18 août 2025·8 min
LLVM de Chris Lattner : le moteur discret derrière les chaînes d'outils modernes
Découvrez comment LLVM, initié par Chris Lattner, est devenu la plateforme modulaire de compilation derrière de nombreux langages et outils — alimentant les optimisations, de meilleurs diagnostics et des builds rapides.
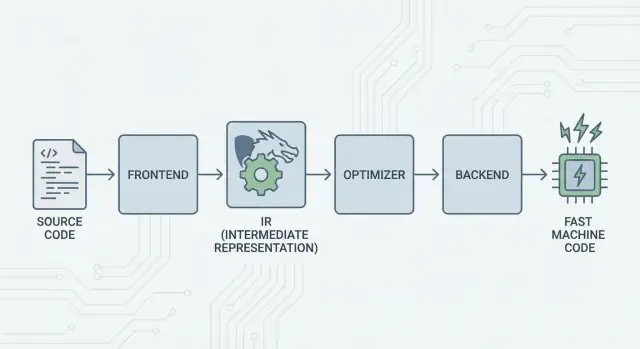
Ce qu'est LLVM, en termes simples
LLVM se comprend mieux comme la « salle des machines » que partagent de nombreux compilateurs et outils développeurs.
Quand vous écrivez du code dans un langage comme C, Swift ou Rust, il faut traduire ce code en instructions que votre CPU peut exécuter. Un compilateur traditionnel construisait souvent toute la chaîne lui-même. LLVM adopte une approche différente : il fournit un noyau réutilisable et de haute qualité qui gère les parties difficiles et coûteuses — l'optimisation, l'analyse et la génération de code machine pour de nombreux processeurs.
Une fondation partagée pour de nombreux langages
LLVM n'est pas, la plupart du temps, un compilateur unique que l'on « utilise directement ». C'est de l'infrastructure de compilateur : des briques que les équipes de langages peuvent assembler en une chaîne d'outils. Une équipe peut se concentrer sur la syntaxe, la sémantique et les fonctionnalités destinées aux développeurs, puis confier le travail lourd à LLVM.
Cette fondation partagée explique en grande partie pourquoi les langages modernes peuvent proposer rapidement des chaînes d'outils sûres et performantes sans réinventer des décennies de travail sur les compilateurs.
Pourquoi cela compte même si vous n'êtes pas spécialiste des compilateurs
LLVM influence l'expérience quotidienne du développeur :
- Performance : il peut transformer du code de haut niveau en code machine efficace sur plusieurs plateformes.
- Meilleures erreurs et débogage : l'écosystème autour de LLVM permet des diagnostics plus riches et de meilleurs outils.
- Plus que la compilation : l'analyse statique, les sanitizers, la couverture de code et d'autres aides aux développeurs s'appuient souvent sur la même représentation et les mêmes bibliothèques sous-jacentes.
Ce que cet article sera (et ne sera pas)
Ceci est une visite guidée des idées lancées par Chris Lattner : comment LLVM est structuré, pourquoi la couche intermédiaire est importante, et comment elle permet les optimisations et le support multi-plateforme. Ce n'est pas un manuel — l'accent est mis sur l'intuition et l'impact réel plutôt que sur la théorie formelle.
La vision originelle de Chris Lattner
Chris Lattner est un informaticien et ingénieur qui, alors qu'il était doctorant au début des années 2000, a lancé LLVM en partant d'une frustration pratique : la technologie des compilateurs était puissante, mais difficile à réutiliser. Si vous vouliez un nouveau langage, de meilleures optimisations, ou le support d'un nouveau CPU, il fallait souvent bricoler un compilateur monolithique où chaque changement avait des effets de bord.
Le problème qu'il voulait résoudre
À l'époque, de nombreux compilateurs étaient construits comme une seule grande machine : la partie qui comprend le langage, la partie qui optimise et la partie qui génère le code machine étaient profondément entremêlées. Cela les rendait efficaces pour leur usage initial, mais coûteux à adapter.
