Intégrations webhook fiables : signature, idempotence et débogage
Apprenez à créer des intégrations webhook fiables avec signature, clés d'idempotence, protection contre les replays et un flux de débogage rapide pour les incidents signalés par les clients.
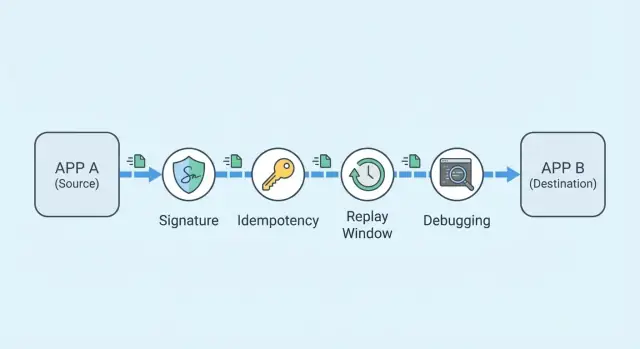
Pourquoi les webhooks échouent dans la vraie vie
Quand quelqu'un dit « les webhooks sont cassés », il veut généralement dire l'une des trois choses suivantes : les événements ne sont jamais arrivés, ils sont arrivés deux fois, ou ils sont arrivés dans un ordre déroutant. De leur point de vue, le système a « raté » quelque chose. De votre point de vue, le fournisseur a envoyé l'événement, mais votre endpoint ne l'a pas accepté, ne l'a pas traité, ou ne l'a pas enregistré comme vous l'attendiez.
Les webhooks circulent sur l'internet public. Les requêtes peuvent être retardées, réessayées, et parfois livrées hors ordre. La plupart des fournisseurs réessaient de façon agressive quand ils rencontrent des timeouts ou des réponses non-2xx. Cela transforme une petite perturbation (une base lente, un déploiement, une brève panne) en duplications et conditions de course.
De mauvais logs donnent l'impression que c'est aléatoire. Si vous ne pouvez pas prouver qu'une requête était authentique, vous ne pouvez pas agir en toute sécurité dessus. Si vous ne pouvez pas rattacher une plainte client à une tentative de livraison précise, vous vous retrouvez à deviner.
La plupart des échecs réels tombent dans quelques catégories :
- Événements « manquants » (vous avez timeouté, renvoyé une erreur, ou échoué après avoir accusé réception)
- Duplicatas (retries plus un handler qui n'est pas idempotent)
- Mauvais ordre (vous avez supposé que l'ordre de livraison = ordre des événements)
- Requêtes mystérieuses (pas de vérification de signature, vous ne pouvez pas distinguer le vrai du faux)
L'objectif pratique est simple : accepter les événements réels une fois, rejeter les faux, et laisser une trace claire pour pouvoir déboguer un signalement client en quelques minutes.
Comment les webhooks se comportent réellement
Un webhook n'est rien d'autre qu'une requête HTTP que le fournisseur envoie à un endpoint que vous exposez. Vous ne la récupérez pas comme pour un appel d'API. L'émetteur push quand quelque chose se produit, et votre travail est de la recevoir, répondre rapidement, et la traiter en toute sécurité.
Une livraison typique inclut un corps de requête (souvent JSON) plus des en-têtes qui vous aident à valider et tracer ce que vous avez reçu. Beaucoup de fournisseurs incluent un timestamp, un type d'événement (comme invoice.paid) et un ID d'événement unique que vous pouvez stocker pour détecter les duplicatas.
Ce qui surprend les équipes : la livraison est presque jamais « exactement une fois ». La plupart des fournisseurs visent le « au-moins-une-fois », ce qui signifie que le même événement peut arriver plusieurs fois, parfois à des minutes ou des heures d'intervalle.
Les retries surviennent pour des raisons banales : votre serveur est lent ou timeoute, vous renvoyez un 500, leur réseau ne voit pas votre 200, ou votre endpoint est momentanément indisponible pendant des déploiements ou des pics de trafic.
Un timeout est particulièrement délicat. Votre serveur peut recevoir la requête et même terminer son traitement, mais la réponse n'atteint pas l'émetteur à temps. Du point de vue du fournisseur, cela a échoué, donc il réessaie. Sans protection, vous traitez le même événement deux fois.
Un bon modèle mental consiste à considérer la requête HTTP comme une « tentative de livraison », pas comme « l'événement ». L'événement est identifié par son ID. Votre traitement doit se baser sur cet ID, pas sur le nombre de fois où le fournisseur vous appelle.
