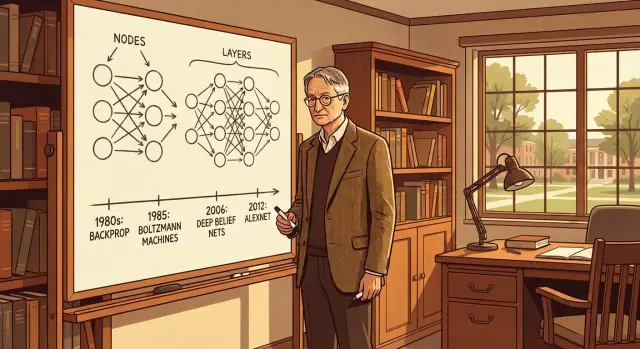
Pourquoi Geoffrey Hinton compte
Ce guide s'adresse aux lecteurs curieux et non techniques qui entendent souvent que « les réseaux neuronaux ont tout changé » et qui veulent une explication claire et ancrée de ce que cela signifie réellement — sans avoir besoin de calcul intégral ou de programmation.
Ce que vous apprendrez ici
Vous aurez un aperçu en langage clair des idées que Geoffrey Hinton a contribué à faire avancer, pourquoi elles importaient à l'époque, et comment elles se relient aux outils d'IA utilisés aujourd'hui. Pensez-y comme à une histoire sur de meilleures façons d'apprendre aux ordinateurs à reconnaître des motifs — mots, images, sons — en apprenant à partir d'exemples.
Pourquoi Hinton compte (sans hyperbole)
Hinton n'a pas « inventé l'IA », et aucune personne seule n'a créé l'apprentissage automatique moderne. Son importance tient au fait qu'il a, à plusieurs reprises, aidé à rendre les réseaux neuronaux utilisables en pratique quand beaucoup de chercheurs pensaient qu'ils étaient des impasses. Il a apporté des concepts clés, des expériences et une culture de recherche qui ont placé l'apprentissage de représentations (des caractéristiques internes utiles) au centre du problème — plutôt que le codage manuel de règles.
Un aperçu rapide des percées abordées
Dans les sections qui suivent, nous détaillerons :
- la rétropropagation comme moyen pratique d'améliorer un réseau en apprenant de ses erreurs
- les machines de Boltzmann et l'apprentissage basé sur l'énergie comme voie ancienne pour apprendre la structure des données
- l'apprentissage de représentations et pourquoi de « bonnes caractéristiques » peuvent être apprises plutôt que conçues
- les réseaux de croyance profonds, le dropout, et les astuces d'entraînement qui ont rendu possibles des modèles plus profonds
- AlexNet et le moment où les réseaux neuronaux se sont imposés à grande échelle
Qu'est-ce qu'une « percée » en réseaux neuronaux ?
Dans cet article, une percée signifie un changement qui rend les réseaux neuronaux plus utiles : ils s'entraînent plus de manière fiable, apprennent de meilleures caractéristiques, généralisent mieux à de nouvelles données, ou montent en échelle vers des tâches plus difficiles. Il s'agit moins d'une démonstration spectaculaire et plus de transformer une idée en une méthode fiable.
Le problème que tentaient de résoudre les réseaux neuronaux
Les réseaux neuronaux n'ont pas été inventés pour « remplacer les programmeurs ». Leur promesse initiale était plus précise : construire des machines capables d'apprendre des représentations internes utiles à partir d'entrées réelles et désordonnées — images, parole et texte — sans que des ingénieurs codent manuellement chaque règle.
Des entrées brutes au sens
Une photo n'est que des millions de valeurs de pixels. Un enregistrement sonore est une suite de mesures de pression. Le défi est de transformer ces nombres bruts en concepts qui comptent pour les gens : bords, formes, phonèmes, mots, objets, intentions.
Avant que les réseaux neuronaux ne deviennent pratiques, de nombreux systèmes reposaient sur des caractéristiques conçues à la main — des mesures soigneusement élaborées comme des détecteurs de bords ou des descripteurs de texture. Cela fonctionnait dans des contextes restreints, mais échouait souvent quand la lumière changeait, que les accents différaient ou que l'environnement devenait plus complexe.
