03 sept. 2025·8 min
Comment créer une application web pour gérer les permissions entre produits
Apprenez à concevoir et construire une application web qui centralise rôles, groupes et permissions sur plusieurs produits, avec audits, SSO et déploiement sûr.
Problème à résoudre et critères de succès
Quand on dit qu'il faut gérer des permissions sur « plusieurs produits », cela signifie généralement l'une des trois situations suivantes :
- Applications séparées (par ex. facturation, analytics, support) qui ont chacune développé leur propre système d'utilisateurs et de rôles.
- Modules au sein d'une même plateforme qui se comportent comme des produits séparés (données, actions et équipes distinctes).
- Tenants ou workspaces où le même produit est répété pour différents clients, régions ou unités business.
Dans tous les cas, le problème racine est le même : les décisions d'accès sont prises à trop d'endroits, avec trop de définitions contradictoires de rôles comme « Admin », « Manager » ou « Lecture seule ».
Les problèmes les plus fréquents
Les équipes ressentent généralement la casse avant de pouvoir la nommer précisément.
Rôles et politiques incohérents. L’“Éditeur” d’un produit peut supprimer des enregistrements ; celui d’un autre ne le peut pas. Les utilisateurs demandent trop d'accès parce qu'ils ne savent pas ce dont ils auront besoin.
Provisioning et déprovisioning manuels. Les changements d'accès se font via des messages Slack ad hoc, des spreadsheets ou des tickets. Le offboarding est particulièrement risqué : un utilisateur perd l'accès dans un outil mais le conserve dans un autre.
Propriété floue. Personne ne sait qui peut approuver un accès, qui doit le revoir, ni qui est responsable lorsqu'une erreur de permission cause un incident.
À quoi ressemble le succès
Une bonne appli de gestion des permissions n'est pas juste un panneau de contrôle — c'est un système qui crée de la clarté.
Admin central avec définitions cohérentes. Les rôles sont compréhensibles, réutilisables et se mappent proprement entre produits (ou au moins rendent explicites les différences).
Self-service avec garde‑fous. Les utilisateurs peuvent demander des accès sans courir après la bonne personne, tandis que les permissions sensibles exigent toujours des approbations.
Flux d'approbation et responsabilité. Chaque changement a un propriétaire : qui l'a demandé, qui l'a approuvé, et pourquoi.
Auditabilité par défaut. Vous pouvez répondre à « qui avait accès à quoi, quand ? » sans reconstituer des logs venant de cinq systèmes.
Indicateurs qui prouvent que ça marche
Suivez des résultats qui reflètent rapidité et sécurité :
- Temps pour accorder un accès (médiane et 95e percentile)
- Moins de tickets support liés à l'accès (« Je ne vois pas X », « Ajoutez-moi à Y »)
- Moins d'incidents liés aux accès (surtitres d'accès, déprovisionning manqué)
- Taux de complétion des revues pour la recertification périodique des accès (si vous l'ajoutez)
Si vous rendez les changements d'accès plus rapides et plus prévisibles, vous êtes sur la bonne voie.
Checklist d'exigences et périmètre
Avant de concevoir des rôles ou de choisir une stack technique, clarifiez ce que votre appli doit couvrir au jour 1 — et ce qu'elle n'abordera pas. Un périmètre serré évite de tout reconstruire en cours de route.
1) Inventoriez les produits à intégrer en premier
Commencez par une petite liste (souvent 1–3 produits) et notez comment chacun exprime actuellement l'accès :
- Utilise-t-il des rôles, des groupes, des attributions par ressource, ou des flags
is_admin? - Les permissions sont-elles globales (au niveau produit) ou liées à des entités (projets, workspaces, comptes) ?
- Où les permissions sont-elles appliquées aujourd'hui (frontend, backend, les deux) ?
Si deux produits ont des modèles fondamentalement différents, notez-le tôt — vous pourriez avoir besoin d'une couche de traduction plutôt que de les forcer dans une seule forme immédiatement.
2) Identifiez les types d'utilisateurs et les réalités opérationnelles
Votre système de permissions doit gérer autre chose que « utilisateurs finaux ». Définissez au minimum :
- Admins internes et support (souvent besoin d'accès larges et temporaires)
- Admins clients et utilisateurs réguliers
- Partenaires / revendeurs (peuvent couvrir plusieurs comptes clients)
- Comptes de service et clients API (l'automatisation nécessite un accès stable et au moindre privilège)
Capturez les cas limites : contractors, comptes de boîte partagée, et utilisateurs appartenant à plusieurs organisations.
