Comment construire une application web pour gérer les permissions des outils internes
Guide pas à pas pour concevoir et construire une application web de gestion des accès aux outils internes avec rôles, approbations, journaux d’audit et opérations sécurisées.
Définir le problème et le périmètre
Avant de choisir des rôles RBAC ou de commencer à concevoir des écrans, soyez précis sur ce que « permissions des outils internes » signifie dans votre organisation. Pour certaines équipes, c’est un simple « qui peut accéder à quelle appli » ; pour d’autres, cela inclut des actions fines dans chaque outil, des élévations temporaires et des preuves d’audit.
Qu’est-ce qui compte comme permission ?
Écrivez les actions exactes que vous devez contrôler, en utilisant des verbes qui correspondent à la manière dont les gens travaillent :
- View (accès en lecture aux tableaux de bord, tickets, dossiers clients)
- Edit (modifier des configurations, mettre à jour des données, clore des demandes)
- Admin (gérer les utilisateurs, modifier la facturation, changer les réglages de sécurité)
- Export (télécharger des rapports, extraire des données clients, accès API)
Cette liste devient la base de votre application de gestion d’accès : elle détermine ce que vous stockez, ce que vous approuvez et ce que vous auditez.
Inventaire des outils et où l’application s’applique
Faites l’inventaire des systèmes et outils internes : applications SaaS, panneaux d’administration internes, entrepôts de données, dossiers partagés, CI/CD et toute feuille de calcul « shadow admin ». Pour chacun, notez si l’application des permissions se fait :
- À l’intérieur de l’outil (rôles natifs)
- Au niveau de votre passerelle (reverse proxy, couche API)
- Par processus (étapes manuelles, identifiants partagés)
Si l’application est « par processus », c’est un risque que vous devriez soit supprimer, soit accepter explicitement.
Parties prenantes et métriques de succès
Identifiez les décideurs et les opérateurs : IT, sécurité/conformité, chefs d’équipe et utilisateurs finaux qui demandent l’accès. Mettez-vous d’accord sur des métriques de succès mesurables :
- Temps médian pour accorder l’accès
- Nombre d’incidents liés aux permissions
- Pourcentage d’accès avec un propriétaire et une justification métier
- Préparation à l’audit (pouvez-vous répondre « qui avait accès à quoi, quand et pourquoi ? »)
Bien définir le périmètre évite de construire un système de permissions trop complexe à gérer — ou trop simple pour assurer le moindre privilège.
Choisir votre modèle d’autorisation (rôles, politiques et exceptions)
Votre modèle d’autorisation est la « forme » de votre système de permissions. Bien le définir tôt simplifie tout le reste — UI, approbations, audits et application.
Commencez par le modèle le plus simple qui survive à la réalité
La plupart des outils internes peuvent commencer avec le contrôle d’accès basé sur les rôles (RBAC) :
- Rôles simples : les utilisateurs ont un ou plusieurs rôles (ex. Viewer, Operator, Admin).
- Rôle + overrides : les rôles couvrent 90% des cas, plus un petit ensemble d’octrois/cessions explicites par utilisateur.
- Règles basées sur des attributs (ABAC) : les permissions dépendent d’attributs comme le département, la localisation, la sensibilité des données ou l’environnement.
Le RBAC est le plus simple à expliquer et à relire. Ajoutez des overrides seulement lorsque vous constatez des demandes « cas spéciaux » fréquentes. Passez à l’ABAC quand vous avez des règles cohérentes qui feraient exploser votre nombre de rôles (ex. « accès à l’outil X uniquement pour leur région »).
Faire du moindre privilège la valeur par défaut
Concevez les rôles pour que le comportement par défaut soit l’accès minimal :
- Commencez par « pas d’accès » ou « lecture seule » par défaut.
- Séparez « peut voir » de « peut modifier » (et « peut approuver » de « peut demander »).
- Évitez les rôles « Admin » qui contiennent tout ; rendez les actions à fort impact visibles.
Décider ce qui est global vs spécifique à un outil
Définissez les permissions à deux niveaux :
- Permissions globales : capacités à l’échelle de l’organisation comme “gérer les utilisateurs”, “voir les journaux d’audit” ou “approuver l’accès”.
- Permissions spécifiques aux outils : actions à l’intérieur de chaque outil (ex. déployer, modifier des configs, voir des secrets).
Cela empêche les besoins d’un outil d’imposer la même structure de rôles à tous les autres.
