Clarifier le cas d'usage et les métriques de succès
Avant de concevoir des écrans ou de choisir une stack technique, soyez précis sur le problème que vous résolvez. Une application de dépendances échoue quand elle devient « un autre endroit où mettre à jour les choses », alors que la vraie douleur — les surprises et les remises tardives entre équipes — persiste.
Définir le problème central
Commencez par une phrase simple que vous pouvez répéter dans chaque réunion :
Les dépendances interfonctionnelles provoquent des retards et des surprises de dernière minute parce que la responsabilité, les dates et le statut sont flous.
Rendez‑la spécifique à votre organisation : quelles équipes sont le plus affectées, quels types de travail sont bloqués, et où vous perdez du temps aujourd’hui (transferts, validations, livrables, accès aux données, etc.).
Identifier les utilisateurs cibles (et leurs besoins)
Listez les utilisateurs principaux et comment ils utiliseront l’app :
- Chefs de projet : ont besoin d’une vue fiable des blocages à venir et de ce qu’il faut escalader.
- Leads d’équipe : ont besoin de clarté sur ce que leur équipe doit fournir, et des compromis.
- Sponsors exécutifs : ont besoin d’une vue synthétique des risques et de la responsabilité.
- Contributeurs individuels (ICs) : ont besoin de demandes actionnables, de contexte et de dates d’échéance.
Capturer les principaux “jobs-to-be-done”
Gardez les “jobs” serrés et testables :
- Découvrir des dépendances tôt (pendant la planif, pas en delivery).
- Créer des demandes de dépendance avec périmètre et dates clairs.
- Valider (accepter/rejeter) avec des délais négociés.
- Suivre l’avancement et les changements dans le temps.
- Escalader quand le risque augmente ou que les engagements glissent.
Décider de ce que « dépendance » signifie ici
Rédigez une définition d’un paragraphe. Exemples : un transfert (l’équipe A fournit des données), une approbation (validation Legal), ou un livrable (spec de design). Cette définition devient votre modèle de données et l’épine dorsale du workflow.
Définir les métriques de succès
Choisissez un petit ensemble de résultats mesurables :
- Moins de bloqueurs actifs par projet (ou moins de dépendances « découvertes tardivement »).
- Temps moyen plus court de la demande → acceptation → livraison.
- Meilleure prévisibilité (moins de glissements de date, meilleur taux de livraison à l’heure).
Si vous ne pouvez pas le mesurer, vous ne pouvez pas prouver que l’app améliore l’exécution.
Cartographier les parties prenantes et le workflow actuel
Avant de concevoir des écrans ou une base de données, clarifiez qui participe aux dépendances et comment le travail circule entre eux. La gestion des dépendances interfonctionnelles échoue moins à cause d’un mauvais outil que d’attentes mal alignées : « Qui en est responsable ? », « Qu’est‑ce que ‘terminé’ signifie ? », « Où voit‑on le statut ? »
Trouver où les données de dépendance vivent aujourd’hui
Les informations sont généralement dispersées. Faites un inventaire rapide et capturez des exemples (captures d’écran réelles ou liens) de :
- Tableurs qui suivent les « demandes » et les dates
- Tickets et epics Jira/Asana/Trello
- Docs et notes de réunion (Google Docs/Notion/Confluence)
- Fils Slack/Teams où les décisions et promesses ont lieu
Cela vous indique quels champs les gens utilisent déjà (dates, liens, priorité) et ce qui manque (propriétaire clair, critères d’acceptation, statut).
Cartographier le flux de bout en bout
Écrivez le flux actuel en langage simple, typiquement :
demande → acceptation → livraison → vérification
Pour chaque étape, notez :
- Qui le déclenche (rôle/équipe, pas une personne)
- Quelles informations sont nécessaires pour avancer
- Où c’est enregistré aujourd’hui
- Ce que signifie « complet » (et qui le valide)
Repérer les points de défaillance et classer la douleur
Cherchez des motifs comme propriétaires flous, dates manquantes, statut « silencieux », ou dépendances découvertes tard. Demandez aux parties prenantes de classer les scénarios les plus douloureux (par ex. « accepté mais jamais livré » vs « livré mais non vérifié »). Optimisez les 1–2 cas les plus critiques en premier.
