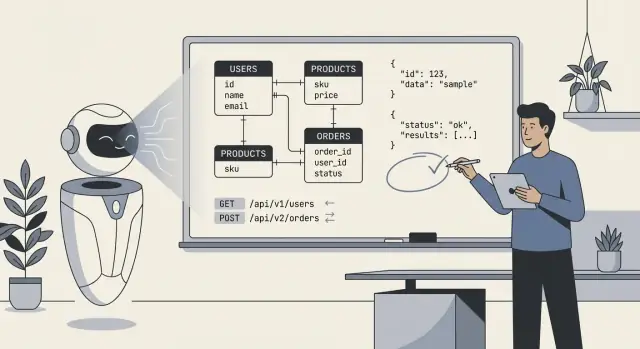
Ce que signifie vraiment « l'IA conçoit votre backend »
Quand on dit « l'IA a conçu notre backend », on veut en général dire que le modèle a produit un premier brouillon du plan technique central : tables de base de données (ou collections), leurs relations, et les API qui lisent/écrivent les données. En pratique, c'est moins « l'IA a tout construit » que « l'IA a proposé une structure que nous pouvons implémenter et affiner ».
Ce qu'inclut typiquement un backend conçu par l'IA
Au minimum, l'IA peut générer :
- Schemas et entités : tables/collections comme
users, orders, subscriptions, plus champs et types de base.
- Relations : liens one-to-many et many-to-many (par ex. une commande a plusieurs lignes ; un produit appartient à plusieurs catégories).
- Contraintes et validations : champs requis, clés uniques, plages basiques, statuts de type enum, et règles d'intégrité référentielle simples.
- Surface API : endpoints CRUD, formes de requête/réponse, patterns de pagination, formats d'erreur, et parfois des suggestions de versioning.
Ce qu'elle ne peut pas décider sans votre contexte métier
L'IA peut inférer des motifs « typiques », mais elle ne peut pas choisir de façon fiable le bon modèle lorsque les exigences sont ambiguës ou spécifiques au domaine. Elle ne saura pas vos vraies politiques pour :
- Ce qui compte comme un « user » (rôles ? organisations ? comptes invités ?).
- Quels champs sont légalement requis, sensibles ou soumis à des règles de rétention.
- Quelles actions doivent être auditables, réversibles ou nécessiter une approbation.
- La vraie signification des statuts (par ex.
cancelled vs refunded vs voided).
La bonne attente : copilote, pas autorité finale
Considérez la sortie de l'IA comme un point de départ structuré et rapide — utile pour explorer des options et détecter des oublis — mais pas comme une spécification prête à être déployée telle quelle. Votre rôle est d'apporter des règles nettes et des cas limites, puis de relire ce que l'IA a produit comme vous le feriez pour le premier jet d'un ingénieur junior : utile, parfois impressionnant, parfois erroné de façon subtile.
Entrées qui déterminent la qualité du résultat de l'IA
L'IA peut rédiger un schéma ou une API rapidement, mais elle ne peut pas inventer les faits manquants qui rendent un backend adapté à votre produit. Les meilleurs résultats viennent quand vous traitez l'IA comme un concepteur junior rapide : vous fournissez des contraintes claires et elle propose des options.
Avant de demander des tables, endpoints ou modèles, notez l'essentiel :
- Entités et définitions clés : quels objets existent (p. ex. User, Subscription, Order) et ce que chacun signifie dans votre activité.
- Workflows principaux : les parcours majeurs (inscription, paiement, remboursements, approbations) et les états par lesquels ils passent.
- Rôles et permissions : qui peut faire quoi (admin, staff, client, auditeur) et ce qu'il faut restreindre.
- Besoins de reporting et d'analytics : les questions auxquelles vous devez répondre plus tard (revenu mensuel, rétention par cohorte, métriques SLA), y compris les dimensions de « group by ».
