30 août 2025·8 min
Nginx vs HAProxy : choisir le bon proxy inverse
Comparer Nginx et HAProxy comme proxies inverses : performance, équilibrage, TLS, observabilité, sécurité et architectures courantes pour choisir la meilleure option.
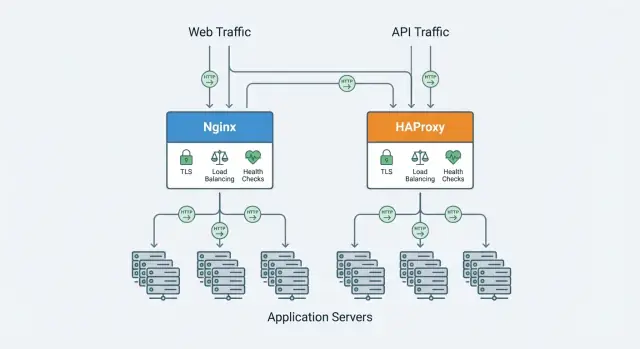
Ce qu’un reverse proxy apporte à vos applications
Un reverse proxy est un serveur qui se place devant vos applications et reçoit d’abord les requêtes des clients. Il achemine chaque requête vers le bon service backend (vos serveurs d’application) et renvoie la réponse au client. Les utilisateurs communiquent avec le proxy ; le proxy communique avec vos apps.
Un forward proxy fonctionne dans l’autre sens : il se place devant les clients (par exemple, dans un réseau d’entreprise) et relaie leurs requêtes sortantes vers Internet. Il sert principalement à contrôler, filtrer ou masquer le trafic client.
Un équilibreur de charge est souvent implémenté comme un reverse proxy, mais avec un objectif précis : répartir le trafic entre plusieurs instances backend. De nombreux produits (y compris Nginx et HAProxy) font à la fois reverse proxy et équilibrage, d’où l’emploi parfois interchangeable des termes.
Objectifs typiques pour lesquels les équipes utilisent un reverse proxy
La plupart des déploiements démarrent pour une ou plusieurs de ces raisons :
- Terminaison TLS/SSL : gérer HTTPS en un point unique, administrer les certificats de façon centralisée, et éventuellement renvoyer du HTTP non chiffré vers les services internes.
- Routage : adresser le trafic vers différents services selon le hostname, le chemin, les en-têtes ou d’autres règles (par ex.
/apivers un service API,/vers une application web). - Buffering et gestion des connexions : lisser les clients lents ou les upstreams lents, réduire le coût par connexion sur vos serveurs d’apps et améliorer la fiabilité perçue.
- Contrôles de protection : appliquer des limites de requêtes, filtrages basiques et des valeurs par défaut plus sûres avant que les requêtes n’atteignent votre application.
Où il se place devant vos apps
Les reverse proxies servent souvent de façade pour des sites web, API et microservices—soit en bordure (internet public), soit en interne entre services. Dans les stacks modernes, ils sont aussi des blocs de construction pour les gateways d’ingress, les déploiements blue/green et les architectures haute disponibilité.
Ce que ce guide va vous aider à décider
Nginx et HAProxy se recoupent, mais diffèrent d’un point de vue fonctionnel. Dans les sections suivantes, nous comparerons des facteurs de décision comme la performance sous forte concurrence, l’équilibrage et les health checks, le support des protocoles (HTTP/2, TCP), les fonctionnalités TLS, l’observabilité, et l’exploitation quotidienne et la configuration.
Présentation de Nginx : forces et cas d’usage typiques
Nginx est largement utilisé à la fois comme serveur web et comme reverse proxy. Beaucoup d’équipes commencent par l’utiliser pour servir un site public puis étendent son rôle pour se placer devant des serveurs d’applications—gérant TLS, routage et lissage des pics.
Pourquoi Nginx plaît en bordure
Nginx excelle quand votre trafic est principalement HTTP(S) et que vous voulez une « porte d’entrée » capable de tout couvrir un peu. Il est particulièrement bon pour :
- Servir assets statiques (images, CSS/JS) efficacement
- Agir comme reverse proxy HTTP avec un routage basé sur le chemin et l’hôte simple
- Mettre en cache des réponses pour réduire la charge sur les apps upstream
- Ajouter ou normaliser des en-têtes (ex.
