Joe Armstrong et Erlang : laisser planter pour des plateformes fiables
Découvrez comment Joe Armstrong a façonné la concurrence, la supervision et l’état d’esprit « laisser planter » d’Erlang — des idées toujours utilisées pour construire des services temps réel fiables.
Ce que couvre cet article (et pourquoi c'est toujours pertinent)
Joe Armstrong n’a pas seulement contribué à créer Erlang — il en a été le meilleur vulgarisateur. Par ses conférences, ses articles et son pragmatisme, il a popularisé une idée simple : si vous voulez un logiciel qui reste en service, vous concevez pour l’échec au lieu de prétendre l’éviter.
Cet article est une visite guidée de l’état d’esprit Erlang et de pourquoi il importe encore quand vous construisez des plateformes temps réel fiables — des systèmes de chat, du routage d’appels, des notifications en direct, de la coordination multijoueur, et des infrastructures qui doivent répondre vite et de façon cohérente même quand certaines parties dysfonctionnent.
« Temps réel » en termes simples
« Temps réel » ne signifie pas toujours « microsecondes » ou « deadlines strictes ». Pour beaucoup de produits, cela signifie :
- des réponses rapides que les utilisateurs perçoivent (pas de pauses mystérieuses)
- un comportement prévisible sous charge (ça peut ralentir, mais ça ne doit pas partir en spirale)
- la continuité du service lors de pannes partielles (un composant défaillant ne doit pas tout emporter)
Erlang a été conçu pour des systèmes télécoms où ces attentes sont non négociables — et cette contrainte a façonné ses idées les plus influentes.
Les trois piliers sur lesquels nous allons nous concentrer
Plutôt que de plonger dans la syntaxe, nous nous concentrerons sur les concepts qui ont rendu Erlang célèbre et qui réapparaissent dans la conception moderne des systèmes :
- Concurrence par défaut : construire des logiciels à partir de nombreux petits travailleurs isolés plutôt que de quelques gros.
- Tolérance aux pannes comme objectif de conception : supposer que bugs, timeouts et plantages arriveront — et planifier la suite.
- « Laisser planter » : ne pas surprotéger chaque ligne de code ; échouer rapidement et récupérer proprement grâce à une structure (pas du sauvetage héroïque).
En chemin, nous relierons ces idées au modèle acteur et au passage de messages, expliquerons les arbres de supervision et OTP en termes accessibles, et montrerons pourquoi la VM BEAM rend l’approche praticable.
Même si vous n’utilisez pas Erlang (et ne l’utiliserez jamais), l’idée reste utile : le cadrage d’Armstrong vous donne une checklist puissante pour construire des systèmes qui restent réactifs et disponibles quand la réalité devient chaotique.
La motivation de Joe Armstrong : construire des systèmes qui tiennent
Les commutateurs télécoms et les plates-formes de routage d’appels ne peuvent pas « tomber en maintenance » comme beaucoup de sites web. Ils sont censés continuer à traiter appels, événements de facturation et signalisation en continu — souvent avec des exigences strictes de disponibilité et de latence prévisible.
Erlang est né chez Ericsson à la fin des années 1980 pour répondre à ces réalités avec du logiciel, pas seulement du matériel spécialisé. Joe Armstrong et ses collègues ne cherchaient pas l’élégance pour elle-même ; ils essayaient de bâtir des systèmes auxquels les opérateurs pourraient faire confiance sous charge constante, pannes partielles et conditions réelles désordonnées.
Ce que « fiable » signifie en pratique
Un changement clé de perspective est que la fiabilité n’est pas synonyme de « ne jamais échouer ». Dans les grands systèmes qui tournent longtemps, quelque chose échouera : un processus recevra une entrée inattendue, un nœud redémarrera, un lien réseau fluctue, ou une dépendance ralentira.
