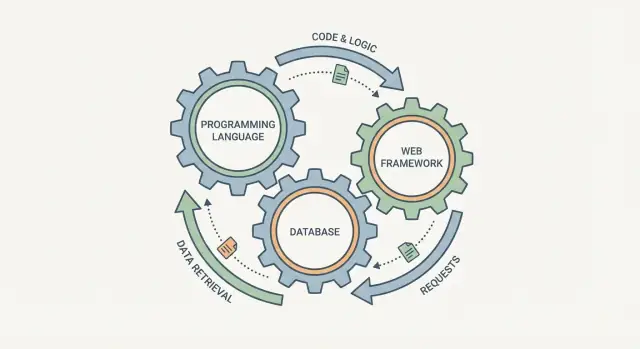
Pourquoi ce ne sont pas des choix séparés
Il est tentant de cocher un langage, une base de données et un framework comme trois items indépendants. En pratique, ils fonctionnent plutôt comme des engrenages connectés : changez l’un, et les autres le ressentent.
Un framework web façonne la façon dont les requêtes sont traitées, comment les données sont validées et comment les erreurs sont exposées. La base de données façonne ce qui est « facile à stocker », comment on interroge l’information, et quelles garanties on obtient lorsque plusieurs utilisateurs agissent simultanément. Le langage se situe au milieu : il détermine à quel point on peut exprimer les règles en sécurité, comment on gère la concurrence et sur quelles bibliothèques/outils on peut compter.
Ce que signifie « un seul système »
Traiter la stack comme un seul système, c’est ne pas optimiser chaque partie isolément. Vous choisissez une combinaison qui :
- Représente naturellement vos données (pour éviter les conversions permanentes)
- Supporte vos besoins de cohérence (pour que les bugs ne se cachent pas dans des cas limites)
- Correspond au flux de travail de votre équipe (pour que livrer et maintenir soit prévisible)
Cet article reste pratique et volontairement non technique. Vous n’avez pas besoin de mémoriser la théorie des bases de données ou les internals des langages — voyez simplement comment les choix se propagent à travers l’application.
Un exemple rapide : utiliser une base sans schéma pour des données métier très structurées et orientées reporting mène souvent à des « règles » éparpillées dans le code applicatif et à des analyses confuses plus tard. Une meilleure combinaison serait d’associer ce domaine à une base relationnelle et à un framework qui encourage la validation cohérente et les migrations, pour que vos données restent cohérentes à mesure que le produit évolue.
Quand vous planifiez la stack ensemble, vous concevez un seul ensemble de compromis — pas trois paris séparés.
Un modèle mental simple : requête entrée, données sortie
Une façon utile de penser la « stack » est comme un pipeline unique : une requête utilisateur entre dans votre système, et une réponse (plus des données sauvegardées) en sort. Le langage de programmation, le framework web et la base de données ne sont pas des choix indépendants — ce sont les trois parties du même trajet.
Le parcours d’une requête
Imaginez qu’un client met à jour son adresse de livraison.
- Requête entrante : Le framework reçoit une requête HTTP. Le routage décide quel handler exécuter (ex.
/account/address). La validation vérifie que l’entrée est complète et sensée.
- Travail : Le code applicatif (dans votre langage choisi) exécute les règles métier : « L’utilisateur est‑il connecté ? », « Le format d’adresse est‑il acceptable ? », « Faut‑il marquer cette commande pour re‑vérification ? »
- Données : La couche base lit et écrit des enregistrements — souvent dans une transaction — de sorte que la mise à jour soit entièrement appliquée ou pas du tout.
- Réponse : Le framework formate le résultat (HTML/JSON), définit les codes de statut et renvoie la réponse à l’utilisateur.
- Après coup : Des jobs en arrière‑plan peuvent s’exécuter (envoyer un email de confirmation, mettre à jour l’index de recherche, notifier l’entrepôt).
