02 juin 2025·8 min
Créer une application web pour gérer les demandes de communication entre équipes
Apprenez à planifier, concevoir et construire une application web qui collecte, achemine et suit les demandes de communication entre équipes avec une responsabilité claire, des statuts et des SLA.
Définir le problème et le périmètre
Avant de construire quoi que ce soit, précisez exactement ce que vous cherchez à résoudre. « Communication entre équipes » peut couvrir tout, d'un message Slack rapide à une annonce de lancement produit complète. Si le périmètre est flou, l'application deviendra soit une poubelle à demandes, soit personne ne l'utilisera.
Qu'est-ce qu'une « demande de communication » ici ?
Rédigez une définition simple que l'on peut retenir, avec quelques exemples et non-exemples. Les types de demandes typiques incluent :
- Annonces destinées aux clients (maintenance, changements de politique)
- Approbations de réponses de support pour des cas sensibles
- Notes de version et changelogs
- Mises à jour pour l'équipe commerciale (nouveaux tarifs, positionnement)
- Déclarations revues par la direction ou le service juridique
Documentez aussi ce qui *n'*appartient pas (par ex. brainstorming ad hoc, mises à jour « FYI » générales, ou « peux-tu te rendre disponible pour un appel ? »). Une frontière nette évite que le système ne devienne une boîte de réception générique.
Qui est impliqué et quel rôle occupe-t-il ?
Listez les équipes qui interviennent sur les demandes et la responsabilité de chacune :
- Demandeur (soumet le besoin, fournit le contexte et les éléments)
- Approbatteur (confirme la priorité, les risques, la conformité et le message)
- Exécutant (rédige/produit le contenu, publie ou envoie)
- Relecteur (vérification finale de l'exactitude, du ton et de la marque)
Si un rôle varie selon le type de demande (par ex. le juridique seulement pour certains sujets), capturez-le maintenant — cela orientera plus tard les règles de routage.
Comment saurez‑vous que ça a fonctionné ?
Choisissez quelques résultats mesurables, par exemple :
- Moins de « des nouvelles ? » dans le chat
- Délai de traitement plus court entre la soumission et la publication
- Moins de demandes manquées ou dupliquées
Enfin, écrivez les points douloureux d'aujourd'hui en langage clair : propriété floue, informations manquantes, demandes de dernière minute, et demandes cachées dans les DM. Cela devient votre référence et votre justification pour le changement.
Cartographier le flux de travail et les user stories
Avant de construire, alignez les parties prenantes sur la façon dont une demande passe de « quelqu'un a besoin d'aide » à « travail livré ». Une carte de flux simple évite la complexité accidentelle et met en évidence où les passations cassent souvent.
User stories (restez spécifique)
Voici cinq histoires de départ que vous pouvez adapter :
- En tant que demandeur, je soumets un bref résumé et je vois immédiatement qui en est responsable et quand je peux attendre une date butoir.
- En tant que responsable triage, je peux valider rapidement la demande, poser une question de suivi ou la rejeter en donnant un motif clair.
- En tant qu'approbatteur, je peux examiner la demande, approuver/decliner, et laisser un commentaire qui devient partie du dossier.
- En tant que planificateur/éditeur, je peux placer le travail approuvé sur un calendrier, détecter les conflits, et confirmer la date de publication.
- En tant que partie prenante, je peux suivre le statut et les mises à jour sans courir après les gens dans le chat.
Cartographier le cycle de vie de la demande
Un cycle de vie courant pour une application de gestion de demandes de communication entre équipes ressemble à :
soumettre → triage → valider → planifier → publier → clôturer
Pour chaque étape, notez :
- Critères d'entrée (ce qui doit être vrai pour commencer)
- Propriétaire (personne ou rôle)
- Résultat attendu (ce que signifie « fait »)
- Sorties autorisées (avancer, retourner pour modification, rejeter)
Décisions configurables vs fixes
Rendez configurables : équipes, catégories, priorités, et questions d'intake par catégorie. Gardez fixes (au moins au départ) : les statuts principaux et la définition de “clos”. Trop de configurabilité tôt complique le reporting et la formation.
