12 nov. 2025·8 min
Construire un site prêt pour les crawlers IA et l'indexation LLM
Apprenez à structurer contenu, métadonnées, règles de crawl et performances afin que les crawlers IA et outils LLM découvrent, parsèment et citent vos pages de manière fiable.
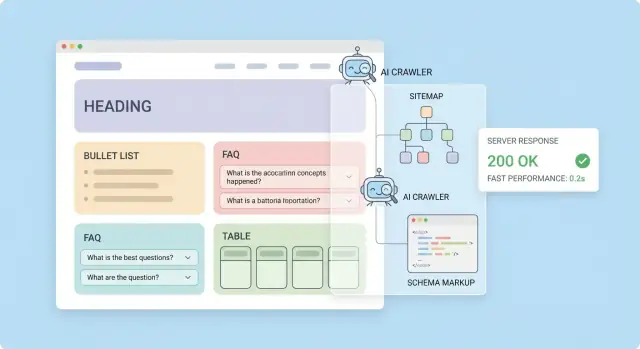
Ce que signifie réellement « optimisé pour l'IA »
« Optimisé pour l'IA » est souvent un mot-clé marketing, mais dans les faits cela signifie que votre site est facile pour les systèmes automatisés à trouver, lire et réutiliser fidèlement.
Quand on parle de crawlers IA, il s'agit généralement de bots opérés par des moteurs de recherche, des produits IA ou des fournisseurs de données qui récupèrent des pages web pour alimenter des fonctions comme des résumés, des réponses, des jeux de données d'entraînement ou des systèmes de récupération. L'indexation LLM désigne typiquement le processus de transformer vos pages en un magasin de connaissances consultable (souvent du texte « découpé » avec des métadonnées) pour qu'un assistant IA puisse récupérer le passage approprié et le citer ou le reproduire.
Les objectifs réels
L'optimisation pour l'IA vise moins le « classement » que quatre résultats concrets :
- Découverte : les crawlers atteignent vos URLs importantes de façon fiable.
- Analyse : votre contenu est lisible sans conjectures (HTML propre, structure prévisible).
- Attribution/citation : on sait qui a écrit, quand la page a été mise à jour et quelles sources la soutiennent.
- Qualité de récupération : les passages sont autonomes, précis et faciles à associer à une question.
Fixer des attentes (et ce que vous pouvez contrôler)
Personne ne peut garantir l'inclusion dans un index ou un modèle donné. Les fournisseurs crawlent différemment, respectent des politiques différentes et se rafraîchissent à des fréquences variées.
Ce que vous pouvez contrôler, c'est rendre votre contenu simple d'accès, d'extraction et d'attribution — afin que, s'il est utilisé, il le soit correctement.
Ce que vous aurez mis en place à la fin
- Un site crawlable avec des règles d'accès claires (robots et directives meta)
- Des pratiques d'URL propres et de canonical pour réduire les doublons
- Des sitemaps et des liens internes qui mettent en avant les pages clés rapidement
- Du contenu formaté en « blocs » que les machines peuvent interpréter
- Des données structurées pour étiqueter le sujet de chaque page
- Un fichier
llms.txtsimple pour guider la découverte orientée LLM - Des performances et réponses serveur qui évitent les timeouts des crawlers
- Des signaux de confiance (auteurs, dates, sources, propriété) favorisant la citation
- Une routine de tests pour vérifier ce que les bots voient réellement
Si vous créez rapidement de nouvelles pages et parcours, il est utile de choisir des outils qui ne s'opposent pas à ces exigences. Par exemple, des équipes utilisant Koder.ai (plateforme de codage par chat qui génère des frontends React et des backends Go/PostgreSQL) intègrent souvent des templates SSR/SSG, des routes stables et des métadonnées cohérentes dès le départ — ainsi « prêt pour l'IA » devient une valeur par défaut, pas un rattrapage.
Structure de contenu que les LLM peuvent parser facilement
Les LLM et les crawlers IA n'interprètent pas une page comme une personne. Ils extraient du texte, infèrent les relations entre les idées et tentent de mapper votre page à une intention claire. Plus votre structure est prévisible, moins ils feront d'hypothèses erronées.
À quoi ressemble une page « idéale »
Commencez par rendre la page facile à parcourir en texte brut :
- Un H1 clair qui correspond à la promesse principale de la page
- Des sections courtes avec des titres descriptifs
- Un minimum de bruit de type sidebar et moins d'encarts flottants qui interrompent le récit principal
Un modèle utile : promesse → résumé → explication → preuves → prochaines étapes.