- Intégrations et identifiants externes : prestataires de paiement, CRM, systèmes d'identité — et quels IDs doivent être stockés.
- Échelle et attentes de performance : ordre de grandeur (centaines vs millions d'enregistrements) et attentes de latence.
- Conformité et rétention : GDPR/CCPA, logs d'audit, règles de suppression, résidence des données, périodes de rétention.
- Réalités opérationnelles : backfills, imports, overrides manuels, et scénarios « l'équipe support doit pouvoir modifier X ».
Pourquoi des exigences floues créent des modèles fragiles
Quand les exigences sont vagues, l'IA a tendance à « deviner » des valeurs par défaut : champs optionnels partout, colonnes de statut génériques, propriété floue, et nommage incohérent. Cela mène souvent à des schémas qui semblent raisonnables mais cassent en production — surtout autour des permissions, du reporting et des cas limites (remboursements, annulations, expéditions partielles, approbations en plusieurs étapes). Vous en paierez le prix plus tard avec des migrations, des contournements et des APIs confuses.
Modèle de contraintes réutilisable à copier
Utilisez ceci comme point de départ et collez-le dans votre prompt :
Product summary (2–3 sentences):
Entities (name → definition):
-
Workflows (steps + states):
-
Roles & permissions:
- Role:
- Can:
- Cannot:
Reporting questions we must answer:
-
Integrations (system → data we store):
-
Constraints:
- Compliance/retention:
- Expected scale:
- Latency/availability:
Non-goals (what we won’t support yet):
-
Où l'IA aide le plus : vitesse, cohérence, couverture
L'IA est à son meilleur lorsque vous la traitez comme une machine à produire des brouillons rapides : elle peut esquisser un modèle de données sensé et un ensemble d'endpoints correspondants en quelques minutes. Cette vitesse change votre façon de travailler — pas parce que la sortie est « magique », mais parce que vous pouvez itérer sur quelque chose de concret tout de suite.
Vitesse : de la page blanche au squelette exploitable
Le plus grand gain est d'éliminer le démarrage à froid. Donnez à l'IA une courte description des entités, des flux utilisateurs clés et des contraintes, et elle peut proposer des tables/collections, des relations et une surface API de base. C'est particulièrement précieux quand il faut un prototype rapidement ou quand vous explorez des exigences instables.
La vitesse rapporte le plus sur :
- Des prototypes pour valider un concept avec de vrais flux de données
- Des outils internes où une structure « suffisante » vaut mieux qu'une modélisation parfaite
- Les premières itérations d'un produit où vous prévoyez de réécrire des parties
Les humains se fatiguent et dérivent. L'IA, non — elle répète donc bien les conventions à l'échelle :
- schémas de nommage cohérents (ex.
createdAt, updatedAt, customerId)
- formes d'endpoints prévisibles (
/resources, /resources/:id) et payloads
- paramètres standards de pagination et filtrage
Cette cohérence facilite la documentation, les tests et la passation à un autre développeur.
Couverture : « avons-nous oublié un endpoint ? »
L'IA est aussi bonne pour la complétude. Si vous demandez un CRUD complet plus opérations communes (recherche, liste, mises à jour en masse), elle générera en général une surface de départ plus complète qu'un brouillon humain bâclé.
Un gain rapide courant est la standardisation des erreurs : une enveloppe d'erreur uniforme (code, message, details) sur tous les endpoints. Même si vous la peaufinez ensuite, partir d'une forme unique évite un mélange désordonné d'erreurs ad hoc.
L'état d'esprit clé : laissez l'IA produire les 80 % initiaux rapidement, puis consacrez votre temps aux 20 % nécessitant du jugement — règles métier, cas limites et le « pourquoi » derrière le modèle.
Modes d'échec typiques dans les schémas générés par l'IA
Les schémas générés par l'IA ont souvent l'air « propres » au premier abord : tables ordonnées, noms sensés, relations qui collent au chemin heureux. Les problèmes surgissent quand de vraies données, de vrais utilisateurs et de vrais workflows frappent le système.
