Pourquoi le message d'Ousterhout reste pertinent
John Ousterhout est un informaticien et ingénieur dont le travail couvre à la fois la recherche et les systèmes réels. Il a créé le langage Tcl, contribué à l'évolution des systèmes de fichiers modernes, et a ensuite distillé des décennies d'expérience dans une affirmation simple et un peu dérangeante : la complexité est l'ennemi principal du logiciel.
Ce message reste d'actualité parce que la plupart des équipes n'échouent pas par manque de fonctionnalités ou d'effort — elles échouent parce que leurs systèmes (et leurs organisations) deviennent difficiles à comprendre, difficiles à changer et faciles à casser. La complexité ne ralentit pas seulement les ingénieurs. Elle s'infiltre dans les décisions produit, la confiance dans la roadmap, la confiance des clients, la fréquence des incidents, et même le recrutement — car l'onboarding devient un exercice de plusieurs mois.
Le thème central : la complexité taxe tout
Le cadrage d'Ousterhout est pratique : lorsque un système accumule des cas particuliers, des exceptions, des dépendances cachées et des correctifs « juste cette fois », le coût ne se limite pas à la base de code. Tout le produit devient plus cher à faire évoluer. Les fonctionnalités prennent plus de temps, l'assurance qualité devient plus difficile, les releases deviennent plus risquées, et les équipes évitent les améliorations parce que toucher quoi que ce soit semble dangereux.
Ce n'est pas un appel à la pureté académique. C'est un rappel que chaque raccourci a des paiements d'intérêts — et la complexité est la dette au taux d'intérêt le plus élevé.
Trois angles que nous utiliserons dans cet article
Pour rendre l'idée concrète (et pas seulement motivante), nous examinerons le message d'Ousterhout selon trois angles :
- L'héritage de Tcl : ce que Tcl a bien fait en matière de simplicité, de composition et de « glue », et pourquoi ces idées se sont répandues bien au-delà du langage lui-même.\n- La connexion avec Brooks : comment « No Silver Bullet » se rapporte à la vision d'Ousterhout, où ils s'accordent, et ce que le désaccord enseigne aux équipes qui veulent livrer.\n- Règles de conception pratiques : en particulier les « modules profonds » et les techniques de conception d'API qui réduisent la charge cognitive pour la prochaine personne qui devra changer le système (qui est généralement vous).
Ce que vous pouvez en retirer
Ce texte n'est pas écrit uniquement pour les passionnés de langages. Si vous construisez des produits, dirigez des équipes ou faites des arbitrages de roadmap, vous trouverez des moyens actionnables pour repérer la complexité tôt, empêcher qu'elle ne s'institutionnalise, et traiter la simplicité comme une contrainte de premier ordre — pas seulement un bonus après le lancement.
Ce que « complexité » signifie vraiment dans les équipes quotidiennes
La complexité ce n'est pas « beaucoup de code » ou « des maths difficiles ». C'est l'écart entre ce que vous pensez que le système fera quand vous le modifiez et ce qu'il fait réellement. Un système est complexe lorsque de petites modifications semblent risquées — parce que vous ne pouvez pas prévoir le périmètre d'impact.
Dans un code sain, vous pouvez répondre : « Si nous changeons ceci, qu'est-ce qui peut casser ? » La complexité rend cette question coûteuse.
Elle se cache souvent dans :
- Dépendances cachées : une fonctionnalité dépend discrètement d'une colonne de base de données, d'un job en arrière-plan ou d'un flag de configuration qui n'est pas évident depuis le code que vous éditez.\n- Cas particuliers : « Sauf pour les clients enterprise », « Sauf quand l'utilisateur s'est inscrit avant 2021 », « Sauf si la requête vient du mobile. » Ces exceptions s'empilent jusqu'à ce que le « chemin normal » soit flou.\n- Propriété floue : personne ne se sent responsable d'une zone, donc les correctifs deviennent des rustines prudentes plutôt que de vraies améliorations. Avec le temps, la solution la plus sûre devient « ajouter un autre contournement ».
Le coût : vitesse, qualité et confiance
Les équipes ressentent la complexité comme des livraisons plus lentes (plus de temps passé à enquêter), plus de bugs (parce que le comportement est surprenant) et des systèmes fragiles (les changements exigent une coordination entre de nombreuses personnes et services). Elle pèse aussi sur l'onboarding : les nouveaux ne peuvent pas construire un modèle mental, donc ils évitent de toucher aux flux critiques.
