Pourquoi les défaillances en production sont difficiles à détecter tôt
La production ne « casse » rarement en un instant dramatique. Le plus souvent elle se dégrade doucement : quelques requêtes commencent à expirer, un job en arrière-plan prend du retard, le CPU grimpe, et ce sont les clients qui s'en aperçoivent en premier — parce que vos outils de monitoring affichent encore « vert ».
Les échecs se manifestent comme des symptômes, pas comme des causes
Le signal utilisateur est généralement vague : « C'est lent. » C'est un symptôme partagé par des dizaines de causes racines — contention de verrous en base, un nouveau plan d'exécution, un index manquant, un « noisy neighbor », une tempête de retries, ou une dépendance externe qui plante de façon intermittente.
Sans bonne visibilité, les équipes finissent par deviner :
- Le ralentissement est-il global ou limité à un endpoint ?
- Est-il apparu après un déploiement, un changement de config ou un pic de trafic ?
- Le problème vient-il de l'application, de la base ou du réseau entre les deux ?
Vos tableaux de bord ne voient pas ce que ressentent les utilisateurs
Nombre d'équipes suivent des moyennes (latence moyenne, CPU moyen). Les moyennes cachent la douleur. Un petit pourcentage de requêtes très lentes peut détruire l'expérience alors que les métriques globales semblent correctes. Et si vous ne surveillez que le « up/down », vous manquerez la longue période où le système est techniquement disponible mais pratiquement inutilisable.
Observabilité + journaux des requêtes lentes : signaux complémentaires
L'observabilité vous aide à détecter et réduire où le système se dégrade (quel service, endpoint ou dépendance). Les journaux des requêtes lentes vous aident à prouver quoi la base faisait quand les requêtes piétinaient (quelle requête, combien de temps, et souvent quel type de travail elle a effectué).
Ce guide reste pragmatique : comment obtenir des alertes plus tôt, relier la latence côté utilisateur à un travail précis en base, et corriger en toute sécurité — sans dépendre d'engagements spécifiques à un fournisseur.
Bases de l'observabilité : métriques, logs et traces
L'observabilité signifie pouvoir comprendre ce que fait votre système en regardant les signaux qu'il produit — sans devoir deviner ou « reproduire en local ». C'est la différence entre savoir que les utilisateurs subissent de la latence et pouvoir identifier où elle se produit et pourquoi elle a commencé.
Les trois piliers (et à quoi chacun sert)
Métriques : des nombres dans le temps (%, débit de requêtes, taux d'erreur, latence DB). Elles sont rapides à interroger et parfaites pour repérer des tendances et des pics soudains.
Logs : des enregistrements d'événements avec détails (message d'erreur, texte SQL, ID utilisateur, timeout). Ils sont meilleurs pour expliquer ce qui s'est passé de façon lisible.
Traces : suivent une requête unique qui traverse services et dépendances (API → app → DB → cache). Elles sont idéales pour répondre où le temps a été passé et quelle étape a causé le ralentissement.
Un modèle mental utile : les métriques disent quelque chose ne va pas, les traces montrent où, et les logs disent quoi exactement.
Les questions auxquelles une bonne observabilité doit répondre
Une configuration saine vous aide à répondre clairement lors d'incidents :
- Qu'est-ce qui a cassé ? (erreurs, timeouts, saturation)
- Où ? (quel endpoint, service, dépendance ou requête)
- Pourquoi maintenant ? (un déploiement, un changement de trafic, un flag, croissance des données)
Monitoring vs observabilité (confusion fréquente)
Le monitoring porte souvent sur des checks prédéfinis et des alertes (« CPU > 90% »). L'observabilité va plus loin : elle vous permet d'investiguer de nouveaux modes de défaillance inattendus en découpant et corrélant les signaux (par exemple, voir qu'un seul segment de clients subit des checkouts lents liés à un appel DB précis).
Cette capacité à poser de nouvelles questions pendant un incident transforme la télémétrie brute en dépannage plus rapide et plus serein.
Ce que sont les journaux des requêtes lentes et ce qu'ils révèlent
Un journal des requêtes lentes est un enregistrement ciblé des opérations de base de données qui ont dépassé un seuil de « lenteur ». Contrairement à la journalisation générale des requêtes (qui peut être écrasante), il met en avant les instructions les plus susceptibles d'entraîner une latence visible par l'utilisateur et des incidents en production.