3) Décidez quelles actions nécessitent des checks de permission
Listez les actions qui importent pour le business et les utilisateurs. Catégories communes :
- Voir vs modifier (lecture/écriture)
- Facturation et changements d'abonnement
- Gestion des utilisateurs (inviter, désactiver, réinitialiser MFA)
- Actions administratives à haut risque (export de données, rotation de clés, suppressions destructrices)
Écrivez-les comme des verbes liés à des objets (par ex. “edit workspace settings”), pas des étiquettes vagues.
4) Documentez les sources de vérité et la propriété
Clarifiez d'où proviennent les identités et attributs :
- HRIS pour les employés, CRM pour les clients, annuaires existants pour les groupes SSO
- Bases produit pour l'appartenance et les ressources
Pour chaque source, décidez ce que votre appli de permissions possédera vs. ce qu'elle reflétera, et comment les conflits sont résolus.
Choisir une architecture : centralisée, fédérée ou hybride
La première grande décision est où l'autorisation "vit". Ce choix façonne votre effort d'intégration, l'expérience admin et la capacité à faire évoluer les permissions en toute sécurité.
Option 1 : Centraliser (un service d'autorisation)
Avec un modèle centralisé, un service d'autorisation dédié évalue l'accès pour tous les produits. Les produits l'appellent (ou valident des décisions émises centralement) avant d'autoriser des actions.
C'est attractif quand vous avez besoin d'un comportement de politique cohérent, de rôles cross-produit et d'un endroit unique pour auditer les changements. Le coût principal est l'intégration : chaque produit dépendra de la disponibilité, de la latence et du format de décision du service partagé.
Option 2 : Fédérer (chaque produit gère ses règles)
Dans un modèle fédéré, chaque produit implémente et évalue ses propres permissions. Votre « app de gestion » se charge principalement des workflows d'assignation puis synchronise le résultat vers chaque produit.
Cela maximise l'autonomie produit et réduit les dépendances d'exécution partagées. L'inconvénient est la dérive : noms, sémantiques et cas limites peuvent diverger, rendant l'administration cross-produit plus difficile et le reporting moins fiable.
Option 3 : Hybride (plan de contrôle + application locale)
Un compromis pratique est de traiter le gestionnaire de permissions comme un control plane (console d'administration unique), tandis que les produits restent points d'application.
Vous maintenez un catalogue de permissions partagé pour les concepts qui doivent correspondre entre produits (ex. “Billing Admin”, “Read Reports”), tout en laissant de la place pour des permissions spécifiques produit où les équipes ont besoin de flexibilité. Les produits récupèrent ou reçoivent les mises à jour (rôles, attributions, mappings de groupe) et appliquent localement.
Arbitrages clés à décider dès le départ
- Vitesse d'intégration : l'évaluation centralisée peut être plus simple à standardiser, mais plus coûteuse à intégrer dans des systèmes legacy ; la synchronisation fédérée peut démarrer petit mais prend plus de temps à normaliser.
- Autonomie : fédéré/hybride permet aux équipes produit de livrer indépendamment ; centralisé exige une coordination plus serrée.
- Risque de breaking changes : un catalogue partagé et une API de décision demandent du versioning et de la compatibilité ascendante, sinon une modification peut impacter plusieurs produits.
Si vous prévoyez une croissance fréquente des produits, l'hybride est souvent le meilleur point de départ : il offre une console admin unique sans forcer chaque produit à utiliser le même moteur d'autorisation à l'exécution dès le jour 1.
Concevoir le modèle de permissions (RBAC d'abord, puis ABAC)
Un système de permissions réussit ou échoue selon son modèle de données. Commencez simple avec RBAC (role-based access control) pour que ce soit facile à expliquer, administrer et auditer. N'ajoutez des attributs (ABAC) que lorsque RBAC devient trop grossier.
Entités de base nécessaires
Au minimum, modélisez explicitement ces concepts :
- Users : les personnes (ou comptes de service) demandant l'accès.
- Groups : collections d'utilisateurs (équipe, département, owners d'environnement).
- Products : les apps/services que vous contrôlez.
- Resources : éléments à l'intérieur d'un produit (projet, workspace, repo, compte client).
- Permissions : actions atomiques (par ex.
project.read,project.write,billing.manage). - Roles : ensembles nommés de permissions.
Un pattern pratique : les attributions de rôle lient un principal (user ou group) à un rôle dans un scope (au niveau produit, au niveau ressource, ou les deux).
RBAC d'abord : faites des rôles votre interface principale
Définissez des rôles par produit afin que le vocabulaire de chaque produit reste clair (par ex. “Analyst” dans le Produit A n'est pas forcé d'être identique à “Analyst” dans le Produit B).
Ajoutez ensuite des templates de rôle : rôles standardisés réutilisables entre tenants, environnements ou comptes clients. Par dessus, créez des bundles pour les fonctions métiers communes à plusieurs produits (ex. “Support Agent bundle” = rôles dans Produit A + Produit B + Produit C). Les bundles réduisent le travail admin sans tout fusionner en un méga-rôle.