Lattner ne visait pas « un compilateur pour un seul langage ». Son objectif était une fondation partagée capable d'alimenter de nombreux langages et outils — sans que tout le monde réécrive sans cesse les mêmes pièces complexes. Le pari était que si l'on pouvait standardiser le milieu de la chaîne, on pourrait innover plus vite aux extrémités.
Pourquoi « l'infrastructure modulaire » était une idée neuve
Le changement clé a été de traiter la compilation comme un ensemble de blocs séparables avec des frontières claires. Dans un monde modulaire :
- une équipe langage peut se concentrer sur l'analyse et les fonctionnalités orientées développeur,
- une équipe optimisation peut améliorer les performances une fois pour toutes et partager le résultat,
- le support matériel peut être ajouté sans repenser toute la chaîne en amont.
Cette séparation paraît évidente aujourd'hui, mais elle allait à l'encontre de l'évolution de nombreux compilateurs de production.
Open source, conçu pour être utilisé par d'autres
LLVM a été publié en open source tôt, ce qui a compté : une infrastructure partagée ne fonctionne que si plusieurs groupes peuvent la faire confiance, l'inspecter et l'étendre. Au fil du temps, universités, entreprises et contributeurs indépendants ont façonné le projet en ajoutant des cibles, corrigeant des cas limites, améliorant les performances et construisant de nouveaux outils autour.
Cet aspect communautaire n'était pas qu'un geste altruiste — il faisait partie du design : rendre le noyau largement utile le rendait digne d'entretien collectif.
La grande idée : frontends, un noyau partagé et backends
L'idée centrale de LLVM est simple : diviser un compilateur en trois grandes parties pour que de nombreux langages puissent partager le travail le plus difficile.
1) Frontends : « Que voulait dire le programmeur ? »
Un frontend comprend un langage de programmation spécifique. Il lit votre code source, vérifie les règles (syntaxe et types) et le transforme en une représentation structurée.
Le point clé : les frontends n'ont pas besoin de connaître tous les détails du CPU. Leur travail est de traduire les concepts du langage — fonctions, boucles, variables — en quelque chose de plus universel.
2) Le milieu partagé : un noyau commun au lieu de N×M travaux
Traditionnellement, construire un compilateur signifiait refaire le même travail encore et encore :
- Avec N langages et M cibles matériel, on se retrouve avec N×M combinaisons à supporter.
LLVM réduit cela à :
- N frontends qui traduisent vers une forme partagée
- M backends qui traduisent de cette forme partagée vers du code machine
Cette « forme partagée » est le cœur de LLVM : un pipeline commun où résident les optimisations et analyses. C'est le grand simplificateur. Les améliorations du milieu (comme de meilleures optimisations ou une meilleure info de debug) peuvent profiter à de nombreux langages à la fois, au lieu d'être réimplémentées dans chaque compilateur.
3) Backends : « Comment faire vite sur ce CPU ? »
Un backend prend la représentation partagée et produit une sortie spécifique à la machine : instructions pour x86, ARM, etc. C'est là que des détails comme les registres, les conventions d'appel et la sélection d'instructions comptent.
Une image intuitive de la chaîne
Pensez à la compilation comme à un itinéraire de voyage :
- Le code source commence dans un pays spécifique au langage (frontend).
- Il franchit une frontière vers une « langue intermédiaire » standardisée (le noyau et les passes de LLVM).
- Il prend ensuite un réseau local pour atteindre une ville de destination précise (le backend pour votre machine cible).
Le résultat est une chaîne d'outils modulaire : les langages peuvent se concentrer sur l'expression des idées, tandis que le noyau partagé de LLVM s'occupe de faire tourner ces idées efficacement sur de nombreuses plateformes.
LLVM IR : la couche intermédiaire qui permet la réutilisation
LLVM IR (Intermediate Representation) est la « langue commune » qui se trouve entre un langage de programmation et le code machine que votre CPU exécute.
Un frontend (comme Clang pour C/C++) traduit votre code source en cette forme partagée. Ensuite, les optimiseurs et générateurs de code de LLVM travaillent sur l'IR, pas sur le langage d'origine. Enfin, un backend transforme l'IR en instructions pour une cible spécifique (x86, ARM, etc.).