Complexité essentielle vs accidentelle
Une partie de la complexité est essentielle : règles métier, exigences réglementaires, cas limites du monde réel. Vous ne pouvez pas supprimer cela.
Mais beaucoup est accidentelle : APIs confuses, logique dupliquée, flags « temporaires » devenus permanents, et modules qui laissent fuir des détails internes. C'est la complexité créée par les choix de conception — et la seule que vous puissiez réduire de façon systématique.
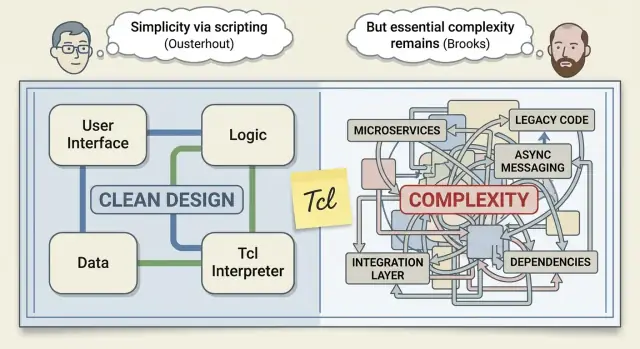
L'héritage de Tcl : les bonnes idées qui se sont répandues
Tcl est né d'un objectif pratique : faciliter l'automatisation logicielle et l'extension d'applications existantes sans les réécrire. John Ousterhout l'a conçu pour que les équipes puissent ajouter « juste assez de programmabilité » à un outil — puis donner ce pouvoir aux utilisateurs, aux opérateurs, à la QA ou à quiconque avait besoin de scriptifier des workflows.
L'idée de « glue language »
Tcl a popularisé la notion de langage de glue : une couche de scripting petite et flexible qui relie des composants écrits dans des langages plus rapides et bas niveau. Plutôt que de tout intégrer dans un monolithe, on expose un ensemble de commandes, puis on les compose pour créer de nouveaux comportements.
Ce modèle s'est avéré influent parce qu'il correspond à la façon dont le travail se déroule réellement. Les gens ne construisent pas seulement des produits ; ils créent des systèmes de build, des harness de tests, des outils d'administration, des convertisseurs de données et des automatisations ponctuelles. Une couche de scripting légère transforme ces tâches d'un « ouvrir un ticket » en un « écrire un script ».
Ce que Tcl a bien fait (et ce qui s'est répandu)
Tcl a fait de l'embarquement d'un interpréteur une préoccupation de premier plan. On pouvait intégrer un interprète dans une application, exporter une interface de commandes propre et gagner instantanément en configurabilité et en itération rapide.
On retrouve aujourd'hui ce même modèle dans les systèmes de plugins, les langages de configuration, les API d'extension et les moteurs de script embarqués — que la syntaxe ressemble ou non à Tcl.
Cela a aussi renforcé une habitude de conception importante : séparer des primitives stables (les capacités cœur de l'application hôte) de la composition changeante (les scripts). Quand cela fonctionne, les outils évoluent plus vite sans déstabiliser en permanence le noyau.
Limites et pourquoi la part de marché a évolué
La syntaxe de Tcl et son modèle « tout est une chaîne » pouvaient sembler peu intuitifs, et de grandes bases de code Tcl devenaient difficiles à raisonner sans conventions fortes. À mesure que de nouveaux écosystèmes offraient des bibliothèques standard plus riches, de meilleurs outils et des communautés plus larges, beaucoup d'équipes ont naturellement migré.
Rien de cela n'efface l'héritage de Tcl : il a contribué à normaliser l'idée que l'extensibilité et l'automatisation ne sont pas des extras — ce sont des fonctionnalités produit qui peuvent réduire dramatiquement la complexité pour les personnes qui utilisent et maintiennent un système.
Leçons de conception cachées dans la philosophie de Tcl
Tcl a été construit autour d'une idée apparemment stricte : garder le cœur petit, rendre la composition puissante, et garder les scripts lisibles pour que les gens puissent travailler ensemble sans traduction constante.
