03 nov. 2025·8 min
Leslie Lamport et les systèmes distribués : temps, ordre, correction
Découvrez les idées clés de Lamport sur les systèmes distribués — horloges logiques, ordonnancement, consensus et correction — et pourquoi elles guident encore les infrastructures modernes.
Pourquoi Lamport reste pertinent pour les systèmes distribués modernes
Leslie Lamport est l’un de ces rares chercheurs dont le travail « théorique » réapparaît à chaque fois que vous déployez un système réel. Si vous avez déjà exploité un cluster de bases de données, une file de messages, un moteur de workflow, ou quoi que ce soit qui réessaie des requêtes et survive à des pannes, vous avez vécu des problèmes que Lamport a aidé à nommer et à résoudre.
Ce qui rend ses idées durables, c’est qu’elles ne sont pas liées à une technologie précise. Elles décrivent les vérités gênantes qui surgissent chaque fois que plusieurs machines tentent de se comporter comme un seul système : les horloges ne sont pas d’accord, le réseau retarde et perd des messages, et les pannes sont la norme — pas l’exception.
Trois thèmes que nous utiliserons tout au long
Temps : Dans un système distribué, « quelle heure est-il ? » n’est pas une question simple. Les horloges physiques dérivent, et l’ordre d’observation des événements peut différer d’une machine à l’autre.
Ordonnancement : Quand on ne peut plus se fier à une horloge unique, il faut d’autres moyens pour parler de quels événements sont passés avant d’autres — et quand il faut imposer à tout le monde la même séquence.
Correction : « Ça marche la plupart du temps » n’est pas une conception. Lamport a poussé le domaine vers des définitions nettes (sécurité vs vivacité) et des spécifications sur lesquelles on peut raisonner, pas seulement tester.
À quoi s’attendre (pas de maths lourdes)
Nous nous concentrerons sur les concepts et l’intuition : les problèmes, les outils minimaux pour y voir clair, et comment ces outils façonnent des architectures pratiques.
Voici la carte :
- Pourquoi l’absence d’horloge partagée empêche une histoire globale des événements
- Comment la causalité ("happened-before") conduit aux horloges logiques et aux horodatages de Lamport
- Quand un ordre partiel ne suffit pas et qu’il faut une seule ligne temporelle
- Comment le consensus et Paxos permettent de s’accorder sur un ordre
- Pourquoi la réplication de machine à états fonctionne quand l’ordonnancement est partagé
- Comment parler de correction dans des spécifications — et comment des outils comme TLA+ aident
Le problème central : pas d’horloge partagée, pas d’unique réalité
Un système est « distribué » quand il est composé de plusieurs machines qui se coordonnent sur un réseau pour accomplir une tâche unique. Cela semble simple jusqu’à ce que vous acceptiez deux faits : les machines peuvent tomber indépendamment (pannes partielles), et le réseau peut retarder, perdre, dupliquer ou réordonner des messages.
Dans un seul programme sur un seul ordinateur, on peut généralement indiquer « qu’est‑ce qui est arrivé en premier ». Dans un système distribué, différentes machines peuvent observer des séquences d’événements différentes — et les deux peuvent être correctes du point de vue local.
Pourquoi vous ne pouvez pas faire confiance à une horloge globale
Il est tentant de résoudre la coordination en horodatant tout. Mais il n’existe pas d’horloge unique dont vous puissiez vous fier à travers des machines :
- L’horloge matérielle de chaque serveur dérive à son propre rythme.
- La synchronisation d’horloge (par exemple NTP) est du best-effort, pas une garantie.
- La virtualisation, la charge CPU ou des pauses peuvent faire sauter ou bloquer le temps.
Donc « l’événement A s’est produit à 10:01:05.123 » sur un hôte ne se compare pas de façon fiable à « 10:01:05.120 » sur un autre.
Comment les délais brouillent la réalité
Les retards réseau peuvent inverser ce que vous croyez avoir vu. Un write peut être envoyé en premier mais arriver en second. Un retry peut arriver après l’original. Deux datacenters peuvent traiter la « même » requête dans des ordres opposés.
Cela complique singulièrement le débogage : les logs de machines différentes peuvent diverger, et un tri par horodatage peut produire une histoire qui n’a jamais eu lieu.
