Ce que doit faire un gestionnaire d'expériences tarifaires
Les expérimentations tarifaires sont des tests structurés où vous affichez différents prix (ou packagings) à différents groupes de clients et mesurez ce qui change — conversion, montées en gamme, churn, revenu par visiteur, et plus. C’est la version tarification d’un test A/B, mais avec un risque supplémentaire : une erreur peut perturber des clients, générer des tickets support ou même violer des règles internes.
Un gestionnaire d'expériences tarifaires est le système qui garde ces tests contrôlés, observables et réversibles.
Les problèmes que cette application doit résoudre
Contrôle : Les équipes ont besoin d’un endroit unique pour définir ce qui est testé, où et pour qui. « On a changé le prix » n’est pas un plan — une expérience doit avoir une hypothèse claire, des dates, des règles de ciblage, et un bouton d’arrêt.
Suivi : Sans identifiants cohérents (clé d’expérience, clé de variante, horodatage d’assignation), l’analyse devient devinette. Le gestionnaire doit garantir que chaque exposition et achat peut être attribué au bon test.
Cohérence : Les clients ne doivent pas voir un prix sur la page tarifaire et un autre au checkout. Le gestionnaire doit coordonner l’application des variantes sur toutes les surfaces pour que l’expérience soit cohérente.
Sécurité : Les erreurs de tarification coûtent cher. Il faut des garde-fous comme des limites de trafic, des règles d’éligibilité (par ex. uniquement nouveaux clients), des étapes d’approbation et une traçabilité.
Qui l’utilise
- Produit pour planifier les expériences, définir les métriques de succès et décider des envois.
- Growth/Marketing pour itérer sur les offres et messages liés au prix.
- Finance pour faire respecter les règles de revenu, les politiques de remise et les besoins de reporting.
- Support pour comprendre ce qu’un client a vu et résoudre rapidement les litiges.
- Ingénierie pour intégrer les changements de prix de façon sûre et prévisible.
Ce que nous construisons (et ce que nous ne construisons pas)
Ce post se concentre sur une application web interne qui gère les expériences : création, assignation de variantes, collecte d’événements et reporting.
Ce n’est pas un moteur de tarification complet (calcul de taxes, facturation, catalogues multi-devises, prorata, etc.). C’est plutôt le panneau de contrôle et la couche de suivi qui rendent les tests de prix suffisamment sûrs pour être exécutés régulièrement.
Périmètre, exigences et non-objectifs
Un gestionnaire d’expériences tarifaires n’est utile que si l’on sait précisément ce qu’il fera — et ne fera pas. Un périmètre restreint maintient le produit facile à exploiter et plus sûr à déployer, surtout lorsque du vrai revenu est en jeu.
Exigences minimales (capacités indispensables)
Au minimum, votre application web doit permettre à un opérateur non technique d’exécuter une expérience de bout en bout :
- Créer des expériences avec un nom, une hypothèse, le(s) produit(s) ciblé(s), le(s) segment(s) ciblé(s) et une durée planifiée.
- Définir des variantes (par ex. « Contrôle : 29 $ », « Traitement : 35 $ »), incluant la devise, la période de facturation et les règles d’éligibilité.
- Démarrer / mettre en pause / arrêter une expérience, avec statut clair et horodatages effectifs.
- Voir les résultats au niveau basique : conversion, revenu par visiteur, panier moyen, plus des indicateurs de confiance/incertitude.
Si vous ne faites rien d’autre, faites ces éléments bien — avec des valeurs par défaut claires et des garde-fous.
Types d’expériences pris en charge (restez intentionnels)
Décidez tôt des formats d’expériences que vous supporterez pour que l’UI, le modèle de données et la logique d’assignation restent cohérents :
- Tests A/B (un contrôle vs un traitement) comme voie principale.
- Tests multivariés / multi-armés (plusieurs points de prix) pour les équipes qui ont besoin de plus de deux options.