Ce qu'un journal de requêtes lentes enregistre typiquement
La plupart des bases peuvent capturer un noyau de champs similaires :
- La requête (souvent le SQL normalisé)
- Durée (temps total, parfois avec répartition)
- Horodatages (début et fin)
- Contexte comme base/utilisateur, hôte, nom de l'application, lignes examinées/retournées, et parfois le plan de requête ou un hash de plan
Ce contexte transforme un simple « cette requête était lente » en « cette requête était lente pour ce service, depuis ce pool de connexions, à cet instant précis », ce qui est crucial quand plusieurs apps partagent la même base.
Pourquoi des requêtes deviennent lentes
Les journaux des requêtes lentes ne signifient pas souvent « mauvais SQL » isolément. Ce sont des signaux que la base a dû faire un travail supplémentaire ou s'est retrouvée à attendre. Causes courantes :
- Index manquants ou inefficaces, forçant des scans complets ou des jointures coûteuses
- Mauvais plans d'exécution (souvent déclenchés par des valeurs de paramètres, des statistiques obsolètes ou le cache de plans)
- Attentes de verrous et contention, où la requête est rapide quand elle s'exécute mais lente quand elle attend
- Pics de charge, où une requête normalement acceptable devient lente sous forte concurrence ou pression I/O
Un modèle mental utile : les journaux des requêtes lentes capturent à la fois le travail (requêtes lourdes CPU/I/O) et l'attente (verrous, ressources saturées).
Définir « lent » : seuils et percentiles
Un seuil unique (par exemple « journaliser tout au-dessus de 500ms ») est simple, mais peut manquer des douleurs lorsque la latence typique est beaucoup plus basse. Envisagez de combiner :
- Un seuil fixe pour attraper les vrais outliers
- Une vue basée sur les percentiles (p95/p99) dans votre monitoring pour remarquer les régressions même si les temps absolus semblent « acceptables »
Cela garde le journal de requêtes lentes actionnable pendant que vos métriques font remonter les tendances.
Remarque confidentialité : éviter de journaliser des valeurs sensibles
Les journaux des requêtes lentes peuvent capturer accidentellement des données personnelles si les paramètres sont inline (emails, tokens, IDs). Privilégiez les requêtes paramétrées et des réglages qui enregistrent la forme de la requête plutôt que les valeurs brutes. Quand on ne peut pas l'éviter, ajoutez un masquage/redaction dans le pipeline de logs avant le stockage ou le partage lors de la réponse à un incident.
Une requête lente reste rarement « juste lente ». La chaîne type est : latence utilisateur → latence API → pression sur la base → timeouts. L'utilisateur le ressent d'abord comme des pages qui bloquent ou des écrans mobiles qui tournent. Peu après, vos métriques API montrent une latence élevée, même si le code applicatif n'a pas changé.
Pourquoi la douleur DB ressemble à un problème d'app
Vu de l'extérieur, une base lente apparaît souvent comme « l'app est lente » parce que le thread API est bloqué en attendant la requête. Le CPU et la mémoire des serveurs applicatifs peuvent sembler normaux, pourtant la p95/p99 augmente. Si vous ne regardez que les métriques app, vous pouvez chercher le mauvais coupable — handlers HTTP, caches ou déploiements — alors que le goulot réel est un plan de requête qui a régressé.
Quand une requête traîne, les mécanismes de mitigation peuvent amplifier la défaillance :
- Retries des clients ou services multiplient le trafic, augmentant la charge DB.
- Épuisement du pool de connexions survient quand les requêtes tiennent les connexions plus longtemps, forçant les nouvelles requêtes à attendre.
- Accumulation de files se forme chez les workers et consommateurs de messages quand le débit chute.
- Timeouts déclenchent des échecs partiels, qui entraînent plus de retries et du travail dupliqué.