Les réseaux neuronaux visaient à résoudre cela en apprenant automatiquement des caractéristiques, couche par couche, à partir des données. Si un système peut découvrir les bons blocs de construction intermédiaires par lui-même, il peut mieux généraliser et s'adapter à de nouvelles tâches avec moins d'ingénierie manuelle.
Pourquoi cela a été difficile pendant des décennies
L'idée était séduisante, mais plusieurs barrières ont empêché les réseaux de tenir leurs promesses pendant longtemps :
- Calcul : l'entraînement nécessitait un très grand nombre de calculs. Dans les années 1980 et 1990, la plupart des laboratoires n'avaient tout simplement pas assez de puissance pour des modèles volumineux.
- Données : les grands ensembles de données étiquetées qui rendent l'apprentissage fiable n'étaient pas largement disponibles avant les années 2000.
- Stabilité de l'entraînement : les réseaux multicouches précoces étaient difficiles à entraîner correctement ; le progrès dépendait d'algorithmes d'apprentissage et d'astuces pratiques encore immatures.
La persistance comme stratégie
Même lorsque les réseaux neuronaux étaient impopulaires — notamment dans les années 1990 et au début des années 2000 — des chercheurs comme Geoffrey Hinton ont continué à pousser l'apprentissage de représentations. Il a proposé des idées (à partir du milieu des années 1980) et revisité des concepts anciens (comme les modèles basés sur l'énergie) jusqu'à ce que le matériel, les données et les méthodes rattrapent le retard.
Cette persistance a aidé à maintenir l'objectif central vivant : des machines qui apprennent les bonnes représentations, pas seulement la réponse finale.
La rétropropagation, en langage clair
La rétropropagation (souvent appelée « backprop ») est la méthode qui permet à un réseau neuronal de s'améliorer en apprenant de ses erreurs. Le réseau fait une prédiction, on mesure à quel point il s'est trompé, puis on ajuste les « boutons » internes du réseau (ses poids) pour qu'il fasse un peu mieux la prochaine fois.
Apprendre en corrigeant les erreurs
Imaginez un réseau qui tente d'étiqueter une photo « chat » ou « chien ». Il suppose « chat », mais la bonne réponse est « chien ». La rétropropagation commence par cette erreur finale et remonte en arrière à travers les couches du réseau, déterminant dans quelle mesure chaque poids a contribué à la mauvaise réponse.
Une façon pratique de l'envisager :
- Passage avant : faire une supposition.
- Loss : calculer l'erreur (à quel point la supposition est éloignée).
- Passage arrière : répartir la « faute » à travers les couches.
- Mise à jour : ajuster les poids pour réduire cette erreur la prochaine fois.
Ces ajustements se font généralement avec un algorithme compagnon appelé descente de gradient, qui signifie simplement « faire de petits pas en descente sur l'erreur ».
Ce que la rétropropagation a rendu possible
Avant l'adoption généralisée de la rétropropagation, entraîner des réseaux multicouches était peu fiable et lent. La rétropropagation a rendu possible l'entraînement de réseaux plus profonds parce qu'elle fournissait un moyen systématique et reproductible d'ajuster plusieurs couches à la fois — plutôt que de n'ajuster que la couche finale ou de deviner des corrections.
Ce changement a compté pour les percées qui ont suivi : une fois que l'on peut entraîner efficacement plusieurs couches, les réseaux peuvent apprendre des caractéristiques plus riches (bords → formes → objets, par exemple).
Idées fausses courantes
La rétropropagation n'est pas le réseau en train de « penser » ou de « comprendre » comme une personne. C'est un retour mathématique : une façon d'ajuster des paramètres pour mieux correspondre aux exemples.
De plus, la rétropropagation n'est pas un modèle unique — c'est une méthode d'entraînement qui peut être utilisée pour de nombreux types de réseaux neuronaux.
Si vous voulez un approfondissement doux sur la structure des réseaux, voyez /blog/neural-networks-explained.
