Pourquoi les applications temps réel semblent lentes même quand le code est rapide
La vitesse a deux faces : le débit et la latence. Le débit est la quantité de travail que vous terminez par seconde (requêtes, messages, images). La latence est le temps qu'une seule unité de travail met du début à la fin.
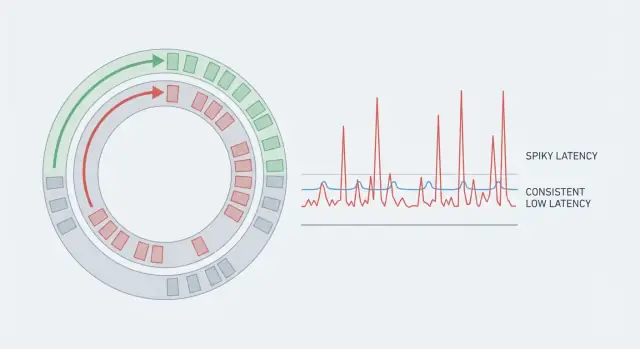
Un système peut avoir un excellent débit et pourtant paraître lent si certaines requêtes prennent beaucoup plus de temps que d'autres. C’est pourquoi les moyennes induisent en erreur. Si 99 actions prennent 5 ms et qu'une seule prend 80 ms, la moyenne semble correcte, mais la personne qui tombe sur le cas à 80 ms ressent le décrochement. Dans les systèmes temps réel, ces pics rares sont toute l’histoire parce qu’ils cassent le rythme.
La latence prévisible signifie que vous ne visez pas seulement une faible moyenne. Vous visez la cohérence, pour que la plupart des opérations se terminent dans une plage étroite. C’est pour cela que les équipes regardent la queue (p95, p99). C’est là que se cachent les pauses.
Un pic de 50 ms peut compter dans des domaines comme la voix et la vidéo (accrocs audio), les jeux multijoueurs (rubber-banding), le trading en temps réel (prix manqués), la surveillance industrielle (alertes tardives) et les tableaux de bord en direct (les chiffres sautent, les alertes semblent peu fiables).
Un exemple simple : une application de chat peut livrer des messages rapidement la plupart du temps. Mais si une pause en arrière-plan fait qu’un message arrive avec 60 ms de retard, les indicateurs de saisie clignotent et la conversation paraît saccadée même si le serveur semble « rapide » en moyenne.
Si vous voulez que le temps réel paraisse réel, vous avez besoin de moins de surprises, pas seulement d’un code plus rapide.
Bases de la latence : où le temps passe vraiment
La plupart des systèmes temps réel ne sont pas lents parce que le CPU est à la peine. Ils paraissent lents parce que le travail passe la plupart de son temps à attendre : attendre d’être programmée, attendre dans une file, attendre le réseau ou attendre le stockage.
La latence de bout en bout est le temps complet entre « quelque chose s’est produit » et « l’utilisateur voit le résultat ». Même si votre handler tourne en 2 ms, la requête peut encore prendre 80 ms si elle est mise en pause à cinq endroits différents.
Une façon utile de décomposer le chemin est :
- Temps réseau (client vers edge, service à service, réessais)
- Temps d’ordonnancement (votre thread attend de s’exécuter)
- Temps en file (le travail attend derrière d’autres travaux)
- Temps de stockage (disque, verrous BD, défauts de cache)
- Temps de sérialisation (encodage et décodage des données)
Ces attentes s’additionnent. Quelques millisecondes ici et là transforment un chemin de code « rapide » en une expérience lente.
La latence des extrêmes est là où les utilisateurs commencent à se plaindre. La latence moyenne peut sembler correcte, mais p95 ou p99 signifie les 5 % ou 1 % de requêtes les plus lentes. Les outliers viennent généralement de pauses rares : un cycle de GC, un voisin bruyant sur l’hôte, une brève contention sur un verrou, un refill de cache ou une rafale qui crée une queue.
Exemple concret : une mise à jour de prix arrive par le réseau en 5 ms, attend 10 ms qu’un worker soit disponible, passe 15 ms derrière d’autres événements, puis subit un blocage BD de 30 ms. Votre code a quand même tourné en 2 ms, mais l’utilisateur a attendu 62 ms. L’objectif est de rendre chaque étape prévisible, pas seulement la computation rapide.
Les sources habituelles de gigue au-delà de la vitesse du code
Un algorithme rapide peut encore paraître lent si le temps par requête varie. Les utilisateurs remarquent les pics, pas les moyennes. Cette variation est la gigue, et elle vient souvent de choses que votre code ne contrôle pas entièrement.