Normalisation : trop ou pas assez
L'IA peut osciller entre deux extrêmes :
- Sur-normalisation : tout fractionner en de nombreuses tables (ex. tables séparées pour chaque attribut), rendant les requêtes courantes coûteuses et multipliant la complexité des jointures.
- Sous-normalisation : entasser des champs répétitifs dans une même table (ex. plusieurs colonnes d'adresse, flags de statut dénormalisés) qui deviennent difficiles à valider et à mettre à jour.
Test rapide : si vos pages les plus courantes nécessitent 6+ jointures, vous êtes peut-être sur-normalisé ; si une mise à jour exige de modifier la même valeur dans de nombreuses lignes, vous êtes peut-être sous-normalisé.
Cas limites manquants mais cruciaux en production
L'IA omet fréquemment des exigences « ennuyeuses » qui orientent la conception réelle :
- Multi-tenant : oublier
tenant_id sur des tables, ou ne pas appliquer le scope tenant dans les contraintes uniques.
- Soft deletes : ajouter
deleted_at sans adapter les règles d'unicité ou les patterns de requête pour exclure les supprimés.
- Audit : absence de
created_by/updated_by, historique des changements ou logs d'événements immuables.
- Fuseaux horaires : mélanger
date et timestamp sans règle claire (stockage en UTC vs affichage local), provoquant des bugs "off-by-one".
Mauvaises hypothèses sur l'unicité et le cycle de vie
L'IA peut deviner :
- qu'un champ est globalement unique alors qu'il ne l'est que par tenant (ex.
invoice_number),
- qu'un champ est requis alors qu'il est optionnel lors de l'onboarding,
- qu'un statut unique suffit alors qu'il faut un cycle de vie (draft → active → suspended → archived).
Ces erreurs se traduisent souvent par des migrations maladroites et des contournements applicatifs.
La plupart des schémas générés n'intègrent pas la manière dont vous allez interroger :
- absence d'index composites pour filtres fréquents (
tenant_id + created_at),
- pas de plan pour les « hot paths » (derniers éléments, compteurs non lus),
- forte dépendance à des champs JSON sans stratégie d'indexation.
Si le modèle ne peut pas décrire les 5 requêtes principales de votre appli, il ne peut pas concevoir un schéma fiable pour elles.
Conception d'API : ce que l'IA fait bien et se trompe
L'IA produit souvent une API qui « ressemble » à un standard. Elle reflétera des patterns familiers depuis des frameworks populaires et des APIs publiques, ce qui peut faire gagner beaucoup de temps. Le risque est qu'elle optimise pour ce qui paraît plausible plutôt que pour ce qui est correct pour votre produit, vos données et vos évolutions futures.
Ce que l'IA réussit généralement
Notions de ressource. Donné un domaine clair, l'IA choisit en général des noms et structures URL sensés (ex. /customers, /orders/{id}, /orders/{id}/items). Elle répète aussi souvent des conventions de nommage cohérentes.
Scaffolding d'endpoints courant. L'IA inclut généralement l'essentiel : endpoints list vs detail, create/update/delete, et des formes de requête/réponse prévisibles.
Conventions de base. Si vous le demandez explicitement, elle peut standardiser pagination, filtrage et tri (ex. ?limit=50&cursor=... pour pagination par curseur ou ?page=2&pageSize=25 pour page-based), ainsi que ?sort=-createdAt et des filtres comme ?status=active.
Où l'IA se trompe souvent
Abstractions qui fuient. Un échec classique consiste à exposer des tables internes directement comme « ressources », surtout quand le schéma contient des tables de jointure, des champs dénormalisés ou des colonnes d'audit. Vous obtenez des endpoints comme /user_role_assignments qui reflètent un détail d'implémentation plutôt que le concept côté utilisateur (« rôles d'un utilisateur »). Cela rend l'API plus difficile à utiliser et à faire évoluer.