Un scénario simple
Imaginez un endpoint checkout qui exécute SELECT ... FROM orders WHERE user_id = ? ORDER BY created_at DESC LIMIT 1. Après une croissance de volume, l'index n'aide plus suffisamment et le temps passe de 20ms à 800ms. En trafic normal, c'est gênant. En pic, les requêtes API s'empilent en attente de connexions DB, expirent à 2s, et les clients réessaient. En quelques minutes, une « petite » requête lente devient des erreurs visibles par les utilisateurs et un incident complet en production.
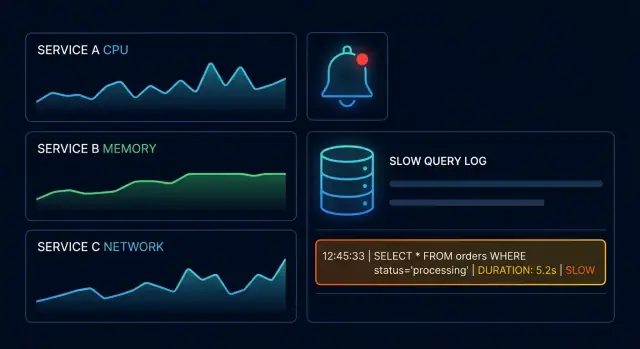
Les métriques qui pointent rapidement vers une souffrance DB
Quand une base commence à souffrir, les premiers indices apparaissent généralement dans un petit ensemble de métriques. Le but n'est pas de tout suivre — c'est de repérer un changement vite, puis de réduire l'enquête.
Commencez par les signaux d'or
Ces quatre signaux vous aident à déterminer si vous avez un problème DB, applicatif ou mixte :
- Latence : une hausse du p95/p99 des requêtes est souvent le premier symptôme visible client.
- Trafic : un pic peut être la cause (plus de charge) ou la conséquence (retries).
- Erreurs : surveillez timeouts, 5xx et codes d'erreur DB.
- Saturation : une DB peut être « up » mais saturée — CPU, I/O, slots de connexion ou contention de verrous.
Métriques DB essentielles à surveiller
Quelques graphiques DB spécifiques peuvent vous dire si le goulot est l'exécution de requêtes, la concurrence ou le stockage :
- Distribution de latence des requêtes (pas seulement la moyenne) : cherchez une queue plus lourde (p95/p99) et une variance croissante.
- Connexions et utilisation des pools : hausse des connexions actives, mise en queue dans le pool, ou épuisement fréquent du pool.
- Verrous et temps d'attente : durée d'attente de verrous et deadlocks ; souvent corrélés à des sauts soudains de latence.
- Taux de hit du cache / efficacité du buffer : une chute peut signifier que votre working set ne tient plus en mémoire, entraînant plus de lectures disque.
Métriques côté service qui impliquent la DB
Associez les métriques DB à l'expérience du service :
- Taux de requêtes et timeouts (y compris timeouts en amont).
- p95/p99 de latence par endpoint : un seul endpoint qui se dégrade peut indiquer un motif de requête.
- Taux de retries : les retries peuvent amplifier la charge et masquer le déclencheur initial.
Tableaux de bord qui répondent aux bonnes questions
Concevez des dashboards pour répondre rapidement :
- Est-ce nouveau ? Comparez à la même heure hier/semaine dernière.
- Est-ce isolé ? Un seul endpoint, un tenant, un nœud, une AZ ?
- Est-ce en croissance ? La saturation augmente-t-elle et des files se forment-elles ?
Quand ces métriques s'alignent — latence tail en hausse, timeouts croissants, saturation qui monte — vous avez un signal fort pour basculer vers les journaux des requêtes lentes et le traçage afin d'identifier l'opération exacte.
Tracer le chemin de la requête jusqu'à l'opération lente exacte
Construisez pour des améliorations continues
Allez au-delà des expérimentations et continuez d'itérer sur les corrections de performance avec une offre payante.
Les journaux des requêtes lentes disent quoi était lent en base. Le traçage distribué dit qui l'a demandé, d'où, et pourquoi ça comptait.
Suivez la requête, pas l'intuition
Avec le traçage en place, une alerte « la base est lente » devient une histoire concrète : un endpoint ou un job précis a déclenché une séquence d'appels, dont l'un a passé la majorité du temps à attendre une opération DB.
Dans votre UI APM, partez d'une trace à haute latence et cherchez :
- La route ou le nom du job qui a initié la requête (ex.
