26 déc. 2025·8 min
Outils internes pour développeurs avec Claude Code : tableaux de bord CLI sécurisés
Construisez des outils internes avec Claude Code pour résoudre la recherche de logs, les feature toggles et les contrôles de données tout en appliquant le moindre privilège et des garde-fous clairs.
Quel problème votre outil interne doit-il réellement résoudre
Les outils internes commencent souvent comme un raccourci : une commande ou une page qui fait gagner 20 minutes à l'équipe pendant un incident. Le risque, c'est que ce raccourci devienne silencieusement une porte dérobée avec privilèges si vous ne définissez pas le problème et les limites dès le départ.
Les équipes cherchent généralement un outil quand la même douleur se répète chaque jour, par exemple :
- Recherche de logs lente, incohérente ou répartie entre plusieurs systèmes
- Basculement de fonctionnalités qui demande une modification manuelle risquée ou un écrit direct en base
- Contrôles de données qui dépendent d'une seule personne exécutant un script depuis son portable
- Tâches on-call simples, mais faciles à foirer à 2h du matin
Ces problèmes paraissent mineurs jusqu'à ce que l'outil puisse lire des logs de production, interroger des données clients ou basculer un flag. Alors vous devez gérer le contrôle d'accès, les traces d'audit et les écritures accidentelles. Un outil « juste pour les ingénieurs » peut quand même provoquer une panne s'il lance une requête trop large, touche le mauvais environnement ou modifie l'état sans étape de confirmation claire.
Définissez le succès en termes étroits et mesurables : des opérations plus rapides sans élargir les permissions. Un bon outil interne supprime des étapes, pas des protections. Plutôt que de donner à tout le monde un accès large à la base pour vérifier un problème de facturation, construisez un outil qui répond à une question : « Montre-moi les événements d'échec de facturation d'aujourd'hui pour le compte X », en utilisant des identifiants en lecture seule et limités.
Avant de choisir une interface, décidez de ce que les gens ont besoin sur le moment. Un CLI est excellent pour des tâches répétables en on-call. Un tableau de bord web est mieux quand les résultats ont besoin de contexte et de visibilité partagée. Parfois vous livrez les deux, mais uniquement s'il s'agit de vues légères sur les mêmes opérations protégées. L'objectif est une capacité bien définie, pas une nouvelle surface d'administration.
Choisissez une seule douleur et gardez la portée petite
La manière la plus rapide de rendre un outil interne utile (et sûr) est de choisir un seul travail clair et de bien l'exécuter. S'il essaie de gérer les logs, les feature flags, les corrections de données et la gestion des utilisateurs dès le jour 1, il développera des comportements cachés et surprendra les gens.
Commencez par une question unique que se pose l'utilisateur pendant le travail réel. Par exemple : « Donné un request ID, montre-moi l'erreur et les lignes environnantes à travers les services. » C'est étroit, testable et facile à expliquer.
Soyez explicite sur pour qui est l'outil. Un développeur qui débugge localement a besoin d'options différentes d'une personne en on-call, et les deux diffèrent du support ou d'un analyste. En mélangeant les publics, on finit par ajouter des commandes « puissantes » que la plupart ne devraient jamais utiliser.
Écrivez les entrées et sorties comme un petit contrat.
Les entrées doivent être explicites : request ID, plage temporelle, environnement. Les sorties doivent être prévisibles : lignes correspondantes, nom du service, horodatage, nombre. Évitez les effets secondaires cachés comme « nettoie aussi le cache » ou « relance aussi le job ». Ce sont ces fonctionnalités qui causent des accidents.
Par défaut, privilégiez la lecture seule. L'outil peut rester précieux avec la recherche, la comparaison, la validation et les rapports. Ajoutez des actions d'écriture seulement quand vous pouvez nommer un scénario réel qui en a besoin et que vous pouvez le contraindre fortement.