L’objectif devient alors :
- continuer à servir les utilisateurs même quand des parties se comportent mal
- détecter rapidement les échecs
- récupérer automatiquement, avec une intervention humaine minimale
- isoler les fautes pour qu’un bug n’emporte pas tout
C’est cet état d’esprit qui rend ensuite raisonnables des concepts comme les arbres de supervision et le « laisser planter » : on conçoit l’échec comme un événement normal, pas comme une catastrophe exceptionnelle.
Moins de mythe, plus de résolution de problèmes
Il est tentant de raconter l’histoire comme la percée d’un visionnaire. La vue la plus utile est plus simple : les contraintes télécom ont forcé un autre compromis. Erlang a priorisé concurrence, isolation et récupération parce que ce sont les outils pratiques nécessaires pour garder les services en marche alors que le monde change autour d’eux.
Ce cadrage centré sur le problème explique aussi pourquoi les leçons d’Erlang se transposent bien aujourd’hui — partout où la disponibilité et la récupération rapide importent plus que la prévention parfaite.
La concurrence comme comportement par défaut : beaucoup de petits travailleurs
Une idée centrale d’Erlang est que « faire plusieurs choses à la fois » n’est pas une fonctionnalité optionnelle à ajouter plus tard — c’est la façon normale de structurer un système.
Processus légers, expliqués simplement
Dans Erlang, le travail est divisé en beaucoup de petits « processus ». Pensez-y comme de petits travailleurs, chacun responsable d’un job : gérer un appel téléphonique, suivre une session de chat, surveiller un appareil, retenter un paiement, ou regarder une file.
Ils sont légers, ce qui signifie qu’on peut en avoir un grand nombre sans matériel énorme. Au lieu d’un gros travailleur pesant essayant de tout jongler, on a une foule de travailleurs focalisés qui peuvent démarrer vite, s’arrêter vite et être remplacés rapidement.
Pourquoi « un gros programme » casse différemment
Beaucoup de systèmes sont conçus comme un seul gros programme avec des parties fortement liées. Quand ce type de système rencontre un bug sérieux, un problème mémoire ou une opération bloquante, l’échec peut se propager — comme faire sauter un disjoncteur et noyer tout le bâtiment.
Erlang pousse l’inverse : isoler les responsabilités. Si un petit worker se comporte mal, vous pouvez l’arrêter et le remplacer sans affecter le travail non lié.
Le passage de messages, expliqué comme « envoyer des notes »
Comment ces travailleurs se coordonnent-ils ? Ils ne fouillent pas l’état interne des autres. Ils envoient des messages — plus comme passer des notes que partager un tableau blanc en bazar.
Un worker peut dire : « voici une nouvelle requête », « cet utilisateur s’est déconnecté », ou « réessaye dans 5 secondes ». Le destinataire lit la note et décide quoi faire.
Le bénéfice clé est la contention : parce que les workers sont isolés et communiquent par messages, les pannes ont moins de chances de se propager à l’ensemble du système.
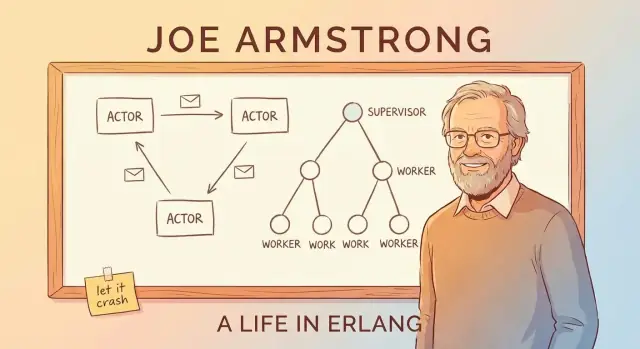
Passage de messages et modèle acteur (sans jargon)
Une manière simple de comprendre le « modèle acteur » d’Erlang est d’imaginer un système composé de nombreux petits travailleurs indépendants.