- Groupes holdout (par ex. 5 % voit le prix de base) pour mesurer des effets long terme ou systémiques.
- Déploiement progressif (ramping du trafic) pour réduire le risque tout en apprenant.
Non-objectifs (ce que vous ne construisez pas)
Soyez explicite pour éviter le « scope creep » qui transformerait l’outil en système fragile et critique pour l’entreprise :
- Pas un système de facturation complet (facturation, taxes, prorata, remboursements).
- Pas une plateforme BI complète (exploration libre, SQL personnalisé, modélisation data warehouse).
- Pas de ML complexe d’optimisation (moteurs de tarification dynamiques, reinforcement learning, auto-tuning).
Critères de succès
Définissez le succès en termes opérationnels, pas seulement statistiques :
- Insights prêts à décision : un PM peut choisir « déployer / revert / itérer » en toute confiance.
- Faible risque opérationnel : valeurs par défaut sûres, rollback facile et exposition contrôlée.
- Auditabilité : qui a changé quoi, quand et pourquoi — adapté aux revues finance et conformité.
Modèle de données : expériences, variantes et assignations
Une application d’expérimentation tarifaire vit ou meurt par son modèle de données. Si vous ne pouvez pas répondre fiablement à « quel prix ce client a-t-il vu, et quand ? », vos métriques seront bruyantes et l’équipe perdra confiance.
Entités clés à modéliser
Commencez par un petit ensemble d’objets centraux qui reflètent le fonctionnement réel de la tarification :
- Product : ce qui est vendu (ex. « Analytics Suite »).
- Plan : un palier de packaging (ex. Starter, Pro, Enterprise).
- Price : le montant effectif et les règles de facturation (devise, intervalle, règles pays/TVA, dates d’effet).
- Customer : l’unité d’analyse (compte, utilisateur, workspace — choisissez-en une et tenez-vous-y).
- Segment : une définition réutilisable (ex. « US seulement », « Self-serve », « Nouveaux clients »).
- Experiment : le conteneur avec périmètre, hypothèse, date de début/fin et ciblage.
- Variant : chaque traitement (Variant A = prix actuel, Variant B = nouveau prix).
- Assignment : l’enregistrement qu’un client a été placé dans une variante spécifique.
- Event : actions suivies (page_view, checkout_started, subscription_created, upgrade).
- Metric : une définition calculée (taux de conversion, ARPA, revenu par visiteur, churn).
Identifiants et champs temporels utiles
Utilisez des identifiants stables entre systèmes (product_id, plan_id, customer_id). Évitez les « jolis noms » comme clés — ils changent.
Les champs temporels sont tout aussi importants :
- created_at pour tout.
- starts_at / ends_at sur les expériences pour les fenêtres de reporting.
- decision_date (ou decided_at) pour marquer quand le résultat a été accepté.
Considérez aussi effective_from / effective_to sur les enregistrements Price afin de reconstituer les prix à tout moment.
Relations qui rendent l’attribution possible
Définissez les relations explicitement :
- Experiment → Variants (one-to-many).
- Customer → Assignments (one-to-many, souvent limité à une assignation active par expérience).
- Event → Customer + Experiment + Variant.
Concrètement, un Event doit porter (ou être joignable à) customer_id, experiment_id et variant_id. Si vous ne stockez que customer_id et « cherchez l’assignation plus tard », vous risquez des joins incorrects quand les assignations changent.
Immutabilité : conservez l’historique, n’écrasez pas
Les expérimentations tarifaires ont besoin d’un historique compatible audit. Rendez les enregistrements clés append-only :
- Prices doivent être versionnés, pas mis à jour en place.
- Assignments ne doivent jamais être édités pour « corriger » des données ; si vous devez modifier une exposition, créez un nouvel enregistrement et clôturez l’ancien.
- Decisions (gagnant, rationale, decision_date) doivent être conservées même si vous relancez un test similaire plus tard.