Ajoutez un TL;DR pour une compréhension rapide
Placez un court résumé près du sommet (2–5 lignes). Cela aide les systèmes IA à classifier rapidement la page et capter les revendications clés.
Exemple de TL;DR :
TL;DR : Cette page explique comment structurer le contenu pour que les crawlers IA puissent extraire le sujet principal, les définitions et les points clés de façon fiable.
Conserver un sujet principal par page
L'indexation LLM fonctionne mieux quand chaque URL répond à une seule intention. Si vous mélangez des objectifs non liés (ex. « tarification », « docs d'intégration » et « histoire de l'entreprise » sur une même page), elle devient plus difficile à catégoriser et risque d'apparaître pour les mauvaises requêtes.
Si vous devez couvrir des intentions proches mais distinctes, séparez-les en pages individuelles et reliez-les par des liens internes (ex. /pricing, /docs/integrations).
Définir les termes ambigus et ajouter du contexte
Si votre public peut interpréter un terme de plusieurs façons, définissez-le tôt.
Exemple :
Optimisation des crawlers IA : préparer le contenu et les règles d'accès du site pour que les systèmes automatisés puissent découvrir, lire et interpréter les pages de façon fiable.
Utilisez une nomenclature cohérente pour les entités
Choisissez un nom unique pour chaque produit, fonctionnalité, offre et concept clé — et tenez-vous-y partout. La cohérence améliore l'extraction (la « fonctionnalité X » désigne toujours la même chose) et réduit la confusion des entités lorsque les modèles résument ou comparent vos pages.
Titres, listes et tableaux : rendez les pages faciles à découper en blocs
La plupart des pipelines d'indexation fragmentent les pages en blocs et stockent/retournent les morceaux qui correspondent le mieux. Votre travail est de rendre ces blocs évidents, autonomes et faciles à citer.
Utilisez une hiérarchie H1–H3 claire
Gardez un seul H1 par page (la promesse), puis utilisez des H2 pour les grandes sections et des H3 pour les sous-thèmes.
Une règle simple : si vous pouvez transformer vos H2 en table des matières qui décrit l'ensemble de la page, vous êtes sur la bonne voie. Cette structure aide les systèmes de récupération à attacher le bon contexte à chaque bloc.
Rédigez des titres qui tiennent debout seuls
Évitez les intitulés vagues comme « Aperçu » ou « Plus d'infos ». Faites en sorte que les titres répondent à l'intention de l'utilisateur :
- « Tarifs et ce qui est inclus »
- « Formats de fichiers pris en charge et limites de taille »
- « Durée typique d'installation (délais) »
Lorsqu'un bloc est extrait hors contexte, le titre devient souvent son « titre ». Rendez-le signifiant.
Privilégiez les paragraphes courts, listes et tableaux
Utilisez des paragraphes courts (1–3 phrases) pour la lisibilité et pour garder les blocs ciblés.
Les listes à puces fonctionnent bien pour les exigences, étapes et points forts. Les tableaux sont excellents pour les comparaisons car ils conservent la structure.
| Forfait | Idéal pour | Limite clé |
|---|---|---|
| Starter | Essayer le service | 1 projet |
| Team | Collaboration | 10 projets |
Ajoutez une FAQ pour des réponses directes
Une petite section FAQ avec des réponses franches et complètes améliore l'extractabilité :
Q : Prenez-vous en charge les imports CSV ?
R : Oui — CSV jusqu'à 50 Mo par fichier.
Incluez « Prochaines étapes » et « Lectures associées »
Terminez les pages clés par des blocs de navigation pour que les utilisateurs et les crawlers suivent des parcours basés sur l'intention :
- Prochaines étapes : /pricing, /signup
- Lectures associées : /blog/technical-seo-for-ai, /docs/sitemaps
Rendu : assurez-vous que le contenu existe sans JavaScript
Les crawlers IA ne se comportent pas tous comme un navigateur complet. Beaucoup téléchargeant et lisent le HTML brut immédiatement, mais peinent (ou ignorent) l'exécution du JavaScript, l'attente des appels API et l'assemblage après l'hydratation. Si votre contenu clé n'apparaît qu'après rendu côté client, vous risquez d'être « invisible » pour des systèmes qui font l'indexation LLM.
HTML crawlable vs pages rendues par JavaScript
Avec une page HTML traditionnelle, le crawler télécharge le document et peut extraire titres, paragraphes, liens et métadonnées immédiatement.
