Ce que doit offrir une recherche serveur instantanée
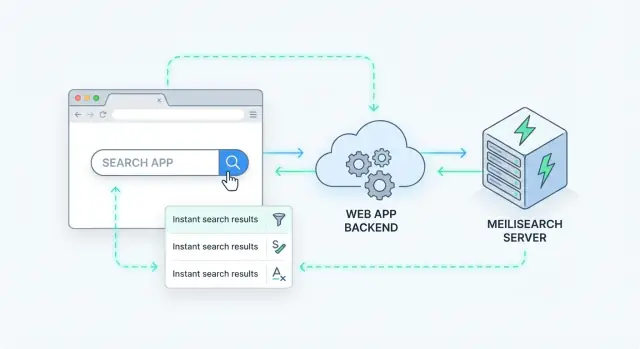
La recherche côté serveur signifie que la requête est traitée sur votre serveur (ou un service de recherche dédié), pas dans le navigateur. Votre application envoie une requête de recherche, le serveur l'exécute contre un index, et renvoie des résultats classés.
Ceci est important quand votre jeu de données est trop volumineux pour être envoyé au client, quand vous avez besoin d'une pertinence cohérente entre plateformes, ou quand le contrôle d'accès est non négociable (par exemple, des outils internes où les utilisateurs ne doivent voir que ce qui leur est permis). C’est aussi le choix par défaut quand vous voulez des analytics, des logs et des performances prévisibles.
Ce que les utilisateurs attendent (et remarquent tout de suite)
Les utilisateurs ne pensent pas aux moteurs de recherche — ils jugent l'expérience. Un bon flux de recherche “instantanée” signifie généralement :
- Retour rapide : les résultats se mettent à jour vite pendant que l'utilisateur tape, sans pauses gênantes.
- Les fautes de frappe ne cassent pas tout : les erreurs d'orthographe, lettres inversées et mots partiels trouvent toujours les bons éléments.
- Contrôles utiles : filtres (catégorie, statut, fourchette de prix), tri (les plus récents, les moins chers), et facettes (comptages par filtre) semblent naturels.
- Ordre pertinent : les meilleurs résultats apparaissent en premier, pas seulement les plus récents ou ceux bourrés de mots-clés.
Si un de ces points manque, les utilisateurs compensent en essayant d'autres requêtes, en faisant plus de défilement, ou en abandonnant la recherche complètement.
Ce que ce guide va vous aider à faire
Cet article est une marche à suivre pratique pour construire cette expérience avec Meilisearch. Nous verrons comment le configurer en toute sécurité, comment structurer et synchroniser vos données indexées, comment ajuster la pertinence et les règles de classement, comment ajouter filtres/tri/facettes, et comment penser à la sécurité et à la montée en charge pour que la recherche reste rapide à mesure que votre application grandit.
Là où la recherche côté serveur excelle
Meilisearch est particulièrement adapté à :
- Documentation et bases de connaissances (trouver des pages rapidement, tolérer les fautes de frappe)
- Catalogues produits et marketplaces (les filtres et le tri sont essentiels)
- Outils internes (recherche avec respect des permissions entre enregistrements)
- Sites de contenu (recherche à travers articles, guides, FAQ)
L'objectif : des résultats qui paraissent immédiats, précis et fiables — sans transformer la recherche en un projet d'ingénierie majeur.
Vue d'ensemble de Meilisearch en langage simple
Meilisearch est un moteur de recherche que vous exécutez à côté de votre application. Vous lui envoyez des documents (produits, articles, utilisateurs, tickets de support), et il construit un index optimisé pour la recherche rapide. Votre backend (ou frontend) interroge ensuite Meilisearch via une API HTTP simple et obtient des résultats classés en millisecondes.
Ce que vous obtenez immédiatement
Meilisearch se concentre sur les fonctionnalités attendues d'une recherche moderne :
- Tolérance aux fautes de frappe pour que “iphnoe” trouve quand même “iPhone”.
- Contrôles de pertinence (règles de classement) pour décider ce que « meilleure correspondance » signifie pour votre activité.
- Filtres, tri et facettes pour que les utilisateurs restreignent les résultats par attributs (catégorie, fourchette de prix, disponibilité, tags).
Il est conçu pour être réactif et indulgent, même quand la requête est courte, légèrement erronée ou ambiguë.