Cette approche rend vos rapports cohérents et facilite plus tard les fonctionnalités de gouvernance comme les journaux d’audit.
Workflow et cycle de vie d’une expérience
Un gestionnaire d’expériences tarifaires a besoin d’un cycle de vie clair pour que tout le monde comprenne ce qui est modifiable, ce qui est verrouillé, et ce qu’il arrive aux clients quand l’expérience change d’état.
Cycle de vie recommandé
Draft → Scheduled → Running → Stopped → Analyzed → Archived
- Draft : Création de l’expérience, des variantes, du ciblage et des métriques de succès. Rien n’est servi aux clients.
- Scheduled : Une date de début (et optionnellement de fin) est définie. Le système valide la readiness et peut notifier les parties prenantes.
- Running : Assignation et livraison des prix en live. La plupart des champs doivent se verrouiller pour éviter des modifications accidentelles en cours de test.
- Stopped : L’expérience n’inscrit plus de nouveaux utilisateurs ; vous choisissez comment traiter les utilisateurs existants.
- Analyzed : Les résultats sont finalisés, documentés et partagés.
- Archived : Stockage en lecture seule pour conformité et référence future.
Champs requis et validations par état
Pour réduire les lancements risqués, imposez des champs requis au fur et à mesure de la progression :
- Avant Scheduled : owner, périmètre (produits/régions/plans), variantes et points de prix, répartition/exposition, start/end times.
- Avant Running : hypothèse, métrique(s) primaire(s), garde-fous (ex. churn, remboursements, tickets support), taille d’échantillon minimale ou règle de durée, plan de rollback, et confirmation du schéma de tracking/événements.
- Avant Analyzed : instantané final des données, notes d’analyse, et décision (ship/iterate/reject).
Garde-fous d’approbation et overrides
Pour la tarification, ajoutez des gates optionnels pour Finance et Legal/Conformité. Seuls les approuveurs peuvent passer Scheduled → Running. Si vous supportez des overrides (ex. rollback urgent), enregistrez qui a overridé, pourquoi et quand dans le journal d’audit.
Ce que signifie « Stop » opérationnellement
Quand une expérience est Stopped, définissez deux comportements explicites :
- Freeze assignments : arrêter d’assigner de nouveaux utilisateurs ; garder les utilisateurs existants épinglés à leur dernière variante assignée.
- Serving policy : soit continuer à servir le dernier prix vu (stabilité pour les clients en cours de parcours), soit revenir au baseline (rollback rapide).
Faites de ce choix une étape obligatoire au moment de l’arrêt pour que l’équipe ne puisse pas stopper une expérience sans décider de l’impact client.
Assignation de variantes et répartition du trafic
Bien réussir l’assignation fait la différence entre un test de prix fiable et du bruit confus. Votre appli doit faciliter la définition de qui reçoit un prix et garantir qu’il le voit de façon cohérente.
Assignation cohérente (règle du “sticky”)
Un client doit voir la même variante entre sessions, appareils (quand c’est possible) et actualisations. Cela signifie que l’assignation doit être déterministe : avec la même clé d’assignation et la même expérience, le résultat est toujours identique.
Approches communes :
- Assignation basée sur hash : calculer un hash de
(experiment_id + assignment_key) et le mapper sur une variante.
- Assignation stockée : écrire la variante assignée dans une table pour la récupérer plus tard (utile pour l’audit ou des overrides complexes).
Beaucoup d’équipes utilisent l’assignation par hash par défaut et ne stockent les assignations que lorsque nécessaire (support ou gouvernance).
Choisir une clé d’assignation
Votre appli doit supporter plusieurs clés, car la tarification peut être au niveau utilisateur ou compte :
- user_id : meilleur si la tarification est individuelle et que la connexion est fiable.
- account_id / org_id : meilleur pour le B2B afin que tout le monde dans la même entreprise voie le même prix.