De quoi chaque choix est réellement responsable
- Langage : Comment le code s’exécute (modèle d’exécution / concurrence), la facilité de test et de debug, et si les compétences/outils de l’équipe rendent les changements sûrs et rapides.
- Framework : Le « contrôle du trafic » des requêtes — routage, validation, hooks d’authentification, gestion des erreurs, et patterns intégrés pour les jobs en arrière‑plan.
- Base de données : Comment les données sont stockées et interrogées, quelles contraintes empêchent les mauvaises données, et comment les transactions maintiennent la cohérence des mises à jour liées.
Quand ces trois éléments s’alignent, une requête circule proprement. Quand ils ne le sont pas, vous obtenez des frictions : accès aux données maladroits, validations qui fuient, et bugs de cohérence subtils.
Modèle de données d’abord : le vrai pilote de la fit de la stack
La plupart des débats sur la « stack » commencent par la marque du langage ou de la base. Un meilleur point de départ est votre modèle de données — car il dicte discrètement ce qui sera naturel (ou pénible) partout ailleurs : validation, requêtes, APIs, migrations, et même le workflow d’équipe.
Les applications jonglent généralement avec quatre formes à la fois :
- Objets dans le code (classes, structs, enregistrements typés)
- Lignes dans des tables relationnelles
- Documents dans un stockage de style JSON ou des APIs
- Événements dans des logs/streams (« OrderPlaced », « EmailSent »)
Un bon ajustement se produit quand vous ne passez pas vos journées à traduire entre ces formes. Si vos données centrales sont fortement connectées (utilisateurs ↔ commandes ↔ produits), les lignes et les jointures peuvent garder la logique simple. Si vos données sont surtout « un blob par entité » avec des champs variables, les documents réduisent la cérémonie — jusqu’au moment où vous avez besoin de reporting inter‑entités.
Schéma vs structure flexible (et où logent les règles)
Quand la base a un schéma fort, beaucoup de règles peuvent vivre près des données : types, contraintes, clés étrangères, unicité. Cela réduit souvent les vérifications dupliquées entre services.
Avec des structures flexibles, les règles remontent dans l’application : code de validation, payloads versionnés, backfills, logique de lecture prudente (« si le champ existe, alors … »). Cela peut très bien fonctionner quand les exigences produit changent chaque semaine, mais cela augmente la charge sur votre framework et vos tests.
Votre modèle décide si votre code est surtout :
- Interrogations et jointures (fortement relationnel)
- Transformations de JSON imbriqué (orienté document)
- Rejeu et agrégation d’événements (orienté événement)
Cela influence à son tour les besoins en langage et framework : le typage fort peut prévenir la dérive subtile des champs JSON, tandis qu’un outillage de migration mature est plus important quand les schémas évoluent fréquemment.
Exemples : profil utilisateur, commandes, journal d’audit
- Profil utilisateur : souvent de type document (préférences, champs optionnels) mais bénéficie de contraintes relationnelles pour l’identité et l’unicité.
- Commandes : typiquement relationnelles (lignes de commande, totaux, statuts) car la cohérence et le reporting comptent.
- Journal d’audit : naturellement orienté événement — append‑only, rarement mis à jour, optimisé pour les requêtes par temps, acteur ou entité.
Choisissez le modèle d’abord ; le « bon » choix de framework et de base devient souvent clair après cela.
Transactions et cohérence : où naissent souvent les bugs
Les transactions sont les garanties « tout ou rien » dont votre appli dépend sans bruit. Quand un paiement aboutit, vous attendez que la commande, le statut de paiement et la mise à jour d’inventaire soient tous appliqués — ou aucun d’eux ne le soit. Sans cette promesse, vous obtenez les pires types de bugs : rares, coûteux et difficiles à reproduire.
Ce que font vraiment les transactions
Une transaction regroupe plusieurs opérations de base de données en une seule unité de travail. Si quelque chose échoue en cours de route (erreur de validation, timeout, plantage), la base peut revenir à l’état sûr précédent.