Machines de Boltzmann et apprentissage basé sur l'énergie
Les machines de Boltzmann ont été une étape clé de Geoffrey Hinton pour faire en sorte que les réseaux neuronaux apprennent des représentations internes utiles, et pas seulement donnent des réponses.
L'idée de base : un score d'« énergie » pour chaque possibilité
Une machine de Boltzmann est un réseau d'unités simples qui peuvent être activées/désactivées (ou prendre des valeurs réelles dans des versions modernes). Plutôt que de prédire directement une sortie, elle attribue une énergie à une configuration complète d'unités. Une énergie plus faible signifie « cette configuration a du sens ».
Une analogie utile est une table parsemée de creux et de vallées. Si vous laissez tomber une bille sur la surface, elle roulent et se stabilise dans un point bas. Les machines de Boltzmann cherchent à faire quelque chose de similaire : données des unités visibles (fixées par les données), le réseau « bouge » ses unités internes jusqu'à se stabiliser dans des états de faible énergie — des états qu'il a appris à considérer comme probables.
Pourquoi c'était important (même si c'était lent)
L'entraînement des machines de Boltzmann classiques impliquait d'échantillonner à plusieurs reprises de nombreuses configurations possibles pour estimer ce que le modèle croit par rapport aux données. Cet échantillonnage peut être terriblement lent, surtout pour de grands réseaux.
Pourtant, l'approche a été influente parce qu'elle :
- a encadré l'apprentissage comme la mise en forme d'une distribution de probabilité, pas seulement l'ajustement d'étiquettes
- a poussé le domaine vers l'apprentissage non supervisé (apprendre à partir de données sans réponses explicites)
- a inspiré des raccourcis pratiques comme la divergence contrastive et des réflexions ultérieures sur les méthodes basées sur l'énergie
Comparaison avec les réseaux profonds d'aujourd'hui
La plupart des produits actuels reposent sur des réseaux profonds feedforward entraînés par rétropropagation car ils sont plus rapides et plus faciles à mettre à l'échelle.
L'héritage des machines de Boltzmann est surtout conceptuel : l'idée que de bons modèles apprennent des « états préférés » du monde — et que l'apprentissage peut s'interpréter comme le déplacement de masse de probabilité vers ces vallées de faible énergie.
Apprentissage de représentations : l'idée centrale des percées
Les réseaux neuronaux ne se sont pas contentés de mieux ajuster des courbes — ils se sont améliorés pour inventer les bonnes caractéristiques. C'est ce que signifie « apprentissage de représentations » : au lieu qu'un humain définisse ce qu'il faut regarder, le modèle apprend des descriptions internes (représentations) qui facilitent la tâche.
Ce que sont les « représentations »
Une représentation est la façon dont le modèle résume son entrée brute. Ce n'est pas encore une étiquette comme « chat » ; c'est la structure utile en route vers cette étiquette — des motifs qui captent ce qui a tendance à importer. Les couches précoces peuvent répondre à des signaux simples, tandis que les couches ultérieures les combinent en concepts plus significatifs.
Avant ce changement, de nombreux systèmes dépendaient de caractéristiques conçues par des experts : détecteurs de bords pour les images, indicateurs audio pour la parole, ou statistiques textes ingénieuses. Ces caractéristiques fonctionnaient, mais se cassaient souvent quand les conditions changeaient (éclairage, accents, formulations).
L'apprentissage de représentations a permis aux modèles d'adapter les caractéristiques aux données elles-mêmes, ce qui a amélioré la précision et rendu les systèmes plus résilients face aux entrées réelles et bruitées.
Une même idée, plusieurs domaines
- Vision : les pixels deviennent des concepts visuels de plus en plus structurés.
- Parole : les ondes sonores deviennent des motifs proches des phonèmes, puis des mots.
- Langage : les tokens deviennent des phrases, des significations et des relations entre idées.
Le fil conducteur est la hiérarchie : des motifs simples se combinent pour former des motifs plus riches.
En reconnaissance d'images, un réseau peut d'abord apprendre des motifs ressemblant à des bords (changements clair-obscur). Ensuite, il combine les bords en coins et courbes, puis en parties comme des roues ou des yeux, et enfin en objets complets comme « bicyclette » ou « visage ».