Ce que Meilisearch n'est pas
Meilisearch ne remplace pas votre base de données principale. Votre base reste la source de vérité pour les écritures, les transactions et les contraintes. Meilisearch conserve une copie des champs que vous choisissez de rendre recherchables, filtrables ou affichables.
Un bon modèle mental : base de données pour stocker et mettre à jour les données, Meilisearch pour les retrouver rapidement.
Meilisearch peut être extrêmement rapide, mais les résultats dépendent de quelques facteurs pratiques :
- Taille et forme des données (nombre de documents, nombre de champs, et combien de texte vous indexez)
- Matériel (CPU, RAM, disque)
- Configuration (quels attributs sont recherchables/filtrables/triables, et à quelle fréquence vous réindexez)
Pour des jeux de données petits à moyens, vous pouvez souvent l'exécuter sur une seule machine. À mesure que votre index grandit, vous devrez être plus sélectif sur ce que vous indexez et comment vous maintenez la synchronisation — sujets abordés dans les sections suivantes.
Planifier vos index et votre modèle de données
Avant d'installer quoi que ce soit, décidez ce que vous allez réellement rechercher. Meilisearch donnera une impression d'“instantanéité” seulement si vos index et documents correspondent à la façon dont les gens naviguent dans votre application.
Mapper les entités vers des index
Commencez par lister vos entités recherchables — typiquement produits, articles, utilisateurs, docs d'aide, lieux, etc. Dans beaucoup d'apps, l'approche la plus propre est un index par type d'entité (par ex. products, articles). Cela garde les règles de classement et les filtres prévisibles.
Si votre UX recherche plusieurs types dans une même zone (“tout rechercher”), vous pouvez conserver des index séparés et fusionner les résultats dans votre backend, ou créer plus tard un index « global » dédié. N'obligez pas tout dans un seul index sauf si les champs et filtres sont vraiment alignés.
Chaque document a besoin d'un identifiant stable (clé primaire). Choisissez quelque chose qui :
- ne change jamais (ou très rarement)
- est unique dans l'index
- existe déjà dans votre base de données (par ex.
id, sku, slug)
Pour la forme du document, privilégiez les champs plats quand c'est possible. Les structures plates sont plus faciles à filtrer et à trier. Les champs imbriqués conviennent quand ils représentent un paquet étroit et immuable (par ex. un objet author), mais évitez les imbrications profondes qui reflètent tout votre schéma relationnel : les documents de recherche doivent être optimisés pour la lecture, pas pour la base de données.
Classifier les champs : recherchables, filtrables, affichés
Une manière pratique de concevoir les documents est d'attribuer à chaque champ un rôle :
- Searchable : texte que les gens tapent (titre, nom, description)
- Filterable : attributs utilisés comme contraintes (catégorie, fourchette de prix, statut, tags)
- Displayed : ce que vous renvoyez à l'UI (titre, URL de miniature, snippet)
Cela évite une erreur courante : indexer un champ “au cas où” puis se demander pourquoi les résultats sont bruyants ou pourquoi les filtres sont lents.
Planifier le contenu multilingue
La “langue” peut signifier différentes choses dans vos données :
- la langue du document (chaque article a
lang: "en")
- la locale de l'utilisateur (langue de l'UI)
- champs en langues mixtes (noms de produit en plusieurs langues)
Décidez tôt si vous utiliserez des index séparés par langue (simple et prévisible) ou un index unique avec des champs de langue (moins d'index, plus de logique). La bonne réponse dépend de si les utilisateurs recherchent dans une seule langue à la fois et comment vous stockez les traductions.
Installer et exécuter Meilisearch en toute sécurité
Exécuter Meilisearch est simple, mais « sûr par défaut » demande quelques choix délibérés : où le déployer, comment persister les données, et comment gérer la clé master.
Options de déploiement (choisissez ce que vous pouvez exploiter)
- Docker (le plus courant) : démarrage rapide, mises à jour faciles, cohérent entre environnements. Accompagnez-le d'un volume persistant.
- VM ou bare metal : bon si vous avez déjà une pipeline de déploiement Linux standard (systemd, rotation des logs, backups).
- Hébergement géré : si votre équipe ne veut pas maintenir des serveurs, cherchez un fournisseur Meilisearch géré ou une plateforme l'offrant en add-on. Vous échangerez flexibilité contre opérations simplifiées.