Cela compte au‑delà des flux monétaires : création de compte (ligne utilisateur + ligne profil), publication de contenu (post + tags + pointeurs d’index de recherche), ou tout workflow touchant plusieurs tables.
Cohérence vs vitesse (en clair)
Cohérence signifie « les lectures reflètent la réalité ». Vitesse signifie « retourner quelque chose rapidement ». Beaucoup de systèmes font des compromis :
- Cohérence forte : les utilisateurs voient les dernières données commit, moins de surprises, souvent un coût de coordination plus élevé.
- Cohérence éventuelle : les mises à jour se propagent avec le temps, généralement plus rapide et plus simple à scaler, mais votre appli doit gérer des désaccords temporaires.
Le piège courant est de choisir une configuration à cohérence éventuelle, puis de coder comme si elle était forte.
Les frameworks et ORMs ne créent pas de transactions automatiquement parce que vous avez appelé plusieurs méthodes save. Certains exigent des blocs de transaction explicites ; d’autres ouvrent une transaction par requête, ce qui peut masquer des problèmes de performance.
Les retries sont délicats aussi : les ORM peuvent retenter sur des deadlocks ou des échecs transitoires, mais votre code doit être sûr à exécuter deux fois.
Pièges courants
Les écritures partielles surviennent lorsque vous mettez à jour A puis échouez avant B. Les actions dupliquées surviennent quand une requête est retentée après un timeout — surtout si vous avez facturé une carte ou envoyé un email avant que la transaction ne soit commit.
Une règle simple aide : effectuez les effets secondaires (emails, webhooks) après le commit en base, et rendez les actions idempotentes via des contraintes d’unicité ou des clés d’idempotence.
La couche d’accès aux données : ORM, requêtes et migrations
C’est la « couche de traduction » entre votre code applicatif et votre base. Les choix ici pèsent souvent plus au quotidien que la marque de la base elle‑même.
ORM vs query builder vs SQL brut (en clair)
Un ORM (Object-Relational Mapper) vous permet de traiter des tables comme des objets : créer un User, mettre à jour un Post, et l’ORM génère le SQL. Il est productif car il standardise les tâches courantes et masque le travail répétitif.
Un query builder est plus explicite : vous construisez une requête de type SQL en code (chaînes de fonctions). Vous pensez toujours en « joins, filtres, groups », mais vous gagnez en sécurité des paramètres et en composabilité.
Le SQL brut consiste à écrire le SQL directement. C’est le plus direct et souvent le plus clair pour les requêtes de reporting complexes — au prix de plus de travail manuel et de conventions.
Les langages avec un typage fort (TypeScript, Kotlin, Rust) tendent à pousser vers des outils qui peuvent valider les requêtes et les shapes de résultats tôt. Cela réduit les surprises à l’exécution, mais encourage centraliser l’accès aux données pour éviter que les types ne divergent.
Les langages offrant du métaprogramming flexible (Ruby, Python) rendent souvent les ORMs naturels et rapides pour itérer — jusqu’au moment où les requêtes cachées ou les comportements implicites deviennent difficiles à raisonner.
Migrations : garder code et schéma synchronisés
Les migrations sont des scripts de changement de schéma versionnés : ajouter une colonne, créer un index, backfiller des données. L’objectif est simple : n’importe qui peut déployer l’app et obtenir la même structure de base. Traitez les migrations comme du code que l’on révise, teste et annule si nécessaire.
Quand les abstractions « faciles » nuisent
Les ORM peuvent générer silencieusement des N+1 queries, récupérer de grosses lignes inutiles, ou compliquer les jointures. Les query builders peuvent devenir des « chaînes » illisibles. Le SQL brut peut être dupliqué et incohérent.
Une bonne règle : utilisez l’outil le plus simple qui garde l’intention évidente — et pour les chemins critiques, inspectez le SQL réellement exécuté.
Compensez votre temps de développement
Obtenez des crédits en partageant vos réalisations avec Koder.ai ou en invitant d'autres à l'essayer.