Gestion d'erreur incohérente. L'IA peut mélanger les styles : parfois renvoyer 200 avec un corps d'erreur, parfois utiliser des 4xx/5xx. Vous voulez un contrat clair :
- Utiliser les codes HTTP appropriés (
400, 401, 403, 404, 409, 422)
- Une enveloppe d'erreur cohérente (ex.
{ "error": { "code": "...", "message": "...", "details": [...] } })
Versioning mis de côté. Beaucoup de designs générés négligent une stratégie de versioning jusqu'à ce que cela devienne douloureux. Décidez dès le jour 1 si vous utiliserez un versioning par chemin (/v1/...) ou par en-tête, et définissez ce qui constitue un changement breaking. Même si vous ne bumperez jamais la version, avoir des règles évite des ruptures accidentelles.
Bon réflexe
Utilisez l'IA pour la vitesse et la cohérence, mais traitez la conception d'API comme une interface produit. Si un endpoint reflète votre base de données plutôt que le modèle mental de l'utilisateur, c'est un indice que l'IA a optimisé pour la génération facile — pas pour l'utilisabilité à long terme.
Un flux pratique pour utiliser l'IA sans perdre le contrôle
Verrouillez le comportement avec des tests
Transformez vos invariants en vérifications répétables pour que l'ébauche de l'IA reste fiable.
Considérez l'IA comme un concepteur junior rapide : excellente pour produire des brouillons, pas responsable du système final. L'objectif est d'exploiter sa vitesse tout en conservant une architecture intentionnelle, révisable et pilotée par les tests.
Si vous utilisez un outil vibe-coding comme Koder.ai, cette séparation des responsabilités devient encore plus importante : la plateforme peut brièvement esquisser et implémenter un backend (par ex. services Go avec PostgreSQL), mais vous devez définir les invariants, limites d'autorisation et règles de migration que vous êtes prêts à accepter.
Une boucle récurrente : prompt → brouillon → revue → tests → révision
Commencez par un prompt précis qui décrit le domaine, les contraintes et « ce qu'est la réussite ». Demandez d'abord un modèle conceptuel (entités, relations, invariants), pas des tables.
Iterez ensuite selon une boucle fixe :
- Prompt : énoncez exigences, non-goals, hypothèses d'échelle et conventions de nommage.
- Draft : demandez à l'IA un modèle conceptuel + un schéma de première passe + des contrats d'API.
- Review : vérifiez la justesse métier, les cas limites et la cohérence avec les décisions produit.
- Tests : générez ou écrivez des tests qui traduisent les décisions (règles de validation, autorisation, idempotence, sécurité des migrations).
- Revise : réinjectez ce qui a échoué (retours de revue + échecs de tests) et demandez une version corrigée.
Cette boucle fonctionne car elle transforme les suggestions de l'IA en artefacts prouvables ou rejetables.
Séparer le modèle conceptuel du schéma physique et des contrats d'API
Gardez trois couches distinctes :
- Modèle conceptuel : ce qui importe au métier (ex. « Subscription peut être mise en pause », « Invoice doit référencer le prix du plan immuable au moment de l'achat »).
- Schéma physique : comment vous le stockez (tables/collections, indexes, contraintes, partitionnement).
- Contrats d'API : comment les clients interagissent (ressources, payloads, codes d'erreur, stratégie de versioning).
Demandez à l'IA de sortir ces sections séparément. Quand quelque chose change (ex. un nouveau statut), mettez à jour la couche conceptuelle d'abord, puis réconciliez le schéma et l'API. Cela réduit les couplages accidentels et facilite les refactors.
Conserver une traçabilité des décisions avec des notes légères
Chaque itération doit laisser une trace. Utilisez de courts résumés de type ADR (une page ou moins) qui capturent :
- Décision : ce que vous avez choisi (ex. « soft delete via
deleted_at »).