Une langue commune entre outils et CPU
Considérez LLVM IR comme un pont soigneusement conçu :
- Au-dessus : de nombreux langages source peuvent se brancher (C, C++, Rust, Swift, Julia, etc.).
- En dessous : de nombreux CPU peuvent être ciblés.
- Au milieu : les mêmes outils d'analyse et d'optimisation peuvent être réutilisés.
C'est pourquoi on décrit souvent LLVM comme une « infrastructure de compilateur » plutôt qu'un simple compilateur. L'IR est le contrat partagé qui rend cette infrastructure réutilisable.
Pourquoi l'IR permet la réutilisation (et fait gagner du travail)
Une fois le code en LLVM IR, la plupart des passes d'optimisation n'ont pas besoin de savoir s'il venait de templates C++, d'itérateurs Rust ou de generics Swift. Elles s'intéressent majoritairement à des idées universelles comme :
- « Cette valeur est constante. »
- « Ce calcul est répété ; peut-on réutiliser le résultat ? »
- « Ce chargement mémoire peut être déplacé ou supprimé en toute sécurité. »
Ainsi, les équipes langage n'ont pas à construire (et maintenir) leur propre pile d'optimiseur complète. Elles peuvent se concentrer sur le frontend — parsing, vérification de types, règles spécifiques au langage — puis confier le reste à LLVM.
À quoi ça « ressemble » conceptuellement
LLVM IR est assez bas niveau pour se mapper proprement au code machine, mais suffisamment structuré pour être analysé. Conceptuellement, il est construit à partir d'instructions simples (add, compare, load/store), d'un contrôle de flux explicite (branches) et de valeurs fortement typées — plus proche d'une assembly proprement conçue pour les compilateurs que de quelque chose qu'on écrit à la main.
Comment fonctionnent les optimisations (sans les mathématiques)
Quand on entend « optimisations de compilateur », on imagine souvent des tours de magie. Dans LLVM, la plupart des optimisations se comprennent mieux comme des réécritures mécaniques et sûres du programme — des transformations qui préservent le comportement, mais visent à l'exécuter plus vite (ou à réduire la taille).
Pensez-y comme de l'édition, pas de l'invention
LLVM prend votre code (en LLVM IR) et applique de manière répétée de petites améliorations, un peu comme on polit un brouillon :
- Supprimer le travail dupliqué : si une valeur est calculée deux fois et que rien ne change entre-temps, LLVM peut la calculer une fois et réutiliser le résultat.
- Simplifier la logique évidente : les expressions constantes peuvent être évaluées tôt (par exemple
3 * 4devient12), pour que le CPU fasse moins de travail à l'exécution. - Rationaliser les boucles : certaines passes liées aux boucles réduisent des vérifications répétées, déplacent le travail invariant hors de la boucle, ou reconnaissent des motifs exécutables plus efficacement.
Ces changements sont délibérément conservateurs. Une passe n'effectue une réécriture que lorsqu'elle peut prouver qu'elle n'altère pas le sens du programme.
Exemples parlants
Si votre programme fait conceptuellement ceci :
- Lit la même valeur de configuration à chaque itération d'une boucle
- Effectue le même calcul sur les mêmes entrées à plusieurs endroits
- Vérifie une condition qui est toujours vraie/faux dans un contexte donné
…LLVM cherche à transformer cela en « faire la mise en place une fois », « réutiliser les résultats » et « supprimer les branches mortes ». C'est moins de la magie que de l'entretien ménager.
Le vrai compromis : temps de compilation vs temps d'exécution
L'optimisation n'est pas gratuite : plus d'analyses et plus de passes entraînent généralement une compilation plus lente, même si le programme final s'exécute plus vite. C'est pourquoi les chaînes d'outils proposent des niveaux comme « optimiser un peu » vs « optimiser agressivement ».
Les profils aident ici. Avec la PGO (profile-guided optimization), vous exécutez le programme, collectez des données d'usage réelles, puis recompilez pour que LLVM concentre ses efforts sur les chemins qui comptent réellement — rendant le compromis plus prévisible.
