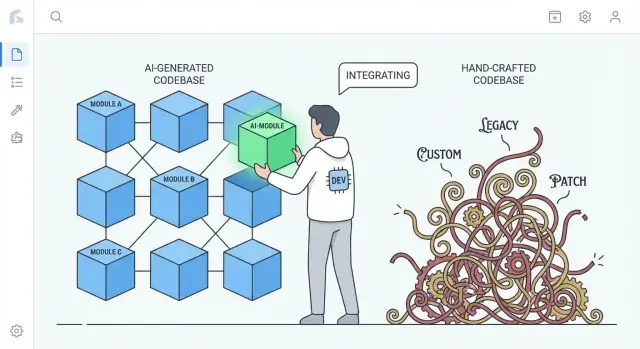
Ce que « plus facile à remplacer » signifie dans des projets réels
« Plus facile à remplacer » ne veut rarement dire supprimer toute une application et repartir de zéro. Dans les équipes réelles, le remplacement se fait à différentes échelles, et ce que « réécrire » signifie dépend de ce que vous remplacez.
Remplacer vs réécrire : ce qui est réellement envisageable
Un remplacement peut être :
- Un module (règles de facturation, génération de PDF, gabarits d’email)
- Un service (API de recommandation, worker en arrière‑plan)
- Une surface front‑end (une page, une zone fonctionnelle, ou l’UI entière)
- Une réécriture complète de l’app (rare, coûteuse, parfois nécessaire)
Quand on dit qu’une base de code est « plus facile à récrire », on veut généralement dire que vous pouvez redémarrer une tranche sans tout défaire, garder le business en fonctionnement et migrer progressivement.
La vraie comparaison : code généré par l’IA vs code fortement artisanal
Ce n’est pas un argument « le code IA est meilleur ». C’est à propos de tendances communes.
- Le code artisanal très personnalisé peut accumuler des patterns uniques, des abstractions ingénieuses et des mini‑frameworks internes. C’est parfois excellent, mais cela crée un écosystème privé que peu de personnes comprennent.
- Le code généré par l’IA tend souvent vers des valeurs par défaut familières : bibliothèques mainstream, couches conventionnelles et patterns que l’on retrouve dans de nombreux projets de référence.
Cette différence compte pour une réécriture : du code qui suit des conventions largement comprises peut souvent être remplacé par une implémentation conventionnelle différente avec moins de négociation et moins de surprises.
Poser les attentes : le code IA peut être désordonné
Le code généré par l’IA peut être incohérent, répétitif ou peu testé. « Plus facile à remplacer » n’est pas une affirmation qu’il est plus propre — c’est qu’il est souvent moins « spécial ». Si un sous‑système est construit à partir d’ingrédients courants, le remplacer ressemble plus à changer une pièce standard qu’à rétro‑concevoir une machine sur mesure.
Aperçu : pourquoi la standardisation réduit le coût du changement
L’idée centrale est simple : la standardisation réduit les coûts de changement. Quand le code est composé de patterns reconnaissables et de coutures (seams) claires, vous pouvez régénérer, refactorer ou réécrire des parties avec moins de crainte de casser des dépendances cachées. Les sections ci‑dessous montrent comment cela se manifeste en termes de structure, de propriété, de tests et de vélocité d’ingénierie au quotidien.
Les patterns standard réduisent le coût du redémarrage
Un avantage pratique du code généré par l’IA est qu’il tend à utiliser des patterns reconnaissables : arborescences de dossiers familières, noms prévisibles, conventions de framework mainstream et approches « livresques » pour le routage, la validation, la gestion d’erreurs et l’accès aux données. Même quand le code n’est pas parfait, il est généralement lisible de la même façon que beaucoup de tutoriels et de projets de démarrage.
La familiarité l’emporte sur l’originalité quand il faut réécrire
Les réécritures sont coûteuses surtout parce que les gens doivent d’abord comprendre ce qui existe. Du code qui suit des conventions bien connues réduit ce temps de « décodage ». Les nouveaux ingénieurs peuvent mapper ce qu’ils voient sur des modèles mentaux qu’ils possèdent déjà : où se trouve la configuration, comment les requêtes circulent, comment les dépendances sont câblées, et où vont les tests.