- cookie/device ID anonyme : utile avant la connexion, avec un chemin d’upgrade pour fusionner vers user_id après inscription/connexion.
Ce chemin d’upgrade compte : si une personne navigue anonymement puis crée un compte, décidez si vous conservez sa variante originale (continuité) ou si vous la réassignez (règles d’identité plus propres). Faites-en un paramètre clair et explicite.
Répartition du trafic et ramp-ups
Supportez une allocation flexible :
- 50/50 pour les tests A/B simples
- Splits pondérés (ex. 90/10) pour contrôler le risque
- Schedules de ramp-up (ex. 1 % → 5 % → 25 % → 50 %) avec dates/heures
En rampant, gardez l’assignation sticky : l’augmentation de trafic doit ajouter de nouveaux utilisateurs à l’expérience, pas reshuffler les existants.
Cas limites à gérer
Les tests concurrents peuvent se chevaucher. Mettez en place des garde-fous pour :
- Groupes mutuellement exclusifs (une seule expérience tarifaire active par utilisateur/compte)
- Règles de priorité (si deux expériences ciblent le même client, laquelle l’emporte ?)
- Exclusions (personnel interne, comptes de test/support, régions, plans, contrats existants)
Un écran « Aperçu d’assignation » (pour un utilisateur/compte d’exemple) aide les équipes non techniques à vérifier les règles avant le lancement.
Intégrer les prix dans le produit en toute sécurité
Testez les affectations en toute sécurité
Ajoutez une vue QA pour vérifier l'affectation d'un utilisateur ou d'une organisation avant le lancement.
Les expérimentations tarifaires échouent le plus souvent à l’intégration — pas parce que la logique d’expérience est mauvaise, mais parce que le produit affiche un prix et en facture un autre. Votre appli doit rendre très explicite « quel est le prix » et « comment le produit l’utilise ».
Séparer la définition du prix de sa livraison
Traitez la définition du prix comme source de vérité (règles du prix de la variante, dates d’effet, devise, gestion fiscale, etc.). Traitez la livraison du prix comme un mécanisme simple pour récupérer le prix de la variante choisie via une API ou un SDK.
Cette séparation garde l’outil d’expérimentation propre : les équipes non techniques modifient les définitions, tandis que les ingénieurs intègrent un contrat de livraison stable comme GET /pricing?sku=....
Décidez où le prix est calculé
Deux patterns courants :
- Côté serveur au checkout (recommandé pour la facturation) : calculez le montant final payable côté serveur pour éviter incohérences et manipulation.
- Côté client pour l’affichage : acceptable pour montrer des estimations, mais doit être vérifié côté serveur au moment de l’achat.
Approche pratique : « afficher côté client, vérifier et calculer côté serveur », en utilisant la même assignation d’expérience.
Soyez stricts sur les devises, taxes et arrondis
Les variantes doivent suivre les mêmes règles pour :
- sélection de la devise (locale utilisateur vs pays de facturation)
- inclusion de la taxe (TVA incluse vs ajoutée)
- arrondis (par article vs par facture)
Stockez ces règles avec le prix pour que chaque variante soit comparable et compatible finance.
Prévoyez des fallback sûrs
Si le service d’expérimentation est lent ou down, votre produit doit retourner un prix par défaut sûr (généralement le baseline). Définissez des timeouts, du caching, et une politique « fail closed » pour que le checkout ne casse pas — et logguez les fallbacks pour quantifier l’impact.
Métriques, événements et bases d’attribution
Les expérimentations tarifaires vivent ou meurent par la mesure. Votre appli doit rendre difficile le « ship and hope » en exigeant des métriques claires, des événements propres et une approche d’attribution cohérente avant le lancement.