Backends : atteindre de nombreux CPU sans tout réécrire
Transformez le partage en crédits
Gagnez des crédits en partageant ce que vous créez ou en invitant d'autres à essayer Koder.ai.
Un compilateur a deux tâches très différentes. D'abord, comprendre votre code source. Ensuite, produire du code machine exécutable par un CPU spécifique. Les backends LLVM se concentrent sur cette deuxième tâche.
Ce que fait réellement un backend
Considérez LLVM IR comme une « recette universelle » de ce que le programme doit faire. Un backend transforme cette recette en instructions exactes pour une famille de processeurs particulière — x86-64 pour la plupart des desktops et serveurs, ARM64 pour de nombreux téléphones et ordinateurs portables récents, ou des cibles spécialisées comme WebAssembly.
Concrètement, un backend est responsable de :
- Sélection d'instructions : mapper les opérations IR aux instructions réelles du CPU
- Allocation de registres : choisir quelles valeurs résident dans les registres rapides du CPU vs en mémoire
- Ordonnancement : organiser les instructions pour que le CPU les exécute efficacement
- Sortie assembleur/objet : émettre du code que l'éditeur de liens et le système d'exploitation comprennent
Pourquoi l'infrastructure partagée facilite le support de nouveau matériel
Sans un noyau partagé, chaque langage devrait réimplémenter tout cela pour chaque CPU qu'il souhaite supporter — un travail énorme et une charge de maintenance constante.
LLVM renverse la tendance : les frontends (comme Clang) produisent l'IR une fois, et les backends s'occupent du « dernier kilomètre » par cible. Ajouter le support d'un nouveau CPU signifie généralement écrire un backend (ou étendre un backend existant), pas réécrire tous les compilateurs existants.
Portabilité pour les équipes qui expédient sur plusieurs plateformes
Pour des projets qui doivent fonctionner sur Windows/macOS/Linux, sur x86 et ARM, ou même dans le navigateur, le modèle backend de LLVM est un avantage pratique. Vous pouvez conserver une seule base de code et essentiellement une seule chaîne de build, puis retargeter en choisissant un backend différent (ou en cross-compilant).
Cette portabilité explique la présence généralisée de LLVM : ce n'est pas seulement une question de performance — c'est aussi une manière d'éviter des travaux de compilateur spécifiques à une plateforme qui ralentissent les équipes.
Clang : là où beaucoup de développeurs rencontrent LLVM
Clang est le frontend C, C++ et Objective-C qui se branche sur LLVM. Si LLVM est le moteur partagé capable d'optimiser et de générer du code machine, Clang est la partie qui lit vos fichiers source, comprend les règles du langage et transforme ce que vous avez écrit en une forme exploitable par LLVM.
Pourquoi Clang s'est fait remarquer
Beaucoup de développeurs n'ont pas découvert LLVM en lisant des articles académiques — ils l'ont rencontré la première fois qu'ils ont changé de compilateur et que les retours se sont soudainement améliorés.
Les diagnostics de Clang sont réputés plus lisibles et plus précis. Au lieu de messages vagues, il pointe souvent le token exact qui a posé problème, montre la ligne concernée et explique ce qu'il attendait. Cela compte au quotidien, car la boucle « compiler, corriger, répéter » devient moins frustrante.
Clang expose aussi des interfaces propres et bien documentées (notamment via libclang et l'écosystème Clang tooling). Cela a facilité l'intégration d'une compréhension approfondie du langage dans les éditeurs, IDEs et autres outils sans réinventer un parser C/C++.
Comment cela se manifeste dans les workflows quotidiens
Une fois qu'un outil peut parser et analyser votre code de façon fiable, vous obtenez des fonctionnalités qui ressemblent moins à de l'édition de texte et plus à du travail sur un programme structuré :
- Navigation de code précise (« aller à la définition », « trouver les références ») même dans de grands projets C++ utilisant beaucoup de macros
- Support de refactoring qui comprend les symboles et les portées, pas juste du rechercher-remplacer
- Indices inline et corrections rapides basées sur une vraie information de syntaxe et de type
C'est pourquoi Clang est souvent le premier point de contact avec LLVM : c'est d'où viennent les améliorations pratiques de l'expérience développeur. Même si vous ne pensez jamais à LLVM IR ou aux backends, vous profitez d'un autocomplete plus intelligent, de vérifications statiques plus précises et d'erreurs de build plus faciles à corriger.