Étapes à risque élevé à concevoir soigneusement
Surveillez les points de défaillance : approbations qui stagnent, conflits de planification entre canaux, et revues conformité/juridique qui nécessitent une piste d'audit et une responsabilité stricte. Ces risques doivent directement façonner vos règles de workflow et transitions de statut.
Concevoir le formulaire d'intake (obtenir les bonnes infos dès le départ)
Une application de demandes ne fonctionne que si le formulaire d'intake capture systématiquement un brief exploitable. L'objectif n'est pas de tout demander, mais d'obtenir les bonnes informations pour que votre équipe ne passe pas des jours à courir après des précisions.
Commencez par le brief minimal viable
Gardez l'écran initial compact. Au minimum, collectez :
- Titre de la demande (résumé en une phrase)
- Description (ce dont vous avez besoin et pourquoi)
- Audience (qui doit recevoir ceci)
- Canal (email, in‑app, réseaux sociaux, presse, etc.)
- Date souhaitée (quand cela doit être diffusé)
- Pièces jointes (brouillon, créa, captures, notes juridiques)
Ajoutez un court texte d'aide sous chaque champ, par ex. : « Exemple d'audience : ‘Tous les clients US sur le plan Pro’. » Ces micro‑exemples réduisent les allers-retours plus efficacement que de longues consignes.
Ajoutez des champs utiles qui évitent la réécriture
Une fois les bases stabilisées, incluez des champs qui facilitent la priorisation et la coordination :
- Priorité (par ex. Faible/Moyenne/Élevée)
- Impact business (ce qui change si cela ne part pas)
- Liens (PRD, ticket Jira, analytics, doc marque)
- Parties prenantes (approbateur et personnes informées)
- Langue/région (si localisation ou règles régionales s'appliquent)
Utilisez des questions conditionnelles pour rester court et complet
La logique conditionnelle garde le formulaire léger. Exemples :
- Si Canal = Presse, demandez porte‑parole, date d'embargo, et liste médias.
- Si Audience inclut des clients, demandez critères de segmentation et préparation du support.
Validez la complétude (sans être pénible)
Appliquez des règles de validation claires : champs requis, date non antérieure à aujourd'hui, pièces jointes obligatoires pour priorité “Élevée”, et minimum de caractères pour la description.
Quand vous rejetez une soumission, renvoyez‑la avec une consigne spécifique (par ex. “Ajoutez l'audience cible et le lien vers le ticket source”), pour que les demandeurs intègrent le standard attendu au fil du temps.
Créer des statuts, la propriété et des règles claires
Une application de gestion des demandes ne fonctionne que si tout le monde fait confiance au statut. Cela signifie que l'appli doit être la source unique de vérité — pas un « vrai statut » caché dans des conversations annexes, DM ou threads d'email.
Définir un ensemble de statuts simple et partagé
Gardez les statuts peu nombreux, non ambigus, et liés à des actions. Un ensemble par défaut pratique pour les demandes de communication entre équipes est :
- Nouveau — soumis et en attente de triage
- Informations manquantes — bloqué tant que le demandeur n'a pas fourni les détails
- En revue — en cours d'évaluation (faisabilité, priorité, politique)
- Approuvé — accepté et prêt à être planifié
- Planifié — assigné à une date/heure ou à un sprint
- Terminé — livré et clos
- Refusé — décliné avec un motif enregistré
L'important est que chaque statut réponde : Quelle est la prochaine étape, et qui attend quoi ?
Assigner des propriétaires par étape (pour que rien ne flotte)
Chaque statut doit avoir un « propriétaire » clair :
- Responsable triage (souvent en rotation) veille à ce que chaque demande Nouveau soit traitée rapidement.
