Pourquoi Docker est si utile pour les déploiements cloud
La plupart des problèmes de déploiement dans le cloud commencent par une surprise familière : l'app fonctionne sur un portable, puis échoue une fois sur un serveur cloud. Peut‑être que le serveur a une version différente de Python ou Node, une bibliothèque système manquante, un fichier de configuration légèrement différent, ou un service d'arrière‑plan qui n'est pas lancé. Ces petites différences s'accumulent, et les équipes finissent par déboguer l'environnement au lieu d'améliorer le produit.
Docker, expliqué simplement
Docker aide en empaquetant votre application avec le runtime et les dépendances dont elle a besoin pour s'exécuter. Plutôt que d'envoyer une liste d'étapes comme « installez la version X, puis ajoutez la bibliothèque Y, puis configurez ceci », vous envoyez une image de conteneur qui inclut déjà ces éléments.
Un modèle mental utile est :
- Image = l'application empaquetée (un instantané contenant tout ce qu'il faut pour fonctionner)
- Conteneur = une instance en cours d'exécution de cette image
Quand vous exécutez la même image dans le cloud que celle que vous avez testée localement, vous réduisez radicalement les problèmes du type « mais mon serveur est différent ».
Qui en bénéficie (indice : ce n'est pas que les développeurs)
Docker aide différents rôles pour des raisons différentes :
- Développeurs obtiennent un environnement prévisible et une intégration plus rapide (« exécutez ce conteneur » vaut mieux que des docs d'installation longues).
- Ops et équipes plateforme gagnent des déploiements plus cohérents et des limites claires entre applications et serveurs.
- Petites équipes obtiennent une voie reproductible vers la production sans inventer des scripts de déploiement sur mesure pour chaque projet.
- Grandes entreprises bénéficient de la standardisation : un même format de packaging pour de nombreuses équipes et services.
Une attente réaliste
Docker est extrêmement utile, mais ce n'est pas l'unique outil dont vous aurez besoin. Il faut toujours gérer la configuration, les secrets, le stockage des données, le réseau, la supervision et la mise à l'échelle. Pour beaucoup d'équipes, Docker est un bloc de construction qui fonctionne aux côtés d'outils comme Docker Compose pour les workflows locaux et des plateformes d'orchestration en production.
Pensez à Docker comme au conteneur maritime de votre application : il rend la livraison prévisible. Ce qui se passe au port (la configuration et le runtime cloud) compte toujours — mais c'est beaucoup plus simple quand chaque envoi est emballé de la même manière.
Notions de base : conteneurs, images et registres
Docker peut sembler rempli de nouveau vocabulaire, mais l'idée centrale est simple : empaqueter votre app pour qu'elle s'exécute de la même façon partout.
Conteneur vs machine virtuelle (VM)
Une machine virtuelle regroupe un système d'exploitation invité complet plus votre application. C'est flexible, mais plus lourd à exécuter et plus lent à démarrer.
Un conteneur regroupe votre application et ses dépendances, mais partage le noyau de l'OS hôte au lieu d'expédier un système complet. Grâce à cela, les conteneurs sont généralement plus légers, démarrent en quelques secondes et vous pouvez en exécuter bien plus sur le même serveur.
Termes clés que vous verrez partout
Image : un modèle en lecture seule pour votre application. Pensez-y comme un artefact empaqueté qui inclut votre code, le runtime, les bibliothèques système et les réglages par défaut.
Conteneur : une instance en cours d'exécution d'une image. Si une image est un plan, le conteneur est la maison où vous habitez actuellement.
Dockerfile : les instructions pas à pas que Docker utilise pour construire une image (installer des dépendances, copier des fichiers, définir la commande de démarrage).
Registre : un service de stockage et distribution pour les images. Vous "push" des images vers un registre et les "pull" depuis les serveurs plus tard (registres publics ou privés au sein de votre entreprise).
Pourquoi la standardisation compte
Une fois que votre application est définie comme une image construite à partir d'un Dockerfile, vous obtenez une unité standardisée de livraison. Cette standardisation rend les releases reproductibles : la même image que vous avez testée est celle que vous déployez.