Signature des webhooks en termes simples
La signature de webhook est la façon dont l'émetteur prouve qu'une requête vient bien de lui et n'a pas été modifiée en chemin. Sans signature, n'importe qui qui devine votre URL de webhook peut poster de faux événements « paiement réussi » ou « utilisateur promu ». Pire encore, un événement réel peut être altéré en transit (montant, ID client, type d'événement) et paraître valide pour votre application.
Le schéma le plus courant est HMAC avec un secret partagé. Les deux côtés connaissent la même valeur secrète. L'émetteur prend la charge utile exacte (souvent le corps brut), calcule un HMAC avec ce secret, et envoie la signature avec la charge. Votre travail est de recalculer le HMAC sur les mêmes octets et de vérifier que les signatures correspondent.
Les données de signature sont généralement placées dans un en-tête HTTP. Certains fournisseurs incluent aussi un timestamp afin que vous puissiez ajouter une protection contre les replays. Plus rarement, la signature est intégrée dans le corps JSON, ce qui est plus risqué car les parsers ou la ré-sérialisation peuvent changer le format et casser la vérification.
Quand vous comparez des signatures, n'utilisez pas une égalité de chaîne classique. Les comparaisons simples peuvent révéler des différences de timing qui aident un attaquant à deviner la bonne signature après plusieurs essais. Utilisez une fonction de comparaison en temps constant fournie par votre langage ou librairie crypto, et rejetez à la moindre différence.
Si un client se plaint « votre système a accepté un événement que nous n'avons jamais envoyé », commencez par les vérifications de signature. Si la vérification échoue, vous avez probablement un secret incorrect ou vous hachez les mauvais octets (par exemple du JSON parsé au lieu du corps brut). Si elle passe, vous pouvez faire confiance à l'identité de l'émetteur et passer à la déduplication, l'ordre et les retries.
Étape par étape : vérifier une signature de webhook
Le traitement fiable des webhooks commence par une règle ennuyeuse mais essentielle : vérifiez ce que vous avez reçu, pas ce que vous souhaiteriez avoir reçu.
La façon sûre de vérifier
Capturez le corps de la requête brut exactement comme il est arrivé. Ne parsez pas et ne ré-serializez pas le JSON avant de vérifier la signature. De petites différences (espaces, ordre des clés, unicode) changent les octets et peuvent faire apparaître des signatures valides comme invalides.
Puis reconstituez exactement la charge signée attendue par votre fournisseur. Beaucoup de systèmes signent une chaîne comme timestamp + "." + raw_body. Le timestamp n'est pas décoratif : il sert à rejeter les requêtes anciennes.
Calculez l'HMAC en utilisant le secret partagé et l'algorithme requis (souvent SHA-256). Gardez le secret dans un coffre sécurisé et traitez-le comme un mot de passe.
Enfin, comparez votre valeur calculée à l'en-tête de signature en utilisant une comparaison en temps constant. Si ça ne correspond pas, renvoyez un 4xx et arrêtez. N'« acceptez » pas quand même.
Checklist d'implémentation rapide :
- Lisez le corps en octets une fois, stockez-le, et utilisez ces octets pour la vérification.
- Recréez la chaîne signée exactement, y compris séparateurs et format du timestamp.
- Calculez l'HMAC avec le bon secret et l'algorithme.
- Comparez les signatures en toute sécurité et rejetez les mismatches.
- Loggez pourquoi la vérification a échoué (en-tête manquant, mauvais timestamp, mismatch) sans logguer le secret ni la signature complète.
Un exemple rapide
Un client signale « les webhooks ont cessé de fonctionner » après l'ajout d'un middleware de parsing JSON. Vous observez des mismatches de signature, surtout sur les payloads volumineux. La solution est généralement de vérifier en utilisant le corps brut avant tout parsing, et de logger l'étape qui a échoué (par exemple, « en-tête de signature manquant » vs « timestamp hors fenêtre autorisée »). Ce détail seul réduit souvent le temps de debug de heures à minutes.
Clés d'idempotence : accepter une fois, en toute sécurité
Les fournisseurs réessaient parce que la livraison n'est pas garantie. Votre serveur peut être down pendant une minute, un saut réseau peut perdre la requête, ou votre handler peut timeouter. Le fournisseur suppose « peut-être que ça a fonctionné » et renvoie le même événement.