Conséquences concrètes
Quand vous supposez une seule chronologie qui n’existe pas, vous obtenez des échecs concrets :
- Double traitement (un paiement facturé deux fois après des réessais)
- Incohérences (deux utilisateurs obtiennent « avec succès » le dernier article)
- Apparente perte de données (une mise à jour arrivée plus tard écrase une mise à jour plus récente)
L’idée clé de Lamport commence ici : si vous ne pouvez pas partager le temps, vous devez raisonner différemment sur l’ordre.
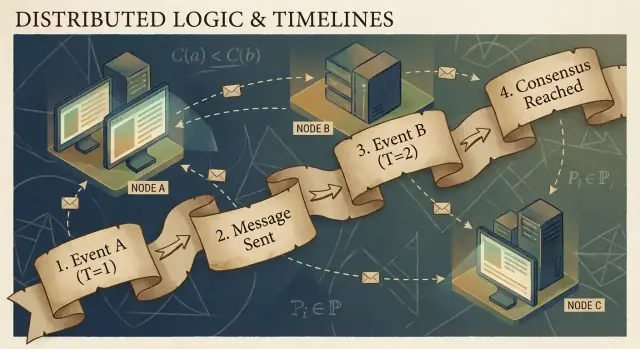
Causalité et la relation "happened-before"
Les programmes distribués sont constitués d’événements : quelque chose qui se produit sur un nœud spécifique (un processus, un serveur ou un thread). Exemples : « a reçu une requête », « a écrit une ligne », ou « a envoyé un message ». Un message est le lien entre les nœuds : un événement est un envoi, un autre est la réception.
L’idée centrale de Lamport est que, dans un système sans horloge partagée fiable, la chose la plus fiable que vous puissiez suivre est la causalité — quels événements ont pu influencer quels autres événements.
La relation happened-before (→)
Lamport a défini une règle simple appelée happened-before, notée A → B (l’événement A s’est produit avant l’événement B) :
- Ordre dans le même processus : Si A et B se produisent sur le même processus, et que A est observé avant B dans ce processus, alors A → B.
- Ordre par message : Si A est « envoi du message m » et B est « réception du message m », alors A → B.
- Transitivité : Si A → B et B → C, alors A → C.
Cette relation vous donne un ordre partiel : elle vous dit que certaines paires sont ordonnées, mais pas toutes.
Une histoire concrète : utilisateur → requête → BD → cache
Un utilisateur clique sur « Acheter ». Ce clic déclenche une requête vers un serveur API (événement A). Le serveur écrit une ligne de commande dans la base de données (événement B). Une fois l’écriture terminée, le serveur publie un message « commande créée » (événement C), et un service de cache le reçoit et met à jour une entrée (événement D).
Ici, A → B → C → D. Même si les horloges divergent, les messages et la structure du programme créent des liens causaux réels.
Ce que « concurrent » signifie réellement
Deux événements sont concurrents lorsque ni l’un n’a causé l’autre : ni (A → B) ni (B → A). La concurrence ne signifie pas « même instant » — elle signifie « aucun chemin causal ne les relie ». C’est pourquoi deux services peuvent chacun prétendre avoir agi « en premier », et les deux peuvent avoir raison sauf si vous imposez une règle d’ordonnancement.
Horloges logiques : les horodatages de Lamport en clair
Si vous avez déjà tenté de reconstruire « qu’est‑ce qui s’est passé en premier » entre plusieurs machines, vous avez rencontré le problème de base : les machines ne partagent pas une horloge parfaitement synchronisée. La solution de Lamport est d’abandonner la quête d’un temps parfait et de suivre plutôt l’ordre.
L’idée : un compteur attaché à chaque événement
Un horodatage de Lamport est simplement un nombre que vous attachez à chaque événement significatif dans un processus (une instance de service, un nœud, un thread — ce que vous choisissez). Pensez-y comme un « compteur d’événements » qui vous donne un moyen cohérent de dire « cet événement est arrivé avant cet autre », même si le temps horloge murale n’est pas fiable.
Les deux règles (vraiment très simples)
-
Incrémenter localement : avant d’enregistrer un événement (par ex. « a écrit en BD », « a envoyé une requête », « a appendu une entrée de journal »), incrémentez votre compteur local.
-
À la réception, prendre max + 1 : quand vous recevez un message qui inclut l’horodatage de l’émetteur, définissez votre compteur sur :
max(local_counter, received_counter) + 1
Puis marquez l’événement de réception avec cette valeur.
