Un Transformer est une manière d’aider les ordinateurs à comprendre des séquences — des choses où l’ordre et le contexte importent, comme des phrases, du code ou une série de requêtes. Plutôt que de lire un token à la fois en traînant une mémoire fragile, les Transformers regardent l’ensemble de la séquence et décident à quoi faire attention pour interpréter chaque élément.
Ce simple changement s’est avéré déterminant. C’est une des raisons majeures pour lesquelles les grands modèles de langage modernes (LLM) peuvent garder le contexte, suivre des instructions, écrire des paragraphes cohérents et générer du code qui référence des fonctions et variables vues plus tôt.
Si vous avez utilisé un chatbot, une fonction « résumer ceci », une recherche sémantique ou un assistant de codage, vous avez interagi avec des systèmes basés sur le Transformer. Le même schéma de base prend en charge :
- les outils de chat et support client qui suivent ce que vous avez dit plus tôt
- les systèmes de recherche et de recommandation qui appariement le sens, pas seulement les mots-clés
- la synthèse qui peut pondérer ce qui est central versus accessoire
- les outils de codage qui relient définitions, usages et intentions à travers des fichiers
Ce que vous apprendrez dans cet article
Nous décomposerons les éléments clés — auto-attention, attention multi-têtes, encodage positionnel et le bloc Transformer de base — et expliquerons pourquoi ce design se met si bien à l’échelle quand les modèles grandissent.
Nous évoquerons aussi des variantes modernes qui gardent l’idée centrale mais l’ajustent pour la vitesse, le coût ou des fenêtres de contexte plus longues.
À quoi vous attendre (et à quoi non)
C’est une visite à haut niveau avec des explications en langage simple et peu de maths. L’objectif est de construire de l’intuition : ce que font les pièces, pourquoi elles fonctionnent ensemble, et comment cela se traduit en capacités produit réelles.
Noam Shazeer est un chercheur et ingénieur en IA surtout connu comme l’un des coauteurs de l’article de 2017 “Attention Is All You Need.” Cet article a introduit l’architecture Transformer, qui est ensuite devenue la fondation de nombreux LLM modernes. Le travail de Shazeer s’inscrit dans un effort d’équipe : le Transformer a été créé par un groupe de chercheurs chez Google, et il est important de le reconnaître ainsi.
Ce que l’article de 2017 a changé
Avant le Transformer, beaucoup de systèmes NLP s’appuyaient sur des modèles récurrents qui traitaient le texte pas à pas. La proposition du Transformer a montré qu’on pouvait modéliser efficacement des séquences sans récurrence en utilisant l’attention comme principal mécanisme pour combiner l’information à travers une phrase.
Ce changement a compté parce qu’il a rendu l’entraînement plus parallélisable (on peut traiter de nombreux tokens à la fois), et il a ouvert la voie à la mise à l’échelle des modèles et des jeux de données d’une façon rapidement applicable aux produits réels.
De l’idée de recherche au bloc réutilisable
La contribution de Shazeer — aux côtés des autres auteurs — ne s’est pas limitée aux benchmarks académiques. Le Transformer est devenu un module réutilisable que les équipes peuvent adapter : changer des composants, ajuster la taille, le tuner pour des tâches, puis le préentraîner à grande échelle.
C’est ainsi que beaucoup de percées voyagent : un article introduit une recette claire et générale ; des ingénieurs la raffin(issent) ; des entreprises l’opérationnalisent ; et elle finit par devenir un choix par défaut pour construire des fonctions de langage.
Rendre le crédit précis
Il est exact de dire que Shazeer a été un contributeur clé et un coauteur de l’article Transformer. Il n’est pas exact de le présenter comme l’unique inventeur. L’impact découle du design collectif — et des nombreuses améliorations ultérieures que la communauté a construites sur ce blueprint initial.
Ce qui précédait : RNN, LSTM et leurs limites
Avant les Transformers, la plupart des problèmes de séquence (traduction, parole, génération de texte) étaient dominés par les Réseaux de Neurones Récurrents (RNN) puis par les LSTM (Long Short-Term Memory). L’idée principale était simple : lire le texte un token à la fois, garder une « mémoire » courante (un état caché) et s’en servir pour prédire la suite.
Une image rapide de leur fonctionnement
Un RNN traite une phrase comme une chaîne. À chaque étape, il met à jour l’état caché en fonction du mot courant et de l’état précédent. Les LSTM améliorent cela en ajoutant des portes qui décident quoi garder, oublier ou émettre — facilitant la conservation d’informations utiles plus longtemps.