Ancrer la construction par des user stories
Rédigez 5–8 user stories qui reflètent la réalité, par exemple :
- « En tant que PM demandeur, je peux soumettre une dépendance avec une date nécessaire et du contexte pour que l’équipe responsable l’évalue. »
- « En tant que lead responsable, je peux accepter/rejeter en indiquant une date d’engagement pour expliciter les attentes. »
- « En tant que partie prenante, je vois le statut en un coup d’œil pour ne pas courir après des mises à jour en réunion. »
Ces stories servent de garde‑fous lorsque les demandes de fonctionnalités s’accumulent.
Concevoir le modèle de données des dépendances
Une application de dépendances réussit ou échoue selon la confiance que les gens accordent aux données. L’objectif du modèle est de capturer qui a besoin de quoi, de qui, et pour quand, et de conserver un enregistrement propre des évolutions d’engagement.
Enregistrement central « Dépendance »
Commencez par une seule entité « Dépendance » lisible indépendamment :
- Titre : court, spécifique (ex. « Fournir revue légale du texte du checkout mis à jour »)
- Description : contexte, critères d’acceptation, liens
- Type : liste contrôlée (revue, livraison, approbation, accès aux données)
- Équipe responsable : l’équipe attendue pour livrer
- Demandeur : personne ou équipe qui le demande
Rendez ces champs obligatoires autant que possible ; les champs optionnels ont tendance à rester vides.
Dates et engagements
Les dépendances concernent le temps, donc stockez les dates explicitement et séparément :
- Date demandée (la date souhaitée par le demandeur)
- Date engagée (la promesse de l’équipe responsable)
- Date de livraison (date réelle d’achèvement)
- Fenêtre de revue (plage start/end pour la validation ou la signature)
Cette séparation évite les débats ultérieurs (« demandé » n’est pas la même chose que « engagé »).
Statut et relations
Utilisez un modèle de statut simple et partagé : Proposé → En attente → Accepté → Livré, avec des exceptions comme À risque et Rejeté.
Modelez les relations en liens un‑à‑plusieurs pour que chaque dépendance puisse se connecter à :
- Projets (une dépendance peut impacter plusieurs initiatives)
- Jalons (attachez‑la à un checkpoint de livraison)
- Tickets (ex. issues Jira pour l’exécution)
Auditabilité et confiance
Rendez les changements traçables avec :
- Créé/mis à jour par
- Historique des changements (mises à jour au niveau champ dans le temps)
- Commentaires (notes de décision, clarifications, approbations)
Si vous faites bien la piste d’audit tôt, vous éviterez les débats « il/elle a dit » et faciliterez les transferts.
Modéliser projets, jalons et responsabilité d’équipe
Une application de dépendances ne fonctionne que si tout le monde s’entend sur ce qu’est un « projet », un « jalon », et qui est responsable quand ça dérape. Gardez le modèle assez simple pour que les équipes l’entretiennent réellement.
Projets et jalons : choisir la bonne granularité
Suivez les projets au niveau où les gens planifient et reportent — généralement une initiative de semaines à mois avec un résultat clair. Évitez de créer un projet pour chaque ticket ; cela relève des outils de delivery.
Les jalons doivent être peu nombreux et significatifs (ex. « contrat d’API approuvé », « lancement beta », « revue sécurité terminée »). Si les jalons deviennent trop détaillés, les mises à jour deviennent une corvée et la qualité des données diminue.
Une règle pratique : un projet devrait avoir 3–8 jalons, chacun avec un propriétaire, une date cible et un statut. Si vous avez besoin de plus, envisagez de réduire la taille du projet.
Annuaire d’équipes : rendre la responsabilité trouvable
Les dépendances échouent quand on ne sait pas à qui parler. Ajoutez un annuaire léger d’équipes qui supporte :
- Nom et fonction de l’équipe (ex. Paiements, Data Platform, Legal)
- Contact principal (personne) et backup/on‑call
- Canal préféré (email, handle Slack, file de tickets)
Cet annuaire doit être utilisable par des partenaires non‑techniques : champs lisibles et possibilité de recherche.
