Ce que fait vraiment l'indexation de base de données
Un index de base de données est une structure de recherche séparée qui aide la base à trouver les lignes plus rapidement. Ce n’est pas une seconde copie de votre table. Pensez-y comme les pages d'index d'un livre : vous utilisez l'index pour sauter près du bon endroit, puis lisez la page exacte (la ligne) dont vous avez besoin.
Sans index, la base a souvent une seule option sûre : lire beaucoup de lignes pour vérifier lesquelles correspondent à votre requête. Cela peut aller quand une table compte quelques milliers de lignes. Quand la table atteint des millions de lignes, « vérifier plus de lignes » se transforme en plus de lectures disque, plus de pression mémoire et plus de travail CPU — la même requête qui paraissait instantanée commence à être lente.
Ce que change un index (et ce qu'il ne change pas)
Les index réduisent la quantité de données que la base doit inspecter pour répondre à des questions comme « trouve la commande avec l'ID 123 » ou « récupère les utilisateurs avec cet email ». Au lieu de tout balayer, la base suit une structure compacte qui resserre rapidement la recherche.
Mais l'indexation n'est pas une solution universelle. Certaines requêtes doivent encore traiter beaucoup de lignes (rapports larges, filtres peu sélectifs, agrégations lourdes). Et les index ont des coûts réels : espace de stockage supplémentaire et écritures plus lentes, parce que les INSERT et UPDATE doivent aussi mettre à jour l'index.
Ce que vous apprendrez dans ce guide
Vous verrez :
- pourquoi éviter les scans complets est le gros gain de vitesse
- comment les structures d'index courantes (comme le B-tree) rendent les recherches rapides
- quelles requêtes en profitent le plus, et quand elles n'aident pas
- comment choisir des index composites/couvrants et les valider avec un plan EXPLAIN
- comment maintenir les index dans le temps pour que les performances ne se dégradent pas en silence
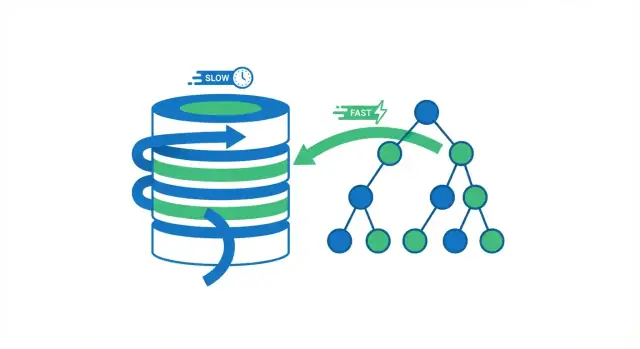
Le gain principal : éviter les scans complets de la table
Quand une base exécute une requête, elle a deux grandes options : parcourir toute la table ligne par ligne, ou sauter directement aux lignes qui correspondent. La plupart des gains d'index proviennent d'éviter des lectures inutiles.
Scan complet vs recherche indexée
Un scan complet de table est exactement ce que ça indique : la base lit chaque ligne, vérifie si elle correspond à la condition WHERE, puis retourne les résultats. C’est acceptable pour des petites tables, mais ça devient plus lent de manière prévisible à mesure que la table grandit — plus de lignes signifie plus de travail.
En utilisant un index, la base peut souvent éviter de lire la majorité des lignes. Au lieu de cela, elle consulte d'abord l'index (une structure compacte conçue pour la recherche) pour trouver où résident les lignes correspondantes, puis lit uniquement ces lignes spécifiques.
Une analogie simple
Pensez à un livre. Si vous voulez chaque page mentionnant « photosynthèse », vous pourriez lire tout le livre de la première à la dernière page (scan complet). Ou vous pourriez utiliser l'index du livre, sauter aux pages listées et ne lire que ces sections (recherche indexée). La deuxième approche est plus rapide parce que vous sautez presque toutes les pages.
Pourquoi moins de lectures signifie généralement des requêtes plus rapides
Les bases passent beaucoup de temps à attendre des lectures — surtout quand les données ne sont pas déjà en mémoire. Réduire le nombre de lignes (et de pages) que la base doit toucher réduit typiquement :
- les lectures disque/SSD
- le temps CPU passé à évaluer les filtres
- la pression mémoire due à l'extraction de données inutiles dans le cache
Quand le gain de vitesse apparaît
L'indexation aide surtout quand les données sont volumineuses et que le motif de requête est sélectif (par exemple, récupérer 20 lignes correspondantes sur 10 millions). Si votre requête retourne la plupart des lignes, ou si la table tient confortablement en mémoire, un scan complet peut être aussi rapide — voire plus rapide.