Moindre privilège : évitez « admin = tout »
Faites en sorte que l'expérience par défaut soit sûre :
- Les nouveaux utilisateurs commencent sans accès (ou avec un rôle minimal “Viewer”).
- Traitez “Admin” comme scopé (admin d'un produit, d'un workspace ou d'un tenant), pas comme un mode dieu global.
- Préférez des permissions séparées à haut risque comme
billing.manage,user.invite, etaudit.exportplutôt que de les cacher sous « admin ».
Quand ajouter ABAC (attributs)
Ajoutez ABAC lorsque vous avez besoin de règles du type « peut voir les tickets seulement pour sa région » ou « peut déployer seulement en staging ». Utilisez des attributs pour des contraintes (région, environnement, classification des données), tout en gardant RBAC comme principal instrument de raisonnement humain sur l'accès.
Si vous voulez un guide plus approfondi sur le nommage et le scope des rôles, renvoyez vers vos docs internes ou une page de référence comme /docs/authorization-model.
Identité, authentification et stratégie de tokens
Votre appli de permissions se situe entre les personnes, les produits et les politiques — vous avez donc besoin d'un plan clair pour comment chaque requête identifie qui agit, quel produit demande et quelles permissions s'appliquent.
Comment les produits s'identifient
Traitez chaque produit (et environnement) comme un client avec sa propre identité :
- Client IDs + secrets / API keys pour les intégrations côté serveur. Faites-les tourner régulièrement et scopez-les aux APIs spécifiques.
- mTLS pour le trafic interne de haute confiance : le produit présente un certificat client et vous le validez au niveau de la passerelle.
Quel que soit votre choix, loggez l'identité du produit sur chaque événement d'autorisation / audit pour pouvoir répondre à « quel système a fait la demande ? » ultérieurement.
Comment les utilisateurs se connectent et comment fonctionnent les sessions
Supportez deux points d'entrée :
- Email / mot de passe (uniquement si nécessaire) : protégez avec MFA, limitation de taux et checks de compromission.
- SSO (SAML / OIDC) : préféré pour les entreprises car le cycle de vie des utilisateurs et le MFA vivent dans l'IdP du client.
Pour les sessions, utilisez des tokens d'accès de courte durée plus un mécanisme serveur de refresh token avec rotation. Gardez la déconnexion et la révocation de session prévisibles (surtout pour les admins).
Stratégie de tokens : claims JWT vs introspection
Deux patterns courants :
- JWT avec claims de permissions : validation rapide hors ligne, mais les permissions peuvent vieillir jusqu'à l'expiration du token.
- Introspection / lookup : les produits appellent votre service auth (ou mettent en cache brièvement). Plus à jour et plus facile à révoquer, mais ajoute de la latence et demande une haute disponibilité.
Un hybride pratique : le JWT contient identité + tenant + rôles, et les produits appellent un endpoint pour obtenir des permissions fines quand nécessaire.
Identités non‑humaines et service‑to‑service
Ne réutilisez pas les tokens utilisateurs pour les jobs background. Créez des comptes de service avec des scopes explicites (moindre privilège), émettez des tokens client-credentials, et séparez-les clairement dans les logs d'audit des actions humaines.
API et pattern d'intégration pour plusieurs produits
Mettez en place des approbations et des garde-fous
Implémentez des demandes et étapes d'approbation encadrées pour que les changements d'accès aient une responsabilité claire.
Une appli de permissions ne fonctionne que si chaque produit peut poser les mêmes questions et obtenir des réponses cohérentes. L'objectif est de définir un petit ensemble d'APIs stables que chaque produit intègre une fois, puis réutilise à mesure que votre portefeuille grandit.
Définir les APIs « noyau stable »
Concentrez les endpoints sur les opérations que chaque produit nécessite :
- Check access : « L'utilisateur X peut-il faire l'action Y sur la ressource Z ? » (chemin critique)
- Liste des droits : « Quels rôles/permissions a l'utilisateur X dans le produit P ? »
- Grant / revoke : actions admin et flux de provisioning automatisés
- Export d'audit : « Qu'est‑ce qui a changé, quand, par qui, et pourquoi ? »
Évitez la logique spécifique produit dans ces endpoints. Standardisez sur un vocabulaire partagé : subject (user/service), action, resource, scope (tenant/org/project), et context (attributs utilisables plus tard).
Choisir un pattern d'intégration par produit
La plupart des équipes finissent par combiner :
- Checks d'autorisation à l'exécution (sync) : Le produit appelle
POST /authz/check(ou utilise un SDK local) sur chaque requête sensible. - Application locale (réplication async) : Le produit maintient un modèle de lecture des droits pour un gating UI rapide et des décisions hors ligne.