GET /checkout ou billing_reconcile_worker).
- Un span DB avec une durée anormalement élevée ou un time-to-first-row long.
- Si la lenteur est isolée à un type de requête ou répartie sur beaucoup de types.
Étiquetez les spans en sécurité (sans fuir du SQL)
Le SQL complet dans les traces peut être risqué (PII, secrets, charges importantes). Une approche pratique consiste à tagger les spans avec un nom d'opération / requête plutôt que l'instruction complète :
db.operation=SELECT et db.table=ordersapp.query_name=orders_by_customer_v2feature_flag=checkout_upsell
Cela rend les traces interrogeables et sûres tout en pointant vers le chemin de code.
Corrélez tout avec des IDs
Le moyen le plus rapide de relier « trace » → « logs app » → « entrée du journal des requêtes lentes » est un identifiant partagé :
- Propagez un trace ID dans les logs applicatifs.
- Si possible, ajoutez le trace ID (ou request ID) au contexte du journal des requêtes lentes (ou en commentaire dans la requête quand c'est sûr et supporté).
Vous pouvez alors répondre vite aux questions à forte valeur :
- Quelle route ou quel worker déclenche l'appel lent ?
- Est-ce lié à un tenant/client spécifique, une région ou un plan ?
- A-t-il commencé après un release ou un changement de config ?
- Est-ce une seule requête couteuse, ou une rafale de petites requêtes (N+1) ?
Mettre en place la journalisation des requêtes lentes sans être submergé
Les journaux des requêtes lentes ne sont utiles que s'ils restent lisibles et actionnables. L'objectif n'est pas de « tout logger pour toujours » — c'est de capturer assez de détails pour expliquer pourquoi les requêtes sont lentes, sans ajouter d'overhead notable ni créer un coût prohibitif.
Choisissez des seuils qui correspondent à l'expérience de l'app
Commencez par un seuil absolu qui reflète les attentes utilisateurs et le rôle de la DB dans la requête.
- Exemples absolus :
>200ms pour des applis OLTP, >500ms pour des workloads mixtes
Puis ajoutez une vue relative pour continuer à voir les problèmes quand tout ralentit (et moins de requêtes franchissent la ligne dure).
- Exemples relatifs : « top 100 les plus lents par minute » ou « top 1% des statements les plus lents »
Utiliser les deux évite les angles morts : les seuils absolus attrapent les requêtes « toujours mauvaises », les seuils relatifs détectent les régressions pendant les périodes chargées.
Échantillonnez intelligemment et capturez le contexte utile
Logger chaque statement lent au pic de trafic peut nuire à la perf et générer du bruit. Préférez le sampling (par ex. logger 10–20% des événements lents) et augmentez l'échantillonnage temporairement pendant un incident.
Assurez-vous que chaque événement contient le contexte actionnable : durée, lignes examinées/retournées, base/utilisateur, nom d'application, et idéalement un request ID ou trace ID si disponible.
Normalisez les requêtes pour faire ressortir les motifs
Les chaînes SQL brutes sont salissantes : différents IDs et timestamps font paraître identiques des requêtes comme uniques. Utilisez la fingerprint (normalisation) pour grouper des instructions similaires, ex. WHERE user_id = ?.
Ainsi vous pouvez répondre : « Quelle forme de requête cause le plus de latence ? » plutôt que de courir après des exemples isolés.
Conservation des plans autour des incidents (et coût)
Conservez les journaux détaillés des requêtes lentes assez longtemps pour comparer « avant vs après » lors d'investigations — souvent 7–30 jours est un point de départ pratique.
Si le stockage est un souci, sous-échantillonnez les données plus anciennes (conservez des agrégats et les empreintes principales) tout en gardant les logs en haute fidélité pour la fenêtre la plus récente.
Alertes qui détectent les ralentissements avant que les clients ne s'en aperçoivent
Examinez les performances ensemble
Mettez votre appli sur un domaine personnalisé et partagez un environnement réaliste avec votre équipe.
Les alertes doivent signaler « les utilisateurs sont sur le point de ressentir ça » et indiquer où regarder en priorité. La façon la plus simple est d'alerter sur les symptômes (ce que vit l'utilisateur) et les causes (ce qui le provoque), avec des contrôles de bruit pour que l'on-call n'apprenne pas à ignorer les pages.