Une simple déclaration de portée qui garde l'équipe honnête :
- Une tâche principale, un écran ou une commande principale
- Une source de données (ou une vue logique), pas « tout »
- Flags explicites pour l'environnement et la plage temporelle
- Lecture seule d'abord, pas d'actions en arrière-plan
- Si des écritures existent, exiger une confirmation et journaliser chaque changement
Cartographiez les sources de données et les opérations sensibles tôt
Avant que Claude Code n'écrive quoi que ce soit, notez ce que l'outil touchera. La plupart des problèmes de sécurité et de fiabilité apparaissent ici, pas dans l'UI. Traitez cette cartographie comme un contrat : elle dit aux réviseurs ce qui est dans le périmètre et ce qui est hors limite.
Commencez par un inventaire concret des sources de données et de leurs propriétaires. Par exemple : les logs (app, gateway, auth) et où ils résident ; les tables ou vues exactes de la base que l'outil pourra interroger ; votre magasin de feature flags et les règles de nommage ; métriques et traces et quelles étiquettes il est sûr d'utiliser ; et si vous prévoyez d'écrire des notes dans des systèmes de tickets ou d'incidents.
Puis nommez les opérations autorisées pour l'outil. Évitez le terme « admin » comme permission. Définissez plutôt des verbes auditables. Exemples courants : recherche et export en lecture seule (avec limites), annoter (ajouter une note sans altérer l'historique), basculer des flags spécifiques avec TTL, backfills bornés (plage de dates et nombre d'enregistrements), et modes dry-run qui montrent l'impact sans changer les données.
Les champs sensibles nécessitent un traitement explicite. Décidez ce qui doit être masqué (emails, tokens, IDs de session, clés API, identifiants clients) et ce qui peut être affiché de façon tronquée. Par exemple : afficher les 4 derniers caractères d'un ID, ou le hacher de façon cohérente pour que l'on puisse corréler des événements sans voir la valeur brute.
Enfin, mettez-vous d'accord sur les règles de rétention et d'audit. Si un utilisateur exécute une requête ou bascule un flag, enregistrez qui l'a fait, quand, quels filtres ont été utilisés et le nombre de résultats. Conservez les logs d'audit plus longtemps que les logs applicatifs. Même une règle simple comme « requêtes conservées 30 jours, enregistrements d'audit 1 an » évite de longs débats pendant un incident.
Modèle d'accès au moindre privilège qui reste simple
Le moindre privilège est le plus simple quand vous gardez le modèle ennuyeux. Commencez par lister ce que l'outil peut faire, puis étiquetez chaque action comme lecture seule ou écriture. La plupart des outils internes n'ont besoin que d'accès en lecture pour la majorité des personnes.
Pour un tableau de bord web, utilisez votre système d'identité existant (SSO avec OAuth). Évitez les mots de passe locaux. Pour un CLI, préférez des tokens à courte durée de vie qui expirent vite et qui sont scoped aux actions nécessaires. Les tokens partagés longue durée ont tendance à être collés dans des tickets, sauvegardés dans l'historique du shell ou copiés sur des machines personnelles.
Gardez le RBAC restreint. Si vous avez besoin de plus de quelques rôles, l'outil fait probablement trop de choses. Beaucoup d'équipes s'en sortent bien avec trois rôles :
- Viewer : lecture seule, paramètres sûrs par défaut
- Operator : lecture plus un petit ensemble d'actions peu risquées
- Admin : actions à haut risque, utilisées rarement
Séparez les environnements tôt, même si l'UI se ressemble. Rendez difficile le fait de « faire par accident du prod ». Utilisez des identifiants différents par environnement, des fichiers de config différents et des endpoints API distincts. Si un utilisateur ne supporte que staging, il ne devrait même pas pouvoir s'authentifier sur la production.
Les actions à haut risque méritent une étape d'approbation. Pensez suppression de données, changement de feature flags, redémarrage de services ou requêtes lourdes. Ajoutez un contrôle à deux personnes quand le rayon d'action est large. Des patterns pratiques : confirmations typées incluant la cible (nom du service et environnement), enregistrement de qui a demandé et qui a approuvé, et un court délai ou une fenêtre programmée pour les opérations les plus dangereuses.