Les index fonctionnent parce qu'ils organisent les valeurs pour que la base puisse sauter près de ce que vous voulez au lieu de vérifier chaque ligne.
Index B-tree : l'outil de base par défaut
La structure d'index la plus courante dans les bases SQL est le B-tree (souvent écrit « B-tree » ou « B+tree »). Conceptuellement :
- les valeurs sont gardées triées
- l'index est divisé en pages (chunks) qui pointent vers d'autres pages, et finalement vers les lignes correspondantes
Parce qu'il est trié, un B-tree est excellent pour les recherches d'égalité (WHERE email = ...) et les requêtes par plage (WHERE created_at >= ... AND created_at < ...). La base peut naviguer vers le bon voisinage de valeurs puis scanner vers l'avant dans l'ordre.
Ce que signifie « logarithmique » (sans les maths)
On dit souvent que les recherches B-tree sont « logarithmiques ». Concrètement, ça veut dire ceci : quand votre table passe de milliers à millions de lignes, le nombre d'étapes pour trouver une valeur augmente lentement, pas proportionnellement.
Au lieu de « deux fois plus de données = deux fois plus de travail », c'est plutôt « beaucoup plus de données = seulement quelques étapes de navigation en plus », parce que la base suit des pointeurs à travers un petit nombre de niveaux dans l'arbre.
Index de hachage : rapides pour les correspondances exactes (avec des limites)
Certains moteurs proposent aussi des index hash. Ils peuvent être très rapides pour les recherches d'égalité exactes parce que la valeur est transformée en hash et utilisée pour trouver l'entrée directement.
Le compromis : les index de hachage n'aident généralement pas pour les plages ou les parcours ordonnés, et leur disponibilité/comportement varie selon les bases.
Les détails varient selon le moteur, l'idée reste la même
PostgreSQL, MySQL/InnoDB, SQL Server et d'autres stockent et utilisent les index différemment (taille de page, clustering, colonnes incluses, contrôles de visibilité). Mais le concept central est le même : les index créent une structure compacte et navigable qui permet à la base de localiser les lignes correspondantes avec beaucoup moins de travail que de scanner toute la table.
Les requêtes qui profitent le plus des index
Les index n'accélèrent pas le « SQL » en général — ils accélèrent des motifs d'accès spécifiques. Quand un index correspond à la façon dont votre requête filtre, joint ou trie, la base peut sauter directement aux lignes pertinentes au lieu de lire toute la table.
Les motifs de requête les plus favorables aux index
1) Filtres WHERE (surtout sur des colonnes sélectives)
Si votre requête restreint souvent une grosse table à un petit ensemble de lignes, un index est souvent la première piste. Un exemple classique est la recherche d'un utilisateur par identifiant.
Sans index sur users.email, la base peut devoir scanner chaque ligne :
SELECT * FROM users WHERE email = '[email protected]';
Avec un index sur email, elle peut localiser rapidement la ou les lignes correspondantes et s'arrêter.
2) Clés de JOIN (clés étrangères et clés référencées)
Les JOINs sont là où de petites inefficacités se transforment en gros coûts. Si vous joignez orders.user_id à users.id, indexer les colonnes de jointure (typiquement orders.user_id et la clé primaire users.id) aide la base à associer les lignes sans scanner à répétition.
3) ORDER BY (quand vous souhaitez des résultats déjà triés)
Le tri coûte cher quand la base doit récupérer beaucoup de lignes et les trier après coup. Si vous exécutez fréquemment :
SELECT * FROM orders WHERE user_id = 42 ORDER BY created_at DESC;
un index qui s'aligne sur user_id et la colonne de tri peut permettre au moteur de lire les lignes dans l'ordre souhaité plutôt que de trier un grand résultat intermédiaire.
4) GROUP BY (quand le groupement s'aligne avec un index)
Le groupement peut en bénéficier lorsque la base peut lire les données dans l'ordre groupé. Ce n'est pas garanti, mais si vous groupezez souvent par une colonne elle-même utilisée pour filtrer (ou naturellement clusterisée dans l'index), le moteur peut faire moins de travail.
Filtres par plage : un gain fréquent pour les B-trees
Les index B-tree sont particulièrement bons pour les conditions de plage — pensez aux dates, prix et requêtes « between » :
SELECT * FROM orders
WHERE created_at >= '2025-01-01' AND created_at < '2025-02-01';
Pour les tableaux de bord, rapports et écrans d'« activité récente », ce schéma est partout, et un index sur la colonne de plage produit souvent une amélioration immédiate.
