Ce que « Palantir » et « logiciel d'entreprise traditionnel » signifient ici
Les gens utilisent souvent « Palantir » comme abréviation pour quelques produits apparentés et une façon générale de concevoir des opérations pilotées par les données. Pour que cette comparaison reste claire, il est utile de préciser ce dont il est question — et ce qui n'en fait pas partie.
Ce que « Palantir » désigne dans cet article
Quand on parle de « Palantir » en contexte d'entreprise, on pense généralement à un (ou plusieurs) des éléments suivants :
- Foundry : la plateforme commerciale de Palantir, centrée sur l'intégration des données, leur modélisation et la prise de décision opérationnelle.
- Gotham : souvent associée aux usages défense et secteur public, avec des thèmes similaires mais une histoire et un positionnement différents.
- Apollo : un système de déploiement et de livraison utilisé pour distribuer et gérer le logiciel à travers de nombreux environnements (y compris restreints).
Dans cet article, « de type Palantir » décrit la combinaison de (1) forte intégration des données, (2) une couche sémantique/ontologique qui aligne les équipes sur le sens, et (3) des schémas de déploiement pouvant couvrir cloud, on‑prem et environnements déconnectés.
Ce que « logiciel d'entreprise traditionnel » signifie ici
« Logiciel d'entreprise traditionnel » n'est pas un produit unique — c'est la pile typique que beaucoup d'organisations assemblent au fil du temps, par exemple :
- ERP et CRM (systèmes de référence pour la finance, la chaîne d'approvisionnement, les ventes)
- Un entrepôt ou lac de données plus des tableaux de bord BI (reporting et analytique)
- Middleware d'intégration (outils ETL/ELT, iPaaS, files de messages, API)
Avec cette approche, l'intégration, l'analytique et les opérations sont souvent gérées par des outils et des équipes séparés, reliés par des projets et des processus de gouvernance.
Ce que cette comparaison est (et n'est pas)
C'est une comparaison d'approches, pas une recommandation de fournisseur. De nombreuses organisations réussissent avec des piles conventionnelles ; d'autres tirent parti d'un modèle de plateforme plus unifié.
La question pratique est : quels compromis faites‑vous en termes de vitesse, de contrôle et de la connexion directe entre l'analytique et le travail au quotidien ?
Pour rester concret, nous nous concentrerons sur trois domaines :
- Intégration des données : comment les données sont connectées, maintenues et prises en charge
- Analytique opérationnelle : comment l'analyse dépasse les tableaux de bord pour influer sur les décisions
- Modèles de déploiement : cloud, on‑prem et réalités déconnectées
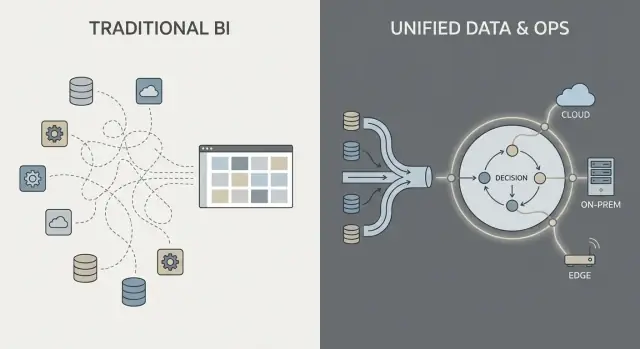
Intégration des données : pipelines et responsabilités
La plupart des travaux de données dans les piles traditionnelles suivent une chaîne familière : extraire les données des systèmes (ERP, CRM, logs), les transformer, les charger dans un entrepôt ou un lac, puis construire des tableaux de bord BI et quelques applications en aval.
Ce schéma peut fonctionner, mais il transforme souvent l'intégration en une série de transferts fragiles : une équipe possède les scripts d'extraction, une autre gère les modèles d'entrepôt, une troisième définit les tableaux de bord, et les équipes métier maintiennent des tableurs qui redéfinissent en douce « le vrai chiffre ».