Si vous générez l'outil avec Claude Code, faites-en une règle : chaque endpoint et commande doit déclarer son rôle requis en amont. Cette habitude rend l'examen des permissions plus simple au fur et à mesure que l'outil grandit.
Garde-fous pour prévenir les accidents et les requêtes dangereuses
Récupérez après de mauvais déploiements
Revenez rapidement si une nouvelle version se comporte différemment de ce qui était attendu.
Le mode d'échec le plus courant pour les outils internes n'est pas un attaquant. C'est un collègue fatigué qui lance la « bonne » commande avec les mauvais paramètres. Traitez les garde-fous comme des fonctionnalités produit, pas comme de la finition esthétique.
Valeurs par défaut sûres
Commencez avec une posture sûre : lecture seule par défaut. Même si l'utilisateur est admin, l'outil devrait s'ouvrir en mode récupération de données uniquement. Faites des actions d'écriture un choix explicite et visible.
Pour toute opération qui change l'état (basculement d'un flag, backfill, suppression d'un enregistrement), exigez une confirmation de type « retapez pour confirmer ». Un simple « Are you sure? y/N » est trop facile à faire machinalement. Demandez à l'utilisateur de retaper quelque chose de spécifique, comme le nom de l'environnement plus l'ID cible.
La validation stricte des entrées empêche la plupart des catastrophes. N'acceptez que les formes que vous supportez réellement (IDs, dates, environnements) et rejetez le reste tôt. Pour les recherches, contraignez la puissance : limitez le nombre de résultats, imposez des plages temporelles raisonnables et adoptez une approche allow-list plutôt que de laisser des patterns arbitraires frapper votre stockage de logs.
Pour éviter les requêtes incontrôlées, ajoutez des timeouts et des limites de débit. Un outil sûr échoue vite et explique pourquoi, plutôt que de rester bloqué et de marteler votre base.
Un ensemble de garde-fous qui fonctionne bien en pratique :
- Lecture seule par défaut, avec un commutateur clair « mode écriture »
- Confirmation typée pour les écritures (inclure env + cible)
- Validation stricte pour IDs, dates, limites et patterns autorisés
- Timeouts de requêtes et limites par utilisateur
- Masquage des secrets dans la sortie et dans les propres logs de l'outil
Hygiène de sortie
Supposez que la sortie de l'outil sera copiée dans des tickets et du chat. Masquez les secrets par défaut (tokens, cookies, clés API, et emails si besoin). Purgez aussi ce que vous stockez : les logs d'audit doivent enregistrer ce qui a été tenté, pas les données brutes retournées.
Pour un tableau de recherche de logs, renvoyez un aperçu court et un compte, pas des payloads complets. Si quelqu'un a vraiment besoin de l'événement complet, en faites une action séparée, clairement verrouillée, avec sa propre confirmation.
Comment travailler avec Claude Code sans perdre le contrôle
Traitez Claude Code comme un coéquipier junior rapide : utile, mais pas télépathe. Votre travail est de garder la tâche bornée, vérifiable et réversible. C'est la différence entre des outils qui semblent sûrs et des outils qui vous surprennent à 2h du matin.
Commencez par une spec que le modèle peut suivre
Avant de demander du code, rédigez une petite spec qui nomme l'action utilisateur et le résultat attendu. Concentrez-vous sur le comportement, pas sur les détails de framework. Une bonne spec tient généralement sur une demi-page et couvre :
- Commandes ou écrans (noms exacts)
- Entrées (flags, champs, formats, limites)
- Sorties (ce qui s'affiche, ce qui est sauvegardé)
- Cas d'erreur (entrée invalide, timeouts, résultats vides)
- Vérifications de permission (ce qui se passe quand l'accès est refusé)
Par exemple, si vous construisez un CLI de recherche de logs, définissez une commande complète : logs search --service api --since 30m --text "timeout", avec un plafond strict sur les résultats et un message clair « accès refusé ».