Pourquoi les dépendances longue distance étaient difficiles
En pratique, la mémoire séquentielle a un goulot : beaucoup d’informations doivent être compressées dans un seul état à mesure que la phrase s’allonge. Même avec les LSTM, les signaux provenant de mots loin en amont peuvent s’estomper ou être écrasés.
Cela rendait certaines relations difficiles à apprendre de façon fiable — comme rattacher un pronom au nom correct situé plusieurs mots plus tôt, ou garder la trace d’un sujet sur plusieurs propositions.
Entraînement et défis de montée en échelle
Les RNN et LSTM sont aussi lents à entraîner car ils ne peuvent pas pleinement paralléliser dans le temps. On peut batcher sur différentes phrases, mais au sein d’une même phrase, l’étape 50 dépend de la 49, qui dépend de la 48, etc.
Cette computation pas à pas devient une vraie limitation quand on veut des modèles plus grands, plus de données et des itérations plus rapides.
La motivation pour une approche plus parallélisable
Les chercheurs avaient besoin d’un design capable de relier des mots entre eux sans marcher strictement de gauche à droite pendant l’entraînement — une façon de modéliser directement les relations longue distance et de mieux tirer parti du matériel moderne. Cette pression a préparé le terrain pour l’approche centrée sur l’attention introduite dans Attention Is All You Need.
L’attention, expliquée sans maths
L’attention est la manière dont le modèle se demande : "Quels autres mots dois‑je regarder maintenant pour comprendre ce mot ?"
Plutôt que de lire une phrase strictement de gauche à droite et d’espérer que la mémoire tienne, l’attention permet au modèle de regarder les parties les plus pertinentes de la phrase au moment où il en a besoin.
L’idée « rechercher et récupérer »
Un modèle mental utile est un petit moteur de recherche qui tourne à l’intérieur de la phrase.
- Query : ce que le mot courant recherche (la question)
- Keys : ce que chaque autre mot propose (les étiquettes sur les correspondances potentielles)
- Values : l’information réelle à extraire en cas de correspondance (le contenu)
Ainsi, le modèle forme une query pour la position courante, la compare aux keys de toutes les positions, puis récupère un mélange de values.
Scores de pertinence → poids d’attention
Ces comparaisons produisent des scores de pertinence : des signaux « à quel point c’est lié ? ». Le modèle les transforme ensuite en poids d’attention, qui sont des proportions sommant à 1.
Si un mot est très pertinent, il obtient une plus grande part de l’attention. Si plusieurs mots comptent, l’attention peut se répartir entre eux.
Un exemple simple (pronoms et grammaire)
Prenons : « Maria a dit à Jenna que elle téléphonerait plus tard. »
Pour interpréter elle, le modèle doit regarder en arrière les candidates comme « Maria » et « Jenna ». L’attention attribuera un poids plus élevé au nom qui convient le mieux au contexte.
Ou encore : « Les clés du placard sont manquantes. » L’attention aide à relier « sont » à « clés » (le vrai sujet), pas à « placard », même si « placard » est plus proche. C’est l’avantage principal : l’attention relie le sens à distance, à la demande.
Auto-attention : le mécanisme central
L’auto-attention signifie que chaque token d’une séquence peut regarder d’autres tokens de cette même séquence pour décider ce qui importe maintenant. Plutôt que de traiter les mots strictement de gauche à droite (comme les anciens modèles récurrents), le Transformer permet à chaque token de rassembler des indices n’importe où dans l’entrée.
Des tokens qui regardent des tokens
Imaginez la phrase : « J’ai versé l’eau dans la tasse parce que elle était vide. » Le mot « elle » devrait se connecter à « tasse », pas à « eau ». Avec l’auto-attention, le token correspondant à « elle » attribue plus d’importance aux tokens qui résolvent son sens (« tasse », « vide ») et moins aux tokens non pertinents.
Après l’auto-attention, chaque token n’est plus seulement lui‑même. Il devient une version adaptative au contexte — un mélange pondéré d’informations venant d’autres tokens. On peut penser que chaque token crée un résumé personnalisé de la phrase entière, ajusté à ses besoins.
Concrètement, la représentation de « tasse » peut porter des signaux venant de « versé », « eau » et « vide », tandis que « vide » peut intégrer ce qu’il décrit.