Elle simplifie aussi les transferts entre équipes. Plutôt que « ça marche sur ma machine », vous pouvez pointer vers une version d'image précise dans un registre et dire : exécutez ce conteneur avec ces variables d'environnement sur ce port. C'est la base d'une cohérence entre dev et prod.
Cohérence du portable au cloud : le bénéfice central
La principale raison pour laquelle Docker compte dans les déploiements cloud est la cohérence. Plutôt que de dépendre de ce qui est installé sur un portable, un runner CI ou une VM cloud, vous définissez l'environnement une fois (dans un Dockerfile) et le réutilisez à travers les étapes.
Ce que « cohérent » signifie concrètement
En pratique, la cohérence se traduit par :
- Les mêmes versions de runtime en dev, test et production (par exemple, le même Node/Python/JVM et les mêmes paquets OS)
- Moins de dérive de dépendances (bibliothèques, paquets OS)
- Rollback plus simple en redéployant un tag d'image précédent
- Débogage plus clair car les environnements correspondent
Cette cohérence rapporte vite : un bug vu en production peut être reproduit localement en exécutant le même tag d'image. Un déploiement qui échoue à cause d'une bibliothèque manquante devient improbable, car cette bibliothèque manquerait aussi dans votre conteneur de test.
Pourquoi c'est différent de « juste installer la même chose »
Les équipes essaient souvent de standardiser avec des docs d'installation ou des scripts qui configurent les serveurs. Le problème est la dérive : les machines changent au fil du temps à mesure que des correctifs et mises à jour de paquets sont appliqués, et les différences s'accumulent.
Avec Docker, l'environnement est traité comme un artefact. Si vous devez le mettre à jour, vous reconstrisez une nouvelle image et la déployez — les changements deviennent explicites et révisables. Si la mise à jour pose problème, revenir en arrière consiste souvent à déployer le tag connu‑bon précédent.
Portabilité entre clouds et serveurs
L'autre grand avantage de Docker est la portabilité. Une image de conteneur transforme votre application en un artefact portable : construisez‑la une fois, puis exécutez‑la partout où un runtime de conteneur compatible existe.
La même image, des maisons différentes
Une image Docker embarque le code de l'app plus ses dépendances runtime (par exemple Node.js, paquets Python, bibliothèques système). Cela signifie qu'une image que vous exécutez sur votre portable peut aussi tourner sur :
- une VM sur AWS, Azure ou Google Cloud
- vos propres serveurs en datacenter
- des plateformes managées de conteneurs (services basés sur Kubernetes)
Cela réduit le verrouillage fournisseur au niveau du runtime applicatif. Vous pouvez toujours utiliser des services cloud natifs (bases, queues, stockage), mais votre application centrale n'a pas besoin d'être reconstruite parce que vous avez changé d'hôte.
Où les registres interviennent
La portabilité fonctionne mieux quand les images sont stockées et versionnées dans un registre — public ou privé. Un workflow typique :
- Construire une image une fois (ex.
myapp:1.4.2).
- La pousser dans un registre.
- Récupérer et exécuter cette image exacte dans chaque environnement.
Les registres facilitent aussi la reproduction et l'audit des déploiements : si la production tourne en 1.4.2, vous pouvez récupérer le même artefact plus tard et obtenir les mêmes bits.
Scénarios pratiques
Migration d'hôte : si vous passez d'un provider de VM à un autre, vous ne réinstallez pas la stack. Pointez le nouveau serveur vers le registre, pull l'image et démarrez le conteneur avec la même configuration.
Mise à l'échelle : besoin de plus de capacité ? Démarrez des conteneurs supplémentaires à partir de la même image sur d'autres serveurs. Comme chaque instance est identique, la montée en charge devient une opération reproductible plutôt qu'une série de tâches manuelles.