Principes d'environnement : stockage, mémoire, sauvegardes, monitoring
Stockage : Meilisearch écrit son index sur disque. Placez le répertoire de données sur un stockage persistant et fiable (pas le stockage éphémère des conteneurs). Prévoir la capacité pour la croissance : les index peuvent s'étendre rapidement avec de grands champs texte et de nombreux attributs.
Mémoire : allouez suffisamment de RAM pour garder la recherche réactive sous charge. Si vous voyez du swap, les performances souffriront.
Sauvegardes : sauvegardez le répertoire de données Meilisearch (ou utilisez des snapshots au niveau du stockage). Testez la restauration au moins une fois ; une sauvegarde que vous ne pouvez pas restaurer n'est qu'un fichier.
Monitoring : suivez CPU, RAM, utilisation disque et I/O disque. Surveillez aussi la santé du processus et les erreurs dans les logs. Au minimum, alertez si le service s'arrête ou si l'espace disque devient faible.
Définir et stocker la clé master en sécurité
Exécutez toujours Meilisearch avec une clé master pour tout environnement au-delà du développement local. Stockez-la dans un gestionnaire de secrets ou un magasin d'environnement chiffré (pas dans Git, pas dans un .env en clair versionné).
Exemple (Docker) :
docker run -d --name meilisearch \\
-p 7700:7700 \\
-v meili_data:/meili_data \\
-e MEILI_MASTER_KEY="$(openssl rand -hex 32)" \\
getmeili/meilisearch:latest
Pensez aussi aux règles réseau : liez sur une interface privée ou restreignez l'accès entrant pour que seul votre backend puisse atteindre Meilisearch.
Checklist de premier démarrage
curl -s http://localhost:7700/version
Indexer des documents et les garder synchronisés
Portez la recherche sur mobile
Générez un client Flutter qui appelle de manière cohérente votre endpoint de recherche côté serveur.
L'indexation dans Meilisearch est asynchrone : vous envoyez des documents, Meilisearch met la tâche en file, et ce n'est qu'après le succès de cette tâche que ces documents deviennent recherchables. Traitez l'indexation comme un système de jobs, pas comme une requête unique.
Un flux d'indexation simple (ajouter → attendre → vérifier)
- Ajouter des documents (assurez-vous que chacun a un id unique et stable, généralement
id).
curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \\
-H 'Content-Type: application/json' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY' \\
--data-binary @products.json
- Attendre la tâche. La réponse API inclut un
taskUid. Poller jusqu'à succeeded (ou failed).
curl -X GET 'http://localhost:7700/tasks/123' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY'
- Vérifier les comptes et une recherche basique. Confirmez que l'index contient le nombre attendu de documents et qu'une requête simple renvoie des résultats.
curl -X GET 'http://localhost:7700/indexes/products/stats' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY'
Si les comptes ne correspondent pas, n'improvisez pas — vérifiez d'abord les détails d'erreur de la tâche.
Batching qui ne vous surprendra pas plus tard
Le batching consiste à garder les tâches prévisibles et récupérables.
- Commencez par 1 000–10 000 documents par batch, ou limitez par taille de payload (pour beaucoup d'apps, 5–15 Mo par requête est confortable).
- Préférez beaucoup de petits lots plutôt qu'un seul upload massif ; c'est plus simple à réessayer et à isoler quand un enregistrement pose problème.
- Si vous avez des changements fréquents, indexez en continu par lots (par ex. chaque minute) plutôt que de tout reconstruire.
Mises à jour vs réindexation complète
addDocuments fonctionne comme un upsert : les documents avec la même clé primaire sont mis à jour, les nouveaux sont insérés. Utilisez cela pour les mises à jour normales.
Faites une réindexation complète lorsque :
- la forme des documents a changé significativement,
- vous devez recalculer des champs dérivés,
- votre synchronisation a dérivé et vous voulez un reset propre.
Pour les suppressions, appelez explicitement deleteDocument(s) ; sinon les anciens enregistrements peuvent persister.
Idempotence : réessais sûrs quand les jobs échouent
L'indexation doit être réessivable. La clé est des ids de document stables.
- Si un upload de batch expire, vous pouvez renvoyer le même lot : upsert + ids stables évitent les doublons.
- Persistez le
taskUid renvoyé avec l'identifiant de lot/job, et réessayez en fonction du statut de la tâche.