Ces règles garantissent que les horodatages respectent la causalité : si un événement A a pu influencer B (par flux d’informations via des messages), alors l’horodatage de A sera inférieur à celui de B.
Ce que les horodatages de Lamport peuvent — et ne peuvent pas — vous dire
Ils peuvent vous renseigner sur l’ordre causal :
- Si
TS(A) < TS(B), A pourrait être arrivé avant B. - Si A a causé B (directement ou indirectement), alors nécessairement
TS(A) < TS(B).
Ils ne peuvent pas vous dire l’heure réelle :
- Un horodatage inférieur ne signifie pas « plus tôt en secondes ».
- Deux événements peuvent être concurrents (aucune causalité) et quand même avoir des horodatages différents à cause des motifs de messages.
Les horodatages de Lamport sont donc excellents pour l’ordonnancement, pas pour mesurer la latence ou répondre à « quelle heure était-il ? »
Exemple pratique : ordonner des entrées de logs entre services
Imaginez que le Service A appelle le Service B, et que les deux écrivent des logs d’audit. Vous voulez une vue unifiée des logs qui préserve cause et effet.
- Le Service A incrémente son compteur, logge « début du paiement », envoie la requête à B avec le timestamp 42.
- Le Service B reçoit la requête avec 42, met son compteur à
max(local, 42) + 1, disons 43, et logge « carte validée ». - B répond avec 44 ; A reçoit, passe à 45, et logge « paiement terminé ».
Maintenant, quand vous agrégez les logs des deux services, trier par (lamport_timestamp, service_id) vous donne une chronologie stable et explicable qui correspond à la chaîne d’influence réelle — même si les horloges murales dérivaient ou que le réseau retardait des messages.
De l’ordre partiel à l’ordre total : quand vous avez besoin d’une seule chronologie
La causalité vous donne un ordre partiel : certains événements sont clairement « avant » d’autres (parce qu’un message ou une dépendance les relie), mais beaucoup d’événements sont simplement concurrents. Ce n’est pas un bug — c’est la forme naturelle de la réalité distribuée.
Ordre partiel : suffisant pour beaucoup de questions
Si vous debuggez « qu’est‑ce qui a pu influencer ceci ? », ou si vous faites respecter des règles comme « une réponse doit suivre sa requête », l’ordre partiel est exactement ce qu’il faut. Il suffit de respecter les arêtes happened-before ; tout le reste peut être traité comme indépendant.
Ordre total : nécessaire quand le système doit choisir une seule histoire
Certains systèmes ne peuvent pas tolérer « les deux ordres sont acceptables ». Ils ont besoin d’une séquence unique d’opérations, notamment pour :
- Les écritures sur un objet partagé (« définir le solde », « mettre à jour le profil », « append au journal »)
- Les commandes qui doivent être appliquées de façon identique partout (réplication de machine à états)
- La résolution de conflits où « le dernier écrit gagne » doit signifier la même chose pour tous les nœuds
Sans un ordre total, deux répliques peuvent être toutes deux « correctes » localement mais diverger globalement : l’une applique A puis B, l’autre applique B puis A, et vous obtenez des états différents.
Comment obtenez-vous une seule chronologie ?
Vous introduisez un mécanisme qui crée l’ordre :
- Un séquenceur/leader qui assigne une position monotone à chaque commande.
- Ou le consensus (par exemple des approches de type Paxos) pour que le groupe s’accorde sur la prochaine entrée du journal malgré les délais et les pannes.
Les compromis inévitables
Un ordre total est puissant, mais il a un coût :
- Latence : vous pouvez attendre une coordination avant de valider.
- Débit : un journal ordonné unique peut devenir un goulot d’étranglement.
- Disponibilité en cas de panne : si vous ne pouvez pas joindre assez de nœuds pour vous mettre d’accord, le progrès peut se figer afin de protéger la correction.
Le choix de conception est simple à énoncer : quand la correction exige une narration partagée, vous payez le coût de coordination pour l’obtenir.
Consensus : s’accorder malgré les délais et les pannes
Conservez la pleine propriété
Envoyez le code source généré vers votre dépôt lorsque la conception vous convient.