Les percées de Hinton ont aidé à rendre pratique cette construction de caractéristiques par couches — et c'est une grande raison pour laquelle l'apprentissage profond a commencé à gagner sur des tâches qui importent vraiment aux gens.
Réseaux de croyance profonds et la route vers des modèles plus profonds
Créez à partir d'une idée simple
Transformez vos connaissances en réseaux neuronaux en une application fonctionnelle en la décrivant dans le chat.
Les réseaux de croyance profonds (DBN) ont été une étape importante vers les réseaux profonds d'aujourd'hui. Globalement, un DBN est une pile de couches où chaque couche apprend à représenter la couche en dessous — en partant des entrées brutes et en construisant progressivement des « concepts » plus abstraits.
Ce qu'est un DBN (conceptuellement)
Imaginez enseigner à un système la reconnaissance d'écritures manuscrites. Au lieu d'apprendre tout en une fois, un DBN apprend d'abord des motifs simples (comme des bords et des traits), puis des combinaisons de ces motifs (boucles, coins), et finalement des formes qui ressemblent à des parties de chiffres.
L'idée clé est que chaque couche tente de modéliser les motifs de son entrée sans connaître encore la bonne réponse. Puis, une fois la pile formée, on peut affiner l'ensemble du réseau pour une tâche spécifique comme la classification.
Pourquoi le pré-entraînement couche par couche importait
Les réseaux profonds initialement avaient souvent du mal à s'entraîner correctement lorsqu'ils étaient initialisés aléatoirement. Le signal d'entraînement pouvait s'affaiblir ou devenir instable en traversant de nombreuses couches, et le réseau pouvait se stabiliser dans des configurations peu utiles.
Le pré-entraînement couche par couche offrait un « départ chaud ». Chaque couche commençait avec une compréhension raisonnable de la structure des données, de sorte que le réseau complet ne cherchait pas à l'aveugle.
Le pré-entraînement n'a pas résolu tous les problèmes miraculeusement, mais il a rendu la profondeur pratique à une époque où les données, la puissance de calcul et les astuces d'entraînement étaient plus limitées qu'aujourd'hui.
Les DBN ont démontré que l'apprentissage de bonnes représentations sur plusieurs couches pouvait fonctionner — et que la profondeur n'était pas que théorie, mais une voie utilisable.
Dropout et la lutte contre le surapprentissage
Les réseaux neuronaux peuvent être étrangement bons pour « bachoter » dans le mauvais sens : ils mémorisent les données d'entraînement au lieu d'apprendre le motif sous-jacent. Ce problème s'appelle le surapprentissage (overfitting), et il se manifeste chaque fois qu'un modèle semble excellent sur des exemples familiers mais déçoit sur de nouvelles données réelles.
Le surapprentissage, avec un exemple de la vie courante
Imaginez que vous vous prépariez à un examen de conduite en mémorisant exactement l'itinéraire utilisé par votre instructeur — chaque tournant, chaque panneau, chaque nid-de-poule. Si l'examen reprend le même itinéraire, vous réussirez brillamment. Mais si l'itinéraire change, vos performances chutent car vous n'avez pas appris la compétence générale de conduire ; vous avez appris un script spécifique.
C'est le surapprentissage : grande précision sur des exemples familiers, résultats plus faibles sur des exemples nouveaux.
Dropout : une idée simple qui marche
Le dropout a été popularisé par Geoffrey Hinton et des collaborateurs comme une astuce d'entraînement étonnamment simple. Pendant l'entraînement, le réseau désactive aléatoirement certaines de ses unités à chaque passage sur les données.
Cela force le modèle à ne pas compter sur un chemin ou un jeu de caractéristiques favoris. À la place, il doit répartir l'information à travers de nombreuses connexions et apprendre des motifs qui tiennent encore quand des parties du réseau sont absentes.
Un modèle mental utile : c'est comme étudier en perdant occasionnellement l'accès à des pages aléatoires de vos notes — vous êtes poussé à comprendre le concept, pas à mémoriser un phrasé unique.
