Pourquoi CAP est devenu le modèle mental de référence
Quand vous stockez les mêmes données sur plus d’une machine, vous gagnez en vitesse et en tolérance aux pannes — mais vous héritez aussi d’un nouveau problème : le désaccord. Deux serveurs peuvent recevoir des mises à jour différentes, des messages peuvent arriver en retard ou pas du tout, et les utilisateurs peuvent lire des réponses différentes selon la réplique qu’ils touchent. CAP est devenu populaire parce qu’il donne aux ingénieurs une manière claire de parler de cette réalité embrouillée sans faire de faux-semblants.
Eric Brewer, informaticien et cofondateur d’Inktomi, a introduit l’idée centrale en 2000 comme une affirmation pratique sur les systèmes répliqués en cas de défaillance. Elle s’est rapidement diffusée parce qu’elle correspondait à ce que les équipes rencontraient déjà en production : les systèmes distribués ne se contentent pas de tomber ; ils se « scindent ».
CAP, une lentille sur les défaillances, pas une checklist de fonctionnalités
CAP est le plus utile quand les choses tournent mal — surtout quand le réseau ne se comporte pas. Lors d’une journée saine, de nombreux systèmes peuvent paraître à la fois suffisamment cohérents et disponibles. Le test de résistance arrive quand les machines ne peuvent plus communiquer de façon fiable et que vous devez décider quoi faire des lectures et écritures pendant que le système est divisé.
C’est ce cadrage qui fait de CAP un modèle mental incontournable : il ne prêche pas des bonnes pratiques ; il pose une question concrète — qu’est‑ce que nous sacrifierons durant une partition ?
Ce que vous saurez décider à la fin
À la fin de cet article, vous devriez être capable de :
- Reconnaître quand vous êtes face à un véritable scénario CAP (réplication + ruptures de communication possibles).
- Choisir, de manière intentionnelle, si votre système doit favoriser la cohérence (tout le monde voit la même vérité) ou la disponibilité (le système continue de répondre) quand les répliques ne peuvent pas s’accorder.
- Relier ce choix à l’impact produit : ce que les utilisateurs vivent, quelles erreurs vous affichez et quelles corrections seront nécessaires après la guérison de la partition.
CAP perdure parce qu’il transforme le vague « distributed is hard » en une décision que vous pouvez prendre — et défendre.
Le contexte : réplication et le problème du désaccord
Un système distribué est, en termes simples, beaucoup d’ordinateurs essayant d’agir comme un seul. Vous pouvez avoir plusieurs serveurs dans différents racks, régions ou zones cloud, mais pour l’utilisateur c’est « l’app » ou « la base de données ».
Pourquoi on réplique les données
Pour que ce système partagé fonctionne à l’échelle réelle, on réplique généralement : on conserve plusieurs copies des mêmes données sur différentes machines.
La réplication est prisée pour trois raisons pratiques :
- Échelle : plus de machines peuvent gérer plus de trafic.
- Performance : les utilisateurs peuvent être servis par une copie proche, réduisant la latence.
- Fiabilité : si une machine meurt, une autre copie peut maintenir le service.
Jusque‑là, la réplication ressemble à un gain net. Le hic, c’est que la réplication crée un nouveau travail : maintenir toutes les copies en accord.
La tension centrale : les copies peuvent diverger
Si chaque réplique pouvait toujours parler instantanément à toutes les autres, elles pourraient coordonner les mises à jour et rester alignées. Mais les réseaux réels ne sont pas parfaits. Les messages peuvent être retardés, perdus ou routés contournant des défaillances.
Quand la communication est saine, les répliques peuvent généralement échanger des mises à jour et converger vers le même état. Mais quand la communication casse (même temporairement), vous pouvez vous retrouver avec deux versions valides de la « vérité ».
Par exemple, un utilisateur change son adresse de livraison. La réplique A reçoit la mise à jour, la réplique B non. Maintenant le système doit répondre à une question apparemment simple : quelle est l’adresse actuelle ?
Fonctionnement normal vs fonctionnement en défaillance
C’est la différence entre :
- Fonctionnement normal : les répliques peuvent se coordonner ; le désaccord est principalement une question de temps.