Demandez de petits incréments vérifiables
Demandez d'abord une ossature : wiring du CLI, chargement de la config et un appel de données stubbé. Ensuite, demandez exactement une fonctionnalité terminée de bout en bout (validation et erreurs incluses). De petits diffs rendent les revues réelles.
Après chaque changement, demandez une explication en langage clair de ce qui a changé et pourquoi. Si l'explication ne correspond pas au diff, arrêtez et reformulez le comportement et les contraintes de sécurité.
Générez des tests tôt, avant d'ajouter d'autres fonctionnalités. Au minimum, couvrez le chemin heureux, les entrées invalides (mauvaises dates, flags manquants), permission refusée, résultats vides et timeouts ou limites backend.
CLI vs tableau de bord web : choisir la bonne interface
Un CLI et un tableau de bord interne peuvent résoudre le même problème, mais ils échouent différemment. Choisissez l'interface qui rend le chemin sûr le plus facile.
Un CLI est généralement meilleur quand la vitesse compte et que l'utilisateur sait déjà ce qu'il veut. Il convient aussi aux workflows en lecture seule, car vous pouvez garder les permissions étroites et éviter des boutons qui déclenchent accidentellement des écritures.
Un CLI est un bon choix pour des requêtes rapides en on-call, des scripts et automatisations, des traces d'audit explicites (chaque commande est écrite), et un déploiement léger (un binaire, une config).
Un tableau de bord web est préférable quand vous avez besoin de visibilité partagée ou d'étapes guidées. Il peut réduire les erreurs en orientant vers des valeurs sûres comme les plages temporelles, les environnements et des actions pré-approuvées. Les dashboards marchent bien pour des vues d'état d'équipe, des actions protégées qui demandent confirmation, et des explications intégrées sur ce que fait un bouton.
Quand c'est possible, utilisez le même backend API pour les deux. Placez l'auth, les limites de débit, les plafonds de requêtes et la journalisation d'audit dans cette API, pas dans l'UI. Alors le CLI et le dashboard deviennent des clients différents avec des ergonomies différentes.
Décidez aussi où ça tourne, car cela change le risque. Un CLI sur un portable peut fuir des tokens. L'exécuter sur un bastion ou dans un cluster interne peut réduire l'exposition et faciliter les logs et l'application des politiques.
Exemple : pour la recherche de logs, un CLI est idéal pour un ingénieur on-call qui veut les 10 dernières minutes pour un service. Un dashboard convient mieux pour une salle d'incident partagée où tout le monde a besoin de la même vue filtrée, plus une action guidée « exporter pour post-mortem » qui est soumise à vérification de permissions.
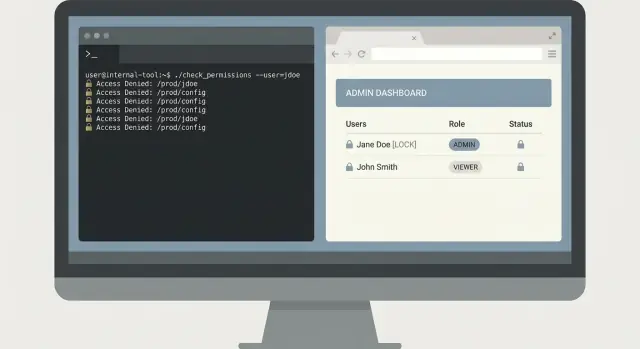
Un exemple réaliste : outil de recherche de logs pour l'on-call
Construisez le premier outil sûr
Transformez votre spécification CLI ou tableau de bord limité en code fonctionnel via une simple conversation.
Il est 02:10 et l'on-call reçoit le signal : « Le clic sur Pay échoue parfois pour un client. » Le support a une capture avec un request ID, mais personne ne veut coller des requêtes aléatoires dans un système de logs avec des permissions admin.