Le thème est simple : les index aident le plus quand ils reflètent la manière dont vous recherchez et triez. Si vos requêtes correspondent à ces motifs d'accès, la base peut effectuer des lectures ciblées au lieu de scans larges.
Sélectivité : pourquoi certains index n'aident pas
Un index aide surtout quand il réduit fortement le nombre de lignes que la base doit toucher. Cette propriété s'appelle la sélectivité.
Ce que signifie la « sélectivité » en pratique
La sélectivité revient à : combien de lignes correspondent à une valeur donnée ? Une colonne hautement sélective a beaucoup de valeurs distinctes, donc chaque recherche correspond à peu de lignes.
- Haute sélectivité :
email, user_id, order_number (souvent uniques ou proches de l'être)
- Basse sélectivité :
is_active, is_deleted, status avec quelques valeurs communes
Avec une haute sélectivité, un index peut sauter directement à un petit ensemble de lignes. Avec une faible sélectivité, l'index pointe vers un énorme morceau de la table — la base doit donc encore lire et filtrer beaucoup.
Pourquoi les index sur des booléens déçoivent
Considérons une table de 10 millions de lignes et une colonne is_deleted où 98% sont false. Un index sur is_deleted n'aide pas beaucoup pour :
SELECT * FROM orders WHERE is_deleted = false;
L'ensemble correspondant est toujours presque toute la table. Utiliser l'index peut même être plus lent qu'un scan séquentiel parce que le moteur fait un travail supplémentaire en sautant entre les entrées d'index et les pages de la table.
Pourquoi la base peut ignorer votre index
Les planificateurs estiment des coûts. Si un index ne réduit pas suffisamment le travail — parce que trop de lignes correspondent, ou parce que la requête a besoin de la plupart des colonnes — ils peuvent choisir un scan complet.
La sélectivité change avec le temps
La distribution des données n'est pas fixe. Une colonne status peut commencer équilibrée, puis dériver vers une valeur dominante. Si les statistiques ne sont pas mises à jour, le planificateur peut prendre de mauvaises décisions, et un index qui aidait peut cesser d'être rentable.
Index composites et couvrants (et ordre des colonnes)
Les index mono-colonne sont un bon début, mais beaucoup de requêtes réelles filtrent sur une colonne et trient ou filtrent sur une autre. C'est là que les index composites (multi-colonnes) brillent : un seul index peut servir plusieurs parties de la requête.
Ordre des colonnes : la règle « de gauche à droite »
La plupart des bases (en particulier avec des B-trees) ne peuvent utiliser efficacement un index composite qu'à partir des colonnes les plus à gauche. Pensez à l'index comme trié d'abord par la colonne A, puis à l'intérieur par la colonne B, etc.
Cela signifie :
- un index sur (account_id, created_at) est excellent pour les requêtes filtrant par
account_id puis triant ou filtrant par created_at
- le même index n'est généralement pas utile pour une requête qui filtre uniquement par
created_at (car ce n'est pas la colonne la plus à gauche)
Un schéma pratique : timelines par compte
Une charge commune est « montre-moi les événements les plus récents pour ce compte ». Ce motif :
SELECT id, created_at, type
FROM events
WHERE account_id = ?
ORDER BY created_at DESC
LIMIT 50;
bénéficie souvent énormément de :
CREATE INDEX events_account_created_at
ON events (account_id, created_at);
La base peut sauter directement à la portion de l'index pour un compte et lire les lignes dans l'ordre temporel, au lieu de scanner et trier un grand ensemble.
Index couvrants : quand l'index est la réponse
Un index couvrant contient toutes les colonnes nécessaires à la requête, de sorte que la base peut retourner les résultats depuis l'index sans aller chercher les lignes de la table (moins de lectures, moins d'E/S aléatoires).
Attention : ajouter des colonnes augmente la taille de l'index et son coût.
Ne construisez pas d'index composites larges « au cas où »
Des index composites larges peuvent ralentir les écritures et consommer beaucoup d'espace. Ajoutez-les uniquement pour des requêtes identifiées de haute valeur, et vérifiez avec un plan EXPLAIN et des mesures réelles avant/après.
Compromis : ralentissements en écriture et stockage supplémentaire
Les index sont souvent décrits comme un « gain de vitesse gratuit », mais ils ne le sont pas. Les structures d'index doivent être maintenues à chaque modification de la table et elles consomment des ressources réelles.
