Ce qu’une application de litiges pour place de marché doit résoudre
Une application de litiges n’est pas juste un « formulaire de support avec un statut ». C’est le système qui décide comment l’argent, les articles et la confiance circulent dans votre place de marché quand quelque chose tourne mal. Avant de dessiner des écrans ou des tables, définissez clairement l’espace du problème — sinon vous construirez un outil facile à utiliser mais difficile à faire respecter.
Définir ce que « litige » signifie pour votre place de marché
Commencez par lister les types de litiges que vous devez réellement gérer et comment ils diffèrent. Catégories communes :
- Objet non reçu (retards d’expédition, mauvaise adresse, colis perdu)
- Non conforme / endommagé (problèmes de qualité, pièces manquantes)
- Fraude / achat non autorisé (prise de contrôle de compte, moyen de paiement volé)
- Rétrofacturations (litiges bancaires avec preuves et délais stricts)
Chaque type demande généralement des preuves, des fenêtres temporelles et des issues différentes (remboursement, remplacement, remboursement partiel, inversion du paiement au vendeur). Traitez le type de litige comme un moteur de workflow—pas seulement comme une étiquette.
Clarifier les objectifs (pour faire des arbitrages)
La gestion des litiges concurrence généralement la rapidité, la cohérence et la prévention des pertes. Écrivez ce à quoi ressemble le succès dans votre contexte :
- Résolution plus rapide : moins d’allers-retours et des délais clairs
- Moins d’erreurs : décisions standardisées et moins d’exceptions « cas spéciaux »
- Meilleure expérience acheteur/vendeur : transparence, clarté des statuts, étapes suivantes prévisibles
- Moins de pertes : réduire les remboursements inutiles, prévenir les abus répétés, gagner plus de rétrofacturations
Ces objectifs influencent tout, depuis les données que vous collectez jusqu’aux actions que vous automatisez.
Identifier qui utilise le système (et ce dont ils ont besoin)
La plupart des places de marché ont plus que « le support client ». Utilisateurs typiques : acheteurs, vendeurs, agents de support, admins, et finance/risque. Chaque groupe a une vue différente :
- Acheteurs et vendeurs : étapes simples, demandes de preuves claires, rappels de délais
- Agents de support : files d’attente, modèles, notes internes, aide à la décision
- Admin/finance : piste d’audit, contrôles des paiements, exports de rétrofacteurs, reporting
Décider ce qui sera en v1 vs plus tard
Un v1 solide se concentre généralement sur : création d’un dossier, collecte de preuves, messagerie, suivi des délais, et enregistrement d’une décision avec piste d’audit.
Les sorties ultérieures peuvent ajouter : règles d’auto-remboursement, signaux fraude, analytics avancés et intégrations plus profondes. Garder le périmètre restreint au début évite un système « tout faire » en qui personne n’a confiance.
Si vous allez vite, il peut être utile de prototyper le workflow de bout en bout avant de vous engager dans une construction complète. Par exemple, des équipes utilisent parfois Koder.ai (une plateforme vibe-coding) pour générer un tableau de bord admin React + backend Go/PostgreSQL à partir d’un cahier des charges conversationnel, puis exporter le code source une fois que les états de dossier et permissions sont établis.
Modéliser le workflow et les états du litige
Une application de litiges réussit ou échoue selon qu’elle reflète comment les litiges se déplacent réellement dans votre place de marché. Commencez par cartographier le parcours actuel de bout en bout, puis transformez cette carte en un petit ensemble d’états et de règles que le système peut faire respecter.
Cartographier le parcours du litige (étape par étape)
Écrivez le « chemin heureux » comme une chronologie : intake → collecte de preuves → revue → décision → paiement/remboursement. Pour chaque étape, notez :
- Qui agit ensuite (acheteur, vendeur, agent, contrôle automatisé)
- Quelles informations sont requises (photos, suivi, messages)
- Ce qui change dans le statut de commande/paiement (blocage des fonds, remboursement initié)
Ceci devient la colonne vertébrale pour l’automatisation, les rappels et le reporting.