X-Forwarded-For, en-têtes de sécurité)
Parce qu’il peut à la fois servir du contenu et proxifier des apps, Nginx est un choix courant pour les petites et moyennes installations qui veulent moins de composants.
Modules et fonctionnalités sur lesquels les équipes comptent
Fonctionnalités populaires :
- Terminaison TLS et workflows de gestion de certificats (souvent automatisés avec des rechargements)
- Compression (gzip/brotli selon la compilation) pour réduire la bande passante
- Limitation de débit et contrôles de requêtes basiques pour amortir les clients bruyants
- Réécritures et redirections pour le nettoyage d’URL et les migrations legacy
- Fonctions optionnelles comme le proxy WebSocket pour les apps temps réel
Scénarios typiques « front door »
Nginx est souvent choisi quand vous avez besoin d’un point d’entrée pour :
- Un site marketing + une API (statique + proxy)
- Un équilibrage simple entre quelques instances d’app
- Du caching devant des backends lents (CMS, services REST)
- Servir de gateway pour plusieurs services sous différents hostnames
Si votre priorité est la richesse du traitement HTTP et que vous aimez l’idée de combiner serveur web et reverse proxy, Nginx est fréquemment le choix par défaut.
Présentation de HAProxy : forces et cas d’usage typiques
HAProxy (High Availability Proxy) est principalement utilisé comme reverse proxy et équilibreur de charge devant des serveurs d’application. Il accepte le trafic entrant, applique des règles de routage/trafficking, et achemine vers des backends sains—souvent en maintenant des temps de réponse stables sous forte concurrence.
Usages courants de HAProxy
Les équipes déploient généralement HAProxy pour la gestion du trafic : répartir les requêtes, maintenir la disponibilité lors des pannes et lisser les pics. C’est un choix fréquent en bordure (trafic nord–sud) et aussi en interne (est–ouest), surtout quand vous voulez un comportement prédictible et un contrôle fort sur la gestion des connexions.
Forces principales : connexions, équilibrage, health checks
HAProxy est reconnu pour sa gestion efficace d’un grand nombre de connexions concurrentes. Cela compte lorsque de nombreux clients sont connectés en même temps (APIs chargées, connexions longues, services microservices bavards) et que vous voulez que le proxy reste réactif.
Ses capacités d’équilibrage sont une grande raison de son adoption. Au-delà du round-robin simple, il supporte plusieurs algorithmes et stratégies qui permettent de :
- Éviter d’écraser les serveurs « hot »
- Basculer le trafic progressivement pendant des rollouts
- Favoriser des instances plus rapides ou moins chargées si nécessaire
Les vérifications de santé sont un autre point fort. HAProxy peut vérifier activement la santé des backends et retirer automatiquement les instances défaillantes, puis les réintégrer quand elles récupèrent. En pratique, cela réduit les temps d’indisponibilité et empêche qu’un déploiement partiellement cassé n’impacte tous les utilisateurs.
Layer 4 vs Layer 7 : ce que cela signifie en pratique
HAProxy peut fonctionner en Layer 4 (TCP) et Layer 7 (HTTP).
- Layer 4 (TCP) se concentre sur le forwarding brut des connexions. Idéal pour des protocoles où l’inspection HTTP n’est pas nécessaire—bases de données, proxies TCP, ou si vous voulez un overhead minimal.
- Layer 7 (HTTP) comprend la sémantique HTTP, permettant le routage basé sur les en-têtes, les chemins et des contrôles de trafic plus fins.
La différence pratique : L4 est généralement plus simple et très rapide pour le passage TCP ; L7 apporte un routage et une logique de requête riches quand vous en avez besoin.
Quand choisir HAProxy
HAProxy est souvent choisi lorsque l’objectif principal est un équilibrage de charge fiable et performant avec des vérifications de santé robustes—par exemple, répartir le trafic API sur plusieurs serveurs, gérer le basculement entre zones de disponibilité, ou fronting des services où le volume de connexions et le comportement prévisible du trafic comptent plus que des fonctionnalités avancées de serveur web.
Notions de performance : latence, débit et connexions
Les comparaisons de performance échouent souvent parce qu’on regarde un unique chiffre (comme « RPS max ») sans tenir compte de la perception utilisateur.