Les caches CPU et le comportement mémoire sont des coûts cachés. Si les données chaudes ne tiennent pas dans le cache, le CPU cale en attendant la RAM. Les structures lourdes en objets, la mémoire dispersée et « encore une recherche » peuvent se transformer en défauts de cache répétés.
L’allocation mémoire ajoute sa propre part d’aléa. Allouer beaucoup d’objets éphémères augmente la pression sur le tas, qui se manifeste ensuite par des pauses (garbage collection) ou de la contention sur l’allocateur. Même sans GC, des allocations fréquentes peuvent fragmenter la mémoire et nuire à la localité.
L’ordonnancement des threads est une autre source commune. Quand un thread est désordonnancé, vous payez le coût du changement de contexte et perdez la chaleur du cache. Sur une machine chargée, votre thread « temps réel » peut attendre derrière des travaux non liés.
La contention sur les verrous est souvent l’endroit où les systèmes prévisibles s’effondrent. Un verrou « généralement libre » peut provoquer un convoi : les threads se réveillent, se battent pour le verrou, et se remettent en sommeil. Le travail est fait, mais la latence des extrêmes s’étire.
Les attentes d’I/O peuvent tout écraser. Un seul syscall, un buffer réseau plein, une handshake TLS, un flush disque ou une résolution DNS lente peut créer un pic aigu qu’aucune micro-optimisation ne résoudra.
Si vous chassez la gigue, commencez par chercher les défauts de cache (souvent causés par des structures à pointeurs et des accès aléatoires), les allocations fréquentes, les changements de contexte dus à trop de threads ou des voisins bruyants, la contention sur les verrous et toute I/O bloquante (réseau, disque, logging, appels synchrones).
Exemple : un service de ticker de prix peut calculer des mises à jour en microsecondes, mais un appel de logger synchronisé ou un verrou de métriques contenté peut ajouter par intermittence des dizaines de millisecondes.
Martin Thompson et ce qu’est le pattern Disruptor
Martin Thompson est reconnu en ingénierie basse latence pour son focus sur le comportement des systèmes sous pression : pas seulement la vitesse moyenne, mais la vitesse prévisible. Avec l’équipe LMAX, il a popularisé le pattern Disruptor, une approche de référence pour faire circuler des événements dans un système avec de petits délais constants.
L’approche Disruptor répond à ce qui rend beaucoup d’apps « rapides » imprévisibles : la contention et la coordination. Les files classiques reposent souvent sur des verrous ou des atomics lourds, réveillent des threads en permanence et créent des rafales d’attente quand producteurs et consommateurs se disputent des structures partagées.
Au lieu d’une file, Disruptor utilise un ring buffer : un tableau circulaire de taille fixe qui contient des événements dans des cases. Les producteurs réservent la case suivante, écrivent les données, puis publient un numéro de séquence. Les consommateurs lisent dans l’ordre en suivant cette séquence. Comme le buffer est préalloué, vous évitez des allocations fréquentes et réduisez la pression sur le garbage collector.
Une idée clé est le principe du single-writer : garder une seule composante responsable d’un état partagé donné (par exemple, le curseur qui avance dans l’anneau). Moins d’auteurs signifie moins de moments « qui passe ensuite ? ».
La rétropression (backpressure) est explicite. Quand les consommateurs prennent du retard, les producteurs finissent par atteindre une case encore utilisée. À ce moment, le système doit attendre, abandonner ou ralentir, mais il le fait de manière contrôlée et visible plutôt que de cacher le problème dans une file qui grandit indéfiniment.
Idées de conception cœur qui maintiennent la latence constante
Ce qui rend les designs à la Disruptor rapides n’est pas une micro-optimisation astucieuse. C’est la suppression des pauses imprévisibles qui surviennent quand un système se bat contre ses propres pièces mobiles : allocations, défauts de cache, contention de verrous et travail lent mélangé dans le chemin chaud.
Un modèle mental utile est une chaîne de montage. Les événements traversent une route fixe avec des remises claires. Cela réduit l’état partagé et rend chaque étape plus simple à garder mesurable.
Garder la mémoire et les données prévisibles
Les systèmes rapides évitent les allocations surprises. Si vous préallouez des buffers et réutilisez des objets message, vous réduisez les pics « parfois » causés par le garbage collection, la croissance du tas et les verrous d’allocateur.
Il aide aussi de garder les messages petits et stables. Quand les données touchées par événement tiennent dans le cache CPU, vous passez moins de temps à attendre la mémoire.