Définir des états clairs (et ce qu’ils signifient)
Gardez les états mutuellement exclusifs et simples à comprendre. Une base pratique :
- Opened : litige créé, en attente d’info initiale
- Waiting on buyer / Waiting on seller : action attendue d’une partie
- Under review : agent ou règles automatisées évaluent les preuves
- Resolved : décision exécutée (remboursement/libération/remplacement)
- Appealed : décision contestée, deuxième niveau de revue
Pour chaque état, définissez critères d’entrée, transitions autorisées et champs requis avant d’avancer. Cela évite les dossiers bloqués et les issues incohérentes.
Délais, SLA et règles d’escalade
Attachez des délais aux états (ex. le vendeur a 72 heures pour fournir le suivi). Ajoutez des rappels automatiques et décidez ce qui se passe quand le temps expire : fermeture auto, décision par défaut, ou escalade vers revue manuelle.
Issues et actions
Modélisez les outcomes séparément des états pour pouvoir tracer ce qui s’est réellement passé : remboursement, remboursement partiel, remplacement, libération des fonds, restriction de compte / bannissement, ou crédit commercial.
Capturer les exceptions tôt
Les litiges deviennent compliqués. Prévoyez des chemins pour suivi manquant, envois fractionnés, preuves de livraison de biens numériques, et commandes avec plusieurs articles (décisions au niveau article vs commande entière). Concevoir ces branches tôt évite la gestion ponctuelle qui casse la cohérence plus tard.
Concevoir le modèle de données (Dossiers, Preuves, Décisions)
Une application de litiges réussit ou échoue selon que le modèle de données correspond aux questions réelles : « Que s’est-il passé ? », « Quelle est la preuve ? », « Qu’avons-nous décidé ? », et « Pouvons‑nous présenter une piste d’audit plus tard ? » Commencez par nommer un petit ensemble d’entités cœur et soyez strict sur ce qui peut changer.
Entités cœur (et pourquoi elles existent)
Au minimum, modélisez :
- Order (ce qui a été acheté, quand, par qui)
- Payment (montants, devise, références autorisation/capture/remboursement)
- User (acheteur, vendeur, agent/admin)
- Dispute / Case (le conteneur qui suit le workflow)
- Claim reason (codes de motif standardisés et descriptions)
- Evidence (fichiers, liens, faits structurés comme des numéros de suivi)
- Message (historique de conversation et notifications système)
- Decision (issue, justification, montants, dates d’effet)
Gardez « Dispute » focalisé : il doit référencer la commande/paiement, stocker le statut, les délais, et pointer vers preuves et décisions.
Données immuables vs éditables
Traitez tout ce qui doit être défendable plus tard comme append-only :
- Changements de statut (qui/quand/pourquoi)
- Décisions et renversements
- Uploads et suppressions de preuves (enregistrer des tombstones, pas de suppressions physiques)
- Modifications de montants associées aux remboursements/rétrofacturations
Autorisez des éditions seulement pour la commodité opérationnelle :
- Notes internes, tags, affectation de file
- Métadonnées en lecture seule (ex. « niveau du vendeur ») qui peuvent être re-synchronisées
Cette séparation est plus facile avec une table de piste d’audit (journal d’événements) plus des champs « snapshot » courants sur le dossier.
Champs requis et validations
Définissez des validations strictes tôt :
- Codes de motif depuis une liste contrôlée (mappez aux codes du processeur si besoin)
- Montants avec devise, règles de précision et contraintes non négatives
- Dates pour ouverture/réception, délais de réponse, temps de résolution
- Attachments requis pour certains motifs (ex. numéro de suivi pour « objet non reçu »)
Pièces jointes, sécurité et rétention
Planifiez le stockage des preuves : types de fichiers autorisés, limites de taille, scan antivirus, et règles de rétention (ex. suppression auto après X mois si la politique le permet). Stockez les métadonnées de fichier (hash, uploader, horodatage) et gardez le blob dans un stockage d’objets.