Règles de propriété : responsabilité sans confusion
Décidez d’entrée si vous autorisez la co‑responsabilité. Pour les dépendances, la règle la plus claire est :
- Un seul responsable redevable par jalon/dépendance (une personne)
- Collaborateurs optionnels (plusieurs personnes)
Si deux équipes partagent vraiment la responsabilité, modelez‑le comme deux jalons (ou deux dépendances) avec un handoff clair, plutôt que des éléments « co‑possédés » que personne ne pilote.
Dépendances inter‑projets et rollups programmes
Représentez les dépendances comme des liens entre un projet/jalon demandeur et un projet/jalon livrant, avec une direction (« A a besoin de B »). Cela permet des vues programmatiques : rollup par initiative, trimestre ou portefeuille sans changer le travail quotidien des équipes.
Les tags aident le reporting sans imposer une nouvelle hiérarchie. Commencez petit et contrôlé :
- Domaine produit
- Trimestre (ou fenêtre de release)
- Nom d’initiative/programme
- Priorité (ex. P0–P3)
Préférez des listes déroulantes pour les tags clés plutôt que du texte libre afin d’éviter « Paiements », « paiements », et « Paymnts » comme trois catégories différentes.
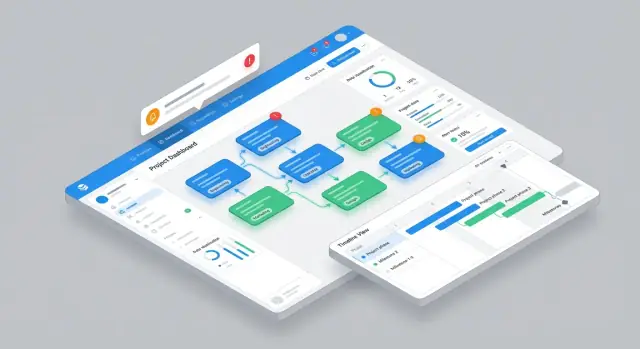
Planifier l’UI principale et la navigation
Une appli de gestion de dépendances réussit quand les gens peuvent répondre en quelques secondes à deux questions : « Que dois‑je livrer ? » et « Qu’est‑ce qui me bloque ? ». Concevez la navigation autour de ces jobs‑to‑be‑done, pas autour des objets BD.
Vues primaires qui correspondent au travail réel
Commencez par quatre vues centrales, chacune optimisée pour un moment de la semaine :
- Liste de dépendances pour le triage et le tri (utile pour les check‑ins quotidiens)
- Graphe de dépendances pour comprendre l’impact amont/aval d’un coup d’œil
- Timeline pour repérer collisions de dates et handoffs qui glissent
- Boîte de réception d’équipe comme page d’accueil par défaut pour les contributeurs (« demandes en attente sur moi »)
Gardez la navigation globale minimale (ex. Inbox, Dépendances, Timeline, Rapports) et laissez les utilisateurs basculer sans perdre leurs filtres.
Création rapide sans sacrifier la clarté
Faire une dépendance doit ressembler à l’envoi d’un message. Fournissez des templates (ex. « contrat d’API », « revue design », « export de données ») et un tiroir Ajout rapide.
Exigez uniquement ce qui est nécessaire pour router correctement : équipe demandeuse, équipe responsable, date d’échéance, courte description, statut. Le reste peut être optionnel ou progressif.
Filtrage, recherche et vues enregistrées
Les gens vivront dans des filtres. Supportez la recherche et les filtres par équipe, intervalle de dates, risque, statut, projet, plus « assigné à moi ». Permettez d’enregistrer des combinaisons fréquentes (« Mes lancements T1 », « Haut risque ce mois »).
Accessibilité et conseils en état vide
Utilisez indicateurs de risque lisibles en daltoniens (icône + libellé, pas la couleur seule) et assurez une navigation clavier complète pour créer, filtrer et mettre à jour des statuts.
Les états vides doivent apprendre. Quand une liste est vide, montrez un exemple court de dépendance forte :
“Équipe Paiements : fournir clés sandbox pour Checkout v2 d’ici le 14 mars ; nécessaire pour le démarrage des tests mobiles.”
Ce type de guidance améliore la qualité des données sans ajouter de processus.
Construire les workflows : Demande, Acceptation, Livraison, Clôture
Réduire le bruit des notifications
Créez des notifications pour acceptations, dates d'échéance et escalades sans inonder les équipes.