Cela accélère :
- l’identification des coutures à remplacer (modules, services, endpoints)
- la reproduction du comportement dans une nouvelle implémentation
- la comparaison ancien/nouveau sans traduction entre styles
En revanche, les bases de code très artisanales reflètent souvent un style profondément personnel : abstractions uniques, mini‑frameworks personnalisés, glue ingénieuse, ou patterns spécifiques au domaine qui n’ont de sens qu’avec le contexte historique. Ces choix peuvent être élégants — mais ils augmentent le coût du redémarrage parce qu’une réécriture doit d’abord réapprendre la vision de l’auteur.
On peut appliquer des conventions quel que soit l’auteur
Ce n’est pas un miracle réservé à l’IA. Les équipes peuvent (et doivent) imposer structure et style via des templates, linters, formatters et outils de scaffolding. La différence est que l’IA tend à produire du « générique par défaut », tandis que le code écrit par des humains dérive parfois vers du sur‑mesure si les conventions ne sont pas activement maintenues.
Moins de « glue » sur mesure peut signifier moins de dépendances cachées
Beaucoup de douleur lors des réécritures ne vient pas de la logique métier principale mais du glue sur mesure — helpers personnalisés, micro‑frameworks internes, metaprogramming, et conventions one‑off qui connectent tout silencieusement.
Qu’est‑ce que le « glue » sur mesure
Le glue sur mesure, c’est ce qui ne fait pas partie de votre produit mais sans quoi votre produit ne fonctionne pas. Exemples : un conteneur d’injection de dépendances maison, une couche de routage bricolée, une classe de base magique qui auto‑enregistre des modèles, ou des helpers qui mutent un état global « par commodité ». Ça commence souvent comme un gain de temps et finit comme un savoir‑faire requis pour chaque changement.
Pourquoi le glue unique augmente le couplage (et le risque de réécriture)
Le problème n’est pas que le glue existe — c’est qu’il devient un couplage invisible. Quand le glue est propre à votre équipe, il :
- Crée des dépendances implicites (ça marche seulement parce que des helpers s’exécutent dans un certain ordre)
- Répand des hypothèses dans les fichiers (des conventions de nommage deviennent du comportement)
- Rend les refactors « simples » risqués (changez le glue, cassez tout)
Pendant une réécriture, ce glue est dur à reproduire correctement parce que les règles sont rarement écrites. On les découvre en cassant en production.
Pourquoi le code IA évite souvent l’extrême ingéniosité
Les sorties IA penchent souvent vers des bibliothèques standard, des patterns explicites et un câblage visible. L’IA n’invente pas un micro‑framework quand un simple module ou objet service suffit. Cette retenue peut être une caractéristique : moins de hooks magiques signifie moins de dépendances cachées, ce qui rend plus facile d’extraire un sous‑système et de le remplacer.
Le compromis : verbosité plutôt que ruse
Le revers est que le code « simple » peut être plus verbeux — davantage de paramètres, un plumbing plus explicite, moins de raccourcis. Mais la verbosité coûte généralement moins cher que le mystère. Quand vous décidez de réécrire, vous voulez du code facile à comprendre, facile à supprimer et difficile à mal interpréter.
Une structure prévisible facilite les réécritures incrémentales
« Structure prévisible » concerne moins l’esthétique que la cohérence : mêmes dossiers, mêmes règles de nommage et mêmes flux de requêtes partout. Les projets générés par l’IA tendent vers des valeurs par défaut familières — controllers/, services/, repositories/, models/ — avec des endpoints CRUD répétitifs et des patterns de validation similaires.
Cette uniformité importe parce qu’elle transforme une réécriture d’un saut en falaise en un escalier.
À quoi ressemble la prévisibilité
Vous voyez des patterns répétés à travers les fonctionnalités :
- Frontières de dossiers claires (API → service → accès aux données)
- Nommage cohérent (
UserService, UserRepository, UserController)
- Flux CRUD similaire (list → get → create → update → delete)
- Forme standard pour les erreurs, logs et objets requête/réponse
Quand chaque feature est construite de la même façon, vous pouvez remplacer une pièce sans réapprendre le système à chaque fois.
Remplacer une pièce à la fois
Les réécritures incrémentales fonctionnent mieux quand vous pouvez isoler une frontière et reconstruire derrière elle. Les structures prévisibles créent naturellement ces coutures : chaque couche a un rôle étroit et la plupart des appels passent par un petit ensemble d’interfaces.
Une approche pratique est le style « strangler » : garder l’API publique stable et remplacer progressivement les internals.