Règle pratique : faites du check centralisé la source de vérité pour les actions à haut risque, et utilisez des données répliquées pour l'UX (menus, feature flags, badges « vous avez accès ») là où une obsolescence occasionnelle est acceptable.
Mises à jour pilotées par événements : garder les produits synchronisés
Quand les permissions changent, ne comptez pas sur chaque produit qui poll :
Publiez des événements comme role.granted, role.revoked, membership.changed, policy.updated vers une file ou des webhooks. Les produits s'abonnent et mettent à jour leurs caches / read models.
Concevez les événements pour qu'ils soient :
- Idempotents (sûrs à traiter plusieurs fois)
- Ordonnés par subject+tenant quand c'est possible
- Assez auto-descriptifs pour reconstruire l'état (ou fournissez un endpoint “fetch current state” pour la réconciliation)
Caching et invalidation pour des checks rapides
Les checks d'accès doivent être rapides, mais le cache peut créer des failles si l'invalidation est faible.
Pattern courant :
- Cachez les résultats allow/deny brièvement (secondes) indexés par subject/action/resource/scope.
- Cachez les snapshots d'entitlements (rôles, appartenance aux groupes) plus longtemps, mais invalidez agressivement sur événements.
Si vous utilisez des JWTs avec rôles embarqués, gardez des durées courtes et combinez avec des stratégies de révocation côté serveur (ou une claim de « token version ») pour que les révocations se propagent rapidement.
Versioning et compatibilité ascendante
Les permissions évoluent avec les produits. Anticipez :
- Versionnez les contrats d'API (
/v1/authz/check) et les schémas d'événements. - Traitez les permissions comme additives quand c'est possible (introduisez de nouvelles actions plutôt que de changer leur sens).
- Dépérez avec calendrier et métriques : mesurez quels produits appellent encore les endpoints anciens.
Un petit investissement en compatibilité empêche le système de permissions de devenir le goulot d'étranglement pour sortir de nouvelles fonctionnalités produit.
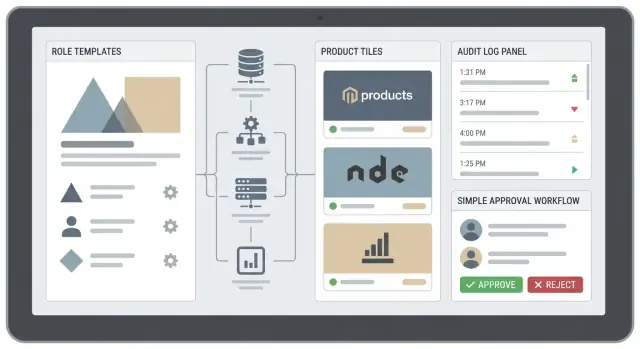
Construire l'UX admin et self‑service
Un système de permissions peut être techniquement correct et quand même échouer si les admins ne peuvent pas répondre : « Qui a accès à quoi, et pourquoi ? » Votre UX doit réduire l'incertitude, empêcher les sur-attributions accidentelles, et rendre les tâches fréquentes rapides.
Écrans de console admin essentiels
Commencez par un petit ensemble de pages couvrant 80 % des opérations quotidiennes :
- Recherche d'utilisateur : chercher par nom, email, employee ID ou identité externe. Montrer un résumé clair : produits, rôles, groupes, et « dernier changement par ».
- Attribution de rôle : un flux unique et cohérent pour ajouter/enlever des rôles across produits. Incluez des dates effectives si vous supportez l'accès time‑boxed.
- Gestion des groupes : créer des groupes (équipes, départements, projets) et assigner des rôles aux groupes pour éviter des maintenances utilisateur‑par‑utilisateur.
Sur chaque rôle, incluez un explicatif en langage courant : « Ce rôle permet de » plus des exemples concrets (« Peut approuver des factures jusqu'à 10k » est mieux que « invoice:write »). Liez vers des docs plus détaillés si besoin (ex. /help/roles).
Opérations en masse sans catastrophes
Les outils bulk économisent du temps mais amplifient les erreurs — sécurisez-les par design :
- Import/export CSV pour l'onboarding ou les audits, avec validation stricte et template téléchargeable.
- Changements massifs de rôles avec étape de revue : montrez un diff (« + Billing Admin, − Viewer ») avant l'application.
- Revues programmées d'accès : laissez les admins planifier une revue, notifier les reviewers et suivre la complétion.
Ajoutez des garde‑fous comme le “dry run”, des limites de débit et des instructions claires de rollback si l'import se passe mal.
Un workflow d'approbation simple
Beaucoup d'organisations ont besoin d'un processus léger :
Request → Approve → Provision → Notify
Les demandes doivent capturer le contexte business (« nécessaire pour la clôture Q4 ») et la durée. Les approbations doivent être conscientes du rôle et du produit (le bon approbateur pour la bonne chose). Le provisioning doit générer une entrée d'audit et notifier demandeur et approbateur.