Avec une page lourde en JS, la première réponse peut être une coque vide (quelques divs et scripts). Le texte significatif n'apparaît qu'après l'exécution des scripts, le chargement des données et le rendu des composants. C'est cette seconde étape où la couverture se réduit : certains crawlers n'exécutent pas les scripts ; d'autres le font avec des timeouts ou un support partiel.
Préférez le rendu côté serveur (ou hybride) pour le contenu critique
Pour les pages que vous voulez indexer — descriptions produits, tarifs, FAQ, docs — privilégiez :
- Server-Side Rendering (SSR) : le contenu est présent dans la réponse HTML initiale
- Static generation (SSG/ISR) : HTML préconstruit avec rafraîchissements périodiques
- Rendu hybride : rendre côté serveur le contenu principal, puis enrichir avec du JS pour l'interactivité
Le but n'est pas « pas de JavaScript ». C'est HTML significatif d'abord, JS ensuite.
Ne cachez pas le texte important derrière une UI « invisible »
Les onglets, accordéons et contrôles « lire la suite » sont acceptables si le texte est dans le DOM. Les problèmes surviennent lorsque le contenu d'un onglet est récupéré seulement après un clic, ou injecté après une requête client. Si ce contenu compte pour la découverte IA, incluez-le dans le HTML initial et utilisez CSS/ARIA pour contrôler la visibilité.
Tests rapides pour repérer les lacunes de rendu
Effectuez ces deux vérifications :
- Afficher la source : montre le HTML livré par le serveur (ce que beaucoup de crawlers voient)
- Inspecter l'élément : montre le DOM post-JS (ce que voit un navigateur réel)
Si vos titres, texte principal, liens internes ou réponses FAQ apparaissent seulement dans Inspecter l'élément et non dans Afficher la source, prenez cela comme un risque de rendu et déplacez ce contenu dans la sortie rendue côté serveur.
Contrôles d'accès au crawl : robots.txt et meta robots
Les crawlers IA et les bots de recherche traditionnels ont besoin de règles d'accès claires et cohérentes. Si vous bloquez par erreur du contenu important — ou autorisez les crawlers dans des zones privées ou « en vrac » — vous pouvez gaspiller le budget de crawl et polluer ce qui est indexé.
robots.txt : le régulateur site-wide
Utilisez robots.txt pour des règles larges : quels dossiers entiers (ou motifs d'URL) doivent être crawlés ou évités.
Un socle pratique :
- Allow/Disallow : bloquez les zones non publiques comme
/admin/,/account/, les résultats de recherche internes ou les URLs paramétrées qui génèrent des combinaisons quasi infinies. - Crawl-delay : ne l'ajoutez que si votre serveur lutte avec le trafic bot. De nombreux bots majeurs l'ignorent, ne comptez donc pas dessus comme moyen principal de régulation.
- Directive Sitemap : pointez les crawlers vers votre emplacement sitemap canonique pour que la découverte soit prévisible.
Exemple :
User-agent: *
Disallow: /admin/
Disallow: /account/
Disallow: /internal-search/
Sitemap: /sitemap.xml
Important : bloquer via robots.txt empêche le crawl, mais cela ne garantit pas toujours qu'une URL n'apparaisse pas dans un index si elle est référencée ailleurs. Pour contrôler l'indexation, utilisez des directives au niveau de la page.
Meta robots et X-Robots-Tag : décisions d'index au niveau page
Utilisez meta name=\"robots\" dans les pages HTML et X-Robots-Tag dans les en-têtes pour les fichiers non-HTML (PDF, flux, exports générés).
Schémas courants :
- Pages fines ou utilitaires (filtres, variantes de tri, vues d'impression) :
noindex,followafin que les liens continuent de circuler mais que la page elle-même reste hors des indexes. - Zones privées ou sensibles : ne comptez pas seulement sur
noindex— protégez par authentification et envisagez de bloquer le crawl également. - Versions dupliquées (ex. URLs de prévisualisation) :
noindexplus une canonicalisation appropriée (voir plus loin).
Règles d'environnement simples (prod vs staging)
Documentez — et appliquez — des règles par environnement :
- Production : crawlable par défaut ; ne bloquez que les zones clairement non publiques ou de faible valeur.
- Staging/preview : nécessite une connexion ; ajoutez aussi
noindexglobalement (baser cela dans l'en-tête est la méthode la plus simple) pour éviter l'indexation accidentelle.