En pratique, les habitudes qui comptent le plus sont : réutiliser des objets plutôt que d’en créer à chaque événement, garder les données d’événement compactes, préférer un seul écrivain pour l’état partagé, et batcher avec soin pour payer moins souvent le coût de coordination.
Rendre les chemins lents évidents
Les apps temps réel ont souvent des extras comme le logging, les métriques, les réessais ou les écritures en base. L’esprit Disruptor est d’isoler ces éléments de la boucle principale pour qu’ils ne puissent pas la bloquer.
Dans un flux de prix en direct, le chemin chaud peut seulement valider un tick et publier l’instantané de prix suivant. Tout ce qui peut bloquer (disque, appels réseau, sérialisation lourde) est déplacé vers un consommateur séparé ou un canal latéral, pour que le chemin prévisible reste prévisible.
Choix d’architecture pour une latence prévisible
La latence prévisible est surtout un problème d’architecture. Vous pouvez avoir du code rapide et trotzdem obtenir des pics si trop de threads se battent pour les mêmes données, ou si les messages rebondissent inutilement sur le réseau.
Commencez par décider combien d’écrivains et de lecteurs touchent la même file ou buffer. Un producteur unique est plus facile à maintenir fluide parce qu’il évite la coordination. Les configurations multi-producteurs peuvent augmenter le débit, mais ajoutent souvent de la contention et rendent les temps d’exécution pires dans le pire des cas. Si vous avez besoin de plusieurs producteurs, réduisez les écritures partagées en sharding par clé (par ex. userId ou instrumentId) pour que chaque shard ait son propre chemin chaud.
Côté consommateur, un consommateur unique donne le timing le plus stable quand l’ordre compte, car l’état reste local à un thread. Les worker pools aident quand les tâches sont vraiment indépendantes, mais ils ajoutent des délais d’ordonnancement et peuvent réordonner le travail sauf si vous êtes prudent.
Le batching est un autre compromis. Les petits batches réduisent les frais (moins de réveils, moins de défauts de cache), mais le batching peut aussi ajouter de l’attente si vous retenez les événements pour remplir un lot. Si vous batcher dans un système temps réel, plafonnez le temps d’attente (par ex. « jusqu’à 16 événements ou 200 microsecondes, selon la première éventualité »).
Les frontières de service comptent aussi. La messagerie intra-processus est généralement la meilleure quand vous avez besoin d’une latence serrée. Les sauts réseau peuvent valoir le coup pour scaler, mais chaque saut ajoute des files, des réessais et des délais variables. Si vous devez faire un saut, gardez le protocole simple et évitez le fan-out dans le chemin chaud.
Un ensemble de règles pratiques : garder une voie single-writer par shard quand possible, scaler en sharding par clé plutôt qu’en partageant une file chaude, batcher seulement avec un cap temporel strict, ajouter des worker pools uniquement pour du travail parallèle et indépendant, et traiter chaque saut réseau comme une source potentielle de gigue jusqu’à ce que vous l’ayez mesuré.
Étape par étape : concevoir un pipeline à faible gigue
Commencez par un budget de latence écrit avant de toucher le code. Choisissez une cible (ce que « bon » doit ressentir) et un p99 (ce que vous devez rester en dessous). Répartissez ce nombre entre des étapes comme l’entrée, la validation, le matching, la persistance et les mises à jour sortantes. Si une étape n’a pas de budget, elle n’a pas de limite.
Ensuite, dessinez le flux de données complet et marquez chaque remise : frontières de thread, files, sauts réseau et appels de stockage. Chaque remise est un endroit où la gigue se cache. Quand vous les voyez, vous pouvez les réduire.
Un workflow qui garde la conception honnête :
- Écrivez un budget par étape (objectif et p99), plus une petite marge pour l’inconnu.
- Cartographiez le pipeline et étiquetez files, verrous, allocations et appels bloquants.
- Choisissez un modèle de concurrence que vous pouvez raisonner (single writer, partitions par clé, ou un thread I/O dédié).
- Définissez la forme des messages tôt : schémas stables, payloads compacts et copies minimales.
- Décidez des règles de backpressure en amont : drop, delay, dégrader ou shed load. Rendez-le visible et mesurable.
Décidez ensuite ce qui peut être asynchrone sans casser l’expérience utilisateur. Règle simple : tout ce qui change ce que l’utilisateur voit « maintenant » reste sur le chemin critique. Le reste sort.
Les analytics, logs d’audit et index secondaires sont souvent sûrs à repousser hors du chemin chaud. La validation, l’ordre et les étapes nécessaires pour produire l’état suivant ne le sont généralement pas.