Débit vs latence vs latence en queue (tail latency)
- Débit : combien de travail vous pouvez traiter (requêtes/s ou octets/s).
- Latence : combien de temps prend une requête.
- Latence en queue (p95/p99) : là où la douleur apparaît réellement : même si la moyenne va bien, les 1–5 % les plus lentes peuvent provoquer timeouts, retry et une mauvaise UX.
Un proxy peut augmenter le débit tout en dégradant la latence en queue s’il met trop de travail en file d’attente sous charge.
Les schémas de connexion comptent
Réfléchissez à la « forme » de votre application :
- Beaucoup de requêtes courtes (trafic web typique) : l’efficacité d’acceptation des connexions, les handshakes TLS et le parsing des requêtes importe.
- Peu de connexions longues (WebSockets, streaming, gRPC) : la stabilité et l’usage prévisible des ressources par connexion comptent plus que le RPS brut.
Si vous faites un benchmark sur un modèle mais en déployez un autre, les résultats ne seront pas transposables.
Buffering : ami et ennemi
Le buffering peut aider quand les clients sont lents ou en rafales, car le proxy peut lire la requête complète (ou la réponse) et alimenter votre app plus régulièrement.
Le buffering peut nuire quand votre app bénéficie du streaming (SSE, gros téléchargements, API temps réel). Le buffering supplémentaire augmente la pression mémoire et peut accroître la latence en queue.
Conseils pratiques pour les benchmarks
Mesurez plus que le « RPS max » :
- RPS/débit, latence p50/p95/p99, et taux d’erreurs (timeouts, 502/503).
- Testez charge stable et pics (les rafales courtes révèlent souvent le comportement de mise en file).
- Utilisez des réglages keep-alive/TLS réalistes et enregistrez CPU, mémoire et connexions ouvertes.
Si le p95 grimpe fortement avant l’apparition d’erreurs, vous voyez des signes précoces de saturation—pas de « marge gratuite ».
Équilibrage de charge et vérifications de santé comparés
Planifiez le flux de travail du proxy
Cartographiez routes, timeouts et étapes de déploiement en mode Planification avant de déployer.
Nginx et HAProxy peuvent tous deux être placés devant plusieurs instances applicatives et répartir le trafic, mais ils diffèrent par la profondeur de leur offre d’équilibrage native.
Algorithmes d’équilibrage
Round-robin est le choix par défaut « suffisamment bon » quand vos backends sont similaires (même CPU/mémoire, même coût par requête). Simple et prévisible, il fonctionne bien pour des apps sans état.
Least connections est utile quand les requêtes varient en durée (téléchargements, appels API longs, WebSocket). Il a tendance à éviter d’affecter les serveurs lents en favorisant ceux qui ont moins de connexions actives.
Weighted balancing (round-robin pondéré, ou least connections pondéré) est l’option pratique quand les serveurs ne sont pas identiques—mélange d’anciennes et nouvelles nœuds, tailles d’instances différentes, ou migration progressive.
En général, HAProxy offre plus de choix d’algorithmes et un contrôle fin en L4/L7, tandis que Nginx couvre proprement les cas courants (et peut être étendu selon l’édition/modules).
Persistance de session (stickiness)
La stickiness garde un utilisateur sur le même backend entre requêtes.
- Persistance par cookie convient généralement le mieux aux apps web : explicite, fonctionne derrière NAT et permet un basculement contrôlé si le backend disparaît.
- Persistance par IP source est facile à activer, mais peut être injuste (beaucoup d’utilisateurs derrière un NAT/IP aboutissent sur un seul backend) et casser si la visibilité IP change (CDN, proxies).
N’utilisez la persistance que si nécessaire (serveurs legacy avec sessions côté serveur). Les apps sans état montent et récupèrent mieux.
Health checks : actifs vs passifs
Les health checks actifs sondent périodiquement les backends (endpoint HTTP, connexion TCP, code attendu). Ils détectent les pannes même quand le trafic est faible.
Les health checks passifs réagissent au trafic réel : timeouts, erreurs de connexion ou mauvaises réponses marquent un serveur comme défaillant. Legers, ils peuvent mettre plus de temps à détecter un problème.