Une clé d'idempotence est le numéro de reçu que vous utilisez pour reconnaître un événement déjà traité. Ce n'est pas une mesure de sécurité et ne remplace pas la vérification de signature. Elle ne résoudra pas non plus les conditions de course à moins que vous ne l'enregistriez et la vérifiiez correctement en concurrence.
Le choix de la clé dépend de ce que le fournisseur vous fournit. Privilégiez une valeur stable à travers les retries :
- Event ID (meilleur quand un événement correspond à un changement métier unique)
- Delivery ID ou message ID (meilleur quand les retries gardent le même identifiant de livraison)
- Un hash de champs stables (dernier recours si aucun ID n'existe)
Quand vous recevez un webhook, écrivez la clé en base d'abord en appliquant une règle d'unicité pour qu'une seule requête « gagne ». Puis traitez l'événement. Si vous voyez la même clé à nouveau, retournez succès sans refaire le travail.
Gardez votre reçu stocké petit mais utile : la clé, le statut de traitement (reçu/traité/échoué), des timestamps (première vue/dernière vue) et un résumé minimal (type d'événement et ID d'objet lié). Beaucoup d'équipes conservent les clés entre 7 et 30 jours pour couvrir les retries tardifs et la plupart des signalements clients.
Protection contre les replays sans bloquer le trafic légitime
La protection contre les replays évite un problème simple mais méchant : quelqu'un capture une requête webhook réelle (avec une signature valide) et l'envoie à nouveau plus tard. Si votre handler traite chaque livraison comme nouvelle, ce replay peut provoquer des remboursements en double, des invitations utilisateur dupliquées ou des changements d'état répétés.
Une approche courante est de signer non seulement la payload mais aussi un timestamp. Votre webhook inclut des en-têtes comme X-Signature et X-Timestamp. À la réception, vérifiez la signature puis que le timestamp est frais dans une courte fenêtre.
Le drift d'horloge est ce qui provoque généralement des rejets faux positifs. Vos serveurs et ceux de l'émetteur peuvent diverger d'une minute ou deux, et le réseau peut retarder la livraison. Prévoyez une marge et loggez pourquoi vous avez rejeté une requête.
Règles pratiques qui fonctionnent bien :
- Acceptez seulement si
abs(now - timestamp) <= window(par exemple, 5 minutes plus une petite marge). - Comptez sur l'idempotence comme véritable filet de sécurité. Même dans la fenêtre, les retries ne doivent pas appliquer deux fois.
- Si vous rejetez pour cause de temps, renvoyez un 4xx clair et loggez le timestamp reçu et l'heure serveur.
Si les timestamps manquent, vous ne pouvez pas faire de protection temporelle basée uniquement sur le temps. Dans ce cas, appuyez-vous davantage sur l'idempotence (stocker et rejeter les event IDs dupliqués) et envisagez d'exiger des timestamps dans la prochaine version du webhook.
La rotation des secrets compte aussi. Si vous faites tourner les secrets de signature, gardez plusieurs secrets actifs pendant une courte période de chevauchement. Vérifiez d'abord avec le secret le plus récent, puis en dernier recours avec les anciens. Cela évite les interruptions clients pendant le déploiement. Si votre équipe déploie rapidement les endpoints (par exemple en générant du code avec Koder.ai et en utilisant snapshots et rollback pendant les deploys), cette période de chevauchement aide parce que d'anciennes versions peuvent rester actives brièvement.
Concevoir le handler pour que les retries ne vous blessent pas
Les retries sont normales. Supposez que chaque livraison peut être dupliquée, retardée ou hors ordre. Votre handler doit se comporter de la même manière qu'il voie un événement une ou cinq fois.
Gardez le chemin de requête court. Ne faites que l'essentiel pour accepter l'événement, puis déplacez le travail lourd vers un job en arrière-plan.
Un pattern simple qui tient en production :
- Validez les basiques (méthode, content-type, en-têtes requis).
- Vérifiez l'authenticité (signature) et rejetez tout ce qui échoue.
- Parsez et validez la payload.
- Dédupliquez en utilisant l'event ID (ou la clé d'idempotence) dans une table avec contrainte d'unicité.
- Enqueuez le travail avec l'event ID, puis répondez.
Renvoyez 2xx seulement après avoir vérifié la signature et enregistré l'événement (ou l'avoir mis en file). Si vous répondez 200 avant d'avoir rien sauvegardé, vous pouvez perdre des événements en cas de crash. Si vous faites du travail lourd avant de répondre, les timeouts déclenchent des retries et vous risquez de répéter des effets de bord.