Choix d’exécution et d’OS qui affectent la latence des extrêmes
Un code rapide peut encore paraître lent quand le runtime ou l’OS met votre travail en pause au mauvais moment. L’objectif n’est pas seulement un haut débit. C’est moins de surprises dans le 1 % le plus lent des requêtes.
Les runtimes à garbage collector (JVM, Go, .NET) sont excellents pour la productivité, mais ils peuvent introduire des pauses quand la mémoire doit être nettoyée. Les collecteurs modernes sont bien meilleurs qu’avant, pourtant la latence des extrêmes peut sauter si vous créez beaucoup d’objets éphémères sous charge. Les langages sans GC (Rust, C, C++) évitent les pauses GC, mais déplacent le coût sur la discipline d’ownership et d’allocation manuelle. Dans tous les cas, le comportement mémoire compte autant que la vitesse CPU.
L’habitude pratique est simple : trouvez où les allocations se produisent et rendez-les ennuyeuses. Réutilisez les objets, pré-dimensionnez les buffers et évitez de transformer les données du chemin chaud en chaînes temporaires ou maps.
Les choix de threading apparaissent aussi comme de la gigue. Chaque file supplémentaire, saut async ou remise à un thread pool ajoute de l’attente et augmente la variance. Préférez un petit nombre de threads de longue durée, gardez clairs les frontières producteur-consommateur et évitez les appels bloquants sur le chemin chaud.
Quelques réglages OS et conteneur décident souvent si votre queue est propre ou saccadée. La throttling CPU dû à des limites strictes, des voisins bruyants sur des hôtes partagés, et des logs/métriques mal placés peuvent tous provoquer des ralentissements soudains. Si vous ne changez qu’une chose, commencez par mesurer le taux d’allocations et les changements de contexte pendant les pics de latence.
Données, stockage et frontières de service sans pauses surprises
Beaucoup de pics de latence ne sont pas du « code lent ». Ce sont des attentes non planifiées : un verrou BD, une tempête de réessais, un appel inter-service qui cale ou un défaut de cache qui devient un aller-retour complet.
Gardez le chemin critique court. Chaque saut ajouté ajoute ordonnancement, sérialisation, files réseau et plus d’endroits où bloquer. Si vous pouvez répondre depuis un processus et un datastore, faites-le d’abord. Séparez en plus de services seulement quand chaque appel est optionnel ou strictement borné.
L’attente bornée fait la différence entre moyennes rapides et latence prévisible. Mettez des timeouts stricts sur les appels distants et échouez vite quand une dépendance est malade. Les circuit breakers ne servent pas qu’à protéger les serveurs. Ils limitent combien de temps les utilisateurs peuvent rester bloqués.
Quand l’accès aux données bloque, séparez les chemins. Les lectures veulent souvent des formes indexées, dénormalisées et cache-friendly. Les écritures veulent durabilité et ordre. Les séparer peut supprimer la contention et réduire le temps de verrou. Si votre besoin de cohérence le permet, les enregistrements append-only (journal d’événements) se comportent souvent de façon plus prévisible que des mises à jour en place qui déclenchent des verrous de ligne chaude ou des maintenances en arrière-plan.
Une règle simple pour les apps temps réel : la persistance ne devrait pas être sur le chemin critique à moins que ce soit vraiment nécessaire pour la correction. Souvent la meilleure forme est : mettre à jour en mémoire, répondre, puis persister de manière asynchrone avec un mécanisme de replay (outbox ou write-ahead log).
Dans beaucoup de pipelines basés sur ring buffer, cela finit comme : publier dans un tampon en mémoire, mettre à jour l’état, répondre, puis laisser un consommateur séparé batcher les écritures vers PostgreSQL.
Un exemple réaliste : mises à jour temps réel avec latence prévisible
Imaginez une application de collaboration en direct (ou un petit jeu multijoueur) qui pousse des mises à jour toutes les 16 ms (environ 60 fois par seconde). L’objectif n’est pas « rapide en moyenne ». C’est « généralement sous 16 ms », même quand la connexion d’un utilisateur est mauvaise.
Un flux à la Disruptor pourrait ressembler à ceci : l’entrée utilisateur devient un petit événement, il est publié dans un ring buffer préalloué, puis traité par un ensemble fixe de handlers en ordre (validate -> apply -> prepare outbound messages), et enfin broadcasté aux clients.
Le batching aide parfois aux bordures. Par exemple, batcher les envois sortants par client une fois par tick pour appeler moins souvent la couche réseau. Mais ne batcher pas à l’intérieur du chemin chaud d’une façon qui attend « un peu plus » pour d’autres événements. Attendre, c’est rater le tick.