Si vos contrôles d'accès affectent des données utilisateurs, assurez-vous que la politique visible par les utilisateurs correspond à la réalité (voir /privacy et /terms lorsque pertinent).
URL canoniques, doublons et hygiène des redirections
Facilitez la découverte par les LLM
Créez un llms.txt simple et maintenez vos points d'entrée clés à jour au fur et à mesure de la croissance du site.
Si vous voulez que les systèmes IA (et les crawlers) comprennent et citent vos pages de façon fiable, il faut réduire les situations « même contenu, plusieurs URLs ». Les doublons gaspillent le budget de crawl, fragmentent les signaux et peuvent entraîner l'indexation ou la référence d'une mauvaise version d'une page.
Créez des URL propres et stables
Visez des URLs qui restent valides pendant des années. Évitez d'exposer des paramètres inutiles comme des IDs de session, options de tri ou codes de suivi dans des URLs indexables (par ex. ?utm_source=..., ?sort=price, ?ref=). Si des paramètres sont nécessaires pour la fonctionnalité (filtres, pagination, recherche interne), assurez-vous qu'une version « principale » reste accessible à une URL stable et propre.
Les URLs stables améliorent les citations à long terme : lorsqu'un LLM apprend ou stocke une référence, il est beaucoup plus susceptible de continuer à pointer vers la même page si votre structure d'URL ne change pas à chaque refonte.
Utilisez les balises canonical pour regrouper les duplicata
Ajoutez un \u003clink rel=\"canonical\"\u003e sur les pages où des doublons sont attendus :
- Variantes de produit partageant la majorité du contenu
- Vues de catégories filtrées
- Versions avec paramètres de tracking
Les canonical doivent pointer vers l'URL préférée indexable (et idéalement cette canonical doit retourner un statut 200).
Hygiène des redirections : simple et prévisible
Quand une page bouge de façon permanente, utilisez une redirection 301. Évitez les chaînes de redirection (A → B → C) et les boucles ; elles ralentissent les crawlers et peuvent conduire à une indexation partielle. Redirigez les anciennes URLs directement vers la destination finale et maintenez la cohérence entre HTTP/HTTPS et www/non-www.
N'utilisez hreflang que pour de vrais équivalents
Implémentez hreflang uniquement lorsque vous avez de véritables équivalents localisés (pas seulement des extraits traduits). Un hreflang incorrect peut créer de la confusion sur la page à citer pour quel public.
Sitemaps et liens internes pour une découverte fiable
Les sitemaps et les liens internes sont votre « système de livraison » pour la découverte : ils indiquent aux crawlers ce qui existe, ce qui compte et ce qu'il faut ignorer. Pour les crawlers IA et l'indexation LLM, l'objectif est simple — rendez vos meilleures URLs propres faciles à trouver et difficiles à manquer.
Construisez des sitemaps XML qui listent uniquement les bonnes URLs
Votre sitemap doit inclure seulement des URL canoniques et indexables. Si une page est bloquée par robots.txt, marquée noindex, redirigée ou n'est pas la version canonique, elle n'a pas sa place dans le sitemap. Cela concentre le budget de crawl et réduit le risque qu'un LLM récupère une version dupliquée ou obsolète.
Soyez cohérent dans les formats d'URL (slash final, minuscules, HTTPS) afin que le sitemap reflète vos règles canoniques.
Scindez les gros sitemaps et utilisez un index de sitemap
Si vous avez beaucoup d'URLs, divisez-les en plusieurs fichiers sitemap (limite commune : 50 000 URLs par fichier) et publiez un index de sitemap qui liste chaque sitemap. Organisez par type de contenu quand c'est utile, par ex. :
/sitemaps/pages.xml/sitemaps/blog.xml/sitemaps/docs.xml
Cela facilite la maintenance et vous aide à surveiller ce qui est découvert.
Utilisez lastmod comme signal de confiance, pas comme horodatage de déploiement
Mettez lastmod à jour avec discernement — uniquement quand la page change de façon significative (contenu, tarifs, politique, métadonnées importantes). Si chaque URL se met à jour à chaque déploiement, les crawlers finissent par ignorer le champ et les mises à jour réellement importantes peuvent être revisitées plus tard que souhaité.
Liens internes : faites de votre site une carte navigable
Une forte structure hub-and-spoke aide les utilisateurs et les machines. Créez des hubs (pages de catégorie, produit ou sujet) qui lient vers les pages « spoke » les plus importantes, et assurez-vous que chaque spoke renvoie à son hub. Ajoutez des liens contextuels dans le corps, pas seulement dans les menus.