Un outil de dépendances réussit quand il reflète la collaboration réelle des équipes — sans les forcer dans des réunions longues. Concevez le workflow autour d’un petit ensemble d’états que tout le monde reconnaît, et faites en sorte que chaque changement de statut réponde à une question : « Quelle est la prochaine action, et qui en est responsable ? »
Flux de demande : créer → router → acceptation
Commencez par un formulaire guidé « Créer une dépendance » qui capture le minimum nécessaire : projet demandeur, résultat attendu, date cible, et impact en cas d’échec. Ensuite, routez automatiquement vers l’équipe responsable selon une règle simple (propriétaire de service/composant, annuaire d’équipe, ou sélection manuelle).
L’acceptation doit être explicite : l’équipe destinatrice accepte, rejette, ou demande une clarification. Évitez l’« acceptation douce » — faites‑en un bouton qui crée la responsabilité et horodate la décision.
Critères d’acceptation : définition de fait et validation
Lors de l’acceptation, exigez une définition de fait légère : livrables (ex. endpoint API, revue de spec, export de données), test d’acceptation ou étape de vérification, et le propriétaire de validation côté demandeur.
Cela évite le mode d’échec courant où une dépendance est « livrée » mais inutilisable.
Gestion des changements : dates, périmètre, réaffectations
Les changements sont normaux ; les surprises ne le sont pas. Chaque changement doit :
- enregistrer ce qui a changé (date, périmètre, propriétaire)
- exiger une courte raison
- notifier les deux équipes
- garder un historique visible pour éviter les débats
Chemin d’escalade : drapeaux à risque et SLA
Donnez un drapeau À risque avec niveaux d’escalade (ex. Lead d’équipe → Program Lead → Sponsor exécutif) et des SLA optionnels (réponse sous X jours, mise à jour tous les Y jours). L’escalade doit être une action de workflow, pas un fil de message agressif.
Flux de clôture : preuve, vérification, notes rétrospectives
Clôturez une dépendance seulement après deux étapes : preuve de livraison (lien, pièce jointe, ou note) et vérification par le demandeur (ou fermeture automatique après une fenêtre définie). Capturez un court champ rétrospectif (« qu’est‑ce qui nous a bloqués ? ») pour améliorer la planification future sans lancer un postmortem complet.
Ajouter rôles, permissions et auditabilité
La gestion des dépendances se casse vite quand les gens ignorent qui peut s’engager, qui peut éditer, et qui a modifié quoi. Un modèle de permissions clair évite les changements de date accidentels, protège le travail sensible et construit la confiance.
Définir des types de rôles qui correspondent au travail réel
Commencez par un petit ensemble et étendez seulement si nécessaire :
- Admin : gère les réglages workspace, intégrations et permissions globales
- Program manager : supervise portefeuilles, règle la gouvernance et résout les conflits
- Lead d’équipe : pilote les engagements d’équipe et approuve les demandes entrantes
- Contributeur : crée et met à jour les dépendances où il est impliqué, ajoute des notes, propose des changements
- Viewer : accès en lecture seule pour les stakeholders qui ont besoin de visibilité sans pouvoir éditer
Permissions par objet (et par action)
Implémentez les permissions au niveau des objets — dépendances, projets, jalons, commentaires/notes — puis par action :
- Créer/éditer des dépendances
- Changer le statut d’une dépendance (ex. Proposé → Accepté → Livré → Clos)
- Modifier dates engagées vs dates suggérées
- Supprimer (généralement restreint aux Admin/Program manager)
Un bon défaut est le moindre privilège : les nouveaux utilisateurs ne devraient pas pouvoir supprimer des enregistrements ou outrepasser des engagements.
Visibilité des données et travail sensible
Tous les projets ne doivent pas être visibles de la même manière. Ajoutez des périmètres de visibilité :
- Interne (par défaut) : visible aux utilisateurs authentifiés du workspace
- Sensibles : limité à des équipes spécifiques ou un groupe sécurité
- Notes privées d’équipe : garder des notes de livraison candides visibles seulement par l’équipe responsable, tandis que le statut reste visible aux stakeholders
Contrôles d’approbation et auditabilité
Définissez qui peut accepter/rejeter et qui peut changer les dates engagées — typiquement le lead de l’équipe destinatrice (ou un délégué). Rendez la règle explicite dans l’UI : « Seule l’équipe responsable peut engager des dates. »
Enfin, ajoutez un journal d’audit pour les événements clés : changements de statut, modifications de date, transferts de propriété, mises à jour de permissions et suppressions (incluant qui, quand et quoi). Si vous prenez en charge le SSO, couplez‑le au journal d’audit pour clarifier l’accès et la responsabilité.