IDs de dossier et métadonnées recherchables
Utilisez un schéma d’ID lisible humainement (ex. DSP-2025-000123). Indexez les champs recherchables comme order ID, buyer/seller IDs, statut, motif, fourchette de montant, et dates clés pour que les agents trouvent les dossiers vite depuis la file.
Rôles, permissions et contrôles des données sensibles
Les litiges impliquent plusieurs parties et des données à haut risque. Un modèle de rôles clair réduit les erreurs, accélère les décisions et aide à respecter les obligations de conformité.
Définir les rôles et ce que chacun peut faire
Commencez avec un petit ensemble explicite de rôles et mappez-les aux actions — pas seulement aux écrans :
- Acheteur / Vendeur : créer un litige, uploader des preuves, voir uniquement ce qu’ils peuvent voir, répondre aux messages, accepter ou rejeter des résolutions proposées
- Agent : trier les dossiers, demander plus d’infos, définir des délais, rédiger des décisions et appliquer des issues standardisées (rembourser, remplacer, refuser)
- Superviseur : annuler des décisions, rouvrir des dossiers, approuver des escalades, gérer modèles/politiques
- Finance : exécuter ou approuver les mouvements d’argent (remboursements, blocage/libération de paiements), et voir uniquement les champs nécessaires au paiement
- Admin : configurer les rôles, intégrations et règles de rétention — idéalement sans lire le contenu des dossiers par défaut
Utilisez des permissions par défaut au moindre privilège et n’ajoutez l’accès « break glass » que pour des urgences auditables.
Authentification et accès privilégié
Pour le personnel, supportez le SSO (SAML/OIDC) afin que l’accès suive le cycle de vie RH. Exigez MFA pour les rôles privilégiés (superviseur, finance, admin) et pour toute action qui modifie de l’argent ou une décision finale.
Les contrôles de session comptent : tokens à courte durée pour les outils staff, refresh lié à l’appareil si possible, et déconnexion automatique pour postes partagés.
PII, données de paiement et visibilité champ par champ
Séparez les “faits du dossier” des champs sensibles. Appliquez des permissions champ par champ pour :
- Informations personnelles identifiables (adresse, téléphone, e-mail)
- Détails de paiement (ne jamais stocker le PAN complet ; tokenisez et masquez)
- Notes internes et signaux de risque
Redigez par défaut dans l’UI et les logs. Si quelqu’un a besoin d’accès, enregistrez la raison.
Piste d’audit et règles de visibilité des preuves
Maintenez un journal immuable pour les actions sensibles : changements de décision, remboursements, blocage/libération de paiements, suppression de preuves, changements de permissions. Incluez horodatage, acteur, anciennes/nouvelles valeurs et source (API/UI).
Pour les preuves, définissez des règles de consentement et de partage : ce que l’autre partie peut voir, ce qui reste interne (ex. signaux fraude), et ce qui doit être partiellement masqué avant partage.
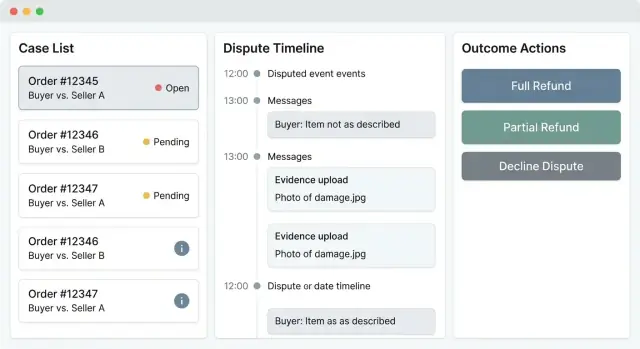
Expérience utilisateur : file de dossiers et fiche détail
Un outil de litiges vit ou meurt selon la rapidité : à quelle vitesse un agent peut trier un dossier, comprendre ce qui s’est passé et prendre une action sûre. L’UI doit rendre évident « ce qui nécessite attention maintenant », tout en rendant les données sensibles et les décisions irréversibles difficiles à cliquer par erreur.