- Fonctionnement en défaillance : certaines répliques ne peuvent pas communiquer ; le désaccord devient inévitable.
La pensée CAP commence précisément ici : une fois la réplication en place, le désaccord sous défaillance de communication n’est pas un cas marginal — c’est le problème de conception central.
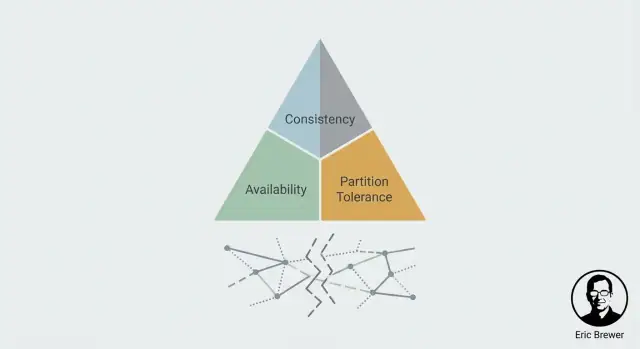
CAP en termes simples : C, A et P
CAP est un modèle mental pour ce que les utilisateurs ressentent réellement quand un système est réparti sur plusieurs machines (souvent en plusieurs emplacements). Il ne décrit pas des systèmes « bons » ou « mauvais » — juste la tension que vous devez gérer.
Cohérence (C) : est‑ce que je vois la dernière écriture ?
La cohérence concerne l’accord. Si vous mettez quelque chose à jour, la prochaine lecture (de n’importe où) reflétera‑t‑elle cette mise à jour ?
Du point de vue utilisateur, c’est la différence entre « je viens de le changer, et tout le monde voit la nouvelle valeur » et « certaines personnes voient encore l’ancienne valeur pendant un moment ».
Disponibilité (A) : puis‑je obtenir une réponse du tout ?
La disponibilité signifie que le système répond aux requêtes — lectures et écritures — par un résultat de succès. Pas « le plus rapide possible », mais « il ne refuse pas de vous servir ».
En cas de problème (un serveur en panne, un pépin réseau), un système disponible continue d’accepter les requêtes, même s’il doit répondre avec des données légèrement périmées.
Tolérance aux partitions (P) : que se passe‑t‑il quand les nœuds ne peuvent pas se parler ?
Une partition est quand le réseau se scinde : des machines tournent, mais les messages entre certaines d’entre elles ne passent plus (ou arrivent trop tard pour être utiles). Dans les systèmes distribués, vous ne pouvez pas traiter cela comme impossible — il faut définir le comportement quand ça arrive.
Une histoire simple : deux boutiques, un inventaire
Imaginez deux boutiques qui vendent le même produit et partagent un « stock unique ». Un client achète le dernier article dans la boutique A, donc A écrit stock = 0. Au même moment, une partition réseau empêche B d’en être informée.
Si B reste disponible, elle peut vendre un article qu’elle n’a plus (accepter la vente pendant la partition). Si B fait primer la cohérence, elle peut refuser la vente tant qu’elle ne confirme pas le stock le plus récent (refuser le service pendant la coupure).
Ce que sont vraiment les partitions (et pourquoi vous ne pouvez pas les ignorer)
Une « partition » n’est pas seulement « Internet est en panne ». C’est toute situation où des parties de votre système ne peuvent pas se parler de façon fiable — même si chaque partie semble tourner correctement.
Dans un système répliqué, les nœuds échangent constamment des messages : écritures, acquittements, heartbeats, élections de leader, requêtes de lecture. Une partition survient quand ces messages cessent d’arriver (ou arrivent trop tard), créant un désaccord sur la réalité : « L’écriture a‑t‑elle eu lieu ? », « Qui est le leader ? », « Le nœud B est‑il vivant ? »
Les partitions sont des défaillances de communication
La communication peut échouer de manière fragmentaire :
- Perte de paquets qui déclenche des retries et des timeouts
- Problèmes de routage où le trafic fait un long détour ou est blackholé
- Liens saturés (ou NIC surchargées) provoquant de longs délais
- Pare‑feu / groupes de sécurité mal configurés bloquant certains ports ou directions
- Problèmes DNS ou de découverte de services empêchant les nœuds de se trouver
Le point important : les partitions sont souvent une dégradation, pas une coupure nette on/off. Du point de vue de l’application, « assez lent » peut être indiscernable de « down ».
