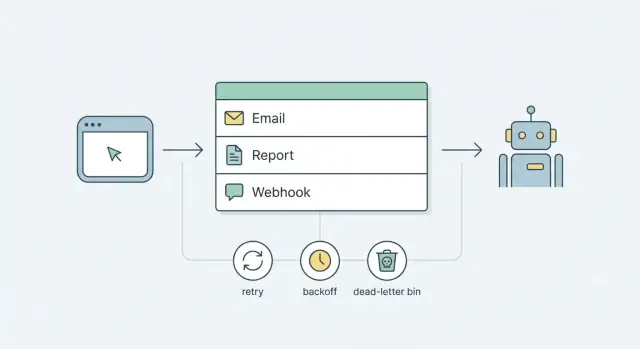
Pourquoi vous avez besoin de tâches en arrière-plan (et pourquoi ça devient vite compliqué)
Tout travail qui peut prendre plus d'une ou deux secondes ne devrait pas s'exécuter dans une requête utilisateur. Envoyer des e-mails, générer des rapports et livrer des webhooks dépendent souvent du réseau, de services tiers ou de requêtes lentes. Parfois ils se pauseront, échoueront ou prendront plus de temps que prévu.
Si vous faites ce travail pendant que l'utilisateur attend, il le remarque tout de suite. Les pages se bloquent, le bouton "Enregistrer" tourne, et les requêtes expirent. Les retries peuvent aussi se produire au mauvais endroit : l'utilisateur rafraîchit, votre load balancer retente, ou le frontend renvoie le formulaire, et vous vous retrouvez avec des e-mails en double, des webhooks dupliqués ou deux runs de rapport qui se concurrencent.
Les tâches en arrière-plan règlent cela en gardant les requêtes petites et prévisibles : acceptez l'action, enregistrez un job à exécuter plus tard, répondez rapidement. Le job s'exécute hors de la requête, avec des règles que vous contrôlez.
La partie difficile est la fiabilité. Une fois le travail sorti du chemin de la requête, il faut toujours répondre à des questions comme :
- Et si le fournisseur d'e-mails est en panne pendant 3 minutes ?
- Et si un endpoint webhook renvoie 500, ou timeoute ?
- Et si le job s'exécute deux fois ?
- Comment remarquer les jobs bloqués avant que les utilisateurs se plaignent ?
Beaucoup d'équipes réagissent en ajoutant une "infrastructure lourde" : un broker de messages, des flottes de workers séparées, des dashboards, de l'alerte et des playbooks. Ces outils sont utiles quand vous en avez vraiment besoin, mais ils ajoutent aussi des pièces en mouvement et de nouveaux modes de défaillance.
Un meilleur objectif de départ est plus simple : des jobs fiables en utilisant ce que vous avez déjà. Pour la plupart des produits, cela signifie une queue basée sur la base de données et un petit processus worker. Ajoutez une stratégie claire de retry et de backoff, et un patron dead-letter pour les jobs qui échouent continuellement. Vous obtenez un comportement prévisible sans adopter une plateforme complexe dès le jour 1.
Même si vous construisez rapidement avec un outil piloté par chat comme Koder.ai, cette séparation reste importante. Les utilisateurs doivent obtenir une réponse rapide maintenant, et votre système doit finir le travail lent et sujet aux erreurs en toute sécurité en arrière-plan.
Ce qu'est une queue en termes simples
Une queue est une file d'attente pour du travail. Plutôt que d'effectuer des tâches lentes ou peu fiables pendant une requête utilisateur (envoyer un e-mail, construire un rapport, appeler un webhook), vous déposez un petit enregistrement dans une queue et répondez rapidement. Plus tard, un processus séparé récupère cet enregistrement et exécute le travail.
Quelques mots que vous verrez souvent :
- Job : une unité de travail, par exemple "envoyer l'e-mail de bienvenue à l'utilisateur 123".
- Worker : le code qui prend les jobs et les exécute.
- Attempt : une tentative d'exécution d'un job.
- Schedule : quand le job doit s'exécuter (maintenant, ou plus tard).
- Queue : où les jobs attendent jusqu'à ce qu'un worker les prenne.