Quand quelque chose ralentit, traitez-le comme un problème de confinement. Si un handler ralentit, isolez-le derrière son propre buffer et publiez un work item léger au lieu de bloquer la boucle principale. Si un client est lent, ne le laissez pas bloquer le diffuseur ; donnez à chaque client une petite file d’envoi et jetez ou coalescez les anciennes mises à jour pour garder l’état le plus récent. Si la profondeur du buffer augmente, appliquez de la rétropression à la bordure (ne plus accepter d’entrées pour ce tick, ou dégrader des fonctionnalités).
Vous savez que cela fonctionne quand les chiffres restent ennuyeux : la profondeur du backlog reste proche de zéro, les événements drop/coalescés sont rares et explicables, et le p99 reste sous votre budget de tick sous charge réaliste.
Erreurs courantes qui créent des pics de latence
La plupart des pics de latence sont auto-infligés. Le code peut être rapide, mais le système pause quand il attend d’autres threads, l’OS ou quoi que ce soit hors du cache CPU.
Quelques erreurs reviennent souvent :
- Utiliser des verrous partagés partout parce que c’est plus simple. Un verrou contenté peut bloquer beaucoup de requêtes.
- Mélanger de l’I/O lente dans le chemin chaud, comme du logging synchrone, des écritures BD ou des appels distants.
- Garder des files non bornées. Elles cachent la surcharge jusqu’à ce que vous ayez des secondes de backlog.
- Regarder les moyennes au lieu du p95 et p99.
- Over-tuner trop tôt. Épingler des threads ne sert à rien si les délais viennent du GC, de la contention ou d’un socket qui attend.
Une façon rapide de réduire les pics est de rendre les attentes visibles et bornées. Mettez le travail lent sur un chemin séparé, plafonnez les files et décidez ce qui se passe quand elles sont pleines (drop, shed, dégrader ou backpressure).
Checklist rapide pour une latence prévisible
Traitez la latence prévisible comme une fonctionnalité produit, pas comme un accident. Avant d’optimiser le code, assurez-vous que le système a des objectifs et des garde-fous clairs.
- Fixez un objectif p99 explicite (et p99.9 si c’est important), puis écrivez un budget de latence par étape.
- Gardez le chemin chaud sans I/O bloquante. Si l’I/O doit arriver, déplacez-la sur un chemin latéral et décidez quoi faire si elle lâche.
- Utilisez des files bornées et définissez le comportement en surcharge (drop, shed, coalesce ou backpressure).
- Mesurez en continu : profondeur du backlog, temps par étape et latence terminale.
- Minimisez les allocations dans la boucle chaude et facilitez leur repérage dans les profils.
Un test simple : simulez une rafale (10× le trafic normal pendant 30 secondes). Si le p99 explose, demandez-vous où l’attente se produit : files qui grandissent, consommateur lent, pause GC ou ressource partagée.
Considérez le pattern Disruptor comme un workflow, pas seulement comme une bibliothèque. Prouvez la latence prévisible avec une tranche fine avant d’ajouter des fonctionnalités.
Choisissez une action utilisateur qui doit sembler instantanée (par ex. « nouveau prix arrive, UI se met à jour »). Écrivez le budget de bout en bout, puis mesurez p50, p95 et p99 dès le premier jour.
Une séquence qui marche souvent :
- Construisez un pipeline mince avec une entrée, une boucle centrale et une sortie. Validez le p99 sous charge tôt.
- R rendez les responsabilités explicites (qui possède l’état, qui publie, qui consomme) et gardez l’état partagé petit.
- Ajoutez concurrence et buffering par petites étapes, et rendez les changements réversibles.
- Déployez proche des utilisateurs quand le budget est serré, puis re-mesurez sous charge réaliste (mêmes tailles de payload, mêmes motifs de rafales).
Si vous développez sur Koder.ai (koder.ai), il peut aider de cartographier d’abord le flux d’événements en Planning Mode pour que files, verrous et frontières de service n’apparaissent pas par accident. Les snapshots et le rollback facilitent aussi l’exécution répétée d’expériences de latence et le retour en arrière des changements qui améliorent le débit mais empirent le p99.
Gardez les mesures honnêtes. Utilisez un script de test fixe, réchauffez le système et enregistrez à la fois le throughput et la latence. Quand le p99 saute sous charge, ne commencez pas par « optimiser le code ». Cherchez des pauses causées par le GC, des voisins bruyants, des rafales de logging, l’ordonnancement des threads ou des appels bloquants cachés.