Pourquoi l’entraînement peut être parallèle
Parce que chaque token peut calculer son attention sur toute la séquence en même temps, l’entraînement n’a pas besoin d’attendre que les tokens précédents soient traités étape par étape. Ce parallélisme est une raison majeure pour laquelle les Transformers s’entraînent efficacement sur de grands jeux de données et montent bien en taille.
L’auto-attention facilite la connexion d’éléments éloignés du texte. Un token peut directement se concentrer sur un mot pertinent lointain — sans passer l’information à travers une longue chaîne d’étapes intermédiaires.
Ce chemin direct aide sur des tâches comme la coréférence, le suivi de sujets à travers des paragraphes et la gestion d’instructions dépendant d’éléments antérieurs.
Attention multi-têtes : plusieurs vues sur la même phrase
Passez du prototype à l'échelle
Passez d'une expérimentation rapide à une solution prête pour l'équipe grâce à des offres supérieures.
Un unique mécanisme d’attention est puissant, mais il peut ressembler à comprendre une conversation en ne regardant qu’un seul angle caméra. Les phrases contiennent souvent plusieurs relations simultanées : qui a fait quoi, à quoi se réfère « il/elle », quels mots définissent le ton, quel est le sujet général.
Pourquoi une seule vue ne suffit pas
Quand vous lisez « Le trophée n’est pas rentré dans la valise parce qu’elle était trop petite », il faut suivre plusieurs indices en même temps (grammaire, sens, contexte réel). Une tête d’attention peut se fixer sur le nom le plus proche ; une autre peut utiliser le verbe pour décider à quoi « elle » fait référence.
Ce que font les têtes multiples
L’attention multi-têtes exécute plusieurs calculs d’attention en parallèle. Chaque « tête » est encouragée à regarder la phrase sous un angle différent — souvent décrit comme des sous-espaces. En pratique, les têtes peuvent se spécialiser sur différents motifs, tels que :
- la syntaxe locale (ex. adjectif → nom)
- les liens longue portée (ex. sujet ↔ verbe à travers une proposition)
- la coréférence (ex. pronom → entité)
- les signaux thématiques (mots qui définissent le sujet ou le sentiment)
Après que chaque tête a produit ses propres insights, le modèle ne choisit pas une seule tête. Il concatène les sorties des têtes (les empilant côte à côte) puis les projette à nouveau dans l’espace de travail principal via une couche linéaire apprise.
Pensez-y comme la fusion de plusieurs notes partielles en un résumé propre que la couche suivante peut utiliser. Le résultat est une représentation capable de capturer de multiples relations à la fois — l’une des raisons de l’efficacité des Transformers à grande échelle.
Encodage positionnel : apprendre l’ordre des mots
L’auto-attention repère bien les relations — mais seule elle ne sait pas qui est venu avant. Si vous mélangez les mots d’une phrase, une couche d’auto-attention sans position pourrait traiter la version mélangée comme aussi valide, car elle compare des tokens sans notion d’ordre.
L’encodage positionnel résout cela en injectant l’information « quelle est ma position dans la séquence ? » dans les embeddings des tokens. Une fois la position attachée, l’attention peut apprendre des motifs comme « le mot juste après pas compte beaucoup » ou « le sujet apparaît généralement avant le verbe » sans inférer l’ordre depuis zéro.
L’idée centrale est simple : chaque embedding de token est combiné avec un signal de position avant d’entrer dans le bloc Transformer. Ce signal de position peut être vu comme un ensemble de caractéristiques supplémentaires qui taguent un token comme 1er, 2e, 3e… de l’entrée.
Parmi les approches courantes :
- Positions absolues (fixes) : les Transformers classiques utilisaient des motifs sinusoïdaux déterministes. Ils n’ajoutent pas de nouveaux paramètres et peuvent généraliser à des longueurs au-delà de l’entraînement (jusqu’à un certain point).
- Positions absolues apprises : le modèle apprend un vecteur pour « position 1 », « position 2 », etc. Cela fonctionne très bien, mais lie souvent le modèle à une fenêtre de contexte maximale vue à l’entraînement.
- Positions relatives : plutôt que d’encoder « ceci est le token 57 », le modèle se concentre sur des distances comme « ce token est 3 positions avant tel autre ». Les variantes modernes (y compris les méthodes rotary) entrent souvent dans cette famille.
Pourquoi c’est important pour les tâches longue-contexte
Les choix positionnels peuvent affecter de façon notable la modélisation de longs contextes — résumer un long rapport, suivre des entités sur plusieurs paragraphes, ou retrouver un détail mentionné des milliers de tokens plus tôt.