- Approbatteur prend la décision go/no‑go pendant En revue.
- Assigné prend la responsabilité de la livraison une fois Approuvé/Planifié.
La responsabilité évite le mode d'échec courant où tout le monde est « impliqué » mais personne n'est responsable.
Rédiger des règles qui empêchent le chaos des statuts
Ajoutez des règles légères directement dans l'appli :
- Qui peut déplacer une demande (par ex. seul le triage peut sortir de Nouveau ; seuls les approbateurs peuvent définir Approuvé/Refusé).
- Quand elle peut être rouverte (par ex. permettre la réouverture depuis Terminé seulement dans les 14 jours, et exiger un motif).
- Ce qui est requis par transition (par ex. passer à Planifié nécessite une date ; passer à Refusé nécessite une justification).
Ces règles gardent le reporting exact, réduisent les allers‑retours et rendent les passations entre équipes prévisibles.
Planifier le modèle de données et les champs clés
Un modèle de données clair garde votre système de demandes flexible à mesure que de nouvelles équipes, types de demandes et étapes d'approbation apparaissent. Visez un petit nombre de tables centrales pouvant supporter de nombreux workflows, plutôt que de créer un schéma par équipe.
Tables cœur (commencez simple)
Au minimum, prévoyez :
- Utilisateurs : nom, email, rôle, indicateur actif
- Équipes : nom de l'équipe, politique SLA par défaut, règles de routage
- Demandes : le « ticket » en lui‑même (détails ci‑dessous)
- Commentaires : discussion filée liée à une demande
- Pièces jointes : fichiers ou liens, avec uploader et horodatage
- HistoriqueStatut : chaque changement de statut (et idéalement les changements de propriétaires aussi)
Cette structure facilite les passations entre équipes et rend le reporting bien plus simple que de compter sur l'« état courant seulement ».
Champs clés sur l'enregistrement Demande
Votre table Demandes doit capter les bases du routage et de la responsabilité :
- équipe_demandeuse et/ou utilisateur_demandeur
- catégorie (campagne, annonce, presse, revue juridique, etc.)
- priorité (ou impact/urgence)
- date_butoir (ce que demande le requérant)
- sla_target_at (date limite calculée selon la politique SLA)
- statut_courant
- propriétaire_courant_utilisateur (ou équipe propriétaire + assigné)
Pensez aussi à : résumé/titre, description, canaux demandés (email, Slack, intranet), et éléments requis.
Tags + recherche pour un filtrage réel
Ajoutez des tags (many-to-many) et un champ texte_recherchable (ou colonnes indexées) pour que les équipes puissent filtrer rapidement les files d'attente et faire des rapports sur des tendances (par ex. “product‑launch” ou “executive‑urgent”).
L'auditabilité n'est pas optionnelle
Préparez‑vous aux besoins d'audit dès le départ :
- Stockez created_at / updated_at / closed_at
- Conservez HistoriqueStatut avec qui a changé quoi, quand
- Préservez les valeurs précédentes pour les champs critiques (statut, propriétaire, dates)
Quand une partie prenante demande « Pourquoi c'était en retard ? », vous aurez une réponse claire sans fouiller les logs de chat.
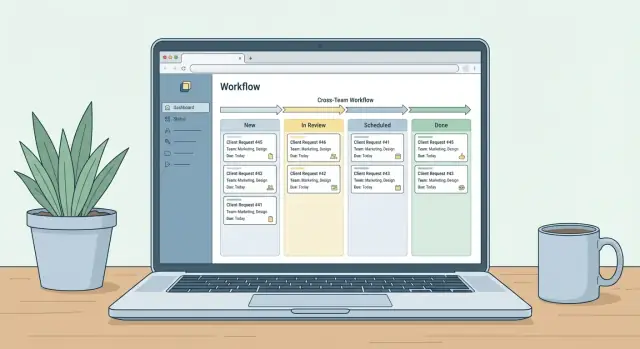
Concevoir les écrans principaux et la navigation
Prototypiez votre flux de demandes
Prototypisez rapidement les formulaires de saisie, les files d'attente et les rôles, puis itérez avec les parties prenantes.