HAProxy est largement réputé pour ses contrôles de santé riches et ses mécanismes de gestion des pannes (seuils, comptes d’élévation/abaissement, vérifications détaillées). Nginx propose des checks solides aussi, selon la compilation/édition.
Déploiements sans interruption : draining et retries
Pour les déploiements progressifs, cherchez :
- Draining des connexions : ne plus envoyer de nouvelles requêtes à un backend, mais laisser finir les requêtes en cours.
- Retries et redispatch : si un backend échoue en cours de requête, réessayer en sécurité (seulement pour les requêtes idempotentes) ou envoyer vers un autre serveur sain.
Associez le draining à des timeouts courts et bien définis et à un endpoint “ready/unready” pour que le trafic bascule en douceur pendant les déploiements.
Protocoles et TLS : HTTP, HTTP/2 et proxy TCP
Prototypez votre configuration edge
Prototypiez une stack web + API via le chat, puis déployez quand vous êtes prêt.
Les reverse proxies se situent en bordure de votre système, donc les choix de protocoles et TLS impactent tout, depuis la performance navigateur jusqu’à la manière dont les services communiquent entre eux.
Terminaison TLS et gestion des certificats
Nginx et HAProxy peuvent tous deux effectuer la « terminaison » TLS : accepter des connexions chiffrées clients, déchiffrer le trafic puis l’aiguiller vers vos apps en HTTP ou TLS ré-chiffré.
La réalité opérationnelle est la gestion des certificats. Il faut planifier :
- Obtention et renouvellement des certificats (souvent via ACME/Let’s Encrypt)
- Stockage sécurisé des clés privées et limitation des accès
- Rechargements de configuration sans couper les connexions
Nginx est souvent choisi quand la terminaison TLS s’accompagne de fonctionnalités serveur web (fichiers statiques, redirections). HAProxy est souvent choisi quand TLS fait surtout partie d’une couche de gestion du trafic (équilibrage, gestion des connexions).
HTTP/2 : performance et compatibilité
HTTP/2 peut réduire les temps de chargement en multiplexant plusieurs requêtes sur une seule connexion. Les deux outils supportent HTTP/2 côté client.
Points clés :
- Compatibilité client : la plupart des navigateurs modernes supportent HTTP/2, mais certains clients anciens et certains outils automatisés peuvent ne pas le faire.
- Support backend : il est courant de terminer HTTP/2 au proxy et de parler HTTP/1.1 aux upstreams, ce qui est plus simple.
Quand le proxy TCP est important
Si vous devez router du trafic non-HTTP (bases de données, SMTP, Redis, protocoles custom), vous avez besoin du proxying TCP plutôt que du routage HTTP. HAProxy est largement utilisé pour l’équilibrage TCP haute performance avec des contrôles fins de connexion. Nginx peut aussi proxyfier du TCP (via son module stream), ce qui suffit pour des configurations de passage simples.
Mutual TLS (mTLS)
Le mTLS vérifie les deux côtés : les clients présentent des certificats, pas seulement les serveurs. Idéal pour la communication service-à-service, les intégrations partenaires ou les architectures zero-trust. Les deux proxies peuvent valider les certificats clients en bordure, et beaucoup d’équipes utilisent aussi le mTLS en interne pour réduire l’hypothèse de « réseau de confiance ».
Observabilité : logs, métriques et debugging
Les reverse proxies sont au milieu de chaque requête, donc ils sont souvent l’endroit idéal pour répondre à « que s’est‑il passé ? ». Une bonne observabilité signifie des logs cohérents, un petit ensemble de métriques à fort signal et une méthode reproductible pour déboguer timeouts et erreurs gateway.
Logs requis : accès, erreur et timings upstream
Au minimum, activez les access logs et error logs en production. Pour les access logs, incluez les timings upstream afin de déterminer si la lenteur vient du proxy ou de l’application.
Dans Nginx, les champs courants sont le temps de requête et le timing upstream (ex. $request_time, $upstream_response_time, $upstream_status). Dans HAProxy, activez le mode de log HTTP et capturez les champs de timing (queue/connect/response) pour séparer « attente d’un créneau backend » de « backend lent ».
Conservez des logs structurés (JSON si possible) et ajoutez un request ID (provenant d’un en‑tête entrant ou généré) pour corréler logs proxy et logs applicatifs.