- Si vous utilisez une queue, rendez le worker “at-least-once” sûr : les doublons doivent être inoffensifs.
Données de seed pour un test pré-production rapide
Avant les données de production, indexez un petit jeu (200–500 items) qui correspond à vos champs réels. Exemple : un set products avec id, name, description, category, brand, price, inStock, createdAt. C'est suffisant pour valider le flux de tâches, les comptes, et le comportement update/delete — sans attendre un import massif.
Pertinence et règles de classement que vous pouvez contrôler
La “pertinence” de la recherche, c'est simplement : qu'est-ce qui apparaît en premier, et pourquoi. Meilisearch permet d'ajuster cela sans vous forcer à créer votre propre scoring.
Commencez par les bons attributs
Deux settings déterminent ce que Meilisearch peut faire avec votre contenu :
searchableAttributes : les champs que Meilisearch consulte quand un utilisateur tape une requête (par ex. : title, summary, tags). L'ordre compte : les champs placés plus tôt sont considérés comme plus importants.displayedAttributes : les champs renvoyés dans la réponse. Cela compte pour la confidentialité et la taille de la payload — si un champ n'est pas affiché, il ne sera pas renvoyé.
Une bonne base pratique : rendre quelques champs à signal élevé recherchables (titre, texte clé), et limiter les champs affichés à ce dont l'UI a besoin.
Meilisearch trie les documents correspondants en utilisant des règles de classement — une pipeline de “désambiguïsation”. Conceptuellement, il préfère :
- les résultats qui correspondent bien à la requête (y compris la tolérance aux fautes), puis
- les résultats où les correspondances sont plus fortes (mots plus proches, correspondance dans des attributs plus importants), puis
- les résultats qui correspondent à votre logique métier (tri personnalisé comme récence ou popularité).
Vous n'avez pas à mémoriser les détails internes pour le régler efficacement ; vous choisissez surtout quels champs comptent le plus et quand appliquer un tri personnalisé.
Objectifs de réglage courants (avec exemples)
Objectif : “Les correspondances dans le titre doivent gagner.” Mettez title en premier :
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
Objectif : “Le contenu plus récent doit apparaître en premier.” Ajoutez un attribut triable et triez au moment de la requête (ou définissez un classement personnalisé) :
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
Puis demandez :
{ "q": "release notes", "sort": ["publishedAt:desc"] }
Objectif : “Promouvoir les éléments populaires.” Rendez popularity triable et triez par ce champ quand c'est approprié.
Évaluer les changements avec un test simple before/after
Choisissez 5–10 requêtes réelles que les utilisateurs tapent. Sauvegardez les meilleurs résultats avant les changements, puis comparez après.
Exemple :
- Avant : requête
"apple" → Apple Watch band, Pineapple slicer, Apple iPhone case
- Après (titre prioritaire + exactitude) : requête
"apple" → Apple iPhone case, Apple Watch band, Pineapple slicer
Si la liste “après” correspond mieux à l'intention utilisateur, gardez les réglages. Si ça nuit à des cas limites, ajustez une chose à la fois (ordre des attributs, puis règles de tri) pour savoir ce qui a causé l'amélioration.
Filtres, tri et facettes pour la recherche en conditions réelles
Une bonne barre de recherche n'est pas seulement “tapez des mots, obtenez des correspondances.” Les gens veulent aussi restreindre les résultats (“seulement les articles disponibles”) et les ordonner (“le moins cher d'abord”). Dans Meilisearch, vous le faites avec des filtres, du tri et des facettes.
Filtres et facettes (même idée, UI différente)
Un filtre est une règle appliquée au jeu de résultats. Une facette est ce que vous montrez dans l'UI pour aider l'utilisateur à construire ces règles (souvent des cases à cocher ou des comptes).
Exemples non techniques :
- Catégorie : “Chaussures”, “Vestes”, “Accessoires”
- Prix : “Moins de 50 $”, “50–100 $”
- Statut : “En stock”, “En réapprovisionnement”, “Archivé”
Un utilisateur peut rechercher “running” puis filtrer par category = Shoes et status = in_stock. Les facettes peuvent afficher des comptes comme “Shoes (128)” et “Jackets (42)” pour indiquer ce qui est disponible.
Meilisearch a besoin que vous autorisiez explicitement les champs utilisés pour le filtrage et le tri.