Le flux le plus simple ressemble à ceci :
-
Enqueue : votre app sauvegarde un enregistrement de job (type, payload, horaire).
-
Claim : un worker trouve le job disponible suivant et le "locke" pour qu'un seul worker l'exécute.
-
Run : le worker réalise la tâche (envoi, génération, livraison).
-
Finish : marquez-le comme terminé, ou enregistrez un échec et définissez la prochaine exécution.
Si votre volume de jobs est modeste et que vous avez déjà une base de données, une queue basée sur la base de données suffit souvent. C'est simple à comprendre, facile à déboguer, et répond aux besoins courants comme le traitement des e-mails et la fiabilité de livraison des webhooks.
Les plateformes de streaming deviennent pertinentes quand vous avez un très haut débit, beaucoup de consommateurs indépendants, ou la capacité de rejouer de grandes histoires d'événements à travers de nombreux systèmes. Si vous exécutez des dizaines de services avec des millions d'événements par heure, des outils comme Kafka aident. D'ici là, une table DB plus une boucle worker couvre une grande partie des queues en pratique.
Les données minimales à suivre pour chaque job
Une queue en base reste saine si chaque enregistrement de job répond rapidement à trois questions : quoi faire, quand retenter, et ce qui s'est passé la dernière fois. Faites cela et les opérations deviennent ennuyeuses (ce qui est l'objectif).
Ce qu'il faut stocker dans le payload (et ce qu'il faut éviter)
Stockez le plus petit input nécessaire pour faire le travail, pas la sortie entièrement rendue. De bons payloads sont des IDs et quelques paramètres, comme { "user_id": 42, "template": "welcome" }.
Évitez de stocker de gros blobs (HTML complet des e-mails, grandes données de rapport, corpos volumineux de webhooks). Ça fait grossir la base de données et complique le débogage. Si le job a besoin d'un gros document, stockez une référence : report_id, export_id, ou une clé de fichier. Le worker pourra récupérer les données complètes à l'exécution.
Les champs qui en valent la peine
Au minimum, prévoyez :
- job_type + payload :
job_type sélectionne le handler (send_email, generate_report, deliver_webhook). payload contient de petits inputs comme des IDs et options.
- status : gardez-le explicite (par exemple :
queued, running, succeeded, failed, dead).
- suivi des tentatives :
attempt_count et max_attempts pour arrêter les retries quand ça n'a clairement pas de sens.
- champs temporels :
created_at et next_run_at (quand il devient éligible). Ajoutez started_at et finished_at si vous voulez une meilleure visibilité sur les jobs lents.
- idempotence + dernière erreur : une
idempotency_key pour éviter les effets doubles, et last_error pour voir pourquoi ça a échoué sans fouiller des tonnes de logs.
L'idempotence semble technique, mais l'idée est simple : si le même job s'exécute deux fois, la seconde exécution doit détecter et ne rien faire de dangereux. Par exemple, un job de livraison webhook peut utiliser une clé d'idempotence comme webhook:order:123:event:paid pour ne pas livrer deux fois le même événement si un retry chevauche un timeout.
Capturez aussi quelques nombres basiques dès le départ. Vous n'avez pas besoin d'un grand dashboard pour commencer, juste des requêtes qui indiquent : combien de jobs sont en queue, combien échouent, et l'âge du job le plus ancien en file.
Pas à pas : une queue simple en base à construire aujourd'hui
Si vous avez déjà une base de données, vous pouvez démarrer une queue en arrière-plan sans ajouter d'infra supplémentaire. Les jobs sont des lignes, et un worker est un processus qui continue de prendre les lignes dues et de faire le travail.
1) Créez une table jobs
Gardez la table petite et ennuyeuse. Vous voulez assez de champs pour exécuter, retenter et déboguer plus tard.