Avec de longues entrées, le modèle n’apprend pas seulement la langue ; il apprend où regarder. Les schémas relatifs et rotary facilitent souvent la comparaison de tokens éloignés et préservent des motifs à mesure que le contexte grandit, tandis que certains schémas absolus peuvent se dégrader plus vite quand on dépasse la fenêtre d’entraînement.
En pratique, l’encodage positionnel est une décision de conception discrète qui peut déterminer si un LLM reste précis à 2 000 tokens — et toujours cohérent à 100 000.
Déployez tout en itérant
Déployez et hébergez votre application tout en itérant sur les prompts et l'évaluation.
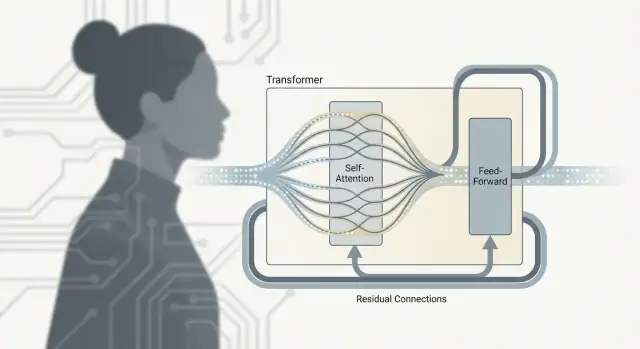
Un Transformer n’est pas juste « attention ». Le vrai travail se passe dans une unité répétée — souvent appelée bloc Transformer — qui mélange l’information entre tokens puis la raffine. Empilez beaucoup de ces blocs et vous obtenez la profondeur qui rend les LLM si capables.
Après l’attention : ce que fait le FFN/MLP
L’auto-attention est l’étape de communication : chaque token rassemble du contexte d’autres tokens.
Le réseau feed-forward (FFN), aussi appelé MLP, est l’étape de traitement : il prend la représentation mise à jour de chaque token et applique le même petit réseau neuronal de façon indépendante.
En termes simples, le FFN transforme et réorganise ce que chaque token sait maintenant, aidant le modèle à construire des caractéristiques plus riches (patterns syntaxiques, faits, indices de style) après avoir collecté le contexte pertinent.
Pourquoi les blocs alternent attention et FFN
L’alternance importe parce que les deux parties font des tâches différentes :
- l’attention déplace l’information entre tokens (qui influence qui)
- le FFN traite l’information à l’intérieur de chaque token (comment convertir ce contexte en caractéristiques utiles)
Répéter ce schéma permet au modèle de construire progressivement des significations de plus haut niveau : communiquer, calculer, communiquer à nouveau, calculer de nouveau.
Connexions résiduelles : les "voies de contournement"
Chaque sous-couche (attention ou FFN) est entourée d’une connexion résiduelle : l’entrée est ajoutée à la sortie. Cela aide les modèles profonds à s’entraîner parce que les gradients peuvent circuler par la « voie de contournement » même si une couche particulière apprend encore. Cela permet aussi à une couche d’effectuer de petits ajustements au lieu de tout réapprendre.
Normalisation de couche : garder les signaux stables
La normalisation de couche est un stabilisateur qui empêche les activations de dériver trop haut ou trop bas à travers de nombreuses couches. Pensez-y comme à un réglage du volume qui maintient un niveau cohérent pour que les couches suivantes ne soient ni saturées ni sous-alimentées — rendant l’entraînement plus fluide et fiable, surtout à l’échelle des LLM.
Encodeur–Décodeur vs Decoder‑Only : lequel alimente les LLM ?
Le Transformer original dans Attention Is All You Need a été conçu pour la traduction, où l’on convertit une séquence (français) en une autre (anglais). Cette tâche se sépare naturellement en deux rôles : lire l’entrée correctement, puis écrire la sortie fluidement.
Encodeur–Décodeur : « Lire, puis Écrire »
Dans un Transformer encodeur–décodeur, l’encodeur traite l’intégralité de la phrase d’entrée et produit un ensemble riche de représentations. Le décodeur génère ensuite la sortie un token à la fois.
Crucialement, le décodeur n’utilise pas seulement ses propres tokens passés. Il a aussi de la cross-attention vers la sortie de l’encodeur, ce qui l’aide à rester ancré dans le texte source.