Le consensus est le problème d’amener plusieurs machines à s’entendre sur une décision — une valeur à valider, un leader à suivre, une configuration à activer — même si chaque machine ne voit que ses événements locaux et les messages qui arrivent.
Cela semble simple jusqu’à ce que vous rappeliez ce qu’un système distribué peut faire : les messages peuvent être retardés, dupliqués, réordonnés ou perdus ; les machines peuvent planter et redémarrer ; et vous n’avez rarement un signal net disant « ce nœud est définitivement mort ». Le consensus consiste à rendre l’accord sûr dans ces conditions.
Pourquoi l’accord est délicat
Si deux nœuds ne peuvent temporairement pas communiquer (partition réseau), chaque côté peut essayer d’« avancer » indépendamment. Si les deux côtés décident de valeurs différentes, vous pouvez finir en split-brain : deux leaders, deux configurations différentes, ou deux historiques concurrents.
Même sans partition, le simple délai pose problème. Au moment où un nœud entend parler d’une proposition, d’autres nœuds ont peut-être évolué. Sans horloge partagée, vous ne pouvez pas dire de façon fiable « la proposition A est arrivée avant la proposition B » simplement parce que A a un timestamp inférieur — le temps physique n’a pas autorité ici.
Où rencontre-t-on le consensus dans les systèmes réels
Vous ne l’appelez peut-être pas « consensus » au quotidien, mais il apparaît dans des tâches d’infrastructure courantes :
- Élection de leader (qui commande désormais ?)
- Journaux répliqués (quelle est la prochaine entrée de l’historique partagé ?)
- Changements de configuration (quel ensemble de nœuds peut voter/valider ?)
Dans chaque cas, le système a besoin d’un résultat unique sur lequel tout le monde converge, ou au moins d’une règle qui empêche que des résultats conflictuels soient tous considérés valides.
Paxos, la réponse de Lamport
Le Paxos de Lamport est une solution fondatrice à ce problème d’« accord sûr ». L’idée clé n’est pas un timeout magique ou un leader parfait — ce sont des règles qui garantissent qu’une seule valeur peut être choisie, même quand les messages sont en retard et que des nœuds tombent.
Paxos sépare la sécurité (« ne jamais choisir deux valeurs différentes ») de la progrès (« finir par choisir quelque chose »), ce qui en fait un plan pratique : vous pouvez optimiser les performances en conditions réelles tout en conservant la garantie fondamentale.
Paxos, sans le mal de tête : l’intuition clé de sécurité
Paxos a la réputation d’être indéchiffrable, mais beaucoup de cela vient du fait que « Paxos » n’est pas un algorithme monotone. C’est une famille de motifs proches pour amener un groupe à s’accorder, même si des messages sont retardés, dupliqués ou si des machines tombent temporairement.
Les rôles : proposeurs, accepteurs et quorums
Un modèle mental utile sépare qui propose de qui valide.
- Les proposeurs essaient de faire choisir une valeur (par exemple : « la prochaine entrée du journal est X »).
- Les accepteurs votent sur les propositions.
- Un quorum est « suffisamment d’accepteurs » pour progresser — typiquement une majorité.
L’idée structurelle : toutes les majorités se recoupent. C’est dans ce recoupement que réside la sécurité.
L’objectif de sécurité : ne jamais décider deux valeurs différentes
La sécurité de Paxos se dit simplement : une fois qu’un système a décidé une valeur, il ne doit jamais décider une autre valeur — pas de décisions split‑brain.
L’intuition clé est que les propositions portent des numéros (pensez : identifiants de scrutin). Les accepteurs promettent d’ignorer les propositions de numéro inférieur une fois qu’ils en ont vu une de numéro supérieur. Et quand un proposeur démarre avec un nouveau numéro, il demande d’abord à un quorum ce qu’ils ont déjà accepté.
Parce que les quorums se recoupent, un nouveau proposeur entendra forcément au moins un accepteur qui « se souvient » de la valeur la plus récemment acceptée. La règle est donc : si quelqu’un dans le quorum a déjà accepté une valeur, vous devez proposer cette valeur (ou la plus récente parmi elles). Cette contrainte empêche que deux valeurs différentes soient choisies.
Vivacité, en bref
La vivacité signifie que le système finit par décider quelque chose dans des conditions raisonnables (par exemple, un leader stable émerge et le réseau finit par livrer les messages). Paxos ne promet pas la rapidité en plein chaos ; il promet la correction, et le progrès une fois que les choses se stabilisent.