Pourquoi les partitions sont inévitables à grande échelle
En ajoutant des machines, des réseaux, des régions et des pièces mobiles, il y a simplement plus d’opportunités pour que la communication casse temporairement. Même si les composants individuels sont fiables, le système global connaît des défaillances parce qu’il a plus de dépendances et plus de coordination inter‑nœuds.
Vous n’avez pas besoin d’assumer un taux d’échec précis pour accepter la réalité : si votre système tourne assez longtemps et couvre assez d’infrastructure, les partitions arriveront.
Que signifie réellement « tolérer les partitions »
Tolérer les partitions signifie que votre système est conçu pour continuer à fonctionner pendant une scission — même quand les nœuds ne peuvent pas s’accorder ou confirmer ce que l’autre côté a vu. Cela force un choix : continuer à servir (au risque d’incohérences) ou arrêter/refuser certaines requêtes (préserver la cohérence).
Le moment clé : choisir cohérence ou disponibilité pendant une partition
Une fois la réplication en place, une partition est simplement une rupture de communication : deux parties de votre système ne peuvent pas parler de façon fiable pendant un moment. Les répliques tournent toujours, les utilisateurs continuent de cliquer, et votre service reçoit encore des requêtes — mais les répliques ne peuvent pas s’accorder sur la vérité la plus récente.
C’est la tension CAP en une phrase : pendant une partition, vous devez choisir de prioriser la Cohérence (C) ou la Disponibilité (A). Vous n’obtenez pas les deux en même temps.
Si vous choisissez la cohérence (C)
Vous dites : « je préfère être correct plutôt que réactif. » Quand le système ne peut pas confirmer qu’une requête maintiendra toutes les répliques synchrones, il doit échouer ou attendre.
Effet pratique : certains utilisateurs voient des erreurs, des timeouts ou des messages « réessayez » — surtout pour les opérations qui modifient des données. C’est courant quand vous préférez refuser un paiement plutôt que de risquer un double débit, ou bloquer une réservation de siège plutôt que de surgérer.
Si vous choisissez la disponibilité (A)
Vous dites : « je préfère répondre plutôt que bloquer. » Chaque côté de la partition continue d’accepter des requêtes, même s’il ne peut pas se coordonner.
Effet pratique : les utilisateurs obtiennent des réponses réussies, mais les données lues peuvent être obsolètes, et des mises à jour concurrentes peuvent entrer en conflit. Vous comptez ensuite sur une réconciliation ultérieure (règles de fusion, last‑write‑wins, revue manuelle, etc.).
Le choix peut varier selon l’opération
Ce n’est pas toujours un réglage global. Beaucoup de produits mélangent les stratégies :
- Lectures vs écritures : garder les lectures disponibles, rendre les écritures plus strictes.
- Actions critiques vs non critiques : appliquer la cohérence pour l’argent, l’identité et l’inventaire ; permettre la disponibilité pour les fils d’actualité, analytics, « likes » ou profils mis en cache.
Le moment clé est de décider — pour chaque opération — ce qui est pire : bloquer un utilisateur maintenant, ou résoudre une vérité conflictuelle plus tard.
Idées reçues : au‑delà du slogan « choisissez deux »
Construisez et gagnez des crédits
Partagez ce que vous avez construit avec Koder.ai et gagnez des crédits pour continuer d'expérimenter.
Le slogan « choisissez deux » est mémorable, mais il induit souvent en erreur en faisant croire que CAP est un menu de trois fonctionnalités dont on ne peut en garder que deux pour toujours. CAP concerne ce qui arrive quand le réseau cesse de coopérer : pendant une partition (ou tout ce qui y ressemble), un système distribué doit choisir entre retourner des réponses cohérentes et rester disponible pour chaque requête.
Idée reçue 1 : « je choisis C et A et j’évite les partitions »
Dans les systèmes réels, les partitions ne sont pas un réglage désactivable. Si votre système couvre des machines, racks, zones ou régions, alors des messages peuvent être retardés, perdus, réordonnés ou routés de manière étrange. C’est une partition du point de vue du logiciel : les nœuds ne peuvent pas s’accorder suffisamment bien.