File de dossiers : triage rapide avec filtres pertinents
Votre liste doit se comporter comme une console d’opérations, pas un tableau générique. Incluez des filtres qui reflètent le travail réel : statut, motif, montant, âge/SLA, vendeur, et score de risque. Ajoutez des vues sauvegardées (ex. « Nouveaux haute valeur », « En retard », « En attente acheteur ») pour que les agents ne recréent pas les filtres tous les jours.
Rendez les lignes scannables : ID de dossier, badge statut, jours ouverts, montant, partie (acheteur/vendeur), indicateur de risque, et prochain délai. Gardez un tri prédictible (par défaut par urgence/SLA). Les actions en lot sont utiles, mais limitez-les à des opérations sûres comme assigner/désassigner ou ajouter des tags internes.
Détail du dossier : tout ce qu’il faut, rien qui distraie
La page détail doit répondre à trois questions en quelques secondes :
- Que s’est-il passé ?
- Quelles sont les preuves ?
- Quelle est la prochaine action et son délai ?
Un layout pratique est une chronologie au centre (événements, changements de statut, signaux paiement/expédition), avec un panneau snapshot à droite pour le contexte commande/paiement (total, méthode de paiement, statut d’expédition, remboursements/rétrofacturations, IDs clés). Gardez des liens profonds vers les objets liés (order, payment, shipment) sous forme de routes relatives comme /orders/123 et /payments/abc.
Ajoutez une zone messages et une galerie de preuves qui supporte l’aperçu rapide (images, PDFs) plus les métadonnées (qui a soumis, quand, type, état de vérification). Les agents ne doivent jamais avoir à fouiller dans des pièces jointes pour comprendre la dernière mise à jour.
Actions claires et sûres (avec garde-fous)
Les actions de décision (rembourser, refuser, demander plus d’infos, escalader) doivent être sans ambiguïté. Utilisez des confirmations pour les étapes irréversibles et exigez des saisies structurées : note obligatoire, code de motif, et modèles de décision optionnels pour un libellé cohérent.
Séparez les canaux de collaboration : notes internes (agents uniquement, pour transmission) vs messages externes (visibles par acheteur/vendeur). Incluez des contrôles d’affectation et un « propriétaire courant » visible pour éviter le travail en double.
Accessibilité et consultation mobile
Concevez pour la navigation au clavier, un contraste lisible des statuts, et des labels pour lecteurs d’écran — surtout sur les boutons d’action et champs. Les vues mobiles doivent prioriser le snapshot, le dernier message, le prochain délai et un accès en un tap à la galerie de preuves pour des revues rapides lors d’astreintes.
Messagerie, notifications et délais
Collectez les preuves correctement
Créez des flux de preuves pour acheteurs et vendeurs avec téléchargements, modèles et dates limites.
Les litiges sont essentiellement des problèmes de communication avec un minuteur. Votre appli doit rendre évident qui doit faire quoi, quand, et par quel canal — sans forcer les gens à fouiller dans des fils d’e-mails.
Canaux : in-app d’abord, e-mail toujours, SMS optionnel
Utilisez la messagerie in-app comme source de vérité : chaque demande, réponse et pièce jointe doit vivre sur la chronologie du dossier. Puis répliquez les mises à jour clés par e-mail (nouveau message, preuve demandée, délai approchant, décision rendue). Si vous ajoutez le SMS, limitez-le aux rappels sensibles au temps (ex. « Délai dans 24 h ») et évitez d’y mettre des informations sensibles.
Modèles qui réduisent les allers-retours
Créez des modèles de message pour les demandes courantes afin que les agents restent cohérents et que les utilisateurs sachent à quoi ressemble une « bonne preuve » :
- Demande de preuve de livraison (transporteur, lien de suivi, scan de livraison)
- Demande photo (état de l’article, emballage, numéro de série)
- Instructions de retour (adresse, RMA, délai, transporteurs autorisés)
Permettez des placeholders comme order ID, dates et montants, plus une courte zone « édition humaine » pour que les réponses ne paraissent pas robotiques.