Si vous publiez du contenu éducatif, gardez vos points d'entrée principaux évidents — orientez vers /blog pour les articles et /docs pour la documentation de référence.
Données structurées : aidez les machines à comprendre vos pages
Créez des URL stables par défaut
Générez des applications React, Go et PostgreSQL tout en conservant des balises canoniques et des redirections prévisibles.
Les données structurées permettent d'étiqueter ce qu'est une page (article, produit, FAQ, organisation) dans un format que les machines lisent de façon fiable. Les moteurs et systèmes IA n'ont pas à deviner quel texte est le titre, qui l'a écrit ou quel est le sujet principal — ils le parsèment directement.
Choisissez le bon type Schema.org
Utilisez les types Schema.org qui correspondent à votre contenu :
- Article (billets de blog, guides, actualités)
- FAQPage (sections question/réponse)
- HowTo (instructions étape par étape)
- Product (pages tarifaires, fiches produit)
- Organization (identité de l'entreprise)
Choisissez un type principal par page, puis ajoutez des propriétés de soutien (par ex. un Article peut référencer une Organization comme éditeur).
Alignez le balisage avec ce que les utilisateurs voient
Les crawlers et moteurs comparent les données structurées au contenu visible. Si votre balisage affirme une FAQ qui n'est pas réellement sur la page, ou liste un auteur non affiché, vous créez de la confusion et risquez que le balisage soit ignoré.
Pour les pages de contenu, incluez author ainsi que datePublished et dateModified lorsque ces informations sont réelles et significatives. Cela clarifie la fraîcheur et la responsabilité — deux éléments que les LLM regardent souvent pour juger de la fiabilité.
Si vous avez des profils officiels, ajoutez des liens sameAs (par ex. vos profils sociaux vérifiés) au schéma Organization.
Exemple : Article JSON-LD
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Build a Website Ready for AI Crawlers and LLM Indexing",
"author": { "@type": "Person", "name": "Jane Doe" },
"datePublished": "2025-01-10",
"dateModified": "2025-02-02",
"publisher": {
"@type": "Organization",
"name": "Acme",
"sameAs": ["https://www.linkedin.com/company/acme"]
}
}
Enfin, validez avec les outils courants (Rich Results Test de Google, Schema Markup Validator). Corrigez les erreurs et traitez les avertissements de manière pragmatique : priorisez ceux liés à votre type choisi et aux propriétés clés (titre, auteur, dates, info produit).
llms.txt : un guide simple pour la découverte orientée LLM
Un llms.txt est une petite fiche lisible par les humains qui pointe les crawlers focalisés sur les modèles de langage (et les personnes qui les configurent) vers les points d'entrée les plus importants : vos docs, pages produit clés et tout matériel de référence qui explique votre terminologie.
Ce n'est pas une norme avec un comportement garanti chez tous les crawlers, et ce ne doit pas remplacer les sitemaps, canonicals ou contrôles robots. Considérez-le comme un raccourci utile pour la découverte et le contexte.
Où le placer
Mettez-le à la racine du site pour qu'il soit facile à trouver :
/llms.txt
C'est la même idée que robots.txt : emplacement prévisible, récupération rapide.
Que mettre (et quoi éviter)
Restez court et sélectionné. Bonnes candidates :
- Points d'entrée principaux : aperçu produit, tarification, démarrage
- Hubs de documentation : page docs, référence API, guides SDK, tutoriels
- Glossaire / terminologie : page qui définit vos termes et noms préférés
- Politiques importantes pour la réutilisation : licences, attentes d'attribution, notes d'utilisation des données
Envisagez aussi d'ajouter de courtes notes de style qui réduisent l'ambiguïté (par ex. « Nous appelons les clients ‘workspaces’ dans notre UI »). Évitez les longs textes marketing, des dumps d'URL complets ou tout ce qui entre en conflit avec vos URLs canoniques.
Voici un exemple simple :
# llms.txt
# Purpose: curated entry points for understanding and navigating this site.
## Key pages
- / (Homepage)
- /pricing
- /docs
- /docs/getting-started
- /docs/api
- /blog
## Terminology and style
- Prefer “workspace” over “account”.
- Product name is “Acme Cloud” (capitalized).
- API objects: “Project”, “User”, “Token”.
## Policies
- /terms
- /privacy
Gardez-le aligné avec les sitemaps et les canonicals
La cohérence compte plus que le volume :
- Ne listez que les URLs que vous voulez voir découvertes et citées.
- Assurez-vous que les pages listées renvoient 200 et ont le canonical correct.