Métriques à exporter
Que vous scrappiez Prometheus ou envoyiez les métriques ailleurs, exposez un ensemble cohérent :
- Requêtes et codes de réponse (2xx/4xx/5xx)
- Compteurs d’erreurs (retries, health checks échoués, 502/504)
- Latence (p50/p95/p99 ; idéalement proxy vs upstream)
- Connexions (actives, en file, rejetées)
Nginx utilise souvent l’endpoint stub status ou un exporter Prometheus ; HAProxy a un endpoint stats intégré que beaucoup d’exporters exploitent.
Endpoints de santé et readiness
Exposez un endpoint léger /health (processus up) et /ready (peut toucher ses dépendances). Utilisez-les dans l’automatisation : vérifications d’équilibreur, déploiements et décisions d’auto-scaling.
Déboguer timeouts, resets, 502/504
- 502 : backend a refusé/fermé la connexion, problème DNS ou mismatch de protocole.
- 504 : le proxy a expiré en attendant le backend.
- Resets/timeouts : vérifiez les réglages keep-alive, la saturation backend et la longueur des files d’attente.
Quand vous dépannez, comparez le timing proxy (connect/queue) au temps de réponse upstream. Si connect/queue est élevé, ajoutez de la capacité ou ajustez l’équilibrage ; si le temps upstream est élevé, concentrez-vous sur l’application et la base de données.
Configuration et exploitation quotidienne
Testez mobile et API
Ajoutez un client Flutter à votre API et validez les connexions longues ainsi que les tentatives de reconnexion.
Gérer un reverse proxy, ce n’est pas seulement viser le débit maximal : c’est aussi pouvoir effectuer des changements sûrs à 14h (ou 2h du matin).
Style de conf et onboarding
La configuration Nginx est directive-based et hiérarchique. Elle s’organise en « blocs dans des blocs » (http → server → location), ce que beaucoup trouvent lisible quand on pense en termes de sites et de routes.
La configuration HAProxy est plus « pipeline » : vous définissez des frontends (ce que vous acceptez), des backends (où vous envoyez le trafic), puis des règles (ACLs) pour connecter le tout. Cela paraît plus explicite et prévisible une fois le modèle assimilé, surtout pour la logique de routage.
Reloads et gestion des changements
Nginx recharge typiquement la config en démarrant de nouveaux workers et en drainant proprement les anciens : pratique pour mises à jour fréquentes et renouvellements de certificats.
HAProxy peut aussi faire des rechargements transparents, mais les équipes le traitent souvent comme un « appliance » : contrôle des changements plus strict, config versionnée claire et coordination prudente pour les reloads.
Validation, templates et garder le DRY
Les deux supportent des tests de config avant reload (indispensable pour le CI/CD). En pratique, vous garderez la config DRY en la générant :
- Utilisez des templates (Helm, Ansible, Terraform, ou tooling interne)
- Conservez des snippets partagés pour logging, en-têtes, timeouts et defaults de sécurité
L’habitude clé : traitez la config du proxy comme du code—revue, tests et déploiement comme pour les changements applicatifs.
Exploiter à grande échelle : nombreuses apps, routes et certificats
Avec l’augmentation du nombre de services, la prolifération des certificats et du routage devient la vraie douleur. Préparez :
- Nommage et propriété standardisés (qui possède quels hostnames)
- Emission/rotation automatisée des certificats
- Conventions claires pour timeouts et retries par application
Si vous attendez des centaines d’hôtes, centralisez les patterns et générez la config à partir des métadonnées services plutôt que d’éditer manuellement les fichiers.
Où Koder.ai s’intègre dans ce workflow
Si vous construisez et itérez plusieurs services, un reverse proxy n’est qu’un élément de la chaîne de livraison—il vous faut aussi un scaffolding applicatif réplicable, la parité d’environnement et des rollouts sûrs.
Koder.ai peut aider les équipes à accélérer de l’idée au service en exécutant la génération d’apps React, backends Go + PostgreSQL et apps Flutter via un workflow conversationnel, puis en supportant l’export du code, le déploiement/hebergement, les domaines personnalisés et snapshots avec rollback. Concrètement, vous pouvez prototyper une API + frontend, la déployer, et décider ensuite si Nginx ou HAProxy est la meilleure porte d’entrée en vous basant sur des patterns de trafic réels plutôt que des hypothèses.