Cette configuration reste excellente lorsqu’il faut fortement conditionner la production sur une entrée — traduction, résumé ou question-réponse avec un passage donné.
Decoder‑Only : un modèle qui prédit continuellement
La plupart des LLM modernes sont decoder-only. Ils sont entraînés sur une tâche simple et puissante : prédire le token suivant.
Pour cela, ils utilisent l’auto-attention masquée (causale). Chaque position peut seulement s’attacher aux tokens antérieurs, pas aux futurs, de sorte que la génération reste cohérente : le modèle écrit de gauche à droite en étendant la séquence.
C’est dominant pour les LLM car c’est simple à entraîner sur d’énormes corpus de texte, cela correspond directement au cas d’usage de génération et ça se met bien à l’échelle en données et calcul.
Où se placent les modèles encodeur-only
Les modèles encodeur-only (à la BERT) ne génèrent pas de texte ; ils lisent l’entrée bidirectionnellement. Ils excellent pour la classification, la recherche et la production d’embeddings — tout ce qui nécessite de bien comprendre un texte plutôt que de produire une longue continuation.
Les Transformers se sont révélés particulièrement adaptés à la mise à l’échelle : si vous leur donnez plus de texte, plus de calcul et des modèles plus grands, ils continuent souvent de s’améliorer de façon prévisible.
Une grande raison est la simplicité structurelle. Un Transformer est construit à partir de blocs répétés (auto-attention + petit réseau feed-forward, plus normalisation), et ces blocs se comportent de façon similaire que l’on entraîne sur un million ou un trillion de mots.
L’entraînement parallèle, le super‑pouvoir caché
Les anciens modèles séquentiels (comme les RNN) devaient traiter les tokens un par un, ce qui limite le travail parallèle. Les Transformers, en revanche, peuvent traiter tous les tokens d’une séquence en parallèle pendant l’entraînement.
Cela les rend parfaitement adaptés aux GPU/TPU et aux architectures distribuées — exactement ce qu’il faut pour entraîner les LLM modernes.
La "fenêtre de contexte" et pourquoi elle compte
La fenêtre de contexte est le morceau de texte que le modèle peut « voir » à un instant donné — votre prompt plus l’historique de conversation ou le texte récent. Une fenêtre plus grande permet au modèle de connecter des idées sur davantage de phrases ou de pages, de garder des contraintes en mémoire et de répondre à des questions dépendant d’éléments antérieurs.
Mais le contexte n’est pas gratuit.
La contrainte clé : le coût de l’attention croît avec la longueur
L’auto-attention compare les tokens entre eux. À mesure que la séquence s’allonge, le nombre de comparaisons augmente rapidement (environ selon le carré de la longueur). C’est pourquoi les très longues fenêtres de contexte peuvent être coûteuses en mémoire et en calcul, et pourquoi beaucoup d’efforts se concentrent sur des attentions plus efficaces.
La mise à l’échelle a débloqué un comportement généraliste
Quand on entraîne des Transformers à grande échelle, ils ne s’améliorent pas seulement sur une tâche étroite. Ils commencent souvent à montrer des capacités larges et flexibles — résumer, traduire, écrire, coder et raisonner — parce que la même machinerie d’apprentissage générale est appliquée sur des données massives et variées.
Variantes modernes bâties sur le même blueprint
Itérations plus sûres avec rollback
Expérimentez librement et restaurez des instantanés en cas de régression.
Le design Transformer original reste le point de référence, mais la plupart des LLM en production sont des « Transformers plus » : de petites modifications pratiques qui conservent le bloc central (attention + MLP) tout en améliorant la vitesse, la stabilité ou la longueur de contexte.
Améliorations courantes que vous verrez
Beaucoup d’améliorations visent moins à changer ce qu’est le modèle qu’à en améliorer l’entraînement et l’exécution :
- Meilleures méthodes positionnelles : des alternatives aux positions sinusoïdales classiques (souvent rotary ou relatives) qui facilitent le traitement longue‑distance.
- Optimisations d’attention : implémentations réduisant la mémoire et augmentant le débit (par ex. noyaux fusionnés ou calculs d’attention plus efficaces).
- Ajustements de normalisation : variations sur où et comment appliquer la normalisation pour améliorer la stabilité et réduire la sensibilité aux hyperparamètres.
Ces changements n’altèrent généralement pas la "Transformer‑ité" fondamentale du modèle — ils la raffinent.