On blâme souvent « la base de données » quand une page est lente. Mais la latence visible par l’utilisateur est la somme de plusieurs petites attentes sur tout le chemin de la requête.
D’où vient réellement la latence
Une requête paie typiquement pour :
- Temps réseau (client → load balancer → app → base et retour)
- Temps de requête (SQL lent, index manquants, trop d’allers‑retours)
- Sérialisation/désérialisation (encodage JSON, mapping ORM, compression)
- Logique applicative (validation, permissions, rendu, appels API externes)
Même si votre base répond en 5 ms, une appli qui fait 20 requêtes par requête, bloque sur I/O et passe 30 ms à sérialiser une immense réponse restera lente.
Ouvrir une nouvelle connexion est coûteux et peut submerger la base sous charge. Un pool de connexions réutilise des connexions existantes pour que les requêtes n’aient pas ce coût à chaque fois.
Le piège : la taille idéale du pool dépend de votre modèle d’exécution. Un serveur asynchrone très concurrent peut créer une demande massive ; sans limites de pool, vous aurez de la mise en file d’attente, des timeouts et des échecs bruyants. Avec des pools trop stricts, votre appli devient le goulot d’étranglement.
Caching : ce qu’il corrige — et ce qu’il ne corrige pas
Le cache peut être côté navigateur, CDN, cache en processus, ou cache partagé (Redis). Il aide quand beaucoup de requêtes demandent les mêmes résultats.
Mais le caching ne sauvera pas :
- Les chemins d’écriture inefficaces
- Les réponses fortement personnalisées
- Les endpoints dominés par des appels externes lents
Runtime : threads vs async
Le runtime du langage façonne le débit. Un modèle thread‑par‑requête peut gaspiller des ressources en attente d’I/O ; un modèle async augmente la concurrence, mais rend la gestion de la pression (comme les limites de pool) essentielle. C’est pourquoi l’optimisation de la performance est une décision de stack, pas seulement de base.
Sécurité et fiabilité : responsabilité partagée dans la stack
La sécurité n’est pas quelque chose qu’on « ajoute » via un plugin de framework ou un réglage de la base. C’est l’accord entre votre langage/runtime, votre framework web et votre base de données sur ce qui doit toujours être vrai — même lorsqu’un développeur se trompe ou qu’un nouvel endpoint est ajouté.
Authentification vs autorisation : couches différentes, même résultat
L’authentification (qui est-ce ?) vit souvent à la frontière du framework : sessions, JWT, callbacks OAuth, middleware. L’autorisation (ce qu’ils peuvent faire) doit être appliquée de façon cohérente à la fois dans la logique applicative et via des règles de données.
Un pattern courant : l’app décide de l’intention (« l’utilisateur peut éditer ce projet »), et la base renforce les frontières (IDs de tenant, contraintes de propriété, et — quand c’est pertinent — des policies au niveau ligne). Si l’autorisation n’existe que dans les contrôleurs, les jobs en arrière‑plan et les scripts internes peuvent la contourner par inadvertance.
Validation : framework, base, ou les deux ?
La validation côté framework donne un retour rapide et de bons messages. Les contraintes en base offrent un filet de sécurité final.
Utilisez les deux quand c’est important :
- Framework : champs requis, formats, messages conviviaux.
- Base : unicité, clés étrangères, CHECK, NOT NULL.
Cela réduit les « états impossibles » qui apparaissent quand deux requêtes sont en concurrence ou quand un nouveau service écrit des données différemment.
Secrets, chiffrement et audit
Les secrets doivent être gérés par le runtime et le workflow de déploiement (variables d’environnement, gestionnaires de secrets), pas codés en dur. Le chiffrement peut s’effectuer côté applicatif (chiffrement au niveau du champ) et/ou côté base (chiffrement au repos, KMS géré), mais il faut clarifier qui fait la rotation des clés et comment récupérer les données.
L’audit est aussi partagé : l’app doit émettre des événements significatifs ; la base doit conserver des logs immuables si pertinent (tables d’audit append‑only, accès restreint).
