25 déc. 2025·8 min
Intégrations de livraison en Inde : téléversements CSV vs API transporteur
Intégrations de livraison en Inde : décidez ce qu'il faut automatiser ou garder manuel en comparant les téléversements CSV aux API des transporteurs, plus une checklist pratique des événements de suivi.
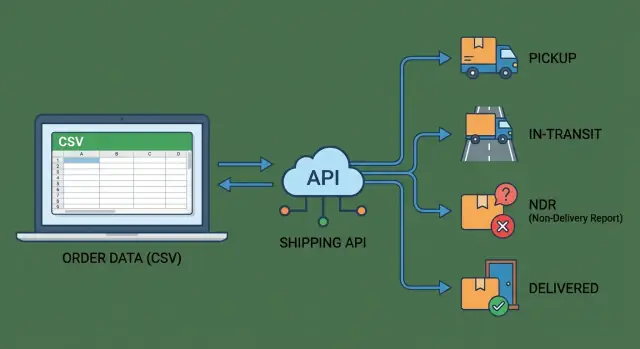
De quoi il s'agit vraiment : moins de relances sur la livraison
Quand le volume de commandes est faible, les mises à jour d'expédition se gèrent avec des vérifs rapides, une feuille de calcul et quelques messages au transporteur. À mesure que les commandes augmentent, les petits ratés s'additionnent : étiquettes créées en retard, collectes manquées, et suivi qui stagne.
Le schéma est familier : les clients demandent « Où est ma commande ? » Le support demande à l'ops. Ops vérifie un portail. Quelqu'un met à jour manuellement un statut qui aurait dû se mettre à jour tout seul.
Une intégration signifie simplement que votre système sait envoyer des données d'expédition (adresse, poids, COD, valeur facture) et récupérer des données d'expédition (numéro AWB, confirmation de pickup, scans de suivi, résultats de livraison) de façon fiable. « Fiable » compte parce que ça doit fonctionner tous les jours, pas seulement quand quelqu'un pense à téléverser un fichier.
C'est pour ça que cette comparaison a de l'importance :
- Un flux de téléversement CSV est la baseline. Facile à démarrer, mais dépend des personnes pour répéter les mêmes étapes à l'heure.
- Une intégration API transporteur complète est la version toujours connectée. Elle peut créer des envois, récupérer des scans de suivi et réagir aux exceptions sans attendre un travail manuel.
La plupart des équipes ne veulent pas « plus de tech ». Elles veulent moins de retards, moins de corrections manuelles et un suivi en lequel tout le monde a confiance. Réduisez les relances (clients et équipes internes), et vous réduisez généralement aussi les remboursements, les coûts de ré-attempt et les tickets support.
Où le travail d'expédition déraille dans les opérations réelles
La plupart des équipes commencent par une routine simple : réserver des pickups, imprimer des étiquettes, coller des numéros de suivi dans une feuille, et répondre quand les clients demandent des nouvelles. Ça marche à faible volume, mais les fissures apparaissent vite en Inde, surtout quand vous jonglez avec plusieurs transporteurs, du COD, et une qualité d'adresse inégale.
Les étapes manuelles ne semblent pas lourdes individuellement. Quelqu'un choisit un transporteur, crée l'envoi, télécharge les étiquettes, et s'assure que le bon colis reçoit le bon airway bill (AWB). Puis quelqu'un d'autre met à jour le statut de la commande, partage le suivi, et vérifie les preuves de livraison pour le COD.
Les points de défaillance les plus courants sont :
- Le mauvais AWB est collé sur le mauvais colis, entraînant un colis perdu ou un retour.
- Des envois en double sont créés après une ré-attempt ou une erreur de copie dans le tableur.
- Le suivi n'est pas mis à jour à temps, le support n'a pas de réponse claire et les clients perdent confiance.
- La collecte n'est pas confirmée, si bien que des commandes restent « prêtes à expédier » alors que le transporteur pense qu'aucune tournée n'est planifiée.
- Les montants COD ou les frais ne correspondent pas, créant des problèmes de rapprochement plus tard.