Prévoir les exceptions sans casser le modèle
Les exceptions sont inévitables ; formalisez-les :
- Accès temporaire : octrois limités dans le temps qui expirent automatiquement.
- Break-glass admin : rôle d’urgence avec protections supplémentaires (durée limitée, raison obligatoire, journalisation renforcée).
Si les exceptions deviennent courantes, c’est le signe qu’il faut ajuster les rôles ou introduire des règles politiques — sans laisser des « cas uniques » devenir des privilèges permanents et non relus.
Concevoir le modèle de données
Une application de permissions vit ou meurt par son modèle de données. Si vous ne pouvez pas répondre rapidement et de façon cohérente à « qui a accès à quoi, et pourquoi ? », toutes les autres fonctionnalités (approbations, audits, UI) deviennent fragiles.
Entités de base (gardez-les explicites)
Commencez par un petit ensemble de tables/collections qui correspondent clairement aux concepts réels :
- Users (personnes nécessitant un accès)
- Teams (groupes pour lesquels vous gérez l’accès)
- Tools/Apps (ce à quoi l’accès est accordé)
- Roles (ensembles nommés comme “Billing Admin”)
- Permissions (capacités fines comme
export_invoices) - Assignments (le fait qu’un utilisateur/une équipe ait un rôle pour un outil spécifique)
Les rôles ne doivent pas « flotter » globalement sans contexte. Dans la plupart des environnements internes, un rôle a du sens uniquement au sein d’un outil (ex. “Admin” dans Jira vs “Admin” dans AWS).
Relations et règles d’héritage
Attendez-vous à des relations plusieurs-à-plusieurs :
- Un utilisateur peut appartenir à plusieurs équipes, et une équipe a plusieurs utilisateurs.
- Un rôle contient plusieurs permissions, et une permission peut appartenir à plusieurs rôles.
- Une assignation lie typiquement : (sujet = utilisateur ou équipe) → (rôle) → (outil/app).
Si vous supportez l’héritage basé sur les équipes, décidez de la règle dès le départ : accès effectif = assignations directes utilisateur plus assignations d’équipe, avec un traitement clair des conflits (ex. « deny bat quand allow » si vous modélisez des refus).
Champs de cycle de vie qui facilitent les audits
Ajoutez des champs qui expliquent les changements dans le temps :
created_by(qui l’a accordé)expires_at(accès temporaire)disabled_at(désactivation douce sans perdre l’historique)
Ces champs vous aident à répondre à « cet accès était-il valide mardi dernier ? » — critique pour les enquêtes et la conformité.
Indexation pour des vérifications rapides
Votre requête la plus fréquente est souvent : « L’utilisateur X a-t-il la permission Y dans l’outil Z ? » Indexez les assignations par (user_id, tool_id), et pré-calculer les « permissions effectives » si les vérifications doivent être instantanées. Gardez les chemins d’écriture simples, mais optimisez les chemins de lecture quand l’application en dépend.
Authentification et intégration SSO
L’authentification est la manière dont les personnes prouvent leur identité. Pour une application de permissions interne, l’objectif est de rendre la connexion simple pour les employés tout en protégeant fortement les actions d’administration.
Choisir la méthode de connexion
Vous avez typiquement trois options :
- SSO (recommandé pour la plupart des entreprises) : connexion via l’identité corporate (Google Workspace, Microsoft Entra ID/ADFS, Okta, Ping).
- Lien magique par e‑mail (passwordless) : l’utilisateur entre son e‑mail et reçoit un lien valide sur une courte durée. Simple à gérer, mais plus faible si la sécurité de la boîte mail varie.
- Mots de passe : généralement en dernier recours pour les outils internes en raison de la surcharge de réinitialisation et des politiques.
Si vous supportez plusieurs méthodes, choisissez-en une par défaut et traitez les autres comme exceptions explicites — sinon les admins auront du mal à prédire la création des comptes.
Intégration SAML ou OIDC (SSO)
La plupart des intégrations modernes utilisent OIDC ; beaucoup d’entreprises exigent encore SAML.
- OIDC : validez un ID token, mappez un identifiant utilisateur stable (subject/issuer) et lisez éventuellement les claims de groupes/rôles.
- SAML : validez des assertions signées, mappez le NameID (ou un attribut dédié) et gérez la rotation des métadonnées/certs.
Indépendamment du protocole, décidez de ce que vous faites confiance de la part de l’IdP :
- Identité seulement (qui est l’utilisateur), votre appli stocke les permissions.