- Marquez les champs comme filterable quand vous les utiliserez en filtre :
category, status, brand, price, created_at (si vous filtrez par durée), tenant_id (pour isoler des clients).
- Marquez les champs comme sortable quand vous trierez par eux :
price, rating, created_at, popularity.
Gardez cette liste serrée. Rendre tout filtrable/triable peut augmenter la taille de l'index et ralentir les mises à jour.
Même si vous avez 50 000 correspondances, les utilisateurs ne voient que la première page. Utilisez des pages petites (souvent 20–50 résultats), définissez un limit sensé, et paginez avec offset (ou les nouvelles fonctionnalités de pagination si vous préférez). Calez aussi une profondeur de page maximale dans votre app pour éviter des requêtes coûteuses “page 400”.
Synonymes et stop words (optionnel, à utiliser avec précaution)
- Synonymes aident quand des mots différents signifient la même chose (ex. “hoodie” ↔ “sweatshirt”). Ajoutez-les progressivement et revoyez les analytics — trop de synonymes peut produire des correspondances surprenantes.
- Stop words suppriment des mots courants (“the”, “and”). Ils peuvent réduire le bruit, mais aussi nuire aux recherches exactes comme les noms d'artistes (“The Who”, “A Team”). Personnalisez les stop words seulement si vous avez un problème clair à résoudre.
Intégrer Meilisearch dans votre backend applicatif
Compensez vos coûts de développement
Partagez ce que vous créez avec Koder.ai ou parrainez des coéquipiers pour gagner des crédits sur la plateforme.
Une façon propre d'ajouter une recherche côté serveur est de traiter Meilisearch comme un service de données spécialisé derrière votre API. Votre app reçoit une requête de recherche, appelle Meilisearch, puis renvoie une réponse organisée au client.
Un pattern backend simple
La plupart des équipes adoptent un flux comme :
- Le client appelle votre endpoint (par ex.
GET /api/search?q=wireless+headphones&limit=20).
- Votre backend valide les entrées, applique les règles métier, et décide quel index interroger.
- Le backend appelle l'API Search de Meilisearch avec la requête utilisateur plus filtres/tri.
- Le backend post-traite les résultats (cacher des champs privés, fusionner avec des données DB, appliquer permissions).
- Le backend renvoie au client une structure de réponse stable.
Ce pattern rend Meilisearch remplaçable et empêche le frontend de dépendre des détails internes des index.
Si vous construisez une nouvelle app (ou reconstruisez un outil interne) et voulez implémenter rapidement ce pattern, une plateforme de vibe-coding comme Koder.ai peut aider à générer le flow complet — UI React, backend Go, PostgreSQL — puis intégrer Meilisearch derrière un unique endpoint /api/search pour garder le client simple et les permissions côté serveur.
Requêter côté frontend vs backend (et pourquoi backend est plus sûr)
Meilisearch supporte les requêtes côté client, mais interroger via le backend est généralement plus sûr car :
- Les secrets restent privés : vous n'exposez pas des clés API privilégiées.
- L'autorisation est cohérente : votre backend peut appliquer “ce que cet utilisateur peut voir” avant de renvoyer les hits.
- Vous contrôlez la complexité des requêtes : limitez les filtres, options de tri et la pagination pour protéger les performances.
Le querying côté client peut convenir pour des données publiques avec des clés restreintes, mais si vous avez la moindre règle de visibilité par utilisateur, routez la recherche via votre serveur.
Cacher les requêtes populaires sans casser la pertinence
Le trafic de recherche a souvent des répétitions (“iphone case”, “return policy”). Ajoutez du caching à votre couche API :
- Mettez en cache la réponse entière pour de courtes périodes (par ex. 10–60 secondes) pour le trafic anonyme.
- Normalisez les clés de cache (trim, lowercase, inclure filtres/tri).
- Invalidatez prudemment : pour des index qui changent vite, gardez des TTLs courts plutôt que d'essayer d'effacer agressivement.
Limites de débit et protections contre les abus
Traitez la recherche comme un endpoint public :
- Appliquez des limites par IP ou par utilisateur.
- Définissez un
limit maximal et une longueur maximale de requête.
- Envisagez de bloquer doucement les bots évidents tout en permettant aux vrais utilisateurs d'accéder.