Le schéma traditionnel : ETL/ELT comme relais
Avec l'ETL/ELT, les changements ont tendance à se propager. Un nouveau champ dans le système source peut casser un pipeline. Une « correction rapide » crée un second pipeline. Bientôt vous avez des métriques dupliquées (« revenu » en trois endroits), et il n'est pas clair qui est responsable quand les chiffres divergent.
Le traitement par lots est courant : les données arrivent chaque nuit, les tableaux de bord se rafraîchissent le matin. Le quasi‑temps réel est possible, mais il devient souvent une pile de streaming séparée avec ses propres outils et propriétaires.
Le schéma à la Palantir : intégrer, standardiser le sens, puis réutiliser partout
Une approche de type Palantir vise à unifier les sources et appliquer des sémantiques cohérentes (définitions, relations et règles) plus tôt, puis à exposer ces mêmes données soignées à l'analytique et aux workflows opérationnels.
En termes simples : au lieu que chaque tableau de bord ou application « comprenne » ce qu'est un client, un actif, un dossier ou une expédition, ce sens est défini une fois et réutilisé. Cela peut réduire la logique dupliquée et clarifier la propriété — car lorsqu'une définition change, vous savez où elle vit et qui l'approuve.
Points de douleur courants à surveiller
L'intégration échoue généralement sur les responsabilités, pas sur les connecteurs :
- Pipelines fragiles qui cassent pour de petits changements sources
- Métriques dupliquées définies différemment selon les équipes
- Propriété floue de la qualité des données, des définitions et des correctifs
La question clé n'est pas seulement « Peut‑on se connecter au système X ? » mais « Qui possède le pipeline, les définitions des métriques et le sens métier dans la durée ? »
Couche sémantique et ontologie : un centre de gravité différent
Le logiciel d'entreprise traditionnel traite souvent le « sens » comme une après‑pensée : les données sont stockées dans de nombreux schémas spécifiques aux applications, les définitions de métriques vivent dans des tableaux de bord individuels, et les équipes entretiennent en silence leurs propres versions de « ce qu'est une commande » ou « quand un dossier est clos ». Le résultat est familier — des chiffres différents selon les lieux, des réunions de réconciliation lentes, et une responsabilité floue quand quelque chose cloche.
L'ontologie, expliquée simplement
Dans une approche de type Palantir, la couche sémantique n'est pas qu'un confort pour le reporting. Une ontologie agit comme un modèle métier partagé qui définit :
- Entités (ce qui compte pour votre entreprise) : Commande, Client, Actif, Expédition, Dossier
- Relations (comment ces éléments se lient) : une Commande appartient à un Client ; une Expédition satisfait une Commande ; un Actif est installé à un Site
- Actions (ce que l'on fait avec eux) : approuver, dispatcher, escalader, retirer, rembourser
Cela devient le « centre de gravité » pour l'analytique et les opérations : plusieurs sources de données peuvent exister, mais elles se cartographient vers un même jeu d'objets métier avec des définitions cohérentes.
Pourquoi la sémantique importe plus qu'on ne le pense
Un modèle partagé réduit les chiffres discordants parce que les équipes n'inventent pas de définitions à chaque rapport ou application. Il améliore aussi la responsabilité : si « Livraison à temps » est définie sur la base des événements d'Expédition dans l'ontologie, il est plus clair qui possède les données sous‑jacentes et la logique métier.
Exemples concrets faciles à imaginer
- Commandes : ventes, finance et support consultent le même objet Commande, incluant statut, valeur, approbations et exceptions — pas de « tables de commandes » séparées par département.
- Actifs : maintenance, opérations et conformité partagent un enregistrement Actif avec localisation, historique d'inspection et indicateurs de risque.
- Dossiers : les dossiers support se relient aux clients, commandes et expéditions, de sorte que les règles d'escalade et les métriques de service ne divergent pas selon les équipes.
Bien faite, une ontologie ne rend pas seulement les tableaux de bord plus propres — elle accélère les décisions quotidiennes et réduit les disputes.