INSERT/UPDATE/DELETE plus lents (car chaque index doit être mis à jour)
Quand vous INSERT une nouvelle ligne, la base n'écrit pas seulement la ligne — elle insère aussi des entrées correspondantes dans chaque index de la table. Il en va de même pour DELETE et de nombreux UPDATE.
C'est pourquoi « plus d'index » peut ralentir de manière notable les charges d'écriture. Un UPDATE touchant une colonne indexée peut être particulièrement coûteux : la base doit supprimer l'ancienne entrée d'index et en ajouter une nouvelle (et dans certains moteurs, cela peut provoquer des split de pages ou un rééquilibrage interne). Si votre appli fait beaucoup d'écritures — événements de commande, données capteurs, logs d'audit — indexer tout peut rendre la base lente même si les lectures sont rapides.
Espace disque supplémentaire et pression mémoire
Chaque index occupe de l'espace disque. Sur de grandes tables, les index peuvent rivaliser (ou dépasser) la taille de la table, surtout si vous avez plusieurs index qui se recoupent.
Cela affecte aussi la mémoire. Les bases s'appuient fortement sur le cache ; si votre working set inclut plusieurs gros index, le cache doit contenir plus de pages pour rester performant. Sinon, vous verrez plus d'E/S disque et des performances moins prévisibles.
L'équilibre pratique
L'indexation consiste à choisir ce qu'on accélère. Si votre charge est très axée lecture, davantage d'index peuvent valoir le coût. Si elle est écriture-intensive, priorisez les index qui servent vos requêtes les plus importantes et évitez les doublons. Une règle utile : ajoutez un index seulement si vous pouvez nommer la requête qu'il aide — et vérifiez que le gain en lecture l'emporte sur le coût en écriture et maintenance.
Ajouter un index devrait aider — mais vous pouvez (et devez) le vérifier. Les deux outils qui rendent cela concret sont le plan de requête (EXPLAIN) et des mesures réelles avant/après.
Lire le plan : l'index est-il réellement utilisé ?
Exécutez EXPLAIN (ou EXPLAIN ANALYZE) sur la requête exacte qui vous importe.
- Type de scan : Un Seq Scan / Full Table Scan signifie que la base lit toute la table. Un Index Scan / Index Seek (ou Index Range Scan) suggère qu'elle utilise un index pour restreindre les lignes.
- Lignes estimées vs réelles (surtout avec
EXPLAIN ANALYZE) : si le plan estimait 100 lignes mais en a réellement touché 100 000, l'optimiseur s'est trompé — souvent parce que les stats sont obsolètes ou que le filtre est moins sélectif que prévu.
- Étapes de tri : si vous voyez une opération explicite Sort, la base ordonne les résultats après les avoir récupérés. Si un nouvel index correspond au
ORDER BY, ce tri peut disparaître, ce qui représente un gain important.
Mesurer correctement : avant/après, mêmes conditions
Mesurez la requête avec les mêmes paramètres, sur un volume de données représentatif, et capturez à la fois la latence et les lignes traitées.
Faites attention au cache : la première exécution peut être plus lente parce que les données ne sont pas en mémoire ; les exécutions répétées peuvent paraître « résolues » même sans index. Pour éviter de vous tromper, comparez plusieurs exécutions et concentrez-vous sur le fait que le plan change (index utilisé, moins de lignes lues) en plus du temps brut.
Si EXPLAIN ANALYZE montre moins de lignes touchées et moins d'étapes coûteuses (comme des tris), vous avez prouvé que l'index aide — pas seulement espéré.
Erreurs courantes qui annulent les bénéfices d'un index
Vous pouvez ajouter le « bon » index et ne voir aucun gain si la requête est écrite d'une manière qui empêche la base de l'utiliser. Ces problèmes sont souvent subtils, car la requête renvoie toujours le bon résultat — elle est juste forcée dans un plan plus lent.
Anti-patterns qui bloquent l'utilisation d'un index
1) Wildcards en tête
Quand vous écrivez :
WHERE name LIKE '%term'
la base ne peut pas utiliser un index B-tree normal pour sauter au bon point de départ, car elle ne sait pas où dans l'ordre trié commence « %term ». Elle retombe souvent sur un scan de nombreuses lignes.
Alternatives :
- Si possible, utilisez une recherche avec préfixe :
WHERE name LIKE 'term%'.