Même si le réseau physique est correct, des défaillances ailleurs créent le même effet : nœuds surchargés, pauses GC, voisins bruyants, problèmes DNS, load balancers instables. Le résultat est le même : certaines parties du système ne peuvent pas se coordonner.
Idée reçue 2 : « les partitions sont des cas rares »
Les applications n’expérimentent pas la « partition » comme un événement binaire net. Elles subissent des pics de latence et des timeouts. Si une requête timeoute après 200 ms, peu importe si le paquet est arrivé à 201 ms ou jamais : l’app doit décider quoi faire ensuite. Du point de vue de l’app, une communication lente est souvent indiscernable d’une communication cassée.
Idée reçue 3 : « les systèmes sont soit CP soit AP »
Beaucoup de systèmes réels sont pour la plupart cohérents ou pour la plupart disponibles, selon la configuration et les conditions d’exploitation. Les timeouts, politiques de retry, tailles de quorum et options « read your writes » peuvent faire évoluer le comportement.
En conditions normales, une base de données peut sembler fortement cohérente ; sous stress ou lors d’un pépin inter‑régions, elle peut commencer à rejeter des requêtes (favorisant la cohérence) ou renvoyer des données plus anciennes (favorisant la disponibilité).
CAP vise moins à étiqueter des produits qu’à comprendre le compromis que vous faites quand le désaccord arrive — surtout quand ce désaccord est causé par une simple lenteur.
Options de cohérence que vous pouvez réellement choisir
Les discussions CAP font parfois paraître la cohérence binaire : « parfaite » ou « tout est permis ». Les systèmes réels offrent un menu de garanties, chacune donnant une expérience utilisateur différente quand les répliques divergent ou qu’un lien réseau casse.
Cohérence forte (et son coût en cas de défaillance)
La cohérence forte (souvent dite « linéarisable ») signifie qu’une fois qu’une écriture est acquittée, toute lecture ultérieure — quel que soit la réplique — renverra cette écriture.
Son coût : pendant une partition ou lorsque la minorité des répliques est inaccessible, le système peut retarder ou rejeter lectures/écritures pour éviter d’afficher des états conflictuels. Les utilisateurs le remarquent via des timeouts, des messages « réessayez » ou un comportement temporaire en lecture seule.
Cohérence éventuelle (et ce que les utilisateurs peuvent remarquer)
La cohérence éventuelle promet que si aucune nouvelle mise à jour n’a lieu, toutes les répliques convergeront. Elle ne promet pas que deux utilisateurs lisant maintenant verront la même chose.
Ce que l’utilisateur peut remarquer : une photo de profil récemment mise à jour qui « revient en arrière », des compteurs qui accusent du retard, ou un message envoyé qui n’apparaît pas sur un autre appareil pendant un court instant.
Garanties intermédiaires utiles
Vous pouvez souvent obtenir une meilleure expérience sans exiger la cohérence forte :
- Lecture de ses propres écritures : après avoir mis à jour quelque chose, vous ne lirez pas une ancienne version de vos données.
- Lectures monotones : une fois que vous avez vu la version N, vous ne reverrez pas la version N‑1.
- Cohérence causale : si l’événement B dépend de A (réponse après lecture d’un message), tout le monde voit A avant B.
Ces garanties correspondent bien à la manière dont les gens pensent (« ne me montre pas mes propres modifications disparaître ») et sont souvent plus faciles à maintenir en cas de pannes partielles.
Choisir un niveau de cohérence selon les attentes
Commencez par les promesses produit, pas par le jargon :
- Si des lectures incorrectes créent un tort irréversible (mouvements d’argent, réservation d’inventaire, changements de permissions), orientez‑vous vers une cohérence plus forte et acceptez une indisponibilité temporaire.
- Si la fonctionnalité tolère de courts désaccords (likes, compteurs, classement de flux), la cohérence éventuelle ou causale convient généralement.
- Si la douleur centrale est une confusion personnelle (« j’ai sauvegardé — pourquoi je ne le vois pas ? »), priorisez lecture de ses propres écritures et lectures monotones.
La cohérence est un choix produit : définissez ce qu’« être faux » signifie pour un utilisateur, puis choisissez la garantie la plus faible qui empêche ce cas inacceptable.