Choisir des métriques primaires (métriques de décision)
Commencez par une ou deux métriques qui serviront à décider du gagnant. Choix courants pour la tarification :
- Taux de conversion (ex. visiteur → checkout, essai → payant)
- Revenu par visiteur (RPV) (capture le prix et la conversion ensemble)
- ARPA/ARPU (utile pour les abonnements)
- Churn / rétention (si mesurable dans une fenêtre raisonnable)
Règle utile : si les équipes se disputent le résultat après le test, vous n’avez probablement pas défini clairement la métrique de décision.
Ajouter des garde-fous (métriques « ne pas casser »)
Les garde-fous détectent un dommage que pourrait causer un prix plus élevé même si le revenu à court terme paraît bon :
- Taux de remboursement et rétrofacturations
- Tickets support (facturation, confusion, plaintes)
- Échecs de paiement (cartes refusées, problèmes 3DS)
- Baisse essai→payant (les changements de prix peuvent affecter l’intention)
Votre appli peut imposer des seuils (ex. « le taux de remboursement ne doit pas augmenter de plus de 0,3 % ») et mettre en évidence les dépassements sur la page de l’expérience.
Définir un schéma d’événements fiable
Au minimum, votre tracking doit inclure des identifiants stables pour l’expérience et la variante sur chaque événement pertinent.
{
"event": "purchase_completed",
"timestamp": "2025-01-15T12:34:56Z",
"user_id": "u_123",
"experiment_id": "exp_earlybird_2025_01",
"variant_id": "v_price_29",
"currency": "USD",
"amount": 29.00
}
Rendez ces propriétés obligatoires à l’ingestion, pas « au mieux ». Si un événement arrive sans experiment_id/variant_id, routez-le vers un bucket « unattributed » et signalez des problèmes de qualité des données.
Choisir les fenêtres d’attribution (et gérer les résultats différés)
Les résultats de tarification sont souvent différés (renouvellements, montées en gamme, churn). Définissez :
- Fenêtre d’attribution : ex. « compter les achats dans les 7 jours suivant la première exposition »
- Règle d’exposition : première exposition vs dernière exposition (la première est généralement plus sûre pour la tarification)
- Métriques différées : afficher un « premier aperçu » rapidement, mais conserver un état « final » qui se met à jour quand la fenêtre se ferme
Cela aligne les équipes sur quand un résultat est fiable et prévient les décisions prématurées.
UX et écrans pour les équipes non techniques
Faites durer votre budget
Publiez ce que vous créez avec Koder.ai ou parrainez des collègues et gagnez des crédits d'utilisation.
Un outil d’expérimentation tarifaire ne fonctionne que si PMs, marketeurs et finance peuvent l’utiliser sans demander un ingénieur à chaque action. L’UI doit répondre rapidement à trois questions : Qu’est-ce qui tourne ? Qu’est-ce qui changera pour les clients ? Que s’est-il passé et pourquoi ?
Écrans principaux à inclure
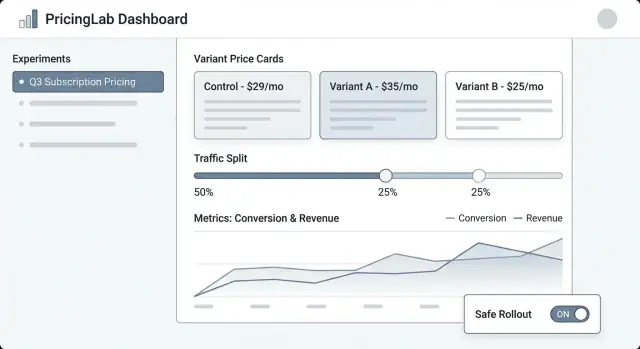
Liste d’expériences doit ressembler à un tableau de bord opérationnel. Affichez : nom, statut (Draft/Scheduled/Running/Paused/Ended), dates, répartition du trafic, métrique primaire et owner. Ajoutez un « last updated by » et un horodatage visible pour renforcer la confiance.
Détail d’expérience est le poste de commande. Mettez un résumé compact en haut (statut, dates, audience, répartition, métrique primaire). En dessous, utilisez des onglets comme Variants, Targeting, Metrics, Change log et Results.