- Si une page est remplacée, mettez à jour le lien plutôt que de compter sur une redirection.
- N'incluez pas d'URLs bloquées par
robots.txt(cela crée des signaux contradictoires).
Processus de maintenance léger (trimestriel)
Une routine pratique et gérable :
- Revue trimestrielle (15 minutes) : cliquez chaque lien dans
llms.txtet confirmez que c'est toujours le meilleur point d'entrée. - Après les grandes versions : ajoutez/retirez des hubs docs quand vous restructurez la navigation.
- Lie à vos contrôles existants : mettez à jour
llms.txtchaque fois que vous mettez à jour votre sitemap ou changez des canonicals.
Bien fait, llms.txt reste petit, précis et réellement utile — sans promettre quoi que ce soit sur le comportement d'un crawler donné.
Performances et réponses serveur que les crawlers apprécient
Les crawlers (incluant les crawlers IA) se comportent souvent comme des utilisateurs impatients : si votre site est lent ou instable, ils récupéreront moins de pages, réessaieront moins souvent et mettront à jour leur index moins fréquemment. De bonnes performances et des réponses serveur fiables augmentent les chances que votre contenu soit découvert, recrawlisé et maintenu à jour.
Vitesse et disponibilité : ce que les crawlers « ressentent »
Si votre serveur timeoute fréquemment ou renvoie des erreurs, un crawler peut réduire automatiquement sa fréquence. Cela signifie que les nouvelles pages mettent plus de temps à apparaître et que les mises à jour sont moins rapidement reflétées.
Visez une disponibilité constante et des temps de réponse prévisibles pendant les heures de pointe — pas seulement d'excellents scores en laboratoire.
Améliorez le TTFB et réduisez les charges utiles
Time to First Byte (TTFB) est un indicateur fort de la santé serveur. Quelques réparations à fort impact :
- Utilisez un CDN pour la mise en cache des pages publiques et activez la mise en cache d'origine si possible.
- Activez la compression (Brotli ou gzip) pour HTML, CSS et JavaScript.
- Gardez le HTML léger : évitez d'envoyer d'énormes scripts inline ou des tags de tracking excessifs.
- Redimensionnez et compressez les images pour éviter des téléchargements lourds juste pour comprendre le contenu.
Même si les crawlers ne « voient » pas les images comme les humains, les gros fichiers gaspillent du temps de crawl et de la bande passante.
Renvoyez les bons codes HTTP
Les crawlers s'appuient sur les codes de statut pour décider quoi garder ou supprimer :
- 200 pour les pages valides avec contenu.
- 301 pour les déplacements permanents (et évitez les chaînes de redirection).
- 404 lorsqu'une page n'existe pas.
- 410 quand une page est volontairement supprimée et doit être retirée plus rapidement.
- Gérez les 5xx avec attention : corrigez les causes racines rapidement et envisagez une page de secours légère seulement si elle renvoie toujours le code d'erreur approprié.
Ne cachez pas le contenu principal derrière des connexions
Si le texte principal demande une authentification, de nombreux crawlers n'indexeront que la coque. Gardez l'accès de lecture principal public, ou fournissez un aperçu crawlable qui contient le contenu clé.
Limitation de débit sans bloquer les crawlers légitimes
Protégez votre site contre les abus, mais évitez les blocages aveugles. Préférez :
- Des limites de type token-bucket avec des rafales raisonnables
- Des listes blanches pour les plages IP des crawlers connus (quand disponible)
- Des réponses 429 claires avec en-têtes
Retry-After
Cela protège votre site tout en permettant aux crawlers responsables de faire leur travail.
Signaux de confiance : sources, auteurs et propriété claire
Gardez le contrôle total des bases du SEO
Maîtrisez le code source pour appliquer vos règles robots, balises canoniques et codes de statut comme vous l'entendez.
L'« E‑E‑A‑T » n'exige pas de grandes proclamations ou de badges sophistiqués. Pour les crawlers IA et les LLM, il s'agit surtout d'être clair sur qui a écrit quelque chose, d'où proviennent les faits et qui est responsable de la maintenance.
Rendre les sources évidentes (et vérifiables)
Quand vous avancez un fait, attachez la source aussi près que possible de l'énoncé. Priorisez les références primaires et officielles (lois, organismes normatifs, docs fournisseurs, articles revus par des pairs) plutôt que des résumés de seconde main.