Pourquoi de nombreux langages modernes s'appuient sur LLVM
LLVM séduit les équipes langage pour une raison simple : il leur permet de se concentrer sur le langage au lieu de passer des années à réinventer un compilateur optimisant complet.
Un time-to-market plus rapide
Créer un nouveau langage implique déjà le parsing, la vérification de types, les diagnostics, l'outillage de paquets, la documentation et la construction d'une communauté. Si vous devez en plus créer un optimiseur de production, un générateur de code et un support de plateformes à partir de zéro, la mise sur le marché se retarde — parfois de plusieurs années.
LLVM fournit un noyau de compilation prêt à l'emploi : allocation de registres, sélection d'instructions, passes d'optimisation matures et cibles pour les CPU courants. Les équipes peuvent brancher un frontend qui abaisse leur langage en LLVM IR, puis s'appuyer sur la chaîne existante pour produire du code natif pour macOS, Linux et Windows.
Haute performance (sans exploits héroïques)
L'optimiseur et les backends de LLVM résultent d'un long travail d'ingénierie et de tests en conditions réelles. Cela se traduit par une performance de base solide pour les langages qui l'adoptent — souvent suffisante dès le départ, et susceptible de s'améliorer au fil des évolutions de LLVM.
C'est pourquoi plusieurs langages connus se sont construits autour de lui :
- Swift utilise LLVM pour générer des binaires natifs très optimisés sur les plateformes Apple.
- Rust s'appuie sur LLVM pour la génération de code et pour de nombreuses cibles d'architecture.
- Julia utilise LLVM pour permettre du code numérique rapide, y compris la compilation à l'exécution pour des charges spécialisées.
LLVM n'est pas nécessaire pour tous les langages
Choisir LLVM est un compromis, pas une obligation. Certains langages privilégient des binaires très petits, une compilation ultra-rapide, ou un contrôle total de la chaîne d'outils. D'autres disposent déjà de compilateurs établis (comme les écosystèmes basés sur GCC) ou préfèrent des backends plus simples.
LLVM est populaire parce que c'est un bon choix par défaut — pas parce que c'est la seule voie valable.
JIT et compilation à l'exécution : boucles de feedback rapides
Passez au multiplateforme
Créez une application mobile Flutter en complément de votre web et de votre serveur.
La compilation « just-in-time » (JIT) se comprend le plus facilement comme de la compilation pendant l'exécution. Plutôt que de traduire tout le code en avance, un moteur JIT attend qu'un morceau de code soit réellement nécessaire, puis compile cette partie à la volée — souvent en utilisant des informations d'exécution réelles (types exacts, tailles de données) pour faire des choix meilleurs.
Pourquoi le JIT peut sembler rapide
Parce que vous n'avez pas à compiler tout en amont, les systèmes JIT peuvent fournir un retour rapide pour le travail interactif. Vous écrivez ou générez un bout de code, l'exécutez immédiatement, et le système compile uniquement ce qui est nécessaire maintenant. Si ce même code s'exécute de façon répétée, le JIT peut mettre en cache le résultat compilé ou recompiler les sections « chaudes » plus agressivement.
Où la compilation à l'exécution aide en pratique
Le JIT brille quand les charges sont dynamiques ou interactives :
- REPLs et notebooks : évaluer des extraits instantanément tout en obtenant une exécution à vitesse native pour les boucles lourdes.
- Plugins et extensions : les applications peuvent charger du code utilisateur à l'exécution et le compiler pour correspondre au CPU hôte.
- Charges dynamiques : quand les entrées varient beaucoup, le profil d'exécution peut guider quelles voies méritent optimisation.
- Calcul scientifique : des kernels générés (pour une taille de matrice spécifique, une forme de modèle ou une fonctionnalité hardware) peuvent être compilés à la demande.
