui permettrait à un client d'usurper votre application doit rester backend-only : clés API, connecteurs privés (Slack/Drive/DB creds) et prompts système internes ou logique de routage. Le frontend peut demander une action (« résume ce fichier »), mais le backend décide comment l'exécuter et avec quelles credentials.
Autorisez chaque écriture (et la plupart des lectures)
Traitez chaque mutation d'état comme une opération privilégiée. Quand le client tente de créer un message, renommer une conversation ou attacher un fichier, le backend doit vérifier :
- L'utilisateur est authentifié.
- L'utilisateur possède la ressource (conversation, workspace, projet).
- L'utilisateur est autorisé à effectuer l'action (rôle, limites de plan, politique org).
Cela évite les attaques par « devinette d'ID » où quelqu'un échange un conversation_id et accède à l'historique d'un autre.
Ne faites jamais confiance au navigateur : validez et assainissez
Considérez tout état fourni par le client comme une entrée non fiable. Validez le schéma et les contraintes (types, longueurs, enums autorisées) et assainissez selon la destination (SQL/NoSQL, logs, rendu HTML). Si vous acceptez des « mises à jour d'état » (ex. paramètres, outils), whitelistez les champs autorisés plutôt que de fusionner un JSON arbitraire.
Pistes d'audit pour actions critiques
Pour les actions qui modifient l'état durable — partage, export, suppression, accès à des connecteurs — enregistrez qui a fait quoi et quand. Un log d'audit léger aide pour la réponse aux incidents, le support client et la conformité.
Minimisation des données et chiffrement
Conservez seulement ce dont vous avez besoin pour la fonctionnalité. Si vous n'avez pas besoin des prompts complets indéfiniment, envisagez des fenêtres de rétention ou de la redaction. Chiffrez l'état sensible au repos si nécessaire (tokens, creds de connecteurs, documents uploadés) et utilisez TLS en transit. Séparez la métrologie opérationnelle du contenu pour restreindre plus facilement les accès.
Architecture de référence pratique et checklist de construction
Un défaut utile pour les apps IA : le backend est la source de vérité, et le frontend est un cache optimiste et rapide. L'UI peut sembler instantanée, mais tout ce que vous ne voudriez pas perdre (messages, statut des jobs, sorties d'outils, événements facturables) doit être confirmé et stocké côté serveur.
Si vous construisez via un workflow « vibe-coding » — où beaucoup de surface produit est générée rapidement — le modèle d'état devient encore plus important. Des plateformes comme Koder.ai peuvent aider les équipes à livrer des apps web, backend et mobiles depuis du chat, mais la même règle demeure : l'itération rapide est la plus sûre quand vos sources de vérité, IDs et transitions de statut sont conçues en amont.
Architecture de référence (prête à être déployée)
Frontend (navigateur/mobile)
- État UI : panneaux ouverts, texte de brouillon, modèle sélectionné, indicateurs temporaires « en train de taper ».
- Cache d'état serveur : conversations récentes, dernier statut connu des jobs, tampon partiel de streaming.
- Pipeline de requête unique qui attache toujours :
session_id,conversation_idet un nouveaurequest_id.
Backend (API + workers)
- Service API : valide les entrées, crée des enregistrements, émet des réponses en streaming.
- Stockage durable (SQL/NoSQL) : conversations, messages, appels d'outils, statut des jobs.
- Queue + workers : tâches longue durée (indexation RAG, parsing de fichiers, génération d'images).
- Cache (optionnel) : lectures chaudes (résumés de conversations, métadonnées d'embeddings), toujours clefsées par versions/timestamps.
Remarque : une manière pratique de garder cette cohérence est de standardiser tôt votre stack backend. Par exemple, des backends générés par Koder.ai utilisent souvent Go avec PostgreSQL (et React en frontend), ce qui facilite de centraliser l'état "autoritatif" en SQL tout en gardant le cache client jetable.
Concevez d'abord votre modèle d'état
Avant de construire des écrans, définissez les champs dont vous dépendrez à chaque couche :
- IDs et propriété :
user_id,org_id,conversation_id,message_id,request_id. - Timestamps et ordre :
created_at,updated_atet unsequenceexplicite pour les messages. - Champs de statut :
queued | running | streaming | succeeded | failed | canceled(pour jobs et appels d'outils). - Versioning :
etagouversionpour des updates sûres contre les conflits.
Cela évite le bug classique où l'UI « a l'air correcte » mais ne peut pas concilier retries, rafraîchissements ou éditions concurrentes.
Utilisez des formes d'API cohérentes
Gardez des endpoints prévisibles across features :
GET /conversations(liste)GET /conversations/{id}(récupérer)POST /conversations(créer)POST /conversations/{id}/messages(append)PATCH /jobs/{id}(mettre à jour le statut)GET /streams/{request_id}ouPOST .../stream(stream)
Retournez le même envelope partout (y compris pour les erreurs) afin que le frontend puisse mettre à jour l'état de manière uniforme.
Ajoutez de l'observabilité là où l'état peut casser
Loggez et retournez un request_id pour chaque appel IA. Enregistrez les inputs/outputs d'appels d'outils (avec redaction), latences, retries et statut final. Facilitez la réponse à la question : « Qu'est-ce que le modèle a vu, quels outils ont tourné et quel état avons-nous persisté ? »
Checklist de construction (pour éviter les bugs d'état courants)
- Le backend est la source de vérité ; le cache frontend est clairement identifié et jetable.
- Chaque écriture est idempotente (safe à relancer) via
request_id(et/ouIdempotency-Key). - Les transitions de statut sont explicites et validées (pas de sauts silencieux
queued→succeeded). - Les updates en streaming se fusionnent par IDs/séquence, pas par « dernier message gagne ».
- Les conflits se gèrent via
version/etagou des règles de merge serveur. - Les PII et secrets ne sont jamais stockés dans l'état client ; redigez les logs par défaut.
- Une vue dashboard existe pour le debug : requêtes, appels d'outils, statut des jobs et erreurs.
Quand vous adoptez des cycles de build plus rapides (y compris la génération assistée par IA), pensez à ajouter des garde-fous qui font respecter automatiquement ces items — validation de schéma, idempotence et streaming eventé — pour que « aller vite » n'entraîne pas une dérive d'état. En pratique, c'est là qu'une plateforme end-to-end comme Koder.ai devient utile : elle accélère la livraison tout en permettant d'exporter le code source et en gardant des patterns de gestion d'état cohérents sur web, backend et mobile.