Par exemple, si vous mentionnez le comportement des données structurées, citez la documentation de Google (« Google Search Central — Structured Data ») et, si pertinent, les définitions du schéma (« Schema.org vocabulary »). Si vous discutez des directives robots, référencez les standards et docs officiels (ex. « RFC 9309: Robots Exclusion Protocol »). Même si vous ne liez pas chaque mention, donnez assez d'information pour que le lecteur retrouve le document exact.
Affichez la paternité et la responsabilité éditoriale
Ajoutez un byline d'auteur avec une courte bio, des credentials et ce dont l'auteur est responsable. Puis rendez la propriété explicite :
- Un propriétaire clair du site (entité légale) dans le footer
- Une page de contact avec des canaux réels (pas seulement un formulaire)
- Une page À propos expliquant votre mission et votre processus éditorial (voir /about)
Restez précis dans vos affirmations — et conservez les preuves
Évitez les formulations « meilleur » ou « garanti ». Décrivez plutôt ce que vous avez testé, ce qui a changé et quelles sont les limites. Ajoutez des notes de mise à jour en haut ou en bas des pages clés (ex. « Mis à jour le 2025‑12‑10 : clarification du traitement des canonicals pour les redirections »). Cela crée une trace de maintenance que les humains et les machines peuvent interpréter.
Maintenez un glossaire cohérent
Définissez vos termes clés une fois, puis utilisez-les de façon cohérente sur le site (ex. « crawler IA », « indexation LLM », « HTML rendu »). Une page glossaire légère (ex. /glossary) réduit l'ambiguïté et facilite des résumés précis.
Tests, surveillance et améliorations continues
Un site prêt pour l'IA n'est pas un projet ponctuel. De petits changements — mise à jour CMS, nouvelle redirection ou refonte de navigation — peuvent casser discrètement la découverte et l'indexation. Une routine de tests simple vous évite de deviner quand la visibilité change.
Surveillez les signaux qui indiquent des problèmes de découverte
Commencez par les bases : suivez les erreurs de crawl, la couverture d'index et vos pages les plus liées. Si les crawlers ne peuvent pas récupérer des URLs clés (timeouts, 404, ressources bloquées), l'indexation LLM décline rapidement.
Surveillez aussi :
- Pages qui disparaissent soudainement de la couverture d'index
- URLs importantes qui cessent de recevoir des liens internes
- Pics inattendus de pages « dupliquées » ou « exclues »
Contrôlez les releases comme un ingénieur fiabilité
Après les lancements (même « petits »), vérifiez ce qui a changé :
- Redirections : les anciennes URLs envoient-elles correctement utilisateurs et bots vers la nouvelle destination ?
- Canonicals : les templates ont-ils changé et pointent-ils les canonicals au mauvais endroit ?
- Sitemaps : sont-ils toujours valides, à jour et sans URLs cassées ?
Un audit post-release de 15 minutes détecte souvent des problèmes avant qu'ils n'entraînent des pertes de visibilité à long terme.
Testez comment vos pages sont résumées
Choisissez quelques pages à forte valeur et testez leur résumé par des outils IA ou des scripts internes de résumé. Recherchez :
- Définitions manquantes (la phrase « qu'est-ce que c'est ? » n'est pas claire)
- Titres qui ne correspondent pas aux sections réelles
- Détails clés enfouis dans de longs paragraphes sans étiquettes
Si les résumés sont vagues, la correction est généralement éditoriale : titres H2/H3 plus forts, paragraphes d'introduction plus clairs et terminologie explicite.
Créez une checklist récurrente « Prêt pour l'IA »
Transformez ce que vous apprenez en une checklist périodique et assignez un responsable (un vrai nom, pas « marketing »). Gardez-la vivante et actionnable — puis liez la dernière version en interne pour que toute l'équipe utilise le même playbook. Publiez une référence légère comme /blog/ai-seo-checklist et mettez-la à jour au fil de l'évolution du site et des outils.
Si votre équipe déploie vite (surtout avec de l'assistance IA), envisagez d'ajouter des contrôles « AI readiness » directement dans votre workflow de build/release : des templates qui émettent toujours des balises canonical, des champs auteur/date cohérents et du contenu rendu côté serveur. Des plateformes comme Koder.ai peuvent aider en rendant ces choix par défaut reproductibles sur de nouvelles pages React et surfaces applicatives — et en proposant des modes planification, snapshot et rollback quand un changement affecte accidentellement la crawlabilité.
De petits progrès réguliers s'additionnent : moins d'échecs de crawl, une indexation plus propre et du contenu plus facile à comprendre pour les humains comme pour les machines.