Réplication de machine à états : la correction par un ordonnancement partagé
Sécurisez les réessais
Lancez un service de workflow sécurisé pour les réessais avec clés d'idempotence et traçage clair des requêtes.
La réplication de machine à états (SMR) est le schéma de base derrière beaucoup de systèmes « haute disponibilité » : au lieu d’un seul serveur qui décide, vous exécutez plusieurs répliques qui traitent toutes la même séquence de commandes.
L’idée du journal répliqué
Au centre se trouve un journal répliqué : une liste ordonnée de commandes comme « put key=K value=V » ou « transférer $10 de A vers B ». Les clients ne renvoient pas les commandes à chaque réplique en espérant le meilleur. Ils soumettent des commandes au groupe, et le système s’accorde sur un ordre pour ces commandes, puis chaque réplique les applique localement.
Pourquoi l’ordonnancement vous donne la correction
Si chaque réplique part du même état initial et exécute les mêmes commandes dans le même ordre, elles aboutiront au même état. C’est l’intuition de sécurité centrale : vous ne tentez pas de garder plusieurs machines « synchronisées » par le temps ; vous les rendez identiques par déterminisme et ordonnancement partagé.
C’est pourquoi le consensus (comme Paxos ou Raft) est souvent associé à SMR : le consensus décide la prochaine entrée du journal, et la SMR transforme cette décision en un état cohérent sur toutes les répliques.
Où l’on voit cela dans les systèmes réels
- Services de coordination (par ex. pour configuration et élection de leader)
- Bases de données avec journaux d’écriture répliqués
- Systèmes de messagerie exigeant un ordonnancement strict des partitions
Préoccupations pratiques auxquelles les ingénieurs ne peuvent pas échapper
Le journal grossit indéfiniment si vous ne le gérez pas :
- Snapshots : capturez périodiquement l’état courant pour que les nouveaux nœuds puissent rattraper sans rejouer toute l’histoire.
- Compaction du journal : supprimez en sécurité les anciennes entrées une fois qu’elles sont intégrées dans un snapshot et plus nécessaires.
- Changements de membres : ajouter/retirer des répliques doit aussi être ordonné, sinon des nœuds différents peuvent avoir des vues divergentes sur qui fait partie du groupe et provoquer un split‑brain.
La SMR n’est pas magique ; c’est une méthode rigoureuse pour transformer « accord sur un ordre » en « accord sur un état ».
Correction : sécurité, vivacité et rédaction d’une spécification claire
Les systèmes distribués échouent de façons étranges : des messages arrivent tard, des nœuds redémarrent, les horloges divergent, les réseaux se partitionnent. La « correction » n’est pas une impression — ce sont des promesses que vous pouvez énoncer précisément puis vérifier dans chaque situation, y compris en présence de pannes.
Sécurité vs vivacité (avec exemples concrets)
Sécurité signifie « rien de mauvais ne se produit ». Exemple : dans un magasin clé‑valeur répliqué, deux valeurs différentes ne doivent jamais être validées pour le même index de journal. Autre exemple : un service de verrouillage ne doit jamais accorder le même verrou à deux clients simultanément.
Vivacité signifie « quelque chose de bon finit par arriver ». Exemple : si une majorité de répliques est disponible et que le réseau finit par livrer les messages, une requête d’écriture finit par aboutir. Une requête de verrou finit par obtenir une réponse (pas d’attente infinie).
La sécurité empêche les contradictions ; la vivacité évite les blocages permanents.
Invariants : vos règles non négociables
Un invariant est une condition qui doit toujours être vraie, dans tout état accessible. Par exemple :
- « Chaque index de journal a au maximum une valeur validée. »
- « Le numéro de terme d’un leader n’augmente jamais vers le bas. »
Si un invariant peut être violé lors d’une panne, d’un timeout, d’un retry ou d’une partition, il n’était pas vraiment appliqué.
Ce que signifie une "preuve" ici
Une preuve est un argument qui couvre toutes les exécutions possibles, pas seulement le chemin nominal. Vous raisonnez sur chaque cas : perte, duplication et réordonnancement de messages ; pannes et redémarrages de nœuds ; leaders concurrents ; clients qui réessaient.