- Rationnel : pourquoi (exigences d'audit, flux de restauration).
- Alternatives envisagées : et pourquoi rejetées.
- Conséquences : impact sur les migrations, complexité des requêtes, comportement de l'API.
Quand vous réinjectez un retour à l'IA, incluez les notes de décision pertinentes verbatim. Cela empêche le modèle d'« oublier » les choix antérieurs et aide l'équipe à comprendre le backend des mois plus tard.
Prompts qui produisent de meilleurs schémas et API
L'IA est plus facile à orienter quand vous traitez le prompting comme un exercice d'écriture de spec : définissez le domaine, énoncez les contraintes, et exigez des livrables concrets (DDL, tableau d'endpoints, exemples). Le but n'est pas « être créatif » mais « être précis ».
Prompts pour entités et relations (avec contraintes)
Demandez un modèle de données et les règles qui le rendent consistant.
- « Design a relational schema for subscriptions with entities: User, Plan, Subscription, Invoice. Include cardinalities, unique constraints, and soft-delete strategy. Rules: one active subscription per user; invoices must reference immutable plan price at purchase time; store currency as ISO code; timestamps in UTC. »
Si vous avez déjà des conventions, précisez-les : style de nommage, type d'ID (UUID vs bigint), politique de nullable, et attentes d'indexation.
Prompts pour endpoints et contrats (avec exemples)
Demandez un tableau d'API avec des contrats explicites, pas juste une liste de routes.
- « Propose REST endpoints for Subscription management. For each endpoint: method, path, auth, query params, request JSON, response JSON, error codes, and idempotency guidance. Include examples for success and two failure cases. »
Ajoutez le comportement métier : style de pagination, champs de tri, et fonctionnement du filtrage.
Prompts pour migrations et compatibilité ascendante
Faites penser le modèle en releases.
- « We’re adding
billing_address to Customer. Provide a safe migration plan: forward migration SQL, backfill steps, feature-flag rollout, and a rollback strategy. API must remain compatible for 30 days; old clients may omit the field. »
Anti-patterns à éviter dans les prompts
Les prompts vagues produisent des systèmes vagues. Évitez :
- « Design the database for an e-commerce app » (trop large)
- « Make it scalable and secure » (sans contraintes mesurables)
- « Generate the best schema » (sans règles métier)
- « Create APIs for everything » (pas de priorisation)
Quand vous voulez de meilleurs résultats, resserrez le prompt : spécifiez les règles, les cas limites, et le format du livrable.
Checklist de revue humaine avant mise en production
Transformez vos prompts en backend
Élaborez un schéma, des API et des services à partir d'un seul prompt de chat dans Koder.ai.
L'IA peut esquisser un backend correct, mais le mettre en production nécessite toujours une passe humaine. Considérez cette checklist comme une « gate » de release : si vous ne pouvez pas répondre à un point avec assurance, arrêtez et corrigez avant que cela ne devienne des données de production.
Checklist schéma (tables, collections, colonnes)
- Clés primaires : chaque table a une PK claire. Si vous utilisez des UUIDs, confirmez la stratégie de génération (base vs app) et l'indexation.
- Clés étrangères & contraintes : ajoutez des FK quand les relations sont réelles. Vérifiez les règles ON DELETE/ON UPDATE (restrict vs cascade vs set null) et assurez-vous qu'elles sont intentionnelles.
- Unicité : imposez l'unicité dans la base (pas seulement en code) : emails, IDs externes, contraintes composites (ex.
(tenant_id, slug)).
- Nullabilité : revoyez chaque champ nullable. Si « inconnu » diffère de « vide », modélisez-le explicitement.
- Indexes : ajoutez des index pour filtres/tri/jointures fréquents. Évitez des index sur des champs basse-cardinalité inutiles.
- Cohérence de nommage : choisissez des conventions (singulier vs pluriel, suffixe
_id, timestamps) et appliquez-les uniformément.