Implémenter alertes et notifications
Planifier le modèle de données
Cartographiez d'abord les entités, les rôles et les indicateurs de succès, puis générez l'application à partir du plan.
Les alertes font basculer une appli de dépendances entre « vraiment utile » et « bruit que tout le monde ignore ». L’objectif est simple : faire avancer le travail entre équipes en notifiant les bonnes personnes au bon moment, avec le bon niveau d’urgence.
Commencer par des déclencheurs de notification clairs
Définissez les événements qui comptent le plus :
- Nouvelle demande créée (l’équipe destinatrice doit l’accuser réception)
- Demande acceptée / rejetée (le demandeur a besoin de certitude)
- Échéance approchante (prévenir les surprises de dernière minute)
- Statut passé en « à risque » ou « bloqué » (inciter à agir)
Associez chaque déclencheur à un propriétaire et à une « prochaine étape », pour que la notification soit actionnable et pas seulement informative.
Proposer des canaux sans les imposer
Supportez plusieurs canaux :
- Notifications in‑app pour une piste d’audit propre et un tri facile
- Email pour ceux qui vivent dans leur boîte de réception
- Slack/Teams pour la visibilité rapide d’équipe
Rendez cela configurable au niveau utilisateur et équipe. Un lead de dépendance peut vouloir des pings Slack ; un sponsor exécutif peut préférer un résumé quotidien par email.
Équilibrer temps réel et digests
Les messages en temps réel conviennent aux décisions (accept/reject) et aux escalades. Les digests conviennent à la prise de conscience (dates à venir, éléments “en attente”).
Incluez des réglages comme : « immédiat pour assignations », « digest quotidien pour les dates », et « résumé hebdomadaire pour la santé ». Cela réduit la fatigue de notification tout en maintenant la visibilité.
Obtenir la logique de rappels et d’escalade correcte
Les rappels doivent respecter jours ouvrés, fuseaux horaires et heures calmes. Ex. : envoyer un rappel 3 jours ouvrés avant une échéance, et ne jamais notifier hors 9h–18h heure locale.
Les escalades doivent se déclencher quand :
- Une demande reste sans réponse après un SLA défini (ex. 48h)
- Une date glisse ou une dépendance est marquée à risque
Escaladez au niveau responsable suivant (lead d’équipe, program manager) et incluez le contexte : ce qui est bloqué, par qui, et quelle décision est nécessaire.
Planifier intégrations et synchronisation des données
Les intégrations rendent une app de dépendances utile dès le jour 1 car la plupart des équipes suivent déjà le travail ailleurs. L’objectif n’est pas de « remplacer Jira » (ou Linear, GitHub, Slack) — c’est de connecter les décisions aux systèmes où l’exécution a lieu.
Intégrations à prioriser
Commencez par les outils qui représentent le travail, le temps et la communication :
- Jira / Linear pour issues, statuts, assignés et contexte sprint/itération
- GitHub pour pull requests, releases et signaux de déploiement
- Google Calendar pour dates de jalons, fenêtres de changement et réunions clés
- Slack pour notifications et validations légères
Choisissez 1–2 à piloter d’abord. Trop d’intégrations tôt transforme le debug en activité principale.
Stratégie d’import : CSV d’abord, puis sync
Utilisez un import CSV ponctuel pour démarrer avec les dépendances, projets et propriétaires existants. Gardez le format opinionné (ex. titre dépendance, équipe demandeuse, équipe fournisseuse, date d’échéance, statut).
Puis ajoutez une synchronisation continue seulement pour les champs qui doivent rester cohérents (comme le statut d’issue externe ou la date d’échéance). Cela réduit les changements surprises et facilite le dépannage.
Lier vs synchroniser (et quand)
Tous les champs externes ne doivent pas être copiés dans votre base :
- Liaison : stockez l’ID du système externe (ex. clé Jira) et lien profond. Idéal si l’outil externe est la source de vérité.