- Si vous avez vraiment besoin d'une recherche « contient », envisagez un index spécialisé (ex. full-text/trigram) plutôt que d'espérer qu'un index standard aide.
2) Fonctions sur des colonnes indexées
Cela semble anodin :
WHERE LOWER(email) = '[email protected]'
Mais LOWER(email) transforme l'expression, donc l'index sur email ne peut pas être utilisé directement.
Alternatives :
- Stockez les données normalisées (par ex. emails en minuscules) et interrogez
WHERE email = ....
- Ou créez un index d'expression/fonction (selon la base) spécifiquement pour
LOWER(email).
Bloqueurs d'index cachés que l'on oublie
Casts implicites de type : comparer des types différents peut forcer la base à caster un côté, ce qui peut désactiver un index. Exemple : comparer une colonne entière à une chaîne littérale.
Collations/encodages mismatches : si la comparaison utilise une collation différente de celle de l'index (commun pour des colonnes textuelles entre locales), l'optimiseur peut éviter l'index.
Checklist rapide : « Pourquoi mon index n'est-il pas utilisé ? »
- La condition commence-t-elle par un wildcard (
LIKE '%x') ?
- Appliquez-vous une fonction à la colonne indexée (
LOWER(col), DATE(col), CAST(col)) ?
- Les types sont-ils identiques des deux côtés (pas de cast implicite) ?
- La collation/locale est-elle cohérente pour la comparaison ?
- Le prédicat est-il assez sélectif (n'épingle pas une grosse portion de la table) ?
- Filtrez/trierez-vous sur les colonnes les plus à gauche d'un index composite ?
- Avez-vous vérifié le plan avec
EXPLAIN pour confirmer le choix du moteur ?
Maintenance des index : statistiques, bloat et santé à long terme
Les index ne sont pas « posez et oubliez ». Avec le temps, les données changent, les motifs de requêtes évoluent et la forme physique des tables/index dérive. Un index bien choisi peut devenir progressivement moins efficace — ou même nuisible — si vous ne l'entretien pas.
Statistiques : la carte du planificateur peut devenir obsolète
La plupart des bases s'appuient sur un planificateur pour choisir comment exécuter une requête : quel index utiliser, quel ordre de jointure, et si une recherche d'index vaut le coup. Pour cela, le planificateur utilise des statistiques — des résumés sur la distribution des valeurs, le nombre de lignes et les biais.
Quand les statistiques sont obsolètes, les estimations de lignes du planificateur peuvent être complètement à côté. Cela conduit à de mauvais choix de plan, comme choisir un index qui retourne beaucoup plus de lignes qu'attendu, ou ignorer un index utile.
Correctif courant : planifiez des mises à jour régulières des stats (souvent ANALYZE). Après de gros chargements de données, des suppressions massives ou un fort turnover, rafraîchissez les stats plus tôt.
Bloat et fragmentation : quand les structures s'encrassent
À mesure que des lignes sont insérées, mises à jour et supprimées, les index peuvent accumuler du bloat (pages en trop qui ne contiennent plus de données utiles) et de la fragmentation (données dispersées qui augmentent les E/S). Le résultat : des index plus grands, plus de lectures et des scans plus lents — surtout pour les requêtes par plage.
Correctif courant : reconstruisez ou réorganisez périodiquement les index très utilisés quand ils ont grossi de façon disproportionnée ou que les performances dérivent. Les outils et impacts varient selon la base, considérez cela comme une opération mesurée, pas une règle générale.
Surveillez dans le temps, pas une seule fois
Mettez en place une supervision pour :
- requêtes lentes (latence, fréquence et pires cas)
- utilisation des index (index jamais utilisés vs indexes « chauds »)
- croissance de la taille des index et changements de plan soudains
Cette boucle de rétroaction vous aide à repérer quand la maintenance est nécessaire — et quand un index doit être ajusté ou supprimé. Pour plus sur la validation des améliorations, voyez /blog/how-to-prove-an-index-helps-explain-and-measurements.
Un workflow pratique pour ajouter le bon index
Ajouter un index doit être un changement délibéré, pas une supposition. Un workflow léger vous garde concentré sur des gains mesurables et évite la « prolifération » d'index.
1) Identifiez la vraie requête problématique
Commencez par des preuves : logs de requêtes lentes, traces APM, ou signalements utilisateurs. Choisissez une requête à la fois lente et fréquente — un rapport rare de 10s compte moins qu'une recherche commune de 200 ms.