Un petit cœur qui encourage la composition
Plutôt que de livrer un vaste ensemble de fonctionnalités spécialisées, Tcl misait sur un ensemble compact de primitives (chaînes, commandes, règles d'évaluation simples) et attendait des utilisateurs qu'ils les combinent.
Cette philosophie encourage les concepteurs à réduire le nombre de concepts, réutilisés dans de nombreux contextes. La leçon pour la conception produit et d'API est évidente : si vous pouvez résoudre dix besoins avec deux ou trois blocs de construction cohérents, vous réduisez la surface que les gens doivent apprendre.
« Simple à utiliser » vs « simple à implémenter »
Un piège clé est d'optimiser pour la commodité du constructeur. Une fonctionnalité peut être facile à implémenter (copier une option existante, ajouter un flag spécial, patcher un coin) tout en rendant le produit plus difficile à utiliser.
L'accent de Tcl était inverse : garder le modèle mental serré, même si l'implémentation doit faire plus de travail en coulisse.
Quand vous examinez une proposition, demandez : cela réduit-il le nombre de concepts qu'un utilisateur doit mémoriser, ou ajoute-t-il une exception de plus ?
De petites primitives peuvent rassurer — ou être dangereusement tranchantes
Le minimalisme ne sert que si les primitives sont cohérentes. Si deux commandes se ressemblent mais se comportent différemment sur les cas limites, les utilisateurs finissent par mémoriser des détails triviaux. Un petit ensemble d'outils peut devenir un ensemble de « bords tranchants » lorsque les règles varient subtilement.
Composition vs fonctionnalités one-off (non technique)
Pensez à une cuisine : un bon couteau, une poêle et un four vous permettent de préparer de nombreux plats en combinant des techniques. Un gadget qui ne tranche que les avocats est une fonctionnalité one-off — facile à vendre, mais qui encombre les tiroirs.
La philosophie de Tcl plaide pour le couteau et la poêle : des outils généraux qui se composent proprement, pour éviter d'avoir un nouveau gadget pour chaque recette.
Brooks en une page : « No Silver Bullet » et son constat
En 1986, Fred Brooks a écrit un essai avec une conclusion volontairement provocatrice : il n'existe pas un seul saut — pas de « silver bullet » — qui rendra le développement logiciel dix fois plus rapide, moins cher et plus fiable en un seul bond.
Son propos n'était pas que le progrès est impossible. C'était que le logiciel est déjà un médium où l'on peut quasiment tout faire, et que cette liberté impose un fardeau unique : nous définissons constamment la chose en la construisant. De meilleurs outils aident, mais ils n'effacent pas la partie la plus difficile du travail.
Complexité essentielle vs accidentelle
Brooks sépare la complexité en deux catégories :
- Complexité essentielle : difficulté issue du problème lui-même — règles du monde réel, cas limites et objectifs concurrents que le logiciel doit représenter.\n- Complexité accidentelle : difficulté créée par nos méthodes et outils — langages maladroits, pipelines de build bancals, déploiements manuels ou architectures qui vous obligent à penser à trop de détails à la fois.
Les outils peuvent écraser la complexité accidentelle. Pensez à ce que nous avons gagné avec les langages de haut niveau, le contrôle de version, le CI, les containers, les bases de données gérées et de bons IDEs. Mais Brooks soutenait que la complexité essentielle domine, et elle ne disparaît pas parce que l'outillage s'améliore.
Pourquoi cela compte encore
Même avec des plateformes modernes, les équipes passent encore la majeure partie de leur énergie à négocier les exigences, intégrer des systèmes, gérer les exceptions et maintenir la cohérence comportementale dans le temps. La surface change peut-être (APIs cloud au lieu de pilotes matériels), mais le défi central reste : traduire des besoins humains en comportements précis et maintenables.
Cela crée la tension sur laquelle Ousterhout insiste : si la complexité essentielle ne peut pas être éliminée, une conception disciplinée peut-elle réduire significativement la part de celle-ci qui fuit dans le code — et dans la tête des développeurs au quotidien ?
Le débat « Ousterhout vs Brooks », sans emportement
Du concept au code
Transformez un flux produit clair en une application web React avec un backend Go.
On présente parfois « Ousterhout vs Brooks » comme un affrontement entre optimisme et réalisme. Il est plus utile de le lire comme deux ingénieurs expérimentés décrivant des facettes différentes du même problème.