Une bonne navigation n'est pas un ornement — c'est comment vous empêchez les messages « Où dois-je vérifier ça ? » de devenir le vrai workflow. Concevez des écrans autour des rôles que les gens prennent naturellement et gardez chaque vue centrée sur la prochaine action.
Vue demandeur (soumettre et suivre)
L'expérience du demandeur doit ressembler au suivi d'un colis : claire, calme et toujours à jour. Après soumission, affichez une page unique de la demande avec le statut, le propriétaire, les dates cibles et la prochaine étape attendue.
Rendez simple :
- Soumettre une demande et joindre des éléments
- Voir la progression dans le temps (une timeline simple suffit)
- Répondre rapidement à Informations manquantes avec commentaires/fichiers
- Recevoir des mises à jour sans chercher (email + in‑app)
Vue triage (file d'attente et décisions)
C'est la salle de contrôle. Par défaut, affichez une file d'attente avec filtres (équipe, catégorie, statut, priorité) et actions en masse.
Incluez :
- Une file priorisée avec « temps passé dans le statut » visible
- Assignation et réassignation rapides
- Détection de doublons (correspondance titre + demandeur + liens)
- Contrôles de priorité et de date d'échéance sans ouvrir chaque demande
Vue exécutant (faire le travail)
Les exécutants ont besoin d'un écran de charge personnelle : « Ce qui est à moi, ce qui est ensuite, ce qui est à risque ». Affichez les échéances à venir, les dépendances et une checklist d'éléments pour éviter les allers‑retours.
Vue admin (configurer sans casser le flux)
Les admins doivent gérer équipes, catégories, permissions et SLA depuis une zone de paramètres. Gardez les options avancées à un clic, avec des valeurs par défaut sûres.
Navigation cohérente
Utilisez une navigation à gauche (ou onglets en haut) mappée sur les zones basées sur les rôles : Demandes, File d'attente, Mon travail, Rapports, Paramètres. Si un utilisateur a plusieurs rôles, affichez toutes les sections pertinentes, mais que son écran d'accueil soit adapté au rôle principal (par ex. les triages atterrissent sur File d'attente).
Permissions, sécurité et auditabilité
Les permissions ne sont pas que des exigences IT — elles empêchent le partage accidentel et maintiennent le flux sans confusion. Commencez simple, puis durcissez selon les besoins.
Accès par rôle (prévisible)
Définissez un petit ensemble de rôles et rendez chaque rôle explicite dans l'interface :
- Demandeur : peut soumettre, voir ses propres demandes, répondre aux questions et voir le statut.
- Membre d'équipe (exécutant) : peut voir la file de son équipe, commenter, demander des modifications et mettre à jour le statut.
- Approbatteur : peut approuver/refuser des étapes spécifiques (par ex. validation comms ou revue juridique).
- Admin : gère les modèles, champs, équipes et règles de permission.
Évitez les « cas spéciaux » au départ. Si quelqu'un a besoin d'un accès supplémentaire, traitez‑le comme un changement de rôle, pas une exception ponctuelle.
Protéger les demandes sensibles sans freiner l'activité
Utilisez par défaut la visibilité par équipe : une demande est visible du demandeur plus des équipes assignées. Ajoutez ensuite deux options :
- Champs privés (par ex. budget, données employés) visibles seulement par certains rôles.
- Demandes restreintes où seul un groupe nommé peut accéder à l'enregistrement complet.
Cela garde la plupart du travail collaboratif tout en protégeant les cas sensibles.
Décider du fonctionnement des invités (si nécessaire)
Si vous avez besoin d'examinateurs externes ou de parties prenantes occasionnelles, choisissez un modèle :
- Liens en lecture seule avec expiration (utile pour partager une version finale).