Le rôle de LLVM (sans hyperbole)
LLVM ne rend pas magiquement chaque programme plus rapide, et ce n'est pas un JIT complet en lui-même. Ce qu'il fournit, c'est une boîte à outils : une IR bien définie, un grand ensemble de passes d'optimisation et une génération de code pour de nombreux CPU. Des projets peuvent construire des moteurs JIT au-dessus de ces briques, en choisissant le bon compromis entre temps de démarrage, performance de pointe et complexité.
Performance, prévisibilité et compromis réels
Les toolchains basés sur LLVM peuvent produire un code extrêmement rapide — mais « rapide » n'est pas une propriété unique et stable. Elle dépend de la version du compilateur, du CPU cible, des paramètres d'optimisation et même de ce que vous demandez au compilateur de supposer sur le programme.
Pourquoi « même source, résultats différents » arrive
Deux compilateurs peuvent lire la même source C/C++ (ou Rust, Swift, etc.) et générer un code machine notablement différent. Une partie de cela est intentionnelle : chaque compilateur a son ensemble de passes d'optimisation, d'heuristiques et de paramètres par défaut. Même au sein de LLVM, Clang 15 et Clang 18 peuvent prendre des décisions d'inlining différentes, vectoriser différentes boucles ou ordonnancer différemment les instructions.
Cela peut aussi être causé par un comportement indéfini ou non spécifié dans le langage. Si votre programme dépend accidentellement de quelque chose que la norme ne garantit pas (comme un dépassement d'entier signé en C), différents compilateurs — ou différentes options — peuvent « optimiser » de façon à changer les résultats.
Déterminisme, builds de debug et builds de release
On attend souvent que la compilation soit déterministe : mêmes entrées, mêmes sorties. En pratique, on s'en approche, mais les binaires peuvent ne pas être identiques d'un environnement à l'autre. Les chemins de build, les horodatages, l'ordre d'édition des liens, les données de profile-guidé et les choix LTO peuvent tous affecter l'artéfact final.
La distinction plus pratique est debug vs release. Les builds de debug désactivent généralement de nombreuses optimisations pour préserver le pas-à-pas et des traces de pile lisibles. Les builds release activent des transformations agressives qui peuvent réordonner le code, inliner des fonctions et supprimer des variables — excellentes pour la performance, mais parfois plus difficiles à déboguer.
Conseil pratique : mesurer, ne pas deviner
Considérez la performance comme un problème de mesure :
- Benchmez sur du hardware représentatif et des jeux de données réalistes.
- Chauffez les caches et exécutez plusieurs itérations.
- Comparez des builds avec des flags explicites (par exemple, changer
-O2vs-O3, activer/désactiver LTO, ou sélectionner une cible avec-march).
Un petit changement de flag peut déplacer la performance dans un sens ou dans l'autre. Le flux de travail le plus sûr : formuler une hypothèse, la mesurer et garder des benchmarks proches des usages réels.
Outillage au-delà de la compilation : analyse, débogage et sécurité
Gardez le contrôle du code source
Gardez le contrôle total en exportant le code source lorsque vous êtes prêt à posséder le dépôt.
LLVM est souvent décrit comme une boîte à outils de compilateur, mais de nombreux développeurs ressentent son impact via des outils qui entourent la compilation : analyseurs, débogueurs et vérifications de sécurité activables pendant les builds et les tests.
Analyse et instrumentation comme « extensions »
Parce que LLVM expose une représentation intermédiaire bien définie (IR) et un pipeline de passes, il est naturel de construire des étapes supplémentaires qui inspectent ou réécrivent le code pour un but autre que la vitesse. Une passe peut insérer des compteurs pour le profiling, marquer des opérations mémoire suspectes ou collecter des données de couverture.
Le point clé est que ces fonctionnalités peuvent être intégrées sans que chaque équipe langage réinvente la même plomberie.