- Identité + groupes (qui est l’utilisateur et à quels groupes il appartient), ce qui peut auto-assigner des rôles de base.
Sessions : expiration, refresh et confiance périphérique
Définissez les règles de session dès le départ :
- Session courte (ex. 8–12 heures) avec demande de ré-auth. claire.
- Stratégie de refresh : refresh silencieux via l’IdP (OIDC) ou re-login après expiration (plus simple, plus sûr).
- Confiance appareil : souvenir d’un appareil pour les actions à faible risque, mais exiger la ré-auth pour les changements admin. Suivez les sessions par appareil pour que les admins puissent les révoquer.
MFA pour les actions admin sensibles
Même si l’IdP impose la MFA au login, ajoutez une authentification renforcée (step-up) pour les actions à fort impact comme accorder des droits admin, modifier les règles d’approbation ou exporter des journaux d’audit. Concrètement, vérifiez « MFA effectuée récemment » (ou forcez la ré-auth) avant d’exécuter l’action.
Flux de demande et d’approbation des accès
Une application de permissions réussit ou échoue sur une chose : permettre aux gens d’obtenir l’accès dont ils ont besoin sans créer de risques invisibles. Un workflow clair de demande et d’approbation maintient l’accès cohérent, relu et facile à auditer ultérieurement.
Flux de base : demande → décision → attribution
Commencez par un chemin simple et reproductible :
- L’utilisateur demande l’accès à un outil spécifique, un environnement (prod vs staging) et un ensemble de permissions.
- Les approbateurs examinent la demande (avec le contexte : justification métier, durée).
- Le système accorde l’accès automatiquement après approbation (ou crée une tâche admin si l’automatisation n’est pas possible).
- L’utilisateur est notifié, et l’octroi est enregistré dans le journal d’audit.
Gardez les demandes structurées : évitez le « donnez-moi admin » en texte libre. Faites choisir un rôle/préconfiguration et demandez une courte justification.
Qui peut approuver quoi
Définissez les règles d’approbation pour éviter les débats :
- Approbation du manager : confirme que la demande correspond aux responsabilités du poste.
- Approbation du propriétaire de l’application : confirme que le niveau de permission est approprié pour l’outil (et souvent pour l’environnement).
- Approbation sécurité : réservée aux accès à fort impact (rôles admin, écriture en production, données sensibles).
Utilisez une politique comme « manager + propriétaire d’app » pour l’accès standard, et ajoutez la sécurité pour les rôles privilégiés.
Accès limité dans le temps avec expiration automatique
Par défaut, préférez l’accès limité dans le temps (ex. 7–30 jours) et autorisez « jusqu’à révocation » seulement pour une courte liste de rôles stables. L’expiration doit être automatique : le workflow qui accorde l’accès doit aussi planifier la suppression et notifier l’utilisateur avant la fin.
Accès urgent sans perdre le contrôle
Soutenez un chemin « urgent » pour la gestion d’incidents, mais ajoutez des garde-fous :
- Demande d’un code raison (ticket d’incident, référence d’interruption)
- Durée par défaut plus courte (heures, pas jours)
- Journalisation et alertes supplémentaires vers les propriétaires d’app et la sécurité
Ainsi, l’accès rapide n’est pas un accès invisible.
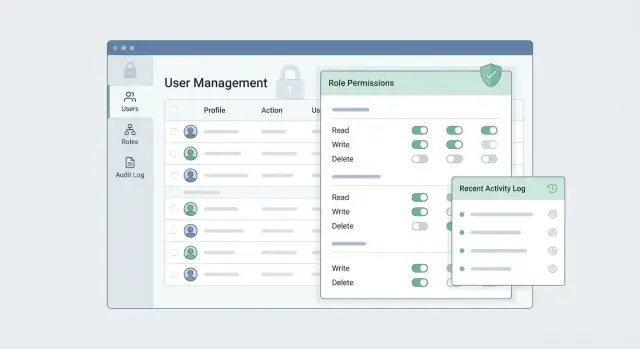
UX du tableau de bord admin qui prévient les erreurs
Votre tableau de bord admin est l’endroit où un clic peut accorder l’accès à la paie ou révoquer des droits en production. Une bonne UX traite chaque changement de permission comme une modification à hauts enjeux : claire, réversible et facile à relire.
Commencez par une mise en page orientée admin
Utilisez une navigation qui correspond à la pensée des admins :
- Users : qui a accès et pourquoi
- Roles : ensembles réutilisables de permissions
- Apps/Resources : ce qui peut être accédé
- Requests : approbations en attente et historique
- Audit : qui a changé quoi et quand
Cette organisation réduit les erreurs « où aller ? » et rend plus difficile la modification du mauvais élément au mauvais endroit.