CREATE TABLE jobs (
id bigserial PRIMARY KEY,
job_type text NOT NULL,
payload jsonb NOT NULL,
status text NOT NULL DEFAULT 'queued',
attempts int NOT NULL DEFAULT 0,
next_run_at timestamptz NOT NULL DEFAULT now(),
locked_at timestamptz,
locked_by text,
last_error text,
created_at timestamptz NOT NULL DEFAULT now(),
updated_at timestamptz NOT NULL DEFAULT now()
);
CREATE INDEX jobs_due_idx ON jobs (status, next_run_at);
Si vous êtes sur Postgres (commun avec des backends Go), jsonb est pratique pour stocker des données de job comme { "user_id":123,"template":"welcome" }.
2) Enqueuez en toute sécurité (surtout pour les actions utilisateur)
Quand une action utilisateur doit déclencher un job (envoyer un e-mail, déclencher un webhook), écrivez la ligne de job dans la même transaction que le changement principal quand c'est possible. Cela empêche le cas "utilisateur créé mais job manquant" si un crash survient juste après l'écriture principale.
Exemple : quand un utilisateur s'inscrit, insérez la ligne utilisateur et un job send_welcome_email dans une seule transaction.
3) Exécutez une boucle worker qui peut monter en charge
Un worker répète le même cycle : trouver un job dû, le réclamer pour que personne d'autre ne le prenne, le traiter, puis le marquer terminé ou programmer un retry.
En pratique, cela signifie :
- Choisir un job où
status='queued' et next_run_at <= now().
- Le réclamer de façon atomique (en Postgres,
SELECT ... FOR UPDATE SKIP LOCKED est courant).
- Définir
status='running', locked_at=now(), locked_by='worker-1'.
- Traiter le job.
- Le marquer terminé (par exemple
done/succeeded), ou enregistrer last_error et planifier la tentative suivante.
Plusieurs workers peuvent tourner en même temps. L'étape de claim empêche le double-pick.
4) Gérer l'arrêt sans casser les jobs
À l'arrêt, cessez de prendre de nouveaux jobs, terminez celui en cours, puis quittez. Si un processus meurt en plein job, appliquez une règle simple : traitez les jobs running bloqués au-delà d'un timeout comme éligibles à être re-queueés par une tâche périodique "reaper".
Si vous construisez sur Koder.ai, ce patron DB-queue est un choix par défaut solide pour les e-mails, rapports et webhooks avant d'ajouter des services spécialisés.
Retries et backoff qui n'engendrent pas le chaos
Posséder votre implémentation de queue
Obtenez le code source complet de votre queue et worker pour que votre équipe puisse l'étendre.
Les retries permettent à une queue de rester calme quand le monde réel est désordonné. Sans règles claires, les retries deviennent une boucle bruyante qui spamme les utilisateurs, martèle les APIs et masque le vrai bug.
Commencez par décider ce qui doit être retenté et ce qui doit échouer vite.
Retentez les problèmes temporaires : timeouts réseau, erreurs 502/503, limites de débit, ou un petit incident de connexion DB.
Échouez vite quand le job ne réussira pas : adresse e-mail manquante, 400 d'un webhook parce que le payload est invalide, ou une demande de rapport pour un compte supprimé.
Le backoff est la pause entre les tentatives. Le backoff linéaire (5s, 10s, 15s) est simple, mais peut créer des vagues de trafic. Le backoff exponentiel (5s, 10s, 20s, 40s) répartit mieux la charge et est généralement plus sûr pour les webhooks et fournisseurs tiers. Ajoutez du jitter (un petit délai aléatoire) pour éviter qu'un millier de jobs ne retentent à la même seconde après une panne.
Règles qui se comportent bien en production :
- Retry uniquement sur des erreurs manifestement temporaires (timeouts, 429, 5xx).
- Utilisez un backoff exponentiel avec jitter.
- Couvrez les tentatives et marquez le job comme failed quand on atteint la limite.
- Définissez un timeout par tentative pour éviter que les workers ne restent bloqués.
- Rendez chaque job idempotent pour que les retries n'entraînent pas de duplications.
Le nombre max de tentatives limite les dégâts. Pour beaucoup d'équipes, 5 à 8 tentatives suffisent. Après cela, arrêtez de retenter et placez le job en dead-letter pour examen plutôt que le laisser boucler indéfiniment.