Éditeur de variante doit être simple et opiniâtre. Chaque ligne variante doit inclure le prix (ou règle de prix), la devise, la période de facturation et une description en langage clair (« Annuel : 120 $ → 108 $ »). Rendre l’édition d’une variante live difficile en demandant une confirmation.
Vue des résultats doit commencer par la décision, pas seulement des graphiques : « La variante B a augmenté la conversion au checkout de 2,1 % (IC 95 % …). » Puis fournissez des drills et des filtres.
Concevoir pour la clarté (et la confiance)
Utilisez des badges de statut cohérents et affichez une timeline des dates clés. Montrez la répartition du trafic en pourcentage et en barre visuelle. Incluez un panneau « Qui a changé quoi » qui liste les modifications des variantes, du ciblage et des métriques.
Garde-fous et validations
Avant d’autoriser Start, exigez : au moins une métrique primaire sélectionnée, au moins deux variantes avec prix valides, un plan de montée en charge (optionnel mais recommandé) et un plan de rollback ou un prix fallback. Si quelque chose manque, affichez des erreurs actionnables (« Ajoutez une métrique primaire pour activer les résultats »).
Actions rapides qui font gagner du temps
Fournissez des actions sûres et proéminentes : Pause, Stop, Ramp up (ex. 10 % → 25 % → 50 %), et Duplicate (copier les paramètres dans un nouveau Draft). Pour les actions risquées, utilisez des confirmations qui résument l’impact (« Mettre en pause fige les assignations et arrête l’exposition »).
Prototyper l’outil interne plus vite
Si vous voulez valider les workflows (Draft → Scheduled → Running) avant d’investir dans une construction complète, une plateforme vibe-coding comme Koder.ai peut vous aider à créer rapidement une appli interne à partir d’un spec conversationnel — puis itérer avec des écrans par rôle, journaux d’audit et dashboards simples. Utile pour des prototypes où vous voulez une UI React fonctionnelle et un backend Go/PostgreSQL exportable et durcissable plus tard.
Tableaux de bord et reporting qui permettent de décider
Un dashboard d’expérimentation tarifaire doit répondre à une question rapidement : « Doit-on garder ce prix, le rollbacker ou continuer d’apprendre ? » Le meilleur reporting n’est pas le plus sophistiqué — il est le plus facile à croire et à expliquer.
L’essentiel au-dessus de la ligne de flottaison
Commencez par un petit ensemble de graphiques de tendance qui se mettent à jour automatiquement :
- Taux de conversion au fil du temps (avec un marqueur clair « expérience démarrée »)
- Revenu par visiteur (ou panier moyen selon votre modèle)
- Remboursements/annulations si la tarification affecte la rétention
Sous les graphiques, incluez un tableau comparatif des variantes : nom de variante, part de trafic, visiteurs, achats, taux de conversion, revenu par visiteur, et le delta vs contrôle.
Pour les indicateurs de confiance, évitez le jargon académique. Utilisez des libellés clairs :
- « Aperçu initial » (pas assez de données)
- « Tendance favorable / défavorable » (directionnel)
- « Haute confiance » (prêt pour décision)
Un bref tooltip peut expliquer que la confiance augmente avec la taille d’échantillon et le temps.
Découpages par segment pour éviter de mauvais déploiements
La tarification gagne souvent globalement mais échoue pour des groupes clés. Facilitez le changement d’onglet de segment :
- Nouveaux vs récurrents
- Région (pays/état)
- Appareil (mobile/desktop)
- Palier de plan (ou catégorie de produit)
Conservez les mêmes métriques partout pour que les comparaisons restent cohérentes.