Construire des images petites, reproductibles et maintenables
Une bonne image Docker n'est pas juste « quelque chose qui s'exécute ». C'est un artefact empaqueté et versionné que vous pouvez reconstruire plus tard et toujours faire confiance. C'est ce qui rend les déploiements cloud prédictibles.
Le Dockerfile : votre recette de build
Un Dockerfile décrit comment assembler votre image app étape par étape — comme une recette avec des ingrédients et des instructions exacts. Chaque ligne crée une couche, et ensemble elles définissent :
- le point de départ (image de base)
- quelles dépendances installer
- comment copier votre code
- quelle commande démarre l'app
Garder ce fichier clair et intentionnel facilite le débogage, la revue et la maintenance de l'image.
Bonnes pratiques pour des images légères et reproductibles
Les petites images se téléchargent plus vite, démarrent plus rapidement et ont moins de « contenu » susceptible de casser ou de contenir des vulnérabilités.
- Choisissez une image de base légère (par exemple
alpine ou des variantes ―slim) quand c'est compatible avec votre app.
- Verrouillez les versions pour les images de base et les paquets clés. Les versions flottantes peuvent évoluer et produire des builds différents.
- Minimisez les couches et les fichiers : combinez les commandes liées et nettoyez les caches des paquets pour ne pas embarquer de résidus de build.
Builds multi‑étapes : construire lourd, déployer léger
Beaucoup d'apps ont besoin de compilateurs et d'outils de build mais pas pour l'exécution. Les builds multi‑étapes permettent d'utiliser une étape pour compiler et une seconde, minimale, pour la production.
# build stage
FROM node:20 AS build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
RUN npm run build
# runtime stage
FROM nginx:1.27-alpine
COPY --from=build /app/dist /usr/share/nginx/html
Le résultat est une image de production plus petite avec moins de dépendances à patcher.
Stratégie de tagging : rendre les déploiements traçables
Les tags permettent d'identifier précisément ce que vous déployez.
- Évitez de compter sur
latest en production ; c'est ambigu.
- Utilisez des versions sémantiques (ex.
1.4.2) pour les releases.
- Ajoutez un tag SHA de commit (ex.
1.4.2-<sha> ou simplement <sha>) pour toujours tracer une image jusqu'au code qui l'a produite.
Cela facilite les rollbacks propres et les audits lorsque quelque chose change dans le cloud.
Exécuter des apps réelles : réseau, config et données
Créez une application prête pour Docker
Depuis le chat, créez une application prête pour les conteneurs et évitez les dérives d'environnement dès le départ.
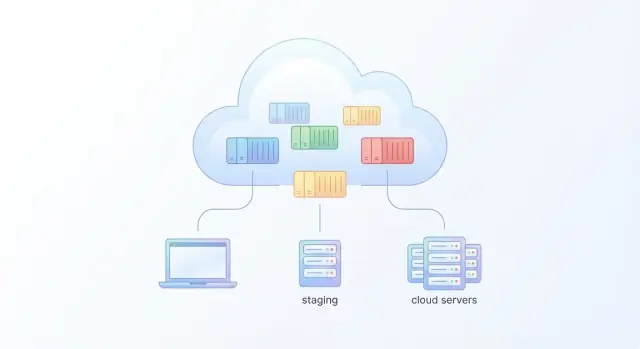
Une « vraie » application cloud n'est généralement pas un seul process. C'est un petit système : un frontend web, une API, peut‑être un worker en arrière‑plan, plus une base de données ou un cache. Docker supporte les configurations simples et multi‑services — il faut juste comprendre comment les conteneurs communiquent, où se situe la configuration et comment les données survivent aux redémarrages.
Applications mono‑conteneur vs multi‑service
Une app mono‑conteneur peut être un site statique ou une API unique qui ne dépend de rien d'autre. Vous exposez un port (par ex. 8080) et vous l'exécutez.
Les apps multi‑service sont plus courantes : web dépend de api, api dépend de db, et un worker consomme des jobs d'une queue. Plutôt que d'encoder des adresses IP, les conteneurs communiquent typiquement par nom de service sur un réseau partagé (par ex. db:5432).