Acteurs : petits travailleurs qui ne communiquent qu’en envoyant des messages
Un acteur est une unité autonome avec son état privé et une boîte aux lettres. Il fait trois choses de base :
- reçoit des messages (un à la fois) de sa boîte
- met à jour son état interne
- envoie des messages à d’autres acteurs
C’est tout. Pas de variables partagées cachées, pas de « plonger dans la mémoire d’un autre worker ». Si un acteur a besoin de quelque chose d’un autre, il le demande par message.
Pourquoi éviter l’état partagé élimine des catégories entières de bugs
Quand plusieurs threads partagent les mêmes données, vous pouvez avoir des conditions de course : deux opérations modifient une même valeur presque en même temps, et le résultat dépend du timing. C’est là que les bugs deviennent intermittents et difficiles à reproduire.
Avec le passage de messages, chaque acteur possède ses données. Les autres acteurs ne peuvent pas les muter directement. Ça n’élimine pas tous les bugs, mais ça réduit drastiquement les problèmes liés à l’accès simultané à la même donnée.
Back-pressure, expliqué comme une file dans un café
Les messages n’arrivent pas « gratuitement ». Si un acteur reçoit des messages plus vite qu’il ne peut les traiter, sa boîte (queue) grossit. C’est la back-pressure : le système vous dit, indirectement, « cette partie est surchargée ».
En pratique, on surveille la taille des boîtes et on impose des limites : shedding de charge, batching, échantillonnage, ou redirection du travail vers plus d’acteurs au lieu de laisser les files grandir sans fin.
Exemple concret : notifications de chat
Imaginez une appli de chat. Chaque utilisateur pourrait avoir un acteur responsable de livrer les notifications. Quand un utilisateur se déconnecte, les messages continuent d’arriver — la boîte grossit. Un bon design peut plafonner la queue, supprimer les notifications non critiques ou basculer en mode digest, plutôt que de laisser un utilisateur lent dégrader tout le service.
« Laisser planter » expliqué : échouer vite, récupérer plus vite
« Laisser planter » n’est pas un slogan pour de l’ingénierie bâclée. C’est une stratégie de fiabilité : quand un composant est dans un état mauvais ou inattendu, il doit s’arrêter rapidement et bruyamment au lieu de traîner.
Ce que cela signifie réellement
Plutôt que d’écrire du code qui essaie de gérer tous les cas limites à l’intérieur d’un même processus, Erlang encourage à garder chaque worker petit et ciblé. Si ce worker rencontre quelque chose qu’il ne peut vraiment pas gérer (état corrompu, hypothèse violée, entrée inattendue), il sort. Une autre partie du système est responsable de le redémarrer.
Cela déplace la question principale de « comment empêcher l’échec ? » vers « comment récupérer proprement après un échec ? »
Le compromis : moins de vérifications défensives, une logique plus claire
La programmation défensive partout peut transformer des flux simples en un labyrinthe de conditionnels, retries et états partiels. « Laisser planter » échange une partie de cette complexité in-process contre :
- des chemins de code plus simples et lisibles
- une détection plus rapide des hypothèses brisées
- une récupération cohérente (parce qu’elle est centralisée)
L’idée forte est que la récupération doit être prévisible et répétable, pas improvisée dans chaque fonction.
Quand c’est adapté — et quand ce ne l’est pas
C’est le mieux adapté quand les échecs sont récupérables et isolés : un problème réseau temporaire, une requête malformée, un worker bloqué, un timeout tiers.
Ce n’est pas adapté quand un plantage peut causer un dommage irréversible, par exemple :
- perte de données sans source de vérité durable
- opérations critiques pour la sécurité où « réessayer » n’est pas acceptable
Redémarrages rapides et état connu
Le crash n’aide que si le retour est rapide et sûr. En pratique cela signifie redémarrer les workers dans un état connu — souvent en rechargeant la config, en reconstruisant des caches mémoire depuis un stockage durable, et en reprenant le travail sans prétendre que l’état corrompu n’a jamais existé.