NDR signifie Non-Delivery Report. C'est ce qui arrive quand la livraison échoue (mauvaise adresse, client absent, refus, problème de paiement). La NDR crée du travail supplémentaire parce qu'elle oblige à prendre des décisions : appeler le client, corriger l'adresse, approuver une nouvelle tentative, ou marquer pour retour.
Ops subit la pression en premier. Le support reçoit les messages en colère. Les finances se retrouvent bloquées sur le rapprochement COD. Les clients ressentent le silence quand les statuts ne changent pas.
Option A : la baseline du téléversement CSV (ce que vous obtenez et ce que vous n'obtenez pas)
Le téléversement CSV est le point de départ par défaut pour beaucoup de setups d'expédition en Inde. Vous exportez un lot de commandes payées depuis votre boutique ou ERP, les mettez au format du transporteur ou de l'agrégateur, puis téléversez le fichier dans un tableau de bord pour générer AWB et étiquettes.
Ce que vous obtenez, c'est la simplicité. Il y a généralement peu de travail d'ingénierie, et vous pouvez être en production en une journée. Pour un faible volume ou une expédition prévisible (même adresse de pickup, petit éventail de SKUs, peu d'exceptions), un CSV quotidien peut être « suffisant » et facile à former.
Là où ça casse, c'est tout ce qui se passe après le téléversement. La plupart des équipes finissent par faire le même nettoyage tous les jours : corriger des lignes échouées parce qu'un pincode ou un format de téléphone ne correspond pas au modèle, retéléverser les fichiers corrigés, vérifier les doublons accidentels, et copier‑coller les numéros de suivi dans le storefront.
Ensuite vient la partie désordonnée : courir après les exceptions (problèmes d'adresse, problèmes de paiement, risque de RTO) à travers emails, appels et portails transporteur, et mettre à jour le statut à plusieurs endroits parce que le tableau de bord du transporteur n'est pas votre système de référence.
Le coût caché, c'est le temps et l'incohérence. Différents transporteurs attendent différentes colonnes et règles, donc « un CSV » se transforme vite en plusieurs versions plus des bricolages de tableur. Et parce que les mises à jour ne sont pas en temps réel, le support apprend souvent les retards uniquement quand un client se plaint.
Option B : intégration API transporteur complète (ce que ça débloque et ce que ça coûte)
Une intégration API complète signifie que votre système et les systèmes du transporteur communiquent directement. Au lieu de téléverser des fichiers, vous envoyez automatiquement les détails de commande et d'adresse, recevez une étiquette, et continuez à remonter les mises à jour de suivi sans que personne n'ait à vérifier plusieurs portails. C'est souvent à ce moment que l'expédition cesse d'être une corvée quotidienne et devient une infrastructure fiable.
Ce que ça débloque
La plupart des équipes commencent une intégration API transporteur pour trois actions principales : la réservation, les étiquettes et le suivi. Les capacités typiques incluent la création d'un envoi et l'obtention instantanée d'un AWB, la génération de l'étiquette d'expédition et des données de facture, la demande de pickup (lorsque supportée), et la récupération des scans de suivi en quasi‑temps réel.
Une fois que vous avez ces bases, vous pouvez aussi mieux gérer les exceptions, comme les problèmes d'adresse et les mises à jour d'état NDR.
Le gain est simple : expédition plus rapide, moins d'erreurs de copier‑coller, et des mises à jour clients plus claires. Si une commande est payée à 14h, votre système peut auto‑réserver l'envoi, imprimer l'étiquette et envoyer le numéro de suivi en quelques minutes, sans attendre une exportation CSV et un retéléversement.
Ce que ça coûte
Les intégrations API ne sont pas « installer et oublier ». Prévoyez du temps pour la mise en place, les tests et la maintenance continue.
Les sources d'effort habituelles :
- Règles spécifiques aux transporteurs (serviceabilité par pincode, tranches de poids, limites COD)
- Incohérences dans les codes de statut (le « RTO initiated » d'un transporteur peut être le « return in transit » d'un autre)
- Fiabilité des webhooks et logique de retry pour les événements manqués
- Formats d'étiquettes et exigences documentaires qui évoluent
- Sandboxes qui ne reflètent pas totalement la production
Si vous anticipez ces particularités tôt, la mise en place évolue proprement. Sinon, vous pouvez vous retrouver avec des envois réservés mais non collectés, ou des clients voyant des statuts confus parce que les événements de suivi n'ont pas été mappés correctement.