Les spécifications évitent les comportements surprises
Une spécification claire définit l’état, les actions permises et les propriétés requises. Cela empêche des exigences ambiguës comme « le système doit être cohérent » de devenir des attentes contradictoires. Les specs vous forcent à dire ce qui arrive pendant une partition, ce que signifie « commit », et sur quoi les clients peuvent compter — avant que la production ne vous l’apprenne à la dure.
De la théorie à la pratique : modéliser avec TLA+
Une leçon pratique de Lamport est que vous pouvez (et devriez souvent) concevoir un protocole distribué à un niveau supérieur au code. Avant de vous soucier des threads, des RPC et des boucles de retry, écrivez les règles du système : quelles actions sont permises, quel état peut changer, et ce qui ne doit jamais arriver.
À quoi sert TLA+
TLA+ est un langage de spécification et un outil de model checking pour décrire des systèmes concurrents et distribués. Vous écrivez un modèle simple, proche des mathématiques, du système — états et transitions — plus les propriétés qui vous intéressent (par ex. « au plus un leader » ou « une entrée validée ne disparaît jamais »).
Le model checker explore ensuite les interleavings possibles, les délais de message et les pannes pour trouver un contre‑exemple : une suite concrète d’étapes qui viole votre propriété. Au lieu de débattre des cas limites en réunion, vous obtenez un argument exécutable.
Un bug qu’un modèle peut attraper
Considérez une étape de « commit » dans un journal répliqué. Dans le code, il est facile d’autoriser accidentellement deux nœuds à marquer deux entrées différentes comme validées au même index dans des timings rares.
Un modèle TLA+ peut révéler une trace comme :
- Le nœud A valide l’entrée X à l’index 10 après avoir entendu une majorité.
- Le nœud B (stale) forme aussi une majorité et valide l’entrée Y à l’index 10.
C’est un double commit — une violation de sécurité qui n’apparaît peut‑être qu’une fois par mois en production, mais qui sort rapidement sous recherche exhaustive. Des modèles similaires détectent souvent des mises à jour perdues, des double‑appliques ou des « ack mais pas durable ».
Quand cela vaut la peine de modéliser
TLA+ est le plus utile pour la logique de coordination critique : élection de leader, changements de membres, flux de type consensus, et tout protocole où ordonnancement et gestion des pannes interagissent. Si un bug peut corrompre des données ou nécessiter une récupération manuelle, un petit modèle coûte généralement moins cher que du debug ultérieur.
Si vous construisez des outils internes autour de ces idées, un flux pratique consiste à écrire une spécification légère (même informelle), puis implémenter le système et générer des tests à partir des invariants de la spec. Des plateformes comme Koder.ai peuvent aider ici en accélérant la boucle build-test : décrivez le comportement d’ordonnancement/consensus attendu en langage naturel, faites évoluer rapidement un squelette de service (frontends React, backends Go avec PostgreSQL, ou clients Flutter), et gardez visible « ce qui ne doit jamais arriver » pendant le déploiement.
Conseils pratiques pour concevoir et exploiter des systèmes fiables
Visualisez la relation 'happened-before'
Créez une vue chronologique triant les événements par horodatages de Lamport pour faciliter le débogage.
Le grand cadeau de Lamport aux praticiens est un état d’esprit : traitez le temps et l’ordonnancement comme des données que vous modélisez, pas comme des hypothèses héritées de l’horloge murale. Cet état d’esprit se traduit par des habitudes que vous pouvez appliquer dès lundi.
Transformer la théorie en pratiques d’ingénierie quotidiennes
Si les messages peuvent être retardés, dupliqués ou arriver hors d’ordre, concevez chaque interaction pour être sûre dans ces conditions.
- Idempotence par défaut : rendez les opérations « les refaire » inoffensives. Utilisez des clés d’idempotence pour les paiements, le provisioning ou toute écriture susceptible d’être réessayée.
- Retries avec déduplication : les retries sont nécessaires, mais sans déduplication vous créerez des doubles écritures. Suivez des IDs de requête et stockez des marqueurs « déjà traité ».
- Livraison au moins une fois + effets exactement une fois : acceptez que le réseau puisse livrer deux fois ; assurez-vous que vos changements d’état n’en souffrent pas.