Avertissements d’anomalie actionnables
Ajoutez des alertes légères directement sur le dashboard :
- Chute soudaine de conversion après un changement de prix
- Pic de revenu pouvant provenir d’un bug de tracking ou d’un événement ponctuel
- Pertes de données (événements arrêtés, trafic anormalement bas, ingestion retardée)
Quand une alerte apparaît, montrez la fenêtre suspecte et un lien vers l’état brut des événements.
Exports et partage pour une alignement rapide
Rendez le reporting portable : un download CSV pour la vue courante (y compris segments) et un lien interne partageable vers le rapport d’expérience. Si utile, liez un court explicatif comme /blog/metric-guide pour que les parties prenantes comprennent sans organiser une réunion.
Permissions, journaux d’audit et gouvernance
Les expérimentations tarifaires touchent au revenu, à la confiance client et souvent au reporting réglementé. Un modèle de permissions simple et une piste d’audit claire réduisent les lancements accidentels, les disputes « qui a changé ça ? » et vous aident à livrer plus vite avec moins de retours en arrière.
Rôles qui correspondent au fonctionnement des équipes
Gardez les rôles faciles à expliquer et difficiles à mal utiliser :
- Viewer : accès en lecture seule aux configurations, statuts et rapports.
- Editor : peut créer des drafts (variantes, textes, règles d’éligibilité) mais ne peut pas démarrer/arrêter ni changer la répartition en production.
- Approver : peut revoir et approuver un draft, et effectuer des actions en production (start, stop, ramp) dans les garde-fous.
- Admin : gère les rôles, paramètres globaux et contrôles d’urgence.
Si vous avez plusieurs produits ou régions, scopez les rôles par workspace (ex. « Tarification UE ») pour que quelqu’un d’une zone ne puisse pas impacter une autre.
Journaux d’audit fiables
L’application doit journaliser chaque changement avec qui, quoi, quand, idéalement avec des diffs before/after. Événements minimum à capturer :
- Définitions de variantes (prix, devise, période), répartition du trafic, start/stop et règles de ciblage.
- Actions d’approbation (demandé, approuvé, rejeté) et rollbacks.
- Changements de source de données (quelle source de revenu ou stream d’événements est utilisé).
Rendez les logs recherchables et exportables (CSV/JSON), et liez-les depuis la page d’expérience pour que les réviseurs ne cherchent pas. Une vue dédiée /audit-log aide les équipes conformité.
Traitez les identifiants client et les revenus comme sensibles par défaut :
- Masquez les identifiants bruts (hashing, tokenisation) et limitez l’accès aux découpages de revenu.
- Restreignez les règles de segmentation qui pourraient révéler des attributs protégés.
- Stockez les secrets (clés API, identifiants warehouse) en dehors de la base principale.
Ajoutez des notes légères sur chaque expérience : hypothèse, impact attendu, justification d’approbation et résumé « pourquoi on a arrêté ». Six mois plus tard, ces notes évitent de relancer des idées qui ont déjà échoué et rendent le reporting beaucoup plus crédible.
Tests et contrôles qualité avant le lancement
Ajoutez des contrôles de cycle de vie plus sûrs
Modélisez Brouillon → Planifié → En cours avec champs verrouillés et étapes d'approbation.
Les expérimentations tarifaires échouent de façon subtile : un split 50/50 dérive à 62/38, une cohorte voit la mauvaise devise, ou les événements n’arrivent jamais dans les rapports. Avant d’exposer de vrais clients, traitez le système d’expérimentation comme une fonctionnalité de paiement — validez le comportement, les données et les modes de défaillance.
Consistance d’assignation et précision du split
Commencez par des cas de test déterministes pour prouver que la logique d’assignation est stable entre services et releases. Utilisez des entrées fixes (customer IDs, clés d’expérience, salt) et assert que la même variante est retournée à chaque fois.
customer_id=123, experiment=pro_annual_price_v2 -> variant=B
customer_id=124, experiment=pro_annual_price_v2 -> variant=A
Testez ensuite la distribution à grande échelle : générez par exemple 1M d’IDs synthétiques et vérifiez que le split observé reste dans une tolérance serrée (ex. 50 % ± 0,5 %). Vérifiez aussi les cas limites comme les plafonds de trafic (seulement 10 % enrôlés) et les groupes holdout.