Rendre les permissions lisibles (pas seulement techniquement correctes)
Les noms de permissions doivent être d’abord en langage courant, détail technique ensuite. Par exemple :
- “View invoices” (scope : Billing → Invoices:read)
- “Deploy to production” (scope : CI/CD → prod:deploy)
Affichez l’impact d’un rôle dans un résumé court (« Donne accès à 12 ressources, y compris Production ») et liez au détail complet.
Ajouter des garde‑fous pour les actions risquées
Utilisez la friction volontairement :
- Aperçu avant application : “Ceci ajoutera 3 permissions et en supprimera 1.”
- Dialogues de confirmation pour les scopes sensibles (prod, finance, RH)
- Modifications en masse : requérir un aperçu CSV, mettre en évidence les lignes invalides et demander une case « Je comprends »
- Rollback facile : « Revert this change » depuis la page de détail du changement
Optimiser pour les grandes organisations
Les admins ont besoin de vitesse sans sacrifier la sécurité. Incluez recherche, filtres (app, rôle, département, statut) et pagination partout où vous listez Users, Roles, Requests et Audit. Conservez l’état des filtres dans l’URL pour partager et répéter les pages.
Couche d’application : comment les permissions sont réellement vérifiées
La couche d’application est l’endroit où votre modèle de permissions devient concret. Elle doit être ennuyeuse, cohérente et difficile à contourner.
Une seule fonction de vérification de permission, partout
Créez une fonction unique (ou un petit module) qui répond à la question : “L’utilisateur X peut‑il faire l’action Y sur la ressource Z ?” Toute interface, handler d’API, job background et outil admin doit l’appeler.
Cela évite les ré‑implémentations approximatives qui divergent avec le temps. Gardez les entrées explicites (user id, action, resource type/id, contexte) et les sorties strictes (allow/deny plus une raison pour audit).
Protéger routes et API (pas seulement l’UI)
Cacher des boutons n’est pas une sécurité. Faites appliquer les permissions côté serveur pour :
- Chaque endpoint API (y compris endpoints internes/admin)
- Chaque route server-rendered
- Les tâches background (exports, synchronisations, jobs planifiés)
Un bon pattern est un middleware qui charge le sujet (ressource), appelle la fonction de vérification des permissions et échoue fermé (403) si la décision est « deny ». Si une UI appelle /api/reports/export, l’endpoint d’export doit appliquer la même règle même si l’UI désactive déjà le bouton.
Mettre en cache prudemment pour que les décisions restent à jour
Le cache des décisions peut améliorer les performances, mais il peut aussi maintenir un accès après un changement de rôle.
Préférez mettre en cache des entrées qui changent lentement (définitions de rôles, règles politiques) et conservez des caches de décisions à courte durée. Invalidez les caches lors d’événements comme les mises à jour de rôle, les changements d’assignation utilisateur ou la déprovision. Si vous devez mettre en cache les décisions par utilisateur, ajoutez un compteur de « version des permissions » sur l’utilisateur et incrémentez‑le à chaque changement.
Pièges courants à éviter
Évitez :
- Admin implicite : « isEmployee=true » ou « a créé l’espace » donnant tout silencieusement
- Endpoints oubliés : anciennes routes v1, exports CSV, webhooks, champs GraphQL, outils internes
- Lacunes « deny » : absence de politique = allow. Le défaut doit être deny sauf autorisation explicite
Si vous voulez une implémentation de référence concrète, documentez-la et liez-la depuis votre runbook d’ingénierie (ex. /docs/authorization) pour que les nouveaux endpoints suivent la même voie d’application.
Journaux d’audit et reporting
Les journaux d’audit sont votre « système de reçus » pour les permissions. Quand quelqu’un demande « pourquoi Alex a accès à la paie ? », vous devez pouvoir répondre en quelques minutes — sans deviner ni fouiller dans des chats.
Que journaliser (et comment le rendre utile)
Pour chaque changement de permission, enregistrez qui a changé quoi, quand et pourquoi. Le « pourquoi » ne doit pas être uniquement du texte libre ; il doit rattacher au workflow qui a justifié le changement.
Au minimum, capturez :
- L’acteur (admin/service), l’utilisateur ou groupe cible, et la ressource (outil, environnement, dataset)
- Ancienne valeur → nouvelle valeur (ex.