Ce qu'il faut automatiser vs garder manuel (une séparation pratique)
Une règle simple marche bien : automatisez les tâches qui se répètent plusieurs fois par jour et qui génèrent le plus de retouches quand quelqu'un fait une petite erreur.
En Inde, cela signifie généralement la réservation, les étiquettes et les mises à jour de suivi. Une seule faute de frappe ou un scan manqué peut déclencher une chaîne de relances.
Les étapes manuelles ont toujours leur place. Gardez‑les manuelles quand le volume est faible, quand les exceptions sont fréquentes, ou quand les processus transporteur ne sont pas assez constants pour faire confiance à l'automatisation.
Une séparation pratique par workflow :
- À automatiser en priorité : réservation d'envoi depuis votre système de commande, génération et impression d'étiquettes, récupération des statuts de suivi via pulls ou webhooks, alertes NDR avec file interne, et messages de confirmation de livraison pour votre équipe support.
- À garder manuel (jusqu'à avoir du volume) : choix du transporteur pour les cas limites, négociation de changements de pickup par téléphone, approbation des ré‑attempts COD risqués, et corrections d'adresse ponctuelles nécessitant du jugement.
Un tableau de décision rapide avant de construire quoi que ce soit :
| Facteur | Quand le manuel suffit | Quand l'automatisation paie |
|---|---|---|
| Volume quotidien | Moins d'environ 20/jour | 50+/jour ou pics fréquents |
| Nombre de transporteurs | 1 transporteur | 2+ transporteurs ou changements fréquents |
| Pression SLA | Livraison 3‑5 jours acceptable | Promesses jour même/next‑day, pénalités élevées |
| Taille de l'équipe | Personne ops dédiée | Rôles ops/support partagés |
Un point de contrôle simple : si votre équipe touche deux fois la même donnée (copier‑coller depuis la commande vers le portail transporteur, puis retour dans une feuille), cette étape est un bon candidat à l'automatisation.
Checklist des événements de suivi : pickup, in‑transit, NDR, livré
Arrêtez de courir après les mises à jour de suivi
Construisez une timeline de suivi qui synchronise les scans et réduit les relances quotidiennes du support.
Si vous voulez moins de « où est ma commande ? », traitez le suivi comme une chronologie d'événements, pas un seul statut. Cela a de l'importance en Inde, où un même envoi peut rebondir entre hubs, tentatives et retours.
Capturez ces étapes pour que votre équipe et vos clients voient la même histoire :
- Pickup : quand la collecte est planifiée, si elle a été tentée, et le résultat final (collecté ou échec). En cas d'échec, enregistrez la raison fournie par le transporteur pour agir sans appeler le livreur.
- In‑transit : le premier scan (souvent le véritable départ), les scans des hubs majeurs, les flags d'exception ou de retard, et « out for delivery ». Ce sont les points qui déclenchent le plus de questions du support.
- NDR (Non‑Delivery Report) : quand une NDR est levée, le code raison, si le client a été contacté, et la suite (reattempt prévu ou retour). Le temps est souvent compté ici.
- Livré (ou pas) : heure de livraison et preuves (nom, signature, référence photo) quand elles sont disponibles. Séparez « livraison échouée » et « retourné », les clients percevant ces issues très différemment.
Pour chaque événement, stockez les mêmes champs clés : timestamp, emplacement (ville et hub si disponible), texte brut du statut, statut normalisé, code raison, et la référence transporteur/AWB. Conserver les valeurs brutes et normalisées facilite les audits et les litiges avec les transporteurs.
Données dont vous avez besoin avant d'intégrer (pour éviter les pannes ultérieures)
Beaucoup d'intégrations faillent pour des raisons ennuyeuses : numéros de téléphone manquants, poids incohérents, ou absence d'accord sur quel système « possède » la vérité. Avant de toucher une API, verrouillez les données minimales que vous aurez toujours pour chaque commande.