Arbres de supervision : concevoir l’échec volontairement
L’idée du « laisser planter » ne fonctionne que parce que les crashs ne sont pas laissés au hasard. Le pattern clé est l’arbre de supervision : une hiérarchie où les superviseurs sont comme des managers et les workers exécutent le travail (gérer un appel, suivre une session, consommer une file, etc.). Quand un worker se comporte mal, le manager le remarque et le redémarre.
Managers qui redémarrent des workers
Un superviseur n’essaie pas de « réparer » un worker en place. Il applique plutôt une règle simple et cohérente : si le worker meurt, on en démarre un neuf. Cela rend le chemin de récupération prévisible et réduit le besoin d’un handling d’erreurs ad hoc dispersé dans le code.
Tout aussi important, les superviseurs peuvent décider de ne pas redémarrer — si quelque chose plante trop souvent, cela peut indiquer un problème plus profond, et le redémarrage répété peut empirer la situation.
Stratégies de redémarrage (haut niveau)
La supervision n’est pas universelle. Stratégies courantes :
- One-for-one : seul le worker défaillant est redémarré. Convient aux tâches indépendantes où une panne ne doit pas perturber les autres.
- Redémarrages groupés : si un worker échoue, un ensemble lié est redémarré ensemble. Utile pour des composants fortement couplés qui doivent rester synchrones.
Dépendances : la partie qui demande réflexion
Un bon design de supervision commence par une cartographie des dépendances : quels composants dépendent d’autres, et qu’est-ce qu’un « démarrage propre » signifie pour eux.
Si un gestionnaire de session dépend d’un processus cache, redémarrer seulement le handler peut le laisser connecté à un état incorrect. Les regrouper sous le bon superviseur (ou les redémarrer ensemble) transforme des modes de panne désordonnés en comportements de récupération cohérents et reproductibles.
OTP : des blocs réutilisables pour des services fiables
Si Erlang est le langage, OTP (Open Telecom Platform) est la boîte à outils qui transforme le « laisser planter » en quelque chose qu’on peut exploiter en production pendant des années.
OTP comme boîte à outils de patterns éprouvés
OTP n’est pas une unique bibliothèque — c’est un ensemble de conventions et de composants prêts à l’emploi (appelés behaviours) qui résolvent les parties ennuyeuses mais critiques de la construction de services :
gen_serverpour un worker longue durée qui garde un état et gère des requêtes une à la foissupervisorpour redémarrer automatiquement les workers défaillants selon des règles clairesapplicationpour définir comment un service entier démarre, s’arrête et s’intègre dans une release
Ce ne sont pas de la « magie ». Ce sont des templates avec des callbacks bien définis, donc votre code s’insère dans une forme connue plutôt que d’inventer une nouvelle forme à chaque projet.
Pourquoi les patterns standard battent les frameworks maison
Les équipes construisent souvent des workers ad hoc, des hooks de monitoring bricolés et une logique de redémarrage unique. Ça marche — jusqu’à ce que ça ne marche plus. OTP réduit ce risque en poussant tout le monde vers le même vocabulaire et le même cycle de vie. Quand un nouvel ingénieur arrive, il n’a pas à apprendre votre framework maison ; il peut compter sur des patterns partagés et bien connus dans l’écosystème Erlang.
Comment OTP guide l’architecture au quotidien
OTP vous incite à penser en termes de rôles de processus et de responsabilités : qu’est-ce qu’un worker, qu’est-ce qu’un coordinateur, qui doit redémarrer quoi et qui ne doit jamais redémarrer automatiquement.
Il encourage aussi une bonne hygiène : noms clairs, ordre de démarrage explicite, arrêt prévisible et signaux de monitoring intégrés. Le résultat : des logiciels pensés pour tourner en continu — des services capables de récupérer des fautes, d’évoluer dans le temps et de continuer à fonctionner sans surveillance humaine constante.