Approches pour le long‑contexte (haut niveau)
Étendre le contexte de quelques milliers de tokens à dizaines ou centaines de milliers s’appuie souvent sur l’attention éparse (n’attacher qu’à des tokens sélectionnés) ou des variantes efficaces d’attention (approximer ou restructurer l’attention pour réduire le calcul).
Le compromis se situe généralement entre précision, mémoire et complexité d’ingénierie.
Mixture-of-Experts (MoE) : plus de capacité sans coût linéaire
Les modèles MoE ajoutent plusieurs sous‑réseaux « experts » et routent chaque token vers un sous‑ensemble seulement. Conceptuellement : on obtient un cerveau plus grand sans activer tout le réseau à chaque fois.
Cela peut baisser le coût par token pour un nombre de paramètres donné, mais augmente la complexité système (routage, équilibrage des experts, serving).
Quand un modèle met en avant une nouvelle variante Transformer, demandez :
- Des benchmarks pertinents pour vos tâches (pas seulement des scores généraux)
- La latence (temps jusqu’au premier token et tokens/sec)
- Le coût (entraînement et inférence), incluant mémoire et besoins hardware
La plupart des améliorations sont réelles — mais rarement gratuites.
Ce que cela signifie pour les équipes qui bâtissent avec des LLM
Les idées du Transformer comme l’auto-attention et la mise à l’échelle sont fascinantes — mais pour les équipes produit, elles se ressentent surtout comme des compromis : combien de texte vous pouvez fournir, à quelle vitesse vous obtenez une réponse et quel est le coût par requête.
Choisir un modèle ou un fournisseur : quatre compromis
Longueur de contexte : Une plus grande fenêtre permet d’inclure davantage de documents, d’historique et d’instructions. Elle augmente aussi la consommation de tokens et peut ralentir les réponses. Si votre fonctionnalité repose sur « lire ces 30 pages et répondre », priorisez la longueur de contexte.
Latence : Les expériences de chat et de copilote côté utilisateur tiennent par la latence. La diffusion (streaming) aide, mais le choix du modèle, la région et le batching comptent aussi.
Coût : La tarification se fait souvent par token (entrée + sortie). Un modèle 10 % « meilleur » peut coûter 2–5× plus. Faites des comparaisons de type prix/qualité pour décider du niveau de qualité qui vaut le coup.
Qualité : Définissez‑la pour votre cas d’usage : exactitude factuelle, suivi d’instructions, ton, utilisation d’outils ou génération de code. Évaluez avec des exemples réels de votre domaine, pas seulement des benchmarks génériques.
Quand les embeddings surpassent la génération
Si vous avez surtout besoin de recherche, déduplication, clustering, recommandations ou « trouver similaire », les embeddings (souvent via des modèles encodeur) sont généralement moins chers, plus rapides et plus stables que d’interroger un modèle de génération. Utilisez la génération uniquement pour l’étape finale (résumés, explications, brouillons) après récupération.
Pour une analyse plus approfondie, orientez votre équipe vers un explicatif technique comme /blog/embeddings-vs-generation.
Où cela apparaît dans des workflows de mise en production
Quand vous transformez des capacités Transformer en produit, la difficulté se situe souvent moins dans l’architecture que dans le workflow autour : itération sur les prompts, ancrage (grounding), évaluation et déploiement sécurisé.
Une voie pratique consiste à utiliser une plateforme de type « vibe-coding » comme Koder.ai pour prototyper et livrer des fonctionnalités alimentées par LLM plus rapidement : vous pouvez décrire l’app web, les endpoints back-end et le modèle de données en chat, itérer en mode planification, puis exporter le code source ou déployer avec hébergement, domaines personnalisés et rollback via snapshots. C’est particulièrement utile quand vous expérimentez la récupération, les embeddings ou les boucles d’appel d’outils et que vous voulez itérer vite sans reconstruire la même ossature à chaque fois.
Checklist pratique d’adoption
- Rédigez une spécification d’une page : objectif utilisateur, modes d’échec et ce qu’est un résultat "bon".
- Décidez ce qui doit être ancré dans vos données (RAG, citations ou appels d’outils).
- Fixez des budgets pour tokens, latence et dépense mensuelle ; mesurez‑les en staging.
- Ajoutez des garde‑fous : refus, redaction et comportements « je ne sais pas ».
- Construisez l’évaluation tôt : prompts gold, tests de régression et revue humaine.
- Prévoyez des swaps de modèle : gardez prompts et routage configurables.