Les timeouts évitent les jobs "zombies". Les e-mails peuvent avoir un timeout de 10 à 20 secondes par tentative. Les webhooks nécessitent souvent une limite plus courte, comme 5 à 10 secondes, car le destinataire peut être down et il faut passer à autre chose. La génération de rapports peut autoriser des minutes, mais doit tout de même avoir un cutoff dur.
Si vous implémentez cela dans Koder.ai, traitez should_retry, next_run_at et la clé d'idempotence comme des champs de première classe. Ces petits détails calment le système quand quelque chose tourne mal.
Dead-letter et opérations simples
Un état dead-letter est l'endroit où vont les jobs quand les retries ne sont plus sûrs ou utiles. Il transforme un échec silencieux en quelque chose que vous pouvez voir, rechercher et corriger.
Que sauvegarder pour un job en dead-letter
Sauvegardez assez pour comprendre ce qui s'est passé et pouvoir rejouer le job sans deviner, mais attention aux secrets.
Conservez :
- Les inputs du job (payload) exactement comme utilisés, plus le type et la version du job
- Le dernier message d'erreur et une petite trace de pile (ou un code d'erreur si pas de stack)
- Le nombre de tentatives, l'heure du premier run, la dernière exécution, et le prochain run prévu (si programmé)
- L'identité du worker (nom du service, hôte) et un ID de corrélation pour les logs
- Une raison dead-letter (timeout, erreur de validation, 4xx du fournisseur, etc.)
Si le payload contient des tokens ou des données personnelles, redigez ou chiffrez avant de stocker.
Un workflow de triage simple
Quand un job atteint le dead-letter, prenez une décision rapide : retenter, corriger, ou ignorer.
Retenter pour les pannes externes et timeouts. Corriger pour des données erronées (adresse e-mail manquante, URL webhook invalide) ou un bug dans votre code. Ignorer doit rester rare, mais peut être valide si le job n'a plus de sens (par ex. le client a supprimé son compte). Si vous ignorez, enregistrez la raison pour qu'il ne semble pas que le job ait disparu.
Le requeue manuel est plus sûr quand il crée un nouveau job et laisse l'ancien immuable. Marquez le job dead-letter avec qui l'a re-queueé, quand et pourquoi, puis enqueuez une nouvelle copie avec un nouvel ID.
Pour l'alerte, surveillez les signaux qui annoncent une vraie douleur : montée rapide du nombre de dead-letter, la même erreur répétée sur de nombreux jobs, et des jobs vieux en file qui ne sont pas réclamés.
Si vous utilisez Koder.ai, les snapshots et rollback aident quand une mauvaise release fait monter les échecs, car vous pouvez revenir en arrière rapidement pendant l'investigation.
Enfin, ajoutez des valves de sécurité pour les pannes de fournisseurs. Limitez le débit d'envoi par fournisseur, et utilisez un circuit breaker : si un endpoint webhook échoue fortement, mettez en pause les nouvelles tentatives pendant une courte fenêtre pour ne pas submerger leurs serveurs (et les vôtres).
Patrons pour e-mails, rapports et webhooks
Grandir au-delà d'un worker
Montez en charge d'une simple file DB vers plusieurs workers quand votre débit augmente.
Une queue fonctionne mieux quand chaque type de job a des règles claires : ce qui compte comme succès, ce qui doit être retenté, et ce qui ne doit jamais arriver deux fois.
E-mails. La plupart des échecs d'e-mail sont temporaires : timeouts fournisseur, limites de débit, ou courtes pannes. Traitez-les comme retryables, avec backoff. Le risque majeur est l'envoi en double, donc rendez les jobs e-mail idempotents. Stockez une clé de dédup stable comme user_id + template + event_id et refusez d'envoyer si cette clé est déjà marquée comme envoyée.
Il vaut aussi la peine de stocker le nom et la version du template (ou un hash du sujet/corps rendu). Si vous devez relancer des jobs, vous pouvez choisir de renvoyer le même contenu exact ou de régénérer à partir du template actuel. Si le fournisseur renvoie un message ID, sauvegardez-le pour le support.