Finance-Read→Finance-Admin) - Horodatage (UTC) et source (UI, API, job automatisé)
- Request ID et approval ID (ou ticket ID) pour rejouer la chaîne de décision
- Optionnel : justification métier, date d’expiration et la politique qui l’a permis
Utilisez un schéma d’événement cohérent pour que le reporting soit fiable. Même si l’UI change, l’histoire d’audit reste lisible.
Journaliser les lectures de données sensibles
Toutes les lectures ne nécessitent pas un enregistrement, mais l’accès aux données à haut risque souvent oui. Exemples : détails de paie, exports de PII clients, vues de clés API, ou actions « download all ».
Rendez la journalisation des lectures pratique :
- Journalisez des événements, pas des payloads entiers (évitez de stocker des valeurs sensibles dans les logs)
- Capturez les identifiants de ressource, les filtres utilisés et le volume si pertinent (ex. « exporté 2 431 lignes »)
- Utilisez l’échantillonnage seulement si la conformité le permet — et documentez ce choix
Reporting et exports (avec garde‑fous)
Fournissez des rapports de base réellement utiles aux admins : « permissions par personne », « qui peut accéder à X » et « changements des 30 derniers jours ». Incluez des options d’export (CSV/JSON) pour les auditeurs, mais traitez les exports comme sensibles :
- Exiger une permission explicite pour exporter les données d’audit
- Filigraner les exports avec qui les a générés et quand
- Journaliser l’événement d’export (filtres et format de fichier inclus)
Rétention et qui peut voir les traces d’audit
Définissez la rétention dès le départ (par ex. 1–7 ans selon les besoins réglementaires) et séparez les devoirs :
- Seul un jeu limité de rôles peut voir les logs d’audit
- Supportez un accès auditeur en lecture seule
- Rendez les logs append-only et évidents à altérer (stockage immuable ou chaînes d’événements signées)
Si vous ajoutez une zone « Audit » dans l’UI admin, liez‑la depuis /admin avec des avertissements clairs et une approche « recherche d’abord ».
Cycle de vie utilisateur et provisioning
Les permissions dérivent quand les personnes rejoignent, changent d’équipe, sont en congé ou quittent l’entreprise. Une application solide de gestion d’accès traite le cycle de vie utilisateur comme une fonctionnalité de première classe, pas comme une réflexion de fin.
Provisioning : comment de nouveaux utilisateurs obtiennent le bon accès
Commencez par une source de vérité claire pour l’identité : votre système RH, votre IdP (Okta, Azure AD, Google) ou les deux. Votre appli doit pouvoir :
- Créer un enregistrement utilisateur automatiquement quand un employé apparaît dans l’IdP.
- Assigner un accès de base en moindre privilège (ex. rôle « Employee » + rôles spécifiques à l’équipe).
Si votre IdP supporte SCIM, utilisez‑le. SCIM permet de synchroniser automatiquement utilisateurs, groupes et statuts dans votre appli, réduisant le travail manuel et évitant les « ghost users ». Si SCIM n’est pas dispo, planifiez des imports périodiques (API ou CSV) et exigez des relectures par les propriétaires pour les exceptions.
Changements de rôle : gérer les mouvements d’équipe sans chaos
Les changements d’équipe sont souvent là où les permissions se compliquent. Modélisez « équipe » comme un attribut géré (sync depuis HR/IdP), et traitez les assignations de rôles comme des règles dérivées quand c’est possible (ex. « Si department = Finance, accorder le rôle Finance Analyst »).
Quand quelqu’un change d’équipe, votre appli devrait :
- Retirer automatiquement les rôles basés sur l’ancienne équipe.
- Préserver les exceptions approuvées explicitement (et les signaler pour ré-approbation).
Déprovisionnement : offboarding rapide sur tous les outils
Le offboarding doit révoquer l’accès rapidement et de façon prévisible. Déclenchez le déprovisionnement depuis l’IdP (désactiver l’utilisateur) et faites en sorte que votre appli :
- Révoque les sessions actives et les tokens API.
- Retire les droits d’accès aux outils et notifie les propriétaires d’outils.
Si votre appli provisionne aussi des accès vers des outils en aval, mettez ces suppressions en file d’attente et affichez les échecs dans le dashboard admin pour que rien ne traîne inaperçu.