Accessibilité et clarté
Utilisez un nommage cohérent, évitez les acronymes dans l'UI et ajoutez des avertissements en ligne (« Cela donne accès aux PII du client »). Assurez la navigation au clavier, un contraste lisible et des états vides clairs (« Aucun rôle attribué — ajoutez-en un pour activer l'accès »).
Audit, reporting et bases compliance
Créer une application pilote de permissions
Prototypez une application d'administration des permissions plus rapidement avec un générateur React, Go et Postgres piloté par chat.
L'audit fait la différence entre « on pense que l'accès est correct » et « on peut le prouver ». Lorsque votre appli gère les permissions across produits, chaque changement doit être traçable — surtout les grants de rôle, les edits de politique et les actions admin.
Ce que doit capturer votre journal d'audit
Au minimum, loggez qui a changé quoi, quand, d'où et pourquoi :
- Acteur : user ID, admin ID, compte de service, ou automatisation (inclure l'impersonateur si on agit “au nom de”).
- Action + objet : ex. « a assigné le template de rôle X », « a révoqué l'accès au produit Y », « a modifié la politique Z », incluant les valeurs avant/après.
- Timestamp : en UTC avec précision milliseconde.
- Source : adresse IP, user agent, device/session ID, et le produit/UI/API utilisé.
- Raison : champ obligatoire pour les actions sensibles (assignation d'admin, édition de template, désactivation MFA, etc.).
Immutabilité, rétention et export SIEM
Traitez les événements d'audit comme append-only. N'autorisez pas les mises à jour ou suppressions via le code applicatif ; si des corrections sont nécessaires, écrivez un événement compensateur.
Définissez la rétention selon le risque et la régulation : beaucoup d'équipes conservent des logs « chauds » pour 30–90 jours et archivage pour 1–7 ans. Facilitez l'export : livraison planifiée (daily) et options de streaming vers des outils SIEM. Au minimum, supportez l'export en newline-delimited JSON et incluez des IDs stables pour dé‑dupliquer.
Détecter tôt les comportements à risque
Construisez des détecteurs simples qui signalent :
- Escalade de privilèges (saut brusque vers des rôles à hauts privilèges, nouveaux admins globaux, élargissement de politique)
- Activité admin inhabituelle (heures hors norme, nombreux changements en peu de temps, changements sur plusieurs tenants/produits)
- Patterns d'accès suspects (nouvelle IP/géographie, erreurs admin répétées)
Affichez ces alertes dans une vue « Activité admin » et envoyez éventuellement des notifications.
Rapports demandés par les parties prenantes
Rendez le reporting pratique et exportable :
- Accès par produit (qui a quoi, groupé par template de rôle et tenant)
- Comptes dormants (pas de login ou d'usage produit depuis N jours, mais toujours provisionnés)
- Utilisateurs à haut privilège (admins globaux, éditeurs de politique, comptes break‑glass) avec timestamp du dernier usage
Si vous ajoutez plus tard des workflows d'approbation, liez les événements d'audit à l'ID de la demande pour accélérer les revues compliance.
Contrôles de sécurité et modes de défaillance courants
Une appli de gestion des permissions est elle‑même une cible de grande valeur : une mauvaise décision peut ouvrir un accès large à travers tous les produits. Traitez la surface admin et les checks d'autorisation comme des systèmes de « tier‑0 ».
Empêcher l'escalade de privilèges
Commencez par le moindre privilège et rendez l'escalade volontairement difficile :
- Séparation des tâches : séparez les rôles pour qu'aucune personne ne puisse à la fois accorder l'accès et approuver les changements sensibles (ex. “Role Editor” vs “Role Approver”).
- Rôles protégés : marquez les rôles break‑glass/admin comme templates immuables (ne peuvent pas être édités, seulement assignés). Exigez une vérification renforcée et une approbation supplémentaire pour les assigner.
- Règle à deux personnes pour les actions à risque : assignation d'un rôle protégé, élargissement d'un template ou changement des règles d'évaluation doivent requérir une approbation secondaire et être entièrement loggés.
Mode de défaillance courant : un « role editor » modifie le rôle admin, puis se l'assigne.
Durcir les endpoints admin
Les APIs admin ne doivent pas être aussi exposées que les APIs utilisateur :
- Limitation de taux sur les endpoints de mutation role/permission pour réduire force brute et abus.
- Allowlists IP (ou accès réseau privé) pour les actions admin quand c'est possible.
- Defaults sécurisés : refuser par défaut, exiger des grants explicites, et éviter les permissions wildcard temporaires qui ne sont jamais supprimées.