- Comptes requis (mieux pour approbations, commentaires et traçabilité).
Les deux peuvent coexister, mais documentez quand chacun est autorisé.
Auditabilité : rendre la responsabilité automatique
Journalisez les actions clés avec horodatage et acteur : changements de statut, modifications de champs critiques, approbations/refus, et confirmation finale de publication. Facilitez l'export de la piste d'audit pour la conformité, et rendez l'historique suffisamment visible pour que les équipes fassent confiance sans « demander autour ».
Notifications et rappels qui n'engendrent pas de bruit
Passez du prototype à la production
Hébergez et déployez votre outil interne avec vos propres politiques et domaines personnalisés.
Les notifications doivent faire avancer une demande — pas créer une seconde boîte que les gens ignorent. L'objectif : dire à la bonne personne la bonne chose au bon moment, avec une prochaine étape claire.
Notifier seulement sur les événements clé du workflow
Commencez par un petit ensemble d'événements qui modifient directement ce que quelqu'un doit faire :
- Soumis (confirmation au demandeur + « ce qui va se passer ensuite »)
- Assigné (le propriétaire reçoit le contexte + lien)
- Informations manquantes (le demandeur reçoit des questions précises et un délai)
- Approuvé/refusé (le demandeur + l'équipe en aval si pertinent)
- Bientôt dû et en retard (propriétaire + éventuelle remontée au manager)
Si un événement n'entraîne pas d'action, laissez‑le dans le journal d'activité plutôt que d'en faire une notification.
Choisir 1–2 canaux et bien les régler
Évitez de diffuser partout. La plupart des équipes réussissent en commençant par un canal principal (souvent l'email) plus un canal temps réel (Slack/Teams) pour les propriétaires.
Règle pratique : utilisez les messages temps réel pour le travail que vous possédez, et l'email pour la visibilité et les archives. Les notifications in‑app deviennent utiles quand les gens vivent quotidiennement dans l'outil.
Règles de rappel qui réduisent le bruit
Les rappels doivent être prévisibles et configurables :
- Digests quotidiens ou bi‑hebdomadaires pour « informations manquantes » et « en attente de vous »
- Heures calmes (pas de pings en dehors des heures ; envoyer le matin suivant)
- Escalade seulement après un seuil clair (par ex. 48 heures de retard)
Utiliser des modèles pour que les mises à jour soient actionnables
Les modèles rendent les messages cohérents et faciles à scanner. Chaque notification doit inclure :
- Titre + ID de la demande
- Statut et propriétaire actuels
- Ce qui a changé
- Un CTA clair (ex. « Ajouter une info », « Examiner », « Marquer comme terminé »)
Cela fait que chaque message ressemble à un progrès plutôt qu'à du bruit.
SLA, dates butoir et planification
Si les demandes ne sont pas livrées à temps, la cause est souvent des attentes floues : « Combien de temps cela doit‑il prendre ? » et « Pour quand ? ». Intégrez le timing dans le workflow pour qu'il soit visible, cohérent et équitable.
Définir des SLA par type de demande
Fixez des attentes de niveau de service adaptées au travail. Par exemple :
- Annonces : 5 jours ouvrés
- Articles de newsletter : 3 jours ouvrés
- Communications exécutives : 10 jours ouvrés
Rendez le champ SLA piloté par le type de demande : dès que le demandeur choisit un type, l'appli peut afficher le délai attendu et la date de publication la plus proche possible.
Calculer automatiquement les dates cibles
Évitez les calculs manuels. Conservez deux dates :
- Date de publication souhaitée (ce que veut le demandeur)
- Date cible de complétion (ce que l'équipe s'engage à livrer)
Calculez ensuite la date cible en utilisant le temps d'avance du type de demande (jours ouvrés) et les étapes requises (ex. approbations). Si quelqu'un change la date de publication, l'appli met à jour la date cible et signale une « timeline serrée » quand la date du demandeur est antérieure à la plus proche date réalisable.