- Synchronisation : conservez une copie locale de champs sélectionnés (statut, date d’échéance, assigné) pour le reporting, les alertes et l’historique — surtout si vous avez besoin de « qui a changé quoi ».
Un pattern pratique : stockez toujours les IDs externes, synchronisez un petit ensemble de champs, et autorisez les overrides manuels seulement quand votre app est la source de vérité.
Webhooks + APIs : sync pilotée par événements
Le polling est simple mais bruyant. Préférez les webhooks quand c’est possible :
- Écoutez les changements de statut (ex. « In Progress » → « Done »)
- Écoutez les changements de date (souvent le déclencheur le plus important pour le risque de dépendance)
Quand un événement arrive, placez un job en arrière‑plan pour récupérer la dernière version via API et mettre à jour l’objet dépendance.
Définir les frontières de propriété des données
Écrivez qui possède chaque champ :
- Jira/Linear possède le statut d’issue et l’assigné
- Votre app possède la relation de dépendance, la date d’engagement, et les décisions accepter/refuser
- Slack possède le canal de livraison et l’historique des messages (ne tentez pas de le répliquer)
Des règles claires de source de vérité évitent les « guerres de sync » et simplifient la gouvernance et les audits.
Créer des rapports et tableaux de bord de santé
Les dashboards sont l’endroit où votre app gagne la confiance : les responsables cessent de demander « encore une slide », et les équipes arrêtent de courir après des mises à jour dans les chats. L’objectif n’est pas un mur de graphiques — c’est une façon rapide de répondre à « Qu’est‑ce qui est à risque, pourquoi, et qui doit agir ? »
Définir des signaux de santé clairs
Commencez par un petit ensemble d’indicateurs de risque calculables de façon cohérente :
- En retard : date promise dépassée et non livrée
- Bloqué : marqué comme bloqué, ou absence d’un input requis
- Propriétaire manquant : pas d’équipe/personne redevable assignée
- Dates conflictuelles : demandeur a besoin après la livraison prévue du fournisseur (ou inverse)
Ces signaux doivent être visibles au niveau dépendance et agrégés jusqu’à la santé projet/programme.
Construire des vues prêtes pour les réunions
Créez des vues qui correspondent aux réunions de pilotage :
- Dépendances critiques à venir : 2–4 semaines, triées par risque et échéance
- Impact capacité équipe : montrer où les demandes entrantes dépassent la charge disponible (même un indicateur simple « faible/moyen/élevé » aide)
- Rollups programme : grouper par initiative, trimestre ou release train pour que les leaders comparent les workstreams sans agrégation manuelle
Un bon défaut est une page unique répondant à : « Qu’est‑ce qui a changé depuis la semaine dernière ? » (nouveaux risques, bloqueurs résolus, shifts de date).
Faciliter le partage
Les dashboards doivent souvent sortir de l’app. Ajoutez des exports qui préservent le contexte :
- CSV pour analyse et filtrage
- PDF pour réunions de pilotage et validations
Lors de l’export, incluez propriétaire, dates, statut et le dernier commentaire pour que le fichier soit autonome. C’est ainsi que les dashboards remplacent les slides manuelles au lieu de créer une tâche de reporting additionnelle.
Choisir une stack technique et une architecture pragmatiques
Itérer sans crainte
Utilisez des instantanés et des restaurations pour tester de nouvelles règles de statut ou champs de données.
L’objectif n’est pas de choisir la « techno parfaite » — c’est de sélectionner une stack que votre équipe peut construire et exploiter en toute confiance tout en gardant les vues rapides et fiables.
Un baseline pratique :
- Une application web (server‑rendered ou SPA) pour l’usage quotidien
- Une API unique (REST ou GraphQL) pour l’UI et les intégrations
- Une base relationnelle
- Jobs en arrière‑plan pour notifications, syncs planifiés et génération de rapports
Cela rend le système simple à raisonner : actions utilisateur synchrones, travail lent (alertes, calculs santé) en asynchrone.
Base de données : modélisez les liens volontairement
La gestion des dépendances implique beaucoup de requêtes « trouver tous les éléments bloqués par X ». Un modèle relationnel fonctionne bien, surtout avec les bons index.