Un petit CLI peut résoudre cela en toute sécurité. L'essentiel est de garder la solution étroite : trouver l'erreur vite, n'afficher que l'essentiel et laisser les données de production inchangées.
Un flux CLI minimal
Commencez par une commande qui impose des limites temporelles et un identifiant spécifique. Exigez un request ID et une fenêtre temporelle, et par défaut une fenêtre courte.
oncall-logs search --request-id req_123 --since 30m --until now
Retournez d'abord un résumé : nom du service, classe d'erreur, nombre et les 3 messages correspondants les plus significatifs. Ensuite, proposez une étape explicite d'expansion qui affiche les lignes de log complètes uniquement si l'utilisateur le demande.
oncall-logs show --request-id req_123 --limit 20
Ce design en deux étapes évite les dumps accidentels de données. Il facilite aussi les revues parce que l'outil a un chemin sûr par défaut bien défini.
Action de suivi optionnelle (sans écritures)
L'on-call doit souvent laisser une trace pour la personne suivante. Plutôt que d'écrire en base, ajoutez une action optionnelle qui crée le payload d'une note de ticket ou applique un tag dans le système d'incidents, mais qui ne touche jamais les enregistrements clients.
Pour conserver le moindre privilège, le CLI doit utiliser un token de logs en lecture seule, et un token séparé et scindé pour l'action de ticket ou de tag.
Enregistrez une trace d'audit pour chaque exécution : qui l'a lancée, quel request ID, quelles bornes temporelles ont été utilisées et si les détails ont été étendus. Ce journal d'audit est votre filet de sécurité quand quelque chose tourne mal ou quand il faut vérifier des accès.
Erreurs fréquentes qui créent des problèmes de sécurité et de fiabilité
Les petits outils internes commencent souvent comme des « aides rapides ». C'est précisément pourquoi ils finissent avec des paramètres dangereux. La manière la plus rapide de perdre la confiance est un incident grave, comme un outil qui supprime des données alors qu'il était censé être en lecture seule.
Les erreurs qui reviennent le plus souvent :
- Donner à l'outil un accès en écriture à la base de production alors qu'il n'avait besoin que de lectures, puis se dire « on fera attention »
- Sauter la piste d'audit, si bien qu'ensuite on ne peut pas savoir qui a lancé une commande, avec quelles entrées et ce qui a changé
- Autoriser du SQL libre, des regex ou des filtres ad hoc qui scannent par accident des tables énormes ou des logs et mettent les systèmes à genoux
- Mélanger les environnements de sorte que des actions de staging atteignent la production parce que configs, tokens ou URLs de base sont partagés
- Afficher des secrets dans un terminal, une console navigateur ou des logs, puis oublier que ces sorties sont copiées dans des tickets et du chat
Un échec réaliste ressemble à ceci : un ingénieur on-call utilise un CLI de recherche de logs pendant un incident. L'outil accepte n'importe quelle regex et l'envoie au backend de logs. Un pattern coûteux parcourt des heures de logs à fort volume, fait exploser les coûts et ralentit les recherches pour tout le monde. Dans la même session, le CLI affiche un token API en mode debug, et il finit collé dans un document d'incident public.
Valeurs par défaut plus sûres qui empêchent la plupart des incidents
Traitez la lecture seule comme une vraie barrière de sécurité, pas comme une habitude. Utilisez des identifiants séparés par environnement et des comptes de service distincts par outil.
Quelques garde-fous suffisent dans la plupart des cas :
- Utiliser des requêtes allow-listées (ou des templates) au lieu de SQL libre, et plafonner les plages et le nombre de lignes
- Journaliser chaque action avec un request ID, l'identité de l'utilisateur, l'environnement cible et les paramètres exacts
- Exiger la sélection explicite d'environnement, avec une confirmation bien visible pour la production
- Réduire par défaut l'affichage des secrets et désactiver le debug sauf avec un flag privilégié
Si l'outil ne peut pas faire quelque chose de dangereux par conception, votre équipe n'aura pas à compter sur une attention parfaite à 3h du matin.