Modes de défaillance typiques
Faire trop confiance à la logique applicative est classique : contraintes manquantes, nulls silencieux, flags « admin » sans vérification. La solution est simple : supposez que des bugs arriveront, et concevez la stack pour que la base puisse refuser des écritures non sûres — même de la part de votre propre code.
Voies de montée en charge : ce que chaque choix débloque ou bloque
Testez les changements sans crainte
Expérimentez des changements de schéma et des fonctionnalités, puis revenez en arrière en toute sécurité si quelque chose cloche.
La mise à l’échelle échoue rarement parce que « la base ne peut pas le faire ». Elle échoue parce que toute la stack réagit mal quand la charge change de forme : un endpoint devient populaire, une requête devient « hot », un workflow se met à retenter.
Quand le trafic augmente, la douleur apparaît à des endroits précis
La plupart des équipes rencontrent les mêmes goulots :
- Requêtes chaudes : une requête de page/top dashboard tourne en continu et domine CPU/IO.
- Contention de verrous : des mises à jour s’accumulent derrière quelques lignes (compteurs d’inventaire,
last_seen, tables de queue).
- Pression sur les connexions : les workers ouvrent trop de connexions ; la base passe son temps à gérer des sessions plutôt qu’à faire du travail.
Votre capacité à répondre rapidement dépend de la visibilité que fournissent le framework et l’outillage DB sur les plans de requête, les migrations, le pooling et les patterns de cache sûrs.
Réplicas de lecture, sharding et queues : quand ils arrivent
Les mouvements d’échelle courants arrivent souvent dans cet ordre :
- Réplicas de lecture quand les lectures surpassent les écritures et que vous pouvez tolérer des données légèrement obsolètes. Votre ORM/framework doit supporter le split lecture/écriture (ou faciliter le routage des requêtes).
- Queues / jobs en arrière‑plan quand le travail « maintenant » commence à nuire à la latence des requêtes (emails, exports, appels facturation). C’est aussi là que les retries et la déduplication deviennent des exigences réelles.
- Sharding / partitionnement quand un primaire unique ne suit plus en débit d’écriture ou en croissance de stockage. Cela exige une modélisation soigneuse : clés de shard, requêtes cross‑shard, et limites transactionnelles.
Travail en arrière‑plan et idempotence sont des fonctionnalités de framework
Une stack scalable a besoin d’un support natif pour les tâches background, la planification et les retries sûrs.
Si votre système de jobs ne peut pas garantir l’idempotence, vous « scalerez » vers la corruption des données. Les choix précoces — s’appuyer sur des transactions implicites, des contraintes faibles d’unicité, ou des comportements ORM opaques — peuvent bloquer l’introduction propre de queues, du pattern outbox, ou de workflows « presque une fois » plus tard.
L’alignement précoce paie : choisissez une base qui correspond à vos besoins de cohérence, et un écosystème de framework qui rend l’étape suivante (réplicas, queues, partitionnement) une voie supportée plutôt qu’un rewrite.
Expérience développeur et opérations : un seul workflow
Une stack est « facile » quand développement et opérations partagent les mêmes hypothèses : comment démarrer l’app, comment changent les données, comment tournent les tests, et comment savoir ce qui s’est passé quand quelque chose casse. Si ces pièces ne concordent pas, les équipes perdent du temps sur du glue code, des scripts fragiles et des runbooks manuels.
Rapidité en développement local
Un démarrage local rapide est une fonctionnalité. Préférez un workflow où un nouveau membre peut cloner, installer, lancer les migrations et disposer de données réalistes en minutes — pas en heures.
Cela signifie généralement :
- Une commande pour démarrer l’app et ses dépendances (souvent via containers).
- Des migrations qui s’exécutent de façon fiable sur chaque machine.
- Des données seeds qui correspondent à la forme production (pas seulement des lignes « hello world »).
Si l’outillage de migrations du framework lutte avec votre choix de base, chaque changement de schéma devient un petit projet.