Rapports. Les rapports échouent différemment. Ils peuvent s'exécuter pendant des minutes, atteindre des limites de pagination, ou manquer de mémoire si tout est fait en une passe. Scindez le travail en morceaux. Un patron courant : un job "report request" crée de nombreux jobs "page" (ou "chunk"), chacun traitant une tranche de données.
Stockez les résultats pour téléchargement ultérieur au lieu de faire attendre l'utilisateur. Cela peut être une table DB indexée par report_run_id, ou une référence de fichier plus des métadonnées (status, nombre de lignes, created_at). Ajoutez des champs de progression pour que l'UI affiche "processing" vs "ready" sans deviner.
Webhooks. Les webhooks concernent la fiabilité de livraison, pas la vitesse. Signez chaque requête (par ex. HMAC avec un secret partagé) et incluez un timestamp pour éviter la relecture. Retentez uniquement quand le destinataire pourrait réussir plus tard.
Règles simples :
- Retentez sur timeouts et réponses 5xx, en utilisant backoff et un max d'essais.
- Considérez la plupart des 4xx comme des échecs définitifs et arrêtez les retries.
- Enregistrez le dernier code de statut et un court corps de réponse pour le débogage.
- Utilisez une clé d'idempotence pour que les récepteurs puissent ignorer les doublons en toute sécurité.
- Limitez la taille des payloads et logguez ce que vous avez effectivement envoyé.
Ordonnancement et priorité. La plupart des jobs n'ont pas besoin d'un ordre strict. Quand l'ordre est important, c'est généralement par clé (par utilisateur, par facture, par endpoint webhook). Ajoutez un group_key et n'exécutez qu'un seul job en vol par clé.
Pour la priorité, séparez le travail urgent du travail lent. Un backlog de gros rapports ne doit pas retarder les e-mails de réinitialisation de mot de passe.
Exemple : après un achat, vous enfilez (1) un e-mail de confirmation de commande, (2) un webhook partenaire, et (3) une mise à jour de rapport. L'e-mail peut retenter rapidement, le webhook retente plus longuement avec backoff, et le rapport s'exécute plus tard en basse priorité.
Un exemple réaliste : inscription, webhook et rapport nocturne
Un utilisateur s'inscrit à votre app. Trois choses doivent arriver, mais aucune d'elles ne doit ralentir la page d'inscription : envoyer un e-mail de bienvenue, notifier votre CRM via webhook, et inclure l'utilisateur dans un rapport d'activité nocturne.
Ce qui est mis en queue à l'inscription
Juste après la création du record utilisateur, écrivez trois lignes de job dans votre table de queue. Chaque ligne a un type, un payload (comme user_id), un status, un compteur de tentatives, et un timestamp next_run_at.
Un cycle typique ressemble à :
queued : créé et en attente de workerrunning : un worker l'a réclamésucceeded : terminé, plus de travailfailed : échoué, programmé pour plus tard ou hors retriesdead : échoué trop de fois et nécessite une intervention humaine
Le job d'e-mail de bienvenue inclut une clé d'idempotence comme welcome_email:user:123. Avant d'envoyer, le worker vérifie une table des clés d'idempotence complétées (ou applique une contrainte d'unicité). Si le job s'exécute deux fois à cause d'un crash, la seconde exécution voit la clé et saute l'envoi. Pas de doublon d'e-mail de bienvenue.
Imaginons que l'endpoint CRM soit down. Le job webhook échoue avec un timeout. Votre worker programme un retry avec backoff (par exemple : 1 minute, 5 minutes, 30 minutes, 2 heures) plus un peu de jitter pour éviter que de nombreux jobs ne retentent à la même seconde.
Après le nombre max de tentatives, le job devient dead. L'utilisateur est tout de même inscrit, a reçu l'e-mail de bienvenue, et le job du rapport nocturne peut s'exécuter normalement. Seule la notification CRM est bloquée, et elle est visible.
Le lendemain, le support (ou l'astreinte) peut le traiter sans fouiller les logs des heures :
- Filtrer les dead jobs par type (par ex.
webhook.crm).
- Lire le dernier message d'erreur et confirmer que le payload semble correct.
- Vérifier que le CRM est de nouveau opérationnel.