Les sanitizers : attraper les bugs près de la source
Clang et LLVM ont popularisé une famille de « sanitizers » d'exécution qui instrumentent les programmes pour détecter des classes de bugs communes lors des tests — accès mémoire hors bornes, use-after-free, races de données, et patterns de comportement indéfini. Ce ne sont pas des boucliers magiques et ils ralentissent généralement les programmes, donc on les utilise surtout en CI et en pré-release. Mais lorsqu'ils déclenchent, ils pointent souvent une localisation source précise et une explication lisible, ce dont les équipes ont besoin pour traquer des crashes intermittents.
Meilleurs diagnostics = intégration plus rapide
La qualité de l'outillage, c'est aussi la communication. Des warnings clairs, des messages d'erreur actionnables et des infos de débogage cohérentes réduisent le facteur « mystère » pour les nouveaux venus. Quand la chaîne d'outils explique ce qui s'est passé et comment le corriger, les développeurs passent moins de temps à mémoriser les bizarreries du compilateur et plus de temps à apprendre la base de code.
LLVM ne garantit pas des diagnostics parfaits ou une sécurité complète par lui-même, mais il fournit une fondation commune qui rend ces outils pratiques à construire, maintenir et partager entre projets.
Quand utiliser LLVM (et quand ne pas l'utiliser)
LLVM est mieux vu comme un « construisez votre propre compilateur et kit d'outillage ». Cette flexibilité est précisément la raison pour laquelle il alimente tant de chaînes d'outils modernes — mais c'est aussi pourquoi ce n'est pas la bonne réponse pour tous les projets.
Quand LLVM est un bon choix
LLVM brille quand vous voulez réutiliser un gros travail d'ingénierie compilateur sans le réinventer.
Si vous développez un nouveau langage de programmation, LLVM peut vous fournir une pipeline d'optimisation éprouvée, une génération de code mature pour de nombreux CPU et un chemin vers un bon support de debug.
Si vous expédiez des applications multiplateformes, l'écosystème backend de LLVM réduit le travail nécessaire pour cibler différentes architectures. Vous vous concentrez sur votre logique produit plutôt que d'écrire des générateurs de code séparés.
Si votre objectif est l'outillage développeur — linters, analyses statiques, navigation de code, refactoring — LLVM (et son écosystème) est une base solide parce que le compilateur comprend déjà la structure du code et les types.
Quand il peut être excessif
LLVM peut être lourd si vous travaillez sur des systèmes embarqués très contraints où la taille du build, la mémoire et le temps de compilation sont des contraintes fortes.
Il peut aussi être inadapté pour des pipelines très spécialisés où vous ne voulez pas d'optimisations généralistes, ou quand votre « langage » est plus proche d'un DSL fixe avec un mappage direct et simple vers le code machine.
Une check-list simple
Posez-vous trois questions :
- Devons-nous cibler plusieurs plateformes/CPU maintenant ou bientôt ?
- Bénéficions-nous d'optimisations et d'info de debug existantes plutôt que de construire les nôtres ?
- Préférons-nous une voie écosystème (outillage, intégrations, recrutement) plutôt qu'un compilateur minimal et sur mesure ?
Si vous avez répondu « oui » à la plupart, LLVM est généralement un pari pratique. Si vous voulez surtout le compilateur le plus petit et le plus simple pour un problème étroit, une approche plus légère peut l'emporter.
Note pratique pour les équipes produit : les bénéfices de LLVM sans devenir experts en compilateurs
La plupart des équipes ne veulent pas « adopter LLVM » comme projet. Elles veulent des résultats : builds multiplateformes, binaires rapides, bons diagnostics et outillage fiable.
C'est une des raisons pour lesquelles des plateformes comme Koder.ai sont intéressantes dans ce contexte. Si votre flux de travail est de plus en plus piloté par de l'automatisation de haut niveau (planification, génération de squelettes, itération rapide), vous bénéficiez encore indirectement de LLVM via les toolchains sous-jacentes — que vous développiez une application React, un backend Go avec PostgreSQL ou un client mobile Flutter. L'approche « vibe-coding » pilotée par chat de Koder.ai vise à accélérer le shipping produit, tandis que l'infrastructure moderne de compilateur (LLVM/Clang et ses outils, quand applicable) continue de faire le travail ingrat d'optimisation, de diagnostics et de portabilité en arrière-plan.