Analytique opérationnelle vs tableaux de bord BI
Les tableaux de bord BI et le reporting traditionnel concernent principalement le retrospectif et le monitoring. Ils répondent à des questions comme « Que s'est‑il passé la semaine dernière ? » ou « Sommes‑nous dans les clous par rapport aux KPI ? » Un tableau de ventes, un rapport de clôture financière ou un tableau de bord exécutif a sa valeur — mais s'arrête souvent à la visibilité.
L'analytique opérationnelle est différente : c'est de l'analytique intégrée dans les décisions et l'exécution quotidiennes. Au lieu d'une « destination analytique » séparée, l'analyse apparaît dans le flux de travail où le travail est réalisé, et elle déclenche une étape suivante précise.
BI : observer et expliquer
Le BI/reporting se concentre typiquement sur :
- Des métriques standardisées et des définitions de KPI
- Des rafraîchissements programmés et des revues hebdo/mensuelles
- Des vues agrégées (équipes, régions, périodes)
- L'exploration des causes après que les résultats sont connus
C'est excellent pour la gouvernance, la gestion de la performance et la responsabilité.
Analytique opérationnelle : décider et agir
L'analytique opérationnelle met l'accent sur :
- Des signaux en temps réel ou quasi‑temps réel
- L'aide à la décision au moment même de l'action
- Des recommandations, des priorisations et la gestion des exceptions
- Des boucles de feedback (l'action a‑t‑elle fonctionné et qu'est‑ce qui a changé ?)
Des exemples concrets ressemblent moins à « un graphique » et davantage à une liste de travail contextualisée :
- Dispatching : choisir quelle équipe envoyer en fonction de la localisation, des compétences, du SLA et de la disponibilité des pièces
- Allocation d'inventaire : décider où affecter un stock limité pour réduire les ruptures et les livraisons manquées
- Triage de fraude : classer les dossiers par risque et les router aux enquêteurs avec les preuves attachées
- Planification de maintenance : prédire les pannes et programmer des arrêts en tenant compte des contraintes de production
Le changement clé : passer de « voir » à « agir »
Le changement le plus important est que l'analyse est liée à une étape précise du workflow. Un tableau BI peut indiquer « les livraisons en retard augmentent ». L'analytique opérationnelle transforme cela en « voici les 37 expéditions à risque aujourd'hui, les causes probables et les interventions recommandées », avec la possibilité d'exécuter ou d'assigner l'action suivante immédiatement.
Des insights aux actions : conception centrée sur le workflow
L'analytique d'entreprise traditionnelle s'arrête souvent au tableau de bord : quelqu'un repère un problème, exporte en CSV, envoie un e‑mail, et une équipe séparée « fait quelque chose » plus tard. Une approche de type Palantir cherche à raccourcir cet écart en intégrant l'analytique directement dans le workflow où les décisions sont prises.
Décisions human-in-the-loop (pas de pilotage automatique)
Les systèmes centrés sur le workflow génèrent typiquement des recommandations (par ex. « prioriser ces 12 expéditions », « signaler ces 3 fournisseurs », « programmer la maintenance sous 72 heures ») mais nécessitent encore des validations explicites. Cette étape d'approbation importe car elle crée :
- Responsabilité des décisions : qui a approuvé, quand, et sur quelle base de données
- Pistes d'audit : une chaîne enregistrée depuis les données d'entrée → logique/modèle → recommandation → action
- Exceptions contrôlées : les opérateurs peuvent outrepasser avec une raison, plutôt que de contourner l'outil
C'est particulièrement utile dans les opérations régulées ou critiques où « le modèle l'a dit » n'est pas une justification acceptable.
Les workflows remplacent le « transfert de rapport »
Au lieu de considérer l'analytique comme une destination séparée, l'interface peut rediriger les insights en tâches : assigner à une file, demander une validation, déclencher une notification, ouvrir un dossier ou créer un ordre de travail. L'important est que les résultats soient suivis dans le même système — vous pouvez donc mesurer si les actions ont réellement réduit le risque, le coût ou les délais.