Mode de défaillance courant : un endpoint de commodité (ex. « grant all for support ») est déployé sans garde‑fous.
Protéger les secrets et les sessions
- Utilisez un vrai secrets manager (pas des variables d'environnement en clair disséminées).
- Chiffrez en transit (TLS partout) et chiffrez au repos pour les données de politique, les logs d'audit et toute PII.
- Verrouillez les cookies :
HttpOnly,Secure,SameSite, durées de session courtes, et protection CSRF pour les flows navigateur.
Mode de défaillance courant : fuite d'identifiants de service permettant des écritures de politique.
Testez l'autorisation sérieusement
Les bugs d'autorisation sont souvent des scénarios « deny manquant » :
- Écrivez des tests négatifs (« l'utilisateur ne doit PAS accéder à X »).
- Maintenez une matrice de tests de rôles (roles × actions × resources) pour attraper les accès non voulus quand les templates changent.
- Ajoutez des tests de régression pour les incidents et cas limites rapportés (utilisateurs supprimés, tokens périmés, accès cross‑tenant).
Plan de déploiement : pilote, migration et extension
Un système de permissions n'est jamais « fini » à la mise en production — vous gagnez la confiance en le déployant progressivement. L'objectif est de prouver que les décisions d'accès sont correctes, que le support peut résoudre rapidement les incidents, et que vous pouvez rollback sans casser les équipes.
1) Piloter avec un produit (end‑to‑end)
Commencez avec un produit qui a des rôles clairs et des utilisateurs actifs. Mappez ses rôles/groupes actuels en un petit ensemble de rôles canoniques dans votre nouveau système, puis construisez un adaptateur qui traduit les « nouvelles permissions » vers ce que le produit applique aujourd'hui (scopes API, feature toggles, flags en base, etc.).
Pendant le pilote, validez la boucle complète :
- Un admin change une attribution de rôle
- Le produit reçoit la mise à jour (push ou pull)
- Les vrais utilisateurs peuvent se connecter et effectuer les actions attendues
- Les événements d'audit capturent qui a changé quoi et quand
Définissez les métriques de succès : moins de tickets support liés à l'accès, aucun incident critique de sur‑permission, et temps de révocation mesuré en minutes.
2) Migrer les données soigneusement (et réversiblement)
Les permissions legacy sont souvent un bazar. Prévoyez une étape de traduction qui convertit les groupes existants, exceptions ad‑hoc et rôles produits en nouveau modèle. Conservez une table de mapping pour pouvoir expliquer chaque attribution migrée.
Faites un dry run en staging, puis migrez par vagues (par organisation, région ou tier client). Pour les clients délicats, migrez en mode « shadow » pour comparer anciennes et nouvelles décisions avant d'enforcer.
3) Utiliser feature flags et déploiement phasé
Les feature flags vous permettent de séparer le chemin d'écriture du chemin d'application. Phases typiques :
- UI en lecture seule (reporting seulement)
- Écritures activées, pas d'application (sync uniquement)
- Application partielle (actions spécifiques)
- Application complète
Si quelque chose tourne mal, vous pouvez désactiver l'enforcement tout en gardant la visibilité d'audit.
4) Runbooks pour le support et les révocations d'urgence
Documentez des runbooks pour les incidents courants : utilisateur sans accès, utilisateur avec trop d'accès, erreur admin, révocation d'urgence. Incluez qui est on‑call, où regarder les logs, comment vérifier les permissions effectives, et comment réaliser un « break‑glass » qui se propage rapidement.
Une fois le pilote stable, répétez le même playbook produit par produit. Chaque nouveau produit doit ressembler à un travail d'intégration, pas à une réinvention du modèle de permissions.
Notes d'implémentation : stack tech et opérations
Des modifications plus sûres avec restauration
Prenez des instantanés avant les changements de modèles de rôles et restaurez rapidement si quelque chose casse.
Vous n'avez pas besoin d'une techno exotique pour livrer une appli de gestion des permissions solide. Priorisez la correction, la prévisibilité et l'opérabilité — puis optimisez.
Une stack pratique et peu exotique
Un baseline courant :
- API service : Node.js (NestJS / Fastify) ou Go (Gin / chi)
- Base de données : Postgres (consistance forte et bons index pour les requêtes de politique)
- Cache : Redis (cache des expansions de rôles, configs tenant, et décisions "can user X do Y")
- Queue : file Redis (BullMQ) ou service managé (SQS / Pub/Sub)
Gardez la logique de décision d'autorisation dans un seul service / librairie pour éviter que les produits divergent de comportement.
Si vous voulez prototyper rapidement une console admin et des APIs (surtout pour un pilote), des plateformes low-code peuvent vous aider à livrer l'UI React, un backend Go + PostgreSQL et le scaffolding pour logs d'audit et approbations — mais la logique d'autorisation nécessite une revue rigoureuse même si le scaffolding accélère le temps jusqu'au pilote.