Planification pour éviter les collisions
Une file ne suffit pas pour montrer les conflits. Ajoutez une vue calendrier simple qui regroupe les éléments par date de publication et par canal (email, intranet, social, etc.). Cela aide à repérer les surcharges (trop d'envois un mardi) et à négocier des alternatives avant de démarrer le travail.
Suivre les raisons des retards
Quand une demande prend du retard, capturez une unique « raison du retard » pour que le reporting soit exploitable : en attente du demandeur, en attente d'approbations, capacité, ou changement de périmètre. Avec le temps, les retards deviennent des motifs réparables plutôt que des surprises récurrentes.
Construire un MVP et choisir une approche technique pratique
La voie la plus rapide vers la valeur est de livrer un petit MVP utilisable qui remplace les chats ad‑hoc et les tableurs — sans essayer de résoudre tous les cas limites.
Commencez par un MVP que les gens utiliseront réellement
Visez le plus petit ensemble de fonctionnalités qui couvre un cycle de demande complet :
- Un formulaire d'intake qui capture l'essentiel (type de demande, audience, échéance, priorité, pièces jointes)
- Une file de demandes partagée (un endroit pour voir « ce qui attend »)
- Des statuts simples alignés sur votre workflow (par ex. Nouveau → En revue → Approuvé → Planifié → Terminé, avec Informations manquantes et Refusé en chemins alternatifs)
- Commentaires et @mentions pour clarifications
- Notifications basiques (confirmation au demandeur, assignation au propriétaire, changements de statut)
Si vous faites bien cela, vous réduirez immédiatement les allers‑retours et créerez une source unique de vérité.
Choisissez une stack qui convient à votre équipe (pas à votre liste de souhaits)
Optez pour l'approche qui correspond à vos compétences, vos besoins de rapidité et votre gouvernance :
- Low‑code (livraison la plus rapide) : excellent pour formulaires + approbations + tableaux de bord simples.
- Plateformes d'outils internes : adaptées aux applis authentifiées avec tables, filtres et panneaux admin.
- Développement full‑stack : préférable si vous avez besoin d'intégrations sur mesure, de permissions complexes ou d'automatisations lourdes.
Si vous voulez accélérer la voie full‑stack sans revenir à des tableurs fragiles, des plateformes comme Koder.ai peuvent aider à obtenir une appli interne fonctionnelle à partir d'un cahier des charges structuré. Vous pouvez prototyper le formulaire d'intake, la file, les rôles/permissions et les tableaux de bord rapidement, puis itérer avec les parties prenantes — tout en gardant l'option d'exporter le code source et déployer selon vos politiques.
Implémentez la recherche et les filtres tôt
Même à 50–100 demandes, les gens ont besoin de trancher la file par équipe, statut, date d'échéance et priorité. Ajoutez des filtres dès le jour 1 pour que l'outil ne devienne pas une longue page à faire défiler.
Ajoutez l'analytics plus tard (une fois les données propres)
Après stabilisation du workflow, superposez le reporting : débit, temps de cycle, taille du backlog et taux de respect des SLA. Vous aurez de meilleures analyses quand les équipes utiliseront de façon cohérente les mêmes statuts et règles de dates.
Lancement, adoption et plan d'itération
Évitez le verrouillage
Gardez le contrôle en exportant le code source quand vous êtes prêt à prendre en charge la stack.
Une application de gestion des demandes ne fonctionne que si les gens l'utilisent — et continuent de l'utiliser. Traitez la première version comme une phase d'apprentissage, pas un grand déploiement. Votre objectif est d'établir la nouvelle « source de vérité », puis d'ajuster le workflow selon le comportement réel.