- Requeue le job (dead -> queued, reset attempts) ou désactiver temporairement cette destination.
Si vous bâtissez des apps sur une plateforme comme Koder.ai, le même patron s'applique : gardez le flux utilisateur rapide, poussez les effets secondaires en jobs, et facilitez l'inspection et la réexécution des échecs.
Erreurs courantes qui rendent les queues peu fiables
Expérimenter sans crainte
Capturez un snapshot avant les changements pour pouvoir revenir en arrière si une release augmente les erreurs.
La manière la plus rapide de casser une queue est de la traiter comme optionnelle. Les équipes commencent souvent par "cette fois j'envoie l'e-mail dans la requête" parce que ça paraît plus simple. Puis ça se répand : réinitialisations de mot de passe, reçus, webhooks, exports de rapports. Bientôt l'app est lente, les timeouts augmentent, et le moindre accroc tiers devient votre incident.
Un autre piège courant est d'ignorer l'idempotence. Si un job peut s'exécuter deux fois, il ne doit pas produire deux résultats. Sans idempotence, les retries deviennent des e-mails en double, des événements webhook répétés, ou pire.
Un troisième problème est la visibilité. Si vous n'apprenez les échecs que via les tickets support, la queue vous nuit déjà. Même une vue interne basique montrant les comptes de jobs par statut et un last_error searchable sauve du temps.
Tueurs de fiabilité à surveiller
Quelques problèmes apparaissent tôt, même dans des queues simples :
- Retenter immédiatement après un échec. Si un fournisseur est down, des retries rapides créent votre propre pic de trafic.
- Mélanger jobs lents et jobs urgents. Un rapport de 10 minutes peut bloquer un message "vérifiez votre e-mail".
- Traiter les erreurs comme temporaires pour toujours. Les jobs qui ne réussiront jamais continuent de tourner et cachent de vrais problèmes.
- Pas de gestion des versions de payload. Si vous changez la forme d'un job, les anciens jobs peuvent commencer à échouer.
- Ignorer les limites de débit. Les queues peuvent inonder des fournisseurs qui vous throttlent.
Le backoff empêche les auto-pannes. Même un planning basique comme 1 minute, 5 minutes, 30 minutes, 2 heures rend la défaillance plus sûre. Fixez aussi une limite de tentatives pour qu'un job cassé s'arrête et devienne visible.
Si vous développez sur une plateforme comme Koder.ai, faites ces basiques en même temps que la fonctionnalité, pas des semaines plus tard en correction.
Checklist rapide et prochaines étapes
Avant d'ajouter davantage d'outils, assurez-vous que les bases sont solides. Une queue basée en DB fonctionne bien quand chaque job est facile à réclamer, à retenter et à inspecter.
Checklist de fiabilité :
- Chaque job a : id, type, payload, status, attempts, max_attempts, run_at/next_run_at, et last_error.
- Les workers réclament les jobs en sécurité (un worker obtient un job) et se remettent des crashs (timeout de lock + reaper).
- Chaque job a un timeout clair pour que le travail bloqué devienne retentable au lieu de rester pendu.
- Les retries sont limités et les délais augmentent (backoff) pour éviter les thundering herds.
- Il y a un état dead-letter (ou une table) et un moyen clair de re-run ou d'abandonner les jobs.
Ensuite, choisissez vos trois premiers types de jobs et écrivez leurs règles. Par exemple : e-mail de réinitialisation de mot de passe (retries rapides, max court), rapport nocturne (peu de retries, timeouts plus longs), livraison webhook (plus de retries, backoff prolongé, arrêter sur 4xx permanent).
Si vous n'êtes pas sûr quand une queue DB ne suffit plus, surveillez des signaux comme : contention au niveau des lignes avec trop de workers, besoin d'ordre strict entre de nombreux types de jobs, fan-out important (un événement déclenche des milliers de jobs), ou consommation inter-services où différentes équipes possèdent différents workers.
Pour un prototype rapide, vous pouvez esquisser le flux dans Koder.ai (koder.ai) en mode planning, générer la table jobs et la boucle worker, et itérer avec snapshots et rollback avant de déployer.