Alerter sur les symptômes (impact utilisateur)
Commencez par un petit ensemble d'indicateurs à fort signal qui corrèlent à la douleur client :
- Hausse du p95/p99 des latences pour les endpoints clés (pas seulement les moyennes)
- Taux de timeouts (app et upstream) et taux de retries
- Profondeur des files / saturation des workers (thread pools, pools de connexions)
- Attentes de verrous et transactions bloquées (précurseur commun d'un ralentissement généralisé)
Si possible, scopez les alertes aux « chemins d'or » (checkout, login, recherche) pour ne pas pager sur des routes à faible importance.
Alerter sur les causes (pour démarrer l'enquête)
Associez aux alertes de symptômes des alertes orientées cause pour raccourcir le diagnostic :
- Empreintes de requêtes lentes dépassant un seuil (ex. p95 ou temps total)
- Changements de plan (augmentation soudaine des lignes examinées, nouveaux scans de table, index non utilisés)
- Pics d'erreurs au niveau DB (deadlocks, trop de connexions, annulations de requêtes)
Ces alertes de cause devraient idéalement inclure l'empreinte de la requête, des exemples de paramètres (sanitisés) et un lien direct vers le dashboard ou la vue de trace pertinente.
Réduire le bruit sans manquer les vrais incidents
Utilisez :
- Alertes burn-rate sur les SLO (page rapide pour régressions rapides, page lente pour dégradations soutenues)
- Vérifications multi-fenêtres (ex. 5m et 30m) pour éviter le flapping
- Déduplication et grouping (un incident par service/DB + empreinte)
Chaque page doit inclure « que faire ensuite ? » — liez un runbook comme /blog/incident-runbooks et spécifiez les trois premières vérifications (panel latence, liste des requêtes lentes, graphiques verrous/connexions).
Un workflow d'incident pragmatique : du pic à la cause racine
Quand la latence monte, la différence entre une récupération rapide et une longue panne tient à un workflow répétable. L'objectif est de passer de « quelque chose est lent » à une requête, un endpoint et un changement spécifiques.
1) Détecter → confirmer que c'est réel
Commencez par le symptôme utilisateur : hausse de la latence des requêtes, timeouts ou taux d'erreur.
Confirmez avec un petit ensemble d'indicateurs à fort signal : p95/p99, débit et santé DB (CPU, connexions, files/attentes). Évitez de chasser une anomalie sur un seul hôte — cherchez un motif à l'échelle du service.
2) Cibler → qui et quoi est affecté
Réduisez le rayon d'impact :
- Quels endpoints sont lents (routes avec p95 les plus élevées) ?
- Est-ce tous les clients ou un sous-ensemble (tenant, région, plan) ?
- Cela a-t-il commencé à une frontière temporelle claire (déploiement, job batch, changement de trafic) ?
Cette étape évite d'optimiser la mauvaise cible.
3) Isoler → utilisez les traces pour trouver l'opération lente
Ouvrez les traces distribuées pour les endpoints lents et triez par durée.
Cherchez le span qui domine la requête : un appel DB, une attente de verrou, ou des requêtes répétées (comportement N+1). Corrélez les traces avec des tags de contexte comme la version, l'ID du tenant et le nom du endpoint pour voir si la lenteur coïncide avec un déploiement ou une charge cliente particulière.
4) Confirmer → relier les traces aux journaux des requêtes lentes
Validez maintenant la requête suspectée dans les journaux des requêtes lentes.
Concentrez-vous sur les « fingerprints » (requêtes normalisées) pour trouver les plus coûteuses par temps total et par count. Notez les tables et prédicats concernés (filtres, jointures). C'est souvent ici que vous découvrez un index manquant, une nouvelle jointure ou un changement de plan.
5) Atténuer → réduire l'impact utilisateur en sécurité
Choisissez la mitigation la moins risquée en premier : rollback du release, désactiver le feature flag, réduire la charge, ou augmenter les limites de pool de connexions seulement si vous êtes sûr que cela n'amplifiera pas la contention. Si vous devez changer la requête, gardez la modification petite et mesurable.