Délais, rappels et conséquences de l’expiration
Chaque demande doit générer un délai (ex. le vendeur a 3 jours ouvrés pour répondre). Affichez-le sur le dossier, envoyez des rappels automatiques (48h et 24h) et définissez des issues claires pour non-réponse (fermeture auto, remboursement auto, ou escalade).
Multilingue et sécurité par défaut
Si vous servez plusieurs régions, stockez le contenu des messages avec un tag de langue et fournissez des modèles localisés. Pour prévenir l’abus, ajoutez des limites de taux par dossier/utilisateur, limites taille/type pour les pièces jointes, scan antivirus, et rendu sûr (pas de HTML inline, assainir les noms de fichiers). Conservez une piste d’audit de qui a envoyé quoi et quand.
Collecte et vérification des preuves
Les preuves font gagner ou perdre la plupart des litiges, votre appli doit donc les traiter comme un workflow de première classe — pas comme un tas de pièces jointes.
Planifier les preuves acceptées
Définissez les types de preuves attendus pour les litiges courants : liens de suivi et scans de livraison, photos de l’emballage ou du dommage, factures/reçus, logs de chat, étiquettes de retour, et notes internes. Rendre ces types explicites aide à valider les entrées, standardiser la revue et améliorer le reporting.
Demander des preuves selon le motif
Évitez les invites génériques « uploadez n’importe quoi ». Générez plutôt des demandes structurées depuis le code de motif (ex. « Objet non reçu » → suivi transporteur + preuve de livraison ; « Non conforme » → capture de la fiche produit + photos de l’acheteur). Chaque demande devrait inclure :
- Ce qu’il faut envoyer
- Un court exemple (à quoi ressemble une « bonne » preuve)
- Une date limite alignée sur votre SLA
Ceci réduit les allers-retours et rend les dossiers comparables entre réviseurs.
Intégrité et contrôle de la chaîne de possession
Traitez les preuves comme des documents sensibles. Pour chaque upload, enregistrez :
- Un hash cryptographique (ex. SHA-256) du fichier
- Horodatages côté serveur
- Identité de l’uploader (utilisateur/service), rôle, et IP (si approprié)
- Événements d’audit immuables pour uploads, téléchargements et suppressions
Ces contrôles ne prouvent pas la véracité du contenu, mais prouvent si le fichier a été modifié après soumission et qui l’a manipulé.
Fournir un export « paquet de preuves »
Les litiges finissent souvent en revue externe (processeur de paiement, transporteur, arbitrage). Fournissez un export en un clic qui regroupe les fichiers clés plus un résumé : faits du dossier, chronologie, métadonnées de commande, et index des preuves. Gardez-le cohérent pour que les équipes puissent s’y fier sous pression.
Rétention et workflows de suppression
Les preuves peuvent contenir des données personnelles. Implémentez des règles de rétention par type de litige et région, plus un processus de suppression tracé (avec approbations et logs) quand la loi l’exige.
Décision, issues et appels
Exportez un dossier de preuves
Créez des exports qui regroupent fichiers clés et chronologie pour contestations et appels.
La décision est l’endroit où une appli de litiges construit la confiance ou créé du travail. L’objectif est la cohérence : des dossiers semblables doivent obtenir des issues semblables, et les deux parties doivent comprendre pourquoi.
Rédiger des politiques de décision en langage clair
Définissez les politiques comme des règles lisibles, pas du jargon légal. Pour chaque motif de litige, documentez :
- Ce qui qualifie pour approuver, refuser, ou relief partiel
- Quelles preuves sont requises (et ce qui est « souhaitable »)
- Quelles fenêtres s’appliquent (délais d’expédition, dates de réponse, scans de livraison)
Versionnez ces politiques pour pouvoir expliquer des décisions prises sous d’anciens textes et réduire la dérive des règles.
Construire des aides à la décision, pas juste des boutons
Une bonne interface de décision guide le réviseur vers des issues complètes et défendables.