Expériences par rôle et droits de décision
La conception centrée sur le workflow sépare d'habitude les expériences par rôle :
- Opérateurs de première ligne : files rapides, action recommandée, contexte minimal requis
- Analystes : exploration approfondie, tests de scénarios et surveillance qualité des données/modèles
- Dirigeants : KPI liés au flux opérationnel et aux goulets d'étranglement, pas seulement des graphiques
Le facteur de succès commun est d'aligner le produit sur les droits de décision et les procédures opérationnelles : qui peut agir, quelles approbations sont requises et ce que signifie « terminé » opérationnellement.
Gouvernance, sécurité et confiance dans les données
UX opérationnelle en React
Créez une interface web qui passe de l'analyse à l'action, pas seulement des graphiques.
La gouvernance est souvent l'endroit où les programmes d'analytique réussissent ou échouent. Ce n'est pas seulement des « paramètres de sécurité » — ce sont les règles pratiques et les preuves qui permettent aux gens de faire confiance aux chiffres, de les partager en toute sécurité et de s'en servir pour prendre de vraies décisions.
Ce que la gouvernance doit couvrir (au‑delà de l'authentification)
La plupart des entreprises ont besoin des mêmes contrôles de base, quel que soit le fournisseur :
- Contrôles d'accès : qui peut voir, modifier ou approuver des données, des modèles et des résultats opérationnels
- Traçabilité des données : d'où provient une métrique, quelles sources l'ont alimentée et quelles transformations ont eu lieu
- Journaux d'audit : un enregistrement défendable de qui a changé quoi et quand
- Approbations et contrôle des changements : notamment pour les métriques « officielles », les jeux de données partagés et les workflows en production
Ce ne sont pas de la bureaucratie pour elle‑même. Ce sont des moyens d'éviter le problème des « deux versions de la vérité » et de réduire le risque quand l'analytique se rapproche des opérations.
« Sécurité au niveau du tableau de bord » vs sécurité sur toute la chaîne
Les implémentations BI traditionnelles placent souvent la sécurité principalement au niveau du rapport : les utilisateurs peuvent voir certains tableaux de bord, et les administrateurs gèrent les permissions à cet endroit. Cela peut suffire quand l'analytique est surtout descriptive.
Une approche de type Palantir étend la sécurité et la gouvernance à toute la chaîne : depuis l'ingestion brute, la couche sémantique (objets, relations, définitions), les modèles, et jusqu'aux actions déclenchées par les insights. L'objectif est qu'une décision opérationnelle (dispatcher une équipe, libérer un stock, prioriser des dossiers) hérite des mêmes contrôles que les données qui la sous‑tendent.
Principe du moindre privilège et séparation des tâches (en termes simples)
Deux principes importent pour la sécurité et la responsabilité :
- Moindre privilège : les personnes n'ont que l'accès nécessaire à leur travail
- Séparation des tâches : la personne qui construit ou modifie la logique n'est pas la même qui l'approuve pour la production
Par exemple, un analyste peut proposer une définition de métrique, un steward des données l'approuve, et les opérations l'utilisent — avec une piste d'audit claire.
Pourquoi la gouvernance favorise l'adoption
Une bonne gouvernance n'est pas réservée aux équipes conformité. Quand les utilisateurs métier peuvent consulter la traçabilité, voir les définitions et compter sur des permissions cohérentes, ils cessent de débattre autour du tableur et commencent à agir sur l'insight. Cette confiance transforme l'analytique de « rapports intéressants » en comportement opérationnel.
Modèles de déploiement : cloud, on‑prem et environnements déconnectés
Le lieu d'exécution du logiciel d'entreprise n'est plus un détail IT — il détermine ce que vous pouvez faire avec les données, la rapidité des changements et les risques acceptables. Les acheteurs évaluent généralement quatre modèles de déploiement.