La VM BEAM : le runtime qui rend le modèle praticable
Les grandes idées d’Erlang — petits processus, passage de messages et « laisser planter » — seraient bien plus difficiles à utiliser en production sans la VM BEAM. BEAM est le runtime qui rend ces patterns naturels, pas fragiles.
Ordonnancement : l’équité plutôt que « un gros thread »
BEAM est conçu pour faire tourner un grand nombre de processus légers. Plutôt que de s’appuyer sur quelques threads OS et espérer que l’application se comporte, BEAM planifie les processus Erlang lui-même.
Le bénéfice pratique est la réactivité sous charge : le travail est découpé en petits morceaux et tourné équitablement, de sorte qu’aucun worker hyper-actif n’est censé dominer le système longtemps. Cela correspond parfaitement à un service composé de nombreuses tâches indépendantes — chacune fait un peu de travail, puis cède.
Isolation et nettoyage mémoire « par processus »
Chaque processus Erlang a son propre tas et sa propre collecte de déchets. C’est un détail clé : nettoyer la mémoire d’un processus ne nécessite pas de stopper tout le programme.
Autre point important, les processus sont isolés. Si l’un plante, il ne corrompt pas la mémoire des autres et la VM reste vivante. Cette isolation est la base qui rend les arbres de supervision réalistes : la faute est contenue, puis traitée en redémarrant la partie défaillante au lieu de tout détruire.
Distribution : plusieurs nœuds, un seul système
BEAM supporte aussi la distribution de façon assez simple : vous pouvez exécuter plusieurs nœuds Erlang (instances VM séparées) et les laisser communiquer par envoi de messages. Si vous avez compris « les processus parlent par messages », la distribution est une extension de la même idée — certains processus vivent juste sur un autre nœud.
BEAM ne promet pas des records de vitesse brute. Il promet de rendre la concurrence, la contention des fautes et la récupération par défaut — de sorte que l’histoire de la fiabilité soit praticable plutôt que théorique.
Mises à jour sans arrêter le système (code à chaud, prudemment)
Un des tours les plus commentés d’Erlang est le hot code swapping : mettre à jour des parties d’un système en cours d’exécution avec un minimum d’arrêt. La promesse pratique n’est pas « ne jamais redémarrer », mais « livrer des correctifs sans transformer un petit bug en longue panne ».
Ce que signifie vraiment « code à chaud »
Dans Erlang/OTP, le runtime peut garder deux versions d’un module chargées simultanément. Les processus existants peuvent finir leur travail avec l’ancienne version tandis que de nouveaux appels peuvent utiliser la nouvelle. Cela vous donne la marge pour patcher un bug, déployer une fonctionnalité ou ajuster un comportement sans déconnecter tout le monde.
Fait correctement, cela soutient directement les objectifs de fiabilité : moins de redémarrages complets, fenêtres de maintenance plus courtes et récupération plus rapide quand quelque chose glisse en production.
Les contraintes à ne pas ignorer
Tous les changements ne sont pas sûrs à échanger en live. Exemples de changements qui demandent de la prudence (ou un redémarrage) :
- modifications de la forme d’un état (un processus attend un format, le nouveau code en attend un autre)
- changements de protocole ou de format de message qui doivent être cohérents entre services
- migrations de schéma longues ou nécessitant une coordination
Erlang fournit des mécanismes pour des transitions contrôlées, mais vous devez quand même concevoir la trajectoire de mise à jour.
L’état d’esprit : upgrades et rollbacks sont normaux
Les mises à jour à chaud fonctionnent mieux quand upgrades et rollbacks sont traités comme des opérations routinières, pas comme des urgences rares. Cela implique de planifier versioning, compatibilité et un chemin clair de « retour en arrière » dès le départ. En pratique, les équipes associent techniques de live-upgrade à des déploiements progressifs, des checks de santé et la récupération pilotée par supervision.