Contrôles de sécurité et vérifications des menaces
Une appli de permissions est une cible attractive car elle peut accorder l’accès à de nombreux systèmes internes. La sécurité n’est pas une fonctionnalité unique : c’est un ensemble de petits contrôles cohérents qui réduisent la probabilité qu’un attaquant (ou un admin pressé) fasse des dégâts.
Valider les entrées et bloquer les attaques web courantes
Traitez chaque champ de formulaire, paramètre de requête et payload API comme non fiable.
- Validez types et valeurs autorisées (ex. noms de rôles à partir d’une liste fixe, pas du texte libre).
- Assainissez le texte utilisateur qui sera affiché ensuite pour prévenir les XSS.
- Utilisez la protection CSRF pour les sessions basées cookie, particulièrement sur les actions « grant/revoke ».
Mettez aussi des valeurs par défaut sûres dans l’UI : pré-sélectionnez « pas d’accès » et exigez une confirmation explicite pour les changements à fort impact.
Faire respecter l’autorisation côté serveur — à chaque fois
L’UI doit réduire les erreurs, mais ne peut pas être votre frontière de sécurité. Si un endpoint modifie des permissions ou révèle des données sensibles, il doit avoir une vérification d’autorisation côté serveur :
- Création/modification de rôles et politiques
- Attribution ou révocation d’accès, ou modification d’exceptions
- Consultation des journaux d’audit et des rapports
Traitez cela comme une règle d’ingénierie : aucun endpoint sensible ne part sans vérification d’autorisation et enregistrement d’un événement d’audit.
Limites de taux et contrôles d’abus
Les endpoints admin et les flux d’authentification sont souvent ciblés pour du brute force et de l’automatisation :
- Limitez le nombre de tentatives de connexion et de réinitialisations de mot de passe.
- Limitez les actions admin comme les grants/exports en masse.
- Ajoutez des alertes pour des pics suspects (ex. beaucoup de changements de permissions en peu de temps).
Quand c’est possible, exigez une vérification renforcée pour les actions risquées (ré-auth ou exigence d’approbation).
Secrets, chiffrement et moindre privilège
Stockez les secrets (secrets client SSO, tokens API) dans un gestionnaire de secrets dédié, pas dans le code source ou des fichiers de config.
- Chiffrez les données sensibles au repos et en transit (TLS partout).
- Utilisez des comptes BD et de service au moindre privilège : l’appli web ne doit avoir que les permissions minimales nécessaires.
- Séparez les identifiants « lecture » et « écriture » quand c’est pertinent, surtout pour le reporting et les exports d’audit.
Vérifications rapides de menace (à tester)
Effectuez régulièrement des vérifications pour :
- Escalade de privilège (un utilisateur s’accordant l’accès à lui‑même ou à son équipe)
- Problèmes IDOR (changer un ID dans une URL pour accéder aux données d’une autre équipe)
- Autorisation manquante sur des endpoints “internes”
- Valeurs par défaut dangereuses (nouvelles intégrations recevant automatiquement un large accès)
Ces contrôles sont peu coûteux et attrapent les façons les plus courantes dont les systèmes de permissions échouent.
Stratégie de tests pour les applications riches en permissions
Les bugs de permissions sont rarement des « l’app est cassée » — ce sont des « mauvaise personne peut faire la mauvaise chose ». Traitez les règles d’autorisation comme de la logique métier avec entrées claires et résultats attendus.
1) Tests unitaires des règles (feedback rapide)
Commencez par tester unitairement votre évaluateur de permissions (la fonction qui décide allow/deny). Rendez les tests lisibles en les nommant comme des scénarios.
- Testez les règles pour allow et deny, y compris les cas limites (ex. utilisateur suspendu, outil archivé, rôle supprimé en cours de session).
- Incluez les chemins d’exception : accès temporaire, break-glass admin, et « self-service mais nécessite approbation ».
Un bon pattern est un petit tableau de cas (état utilisateur, rôle, ressource, action → décision attendue) pour ajouter des règles sans réécrire la suite.
2) Tests d’intégration pour les parcours à haut risque
Les tests unitaires ne détecteront pas les erreurs d’intégration — comme un contrôleur omettant d’appeler la vérification d’autorisation. Ajoutez quelques tests d’intégration sur les flux critiques :
- Demande d’accès → approbation/refus → l’utilisateur obtient/perd l’accès
- Changement de rôle → effet immédiat sur l’accès
- Déprovisionnement d’un utilisateur → suppression d’accès partout
Ces tests doivent utiliser les mêmes endpoints que l’UI, en validant réponses API et changements en base.