Les systèmes en aval lents sont la principale raison pour laquelle les retries deviennent douloureux. Si votre fournisseur d'email, CRM ou base est lent, laissez une queue absorber le délai. Le worker peut réessayer avec backoff, et vous pouvez alerter sur les jobs bloqués sans bloquer l'émetteur.
Les événements hors ordre arrivent aussi. Par exemple, un subscription.updated peut arriver avant subscription.created. Rendez-vous tolérant en vérifiant l'état courant avant d'appliquer des changements, en autorisant des upserts, et en considérant « introuvable » comme une raison de retenter plus tard (quand cela a du sens) plutôt que comme un échec permanent.
Erreurs fréquentes qui causent des bugs difficiles à tracer
Beaucoup de problèmes « aléatoires » de webhook sont d'origine interne. Ils ressemblent à des réseaux instables, mais se répètent selon des motifs, souvent après un déploiement, une rotation de secret, ou un petit changement de parsing.
Le bug de signature le plus courant est de hasher les mauvais octets. Si vous parsez le JSON d'abord, votre serveur peut le reformater (espaces, ordre des clés, format des nombres). Ensuite vous vérifiez la signature contre un corps différent de celui signé par l'émetteur, et la vérification échoue même si la payload est authentique. Vérifiez toujours contre les octets bruts exactement reçus.
La source suivante de confusion est les secrets. Les équipes testent en staging mais vérifient par erreur avec le secret de production, ou gardent un ancien secret après rotation. Quand un client signale des échecs « seulement dans un environnement », supposez d'abord un mauvais secret ou une mauvaise configuration.
Quelques erreurs qui entraînent de longues investigations :
- Logger le corps complet pour déboguer, puis exposer des tokens, emails ou données de paiement dans les logs.
- Renvoyer 500 tout en effectuant des effets de bord (envoi d'emails, mise à jour de commandes). Les retries répéteront ces effets.
- Utiliser une clé d'idempotence qui n'est pas vraiment unique (par ex. type d'événement + minute). De vrais événements sont traités comme « duplicatas ».
- Considérer un 2xx comme « traité » alors que votre code n'a fait que mettre en file et que le job a échoué ensuite.
Exemple : un client dit « order.paid n'est jamais arrivé ». Vous observez des échecs de signature qui ont commencé après un refactor qui a changé le middleware de parsing. Le middleware lit et re-encode le JSON, donc votre vérification de signature utilisait maintenant un corps modifié. La correction est simple, mais seulement si vous savez regarder ce point précis.
Déboguer rapidement les échecs signalés par les clients
Quand un client dit « votre webhook n'a pas été envoyé », traitez-le comme un problème de traçabilité, pas comme un problème de devinette. Ancrez-vous sur une seule tentative de livraison précise du fournisseur et suivez-la à travers votre système.
Commencez par récupérer l'identifiant de livraison du fournisseur, l'ID de requête ou l'ID d'événement pour la tentative échouée. Avec cette seule valeur, vous devriez pouvoir retrouver l'entrée de log correspondante rapidement.
Ensuite, vérifiez trois choses dans l'ordre :
- La vérification de signature a-t-elle passé ?
- Le contrôle de timestamp ou de fenêtre de replay a-t-il passé (si vous en utilisez un) ?
- L'idempotence l'a-t-il traité comme nouveau ou comme duplicata ?
Puis confirmez ce que vous avez répondu au fournisseur. Un 200 lent peut être aussi mauvais qu'un 500 si le fournisseur timeout et réessaie. Regardez le code de statut, le temps de réponse, et si votre handler a accusé réception avant d'effectuer le travail lourd.
Si vous devez reproduire, faites-le en sécurité : stockez un échantillon brut rédigé (en-têtes clés plus corps brut) et rejouez-le dans un environnement de test en utilisant le même secret et le même code de vérification.
Checklist rapide que vous pouvez exécuter en 10 minutes
Quand une intégration webhook commence à échouer « aléatoirement », la rapidité compte plus que la perfection. Ce runbook couvre les causes habituelles.
Saisissez d'abord un exemple concret : nom du fournisseur, type d'événement, timestamp approximatif (avec timezone), et tout event ID que le client peut fournir.
Puis vérifiez :
- La vérification de signature utilise les octets bruts du corps (avant parsing JSON) et le bon secret pour l'environnement.
- Les contrôles de replay ont du sens pour le comportement réel des retries (et votre horloge serveur est correcte).