Astuce pratique : si votre pipeline de livraison le permet, traitez le « rollback » comme un bouton premier choix, pas comme une manœuvre héroïque. Des plateformes comme Koder.ai exploitent cela avec des snapshots et des workflows de rollback, ce qui réduit le temps de mitigation quand un release introduit accidentellement un motif de requête lent.
6) Documenter → raccourcir le prochain incident
Capturez : ce qui a changé, comment vous l'avez détecté, l'empreinte exacte, endpoints/tenants impactés, et ce qui a réparé. Transformez cela en suivi : ajouter une alerte, un panneau de dashboard, et un garde-fou de performance (par ex. « aucune empreinte > X ms au p95 »).
Corriger les requêtes lentes en production en toute sécurité
Quand une requête lente nuit déjà aux utilisateurs, l'objectif est de réduire l'impact d'abord, puis d'améliorer la performance — sans empirer l'incident. Les données d'observabilité (échantillons de requêtes lentes, traces et métriques DB clés) vous indiquent quel levier est le plus sûr à actionner.
1) Stabiliser avec des mitigations à faible risque
Commencez par des changements qui réduisent la charge sans altérer le comportement des données :
- Feature flags : désactivez temporairement les endpoints chers, rapports, filtres de recherche ou panneaux « activité récente » qui déclenchent des requêtes lourdes.
- Rate limits / quotas : bridez la route ou le segment client indiqué par les traces.
- Caching : ajoutez un cache de courte durée pour les endpoints en lecture (même 30–120s peut réduire dramatiquement la charge DB). Préférez le cache au niveau requête ou application avant de toucher la base.
- Désactiver des chemins coûteux : retirez des JOINs optionnels, le tri « order by relevance » ou la pagination profonde derrière un flag.
Ces mitigations achètent du temps et doivent montrer une amélioration immédiate sur la p95 et les métriques CPU/IO de la DB.
2) Correctifs DB : ciblés et testables
Une fois stabilisé, corrigez le motif de requête réel :
- Ajouter un index qui correspond au filtre + tri de la requête. Validez avec
EXPLAIN et confirmez la réduction des lignes scannées.
- Réécrire la requête pour limiter les données scannées (sélectionner moins de colonnes, éviter
SELECT *, ajouter des prédicats sélectifs, remplacer des sous-requêtes corrélées).
- Réduire les patterns N+1 en batchant les IDs, ajoutant des préfetches, ou en utilisant une seule requête avec des JOINs choisis.
Appliquez les changements progressivement et confirmez les améliorations en utilisant le même span/empreinte de requête lente.
3) Mitigations opérationnelles quand le code n'est pas immédiat
- Augmenter la capacité (réplicas de lecture, plus grosse instance) pour arrêter l'hémorragie.
- Ajuster les pools de connexions pour éviter la mise en file et l'épuisement des threads.
- Ajuster les timeouts pour que le système échoue vite plutôt que d'accumuler des requêtes bloquées.
Rollback : revert vs hotfix
Rollback quand le changement augmente les erreurs, la contention de verrous ou provoque des déplacements de charge imprévisibles. Hotfix quand vous pouvez isoler la modification (une requête, un endpoint) et que vous avez une télémétrie claire avant/après pour valider une amélioration sûre.
Concevez d'abord le parcours des requêtes
Cartographiez routes, workers et appels à la base de données en mode Planification avant de générer le code.
Après avoir corrigé une requête lente en production, la vraie victoire est d'empêcher que le même motif revienne sous une autre forme. Là où des SLOs clairs et quelques garde-fous légers transforment un incident unique en fiabilité durable.
Lier les SLOs à ce que ressentent les utilisateurs
Commencez par des SLIs qui se mappent directement à l'expérience client :
- Latence p95 (et p99) des endpoints, segmentée par routes clés et tenants
- Taux d'erreur (timeouts, 5xx et « erreurs douces » comme résultats vides causés par annulations)
- Signaux de saturation qui corrèlent aux ralentissements (CPU DB, temps d'attente pool)
Fixez un SLO qui reflète une performance acceptable, pas parfaite. Ex. : « p95 checkout < 600ms pour 99.9% des minutes ». Quand le SLO est menacé, vous avez une raison objective de geler les déploiements risqués et de vous concentrer sur la perf.