FAQ
Quelle est la différence entre un reverse proxy et un forward proxy?
Un reverse proxy se place devant vos applications : les clients se connectent au proxy, qui achemine les requêtes vers le service backend approprié et renvoie la réponse.
Un forward proxy se place devant les clients et contrôle l'accès sortant vers Internet (usage courant dans les réseaux d'entreprise).
Un équilibreur de charge est-il la même chose qu’un reverse proxy?
Un équilibreur de charge se concentre sur la répartition du trafic entre plusieurs instances backend. Beaucoup d’équilibreurs sont implémentés comme des reverse proxies, d’où le chevauchement des termes.
En pratique, vous utiliserez souvent un outil (comme Nginx ou HAProxy) pour faire les deux : reverse proxy + équilibrage de charge.
Où un reverse proxy doit-il se situer dans une architecture?
Placez-le à la frontière où vous voulez un point de contrôle unique :
- Périmètre (internet public → votre système) : terminaison TLS, routage, protection basique, journalisation cohérente.
- Interne (service → service) : mise en forme du trafic contrôlée, gestion des connexions, déploiements plus sûrs.
L’idée est d’éviter que les clients atteignent directement les backends afin que le proxy reste le point d’application des politiques et de visibilité.
Que signifie « TLS/SSL termination », et pourquoi est-ce utile?
La terminaison TLS signifie que le proxy gère HTTPS : il accepte des connexions chiffrées côté client, les déchiffre, puis achemine le trafic vers les upstreams en HTTP ou en TLS ré-chiffré.
Opérationnellement, il faut prévoir :
- L’émission/renouvellement automatisé des certificats (souvent ACME/Let’s Encrypt)
- Un stockage sécurisé des clés privées
- Des rechargements sûrs sans couper les connexions actives
Quand Nginx est-il généralement le meilleur choix?
Choisissez Nginx quand votre proxy est aussi une « porte d’entrée » web :
- Servir fichiers statiques efficacement
- Mise en cache (y compris micro-caching) pour alléger les upstreams
- Routage HTTP simple (host/path), redirections et normalisation des en-têtes
- Configuration HTTP-friendly et terminaison TLS pratique
Quand HAProxy est-il généralement le meilleur choix?
Choisissez HAProxy lorsque la gestion du trafic et la prévisibilité sous charge sont prioritaires :
- Gestion d’un grand nombre de connexions concurrentes efficacement
- Contrôles d’équilibrage avancés et algorithmes fins
Comment choisir entre round-robin, least-connections et weighted balancing?
Utilisez round-robin pour des backends similaires et des requêtes de coût uniforme.
Utilisez least connections quand la durée des requêtes varie (téléchargements, appels API longs, connexions longues) pour éviter de surcharger les instances lentes.
Utilisez des variantes pondérées quand les backends diffèrent (tailles d’instances, matériel mixte, migrations progressives) afin de diriger le trafic intentionnellement.
Ai-je besoin de persistance de session (sticky sessions), et quel type est préférable ?
La stickiness conserve un utilisateur sur le même backend across requêtes.
- Préférez la persistance par cookie pour les apps web (explicite et équitable derrière un NAT).
- Méfiez-vous de la persistance par IP source (beaucoup d’utilisateurs peuvent partager une même IP via NAT/CDN).
Évitez la stickiness si possible : les services sans état montent en charge, récupèrent et se déploient plus proprement sans elle.
Comment le buffering du proxy peut-il affecter la latence et les workloads en streaming?
Le buffering peut aider en lissant des clients lents ou des rafales, de sorte que votre app reçoive un flux plus régulier.
Il peut nuire quand vous avez besoin de streaming (SSE, WebSockets, gros téléchargements), car le buffering supplémentaire augmente la pression mémoire et peut aggraver la latence en queue.
Si votre app est orientée streaming, testez et ajustez le buffering explicitement au lieu de compter sur les valeurs par défaut.
Comment dépanner les erreurs 502/504 et les timeouts?
Commencez par séparer le délai côté proxy du délai côté backend en utilisant logs/métriques.
Sens courants :
- 502 : le backend a refusé/fermé la connexion, problème DNS, ou incompatibilité de protocole.
- 504 : le proxy a expiré en attendant le backend.
Signaux utiles :