La réplique d'Ousterhout : la conception achète plus qu'on l'imagine
L'argument de Brooks dans « No Silver Bullet » dit qu'il n'existe pas de percée unique qui supprime magiquement la partie la plus dure du logiciel. Ousterhout ne conteste pas vraiment cela.
Sa réplique est plus étroite et pratique : les équipes traitent souvent la complexité comme inévitable alors qu'une grande partie est auto-infligée.
Selon Ousterhout, une bonne conception peut réduire significativement la complexité — pas en rendant le logiciel « facile », mais en le rendant moins confus à modifier. C'est une grande affirmation, et elle compte parce que la confusion transforme le travail quotidien en travail lent.
L'avertissement de Brooks : une part de complexité est inhérente
Brooks insiste sur la difficulté essentielle : le logiciel doit modéliser des réalités désordonnées, des exigences changeantes et des cas limites externes au code. Même avec de bons outils et des gens brillants, on ne peut pas supprimer cela. On peut seulement la gérer.
Là où ils s'accordent réellement
Ils se recoupent plus qu'on ne le pense :
- Une part de la complexité est inévitable parce que le monde est compliqué.\n- Une grande partie de la douleur vient de la complexité accidentelle — détails et exceptions qui n'auraient pas à exister.\n- Le coût réel apparaît plus tard : itération plus lente, risque plus élevé et zones « n'y touchez pas ».
La question pratique pour les équipes
Plutôt que de demander « Qui a raison ? », demandez : Quelle complexité pouvons-nous contrôler ce trimestre ?
Les équipes ne contrôlent pas les changements de marché ou la difficulté fondamentale du domaine. Mais elles peuvent contrôler si de nouvelles fonctionnalités ajoutent des cas particuliers, si des APIs forcent les appelants à retenir des règles cachées, et si les modules cachent la complexité ou la laissent fuir.
C'est le compromis actionnable : acceptez la complexité essentielle, et soyez impitoyable sur l'accidentelle.
Modules profonds : cacher la complexité de la bonne manière
Un module profond est un composant qui fait beaucoup, tout en exposant une interface petite et facile à comprendre. La « profondeur » est la quantité de complexité que le module absorbe : les appelants n'ont pas besoin de connaître les détails, et l'interface ne les y oblige pas.
Un module superficiel est l'inverse : il peut envelopper une petite logique, mais il repousse la complexité vers l'extérieur — via beaucoup de paramètres, des flags spéciaux, un ordre d'appel imposé ou des règles « vous devez vous souvenir de… ».
Profond vs superficiel : une analogie réelle
Pensez à un restaurant. Un module profond est la cuisine : vous commandez « des pâtes » sur un menu simple et vous ne vous souciez pas des choix de fournisseur, des temps d'ébullition ou du dressage.
Un module superficiel est une « cuisine » qui vous remet des ingrédients bruts avec une notice en 12 étapes et vous demande d'apporter votre propre poêle. Le travail est toujours fait — mais il a été déplacé vers le client.
Quand ajouter des couches aide (et quand ça nuit)
Les couches supplémentaires sont utiles si elles concentrent de nombreuses décisions en un choix évident.
Par exemple, une couche de stockage qui expose save(order) et gère en interne les retries, la sérialisation et l'indexation est profonde.
Les couches nuisent quand elles renvoient essentiellement les mêmes choses ou ajoutent des options. Si une nouvelle abstraction introduit plus de configuration qu'elle n'en retire — par exemple save(order, format, retries, timeout, mode, legacyMode) — elle est probablement superficielle. Le code peut sembler « organisé », mais la charge cognitive apparaît sur chaque point d'appel.
Checklist rapide : repérer les modules superficiels
- L'API a beaucoup de paramètres, surtout des booléens comme
useCache, skipValidation, force, legacy.\n- Les appelants doivent suivre une séquence spécifique (« appeler A avant B ») pour éviter des bugs subtils.\n- Le module laisse fuir des concepts internes (chemins de fichiers, noms de tables, règles de threads) dans l'interface.\n- La plupart des changements exigent de toucher de nombreux points d'appel parce que l'abstraction ne stabilise pas le comportement.\n- La doc ressemble davantage à une mise en garde qu'à une promesse (« N'utilisez pas X quand Y sauf Z »).