Jobs background (provisioning et sync)
Les systèmes de permissions accumulent vite du travail asynchrone qui ne doit pas bloquer les requêtes utilisateur :
- Import/sync des utilisateurs et groupes depuis IdPs externes
- Provision des droits vers les produits downstream
- Recalcul des grants dérivés après modification de templates
- Checks périodiques de cohérence (par ex. attributions orphelines)
Rendez les jobs idempotents et retryables, et stockez leur statut par tenant pour la supportabilité.
Opérations : observabilité utile
Au minimum, instrumentez :
- Logs : logs structurés avec request ID, tenant ID, actor ID et résultat de décision
- Métriques : latence des autorisations, taux d'erreur, hit rate cache, temps de requête DB
- Traces : parcours end‑to‑end pour « permission check » et « admin change »
Alertez sur les pics de deny-by-error (ex. timeouts DB) et sur la p95/p99 de latence des checks de permission.
Test de charge et vérifications de capacité
Avant le déploiement, testez le endpoint permission-check avec des patterns réalistes :
- Hot keys (même user/projet vérifié fréquemment)
- Mix reads/writes (mises à jour admin pendant le trafic)
- Tailles de tenant variées
Suivez le throughput, la p95 de latence et le hit rate Redis ; vérifiez que les performances dégradent progressivement quand le cache est froid.
Fonctionnalités avancées : SSO, SCIM et support multi‑tenant
Une fois le modèle de permissions core en place, quelques fonctionnalités « enterprise » rendent le système beaucoup plus facile à opérer à grande échelle — sans changer la manière dont les produits appliquent l'accès.
SSO : SAML / OIDC et mapping des groupes IdP vers des rôles
Le SSO signifie généralement SAML 2.0 (IdPs legacy) ou OpenID Connect (OIDC) (stacks modernes). La décision clé est : que faites‑vous confiance venant de l'IdP ?
Pattern pratique : acceptez l'identité et l'appartenance à des groupes haut‑niveau depuis l'IdP, puis mappez ces groupes à vos role templates internes par tenant. Par ex. le groupe IdP Acme-App-Admins mappe au rôle Workspace Admin dans le tenant acme. Gardez ce mapping explicite et éditable par les admins tenant, pas hardcodé.
Évitez d'utiliser les groupes IdP comme permissions directes. Les groupes changent pour des raisons organisationnelles ; vos rôles doivent rester stables. Considérez l'IdP comme source de « qui est l'utilisateur » et « dans quel groupe org il est », pas comme source de « ce qu'il peut faire dans chaque produit ».
SCIM pour automatiser le cycle de vie des utilisateurs
SCIM permet aux clients d'automatiser le cycle de vie des comptes : créer des utilisateurs, désactiver des utilisateurs, et synchroniser les groupes depuis l'IdP. Cela réduit les invitations manuelles et comble les lacunes de sécurité au départ.
Conseils d'implémentation :
- Traitez la désactivation comme un événement de première classe (révoquez immédiatement sessions/tokens et retirez l'accès produit).
- Faites du sync de groupes un processus idempotent et auditable : les mises à jour SCIM doivent se traduire en changements déterministes d'attributions de rôle.
Support multi‑tenant : isolation et frontières admin
Le contrôle d'accès multi‑tenant doit appliquer la séparation des tenants partout : identifiants dans les tokens, filtres de ligne DB, clés de cache et logs d'audit.
Définissez des frontières admin claires : les admins tenant gèrent les utilisateurs et rôles uniquement dans leur tenant ; les admins plateforme peuvent dépanner sans s'octroyer par défaut un accès produit.
Pour des guides d'implémentation plus approfondis et des options de packaging, voir /blog. Si vous décidez quelles fonctionnalités vont dans quel plan, alignez‑les avec /pricing.
FAQ
Quelle est la meilleure façon de cadrer une application de gestion des permissions pour le jour 1 ?
Commencez par lister 1 à 3 produits à intégrer en priorité et documentez, pour chacun :
- La forme actuelle d'autorisation (rôles / groupes / attributions par ressource / flags)
- La portée (global vs workspace / projet / compte)
- Où les contrôles sont effectués aujourd'hui (frontend, backend, ou les deux)
Si les modèles diffèrent fortement, prévoyez une couche de traduction plutôt que d'imposer un unique modèle immédiatement.
L'autorisation doit-elle être centralisée, fédérée ou hybride entre les produits ?
Choisissez selon l'endroit où vous voulez que les décisions de politique soient évaluées :
- Centralisé : un service d'autorisation unique évalue les décisions pour tous les produits (meilleure cohérence ; dépendance d'exécution plus forte).