Docker Compose pour le développement et le staging
Docker Compose est un choix pratique pour le développement local et le staging car il permet de démarrer tout le stack avec une seule commande. Il documente aussi la « forme » de votre app (services, ports, dépendances) dans un fichier que toute l'équipe peut partager.
Une progression typique :
- Compose en local (retour rapide)
- Compose sur une VM de staging (proche du comportement prod)
- Un runtime cloud/orchestrateur en production
Configuration : ce qui doit rester hors des images
Les images doivent être réutilisables et sûres à partager. Gardez en dehors de l'image :
- les secrets (clés d'API, mots de passe de BD)
- les URL qui diffèrent entre staging et prod
- les feature flags
Passez-les via des variables d'environnement, un fichier .env (attention : ne pas le committer) ou le gestionnaire de secrets de votre cloud.
Persister les données avec des volumes
Les conteneurs sont jetables ; vos données ne doivent pas l'être. Utilisez des volumes pour tout ce qui doit survivre à un redémarrage :
- bases de données (Postgres, MySQL)
- uploads utilisateur
- fichiers générés difficiles à recréer
Dans les déploiements cloud, l'équivalent est le stockage managé (DB managée, disques réseau, stockage d'objets). L'idée clé reste : les conteneurs exécutent l'app ; le stockage persistant garde l'état.
Workflows de déploiement : du build à l'exécution dans le cloud
Un workflow Docker sain est volontairement simple : construire une image une fois, puis exécuter cette même image partout. Plutôt que de copier des fichiers sur des serveurs ou de relancer des installateurs, vous transformez le déploiement en routine reproductible : pull de l'image, run du conteneur.
Le flux basique : build → push → run
La plupart des équipes suivent un pipeline comme :
- Construire une image versionnée (par ex.
myapp:1.8.3).
- La pousser dans un registre (Docker Hub, registre cloud ou privé).
- Déployer en récupérant cette image sur l'environnement cloud et en démarrant des conteneurs.
Cette dernière étape rend Docker « ennuyeux » dans le bon sens :
docker build -t registry.example.com/myapp:1.8.3 .
docker push registry.example.com/myapp:1.8.3
docker pull registry.example.com/myapp:1.8.3
docker run -d --name myapp -p 80:8080 registry.example.com/myapp:1.8.3
Schémas cloud courants
Deux manières courantes d'exécuter des apps Dockerisées dans le cloud :
- VM + Docker : vous gérez une machine virtuelle, installez Docker et exécutez les conteneurs vous‑même. C'est simple et adapté aux petites configurations.
- Services managés de conteneurs : le fournisseur cloud gère les hôtes conteneurs pour vous. Vous déployez la même image, mais la montée en charge, les redémarrages et le réseau sont plus automatisés.
Bases pour du zéro‑downtime
Pour réduire les interruptions lors des releases, les déploiements production ajoutent généralement trois éléments :
- Health checks pour confirmer qu'un conteneur est réellement prêt (pas seulement « démarré »).
- Rolling updates pour remplacer les conteneurs progressivement, pas tous à la fois.
- Load balancers pour acheminer le trafic uniquement vers les conteneurs sains et répartir la charge.
Un registre est plus que du stockage — c'est la manière de garder les environnements cohérents. Une pratique courante est de promouvoir la même image de dev → staging → prod (souvent par retag), plutôt que de reconstruire à chaque fois. Ainsi, la production exécute l'artefact exact déjà testé, ce qui réduit les surprises « ça marchait en staging ».
CI/CD avec Docker : des releases plus rapides et plus propres
Apprenez en construisant
Itérez sur les services, les configs et la configuration Docker via un flux de travail guidé par chat.
CI/CD (Intégration Continue et Livraison Continue) est essentiellement la chaîne de montage pour expédier du logiciel. Docker rend cette chaîne plus prévisible car chaque étape s'exécute dans un environnement connu.