Commencez par une baseline qui fonctionne aussi avec CSV. Si vous ne pouvez pas exporter ces champs de façon fiable, une API ne fera que propulser les erreurs plus vite :
- ID de commande (unique et jamais réutilisé)
- Adresse de livraison complète (nom, pincode, ville, état, repère si vous le collectez)
- Numéro de téléphone (format validé) et email (optionnel)
- Articles et infos d'expédition (SKU, quantité, poids net, dimensions si disponibles)
- Détails de paiement (montant COD, indicateur prépayé)
Ensuite, définissez ce que vous attendez en retour du transporteur, car ce sont vos « poignées » pour le reste. Au minimum, stockez l'ID d'expédition, le numéro AWB, le nom ou code du transporteur, la référence d'étiquette, et la date ou fenêtre de pickup.
Une décision évite des semaines de confusion : choisissez votre source unique de vérité pour le statut d'expédition. Si votre équipe continue de vérifier le portail transporteur et d'outrepasser votre système, les clients verront une chose pendant que le support en affiche une autre.
Un petit plan de mappage qui aligne tout le monde :
- Choisissez les statuts internes que vous utiliserez (par exemple : Created, Picked Up, In Transit, Out for Delivery, Delivered, NDR).
- Mappez chaque statut transporteur vers un statut interne (même si vous perdez du détail).
- Sauvegardez le texte brut du statut du transporteur séparément pour les audits.
- Décidez quels événements peuvent changer le statut automatiquement et lesquels nécessitent une action humaine.
Si vous construisez cela dans un outil comme Koder.ai, traitez ces champs et mappages comme des modèles de premier plan dès le départ, pour que les exports, le suivi et les rollback ne cassent pas quand vous ajoutez un second transporteur.
Étape par étape : passer du CSV à l'API sans chaos
Migrer depuis le CSV en toute sécurité
Commencez par une synchronisation de suivi en lecture seule, puis étendez à la réservation et à la prise en charge des collectes.
La voie la plus sûre est une série de petits basculements, pas une coupure unique. Ops doit continuer d'expédier pendant que l'intégration se renforce.
1) Verrouillez le périmètre avant d'écrire du code
Choisissez les transporteurs que vous utiliserez réellement, puis confirmez quelles actions vous nécessitez maintenant vs plus tard : réservation d'envoi, suivi, gestion NDR et retours (RTO). C'est important car chaque transporteur nomme les statuts différemment et expose des champs différents.
2) Intégrez le suivi d'abord (lecture seule)
Avant d'automatiser la réservation ou la création d'étiquettes, récupérez les événements de suivi dans votre système et affichez‑les à côté de la commande. C'est peu risqué car cela ne change pas la manière dont les colis sont créés.
Assurez‑vous de pouvoir récupérer les événements par AWB, et gérez les cas où l'AWB est manquant ou erroné.
3) Mappez les statuts, mais conservez la vérité brute
Créez un petit modèle de statut interne (pickup, in‑transit, NDR, delivered), puis mappez les statuts transporteur dedans. Sauvegardez aussi chaque payload d'événement brut exactement tel qu'il est reçu.
Quand un client dit « ça indique livré mais je ne l'ai pas reçu », les événements bruts aident le support à répondre rapidement.
4) Ajoutez l'automatisation NDR prudemment
Automatisez d'abord les parties faciles : détecter la NDR, l'assigner à une file, notifier le client, et définir des timers pour les fenêtres de ré‑tentative.
Gardez un override manuel pour les changements d'adresse et les cas spéciaux.
5) Puis ajoutez la réservation, les étiquettes et la planification de pickup
Quand le suivi est stable, ajoutez la réservation via API, la génération d'étiquettes et les demandes de pickup. Déployez par transporteur, en gardant le chemin CSV comme fallback pendant quelques semaines.
Testez avec des scénarios réels :
- Changement d'adresse après NDR
- Reattempt demandé mais non effectué
- RTO déclenché puis annulé
- Livraison partielle ou envois éclatés
- Scan de livraison sans OTP ni détail POD
Erreurs courantes qui provoquent des retards et des tickets support
La plupart des tickets d'expédition ne sont pas seulement « où est ma commande ? ». Ce sont des attentes mal alignées : votre système dit une chose, le transporteur une autre, et le client une troisième.