- L'idempotence déduplique réellement (contrainte d'unicité, écrite avant le traitement, rétention sensée).
- Votre handler accuse réception seulement après validation et enregistrement/queue durable.
- Les logs incluent un reçu minimal, interrogeable : provider, event_id, signature_ok, replay_ok, idempotency_status, response_code, latency_ms.
Si le fournisseur dit « on a réessayé 20 fois », vérifiez d'abord les motifs courants : mauvais secret (signature échoue), drift d'horloge (fenêtre de replay), limites de taille de payload (413), timeouts (pas de réponse), et rafales de 5xx provenant des dépendances en aval.
Exemple : tracer un rapport d'« événement manquant » de bout en bout
Un client écrit : « Nous avons manqué un invoice.paid hier. Notre système ne s'est jamais mis à jour. » Voici une façon rapide de tracer ça.
D'abord, confirmez si le fournisseur a tenté la livraison. Récupérez l'event ID, le timestamp, l'URL de destination et le code de réponse exact que votre endpoint a renvoyé. S'il y a eu des retries, notez la première raison d'échec et si un retry ultérieur a réussi.
Ensuite, validez ce que votre code a vu en périphérie : confirmez le secret de signature configuré pour cet endpoint, recalculer la vérification de signature en utilisant le corps brut, et vérifiez le timestamp de la requête dans la fenêtre autorisée.
Soyez prudent avec les fenêtres de replay pendant les retries. Si votre fenêtre est de 5 minutes et que le fournisseur réessaye 30 minutes plus tard, vous pourriez rejeter un retry légitime. Si c'est votre politique, assurez-vous que c'est intentionnel et documenté. Sinon, élargissez la fenêtre ou changez la logique pour que l'idempotence reste la défense principale contre les duplicatas.
Si la signature et le timestamp sont bons, suivez l'event ID dans votre système et répondez : l'avez-vous traité, dédupliqué ou perdu ?
Issues courantes :
- Dédupliqué : la clé d'idempotence existe déjà, vous avez renvoyé 200 sans relancer la logique métier.
- Rejeté : la validation a échoué (mismatch de signature, timestamp trop ancien, en-têtes manquants).
- Timeout : le handler a mis trop de temps, le fournisseur l'a marqué comme échoué puis a réessayé.
Quand vous répondez au client, soyez clair et précis : « Nous avons reçu des tentatives de livraison à 10:03 et 10:33 UTC. La première a timeouté après 10s ; le retry a été rejeté car le timestamp était hors de notre fenêtre de 5 minutes. Nous avons élargi la fenêtre et ajouté une accusation de réception plus rapide. Merci de renvoyer l'event ID X si nécessaire. »
Étapes suivantes : rendre cela répétable
Le moyen le plus rapide d'arrêter les incendies webhook est de faire en sorte que chaque intégration suive la même feuille de route. Écrivez le contrat sur lequel vous et l'émetteur vous êtes mis d'accord : en-têtes requis, méthode exacte de signature, quel timestamp est utilisé, et quels ID vous considérez uniques.
Standardisez ensuite ce que vous enregistrez pour chaque tentative de livraison. Un petit log de reçu suffit généralement : received_at, event_id, delivery_id, signature_valid, idempotency_result (new/duplicate), handler_version, et response status.
Un workflow utile en croissance :
- Gardez un endpoint de test dédié qui valide les signatures et renvoie 2xx sans exécuter d'actions métier.
- Stockez le corps brut et les en-têtes clés pour une courte durée, juste assez pour déboguer et rejouer.
- Construisez un job de reprocessing sûr en replay qui ré-exécute les événements stockés via le même chemin de traitement.
- Conservez une checklist interne que le support, la QA et l'ingénierie suivent tous.
Si vous construisez des apps avec Koder.ai (koder.ai), Planning Mode est un bon moyen de définir d'abord le contrat webhook (en-têtes, signature, IDs, comportement de retry) puis de générer un endpoint et un reçu cohérents entre projets. Cette cohérence est ce qui rend le débogage rapide au lieu d'être héroïque.
FAQ
Why do webhooks seem to “randomly” fail or duplicate in production?
Parce que la livraison des webhooks est généralement au-moins-une-fois (at-least-once), pas exactement une fois. Les fournisseurs réessaient en cas de timeouts, de réponses 5xx, ou parfois quand ils ne voient pas votre 2xx à temps, donc vous pouvez obtenir des doublons, des retards et des livraisons hors ordre même quand tout semble « fonctionner ».