Exemple : remplacer la couche d’accès aux données sans toucher l’API
Supposons que vos contrôleurs appellent un service, et que le service appelle un repository :
OrdersController → OrdersService → OrdersRepository
Vous voulez passer de requêtes SQL directes à un ORM, ou d’une base à une autre. Dans une base de code prévisible, le changement peut être contenu :
- Créer
OrdersRepositoryV2 (nouvelle implémentation)
- Conserver les signatures de méthode (
getOrder(id), listOrders(filters))
- Changer le câblage en un seul endroit (injection de dépendance ou factory)
- Lancer les tests et déployer feature par feature
Le controller et le service restent en grande partie inchangés.
Contraste : architectures artisanales
Les systèmes très artisanaux peuvent être excellents — mais ils codent souvent des idées uniques : abstractions personnalisées, metaprogramming astucieux ou comportements transverses cachés dans des classes de base. Chaque changement exige alors un contexte historique profond. Avec une structure prévisible, la question « où changer ça ? » est généralement simple, ce qui rend des petites réécritures faisables semaine après semaine.
Un moindre « attachement à l’auteur » rend la suppression plus acceptable
Un frein silencieux aux réécritures n’est pas technique mais social. Les équipes portent souvent un risque de propriété, où une seule personne comprend vraiment comment le système fonctionne. Quand cette personne a écrit de larges portions du code à la main, le code devient un artefact personnel : « ma conception », « ma solution ingénieuse », « mon contournement qui a sauvé la sortie ». Cet attachement rend la suppression coûteuse émotionnellement, même quand elle est rationnelle économiquement.
Le code généré par l’IA peut réduire cet effet. Parce que l’ébauche initiale est produite par un outil (et suit souvent des patterns familiers), le code ressemble moins à une signature et plus à une implémentation interchangeable. Les gens sont généralement plus à l’aise pour dire « remplaçons ce module » quand cela ne ressemble pas à effacer le travail artisanal de quelqu’un — ou à remettre en cause son statut dans l’équipe.
Pourquoi cela change le comportement autour des réécritures
Quand l’attachement à l’auteur est moindre, les équipes ont tendance à :
- Remettre plus librement en cause le code existant (« est‑ce encore la meilleure approche ? »)
- Supprimer de larges sections sans négocier l’ego
- Regénérer ou remplacer plus tôt, au lieu de mois de patchs prudents
- Partager le savoir plus rapidement, car personne ne considère l’interne comme un territoire « réservé »
Note pratique
Les décisions de réécriture doivent toujours être guidées par le coût et les résultats : délais de livraison, risque, maintenabilité et impact utilisateur. « Facile à supprimer » est une qualité utile — pas une stratégie autonome.
Les prompts et traces de génération peuvent servir de documentation
Compenser les coûts de votre pilote
Créez du contenu ou recommandez des collègues pour gagner des crédits pendant vos expérimentations avec Koder.ai.
Un bénéfice sous‑estimé du code généré par l’IA est que les entrées de la génération peuvent agir comme une spécification vivante. Un prompt, un template et une configuration de générateur peuvent décrire l’intention en langage clair : ce que la fonctionnalité doit faire, quelles contraintes comptent (sécurité, perf, style) et ce que « done » signifie.
Les prompts comme specs vivantes
Quand les équipes utilisent des prompts répétables (ou des bibliothèques de prompts) et des templates stables, elles créent une trace d’audit des décisions qui seraient autrement implicites. Un bon prompt peut indiquer des choses qu’un mainteneur futur devrait deviner :
- le flux utilisateur attendu et les cas limites
- conventions de nommage et structure des dossiers
- comment gérer et logger les erreurs
- ce qui doit être testé (et ce qui peut être simulé)
C’est différemment utile par rapport à beaucoup de bases de code artisanales où les choix de conception clés sont dispersés dans des messages de commit, du savoir tribal et des conventions non écrites.
Les traces de génération aident à reproduire le comportement
Si vous conservez les traces de génération (le prompt + modèle/version + inputs + étapes de post‑traitement), une réécriture ne commence pas à partir de rien. Vous pouvez réutiliser la même checklist pour recréer le même comportement dans une structure plus propre, puis comparer les outputs.
Concrètement, cela peut transformer une réécriture en : « régénérer la fonctionnalité X sous de nouvelles conventions, puis vérifier la parité », au lieu de « rétro‑concevoir ce que la fonctionnalité X était censée faire ».
Avertissement important : traitez les prompts comme du code
Ça ne fonctionne que si prompts et configs sont gérés avec la même rigueur que le code source :
- versionnez‑les dans le repo (pas dans les notes personnelles)
- exigez une revue pour les changements
- enregistrez quel prompt/config a généré quels modules
Sans cela, les prompts deviennent une autre dépendance non documentée. Avec ce discipline, ils peuvent devenir la documentation que les systèmes faits main auraient aimé avoir.