Utilisez des checklists par motif qui apparaissent automatiquement dans la vue dossier (ex. : « scan transporteur présent », « photo montre le dommage », « la fiche promet X »). Chaque item de checklist peut :
- Lier la preuve pertinente déjà présente dans le dossier
- Signaler les preuves requises manquantes avant de finaliser
- Ajouter un texte de justification template (« Livraison confirmée par le transporteur le… ») que le réviseur peut éditer
Cela crée une piste d’audit cohérente sans forcer tout le monde à rédiger depuis zéro.
Issues qui reflètent les montants réels
La décision doit calculer l’impact financier, pas le laisser aux tableurs. Stockez et affichez :
- Montant de remboursement (plein/partiel), devise et règles d’arrondi
- Frais (processeur, marketplace, frais de litige), coûts d’expédition, montants de restocking
- Risque attendu de rétrofacturation ou exposition (même sous forme de score simple)
Précisez si le système exécutera automatiquement le remboursement ou générera une tâche pour finance/support (surtout quand les paiements sont splittés ou partiellement capturés).
Appels : les autoriser mais les contrôler
Les appels réduisent la frustration quand de nouvelles infos apparaissent — mais peuvent devenir une boucle infinie.
Définissez : quand les appels sont permis, ce qu’est une preuve « nouvelle », qui révise (file/ réviseur différent si possible), et combien de tentatives sont autorisées. Sur appel, figez la décision initiale et créez un enregistrement d’appel lié pour distinguer le résultat initial du résultat final dans le reporting.
Expliquer les décisions aux deux parties
Chaque décision doit générer deux messages : un pour l’acheteur et un pour le vendeur. Utilisez un langage clair, listez les preuves clés prises en compte, et indiquez les étapes suivantes (y compris l’éligibilité à l’appel et les délais). Évitez le jargon et les reproches — concentrez-vous sur les faits et la politique.
Intégrations : commandes, paiements, expédition et outils de support
Les intégrations transforment un outil de litiges d’un « bloc-note » en un système qui peut vérifier les faits et exécuter en sécurité les issues. Commencez par lister les systèmes externes qui doivent s’accorder sur la réalité : gestion des commandes, paiements, transporteurs, et votre fournisseur e-mail/SMS.
Choisir la bonne stratégie de synchronisation (webhooks vs planifié)
Pour les changements sensibles au temps — alertes de rétrofacturation, statut de remboursement, ou mises à jour de ticket — préférez les webhooks. Ils réduisent le délai et gardent la chronologie exacte.
Utilisez la synchronisation planifiée quand les webhooks ne sont pas disponibles ou fiables (commun avec les transporteurs). Un hybride pratique :
- Webhooks pour paiements et événements internes de commande
- Polling pour les scans d’expédition et confirmations de livraison
Quoi que vous choisissiez, stockez le « dernier statut externe connu » sur le dossier et conservez le payload brut pour audit et debugging.
Idempotence : le rail de sécurité pour les mouvements d’argent
Les actions financières doivent être sûres en répétition. Les retries réseau, doubles clics et re‑livraisons de webhook peuvent déclencher des remboursements en double.
Rendez chaque appel impactant l’argent idempotent en :
- Générant une clé d’action unique par issue (ex.
case_id + decision_id + action_type)
- Persistant un enregistrement d’“integration action” avant d’appeler l’API du paiement
- Traitant les requêtes répétées avec la même clé comme un no-op (retourner le résultat original)
Ce même pattern s’applique aux remboursements partiels, annulations et reversals de frais.
Logs d’événements d’intégration pour support et debug
Quand quelque chose ne colle pas (remboursement « pending » ou scan de livraison manquant), votre équipe a besoin de visibilité. Loggez chaque événement d’intégration avec :
- Horodatage, fournisseur, endpoint/type d’événement
- Payloads de requête/réponse (redigez les champs sensibles)
- IDs de corrélation qui lient les événements à un dossier et entre eux
Exposez un onglet léger “Integration” dans la fiche du dossier pour que le support puisse se débrouiller seul.