What’s the safest basic flow for handling a webhook request?
Par défaut, suivez cette règle : vérifiez d'abord la signature, puis enregistrez/dédoubez l'événement, répondez 2xx, puis effectuez le travail lourd de façon asynchrone.
Si vous faites le travail lourd avant de répondre, vous aurez des timeouts et déclencherez des retries ; si vous répondez avant d'avoir enregistré quoi que ce soit, vous pouvez perdre des événements en cas de crash.
How do I avoid signature mismatches when verifying webhooks?
Utilisez les octets bruts du corps de la requête exactement tels qu'ils sont reçus. Ne parsez pas le JSON puis ne le ré-serializez pas avant vérification — les espaces, l'ordre des clés et le format des nombres peuvent casser les signatures.
Assurez-vous aussi de recréer précisément la chaîne signée par le fournisseur (souvent timestamp + "." + raw_body).
What should my endpoint do when signature verification fails?
Retournez un 4xx (généralement 400 ou 401) et ne traitez pas la charge utile.
Loggez une raison minimale (en-tête de signature manquant, mismatch, fenêtre de timestamp invalide), mais ne loggez pas de secrets ni le corps complet contenant des données sensibles.
What is an idempotency key for webhooks, and which value should I use?
Une clé d'idempotence est un identifiant unique et stable que vous stockez pour que les retries n'appliquent pas deux fois les mêmes effets de bord.
Bonnes options :
- Event ID (idéal quand un événement correspond à une seule modification métier)
- Delivery/message ID (si cet ID reste constant sur les retries)
- Hash de champs stables (dernier recours)
Appliquez-la avec une contrainte d'unicité pour qu'une seule requête « gagne » sous concurrence.
How do I dedupe webhooks without race conditions?
Écrivez la clé d'idempotence avant d'effectuer les effets de bord, avec une règle d'unicité. Puis :
- Marquez-la comme traitée après le succès, ou
- Enregistrez un statut d'échec pour pouvoir retenter en toute sécurité
Si l'insertion échoue parce que la clé existe déjà, retournez 2xx et sautez l'action métier.
How do I add replay protection without rejecting legitimate retries?
Signez non seulement la charge utile mais aussi un timestamp. Votre webhook inclut des en-têtes comme X-Signature et X-Timestamp. À la réception, vérifiez la signature puis que le timestamp est récent (dans une courte fenêtre).
Pour éviter les rejets légitimes :
- Prévoyez une marge pour le drift d'horloge
- Loggez l'heure serveur et le timestamp reçu lors d'un rejet
- Traitez l'idempotence comme la protection principale contre les doublons ; la fenêtre temporelle sert surtout à bloquer les replays tardifs.
Si les timestamps manquent, vous ne pouvez pas faire de protection temporelle complète : appuyez-vous davantage sur l'idempotence et envisagez d'exiger des timestamps dans la prochaine version du webhook.
How should I handle out-of-order webhook events?
Ne supposez pas que l'ordre de livraison soit l'ordre des événements. Rendre les handlers tolérants :
- Utilisez des upserts quand c'est possible
- Vérifiez l'état courant avant d'appliquer un changement
- Si un objet est introuvable, envisagez de re-tenter plus tard (via une queue) plutôt que d'échouer définitivement
Conservez l'ID et le type de l'événement pour pouvoir analyser ce qui s'est passé même si l'ordre est perturbé.
What should I log so webhook debugging doesn’t turn into guessing?
Loggez un petit « reçu » par tentative de livraison pour pouvoir tracer un événement de bout en bout :
- provider, event_id, delivery_id
- signature_ok, replay_ok
- résultat d'idempotence (nouveau/duplicate)
- response_code, latency_ms
- timestamps (received/first_seen/last_seen)
Rendez les logs recherchables par event ID pour que le support puisse répondre rapidement aux signalements clients.
What’s a fast way to investigate a customer report that “a webhook never arrived”?
Commencez par demander un identifiant concret : event ID ou delivery ID, plus un timestamp approximatif.
Puis vérifiez dans cet ordre :
- Résultat de la vérification de signature
- Résultat de la vérification du timestamp/fenêtre replay (si utilisé)
- Issue d'idempotence (nouveau vs duplicate)
- Ce que vous avez renvoyé (code + latence)
Si vous utilisez Koder.ai, gardez le pattern handler cohérent (verify → record/dedupe → queue → respond). La cohérence rend ces vérifications rapides en cas d'incident.