« Plus facile à remplacer » n’est pas vraiment une question de qui a écrit le code, mais de savoir si vous pouvez le modifier en confiance. Une réécriture devient de l’ingénierie de routine quand les tests vous disent, vite et fiablement, que le comportement est resté identique.
Le code généré par l’IA peut aider — si vous le lui demandez. Beaucoup d’équipes demandent la génération de tests boilerplate avec les fonctionnalités (tests unitaires basiques, tests d’intégration happy‑path, mocks simples). Ces tests ne sont pas parfaits, mais ils créent un filet de sécurité initial souvent absent dans les systèmes artisanaux où les tests ont été repoussés « plus tard ».
Priorisez les tests de contrat aux frontières
Si vous voulez de la remplaçabilité, concentrez les efforts de test sur les coutures :
- APIs externes : requêtes, réponses, codes d’erreur, retries, pagination
- Adaptateurs : fournisseurs de paiement, email, stockage, queues
- Modèles de données : migrations, sérialisation, règles de validation
Les tests de contrat verrouillent ce qui doit rester vrai même si vous changez les internals. Cela permet de réécrire un module derrière une API ou de remplacer un adaptateur sans renégocier le comportement métier.
Utilisez la couverture comme boussole, pas comme trophée
Les chiffres de couverture indiquent où se situent les risques, mais viser 100 % produit souvent des tests fragiles qui bloquent les refactors. Au lieu de cela :
- Ajoutez des tests là où les échecs sont coûteux (argent, perte de données, confiance utilisateur)
- Préférez moins de tests à fort signal plutôt que beaucoup de tests superficiels
- Lors d’une réécriture, comparez ancienne et nouvelle implémentation avec les mêmes tests de contrat
Avec des tests solides, les réécritures cessent d’être des projets héroïques et deviennent une série d’étapes sûres et réversibles.
Les défauts courants du code IA sont souvent faciles à repérer et isoler
Rédigez d'abord la spécification
Transformez votre prompt en plan clair : la régénération part de l'intention, pas des suppositions.
Le code généré par l’IA échoue souvent de façons prévisibles : logique dupliquée, branches presque identiques traitant différemment des cas limites, ou fonctions qui s’allongent au fil des « fix » successifs. Rien de tout cela n’est idéal — mais il y a un avantage : les problèmes sont généralement visibles.
Les défauts évidents valent mieux que des bugs subtils
Les systèmes artisanaux peuvent cacher la complexité derrière des abstractions ingénieuses, des micro‑optimisations ou des comportements serrés « juste comme il faut ». Ces bugs sont douloureux parce qu’ils semblent corrects et passent la revue superficielle.
Le code IA est plus susceptible d’être manifestement incohérent : un paramètre ignoré sur un chemin, une validation présente dans un fichier mais pas dans un autre, ou une gestion d’erreurs qui change de style toutes les quelques fonctions. Ces écarts se voient en revue et via l’analyse statique, et ils sont plus faciles à isoler car ils dépendent rarement d’invariants intentionnels profonds.
Les candidats à la réécriture apparaissent par la répétition
La répétition est l’indice. Quand vous voyez la même séquence d’étapes réapparaître — parser l’entrée → normaliser → valider → mapper → renvoyer — vous avez trouvé une couture naturelle à remplacer. L’IA « résout » souvent une nouvelle requête en reproduisant une solution précédente avec des ajustements, ce qui crée des grappes de quasi‑doublons.
Approche pratique : marquez tout bloc répété comme candidat à l’extraction ou au remplacement, surtout quand :
- Il apparaît en 3+ endroits avec de petites différences
- Les différences sont surtout des cas limites ou des messages d’erreur
- Le code n’a pas de propriétaire clair et est sans cesse patché
Règle pratique : consolider les répétitions dans un module testé
Si vous pouvez nommer le comportement répété en une phrase, il devrait probablement devenir un module unique.
Remplacez les morceaux répétés par un composant testé (utilitaire, service partagé ou fonction de bibliothèque), écrivez des tests qui définissent les cas limites attendus, puis supprimez les duplications. Vous avez transformé plusieurs copies fragiles en un seul endroit à améliorer — et un seul endroit à réécrire plus tard si besoin.