Même si vous n’utilisez jamais Erlang, la leçon est transférable : concevez les systèmes pour que les changer en toute sécurité soit une exigence de première classe, pas une réflexion après coup.
Où les idées d'Erlang brillent dans les plateformes temps réel
Les plateformes temps réel concernent moins le timing parfait que le maintien de la réactivité pendant que tout le reste part en vrille : réseaux qui vacillent, dépendances qui ralentissent, pics de trafic. Le design d’Erlang — porté par Joe Armstrong — colle à cette réalité parce qu’il suppose l’échec et traite la concurrence comme normale, pas exceptionnelle.
Cas d’usage « temps réel » courants
Vous verrez la pensée à la manière d’Erlang s’exprimer partout où de nombreuses activités indépendantes ont lieu en parallèle :
- messagerie et chat : des millions de petites conversations, chacune avec son état et ses retries
- communication en temps réel : signalisation voix/vidéo, mises à jour de présence, coordination de sessions
- coordination IoT : des flottes d’appareils qui checkent, disparaissent et réapparaissent de façon imprévisible
- flux de paiements : processus multi-étapes où certaines étapes sont lentes, indisponibles ou nécessitent des actions compensatoires
Ce que signifie généralement « soft real-time »
La plupart des produits n’ont pas besoin de garanties strictes du type « chaque action finit en 10 ms ». Ils ont besoin de soft real-time : latence généralement faible pour les requêtes typiques, récupération rapide quand des parties échouent, et forte disponibilité pour que les utilisateurs perçoivent rarement des incidents.
L’échec est normal : concevez pour ça
Les systèmes réels rencontrent des problèmes comme :
- connexions perdues (réseaux mobiles, basculements Wi‑Fi)
- timeouts quand un service aval est lent
- pannes partielles où une région ou une dépendance se dégrade
Le modèle d’Erlang encourage d’isoler chaque activité (une session utilisateur, un appareil, une tentative de paiement) pour qu’une panne ne se propage pas. Plutôt que de construire un gros composant « qui gère tout », les équipes raisonnent en unités plus petites : chaque worker fait un boulot, parle par messages, et si ça casse, on le redémarre proprement.
Ce déplacement — de « prévenir chaque panne » à « contenir et récupérer vite » — est souvent ce qui rend les plateformes temps réel stables sous pression.
Malentendus fréquents et limites réelles
La réputation d’Erlang peut sonner comme une promesse : des systèmes qui ne tombent jamais parce qu’ils redémarrent. La réalité est plus pragmatique — et plus utile. « Laisser planter » est un outil pour construire des services dépendables, pas un permis d’ignorer les problèmes sérieux.
Les redémarrages ne sont pas un pansement
Une erreur courante est d’utiliser la supervision pour masquer des bugs profonds. Si un processus plante immédiatement au démarrage, un superviseur peut continuer à le relancer jusqu’à provoquer une boucle de crash — consommant du CPU, inondant les logs et créant potentiellement une panne plus grave que le bug initial.
Les bons systèmes ajoutent du backoff, des limites d’intensité de redémarrage et un comportement clair de « abandonner et alerter ». Les redémarrages doivent restaurer un fonctionnement sain, pas masquer une invariant brisée.
L’état, c’est la partie difficile
Redémarrer un processus est souvent facile ; récupérer un état correct est plus compliqué. Si l’état vit seulement en mémoire, vous devez décider ce que signifie « correct » après un crash :
- faut-il reconstruire depuis un stockage durable ?
- peut-on rejouer des événements en idempotence ?
- que devient le travail en vol ou les mises à jour partielles ?
La tolérance aux pannes ne remplace pas une conception soignée des données. Elle vous force à être explicite à ce sujet.
Vous avez toujours besoin d'observabilité
Les crashs n’aident que si vous pouvez les voir tôt et les comprendre. Cela implique d’investir dans logs, métriques et tracing — pas seulement « ça a redémarré, donc tout va bien ». Vous voulez détecter les taux de redémarrage en hausse, les files qui gonflent et les dépendances lentes avant que les utilisateurs ne les ressentent.