Les modules profonds n'« encapsulent » pas seulement du code. Ils encapsulent des décisions.
Conception d'API qui réduit la charge cognitive
Concevoir d'abord, construire ensuite
Utilisez le mode planification pour clarifier les API et les invariants avant de générer le code.
Une bonne API n'est pas simplement capable de faire beaucoup. C'est une API que les gens peuvent garder en tête pendant qu'ils travaillent.
La lentille de conception d'Ousterhout vous pousse à juger une API selon l'effort mental qu'elle exige : combien de règles il faut retenir, combien d'exceptions il faut prévoir, et à quel point il est facile de faire une erreur.
Ce qui rend une API facile pour les humains
Les APIs conviviales sont généralement petites, cohérentes et difficiles à mal utiliser.
Petit ne signifie pas sous-dimensionné — cela signifie que la surface se concentre sur quelques concepts qui se composent bien. Cohérent signifie qu'un même schéma fonctionne à travers tout le système (paramètres, gestion des erreurs, nommage, types de retour). Difficile à mal utiliser signifie que l'API oriente vers des chemins sûrs : invariants clairs, validation aux frontières et vérifications qui échouent tôt.
Pourquoi « plus d'options » augmente le coût de tous
Chaque flag, mode ou configuration « au cas où » devient une taxe pour tous les utilisateurs. Même si seuls 5 % des appelants en ont besoin, 100 % doivent désormais savoir qu'elle existe, se demander s'ils en ont besoin et interpréter le comportement quand elle interagit avec d'autres options.
C'est ainsi que les APIs accumulent de la complexité cachée : pas dans un seul appel, mais dans les combinatoires.
Valeurs par défaut, conventions et nommage
Les valeurs par défaut sont une bienveillance : elles permettent à la plupart des appelants d'omettre des décisions et d'obtenir quand même un comportement sensé. Les conventions (une manière évidente de faire) réduisent les bifurcations dans l'esprit de l'utilisateur. Le nommage travaille aussi : choisissez des verbes et des noms qui correspondent à l'intention de l'utilisateur, et gardez des opérations similaires nommées de façon semblable.
Un rappel : les APIs internes comptent autant que les publiques. La plupart de la complexité produit vit en coulisse — frontières de services, bibliothèques partagées et modules « helper ». Traitez ces interfaces comme des produits, avec revues et discipline de versioning (voir aussi /blog/deep-modules).
Où la complexité s'infiltre : correctifs tactiques et cas particuliers
La complexité n'arrive pas souvent comme une « mauvaise décision » unique. Elle s'accumule par petites rustines raisonnables — surtout quand les équipes sont sous pression et que l'objectif immédiat est de livrer.
Pièges courants qui se cumulent silencieusement
Un piège est les feature flags partout. Les flags servent pour des déploiements sûrs, mais quand ils s'attardent, chaque flag multiplie le nombre de comportements possibles. Les ingénieurs cessent de raisonner sur « le système » et commencent à raisonner sur « le système, sauf quand le flag A est activé et que l'utilisateur est dans le segment B ».
Un autre est la logique des cas particuliers : « Les clients enterprise ont besoin de X », « Sauf dans la région Y », « À moins que le compte ait plus de 90 jours ». Ces exceptions se répandent souvent dans la base de code, et après quelques mois plus personne ne sait lesquelles sont encore nécessaires.
Un troisième est l'abstraction qui fuit. Une API qui force les appelants à comprendre des détails internes (timing, format de stockage, règles de cache) pousse la complexité vers l'extérieur. Au lieu d'un module qui porte le fardeau, chaque appelant apprend les bizarreries.
Programmation tactique vs stratégique (version simple)
Programmation tactique : optimiser pour cette semaine : correctifs rapides, changements minimaux, « patcher ».\n
Programmation stratégique : optimiser pour l'année suivante : petites refontes qui empêchent la même classe de bugs et réduisent le travail futur.
Le danger est « l'intérêt de maintenance ». Un contournement rapide semble peu coûteux maintenant, mais vous le payez avec intérêts : onboarding plus lent, releases fragiles et développement conduit par la peur où personne ne veut toucher l'ancien code.