Ce que le dropout a amélioré
Le gain principal est une meilleure généralisation : le réseau devient plus fiable sur des données qu'il n'a pas vues. En pratique, le dropout a facilité l'entraînement de réseaux plus grands sans qu'ils ne tombent dans la simple mémorisation, et il est devenu un outil courant dans de nombreux montages de deep learning.
AlexNet : le moment où l'apprentissage profond est devenu grand public
Gardez votre code portable
Obtenez le code source pour que votre équipe puisse le revoir, le modifier et s'approprier le projet.
Pourquoi les benchmarks d'images comptaient
Avant AlexNet, la « reconnaissance d'images » n'était pas qu'une démo sympa : c'était une compétition mesurable. Des benchmarks comme ImageNet posaient une question simple : donné une photo, votre système peut-il dire ce qu'il y a dedans ?
Le hic était l'échelle : des millions d'images et des milliers de catégories. Cette taille importait parce qu'elle distinguait les idées qui semblaient bonnes dans de petites expériences des méthodes qui tenaient quand le monde devenait brouillon.
Les progrès sur ces tableaux d'honneur étaient généralement incrémentaux. Puis AlexNet (construit par Alex Krizhevsky, Ilya Sutskever et Geoffrey Hinton) est arrivé et a donné l'impression d'un pas en avant plutôt que d'une montée lente.
Ce qu'AlexNet a réellement démontré
AlexNet a montré qu'un réseau convolutionnel profond pouvait battre les meilleurs pipelines traditionnels de vision quand trois ingrédients étaient combinés :
- Convolutions (couches spéciales qui exploitent la structure des images)
- GPU (pour entraîner un gros modèle en un temps raisonnable)
- Beaucoup de données étiquetées (l'échelle d'ImageNet)
Ce n'était pas seulement « un modèle plus grand ». C'était une recette pratique pour entraîner des réseaux profonds efficacement sur des tâches du monde réel.
La convolution, expliquée visuellement (sans math)
Imaginez glisser une petite « fenêtre » sur une photo — comme déplacer un timbre-poste à travers l'image. Dans cette fenêtre, le réseau cherche un motif simple : un bord, un coin, une bande. Le même détecteur de motif est réutilisé partout sur l'image, de sorte qu'il peut trouver des « choses semblables à des bords » qu'elles soient à gauche, à droite, en haut ou en bas.
Empilez suffisamment de ces couches et vous obtenez une hiérarchie : les bords deviennent des textures, les textures deviennent des parties (comme des roues), et les parties deviennent des objets (comme une bicyclette).
Pourquoi cela a bouleversé l'industrie
AlexNet a rendu l'apprentissage profond tangible et digne d'investissement. Si les réseaux profonds pouvaient dominer un benchmark difficile et public, ils pouvaient probablement aussi améliorer des produits — recherche, étiquetage de photos, fonctionnalités d'appareil photo, outils d'accessibilité, et plus encore.
Il a contribué à transformer les réseaux neuronaux de « recherche prometteuse » en une direction évidente pour les équipes qui construisent des systèmes réels.
Ce qui a changé : données, calcul et entraînement pratique
L'apprentissage profond n'est pas « arrivé du jour au lendemain ». Il a commencé à paraître spectaculaire quand quelques ingrédients se sont alignés — après des années de travaux antérieurs montrant que les idées étaient prometteuses mais difficiles à mettre à l'échelle.
Les trois ingrédients qui ont fait décoller
Plus de données. Le web, les smartphones et les grands ensembles étiquetés (comme ImageNet) ont permis aux réseaux d'apprendre à partir de millions d'exemples au lieu de milliers. Avec peu de données, les gros modèles mémorisent surtout.
Plus de calcul (surtout les GPU). Entraîner un réseau profond signifie refaire les mêmes calculs des milliards de fois. Les GPU ont rendu cela abordable et suffisamment rapide pour itérer. Ce qui prenait des semaines pouvait prendre des jours — ou des heures — permettant d'essayer plus d'architectures et d'hyperparamètres.