- Fédéré : chaque produit évalue localement ; l'app de gestion se contente d'assigner / synchroniser des droits (meilleure autonomie ; plus de dérive possible).
- Hybride : plan de contrôle partagé (catalogue + admin) et application locale des règles dans les produits (souvent le meilleur point de départ pour du legacy et de la croissance).
Si vous prévoyez plusieurs produits et des changements fréquents, l'hybride est généralement le choix le plus sûr par défaut.
Quel modèle de données devrais-je commencer à utiliser pour des permissions cross-produit ?
Un socle pratique est RBAC avec ces entités explicites :
- Utilisateurs (et comptes de service)
- Groupes
- Produits
- Ressources (workspace / projet / compte)
- Permissions (actions atomiques comme
billing.manage) - Rôles (ensembles de permissions)
Stockez ensuite les comme : afin de pouvoir raisonner sur « qui a quoi, où ».
Quand devrais-je ajouter de l'ABAC (attributs) au lieu de me limiter au RBAC ?
Considérez RBAC comme l'interface lisible par les humains et n'introduisez ABAC que pour les contraintes que RBAC n'exprime pas proprement.
Utilisez ABAC pour des règles comme :
- « Peut voir les tickets seulement pour sa région »
- « Peut déployer seulement en staging »
Limitez les attributs à un petit ensemble (région, environnement, classification des données) et documentez-les, tandis que les rôles restent le principal moyen d'assigner l'accès.
En quoi les modèles de rôle et les bundles aident-ils à gérer les permissions sur plusieurs produits ?
Évitez le mega-rôle unique en superposant :
- Rôles produit : vocabulaire clair et spécifique à chaque produit.
- Modèles de rôle (role templates) : rôles réutilisables entre tenants/environnements.
- Bundles : paquets par fonction métier qui assignent plusieurs rôles dans plusieurs produits (par ex. bundle Support).
Cela réduit le travail d'administration sans masquer les différences importantes entre les sémantiques de permissions des produits.
Quelle stratégie de tokens fonctionne le mieux pour les checks de permissions (JWT vs introspection) ?
Concevez autour de deux patterns de décision :
- JWT avec claims : rapide et validation hors ligne, mais peut devenir obsolète jusqu'à l'expiration du token.
- Introspection / lookup : à jour et plus simple à révoquer, mais ajoute de la latence et exige une haute disponibilité.
Un compromis courant : JWT contenant identité + tenant + rôles, et les produits appellent un endpoint de vérification pour les actions à risque ou fines. Gardez des durées de token courtes et une stratégie de révocation pour les suppressions urgentes.
Quelles sont les API minimales qu'un système de permissions multi-produit devrait exposer ?
Conservez un « noyau stable » minimal que chaque produit peut implémenter :
POST /authz/check(hot path)- Liste des droits (rôles/permissions d'un utilisateur par produit)
- Grant/revoke (administration + automatisation)
- Export d'audit
Standardisez le vocabulaire : , , , (tenant/org/workspace) et (attributs optionnels). Évitez la logique spécifique produit dans ces endpoints de base.
Comment faire pour que les produits restent synchronisés quand des rôles ou politiques changent ?
Utilisez des événements pour que les produits n'aient pas à poller. Publiez des changements comme :
role.granted/role.revokedmembership.changedpolicy.updated
Rendez les événements , si possible, et soit (a) assez auto-descriptifs pour mettre à jour l'état local, soit (b) accompagnés d'un endpoint "fetch current state" pour réconciliation.
Que doit inclure l'UX admin / self-service pour prévenir le sur‑octroi de permissions ?
Incluez écrans et garde-fous qui réduisent les erreurs :
- Recherche d'utilisateur avec résumé clair « accès effectif » et « dernier changement par »
- Flux d'attribution de rôle cohérent entre produits, avec possibilité d'accès limité dans le temps
- Gestion des groupes pour éviter les assignations utilisateur-par-utilisateur
- Outils bulk avec étape de diff/revue, « dry run » et validation CSV stricte
Ajoutez des explications en langage naturel pour chaque rôle et des avertissements pour les accès sensibles (PII, facturation).
Que doit contenir un journal d'audit pour une appli de gestion des permissions ?
Consignez chaque changement sensible en append-only avec suffisamment de contexte pour répondre à « qui avait accès à quoi, quand et pourquoi ? »
Capturez au minimum :
- L'acteur (et l'impersonateur si applicable)
- L'action + l'objet avec avant/après
- Horodatage UTC (haute précision)
- La source (IP, user agent, session/appareil, UI/API)
- Un champ « raison » pour les opérations sensibles
Supportez l'export (par ex. newline-delimited JSON), la conservation longue durée et des IDs stables pour la déduplication vers des SIEM.