Attention aux timeouts et aux horloges
Les timeouts ne sont pas la vérité ; ce sont des politiques. Un timeout indique « je n’ai pas eu de réponse dans le délai », pas « l’autre côté n’a pas agi ». Deux implications concrètes :
- Ne traitez pas un timeout comme une défaillance définitive. Concevez des chemins de compensation et de réconciliation.
- Évitez d’utiliser l’heure locale pour ordonner des événements entre nœuds. Préférez des numéros de séquence, des compteurs monotones ou des métadonnées causales explicites (par ex. « cette mise à jour remplace la version X »).
Observabilité qui respecte la causalité
De bons outils de debug encodent l’ordonnancement, pas seulement les timestamps.
- Trace IDs partout : propagez un ID de corrélation/trace à chaque saut et ligne de log.
- Indices causaux dans les logs : loggez les IDs de messages, les IDs de requête parent, et « ce que je croyais être la dernière version » lors de décisions.
- Replays déterministes : enregistrez les entrées (commandes) pour pouvoir rejouer un comportement et confirmer si un bug dépend du timing ou de la logique.
Questions de conception à se poser avant le déploiement
Avant d’ajouter une fonctionnalité distribuée, imposez la clarté avec quelques questions :
- Que se passe‑t‑il si la même requête est traitée deux fois ?
- Quel ordonnancement avons‑nous besoin (le cas échéant), et où est‑il appliqué ?
- Quelles pannes sont « sûres » (aucun état incorrect) vs « bruyantes » (visibles par l’utilisateur) vs « silencieuses » (corruption cachée) ?
- Quel est le chemin de récupération après une panne partielle ou une partition réseau ?
- Que allons‑nous logger pour reconstruire l’histoire happened‑before en production ?
Ces questions ne demandent pas un doctorat — juste la discipline de traiter l’ordonnancement et la correction comme des exigences produit de premier plan.
Conclusion et prochaines étapes suggérées
L’apport durable de Lamport est une manière de penser clairement quand les systèmes ne partagent pas d’horloge et n’accordent pas par défaut sur « ce qui s’est passé ». Plutôt que de courir après un temps parfait, vous suivez la causalité (ce qui a pu influencer quoi), vous la représentez avec du temps logique (horodatages de Lamport), et — quand le produit exige une unique histoire — vous construisez un accord (consensus) afin que chaque réplique applique la même séquence de décisions.
Ce fil de réflexion mène à un état d’esprit d’ingénierie pratique :
Spécifier d’abord, puis construire
Écrivez les règles dont vous avez besoin : ce qui ne doit jamais arriver (sécurité) et ce qui doit éventuellement arriver (vivacité). Implémentez ensuite selon cette spécification, et testez le système sous délais, partitions, retries, duplications de messages et redémarrages de nœuds. Beaucoup d’« incidents mystère » proviennent d’énoncés manquants comme « une requête peut être traitée deux fois » ou « les leaders peuvent changer à tout moment ».
Apprendre ensuite, par étapes focalisées
Si vous voulez approfondir sans vous noyer dans la formalité :
- Lisez « Time, Clocks, and the Ordering of Events in a Distributed System » de Lamport pour intégrer la relation happened‑before.
- Parcourez « Paxos Made Simple » pour l’intuition de sécurité : une fois qu’une valeur est choisie, le progrès futur ne peut pas la contredire.
- Regardez une introduction à TLA+, puis modelez un petit protocole (un service de verrou ou un registre à deux répliques) et vérifiez‑le.
Essayez un exercice pratique
Choisissez un composant que vous possédez et rédigez un « contrat de pannes » d’une page : ce que vous supposez du réseau et du stockage, quelles opérations sont idempotentes, et quelles garanties d’ordonnancement vous fournissez.
Si vous voulez rendre cet exercice plus concret, construisez un petit service de « démonstration d’ordonnancement » : une API de requête qui append des commandes à un journal, un worker en arrière‑plan qui les applique, et une vue d’administration montrant les métadonnées de causalité et les réessais. Le faire sur Koder.ai peut accélérer l’itération — notamment pour le scaffolding rapide, le déploiement, les snapshots/rollbacks pour expérimenter, et l’export du code une fois satisfait.
Bien fait, ces idées réduisent les incidents car moins de comportements restent implicites. Elles simplifient aussi le raisonnement : vous cessez de débattre du temps et commencez à démontrer ce que l’ordonnancement, l’accord et la correction signifient réellement pour votre système.