Garde-fous simples qui aident réellement
Ajoutez des invites légères dans les revues de code : « Ceci ajoute-t-il un nouveau cas particulier ? » « L'API peut-elle cacher ce détail ? » « Quelle complexité laissons-nous derrière ? »
Gardez de courts comptes-rendus de décision pour les arbitrages non triviaux (quelques puces suffisent). Et réservez un petit budget de refactor chaque sprint pour que les corrections stratégiques ne soient pas traitées comme du travail extracurriculaire.
Pourquoi la complexité tue des produits, pas seulement des bases de code
La complexité ne reste pas enfermée dans l'ingénierie. Elle fuit vers les plannings, la fiabilité et l'expérience client.
Coûts au niveau produit : vitesse, stabilité et onboarding
Quand un système est difficile à comprendre, chaque changement prend plus de temps. Le time-to-market glisse parce que chaque release exige plus de coordination, plus de tests de régression et plus de cycles « pour être sûr ».
La fiabilité en pâtit aussi. Les systèmes complexes créent des interactions que personne ne peut totalement prévoir, donc les bugs apparaissent comme des cas limites : le paiement échoue seulement quand un coupon, un panier sauvegardé et une règle fiscale régionale se combinent d'une certaine façon. Ce sont les incidents les plus difficiles à reproduire et les plus longs à corriger.
L'onboarding devient un frein caché. Les nouveaux ne peuvent pas construire un modèle mental utile, ils évitent les zones risquées, copient des patterns qu'ils ne comprennent pas et ajoutent involontairement plus de complexité.
La complexité se manifeste comme une confusion client
Les clients ne se préoccupent pas de savoir si un comportement est causé par un « cas particulier » dans le code. Ils le vivent comme de l'incohérence : des paramètres qui ne s'appliquent pas partout, des flux qui changent selon le chemin d'arrivée, des fonctionnalités qui fonctionnent « la plupart du temps ».
La confiance diminue, le churn augmente et l'adoption stagne.
La taxe complexité sur le support et l'opérationnel
Les équipes support paient la complexité via des tickets plus longs et plus d'échanges pour rassembler le contexte. L'opérationnel paie via plus d'alertes, plus de runbooks et des déploiements plus prudents. Chaque exception devient quelque chose à surveiller, documenter et expliquer.
Exemple concret : encore une fonctionnalité vs flux plus simples
Imaginez une demande pour « une règle de notification supplémentaire ». L'ajout semble rapide, mais il introduit une branche de comportement de plus, plus de copies d'écran UI, plus de cas de test et plus de façons pour les utilisateurs de mal configurer les choses.
Comparez cela à la simplification du flux de notification existant : moins de types de règles, des valeurs par défaut plus claires et un comportement cohérent sur web et mobile. Vous livrez peut-être moins de boutons, mais vous réduisez les surprises — rendant le produit plus simple à utiliser, plus facile à supporter et plus rapide à faire évoluer.
Visez des modules profonds
Définissez une petite interface, puis laissez Koder.ai gérer les parties complexes en coulisses.
Traitez la complexité comme la performance ou la sécurité : quelque chose que vous planifiez, mesurez et protégez. Si vous ne remarquez la complexité que lorsque la livraison ralentit, vous payez déjà des intérêts.
Mettez un « budget de complexité » dans la roadmap
Aux côtés du scope produit, définissez combien de complexité nouvelle une release est autorisée à introduire. Le budget peut être simple : « pas de concepts nets nouveaux sauf si on en retire un », ou « toute nouvelle intégration doit remplacer un chemin ancien ».
Rendez les arbitrages explicites lors de la planification : si une fonctionnalité nécessite trois nouveaux modes de configuration et deux cas d'exception, cela doit « coûter » plus qu'une fonctionnalité qui tient dans les concepts existants.
Utilisez des métriques légères que les équipes peuvent tenir
Vous n'avez pas besoin de chiffres parfaits — seulement des signaux qui pointent dans la bonne direction :
- Surface des modules : nombre de méthodes/endpoints publics, flags ou champs de configuration exposés.\n- Nombre de concepts : combien d'idées un utilisateur (ou un nouvel ingénieur) doit apprendre pour réussir.\n- Taux d'échec des changements : fréquence à laquelle les déploiements nécessitent rollback, hotfix ou travail urgent.