Prévoyez au minimum des tables Projects, Milestones/Deliverables et Dependencies (from_id, to_id, type, statut, dates, owners). Ajoutez des index pour filtres courants (équipe, statut, date d’échéance, projet) et pour les traversées (from_id, to_id). Cela évite que l’app ralentisse quand le nombre de liens augmente.
Les graphes de dépendances et timelines Gantt peuvent être coûteux. Choisissez des librairies qui supportent la virtualisation (rendre seulement ce qui est visible) et les mises à jour incrémentales. Considérez « afficher tout » comme un mode avancé ; par défaut, scopez (par projet, par équipe, par intervalle).
Paginer les listes par défaut, et mettre en cache les résultats calculés fréquents (ex. « nombre bloqué par projet »). Pour les graphes, préchargez le voisinage autour du nœud sélectionné, puis étendez à la demande.
Bonnes pratiques de déploiement
Utilisez des environnements séparés (dev/staging/prod), ajoutez monitoring et suivi d’erreurs, et loggez les événements pertinents pour l’audit. Une app de dépendances devient vite source de vérité — les indisponibilités et les échecs silencieux coûtent du temps réel de coordination.
Une voie rapide pour un prototype
Si l’objectif principal est de valider les workflows et l’UI rapidement (inbox, acceptation, escalation, dashboards) avant d’engager beaucoup d’ingénierie, vous pouvez prototyper sur une plateforme de vibe‑coding comme Koder.ai. Elle permet d’itérer sur le modèle de données, les rôles/permissions et les écrans clés via chat, puis d’exporter le code source quand vous êtes prêt à passer en production (communément React côté web, Go + PostgreSQL côté backend). Utile pour un pilote avec 2–3 équipes où la rapidité d’itération prime sur l’architecture parfaite du jour 1.
Tester, piloter et déployer en sécurité
Une app de dépendances n’aide que si les gens lui font confiance. Cette confiance se gagne par des tests soigneux, un pilote contenu, et un déploiement qui ne perturbe pas les équipes en plein delivery.
Tester le workflow de bout en bout
Commencez par valider le « happy path » : une équipe demande, l’équipe destinatrice accepte, le travail est livré, et la dépendance est close avec un résultat clair.
Ensuite, testez les cas limites qui cassent souvent l’usage réel :
- Réaffectations : déplacer la responsabilité vers une autre équipe et vérifier que l’historique reste intact
- Rejets : rejeter avec une raison, s’assurer que le demandeur peut réviser/soumettre à nouveau
- Changements de date : mettre à jour des dates de jalon et vérifier que les timelines aval, SLA et rapports s’ajustent correctement
Vérifications de permissions et d’audit
Les apps de dépendances échouent quand les permissions sont trop strictes (impossibilité de faire son travail) ou trop lâches (les équipes perdent le contrôle). Testez des scénarios comme :
- Un demandeur peut éditer sa demande, mais ne peut pas modifier les champs de livraison de l’équipe responsable
- Seuls les propriétaires désignés peuvent accepter/engager des dates
- Les admins peuvent intervenir, et chaque changement critique est capturé dans un journal d’audit (qui/quoi/quand)
Notifications sans bruit
Les alertes doivent faire agir, pas désensibiliser. Vérifiez :
- Pas de notifications dupliquées quand plusieurs champs changent en même temps
- Le throttling fonctionne (ex. un résumé d’une mise à jour au lieu de 10 pings distincts)
- Les digests email/Slack contiennent suffisamment de contexte (projet, dépendance, date, propriétaire) pour agir sans chercher
Pré‑charger des données de démonstration pour la validation
Avant d’impliquer des équipes, importez des projets réalistes, jalons et dépendances trans‑équipes. De bonnes données de seed exposent les labels confus, statuts manquants et lacunes de reporting plus vite que des enregistrements synthétiques.
Lancer un petit pilote, puis étendre
Pilotez avec 2–3 équipes qui dépendent souvent les unes des autres. Fixez une fenêtre courte (2–4 semaines), collectez des retours chaque semaine, et itérez sur :
- Les noms de statut et champs requis
- Les règles de notification
- Les vues de reporting (ce qui est « actionnable » vs « intéressant »)
Quand les équipes pilotes confirment que l’outil fait gagner du temps, déployez par vagues et publiez un doc clair « comment on travaille maintenant » (même un simple document interne lié depuis l’app) pour maintenir la cohérence des attentes.