Un piège courant est de croire que le texte de statut est uniforme. Le même jalon peut s'exprimer par des phrases différentes selon les zones, types de service ou hubs. Si vous mappez par texte exact au lieu de normaliser en un petit ensemble d'états, votre dashboard et vos messages clients dérivent.
Erreurs qui créent des retards et des relances en plus :
- Ne sauvegarder que le dernier statut : écraser les événements fait disparaître la timeline qui explique ce qui s'est passé. Conservez l'historique complet avec timestamps et emplacement.
- Traiter la NDR comme un seul statut : la NDR est un processus. Vous avez besoin de la raison, de l'action prise, et de la date de prochaine tentative.
- Pas de gestion des événements tardifs ou hors ordre : les transporteurs peuvent envoyer des événements en lots, ou dans un ordre étrange. Sans réconciliation et mises à jour sûres, votre système peut osciller entre statuts.
- Absence de logique de retry et gestion du rate limit : les appels API échouent. Si vous ne retryez pas de façon sécurisée, vous perdez des mises à jour. Si vous retryez trop agressivement, vous êtes rate‑limited.
- Pas de plan de secours opérationnel : décidez ce qui se passe quand l'API est down. Pouvez‑vous basculer vers le CSV pour une journée, mettre en pause les notifications, ou marquer des commandes pour revue manuelle ?
Un exemple simple : un client appelle en disant que le colis a « été retourné ». Votre système n'affiche que « NDR ». Si vous aviez enregistré la raison NDR et l'historique des tentatives, l'agent pourrait répondre en un seul message au lieu d'escalader vers ops.
Vérifications rapides avant de considérer l'intégration « terminée »
Avant de déclarer la victoire, testez l'intégration comme ops et support l'utiliseront lors d'une journée chargée. Une mise à jour de statut transporteur qui arrive en retard, ou sans les bons détails, crée le même problème qu'une absence de mise à jour.
Réalisez un test « un envoi, bout à bout » sur au moins 10 commandes réelles à travers des pincodes et types de paiement (prépayé et COD). Choisissez une commande et mesurez le temps pour répondre :
- Où est‑elle maintenant ?
- Que s'est‑il passé avant ?
- Que fait‑on ensuite ?
Une checklist rapide qui attrape la plupart des lacunes :
- La preuve de pickup est visible rapidement : vous voyez la confirmation de pickup dans la fenêtre attendue, et vous pouvez distinguer « étiquette créée » et « physiquement collecté ».
- La NDR est exploitable, pas juste un statut : vous stockez le code raison NDR plus l'étape suivante (reattempt, appel, ou RTO), et vous pouvez changer cette décision.
- La timeline est facile à trouver : un agent peut récupérer l'historique complet d'un AWB en moins de 30 secondes, avec timestamps et scans de localisation.
- Le livré correspond à l'argent et aux retours : les livraisons se rapprochent avec les rapports de remise COD et les données de retour/RTO, afin que les finances ne courent pas après des incohérences le week‑end.
- Il existe un override manuel sûr : vous pouvez corriger une adresse, reprogrammer une livraison, ou réassigner à un autre transporteur si nécessaire, et chaque changement manuel est historisé.
Si vous construisez des écrans internes pour cela, gardez la première version plate : une recherche d'envoi, une timeline claire, et deux boutons (note manuelle et override).
Des outils comme Koder.ai peuvent vous aider à prototyper rapidement ce dashboard ops et à exporter le code source quand vous êtes prêt à en prendre la responsabilité. Si vous voulez explorer plus tard, vous pouvez le trouver sur koder.ai.
Exemple : une équipe D2C qui passe de 20 à 150 commandes/jour
Construisez comme le ferait un dev
Créez des outils internes en React avec un backend Go et des modèles de données PostgreSQL.
Une marque D2C de taille moyenne démarre à environ 20 commandes par jour, expédiant principalement dans une métropole. Elle utilise deux partenaires transporteurs. Le processus est simple : exporter les commandes, téléverser un CSV deux fois par jour, puis copier‑coller les numéros de suivi dans l'admin de la boutique.