FAQ
Que signifie réellement « optimisé pour l'IA » pour un site web ?
Cela signifie que votre site est facile pour les systèmes automatisés à découvrir, analyser et réutiliser correctement.
En pratique, cela se traduit par des URL crawlables, une structure HTML propre, une attribution claire (auteur/date/sources) et du contenu rédigé en blocs autonomes que les systèmes de récupération peuvent associer à des questions précises.
Pouvez-vous garantir que mon contenu sera inclus dans les index ou modèles IA ?
Pas de manière fiable. Les différents fournisseurs crawlent à des fréquences différentes, appliquent des politiques distinctes et peuvent ne pas vous crawler du tout.
Concentrez-vous sur ce que vous pouvez contrôler : rendez vos pages accessibles, non ambiguës, rapides à récupérer et faciles à attribuer afin que, si elles sont utilisées, elles le soient correctement.
Comment faire en sorte que les crawlers IA lisent mon contenu si mon site utilise JavaScript ?
Visez du HTML significatif dans la réponse initiale.
Utilisez SSR/SSG/hybride pour les pages importantes (tarifs, docs, FAQ). Ensuite, ajoutez du JavaScript pour l'interactivité. Si votre texte principal n'apparaît qu'après l'hydratation ou des appels API, de nombreux crawlers le manqueront.
Comment vérifier rapidement que mon contenu est invisible pour certains crawlers ?
Comparez :
- Afficher la source : ce que le serveur renvoie (ce que beaucoup de crawlers voient).
- Inspecter l'élément : le DOM après JS (ce que voit un vrai navigateur).
Si les titres clés, le texte principal, les liens ou les FAQ n'apparaissent que dans Inspecter l'élément, déplacez ce contenu dans le HTML rendu côté serveur.
Quand dois-je utiliser robots.txt vs meta robots vs X-Robots-Tag ?
Utilisez robots.txt pour des règles de crawl globales (par ex. bloquer /admin/) et meta robots / X-Robots-Tag pour les décisions d'indexation au niveau d'une page ou d'un fichier.
Un schéma fréquent : pour les pages utilitaires fines, et authentification (pas seulement ) pour les zones privées.
Quelle est la meilleure façon de gérer les URL dupliquées, les paramètres et les redirections ?
Utilisez une URL canonique stable et indexable pour chaque contenu.
- Ajoutez
rel=\"canonical\"là où des doublons sont attendus (filtres, paramètres, variantes). - Utilisez des redirections 301 pour les déplacements permanents.
- Évitez les chaînes de redirection et assurez-vous que les canonicals pointent vers des pages renvoyant 200.
Cela réduit les signaux répartis et rend les citations plus cohérentes dans le temps.
Que devrait (et ne devrait pas) contenir mon sitemap XML pour une découverte orientée IA ?
Incluez seulement des URL canoniques et indexables.
Excluez les URL redirigées, noindex, bloquées par robots.txt ou des duplicata non canoniques. Gardez un format cohérent (HTTPS, règle de slash de fin, minuscules) et n'utilisez lastmod que lorsque le contenu change significativement.
Qu'est-ce que llms.txt et comment l'utiliser ?
Considérez-le comme une « fiche » concise qui pointe vers vos meilleures pages d'entrée (hubs de docs, démarrage, glossaire, politiques).
Restez bref, listez uniquement les URL que vous souhaitez voir découvertes et citées, et assurez-vous que chaque lien renvoie 200 avec le canonical correct. Ne le remplacez pas par les sitemaps, canonicals ou directives robots.
Comment structurer le contenu pour que les LLM récupèrent les bons passages ?
Rédigez les pages pour que les blocs puissent être autonomes :
- Un seul objectif principal par URL
- Hiérarchie claire H1→H2→H3
- Un court TL;DR en haut
- Des titres précis (évitez « Aperçu »)
- Paragraphes courts, listes et tableaux pour contraintes et comparaisons
Cela améliore la précision de la récupération et réduit les résumés erronés.
Quels signaux de confiance améliorent le plus l'attribution et la citation par les systèmes IA ?
Ajoutez et maintenez des signaux de confiance visibles :
- Mention de l'auteur + bio
datePublishedetdateModifiedsignificatifs- Sources proches des affirmations factuelles
- Propriété claire du site et moyens de contact
- Données structurées (Article/Organization) qui correspondent à ce que l'utilisateur voit
Ces éléments rendent l'attribution et la citation plus fiables pour les crawlers et les utilisateurs.