Pyramide de tests adaptée à votre stack
Votre stack doit faciliter naturellement l’écriture de :
- Tests unitaires sans base de données.
- Tests d’intégration qui utilisent le vrai schéma et les vraies requêtes.
- Tests end‑to‑end qui exercent tout le chemin de la requête.
Un échec courant : les équipes s’appuient sur des tests unitaires parce que les tests d’intégration sont lents ou difficiles à configurer. C’est souvent un décalage stack/ops — le provisioning de DB de test, les migrations et les fixtures ne sont pas fluides.
Observabilité appli et base
Quand la latence monte, vous devez suivre une requête depuis le framework jusque dans la base.
Cherchez des logs structurés, des métriques de base (taux de requêtes, erreurs, temps DB) et des traces incluant le timing des requêtes. Même un simple identifiant de corrélation présent dans les logs applicatifs et DB transforme le « guessing » en « finding ».
Fit opérationnel : changement sûr et récupération
L’opération n’est pas séparée du développement ; c’en est la continuation.
Choisissez des outils qui supportent :
- Backups et restores testés (pas seulement configurés)
- Changements de schéma qui peuvent être déployés en sécurité (et parfois annulés)
- Un chemin clair pour « ce qui se passe pendant le déploiement » pour que les releases ne dépendent pas du savoir tribal
Si vous ne pouvez pas répéter une restauration ou une migration localement, vous ne le ferez pas bien sous pression.
Checklist pratique pour choisir une stack cohérente
Choisir une stack, ce n’est pas choisir les « meilleurs » outils, c’est choisir des outils qui fonctionnent ensemble sous vos contraintes réelles. Utilisez cette checklist pour forcer l’alignement tôt.
1) Checklist rapide (fit avant fonctionnalités)
- Compétences de l’équipe : Que peut‑elle livrer et maintenir en confiance sur 12–24 mois ?
- Forme du domaine : majoritairement workflows et enregistrements, règles complexes, ou reporting intensif ?
- Besoins en données : intégrité relationnelle, documents flexibles, séries temporelles, recherche full‑text, analytics ?
- Contraintes : conformité, SLA de latence, modèle de déploiement, budget, infra existante.
- Tolérance aux pannes : cohérence éventuelle acceptable, ou transactions strictes requises ?
2) Cartographiez votre produit vers des patterns communs
- App CRUD-heavy (outils internes, back office, SaaS précoce) : un framework web conventionnel + DB relationnelle est souvent le chemin le plus rapide.
- Analytics-heavy (dashboards, tracking d’événements) : prévoyez tôt un store OLAP ou un entrepôt ; vouloir faire du BI dans Postgres peut ralentir les deux.
- Temps réel (chat, collaboration, streaming) : priorisez le support WebSocket, pub/sub, et une concurrence prévisible.
- SaaS multi‑tenant : décidez dès le départ : bases séparées, schémas séparés, ou tenancy au niveau des lignes. Ce choix a des répercussions sur l’auth, les migrations et le support.
3) Lancez une preuve de concept légère (sans surconstruire)
Limitez à 2–5 jours. Construisez une fine vertical slice : un workflow central, un job background, une requête de type rapport, et une auth basique. Mesurez la friction dev, l’ergonomie des migrations, la clarté des requêtes et la facilité des tests.
Si vous voulez accélérer, un outil comme Koder.ai peut aider à générer rapidement une verticale (UI, API, DB) depuis une spec chat‑driven — puis itérer avec snapshots/rollback et exporter le code quand vous êtes prêts.
4) Rédigez un document de décision d’une page
Title:
Date:
Context (what we’re building, constraints):
Options considered:
Decision (language/framework/database):
Why this fits (data model, consistency, ops, hiring):
Risks & mitigations:
When we’ll revisit:
Commencez par un socle fiable
Générez un backend en Go et PostgreSQL adapté à vos besoins en transactions et cohérence.