Modes sandbox et test
Prévoyez des environnements sûrs dès le départ : sandbox du processeur de paiement, numéros de suivi test pour transporteurs (ou réponses mockées), et « destinataires test » pour e‑mail/SMS. Ajoutez une bannière visible “mode test” en non‑prod pour que QA ne déclenche jamais de vrais remboursements.
Si vous construisez des outils admin, documentez les credentials et scopes requis sur une page interne comme /docs/integrations pour rendre la configuration reproductible.
Choix d’architecture pour maintenir l’app
Un système de gestion des litiges grossit vite. Vous ajouterez uploads de preuves, recherches de paiements, rappels, et reporting — l’architecture doit rester conventionnelle et modulaire.
Choisissez une stack que votre équipe peut livrer
Pour la v1, priorisez ce que votre équipe connaît déjà. Un setup classique (React/Vue + API REST/GraphQL + Postgres) est souvent plus rapide à livrer que d’expérimenter de nouveaux frameworks. L’objectif est une livraison prévisible, pas la nouveauté.
Si vous voulez accélérer la première itération sans vous enfermer dans une boîte noire, une plateforme comme Koder.ai peut aider à générer une base React + Go + PostgreSQL à partir d’un spec écrit, tout en gardant l’option d’exporter le code source.
Séparer les responsabilités dès le départ
Gardez des frontières claires entre :
- Frontend : dashboard admin et vues acheteurs/vendeurs
- API : logique métier, permissions, validations, piste d’audit
- Jobs background : notifications, exports, traitement des preuves, intégrations
- Stockage de fichiers : les preuves doivent vivre hors base de données (object storage), avec la métadonnée en table
Cette séparation facilite la montée en charge de parties spécifiques (ex. jobs background) sans récrire toute l’application.
Utiliser une queue pour le travail longue durée
La collecte et la vérification des preuves impliquent souvent antivirus, OCR, conversions de fichiers, et appels externes. Les exports et rappels planifiés peuvent aussi être lourds. Placez ces tâches derrière une file pour que l’UI reste réactive et que les utilisateurs n’aient pas à resoumettre.
Les files de dossiers vivent et meurent par la recherche. Concevez pour filtrer par statut, SLA/délais, méthode de paiement, flags de risque, et agent assigné. Ajoutez des index tôt, et envisagez la recherche en texte intégral seulement si l’indexation de base ne suffit pas. Prévoyez la pagination et les “vues sauvegardées”.
Environnements, déploiements et rollbacks
Définissez staging et production dès le départ, avec des données seed qui reflètent des scénarios réels (flux de rétrofacturation, automation de remboursement, appels). Utilisez des migrations versionnées, feature flags pour les changements risqués, et un plan de rollback pour déployer souvent sans casser les dossiers actifs.
Si votre équipe veut itérer rapidement, des fonctionnalités comme les snapshots et rollback (disponibles sur certaines plateformes comme Koder.ai) peuvent compléter les contrôles de release traditionnels — surtout quand workflows et permissions évoluent.
Reporting, analytics et amélioration continue
Déployez avec retour arrière prêt
Hébergez votre application de litiges et publiez des mises à jour avec captures d'état et retour arrière lorsque les politiques changent.
Un système de litiges s’améliore quand vous voyez rapidement ce qui se passe au travers des dossiers. Le reporting n’est pas seulement pour les dirigeants ; il aide les agents à prioriser, les managers à détecter les risques opérationnels, et l’entreprise à ajuster les politiques avant que les coûts n’augmentent.
Commencez par les metrics qui changent les décisions
Suivez un petit ensemble de KPIs actionnables :
- Temps de résolution (moyenne et p90), ventilé par motif et segment vendeur
- Taille du backlog et tranches d’ancienneté (0–2 jours, 3–7, 8+)
- Taux de gain pour rétrofacturations et appels, par méthode de paiement et type de preuve
- Totaux des remboursements et taux de remboursement, plus remboursements évitables (lacunes de politique)
- Répétiteurs (acheteurs et vendeurs), avec seuils et tendances
Dashboards pour agents vs managers
Les agents ont besoin d’une vue opérationnelle : « Que dois‑je traiter ensuite ? » Construisez un dashboard style file qui met en avant les SLA en risque, les délais imminents, et les dossiers « preuves manquantes ».