La disponibilité comme décision produit, pas juste un nombre de disponibilité
Itérez sans crainte
Expérimentez des scénarios de panne, puis revenez rapidement en arrière lorsque une approche se comporte mal.
La disponibilité dans CAP n’est pas un argument marketing (« cinq 9 ») — c’est une promesse que vous faites aux utilisateurs sur ce qui arrive quand le système ne peut pas être certain.
Succès rapide vs succès exact
Quand les répliques ne peuvent pas s’accorder, vous choisissez souvent entre :
- Succès rapide : renvoyer quelque chose vite (même si c’est périmé).
- Succès exact : ne répondre que quand vous pouvez prouver que la réponse est à jour.
Les utilisateurs ressentent cela comme « l’app fonctionne » versus « l’app est correcte ». Ni l’un ni l’autre n’est universellement meilleur ; le bon choix dépend de ce que « faux » signifie dans votre produit. Un fil social légèrement périmé est agaçant. Un solde de compte périmé peut être dangereux.
« Fail closed » vs « fail open »
Deux comportements courants en période d’incertitude :
- Fail closed : rejeter la requête (erreurs, timeouts, mode lecture seule). Vous protégez la correction, mais bloquez les utilisateurs.
- Fail open : servir une réponse au mieux (cache, réplique locale, écriture mise en file). Vous maintenez le flux, mais pouvez afficher des incohérences.
Ce n’est pas un choix purement technique ; c’est une politique. Le produit doit définir ce qu’il est acceptable d’afficher et ce qui ne doit jamais être deviné.
La disponibilité partielle est toujours de la disponibilité
La disponibilité est rarement tout ou rien. Pendant une scission, vous pouvez observer une disponibilité partielle : certaines régions, réseaux ou groupes d’utilisateurs réussissent tandis que d’autres échouent. Cela peut être un choix délibéré (continuer à servir là où la réplique locale est saine) ou accidentel (déséquilibres de routage, quorum inatteignable).
Mode dégradé : garder le cœur, limiter le risque
Un compromis pratique est le mode dégradé : continuer à servir les actions sûres tout en restreignant celles à risque. Par exemple, autoriser la navigation et la recherche, mais désactiver temporairement « transférer des fonds », « changer le mot de passe » ou d’autres opérations où la correction et l’unicité comptent.
Exemples concrets : associer les choix CAP aux cas d’usage
CAP paraît abstrait jusqu’à ce que vous le mettiez en correspondance avec ce que vos utilisateurs vivent pendant une scission réseau : préférez‑vous que le système continue de répondre, ou qu’il s’arrête pour éviter de retourner/acceptor des données conflictuelles ?
Inventaire et commandes : risque de survente vs pannes du checkout
Imaginez deux datacenters acceptant des commandes alors qu’ils ne peuvent pas communiquer.
Si vous maintenez le checkout disponible, chaque côté peut vendre le « dernier article » et vous surventerez. Cela peut être acceptable pour des biens à faible enjeu (vous gérez en backorder ou excusez), mais pénalisant pour des drops en quantité limitée.
Si vous choisissez la cohérence, vous pouvez bloquer les nouvelles commandes quand vous ne pouvez pas confirmer le stock global. Les utilisateurs voient « réessayez plus tard », mais vous évitez de vendre ce que vous ne pouvez pas honorer.
Paiements et soldes : patterns « correction d’abord » (et pourquoi)
L’argent est le domaine classique où se tromper coûte cher. Si deux répliques acceptent des retraits indépendamment pendant une scission, un compte peut devenir négatif.
Les systèmes préfèrent souvent la cohérence pour les écritures critiques : refuser ou retarder les actions si l’on ne peut pas confirmer le solde actuel. Vous échangez un peu de disponibilité (échecs de paiement temporaires) contre correction, traçabilité et confiance.
Chat, fils et analytics : « disponible avec données légèrement périmées » est acceptable
Dans le chat et les fils sociaux, les utilisateurs tolèrent généralement de petites incohérences : un message arrive quelques secondes plus tard, un compteur de likes est décalé, une métrique s’actualise plus tard.
Ici, concevoir pour la disponibilité peut être un bon choix produit, tant que vous précisez quels éléments sont « finalement cohérents » et que vous savez fusionner proprement les mises à jour.