La lisibilité et la cohérence peuvent l’emporter sur l’optimisation artisanale
Le code généré par l’IA brille souvent quand on lui demande d’optimiser pour la clarté plutôt que l’originalité. Avec les bons prompts et règles de linting, il choisira habituellement des flux de contrôle familiers, des noms conventionnels et des modules « ennuyeux » plutôt que des nouveautés. Cela peut être un meilleur gain à long terme que quelques pourcents de performance gagnés par des astuces manuelles.
Pourquoi le code lisible est plus facile à réécrire
Les réécritures réussissent quand des personnes nouvelles peuvent rapidement se faire une représentation mentale correcte du système. Du code lisible et cohérent réduit le temps pour répondre à des questions basiques comme « où entre la requête ? » ou « quelle forme a cette donnée ici ? ». Si chaque service suit des patterns similaires (layout, gestion d’erreurs, logs, configuration), une nouvelle équipe peut remplacer une tranche à la fois sans sans cesse réapprendre des conventions locales.
La cohérence réduit aussi la peur. Quand le code est prévisible, les ingénieurs peuvent supprimer et reconstruire des parties en confiance parce que la surface d’impact est plus facile à comprendre et le « rayon d’explosion » paraît plus petit.
Le code fortement optimisé et artisanal peut être difficile à réécrire parce que les techniques de performance s’infiltrent partout : caches personnalisés, micro‑optimisations, patterns de concurrence maison ou couplage serré à des structures de données spécifiques. Ces choix peuvent être valides, mais ils créent souvent des contraintes subtiles qui n’apparaissent qu’au moment où quelque chose casse.
La lisibilité n’autorise pas la lenteur. L’idée est de gagner la performance sur preuve. Avant une réécriture, capturez des métriques de référence (percentiles de latence, CPU, mémoire, coût). Après remplacement d’un composant, mesurez à nouveau. Si la perf régresse, optimisez le hot path ciblé — sans transformer la base de code en puzzle.
Régénérer vs refactorer vs réécrire : choisir le bon reset
Quand une base de code assistée par IA commence à sembler « off », vous n’avez pas automatiquement besoin d’une réécriture complète. Le meilleur reset dépend de ce qui est faux versus simplement sale.
Trois options de reset
Régénérer signifie recréer une partie du code à partir d’une spec ou d’un prompt — souvent à partir d’un template ou d’un pattern connu — puis réappliquer les points d’intégration (routes, contrats, tests). Ce n’est pas « tout supprimer », c’est « reconstruire cette tranche à partir d’une description plus claire ».
Refactorer conserve le comportement mais change la structure interne : renommer, scinder des modules, simplifier des conditionnels, supprimer des duplications, améliorer les tests.
Réécrire remplace un composant ou un système par une nouvelle implémentation, généralement parce que le design actuel ne peut pas être assaini sans changer le comportement, les frontières ou les flux de données.
Quand la régénération est un bon choix
La régénération est idéale quand le code est surtout du boilerplate et que la valeur réside dans les interfaces plutôt que des internals ingénieux :
- Écrans CRUD et panneaux d’administration
- Adaptateurs d’API et couches d’intégration minces
- Scaffolding : routing, serializers, DTOs, validation simple, gestion d’erreurs commune
Si la spec est claire et la frontière du module propre, régénérer est souvent plus rapide qu’essayer de démêler des modifications incrémentales.
Quand la régénération est risquée (ou échoue)
Soyez prudent quand le code encode un savoir‑faire métier difficile ou des contraintes de correction subtiles :
- Règles métier riches en cas limites
- Concurrence délicate (queues, verrous, retries, idempotence)
- Logique de conformité (audit, rétention, vie privée)
Dans ces domaines, le « assez proche » peut coûter cher — la régénération peut aider, mais seulement si vous pouvez prouver l’équivalence avec des tests solides et des revues.
Portes de revue et déploiements progressifs
Traitez le code régénéré comme une nouvelle dépendance : exigez une revue humaine, lancez toute la suite de tests, et ajoutez des tests ciblés pour les échecs connus. Déployez par tranches — un endpoint, un écran, un adaptateur — derrière un feature flag ou via un rollout progressif si possible.
Un default utile : régénérer la coquille, refactorer les coutures, réécrire seulement les parties où les hypothèses cassent.
Risques et garde‑fous pour un code « remplaçable par conception »
Lancer un pilote de module remplaçable
Créez une fonctionnalité remplaçable dans Koder.ai et voyez à quelle vitesse vous pouvez la remplacer en toute sécurité.