À 150 commandes/jour sur trois transporteurs, cette routine commence à craquer. Les clients demandent « où est mon colis ? » et le support doit consulter trois portails.
Le pire, ce sont les NDR. Une tentative échoue, quelqu'un du transporteur appelle, et le suivi devient un fil WhatsApp. Les ré‑attempts sont oubliés, et un petit retard tourne en annulations et remboursements.
Ils migrent vers un setup qui synchronise les événements automatiquement. Désormais chaque mise à jour d'envoi atterrit au même endroit, et l'équipe travaille depuis une file unique au lieu de captures d'écran de chat.
Changements quotidiens :
- Les événements de suivi se synchronisent automatiquement à la commande (pickup, in‑transit, out for delivery, delivered).
- Les NDR créent une file visible avec une raison (problème d'adresse, client injoignable, problème de paiement).
- Des rappels de ré‑attempts s'envoient à heure fixe, de sorte que rien ne reste deux jours en suspens.
- Le support voit le statut le plus récent sans se connecter aux portails transporteur.
Tout n'est pas automatisé. Ils changent encore manuellement de transporteur pour des codes PIN limites ou des pics de saison. Quand un client appelle pour corriger une adresse, un humain vérifie avant de lancer un reattempt.
Prochaines étapes : choisissez un périmètre et construisez une première version simple
Décidez de ce dont vous avez besoin dans les 2–4 premières semaines. Le plus grand bénéfice vient généralement d'un suivi fiable et de moins de tickets « où est ma commande ? », pas d'avoir toutes les fonctionnalités dès le jour 1.
Choisissez un périmètre de départ qui correspond à votre douleur :
- Suivi uniquement : récupérez les événements du transporteur et synchronisez clients et support.
- Réservation + étiquette : créez des envois, générez des étiquettes et stockez automatiquement les AWB.
- Réservation + étiquette + pickup : ajoutez la planification et la confirmation de pickup, pour que ops ne court plus après les livreurs.
Avant d'écrire une seule ligne de code, verrouillez le langage que vous utiliserez en interne. Rédigez votre checklist d'événements (pickup, in‑transit, NDR, delivered) et mappez chaque statut transporteur vers un de vos statuts. Si vous zappez cette étape, vous finirez avec cinq variantes de « in transit » et des règles floues pour notifier un client, ouvrir une tâche NDR ou marquer une commande comme complète.
Déployez par phases (et gardez‑le sobre)
Un déploiement sûr ressemble à : un transporteur, une ligne (ou un entrepôt), puis l'expansion.
Faites tourner votre nouveau flux en parallèle avec votre processus CSV pendant un court laps de temps afin qu'ops puisse comparer AWB, étiquettes et mises à jour. Gardez un fallback simple : si l'appel API échoue, créez une tâche de réservation manuelle plutôt que de bloquer l'expédition.
Avancez vite sans vous enfermer
Si vous voulez aller vite, prototypez l'intégration API transporteur avec Koder.ai : définissez la table de stockage d'événements, les règles de mappage de statuts, et un petit dashboard ops (recherche par commande ou AWB, dernier événement, action suivante). Quand ça fonctionne comme votre équipe l'attend, exportez le code source et durcissez‑le avec des retries, du logging et des contrôles d'accès.
Une bonne première version n'est pas « complète ». C'est un transporteur qui fonctionne bout à bout, avec des événements propres, une responsabilité claire pour les NDR, et une vue quotidienne qui dit à ops ce qui nécessite de l'attention maintenant.
FAQ
When is a CSV upload workflow actually “good enough”?
Les téléversements CSV conviennent quand le volume est faible (par exemple, moins d'environ 20 commandes/jour), que vous n'utilisez qu'un seul transporteur et que les exceptions sont rares. Ils font aussi un bon filet de secours quand une API est indisponible. Le risque est que chaque étape manquée (téléversement tardif, mauvais modèle, erreurs de copier‑coller) se transforme en relances du support et en retards d'expédition.
What’s the clearest sign we should move from CSV to a courier API?