Décisions d'intégrité des données (coûteuses à changer)
Consignez par écrit les règles du système :
- Intégrité référentielle : quelles relations ne doivent jamais casser ? Quelles relations peuvent être best-effort ?
- Règles de cascade : si un parent est supprimé, les enfants doivent-ils être supprimés, orphelinés ou bloqués ?
- Stratégie soft delete : si vous utilisez soft delete, veillez à ce que les requêtes ne « ressuscitent » pas des enregistrements supprimés. Décidez si les contraintes uniques doivent ignorer les lignes soft-deleted.
Checklist API (comportement et sécurité)
- Auth & authorization : identifiez qui peut appeler chaque endpoint et ce qu'il peut accéder (surtout en multi-tenant).
- Validation : validez types, plages, formats et règles cross-field. Ne comptez pas uniquement sur des erreurs DB pour la validation.
- Rate limits & protection : ajoutez des valeurs par défaut sensées, par utilisateur/token/IP si nécessaire.
- Idempotence : pour les opérations create/paiement, supportez des idempotency keys ou IDs déterministes.
- Erreurs cohérentes : standardisez la forme d'erreur et les codes HTTP. Assurez-vous que les messages d'erreur ne divulguent pas d'internes sensibles.
Avant le merge, exécutez un test « happy path + worst path » : une requête normale, une requête invalide, une requête non autorisée, un scénario à fort volume. Si le comportement de l'API vous surprend, il surprendra aussi vos utilisateurs.
Stratégie de test pour les backends conçus par l'IA
L'IA peut générer un schéma et une surface API plausibles rapidement, mais elle ne prouve pas que le backend se comporte correctement sous trafic réel, données réelles et évolutions. Traitez la sortie de l'IA comme un brouillon et ancrez-la avec des tests qui verrouillent le comportement.
Tests de contrat pour les API
Commencez par des tests de contrat qui valident requêtes, réponses et sémantiques d'erreur — pas seulement les "happy paths". Construisez une petite suite qui s'exécute contre une instance réelle (ou container) du service.
Concentrez-vous sur :
- codes de statut et corps d'erreur (ex. 400 vs 404 vs 409)
- cas limites de validation (chaînes vides, payloads surdimensionnés, champs inattendus)
- stabilité de la pagination et du tri (ordre cohérent, exactitude du curseur)
- idempotence des endpoints create/update (retries sûrs, idempotency keys si utilisés)
Si vous publiez un spec OpenAPI, générez des tests à partir de celle-ci — mais ajoutez aussi des cas écrits à la main pour les parties délicates que le spec ne peut pas exprimer (règles d'autorisation, contraintes métier).
Tests de migration et plans de rollback
Les schémas générés par l'IA manquent souvent de détails opérationnels : valeurs par défaut sûres, backfills et réversibilité. Ajoutez des tests de migration qui :
- appliquent les migrations depuis une DB vide et depuis un snapshot ancien « dirty »
- vérifient le comportement des contraintes (uniques, FK) après backfill
- exercent le rollback (ou du moins un plan forward-fix) pour chaque migration
Gardez un plan de rollback scripté pour la production : que faire si une migration est lente, bloque des tables ou casse la compatibilité.
Ne testez pas des endpoints génériques. Capturez des patterns représentatifs (vues principales, recherche, jointures, agrégations) et chargez-les.
Mesurez :
- latence p95/p99 par endpoint
- nombre de requêtes DB et requêtes lentes
- utilisation d'index (et index manquants)
C'est souvent là que les designs IA échouent : des tables « raisonnables » qui produisent des jointures coûteuses sous charge.
Tests sécurité essentiels
Ajoutez des checks automatiques pour :
- règles d'AuthZ (utilisateur A ne peut pas accéder aux ressources de B)
- injection (SQL/NoSQL, traversal de chemin, injection JSON)
- gestion des données sensibles (pas de secrets dans les logs, redaction correcte, chiffrement si nécessaire)
Même des tests de sécurité basiques évitent la catégorie d'erreurs la plus coûteuse de l'IA : des endpoints qui fonctionnent mais exposent trop.