Cloud public
Le cloud public (AWS/Azure/GCP) privilégie la vitesse : le provisionnement est rapide, les services managés réduisent le travail infra, et la montée en charge est simple. Les questions principales pour l'acheteur sont la résidence des données (quelle région, quelles sauvegardes, quel accès support), l'intégration aux systèmes on‑prem et si votre modèle de sécurité peut tolérer la connectivité réseau cloud.
Cloud privé
Un cloud privé (mono‑locataire ou Kubernetes/VMs gérés par le client) est souvent choisi quand on veut l'automatisation du cloud mais un contrôle plus strict des frontières réseau et des exigences d'audit. Il réduit certaines frictions de conformité, mais demande toujours une discipline opérationnelle forte pour les correctifs, la supervision et les revues d'accès.
On‑prem
Les déploiements on‑prem restent courants dans la fabrication, l'énergie et les secteurs fortement régulés où les systèmes et les données ne peuvent pas quitter l'installation. Le compromis est un surcoût opérationnel : cycle de vie du matériel, planification de capacité et plus de travail pour garder la cohérence entre dev/test/prod. Si votre organisation a du mal à exploiter des plateformes de façon fiable, l'on‑prem peut ralentir le time‑to‑value.
Déconnecté / air‑gapped
Les environnements déconnectés (air‑gapped) sont un cas particulier : défense, infrastructures critiques ou sites avec connectivité limitée. Là, le modèle de déploiement doit supporter des contrôles stricts de mise à jour — artefacts signés, promotion contrôlée des releases et installation répétable en réseaux isolés.
Les contraintes réseau affectent aussi le mouvement des données : au lieu d'une synchronisation continue, vous pouvez dépendre de transferts par étapes et de workflows d'« export/import ».
Les compromis clés
En pratique, c'est un triangle : flexibilité (cloud), contrôle (on‑prem/air‑gapped) et vitesse de changement (automatisation + mises à jour). Le bon choix dépend des règles de résidence, des réalités réseau et de la part d'exploitation de la plateforme que votre équipe est prête à prendre en charge.
Opérationnaliser les mises à jour : ce que la livraison type Apollo change
Essayez Koder.ai aujourd'hui
Utilisez le plan gratuit pour tester votre premier workflow sans configuration longue.
La livraison « à la manière d'Apollo » est essentiellement de la livraison continue pour des environnements à enjeux : vous pouvez déployer des améliorations fréquemment (hebdomadaire, quotidien, voire plusieurs fois par jour) tout en maintenant la stabilité opérationnelle.
L'objectif n'est pas « avancer vite et tout casser ». C'est « avancer souvent et ne rien casser ».
Livraison continue en termes simples
Au lieu de regrouper les changements dans une grosse release trimestrielle, les équipes livrent des mises à jour petites et réversibles. Chaque mise est plus facile à tester, à expliquer et à annuler si nécessaire.
Pour l'analytique opérationnelle, c'est crucial car votre « logiciel » n'est pas seulement une UI — ce sont des pipelines de données, de la logique métier et des workflows sur lesquels les gens comptent. Un processus de mise à jour plus sûr devient partie intégrante des opérations quotidiennes.
En quoi cela diffère des cycles traditionnels
Les mises à jour logicielles traditionnelles ressemblent souvent à des projets : longues fenêtres de planification, coordination des arrêts, compatibilité, formation et date de bascule. Même lorsque des correctifs existent, beaucoup d'organisations retardent les mises à jour car le risque et l'effort sont imprévisibles.
Les outils de type Apollo cherchent à rendre la mise à niveau routinière plutôt qu'exceptionnelle — davantage comme la maintenance d'infrastructure que comme une migration majeure.
Séparer « construire » et « livrer »
Les outils modernes permettent aux équipes de développer et tester dans des environnements isolés, puis de « promouvoir » la même build à travers des étapes (dev → test → staging → production) avec des contrôles cohérents. Cette séparation réduit les surprises de dernière minute causées par des différences entre environnements.
Questions à poser aux fournisseurs
- Comment gérez‑vous le rollback — en un clic, partiel, ou via des étapes de récupération complexes ?