3) Fixtures de test fiables
Créez des fixtures stables pour rôles, équipes, outils et utilisateurs exemples (employé, contractuel, admin). Versionnez‑les et partagez‑les entre suites pour que tout le monde teste contre la même définition de « Finance Admin » ou « Support Read-Only ».
4) Checklist de régression avant chaque release
Ajoutez une checklist légère pour les changements de permissions : nouveaux rôles, changement de rôle par défaut, migrations touchant des grants, et tout changement UI sur les écrans admin. Quand c’est possible, liez la checklist à votre process de release (ex. /blog/release-checklist).
Déploiement, monitoring et exploitation continue
Un système de permissions n’est jamais « prêt » une fois déployé. Le vrai test commence après le lancement : nouvelles équipes, outils qui changent, besoins d’accès urgents qui apparaissent aux pires moments. Traitez l’exploitation comme une partie du produit.
Planifiez vos environnements (dev, staging, production)
Isolez dev, staging et production — surtout leurs données. Staging doit refléter la configuration production (paramètres SSO, toggles politiques, feature flags), mais utiliser des groupes d’identité séparés et des comptes test non sensibles.
Pour les apps riches en permissions, séparez aussi :
- Journaux d’audit (pour que le bruit de test ne pollue pas la conformité)
- Workflows d’approbation (les approbations de staging ne devraient pas alerter de vrais approbateurs)
- Secrets et clés (ne réutilisez jamais les clés de signature production dans les environnements inférieurs)
Monitoring qui détecte tôt les problèmes de permissions
Surveillez les basiques (uptime, latence), et ajoutez des signaux spécifiques aux permissions :
- Échecs d’auth par type : session expirée vs erreur SSO vs permission manquante
- Pics de refus d’autorisation pour un outil/équipe (souvent un mapping de rôle cassé)
- Patterns suspects : demandes d’accès répétées, changements rapides de rôles, activité admin inhabituelle
Rendez les alertes actionnables : incluez l’utilisateur, l’outil, le rôle/politique évalué, l’ID de requête et un lien vers l’événement d’audit pertinent.
Runbooks : quoi faire à 2h du matin
Rédigez des runbooks courts pour les urgences courantes :
- Révoquer l’accès rapidement (désactiver l’utilisateur, supprimer bindings, invalider sessions)
- Restaurer le service (rollback d’un changement de politique, décider fail closed vs fail open, rotation de clés)
- Procédure outage SSO (accès break-glass avec approbation limitée dans le temps)
Gardez-les dans le repo et le wiki ops, et testez‑les lors d’exercices.
Avancer vite (sans sacrifier la gouvernance)
Si vous développez cela comme une nouvelle appli interne, le plus grand risque est de passer des mois sur l’infrastructure (flux auth, UI admin, tables d’audit, écrans demande) avant d’avoir validé le modèle avec de vraies équipes. Une approche pratique est de livrer une version minimale rapidement, puis la durcir avec politiques, journalisation et automatisation.
Une façon dont les équipes procèdent est d’utiliser Koder.ai, une plateforme vibe-coding qui permet de créer des applications web et backend via une interface conversationnelle. Pour les apps lourdes en permissions, elle est utile pour générer rapidement le dashboard admin initial, les flux demande/approbation et le modèle CRUD — tout en vous laissant le contrôle de l’architecture sous-jacente (souvent React côté web, Go + PostgreSQL côté backend) et la possibilité d’exporter le code source quand vous êtes prêt à entrer dans votre pipeline standard de revue et déploiement. À mesure que vos besoins grandissent, des fonctionnalités comme snapshots/rollback et un mode planning aident à itérer sur les règles d’autorisation plus sûrement.
Prochaines étapes
Si vous souhaitez une base plus claire pour la conception des rôles avant de monter en charge, voyez /blog/role-based-access-control-basics. Pour les options de packaging et de déploiement, consultez /pricing.
FAQ
Qu’est-ce qui compte comme « permission » dans une application d’accès aux outils internes ?
Une permission est une action spécifique que vous voulez contrôler, exprimée comme un verbe correspondant à la manière dont les gens travaillent — par exemple view, edit, admin ou export.
Une méthode pratique consiste à lister les actions par outil et environnement (prod vs staging), puis à standardiser les noms pour qu’ils soient faciles à relire et auditer.
Comment inventorier les outils et décider où les permissions doivent être appliquées ?
Faites l’inventaire de chaque système où l’accès a de l’importance — applications SaaS, panneaux d’administration internes, entrepôts de données, CI/CD, dossiers partagés et toute feuille de calcul « shadow admin ».