Principes de sécurité : clés, contrôle d'accès, multi-tenant
Meilisearch est souvent placé « derrière » votre app car il peut renvoyer rapidement des données sensibles. Traitez-le comme une base : verrouillez-le et n'exposez que ce que chaque appelant doit voir.
Clés API : master vs restreintes (principe du moindre privilège)
Meilisearch a une clé master qui peut tout faire : créer/supprimer des index, mettre à jour des settings, lire/écrire des documents. Gardez-la côté serveur uniquement.
Pour les applications, générez des clés API avec actions limitées et index limités. Un pattern courant :
- Jobs backend : une clé qui peut écrire des documents et mettre à jour des settings, mais seulement sur des index spécifiques.
- Serveur d'app : une clé en lecture seule pour la recherche.
- Client (si nécessaire) : une clé de recherche strictement limitée avec filtres contraints.
Le moindre privilège signifie qu'une clé divulguée ne peut pas supprimer de données ni lire d'index non autorisés.
Multi-tenancy : index séparés ou filtrer par tenantId
Si vous servez plusieurs clients (tenants), vous avez deux options principales :
1) Un index par tenant.
Simple à raisonner et réduit le risque d'accès croisé entre tenants. Inconvénients : plus d'index à gérer, et les mises à jour de settings doivent être appliquées partout.
2) Index partagé + filtre tenant.
Stockez un champ tenantId sur chaque document et exigez un filtre tenantId = "t_123" pour toutes les recherches. Cela peut bien scaler, mais seulement si vous assurez que chaque requête applique toujours le filtre (idéalement via une clé restreinte pour empêcher la suppression du filtre).
Empêcher les fuites de données : contrôler ce qui peut être renvoyé
Même si la recherche est correcte, les résultats peuvent exposer des champs que vous ne vouliez pas montrer (emails, notes internes, prix de revient). Configurez ce qui est récupérable :
- Limitez les displayed/retrievable attributes à une allowlist sûre.
- Conservez les champs sensibles indexés uniquement si nécessaire — et évitez de les renvoyer dans les résultats.
Faites un test “pire scénario” : cherchez un terme courant et confirmez qu'aucun champ privé n'apparaît.
Sécurité opérationnelle basique
- Restreignez l'accès réseau : liez à localhost ou à un réseau privé, et autorisez le trafic entrant seulement depuis vos serveurs applicatifs.
- Placez Meilisearch derrière un reverse proxy si vous avez besoin de TLS et de limites de débit.
- Stockez les clés dans un gestionnaire de secrets (pas dans le code source ou les bundles frontend) et faites une rotation périodique.
Si vous hésitez à exposer une clé côté client, supposez « non » et gardez la recherche côté serveur.
Ajustez la pertinence en toute confiance
Testez les modifications de classement et restaurez rapidement grâce aux snapshots.
Meilisearch est rapide quand vous gardez en tête deux charges de travail : indexation (écritures) et requêtes de recherche (lectures). La plupart des lenteurs mystérieuses proviennent de l'une de ces charges qui rivalise pour le CPU, la RAM ou le disque.
La charge d'indexation peut monter en flèche lors d'import massifs, de mises à jour fréquentes, ou si vous ajoutez beaucoup de champs recherchables. L'indexation est en tâche de fond, mais elle consomme CPU et bande passante disque. Si votre file de tâches grandit, les recherches peuvent devenir plus lentes même si le volume de requêtes n'a pas changé.
La charge de requêtes augmente avec le trafic, mais aussi avec les fonctionnalités : plus de filtres, plus de facettes, jeux de résultats plus grands, et une tolérance aux fautes plus agressive peuvent augmenter le travail par requête.
L'I/O disque est souvent le coupable silencieux. Des disques lents (ou des voisins bruyants sur des volumes partagés) peuvent transformer “instantané” en “finalement”. Un stockage NVMe/SSD est la base typique pour la production.
Étapes pratiques pour scaler
Commencez par un dimensionnement simple : donnez à Meilisearch assez de RAM pour garder les index en chaud et assez de CPU pour gérer le QPS pic. Séparez ensuite les préoccupations :
- Si l'indexation interfère avec les lectures, planifiez les imports massifs hors-pointe et préférez des batchs plus grands plutôt que beaucoup de petites mises à jour.
- Ajoutez des replicas pour la haute disponibilité et la capacité de lecture (votre app peut load-balancer les requêtes de recherche entre replicas).