- Quel versioning existe pour les pipelines, modèles et changements d'ontologie (pas seulement l'UI) ?
- Comment fonctionne la promotion d'environnements, et qui peut l'approuver ?
- Pouvez‑vous exécuter des déploiements canaris (un sous‑ensemble d'abord) ou des feature flags ?
- Quel journal d'audit montre qui a livré quoi, quand et pourquoi ?
- Quel est le temps d'indisponibilité attendu — idéalement nul — pour des mises à jour classiques ?
Mise en œuvre et time‑to‑value : ce qui demande réellement des efforts
Le time‑to‑value tient moins à la rapidité d'« installation » et plus à la vitesse à laquelle les équipes s'accordent sur les définitions, connectent des données désordonnées, et transforment les insights en décisions quotidiennes.
Le logiciel d'entreprise traditionnel met souvent l'accent sur la configuration : vous adoptez un modèle de données et des workflows prédéfinis, puis cartographiez votre métier dessus.
Les plateformes de type Palantir mélangent en général trois modes :
- Configuration pour les contrôles d'accès, connexions de données et composants standards
- Blocs réutilisables (templates, composants, patterns) assemblables pour de nouveaux cas d'usage
- Développement d'applications sur mesure quand le workflow est unique (ex. : approbations, gestion des exceptions, transferts opérationnels)
La promesse est la flexibilité — mais cela signifie aussi qu'il faut clarifier ce que vous construisez vs ce que vous standardisez.
Une option pratique en phase de découverte est de prototyper rapidement des applications de workflow avant de s'engager sur un gros déploiement. Par exemple, certaines équipes utilisent Koder.ai (plateforme vibe‑coding) pour transformer une description de workflow en une application web fonctionnelle via conversation, puis itérer avec les parties prenantes en mode planning, snapshots et rollback. Comme Koder.ai permet l'export du code source et des stacks de production typiques (React sur le web ; Go + PostgreSQL en backend ; Flutter pour mobile), cela peut être un moyen peu contraignant de valider l'UX « insight → tâche → piste d'audit » lors d'un proof‑of‑value.
Où les équipes passent réellement du temps
La plupart des efforts se concentrent généralement sur quatre axes :
- Onboarding des données : obtenir l'accès des propriétaires de sources, documenter les champs, gérer les lacunes de qualité et définir les attentes de rafraîchissement
- Modélisation et sémantique : s'accorder sur les définitions métier (ce qui compte comme « actif », « en retard », « disponible ») et les maintenir cohérentes
- Conception des workflows : décider qui intervient sur les alertes, quelles décisions sont autorisées et ce que signifie « terminé »
- Formation et adoption : transformer l'outil en habitude — surtout pour les utilisateurs de première ligne qui n'accepteront pas la complexité
Signaux d'alarme qui ralentissent ou tuent la valeur
Surveillez la propriété floue (aucun propriétaire data/produit désigné), trop de définitions sur mesure (chaque équipe invente ses propres métriques), et aucun chemin du pilote à l'échelle (une démo qui ne peut pas être opérationnalisée, supportée ou gouvernée).
Structurer un pilote qui peut monter en charge
Un bon pilote est volontairement étroit : choisissez un workflow, définissez des utilisateurs spécifiques, et engagez‑vous sur un résultat mesurable (ex. réduire le délai de traitement de 15 %, diminuer le backlog d'exceptions de 30 %). Concevez le pilote pour que les mêmes données, la même sémantique et les mêmes contrôles puissent s'étendre au cas d'usage suivant — plutôt que de tout recommencer.
Les conversations sur les coûts peuvent devenir confuses car une « plateforme » regroupe des capacités souvent achetées séparément. L'essentiel est d'aligner la tarification sur les résultats attendus (intégration + modélisation + gouvernance + applications opérationnelles), pas seulement sur une ligne intitulée « logiciel ».