Il existe des limites opérationnelles réelles
Même avec les forces de BEAM, les systèmes peuvent échouer de façons très ordinaires :
- croissance mémoire due à des fuites, caches ou gros tas
- backlog de boîtes quand producteurs dépassent consommateurs (pics de latence et timeouts)
- échecs de dépendances (bases, APIs tierces, DNS) où redémarrer votre code ne résoudra pas la cause racine
Le modèle d’Erlang aide à contenir et récupérer des pannes — il ne peut pas les éliminer.
Comment appliquer les leçons aujourd'hui (même sans Erlang)
Le plus grand cadeau d’Erlang n’est pas la syntaxe — ce sont des habitudes pour bâtir des services qui tiennent quand des parties échouent. Vous pouvez adopter ces habitudes dans presque n’importe quel stack.
Traduire les idées en actions concrètes
Commencez par expliciter les frontières de défaillance. Découpez votre système en composants capables d’échouer indépendamment, et assurez-vous que chacun a un contrat clair (entrées, sorties et ce qu’est un état « mauvais »).
Ensuite, automatisez la récupération plutôt que d’essayer d’empêcher chaque erreur :
- isoler les composants : exécuter le travail risqué dans des processus/containers/threads séparés pour qu’un crash n’empoisonne pas tout
- définir des frontières : timeouts, retries avec backoff, circuit breakers et bulkheads pour éviter les pannes en cascade
- rendre la récupération routinière : health checks, redémarrages automatiques et valeurs par défaut sûres pour que le système retourne vite à un état connu
Une manière concrète d’ancrer ces habitudes est de les intégrer aux outils et au cycle de vie, pas seulement au code. Par exemple, quand des équipes utilisent Koder.ai pour coder via chat, le workflow encourage naturellement une planification explicite (Planning Mode), des déploiements répétables et des itérations sûres avec snapshots et rollback — des concepts alignés avec l’état d’esprit opérationnel qu’Erlang a popularisé : supposer le changement et l’échec, et rendre la récupération banale.
Points de départ hors Erlang
Vous pouvez approximer des patterns de « supervision » avec des outils que vous connaissez peut-être déjà :
- superviseurs : systemd, déploiements Kubernetes, ou un process manager (restart-on-failure, readiness probes)
- isolation de processus : services workers séparés pour les tâches CPU-intensives ou non fiables
- passage de messages : files/streams (RabbitMQ, SQS, Kafka) pour découpler producteurs et consommateurs et lisser les pics
Checklist de décision rapide
Avant d’appliquer des patterns, décidez ce dont vous avez réellement besoin :
- modes d’échec attendus : surcharge, pannes partielles, dépendances lentes, entrées malformées, fuites mémoire
- besoins de latence : réponses temps réel requises ou traitement éventuel suffisant ?
- objectif de récupération : redémarrage rapide, dégradation contrôlée, ou intervention manuelle ?
- compétences et outils de l’équipe : qui sera en on-call, observabilité et réponse aux incidents ?
Si vous voulez des étapes pratiques, voyez d’autres guides dans /blog, ou parcourez les détails d’implémentation dans /docs (et les offres dans /pricing si vous évaluez des outils).
FAQ
Pourquoi l'état d'esprit d'Erlang de Joe Armstrong reste-t-il pertinent aujourd'hui ?
Erlang a popularisé un état d'esprit pratique sur la fiabilité : supposer que des composants vont échouer et concevoir la manière dont le système réagit.
Plutôt que d’essayer d’empêcher chaque plantage, il met l’accent sur l’isolation des fautes, la détection rapide et la récupération automatique, ce qui s’applique bien aux plateformes temps réel comme le chat, le routage d’appels, les notifications et les services de coordination.
Que signifie « temps réel » en termes simples dans cet article ?