Migrations, refactors et maintenabilité à long terme
L'IA peut esquisser un bon schéma « version 0 », mais votre backend vivra jusqu'à la version 50. La différence entre un backend qui vieillit bien et un autre qui s'effondre tient à la façon dont vous l'évoluez : migrations, refactors contrôlés et documentation claire des intentions.
Faire évoluer les schémas générés par l'IA en sécurité
Traitez chaque changement de schéma comme une migration, même si l'IA propose « simplement modifier la table ». Utilisez des étapes explicites et réversibles : ajouter d'abord de nouvelles colonnes, backfiller, puis resserrer les contraintes. Préférez les changements additifs (nouveaux champs, nouvelles tables) aux destructifs (rename/drop) jusqu'à ce que rien ne dépende de l'ancienne forme.
Quand vous demandez à l'IA des mises à jour de schéma, incluez le schéma courant et les règles de migration que vous suivez (par ex. « pas de suppression de colonnes ; utiliser expand/contract »). Cela réduit la probabilité qu'elle propose un changement correct en théorie mais risqué en production.
Gérer les breaking changes sans chaos
Les breaking changes sont rarement instantanés ; ce sont des transitions :
- Dépréciations : gardez les anciens champs/endpoints fonctionnels tout en journalisant leur usage.
- Double écriture : écrivez à la fois dans l'ancien et le nouveau champ/table pendant la fenêtre de transition.
- Backfills : exécutez un job one-shot ou incrémental pour remplir les nouvelles structures.
L'IA peut aider à produire le plan pas-à-pas (y compris snippets SQL et ordre de déploiement), mais vous devez valider l'impact d'exécution : verrous, transactions longues, et capacité de reprise du backfill.
Refactoriser sans tout réécrire
Les refactors doivent viser à isoler le changement. Si vous devez normaliser, scinder une table ou introduire un journal d'événements, conservez des couches de compatibilité : vues, code de traduction ou tables « shadow ». Demandez à l'IA de proposer un refactor qui préserve les contrats d'API existants et de lister ce qui doit changer dans les requêtes, index et contraintes.
Documenter les hypothèses pour que les prochains prompts restent cohérents
La plupart des dérives à long terme viennent du fait que le prochain prompt oublie l'intention originale. Gardez un court « contrat du modèle de données » : règles de nommage, stratégie d'ID, sémantique des timestamps, politique de soft-delete, et invariants (« un order total est dérivé, pas stocké »). Liez-le dans vos docs internes (ex. /docs/data-model) et réutilisez-le dans les prompts futurs pour que le système conçoive dans les mêmes limites.
Considérations de sécurité et de confidentialité
Obtenez une interface API claire
Créez des endpoints CRUD cohérents avec une pagination et des formats d'erreur prévisibles.
L'IA peut esquisser tables et endpoints rapidement, mais elle n'« assume » pas votre risque. Traitez sécurité et confidentialité comme des exigences de première classe à ajouter au prompt, puis vérifiez-les en revue — surtout pour les données sensibles.
Commencez par la classification des données
Avant d'accepter un schéma, étiquetez les champs par sensibilité (public, interne, confidentiel, régulé). Cette classification doit guider ce qui est chiffré, masqué ou minimisé.
Par exemple : les mots de passe ne doivent jamais être stockés (seulement des hash salés), les tokens doivent être court-terme et chiffrés au repos, et les PII comme email/téléphone peuvent nécessiter du masquage dans les vues admin et les exports. Si un champ n'est pas nécessaire, ne le stockez pas — l'IA ajoute souvent des attributs « nice to have » qui augmentent la surface d'exposition.