Un passage à l'API transporteur devient pertinent quand vous traitez ~50+ commandes/jour, utilisez 2+ transporteurs, ou avez des NDR/reattempts fréquents. Vous obtenez une réservation et des étiquettes plus rapides, un suivi quasi temps réel, et moins de mises à jour manuelles. Le coût principal est la mise en place et la maintenance continue pour gérer les règles spécifiques des transporteurs et le mappage des statuts.
What minimum order data should we standardize before integrating any courier?
Commencez par standardiser :
- ID de commande unique (jamais réutilisé)
- Adresse de livraison complète (nom, pincode, ville, état, repère si vous le collectez)
- Numéro de téléphone au format validé
- Détails article/colis (SKU, quantité, poids ; dimensions si disponibles)
- Infos de paiement (prépayé vs COD, montant COD)
Si ces champs sont incohérents dans vos exports, une API échouera plus vite et plus souvent qu'un CSV.
What shipping data should we always store back from the courier?
Conservez au minimum :
- Nom/code du transporteur
- ID d’expédition du transporteur (si fourni)
- Numéro AWB
- Référence/metadata de l’étiquette
- Date/fenêtre de pickup (si vous demandez un pickup)
Ce sont vos « poignées » pour récupérer le suivi, résoudre les incidents et répondre rapidement au support.
Which tracking events matter most to reduce “Where is my order?” tickets?
Suivez une timeline, pas un seul statut :
- Pickup planifié/tenté/confirmé (et raison d'échec)
- Scans en transit (premier scan, scans de hubs, out for delivery, exceptions)
- NDR levée (code raison, action prise, prochaine tentative/retour)
- Livré (heure et preuves si disponibles)
Pour chaque événement, conservez timestamp, emplacement, texte brut du statut, statut normalisé, code raison et AWB.
How should we handle NDRs without creating more chaos?
Traitez la NDR comme un workflow :
- Capturez le code raison NDR et l'heure de sa levée
- Mettez l'expédition dans une file interne avec un responsable
- Enregistrez la décision (appeler le client, correction d'adresse, reattempt, ou retour)
- Suivez la date/heure de la prochaine tentative et les résultats
Conservez une possibilité d'override manuel pour les corrections d'adresse et les reattempts COD risqués afin d'éviter des répétitions automatisées inappropriées.
How do we avoid confusing status mismatches across multiple couriers?
Définissez un petit ensemble d'états internes (Created, Picked Up, In Transit, Out for Delivery, Delivered, NDR, Returned). Mappez chaque événement transporteur dans l'un de ces états, mais sauvegardez aussi le texte brut du transporteur séparément. Ne mappez pas uniquement par texte exact — les transporteurs varient selon zone, type de service et hub.
What’s the safest way to migrate from CSV to an API integration?
Procédez par étapes :
- Récupérez les événements de suivi dans votre système (lecture seule)
- Normalisez les statuts et sauvegardez les payloads bruts pour les audits
- Ajoutez la détection NDR + file + notifications (avec override manuel)
- Automatisez ensuite la réservation, les étiquettes et les demandes de pickup
Gardez le CSV comme solution de secours pendant quelques semaines afin que l'expédition ne soit jamais bloquée.
What reliability features should we build so tracking doesn’t go stale?
Prévoyez les pannes par défaut :
- Utilisez des retries avec backoff pour les erreurs temporaires
- Gérez les limites de débit (ralentissez, ne spammez pas)
- Attendez des événements tardifs ou hors ordre et réconciliez en toute sécurité
- Loggez chaque requête/réponse et gardez l'idempotence pour éviter les doublons
- Définissez un plan de secours ops (tâche de réservation manuelle ou run CSV temporaire)
Cela évite des trous de suivi silencieux qui génèrent des tickets.
How do we prevent wrong AWBs, duplicates, and other costly ops mistakes?
Appliquez des garde‑fous en process et en données :
- Générez et imposez une clé d'expédition unique par commande/colis
- Rendez la réservation idempotente pour qu'un retry ne crée pas une seconde expédition
- Intégrez des workflows d'impression/scannage : vérifiez que l'AWB correspond au colis avant dispatch
- Bloquez la réutilisation d'AWB et signalez automatiquement les doublons
La plupart des colis « perdus » commencent par une confusion d'ID, pas par un problème purement transporteur.