Pour chaque outil, notez où l’application des permissions se produit :
- À l’intérieur de l’outil (rôles natifs)
- Au niveau d’une passerelle (reverse proxy / couche API)
- Par processus (étapes manuelles / identifiants partagés)
Tout ce qui est appliqué « par processus » doit être considéré comme un risque explicite ou priorisé pour suppression.
Quelles métriques de succès devrions-nous utiliser pour la gestion des permissions internes ?
Suivez des métriques qui reflètent à la fois la rapidité et la sécurité :
- Temps médian pour accorder l’accès
- Incidents liés aux permissions
- % d’accès avec un propriétaire et une justification métier
- Préparation à l’audit : « qui a eu accès à quoi, quand et pourquoi ? »
Ces indicateurs vous permettent d’évaluer si le système améliore réellement les opérations et réduit les risques.
Quand dois-je utiliser RBAC vs RBAC avec overrides vs ABAC ?
Commencez par le modèle le plus simple qui résiste à la réalité :
- RBAC si la plupart des accès peuvent être exprimés par des rôles (Viewer/Operator/Admin)
- RBAC + overrides quand il y a des cas spéciaux occasionnels
- ABAC quand des règles basées sur des attributs (région/département/etc.) évitent une explosion du nombre de rôles
Choisissez l’approche la plus simple qui reste compréhensible en revue et en audit.
Comment rendre le moindre privilège par défaut sans ralentir les équipes ?
Faites du privilège minimum le comportement par défaut et exigez une attribution explicite pour tout accès supérieur :
- Partir de « pas d’accès » ou « lecture seule »
- Séparer « voir » de « modifier », et « demander » de « approuver »
- Éviter les rôles « Admin » qui donnent tout en silence ; rendre les actions à fort impact visibles
Le moindre privilège fonctionne bien quand il est simple à expliquer et à relire.
Quelle est la différence entre permissions globales et permissions spécifiques aux outils ?
Définissez des permissions globales pour les capacités à l’échelle de l’organisation (ex. : gérer les utilisateurs, approuver l’accès, consulter les logs d’audit) et des permissions spécifiques aux outils pour les actions à l’intérieur de chaque outil (ex. : déployer en prod, voir des secrets).
Cela évite qu’un outil complexifie la structure de rôles pour tous les autres.
Quel modèle de données faut-il pour répondre à « qui a accès à quoi, et pourquoi ? »
Au minimum, modélisez :
- Utilisateurs, Équipes
- Outils/Applications
- Rôles, Permissions
- Assignations (sujet → rôle → outil)
Ajoutez des champs de cycle de vie comme created_by, expires_at et disabled_at pour pouvoir répondre à des questions historiques (par ex. « cet accès était-il valide mardi dernier ? ») sans hésitation.
Comment devons-nous intégrer l’authentification et le SSO (OIDC vs SAML) ?
Privilégiez l’authentification via SSO pour les applications internes afin que les employés utilisent l’IdP corporate.
- OIDC est courant aujourd’hui (ID tokens + identifiants stables)
- SAML est toujours requis dans beaucoup d’entreprises (assertions signées + rotation des certificats/métadonnées)
Décidez si vous faites confiance à l’IdP pour l’identité seulement, ou pour l’identité + les groupes (pour assigner des accès de base automatiquement).
À quoi doit ressembler un workflow de demande et d’approbation d’accès ?
Utilisez un flux structuré : demande → décision → attribution → notification → audit.
Obligez la sélection de rôles/préconfigurations (pas de texte libre), demandez une courte justification métier et définissez des règles d’approbation telles que :
- Manager + propriétaire de l’application pour l’accès standard
- Ajouter la sécurité pour les rôles privilégiés / prod / sensibles
Par défaut, privilégiez l’accès limité dans le temps avec expiration automatique.
Que doit-on mettre dans les journaux d’audit, et qui doit y avoir accès ?
Consignez les changements en tant que piste append-only : qui a changé quoi, quand et pourquoi, incluant les anciennes → nouvelles valeurs et un lien vers la demande/l’approbation (ou le ticket) qui l’a justifié.
Aussi :
- Envisagez de logger les lectures pour les actions à haut risque (exports, vues de clés API)
- Traitez les exports d’audit comme sensibles (permission explicite, filigrane, événement d’export enregistré)
- Définissez une rétention (souvent 1–7 ans) et limitez qui peut voir les logs (des rôles auditeurs en lecture seule aident)