La plupart des contrats plateforme sont influencés par quelques variables :
- Nombre d'utilisateurs et rôles : builders (ingénieurs, modélisateurs) vs consommateurs (opérateurs, analystes)
- Calcul et stockage : charges plus lourdes (données temps réel, simulations, jointures larges) augmentent le coût infra
- Nombre d'environnements : dev/test/prod, plus les environnements régulés ou déconnectés multiplient la charge
- Exigences de support et de disponibilité : support 24/7, SLA incidents et équipes dédiées modifient le prix
- Services professionnels : onboarding initial des données, conception d'ontologie et construction des workflows sont souvent le principal poste de coût initial
Ce que les coûts de la pile traditionnelle cachent
Une approche par solutions ponctuelles peut sembler moins chère au départ, mais le coût total s'étale souvent sur :
- Plusieurs licences (ETL/ELT, BI, catalogue, gouvernance, workflow, feature store, etc.)
- Travail d'intégration entre outils (connecteurs, identité, synchronisation des métadonnées)
- Maintenance continue (mises à jour, pipelines cassés, définitions de métriques dupliquées)
Les plateformes réduisent souvent la dispersion d'outils, mais vous échangez cela contre un contrat plus large et stratégique.
Avec une plateforme, l'achat doit la traiter comme une infrastructure partagée : définissez la portée entreprise, les domaines de données, les exigences de sécurité et les jalons de livraison. Demandez une séparation claire entre licence, cloud/infrastructure et services, pour pouvoir comparer de manière équitable.
Checklist budgétaire simple
- Quelles équipes construiront activement vs se contenteront de consulter ?
- Quels workflows doivent fonctionner en production (pas seulement des tableaux de bord) ?
- Combien d'environnements et de régions sont requis ?
- Y a‑t‑il des sites air‑gapped ou hors ligne ?
- Croissance attendue du volume de données / fréquence de rafraîchissement ?
- Services nécessaires pour les 90 premiers jours ?
Si vous voulez un moyen rapide de structurer des hypothèses, voyez /pricing.
Quand une approche de type Palantir convient (et quand elle ne convient pas)
Rendre le sens cohérent
Modélisez Orders, Assets et Cases comme des objets partagés que vos équipes peuvent réutiliser.
Les plateformes de type Palantir excellent quand le problème est opérationnel (les personnes doivent prendre des décisions et agir à travers des systèmes), pas seulement analytique (les personnes ont besoin d'un rapport). Le compromis est que vous adoptez un style plus « plateforme » — puissant, mais qui demande plus à votre organisation qu'un simple déploiement BI.
Scénarios où l'approche convient bien
Une approche de type Palantir est souvent adaptée lorsque le travail traverse plusieurs systèmes et équipes et que vous ne pouvez pas vous permettre des transferts fragiles.
Exemples courants : opérations inter‑systèmes comme la coordination de la chaîne d'approvisionnement, la lutte contre la fraude et les opérations de risque, la planification de mission, la gestion de dossiers, ou les workflows de flotte et de maintenance — là où les mêmes données doivent être interprétées de façon cohérente par des rôles différents.
Elle convient aussi quand les permissions sont complexes (accès ligne/colonne, règles need‑to‑know) et quand vous avez besoin d'une piste d'audit claire sur l'utilisation des données. Enfin, elle s'adapte bien aux environnements régulés ou contraints : exigences on‑prem, déploiements air‑gapped ou accréditations de sécurité strictes où le modèle de déploiement est une exigence prioritaire.
Scénarios moins adaptés
Si l'objectif est surtout du reporting simple — KPI hebdomadaires, quelques tableaux de bord, rapprochements financiers basiques — une BI traditionnelle sur un entrepôt bien géré peut être plus rapide et moins coûteuse.
C'est aussi disproportionné pour de petits jeux de données, des schémas stables ou une analytique mono‑départementale où une équipe contrôle les sources et définitions, et où l'action principale a lieu en dehors de l'outil.
Critères de décision (adapter au problème)
Posez trois questions pratiques :
- Urgence : les équipes ont‑elles besoin de workflows opérationnels en quelques semaines, ou est‑ce un long programme de modernisation ?