Commencez par un petit pilote
Pilotez avec 1–2 équipes et 1–2 catégories de demande. Choisissez des équipes qui ont des passations fréquentes et un manager capable de faire respecter le processus. Gardez le volume gérable pour répondre vite aux problèmes et construire la confiance.
Pendant le pilote, conservez l'ancien processus en parallèle seulement si nécessaire. Si les mises à jour continuent dans le chat ou l'email, l'appli ne deviendra jamais le point de référence.
Publiez des consignes légères
Créez des consignes simples qui répondent :
- Ce qui doit être soumis (et ce qui ne doit pas l'être)
- Délai requis (par ex. « 72 heures pour les demandes standards »)
- Où les mises à jour résident (l'appli, pas les DM)
Épinglez les consignes dans le hub d'équipe et liez‑les depuis l'appli (par ex. /help/requests). Faites‑les suffisamment courtes pour que les gens les lisent.
Construisez une boucle de feedback actionnable
Collectez du feedback chaque semaine auprès des demandeurs et des propriétaires. Demandez spécifiquement quels champs manquent, quels statuts sont confus, et où les notifications sont trop bruyantes. Associez cela à une revue rapide de demandes réelles : où les gens ont hésité, abandonné ou contourné le workflow ?
Itérez sans casser les habitudes
Itérez par petites modifications prévisibles : ajustez les champs du formulaire, les SLA et les permissions selon l'usage réel. Annoncez les changements en un endroit unique, avec une note « ce qui a changé / pourquoi ». La stabilité favorise l'adoption ; les révisions constantes l'érodent.
Pour que cela tienne, mesurez l'adoption (demandes soumises via l'appli vs en dehors), le temps de cycle et le retravail. Utilisez ces résultats pour prioriser la prochaine itération.
Mesurer les résultats et s'améliorer dans le temps
Lancer votre appli de demande n'est pas la ligne d'arrivée — c'est le début d'une boucle de feedback. Si vous ne mesurez pas le système, il peut lentement devenir une « boîte noire » où les équipes cessent de faire confiance aux statuts et retournent aux messages secondaires.
Commencez par des tableaux de bord que les gens utilisent réellement
Créez un petit ensemble de vues qui répondent aux questions quotidiennes :
- Demandes ouvertes (ce qui est dans la file maintenant)
- En retard (passé la date butoir ou le SLA)
- À venir (bientôt dû pour la planification)
- Charge par équipe/propriétaire (pour repérer les goulets et répartition inégale)
Gardez ces tableaux visibles et constants. Si les équipes ne les comprennent pas en 10 secondes, elles ne les consulteront pas.
Passez en revue les métriques chaque mois — et décidez quoi changer
Choisissez une réunion mensuelle récurrente (30–45 minutes) avec des représentants des principales équipes. Utilisez‑la pour revoir un petit set stable de métriques, par ex. :
- Temps moyen de première réponse
- Temps moyen jusqu'à complétion
- Taux de respect des SLA
- Taux de réouverture (demandes qui rebondissent)
- Volume par type de demande
Terminez la réunion par décisions concrètes : ajuster les SLA, clarifier les questions d'intake, affiner les statuts, ou déplacer des règles de propriété. Documentez les changements dans un simple changelog pour que les gens sachent ce qui a changé.
Maintenez une taxonomie légère
Une taxonomie de demandes est utile seulement si elle reste petite. Visez une poignée de catégories plus des tags optionnels. Évitez de créer des centaines de types qui demandent une surveillance constante.
Planifiez les améliorations basées sur des preuves
Une fois les bases stables, priorisez les améliorations qui réduisent le travail manuel :
- Modèles pour les demandes récurrentes
- Intégrations (chat, email, calendrier, ticketing)
- Approbations guidées par des règles (uniquement quand nécessaire)
- Une API pour le reporting ou la création de demandes depuis d'autres outils
Laissez l'usage et les métriques — pas les opinions — décider de ce que vous construisez ensuite.