Contrôle d'accès : RBAC vs ABAC
Les APIs générées par l'IA partent souvent sur des « checks par rôle » simples. Le RBAC est facile à raisonner, mais il échoue sur les règles de propriété (« un utilisateur ne doit voir que ses factures ») ou des règles contextuelles (« le support ne peut voir les données que pendant un ticket actif »). L'ABAC gère mieux ces cas, mais exige des politiques explicites.
Soyez clair sur le pattern adopté et assurez-vous que chaque endpoint l'applique de façon cohérente — en particulier les endpoints de liste/recherche, points fréquents de fuite.
Éviter la journalisation accidentelle de champs sensibles
Le code généré peut logger des bodies complets, headers ou rows DB lors d'erreurs. Cela peut exposer mots de passe, tokens d'auth et PII dans les logs et outils APM.
Définissez des defaults : logs structurés, whitelist des champs à logger, redaction des secrets (Authorization, cookies, reset tokens), et évitez de logger des payloads bruts sur des échecs de validation.
Confidentialité, rétention et suppression
Concevez la suppression dès le départ : suppressions initiées par l'utilisateur, fermeture de compte, et workflows de « droit à l'oubli ». Définissez des fenêtres de rétention par classe de données (ex. événements d'audit vs événements marketing) et assurez-vous de pouvoir prouver ce qui a été supprimé et quand.
Si vous conservez des logs d'audit, stockez des identifiants minimaux, protégez-les par des accès plus stricts et documentez comment exporter ou supprimer des données si nécessaire.
Quand utiliser l'IA (et quand ne pas l'utiliser)
L'IA est à son meilleur quand vous la considérez comme un architecte junior rapide : excellente pour un premier brouillon, moins bonne pour arbitrer des choix critiques. La bonne question n'est pas « L'IA peut-elle concevoir mon backend ? » mais « Quelles parties l'IA peut-elle esquisser en toute sécurité, et quelles parties nécessitent une responsabilité experte ? »
Bons cas d'usage : brouillons, prototypes et patterns bien compris
L'IA peut faire gagner du temps réel quand vous construisez :
- petits prototypes, outils internes et MVPs dont l'objectif est d'apprendre vite
- systèmes CRUD avec entités familières (users, orders, subscriptions) et contraintes standards
- moments de page blanche : générer un schéma initial, une surface API et des conventions de nommage
Ici, l'IA apporte vitesse, cohérence et couverture — surtout si vous savez déjà comment le produit doit se comporter et pouvez repérer les erreurs.
Mauvais cas : domaines régulés, à haut risque ou très spécifiques
Soyez prudent (ou limitez l'IA à l'inspiration) quand vous travaillez dans :
- Finance : grands livres, réconciliation, traçabilité d'audit, règles d'idempotence qui doivent être exactes
- Santé : données patients, modèles de consentement, contraintes d'interopérabilité
- Domaines safety-critical : où une hypothèse « raisonnable » peut coûter cher
Dans ces domaines, l'expertise métier prime sur la vitesse de l'IA. Des exigences subtiles — juridiques, cliniques, comptables, opérationnelles — sont souvent absentes du prompt, et l'IA remplira les vides avec assurance.
Guide décisionnel : utiliser l'IA pour des brouillons, exiger une validation humaine
Règle pratique : laissez l'IA proposer des options, mais exigez une revue finale pour les invariants du modèle de données, les frontières d'autorisation et la stratégie de migration. Si vous ne pouvez pas nommer qui est responsable du schéma et des contrats d'API, n'expédiez pas un backend conçu par l'IA.
Prochaines étapes
Si vous évaluez des workflows et des garde-fous, consultez les guides associés dans /blog. Si vous voulez de l'aide pour appliquer ces pratiques à votre processus d'équipe, consultez /pricing.
Si vous préférez un flux de bout en bout où vous itérez via chat, générez une app fonctionnelle et conservez le contrôle via export de code et snapshots rollback-friendly, Koder.ai est conçu pour ce style de boucle build-and-review.