Checklist rapide avant de lancer l'outil
Planifiez avant de construire
Cartographiez les entrées, sorties et permissions avant de générer le code.
Avant que votre outil interne atteigne de vrais utilisateurs (surtout en on-call), traitez-le comme un service de production. Confirmez que les accès, permissions et limites de sécurité sont réels, pas implicites.
Commencez par l'accès et les permissions. Beaucoup d'accidents viennent du fait qu'un accès « temporaire » devient permanent, ou qu'un outil gagne silencieusement des pouvoirs d'écriture avec le temps.
- Auth et offboarding : confirmez qui peut se connecter, comment l'accès est accordé et comment il est révoqué le jour même où quelqu'un change d'équipe
- Rôles limités : gardez 2–3 rôles max (viewer, operator, admin) et écrivez ce que chaque rôle peut faire
- Lecture seule par défaut : faites de l'affichage le chemin par défaut et exigez un rôle explicite pour toute modification
- Gestion des secrets : stockez tokens et clés hors du repo et vérifiez que l'outil ne les imprime jamais dans les logs ou messages d'erreur
- Flux break-glass : si vous avez besoin d'un accès d'urgence, rendez-le limité dans le temps et journalisé
Puis validez les garde-fous qui empêchent les erreurs fréquentes :
- Confirmations pour actions risquées : exigez des confirmations typées pour suppressions, backfills ou changements de config
- Limites et timeouts : plafonnez la taille des résultats, imposez des fenêtres temporelles et coupez les requêtes qui tournent trop longtemps
- Validation des entrées : validez IDs, dates et noms d'environnement ; rejetez tout ce qui ressemble à « run everywhere »
- Logs d'audit : enregistrez qui a fait quoi, quand et d'où ; facilitez la recherche dans ces logs pendant un incident
- Métriques et erreurs basiques : suivez taux de succès, latence et types d'erreurs principaux pour repérer une régression tôt
Faites le contrôle des changements comme pour n'importe quel service : revue par un pair, quelques tests ciblés pour les chemins dangereux et un plan de rollback (y compris un moyen de désactiver rapidement l'outil si nécessaire).
Étapes suivantes : déployer prudemment et améliorer continuellement
Traitez la première version comme une expérience contrôlée. Commencez avec une équipe, un workflow et un petit ensemble de tâches réelles. Un outil de recherche de logs pour l'on-call est un bon pilote car vous pouvez mesurer le temps gagné et repérer rapidement les requêtes risquées.
Rendez le déploiement prévisible : pilotez avec 3 à 10 utilisateurs, commencez en staging, restreignez l'accès avec des rôles au moindre privilège (pas des tokens partagés), fixez des limites d'usage et enregistrez un audit pour chaque commande ou clic. Assurez-vous de pouvoir revenir rapidement sur des configs et permissions.
Écrivez le contrat de l'outil en langage clair. Listez chaque commande (ou action du dashboard), les paramètres autorisés, ce que signifie le succès et ce que signifient les erreurs. Les gens cessent de faire confiance aux outils internes quand les sorties semblent ambiguës, même si le code est correct.
Ajoutez une boucle de feedback que vous consultez vraiment. Suivez quelles requêtes sont lentes, quels filtres sont courants et quelles options déroutent. Quand vous voyez des contournements répétés, c'est souvent le signe que l'interface manque d'une valeur sûre.
La maintenance a besoin d'un propriétaire et d'un planning. Décidez qui met à jour les dépendances, qui fait pivoter les identifiants et qui est pagé si l'outil casse pendant un incident. Revoyez les changements générés par l'IA comme pour un service de production : diffs de permissions, sécurité des requêtes et journalisation.
Si votre équipe préfère itérer via le chat, Koder.ai (koder.ai) peut être un moyen pratique de générer un petit CLI ou dashboard depuis une conversation, garder des snapshots d'états connus bons et revenir rapidement quand un changement introduit un risque.