- Sharding : Meilisearch ne fait pas de sharding distribué automatique. Si vous dépassez une seule instance, partitionnez les données au niveau applicatif (par tenant, région ou plage temporelle) dans plusieurs index ou clusters.
Que surveiller (pour ne pas deviner)
Suivez un petit ensemble de signaux :
- Latence de recherche (p50/p95) et débit
- Longueur de la file de tâches / temps de traitement des tâches (une file qui monte signifie que l'indexation ne suit pas)
- CPU, RAM, usage disque et attente I/O disque
- Taux d'erreurs (timeouts, 4xx/5xx, tâches échouées)
Sauvegardes et planification des mises à jour
Les backups doivent être routiniers. Utilisez la fonctionnalité de snapshot de Meilisearch selon un planning, stockez les snapshots hors-site, et testez périodiquement les restaurations. Pour les upgrades, lisez les notes de version, faites un staging de l'upgrade en non-prod, et prévoyez du temps de réindexation si une version affecte le comportement d'indexation.
Si vous utilisez déjà des snapshots d'environnement et des rollbacks sur votre plateforme (par ex. via le workflow snapshots/rollback de Koder.ai), alignez votre déploiement de recherche sur la même discipline : snapshot avant les changements, vérifiez les health checks, et gardez un chemin rapide vers un état connu bon.
Dépannage et checklist de déploiement pratique
Même avec une intégration propre, les problèmes de recherche tombent souvent dans quelques catégories récurrentes. La bonne nouvelle : Meilisearch vous donne assez de visibilité (tâches, logs, settings déterministes) pour déboguer rapidement — si vous procédez méthodiquement.
Problèmes fréquents (et leur signification)
- “Mes filtres ne fonctionnent pas” : le champ n'a pas été ajouté à
filterableAttributes, ou les documents le stockent dans une forme inattendue (string vs tableau vs objet imbriqué).
- “Les résultats sont classés de façon étrange” : les règles de classement, les synonymes, les stop words, ou un
sortableAttributes/rankingRules manquant poussent de mauvais éléments en haut.
- “La recherche affiche des données anciennes” : les tâches d'indexation sont toujours en cours, vous écrivez dans un index différent de celui que vous lisez, ou votre pipeline de sync a perdu des mises à jour/suppressions.
Flux de débogage qui reste sain
Commencez par vérifier si Meilisearch a appliqué votre dernier changement.
- Inspecter le statut de la tâche : chaque changement de settings et chaque mise à jour de document crée une tâche asynchrone. Si une tâche a échoué, corrigez cela d'abord (payload invalide, mauvais types, documents trop volumineux).
- Utiliser les logs avec une seule question en tête : “Le serveur a-t-il accepté ma requête ?” puis “A-t-il fini de la traiter ?” Évitez de tout scanner à la fois.
- Créer une requête minimalement reproductible :
- Choisissez un index.
- Utilisez une requête qui renvoie un petit ensemble stable.
- Ajoutez les contraintes une par une :
filter, puis sort, puis facets.
Si vous ne pouvez pas expliquer un résultat, réduisez temporairement la configuration : retirez les synonymes, diminuez les modifications des règles de classement, et testez avec un dataset minuscule. Les problèmes complexes de pertinence sont bien plus faciles à repérer sur 50 documents que sur 5 millions.
Stratégie de déploiement : réduire le périmètre d'impact
- Tester un index d'abord : build
your_index_v2 en parallèle, appliquez les settings, et rejouez un échantillon de requêtes de prod.
- Déploiement canari : routez un petit pourcentage du trafic de recherche vers le nouvel index ou les nouveaux settings, comparez le click-through et le taux de “no results”.
- Comportement de repli : décidez ce que voient les utilisateurs si la recherche est lente ou indisponible — résultats en cache, requête simplifiée, ou message aimable “réessayez”. Ne laissez pas une panne de recherche casser toute la page.
Checklist des prochaines étapes
- Vérifier que
filterableAttributes et sortableAttributes correspondent aux besoins de l'UI.
- Confirmer que les tâches d'indexation finissent avec succès après chaque déploiement.
- Ajouter un petit « monitor santé recherche » (latence + tâches échouées).
- S'entraîner au rollback : basculer le trafic vers l'index précédent.
Guides liés : /blog (fiabilité de la recherche, patterns d'indexation et conseils de déploiement en production).