Même les bonnes équipes se retrouvent avec des mismatches — des choix qui semblent acceptables isolément mais créent de la friction une fois le système construit. La bonne nouvelle : la plupart sont prévisibles et évitables avec quelques vérifications.
Odeurs à surveiller
Un classique : choisir une base ou un framework parce que c’est « tendance » alors que le modèle de données est encore flou. Autre piège : scaling prématuré — optimiser pour des millions d’utilisateurs avant de bien gérer des centaines — ce qui mène souvent à plus d’infra et plus de modes de défaillance.
Surveillez aussi les stacks où l’équipe ne peut pas expliquer pourquoi chaque pièce majeure existe. Si la réponse est surtout « tout le monde l’utilise », vous accumulez du risque.
Risques d’intégration qui mordent plus tard
Beaucoup de problèmes apparaissent aux jointures :
- Drivers et fonctionnalités incompatibles : votre driver langage ne supporte pas complètement des features DB attendues (types, streaming, retries).
- Migrations faibles : les changements de schéma sont gérés manuellement, ou l’outillage de migration ne suit pas l’évolution de l’app, causant une dérive.
- Pooling insuffisant : frameworks qui ouvrent trop de connexions, ou déploiements qui multiplient les pools à travers processus/conteneurs, menant à des timeouts.
Ce ne sont pas des « problèmes de base » ou des « problèmes de framework » — ce sont des problèmes de système.
Préférez moins de pièces mobiles et un chemin clair pour les tâches courantes : une approche de migration, un style de requête majoritaire et des conventions constantes entre services. Si votre framework encourage un pattern (cycle de requête, injection de dépendances, pipeline de jobs), profitez‑en au lieu de mélanger les styles.
Revenez sur un choix quand des incidents de production récurrents apparaissent, quand la friction dev persiste, ou quand des exigences produit changent profondément l’accès aux données.
Changez en sécurité en isolant la jointure : introduisez une couche adaptatrice, migrez progressivement (dual‑write ou backfill), et prouvez la parité avec des tests automatisés avant de basculer le trafic.
Conclusion : traitez la stack comme un seul système
Choisir un langage, un framework web et une base n’est pas trois décisions indépendantes — c’est une décision d’architecture système exprimée en trois endroits. La « meilleure » option est la combinaison qui s’aligne avec la forme de vos données, vos besoins de cohérence, le workflow de votre équipe et la façon dont vous attendez que le produit croisse.
À retenir
- Choisissez la stack autour de votre modèle de données central et des opérations que vous effectuez le plus.
- Cohérence et transactions sont aussi des préoccupations applicatives — concevez‑les bout‑à‑bout, pas seulement côté base.
- Les goulots de performance traversent souvent plusieurs couches (schéma, requêtes, cache, sérialisation, queues).
- Sécurité et fiabilité sont des responsabilités partagées entre code, configuration et opérations.
- L’expérience développeur compte car elle détermine la vitesse à laquelle vous pouvez livrer en sécurité.
Documentez les hypothèses (avant qu’elles ne deviennent des contraintes)
Notez les raisons de vos choix : patterns de trafic attendus, latence acceptable, règles de rétention, modes de défaillance tolérés et ce que vous n’optimisez pas maintenant. Cela rend les compromis visibles, aide les nouveaux arrivants à comprendre le « pourquoi » et évite la dérive d’architecture lorsque les exigences changent.
Prochaines étapes
Faites passer votre configuration actuelle dans la checklist et notez où les décisions divergent (par ex. un schéma qui contredit l’ORM, ou un framework qui complique le travail en arrière‑plan).
Si vous explorez une nouvelle direction, des outils comme Koder.ai peuvent aussi vous aider à comparer rapidement les hypothèses de stack en générant une app de base (souvent React web, services Go avec PostgreSQL, et Flutter mobile) que vous pouvez inspecter, exporter et faire évoluer — sans vous engager dans un cycle de construction long.
Pour aller plus loin, consultez les guides liés sur /blog, cherchez les détails d’implémentation dans /docs, ou comparez les options de support et de déploiement sur /pricing.