Le point : votre compromis est une décision métier
Le « bon » choix CAP dépend du coût d’être faux : remboursements, exposition légale, perte de confiance, chaos opérationnel. Décidez où vous pouvez tolérer la staleness temporaire — et où vous devez échouer fermé.
Patterns de conception qui implémentent votre compromis
Une fois que vous avez décidé quoi faire durant une rupture réseau, il faut des mécanismes qui concrétisent cette décision. Ces patterns apparaissent dans les bases de données, systèmes de messages et API — même si le produit ne parle jamais explicitement de « CAP ».
Quorums : accord de la majorité
Un quorum, c’est simplement « la majorité des répliques sont d’accord ». Si vous avez 5 copies d’une donnée, la majorité est 3.
En exigeant que lectures et/ou écritures contactent une majorité, vous réduisez la probabilité de renvoyer des données périmées ou conflictuelles. Par exemple, si une écriture doit être acquittée par 3 répliques, il est plus difficile que deux groupes isolés acceptent des « vérités » différentes.
L’échange est la latence et la portée : si vous n’atteignez pas la majorité (partition, panne), le système peut refuser l’opération — il choisit la cohérence plutôt que la disponibilité.
Timeouts, retries et backoff façonnent la disponibilité perçue
Beaucoup de problèmes d’« disponibilité » ne sont pas des pannes nettes mais des réponses lentes. Définir un timeout court rend l’expérience réactive, mais augmente les chances de considérer des succès lents comme des échecs.
Les retries peuvent récupérer d’états transitoires, mais des retries agressifs peuvent surcharger un service déjà fragilisé. Le backoff (attendre un peu plus entre les retries) et le jitter (aléa) empêchent que les retries deviennent un pic de trafic.
L’important est d’aligner ces réglages avec votre promesse : « toujours répondre » implique généralement plus de retries et de repli ; « ne jamais mentir » implique des limites plus strictes et des erreurs explicites.
Résolution de conflits quand vous autorisez la divergence
Si vous choisissez de rester disponible pendant les partitions, des répliques peuvent accepter des mises à jour différentes et vous devez réconcilier ensuite. Approches courantes :
- La dernière écriture l’emporte (Last‑Write‑Wins) : choisir la mise à jour avec le timestamp le plus récent. Simple mais peut perdre des changements valides si les horloges divergent.
- Vecteurs de version : attacher un petit « historique » aidant à détecter si les mises à jour sont concurrentes ou si l’une remplace l’autre.
- Règles de fusion : définir comment combiner les changements (par ex. union pour les articles de panier ; addition pour les compteurs ; préférer les champs non vides pour les profils). Cela marche bien quand c’est conçu au niveau du modèle de données.
Idempotence : rendre les retries sûrs
Les retries peuvent créer des doublons : débit d’une carte en double ou soumission d’une commande deux fois. L’idempotence empêche cela.
Un pattern courant est la clé d’idempotence (idempotency key) envoyée avec chaque requête. Le serveur conserve le premier résultat et renvoie le même résultat pour les répétitions — ainsi les retries améliorent la disponibilité sans corrompre les données.
Testez tôt les hypothèses CAP
Créez un petit système et testez une latence simulant une partition avec un comportement client réaliste.
La plupart des équipes « choisissent » une posture CAP sur un tableau blanc — puis découvrent en production que le système se comporte différemment sous stress. Valider signifie créer volontairement les conditions où les compromis CAP deviennent visibles, et vérifier que votre système réagit comme prévu.
Tester les partitions volontairement (en sécurité)
Vous n’avez pas besoin d’une coupure réelle pour apprendre : utilisez l’injection de fautes contrôlées en staging (et prudemment en production) pour simuler des partitions :
- Blackhole du trafic entre services ou nœuds spécifiques (drop des paquets sans fermer les connexions) pour mimer une séparation silencieuse.
- Couper des liens en bloquant ports ou règles de groupe de sécurité entre répliques/régions.
- Ajouter une latence extrême et de la perte de paquets pour que timeouts et retries se comportent comme en partition.
- Isoler un leader forcé (par ex. isoler le primaire d’un quorum) pour voir si vous échouez « cohérent » ou « disponible ».