Capturez le SQL exact et le motif de paramètres (par ex. : WHERE user_id = ? AND status = ? ORDER BY created_at DESC LIMIT 50). De petites différences changent l'index utile.
2) Mesurez une baseline
Enregistrez la latence actuelle (p50/p95), les lignes scannées et l'impact CPU/IO. Sauvegardez le plan actuel (EXPLAIN / EXPLAIN ANALYZE) pour pouvoir comparer plus tard.
3) Concevez l'index le plus petit utile
Choisissez des colonnes correspondant au filtre et au tri de la requête. Préférez l'index minimal qui empêche le plan de scanner de larges plages.
Testez en staging avec un volume de données proche de la production. Les index peuvent être prometteurs sur de petits jeux et décevants à grande échelle.
4) Créez-le en sécurité
Sur les grandes tables, utilisez les options online quand disponibles (par ex. PostgreSQL CREATE INDEX CONCURRENTLY). Planifiez les changements pendant les périodes de moindre trafic si votre base peut verrouiller les écritures.
5) Validez avec des preuves avant/après
Relancez la même requête et comparez :
- la forme du plan (est-ce passé d'un scan complet à un accès par index ?)
- le temps d'exécution et les lignes scannées
- l'impact sur les écritures (latence d'insert/update)
6) Ayez un plan de rollback
Si l'index augmente le coût des écritures ou surcharge la mémoire, supprimez-le proprement (par ex. DROP INDEX CONCURRENTLY si disponible). Gardez la migration réversible.
7) Documentez le « pourquoi »
Dans la migration ou les notes de schéma, indiquez quelle requête sert l'index et quelle métrique s'est améliorée. Le futur vous (ou un coéquipier) saura pourquoi il existe et quand il peut être supprimé.
Où Koder.ai s'insère dans ce workflow
Si vous construisez un nouveau service et voulez éviter la « prolifération d'index » dès le départ, Koder.ai peut vous aider à itérer plus vite sur la boucle complète : générer une app React + Go + PostgreSQL depuis le chat, ajuster les migrations de schéma/index à mesure que les besoins changent, puis exporter le code source quand vous êtes prêt à reprendre manuellement. En pratique, cela facilite le passage de « cet endpoint est lent » à « voici le plan EXPLAIN, l'index minimal et une migration réversible » sans attendre une pipeline traditionnelle complète.
Quand l'indexation ne suffit pas (et que faire ensuite)
Les index sont un levier puissant, mais pas un bouton magique « accélérer ». Parfois, la partie lente d'une requête se produit après que la base a trouvé les bonnes lignes — ou votre motif de requête rend l'indexation inefficace.
Cas où l'indexation n'est pas la meilleure solution
Si votre requête utilise déjà un bon index mais reste lente, cherchez ces coupables fréquents :
- Pagination manquante ou incorrecte : récupérer la page 1 000 avec
OFFSET 999000 peut être lent même avec des index. Préférez la pagination par clé (keyset) (ex. « donne-moi les lignes après le dernier id/timestamp vu »).
- Retourner trop de données : sélectionner des lignes larges (
SELECT *) ou renvoyer des dizaines de milliers d'enregistrements peut créer un goulot sur le réseau, la sérialisation JSON ou le traitement applicatif.
- Inadéquations de schéma : jointures excessives, stockage de valeurs recherchables dans des blobs JSON/textes, ou mauvais types qui forcent des opérations coûteuses qu’un index ne peut pas masquer complètement.
Optimisations complémentaires souvent plus importantes
- Réécrire la requête : supprimez les jointures inutiles, évitez les fonctions sur colonnes indexées dans les WHERE, simplifiez les prédicats lourds en OR.
- Limiter colonnes et lignes : sélectionnez uniquement ce qui est nécessaire, ajoutez des
LIMIT sensés et paginez intentionnellement.
- Caching : mettez en cache les lectures chaudes au niveau applicatif ou utilisez un cache read-through pour les requêtes coûteuses et répétées.
- Partitionnement : si la plupart des requêtes visent les « données récentes », partitionnez par temps (ou une autre frontière naturelle) pour réduire l'espace de recherche.
Si vous voulez une méthode plus approfondie pour diagnostiquer les goulets d'étranglement, combinez ceci avec le workflow de /blog/how-to-prove-an-index-helps.
Priorisez : corrigez le plus gros goulot d'abord
Ne devinez pas. Mesurez où le temps est passé (exécution DB vs. lignes retournées vs. code applicatif). Si la base est rapide mais que l'API est lente, ajouter des index ne résoudra rien.
Checklist rapide