Meilleures astuces d'entraînement. Des améliorations pratiques ont réduit l'aléatoire du « ça s'entraîne… ou pas » :
- meilleures initialisations et choix d'optimisation
- normalisation et pipelines d'entrée plus propres
- méthodes de régularisation comme le dropout pour freiner le surapprentissage
- fonctions d'activation et motifs architecturaux améliorés
Aucun de ces éléments n'a changé l'idée centrale des réseaux neuronaux ; ils ont rendu leur entraînement plus fiable.
Pourquoi les progrès ont paru soudains
Une fois que le calcul et les données ont atteint un seuil, les améliorations ont commencé à s'empiler. De meilleurs résultats ont attiré plus d'investissements, qui ont financé de plus grands ensembles et du matériel plus rapide, ce qui a permis d'obtenir de meilleurs résultats encore. De l'extérieur, cela ressemble à un saut ; de l'intérieur, c'est de la composition.
Les compromis : modèles plus grands, coûts plus élevés
Monter en échelle entraîne des coûts réels : consommation d'énergie plus importante, runs d'entraînement plus chers, et plus d'efforts pour déployer les modèles efficacement. Cela creuse aussi l'écart entre ce qu'une petite équipe peut prototyper et ce que seules des structures bien financées peuvent entraîner depuis zéro.
Les idées clés de Hinton — apprendre des représentations utiles à partir des données, entraîner des réseaux profonds de manière fiable et prévenir le surapprentissage — ne sont pas des « fonctionnalités » visibles dans une appli. Elles expliquent pourquoi de nombreuses fonctionnalités du quotidien semblent plus rapides, plus précises et moins frustrantes.
Recherche et recommandations
Les systèmes de recherche modernes ne se contentent pas d'associer des mots-clés. Ils apprennent des représentations des requêtes et du contenu pour que « meilleurs casques anti-bruit » fasse remonter des pages qui ne répètent pas exactement la même phrase. Le même apprentissage de représentations aide les fils de recommandation à comprendre que deux éléments sont « similaires » même si leurs descriptions diffèrent.
Traduction et outils de texte
La traduction automatique s'est améliorée fortement lorsque les modèles ont mieux appris des motifs hiérarchiques (des caractères aux mots, puis au sens). Même si le type de modèle a évolué, la boîte à outils d'entraînement — grands ensembles, optimisation soignée et régularisation — continue d'orienter la façon dont les équipes construisent des fonctionnalités linguistiques fiables.
Voix et reconnaissance vocale
Les assistants vocaux et la dictée reposent sur des réseaux qui transforment l'audio bruité en texte propre. La rétropropagation est l'outil de travail qui affine ces modèles, tandis que des techniques comme le dropout les empêchent de mémoriser les particularités d'un locuteur ou d'un micro.
Photos : étiquetage, regroupement et « recherche par image »
Les applis photo peuvent reconnaître des visages, regrouper des scènes similaires et permettre une recherche « plage » sans étiquetage manuel. C'est l'apprentissage de représentations en action : le système apprend des caractéristiques visuelles (bords → textures → objets) qui rendent l'étiquetage et la recherche robustes à grande échelle.
Où ces idées restent utilisées
Même si vous n'entraînez pas de modèles depuis zéro, ces principes apparaissent dans le travail produit quotidien : commencer avec de bonnes représentations (souvent via des modèles préentraînés), stabiliser l'entraînement et l'évaluation, et utiliser la régularisation quand les systèmes commencent à « mémoriser » le benchmark.
C'est aussi pourquoi des outils modernes de « vibe-coding » peuvent paraître si efficaces. Des plateformes comme Koder.ai s'appuient sur des LLMs de génération actuelle et des workflows agents pour aider les équipes à transformer des spécifications en langage naturel en applications web, backend ou mobiles — souvent plus vite que les pipelines traditionnels — tout en permettant d'exporter le code source et de déployer comme une équipe d'ingénierie normale.
Si vous voulez l'intuition d'entraînement à haut niveau, voyez /blog/backpropagation-explained.
Mythes courants à propos de Hinton et des réseaux neuronaux
Soyez récompensé en partageant
Gagnez des crédits en créant du contenu sur votre projet et en partageant vos apprentissages.