Le but est de répondre à des questions concrètes : les écritures sont‑elles rejetées ou acceptées ? les lectures retournent‑elles des données périmées ? le système récupère‑t‑il automatiquement et combien de temps prend la réconciliation ?
Si vous voulez valider ces comportements tôt (avant d’investir des semaines à monter des services), il peut aider de prototyper rapidement. Par exemple, des équipes utilisant Koder.ai débutent souvent par générer un petit service (souvent un backend Go avec PostgreSQL plus une UI React) puis itèrent sur les comportements comme retries, clés d’idempotence et flux en « mode dégradé » dans un bac à sable.
Surveiller les signaux qui révèlent la douleur CAP
Les checks de disponibilité traditionnels ne détecteront pas le comportement « disponible mais faux ». Surveillez :
- Taux d’erreur par type d’opération (lecture vs écriture vs mise à jour conditionnelle)
- Indicateurs de lectures périmées (violations « read‑your‑writes », mismatch de version/ETag, métriques de lag)
- Divergence des répliques (lag de réplication, échecs d’application, taux de conflits)
- Timeouts / retries (souvent le premier signe d’une partition émergeante)
Runbooks et communication utilisateur
Les opérateurs ont besoin d’actions prédéfinies quand une partition arrive : quand geler les écritures, quand basculer, quand dégrader des fonctionnalités, et comment valider la sécurité de la réunification.
Préparez aussi le comportement visible pour l’utilisateur. Si vous choisissez la cohérence, le message peut être « Nous ne pouvons pas confirmer votre mise à jour pour l’instant — veuillez réessayer. » Si vous choisissez la disponibilité, soyez explicite : « Votre mise à jour peut mettre quelques minutes à apparaître partout. » Un wording clair réduit la charge du support et préserve la confiance.
Une checklist CAP pratique pour les décisions quotidiennes
Quand vous prenez une décision système, CAP est surtout utile comme un bref audit « qu’est‑ce qui casse pendant une partition ? » — pas comme un débat théorique. Utilisez cette checklist avant de choisir un mode de base de données, une stratégie de cache ou un mode de réplication.
1) Une courte checklist CAP
Posez ces questions dans l’ordre :
- Qu’est‑ce qui doit être correct ? (ex. « un solde bancaire ne doit jamais devenir négatif », « l’inventaire ne doit pas sur‑vendre », « les permissions doivent être exactes »)
- Qu’est‑ce qui doit rester up ? (ex. endpoint checkout, login, catalogue en lecture seule)
- Qu’est‑ce qui peut se dégrader temporairement ? (ex. analytics, recommandations, avatars de profil, « vu pour la dernière fois »)
Si une partition arrive, vous décidez ce que vous protégez en priorité.
2) Décider par type de donnée et par endpoint
Évitez un réglage global comme « nous sommes AP ». Décidez par :
- Type de donnée : argent vs likes vs logs
- Endpoint : « passer commande » vs « voir commande » vs « suivre livraison »
Exemple : durant une partition, vous pouvez bloquer les écritures sur payments (préserver la cohérence) tout en gardant les lectures de product_catalog disponibles via cache.
3) Définir l’« incohérence acceptable » en termes concrets
Écrivez ce que vous tolérez, avec exemples :
- Plage temporelle : « les compteurs peuvent avoir 5–10 minutes de retard »
- Amplitude : « l’inventaire peut varier de ±1 pour les articles peu demandés »
- Par champ : « l’ETA d’un envoi peut être périmée ; le total de commande ne l’est pas »
- Texte utilisateur : « afficher ‘en attente’ au lieu d’un statut définitif »
Si vous ne pouvez pas décrire l’incohérence en exemples simples, vous aurez du mal à la tester et à expliquer les incidents.
4) Conclusions + lectures recommandées
- Les partitions transforment des garanties « agréables à avoir » en choix forcés.
- Rendre ces choix explicites par endpoint et documenter l’incohérence acceptable.
Sujets suivants qui s’accordent bien avec cette checklist : consensus (/blog/consensus-vs-cap), modèles de cohérence (/blog/consistency-models-explained) et SLOs / budgets d’erreur (/blog/sre-slos-error-budgets).