Suivre les régressions par release, pas à vue
La plupart des incidents répétés sont des régressions. Facilitez leur détection en comparant avant/après pour chaque release :
- Comparez les traces pour un même endpoint et cherchez un nouveau span dominant.
- Comparez les empreintes de requêtes lentes pour détecter une nouvelle forme de requête, un index manquant ou une hausse soudaine des lignes scannées.
L'important est d'examiner la distribution (p95/p99), pas seulement les moyennes.
Choisissez un petit ensemble d'endpoints qui « ne doivent pas ralentir » et leurs requêtes critiques. Ajoutez des vérifications de performance dans la CI qui échouent lorsque la latence ou le coût de requête dépasse un seuil (même un simple baseline + dérive autorisée). Cela attrape les bugs N+1, les scans de table accidentels et la pagination non bornée avant la mise en production.
Si vous développez vite (par ex. avec un générateur d'apps comme Koder.ai, où frontends React, backends Go et schémas PostgreSQL peuvent être générés rapidement), ces garde-fous comptent encore plus : la vitesse est une fonctionnalité, mais seulement si vous embarquez la télémétrie (trace IDs, fingerprinting, journalisation sûre) dès la première itération.
Créer une responsabilité et un rythme de revue
Faites de la revue des requêtes lentes le travail de quelqu'un, pas une pensée après-coup :
- Assignez un propriétaire par service/base.
- Revoyez les rapports de requêtes lentes à cadence fixe (hebdomadaire suffit pour beaucoup d'équipes).
- Maintenez un backlog court : empreinte, cause suspectée, action suivante et impact attendu.
Avec des SLOs qui définissent le « bien », et des garde-fous qui détectent les dérives, la performance cesse d'être une urgence récurrente et devient une partie gérée de la livraison.
Ce qu'il faut rechercher dans une stack d'observabilité orientée base de données
Une configuration orientée BD doit vous aider à répondre vite à deux questions : « La base est-elle le goulot ? » et « Quelle requête (et quel appelant) l'a causé ? » Les meilleures solutions rendent la réponse évidente sans forcer les ingénieurs à greper des logs bruts pendant une heure.
Checklist pratique
Métriques requises (idéalement ventilées par instance, cluster et rôle/réplica) :
- Latence des requêtes (p50/p95/p99), débit (QPS) et taux d'erreur
- Utilisation du pool de connexions, connexions actives/inactives, temps d'attente
- Verrous : temps d'attente, deadlocks, contention sur lignes
- Signaux de ressources : CPU, mémoire, I/O disque, ratio de hit du cache
- Délai de réplication (si applicable)
Champs requis pour les journaux des requêtes lentes :
- Timestamp, durée, base/schema, user/role, identifiant client/app
- Requête normalisée ou empreinte, plus un moyen sûr de voir le texte complet si autorisé
- Lignes examinées/retournées, hash du plan (si dispo)
Tags de trace pour corréler requêtes et traces :
- service.name, endpoint/route, environnement, version
- db.system, db.name, empreinte de db.statement, db.operation
- request_id / trace_id propagés dans les logs
Dashboards et alertes attendus :
- Vue « DB pain » : p95 latence + QPS + attentes de connexion + attentes de verrous
- Top N empreintes par temps total et par p95
- Alerte sur hausse soutenue du p95/p99, pics d'attente de verrous et saturation des pools (pas seulement CPU)
Questions à poser à un outil ou vendor
Peut-il corréler un pic de latence d'endpoint à une empreinte de requête et à une version de release ? Comment gère-t-il le sampling pour conserver les requêtes rares et coûteuses ? Déduplique-t-il les statements bruyants (fingerprinting) et met-il en évidence les régressions dans le temps ?
Traitement des données à ne pas compromettre
Recherchez une redaction intégrée (PII et littéraux), un RBAC, et des limites de rétention claires pour logs et traces. Assurez-vous que l'export vers votre entrepôt/SIEM ne contourne pas ces contrôles.
Si votre équipe évalue des options, alignez les besoins tôt — partagez une shortlist en interne, puis impliquez les vendors. Si vous voulez une comparaison rapide ou des conseils, voyez /pricing ou contactez-nous via /contact.