Les grandes percées deviennent souvent des histoires simples. Cela les rend plus faciles à retenir — mais cela génère aussi des mythes qui cachent ce qui s'est réellement passé et ce qui compte encore aujourd'hui.
Mythe : « Une seule personne a inventé l'IA »
Hinton est une figure centrale, mais les réseaux neuronaux modernes résultent de décennies de travaux collectifs : chercheurs qui ont développé des méthodes d'optimisation, personnes qui ont construit des jeux de données, ingénieurs qui ont rendu les GPU pratiques pour l'entraînement, et équipes qui ont prouvé des idées à grande échelle.
Même au sein du travail attribué à Hinton, ses étudiants et collaborateurs ont joué des rôles majeurs. La véritable histoire est une chaîne de contributions qui se sont enfin alignées.
Mythe : « Les réseaux neuronaux sont complètement nouveaux »
Les réseaux neuronaux sont étudiés depuis le milieu du 20ᵉ siècle, avec des périodes d'engouement et de déception. Ce qui a changé, ce n'est pas l'existence de l'idée, mais la capacité d'entraîner des modèles plus grands de manière fiable et de montrer des gains clairs sur des problèmes réels.
L'« ère de l'apprentissage profond » est plutôt une résurgence qu'une invention soudaine.
Mythe : « Plus de couches, c'est toujours mieux »
Les modèles plus profonds peuvent aider, mais ce n'est pas magique. Le temps d'entraînement, le coût, la qualité des données et les rendements décroissants sont des contraintes réelles. Parfois, des modèles plus petits surpassent des modèles plus gros parce qu'ils sont plus faciles à régler, moins sensibles au bruit ou mieux adaptés à la tâche.
Mythe : « La rétropropagation équivaut à l'apprentissage humain »
La rétropropagation est une méthode pratique pour ajuster des paramètres à partir d'un retour étiqueté. Les humains apprennent avec beaucoup moins d'exemples, utilisent des connaissances préalables riches et n'utilisent pas les mêmes signaux d'erreur explicites.
Les réseaux neuronaux peuvent être inspirés par la biologie sans en être des répliques fidèles.
Leçons à retenir
L'histoire de Hinton n'est pas qu'une liste d'inventions. C'est un modèle : garder une idée simple d'apprentissage, la tester sans relâche, et améliorer les ingrédients environnants (données, calcul, astuces d'entraînement) jusqu'à ce qu'elle fonctionne à l'échelle.
Ce que les bâtisseurs d'aujourd'hui peuvent reproduire
Les habitudes les plus transférables sont pratiques :
- Itérer en boucles courtes. Traitez chaque exécution comme une petite expérience : changez une chose, enregistrez le résultat, répétez.
- Mesurer ce qui compte. Suivez une métrique claire (précision, taux d'erreur, latence, coût par requête) et comparez à une base. « Mieux » doit être chiffré.
- Simplifier les explications. Si vous ne pouvez pas expliquer l'objectif, les entrées et les modes de défaillance à un collègue non expert, vous ne pourrez probablement pas livrer en sécurité.
Ce qu'il ne faut pas copier
Il est tentant de retenir de gros titres « les modèles plus gros gagnent ». C'est incomplet.
Poursuivre la taille sans but clair conduit souvent à :
- des coûts plus élevés sans amélioration visible pour les utilisateurs
- un débogage plus difficile quand tout va mal
- des équipes optimisant des benchmarks plutôt que des résultats produits
Un meilleur principe : commencez petit, prouvez la valeur, puis montez en échelle — et ne scalez que la partie qui limite clairement la performance.
Lectures suggérées
Si vous voulez transformer ces leçons en pratiques quotidiennes, voici des lectures utiles :
- /blog/ai-model-evaluation
- /blog/how-to-reduce-overfitting
- /blog/representation-learning-explained
Une histoire à retenir
De la règle d'apprentissage basique de la rétropropagation, aux représentations qui captent le sens, en passant par des astuces pratiques comme le dropout, jusqu'à une démonstration décisive comme AlexNet — l'arc est cohérent : apprendre des caractéristiques utiles à partir des données, stabiliser l'entraînement, et valider les progrès par des résultats concrets.
C'est la fiche de jeu à garder.