Valider la collecte d’événements bout en bout
Ne vous contentez pas de « l’événement a été déclenché ». Ajoutez un flux automatisé qui crée une assignation test, déclenche un événement d’achat ou de checkout, et vérifie :
- que l’événement est accepté par le collecteur
- qu’il est stocké avec les bons champs experiment/variant
- qu’il apparaît dans la requête de reporting avec les bons timestamps et la déduplication
Exécutez cela en staging et en production avec une expérience de test limitée aux utilisateurs internes.
Outils QA pour vérifications non techniques
Donnez à QA et aux PMs un simple outil « preview » : entrez un customer ID (ou session ID) et voyez la variante assignée et le prix exact qui serait rendu. Cela détecte arrondis incorrects, devise erronée, taxes affichées différemment et problèmes de mauvais plan avant le lancement.
Considérez une route interne sûre comme /experiments/preview qui n’altère jamais d’assignations réelles.
Simuler pannes et mauvaises configurations
Entraînez-vous aux scénarios désagréables :
- Pipeline d’événements down : l’UI fonctionne ; les métriques affichent une bannière d’alerte et un badge « données incomplètes ».
- Service d’expérience indisponible : le produit retombe sur le prix de contrôle (et loggue le fallback).
- Mauvaise configuration (expériences qui se chevauchent, prix invalides) : bloquer la publication avec des erreurs de validation claires.
Si vous ne pouvez pas répondre à « que se passe-t-il quand X casse ? », vous n’êtes pas prêt à déployer.
Lancement, monitoring et plan d’itération
Lancer un gestionnaire d’expériences tarifaires, ce n’est pas juste « livrer un écran » : il faut contrôler le blast radius, observer rapidement le comportement et récupérer en toute sécurité.
Approche de déploiement : réduire le risque le jour J
Commencez par une trajectoire de lancement qui correspond à votre confiance et aux contraintes produit :
- Déploiement progressif : activer les expériences pour un petit pourcentage du trafic éligible, puis étendre en étapes (ex. 1 % → 10 % → 50 %).
- Feature flag : mettre derrière un flag l’ensemble du système d’expérimentation pour pouvoir le couper sans redeploiement. Utile pendant la stabilisation des intégrations.
- Beta interne : restreindre aux employés ou comptes de test pour valider assignation, rendu des prix et intégrité du checkout avant d’exposer des clients réels.
Monitoring : quoi surveiller durant les premières heures
Traitez le monitoring comme une exigence de release, pas un « nice to have ». Mettez des alertes pour :
- Taux d’erreur : failures API, erreurs checkout, exceptions du service de pricing.
- Latence : p95/p99 pour fetch de prix, assignation et pages checkout.
- Volume d’événements : chutes ou pics soudains sur les événements clés (view price, add to cart, purchase).
- Attribution manquante : achats sans experiment/variant IDs, ou variant IDs qui ne correspondent pas au log d’assignation.
Runbooks : pause et revert rapides
Rédigez un runbook pour l’opérationnel et l’on-call :
- Un kill switch global pour mettre en pause toutes les expériences.
- Un chemin revert vers le pricing baseline (prix baseline en cache, defaults sûrs).
- Propriété claire : qui approuve la pause, qui communique l’impact et comment enregistrer l’incident.
Itération après le MVP
Une fois le workflow de base stable, priorisez des améliorations qui accélèrent de meilleures décisions : règles de ciblage (géographique, plan, type de client), statistiques et garde-fous renforcés, et intégrations (data warehouse, billing, CRM). Si vous proposez des paliers ou packaging, pensez à exposer les capacités d’expérimentation sur /pricing pour que les équipes sachent ce qui est supporté.