« Facile à remplacer » reste un avantage seulement si les équipes traitent le remplacement comme une activité d’ingénierie, pas comme un bouton de réinitialisation. Les modules générés par l’IA se remplacent plus vite — mais ils peuvent aussi tomber en panne plus vite si on leur fait trop confiance sans vérification.
Risques clés à surveiller
Le code généré par l’IA a souvent l’air complet même quand il ne l’est pas. Cela peut créer une fausse confiance, surtout si les démos happy‑path passent.
Un second risque est celui des cas limites manquants : entrées inhabituelles, timeouts, problèmes de concurrence et gestion d’erreurs non couverte par le prompt ou les données d’exemple.
Enfin, il y a l’incertitude licence/IP. Même si le risque est faible dans de nombreux contextes, les équipes devraient avoir une politique sur les sources/outils acceptables et sur la manière de tracer la provenance.
Garde‑fous qui maintiennent les réécritures sûres
Placez le remplacement derrière les mêmes portes que n’importe quel autre changement :
- Revue de code avec un prisme « code généré » : clarté, modes d’échec, validation d’entrée et logging
- Contrôles de sécurité (SAST, scan de dépendances, détection de secrets) et règle qui empêche le code généré de les contourner
- Politiques de dépendances : privilégier peu de librairies connues ; pinner les versions ; éviter d’introduire un nouveau framework juste parce qu’un prompt le suggère
- Traces d’audit : conserver prompts, versions d’outil/modèle et notes de génération dans le repo pour que les changements soient explicables plus tard
Documenter les frontières avant de remplacer des modules
Avant de remplacer un composant, écrivez son périmètre et ses invariants : quelles entrées il accepte, ce qu’il garantit, ce qu’il ne doit jamais faire (par ex. « ne jamais supprimer de données client »), et les attentes perf/latence. Ce « contrat » est ce contre quoi vous testez — quelle que soit la source du code.
Une checklist légère
- Définir le contrat du module (entrées/sorties, invariants).
- Ajouter/confirmer les tests pour les cas limites.
- Lancer scans de sécurité + dépendances.
- Revoir lisibilité et gestion des échecs.
- Enregistrer les métadonnées du prompt/outillage.
- Déployer derrière un flag et surveiller.
Conclusions pratiques et plan d’action simple
Le code généré par l’IA est souvent plus facile à réécrire parce qu’il tend à suivre des patterns familiers, évite la personnalisation profonde et se régénère plus rapidement quand les besoins changent. Cette prévisibilité réduit le coût social et technique de supprimer et remplacer des parties du système.
L’objectif n’est pas « jeter du code », mais rendre le remplacement normal et peu coûteux — soutenu par des contrats et des tests.
Actions à implémenter cette semaine
Commencez par standardiser les conventions pour que tout code régénéré ou réécrit s’intègre au même moule :
- Verrouiller les conventions : formatage, structure de dossiers, nommage, gestion d’erreurs et forme des APIs. Écrivez‑les dans un court CONTRIBUTING.md.
- Ajouter des tests de contrat aux frontières : concentrez‑vous sur les entrées/sorties des modules et services (endpoints HTTP, messages de queue, couches d’accès DB). Ces tests doivent passer quelle que soit l’implémentation.
- Tracer prompts et specs : stockez prompts, notes de requirements et traces de génération avec le code pour que les réécritures futures reproduisent l’intention, pas seulement le texte.
Si vous utilisez un flux de travail vibe‑coding, cherchez des outils qui facilitent ces pratiques : sauvegarde des specs « mode planification » dans le repo, capture des traces de génération et rollback sécurisé. Par exemple, Koder.ai est conçu autour d’une génération pilotée par chat avec snapshots et rollback, ce qui convient bien à une approche « remplaçable par conception » — régénérez une tranche, gardez le contrat stable et revenez en arrière rapidement si les tests de parité échouent.
Lancer un petit pilote « module remplaçable »
Choisissez un module important mais isolé — génération de rapports, envoi de notifications ou une seule zone CRUD. Définissez son interface publique, ajoutez des tests de contrat, puis laissez‑vous régénérer/refactorer/réécrire les internals jusqu’à ce que cela devienne routinier. Mesurez le temps de cycle, le taux de défauts et l’effort de revue ; utilisez les résultats pour définir des règles d’équipe.
Pour opérationnaliser, conservez une checklist dans votre playbook interne (ou partagez‑la via /blog) et faites du trio « contrats + conventions + traces » une exigence pour le nouveau travail. Si vous évaluez des outils, documentez aussi ce dont vous auriez besoin d’un outil avant d’examiner /pricing.