Les managers ont besoin de détection de patterns : pics d’un motif particulier, vendeurs à risque, totaux de remboursement inhabituels, et chute du taux de gain après un changement de politique. Une vue simple semaine‑par‑semaine bat souvent une page de graphiques surchargée.
Exports sans fuite de données sensibles
Supportez les exports CSV et rapports planifiés, mais mettez des garde‑fous :
- Permissions d’export selon rôle
- Redaction par colonne (PII, identifiants de paiement)
- Logs d’audit pour qui a exporté quoi et quand
L’analytics ne marche que si les dossiers sont étiquetés de manière cohérente. Utilisez des codes de motif contrôlés, des tags optionnels (libres mais normalisés), et des invites de validation quand un agent ferme un dossier avec « Other ».
Considérez le reporting comme une boucle de rétroaction : examinez les principales causes de perte chaque mois, ajustez les checklists de preuve, affinez les seuils d’auto‑remboursement, et documentez les changements pour que les améliorations apparaissent dans les cohortes futures.
Tests, checklist de lancement et préparation opérationnelle
Livrer un système de litiges n’est pas tant une question de polissage UI que de savoir qu’il se comporte correctement sous contrainte : preuves manquantes, réponses tardives, cas limites de paiement, et contrôle d’accès strict.
Tester le cycle complet du dossier (et les chemins moches)
Écrivez des cas de test qui suivent des flux réels bout en bout : open → preuve demandée/reçue → décision → paiement/remboursement/hold. Incluez des chemins négatifs et des transitions basées sur le temps :
- Le vendeur ne répond jamais ; le délai expire et le dossier avance automatiquement.
- La preuve arrive après le délai ; vérifiez comment elle est marquée et si elle est admissible.
- Remboursements partiels, envois fractionnés, plusieurs articles dans une commande.
- Retries pour opérations idempotentes (ex. « remboursement déjà émis »).
Automatisez ces tests avec des tests d’intégration autour des APIs et jobs background ; gardez un petit jeu de scripts d’exploration manuelle pour la régression UI.
Permissions et données sensibles : testez comme un attaquant
Les échecs de contrôle d’accès ont fort impact. Construisez une matrice de tests de permissions pour chaque rôle (acheteur, vendeur, agent, superviseur, finance, admin) et vérifiez :
- Qui peut voir/éditer les preuves, PII, et notes internes
- Règles champ par champ (masquage, restrictions de téléchargement, redaction)
- Exhaustivité de la piste d’audit : chaque changement de décision, chaque remboursement, chaque export sensible
Monitoring, alertes et « si ça casse ?»
Les apps de litiges reposent sur des jobs et intégrations (commandes, paiements, expédition). Ajoutez du monitoring pour :
- Jobs background échoués, dossiers bloqués, triggers de délai manquants
- Erreurs d’intégration et échecs de webhook, avec seuils d’alerte
- Pics inhabituels (échecs de remboursement, erreurs d’upload, backlog de queue)
Runbook + déploiement par phases
Préparez un runbook interne couvrant les problèmes courants, voies d’escalade, et actions manuelles (réouvrir un dossier, prolonger un délai, corriger/annuler un remboursement, re‑demander une preuve). Puis déployez par phases :
- Pilote avec une petite équipe et types de litiges limités.
- Augmenter le volume, puis activer progressivement les règles automatiques.
- Collecter le feedback des agents chaque semaine et ajuster les workflows avant de monter en charge.
Quand vous itérez rapidement, un « planning mode » structuré (comme proposé par Koder.ai) peut aider à aligner les parties prenantes sur états, rôles et intégrations avant de pousser des changements en production.