Suivez ces indicateurs par release, et liez-les aux décisions : « Nous avons ajouté deux nouvelles options publiques ; qu'avons-nous supprimé ou simplifié pour compenser ? »
Prototyper pour tester la simplicité, pas seulement la faisabilité
Les prototypes sont souvent jugés sur « Peut-on le construire ? ». Utilisez-les plutôt pour répondre : « Est-ce simple à utiliser et difficile à mal utiliser ? »
Demandez à quelqu'un qui ne connaît pas la fonctionnalité de tenter une tâche réaliste avec le prototype. Mesurez le temps pour réussir, les questions posées et où il fait de mauvaises hypothèses. Ce sont les points chauds de complexité.
C'est aussi là que les workflows modernes peuvent réduire la complexité accidentelle — si ils gardent l'itération serrée et permettent d'annuler facilement les erreurs. Par exemple, quand des équipes utilisent une plateforme de vibe-coding comme Koder.ai pour esquisser un outil interne ou un nouveau flux via chat, des fonctionnalités comme le mode planification (pour clarifier l'intention avant génération) et les captures/rollback (pour annuler rapidement des changements risqués) peuvent rendre l'expérimentation précoce plus sûre — sans s'engager dans une pile d'abstractions à moitié finies. Si le prototype est validé, vous pouvez toujours exporter le code source et appliquer la même discipline de « module profond » et de conception d'API décrite plus haut.
Planifiez des nettoyages de complexité avec des critères de réussite clairs
Rendez le « nettoyage de complexité » périodique (chaque trimestre ou à chaque release majeure), et définissez ce que « fini » signifie :
- Supprimer une option ou un cas particulier (pas seulement refactorer).\n- Réduire les étapes d'onboarding ou la configuration requise.\n- Fusionner deux APIs qui se chevauchent en une seule.\n- Améliorer le taux d'échec des changements pour une zone ciblée.
Le but n'est pas d'avoir un code plus propre en abstraction — c'est moins de concepts, moins d'exceptions et des changements plus sûrs.
Actions pratiques pour les équipes ce trimestre
Voici quelques mouvements qui traduisent l'idée d'Ousterhout « la complexité est l'ennemi » en habitudes semaine après semaine.
5–7 points percutants
- Traitez la complexité comme un centre de coût : si elle n'apporte pas de valeur utilisateur, elle nécessite une approbation budgétaire.\n- Préférez moins, mais des modules profonds à de nombreuses couches fines qui laissent fuir des détails.\n- Visez des interfaces qui s'expliquent d'elles-mêmes : bons noms, surface petite, invariants clairs.\n- Ne « rajoutez pas juste une option ». Les options multiplient les interactions ; les cas particuliers se cumulent avec le temps.\n- Si une correction exige une connaissance de l'appelant, vous avez probablement déplacé la complexité vers l'extérieur.\n- Faites de la suppression une métrique de succès : retirer du code et des cas est souvent le travail de conception le plus à fort levier.
Court plan d'action (1–2 semaines)
Choisissez un sous-système qui cause régulièrement de la confusion (douleurs d'onboarding, bugs récurrents, beaucoup de questions « comment ça marche ? »).
- Cartographiez l'interface : listez fonctions/endpoints publics/flags de config et ce que les appelants doivent savoir.\n2. Simplifiez le contrat : consolidez les paramètres, supprimez les flags « mode », et notez 2–3 invariants que le module garantit.\n3. Supprimez les cas particuliers : retirez les branches ajoutées pour un client, un environnement ou un bug historique — puis remplacez par une règle générale.\n4. Ajoutez une garde légère : nouveaux flags et exceptions requièrent une note de conception courte et un relecteur qui demande « Peut-on éviter ce cas particulier ? »
Lectures complémentaires et suites
- John Ousterhout, A Philosophy of Software Design\n- Fred Brooks, “No Silver Bullet”\n- Fred Brooks, The Mythical Man-Month (en particulier sur l'intégrité conceptuelle)
Suivis internes que vous pouvez lancer : une « revue de complexité » en planification (/blog/complexity-review) et une vérification rapide pour savoir si vos outils réduisent la complexité accidentelle plutôt qu'ils n'ajoutent des couches (/pricing).
Quelle serait la première complexité que vous supprimeriez si vous ne pouviez retirer qu'un seul cas particulier cette semaine ?