- Complexité des données : les décisions clés sont‑elles bloquées par des définitions incohérentes et des sources fragmentées ?
- Capacité de changement : avez‑vous la propriété produit, les SME et la bande passante gouvernance pour adopter une plateforme et la maintenir à jour ?
Les meilleurs résultats viennent d'une approche « adapter au problème », pas d'une attente « un outil remplace tout ». Beaucoup d'organisations conservent la BI existante pour le reporting large tout en utilisant une approche de type Palantir pour les domaines opérationnels les plus critiques.
Checklist pour l'acheteur et prochaines étapes
Acheter une plateforme « de type Palantir » vs un logiciel d'entreprise traditionnel porte moins sur les cases à cocher fonctionnelles que sur l'endroit où le vrai travail tombera : intégration, sens partagé (sémantique) et usage opérationnel quotidien. Utilisez la checklist ci‑dessous pour clarifier tôt, avant de vous enfermer dans une mise en œuvre longue ou un outil ponctuel restreint.
Checklist pratique de comparaison fournisseurs
Demandez à chaque fournisseur d'être précis sur qui fait quoi, comment cela reste cohérent et comment c'est utilisé en opérations réelles.
- Effort d'intégration : quelles sources sont typiques (ERP, logs, tableurs, flux partenaires) ? Qu'est‑ce qui est préconstruit vs sur mesure ? Qui maintient les pipelines après le go‑live — IT, ingénierie data ou le fournisseur ?
- Cohérence sémantique : comment empêchent‑ils cinq équipes de définir « client », « actif » ou « prêt‑à‑mission » différemment ? Peuvent‑ils montrer une couche métier gouvernée (ontologie/modèle sémantique) et comment les changements se propagent ?
- Support des workflows : les équipes de terrain peuvent‑elles compléter une tâche (triage, approbation, dispatch, enquête) dans le produit, ou faut‑il « analyser ici, agir ailleurs » ? Comment gèrent‑ils les exceptions ?
- Gouvernance et sécurité : contrôles d'accès granulaires, journaux d'audit et gestion des politiques — les propriétaires de données peuvent‑ils contrôler qui voit quoi, à quel niveau, et pourquoi ?
- Contraintes de déploiement : peut‑il tourner dans votre environnement requis (cloud, on‑prem, air‑gapped/déconnecté) ? Qu'est‑ce qui casse quand la connectivité est limitée ? Quel est le chemin de mise à jour ?
Questions de preuve pour les démos (pas de slides)
- Montrer la traçabilité : choisissez un KPI critique et tracez‑le depuis la source jusqu'à la métrique finale. Où peut‑il être erroné, et comment le détecteriez‑vous ?
- Démontrer un workflow de bout en bout : commencez par des données brutes, puis alerte → décision → action → piste d'audit. Incluez approbations et « qui a changé quoi ».
- Simuler une panne/rollback : que se passe‑t‑il si un pipeline échoue ou qu'une release provoque une régression ? Peuvent‑ils revenir en arrière proprement, et à quelle vitesse ?
Qui doit être dans la salle
Incluez les parties prenantes qui vivront les compromis :
- IT et propriétaires de plateforme (propriété de l'intégration, fiabilité, coût)
- Sécurité et conformité (contrôles, audit, approbations de déploiement)
- Propriétaires/stewards des données (définitions, règles d'accès, responsabilité)
- Leaders opérationnels (impact sur le processus, adoption)
- Utilisateurs de première ligne (l'outil les aide‑t‑il vraiment à faire le travail plus vite ?)
Prochaines étapes
Lancez un proof‑of‑value limité dans le temps centré sur un workflow opérationnel à enjeu (pas un tableau de bord générique). Définissez les critères de succès à l'avance : temps de décision, réduction d'erreurs, auditabilité et propriété continue du travail data.
Si vous voulez des conseils supplémentaires sur les schémas d'évaluation, voyez /blog. Pour de l'aide pour cadrer un proof‑of‑value ou présélectionner des fournisseurs, contactez‑nous via /contact.