Ici, « temps réel » signifie généralement temps réel souple :
- des réponses qui paraissent rapides et cohérentes
- un comportement prévisible sous charge
- le maintien du service malgré des pannes partielles
Il s’agit moins de garanties en microsecondes que d’éviter blocages, spirales et pannes en cascade.
Que signifie « concurrence par défaut » dans la conception à la manière d'Erlang ?
« Concurrence par défaut » consiste à structurer le système comme beaucoup de petits travailleurs isolés plutôt que quelques gros composants étroitement couplés.
Chaque travailleur gère une responsabilité étroite (une session, un appareil, un appel, une boucle de retry), ce qui facilite la montée en charge et la contention des pannes.
Que sont les « processus légers » en Erlang et pourquoi sont-ils importants ?
Les processus légers sont de petits travailleurs indépendants qu’on peut créer en grand nombre.
Concrètement, ils permettent de :
- modéliser un processus par « chose » (utilisateur/session/appareil)
- maintenir les pannes locales à un seul worker
- redémarrer un travail de façon peu coûteuse comparé au reboot d’un monolithe
Pourquoi Erlang privilégie-t-il le passage de messages plutôt que l'état partagé ?
Le passage de messages, c’est coordonner en envoyant des messages plutôt qu’en partageant de l’état mutable.
Cela réduit des classes entières de bugs de concurrence (comme les conditions de course) parce que chaque worker possède son état interne ; les autres ne peuvent demander une modification qu’au travers de messages.
Qu'est-ce que la back-pressure dans un système acteur/message, et comment la gérer ?
La back-pressure survient lorsqu’un worker reçoit des messages plus vite qu’il ne peut les traiter, et que sa boîte aux lettres grossit.
Façons pratiques de la gérer :
- surveiller la taille des boîtes/queues
- appliquer des limites (drop, échantillonnage, plafonner)
- répartir la charge sur plus de workers
- dégrader gracieusement (par ex. basculer en mode digest pour notifications non critiques)
Que signifie réellement « laisser planter » (et que ne signifie-t-il pas) ?
« Laisser planter » signifie : si un worker atteint un état invalide ou inattendu, il doit échouer rapidement plutôt que de continuer en titubant.
La récupération est alors gérée structurellement (via la supervision), ce qui permet des chemins logiques plus simples et une récupération plus prévisible — à condition que les redémarrages soient sûrs et rapides.
Que sont les arbres de supervision et pourquoi sont-ils essentiels à la tolérance aux pannes ?
Un arbre de supervision est une hiérarchie où des superviseurs surveillent des workers et les redémarrent selon des règles définies.
Au lieu de disperser la récupération partout :
- on décide quel composant redémarre quand quelque chose échoue
- on évite les boucles de crash infinies via des limites et des backoffs
- on redémarre des groupes quand des composants doivent rester synchrones
Qu'est-ce que OTP et comment aide-t-il à construire des services fiables ?
OTP est l’ensemble de patterns standard (behaviours) et de conventions qui rendent les systèmes Erlang opérables sur le long terme.
Briques courantes :
gen_serverpour un worker longue durée qui garde un état et gère les requêtes une par unesupervisorpour des politiques de redémarrageapplicationpour définir comment un service démarre, s’arrête et s’intègre dans une release
L’avantage : des cycles de vie partagés et bien compris plutôt que des frameworks ad hoc.
Comment appliquer les leçons d'Erlang si je n'utilise pas Erlang ?
Appliquez les mêmes principes dans d’autres stacks en faisant de l’échec et de la récupération des priorités :
- isoler le travail risqué (processes/services/containers séparés)
- ajouter timeouts, retries avec backoff, circuit breakers et bulkheads
- automatiser la récupération (health checks + redémarrage au besoin)
- découpler avec des files/streams pour lisser les pics
Pour aller plus loin, l’article renvoie aux guides dans /blog et aux détails d’implémentation dans /docs.