Où Docker s'insère dans le pipeline
Un pipeline Docker‑friendly a généralement trois étapes :
- Build : créer une image Docker versionnée à partir de votre code (par ex.
myapp:1.8.3).
- Test : exécuter des tests automatisés dans des conteneurs pour que les outils et dépendances correspondent à ce qui tournera ensuite.
- Publish : pousser l'image dans un registre (privé ou public) pour que les autres environnements puissent récupérer le même artefact.
Cette approche se résume bien pour les non‑techniques : « on construit une boîte scellée, on teste la boîte, puis on envoie la même boîte à chaque environnement ».
Tester dans des conteneurs (pour éviter les surprises en prod)
Les tests réussissent souvent en local et échouent en production à cause de runtimes différents, de bibliothèques système manquantes ou de variables d'environnement différentes. Exécuter les tests dans un conteneur réduit ces écarts. Votre runner CI n'a pas besoin d'une machine finement configurée — juste Docker.
Docker encourage « promouvoir, ne pas reconstruire ». Plutôt que de reconstruire pour chaque environnement :
- Construire et tester
myapp:1.8.3 une fois.
- Déployer cette même image en dev.
- Si tout est correct, déployer la même image en staging.
- Enfin, déployer la même image en production.
Seule la configuration change entre environnements (URLs, identifiants), pas l'artefact applicatif. Cela réduit l'incertitude le jour de la release et rend les rollbacks simples : redéployer le tag d'image précédent.
Si vous avancez vite et voulez les bénéfices de Docker sans passer des jours sur la mise en place, Koder.ai peut vous aider à générer une application prête pour la production via un workflow piloté par chat, puis la containeriser proprement.
Par exemple, les équipes utilisent souvent Koder.ai pour :
- créer un frontend React et un backend Go avec PostgreSQL,
- ajouter un Dockerfile et un
docker-compose.yml tôt (pour aligner dev et prod),
- exporter le code source complet et le brancher dans un pipeline standard build → push → run,
- utiliser des snapshots et rollback pendant l'itération pour garder le contrôle des changements de déploiement.
L'avantage clé est que Docker reste la primitive de déploiement, tandis que Koder.ai accélère le passage de l'idée à une base de code prête pour les conteneurs.
Passer à l'échelle : Docker et orchestration
Docker facilite le packaging et l'exécution d'un service sur une machine. Mais quand vous avez plusieurs services, plusieurs copies de chaque service et plusieurs serveurs, il faut un système pour coordonner tout ça. L'orchestration est le logiciel qui décide où les conteneurs tournent, les garde sains et ajuste la capacité selon la demande.
Pourquoi l'orchestration est importante avec de nombreux conteneurs
Avec quelques conteneurs, on peut les démarrer et redémarrer manuellement. À grande échelle, cela devient rapidement ingérable :
- un serveur peut tomber et emporter plusieurs conteneurs avec lui ;
- il peut falloir 2, 10 ou 100 copies d'un service web selon le trafic ;
- les mises à jour doivent se faire sans mettre l'app hors ligne ;
- les services ont besoin d'un moyen cohérent pour se découvrir et partager la configuration.
Kubernetes, expliqué sans jargon lourd
Kubernetes (souvent « K8s ») est l'orchestrateur le plus courant. Un modèle mental simple :
- Nodes : les machines (VM ou serveurs) qui exécutent vos conteneurs.
- Pods : l'unité minimale que Kubernetes exécute (généralement un conteneur, parfois plusieurs liés).
- Deployments : « exécutez N copies de ce pod et assurez‑vous qu'il en reste toujours N », incluant les rolling updates.
- Services : réseau stable pour que d'autres parties de l'app atteignent ces pods de façon fiable.
Kubernetes n'a pas pour rôle de construire des conteneurs ; il les exécute. Vous construisez toujours une image Docker, la poussez dans un registre, puis Kubernetes la récupère sur les nodes et démarre des conteneurs à partir d'elle. Votre image reste l'artefact portable et versionné utilisé partout.
Quand une option plus simple suffit
Si vous êtes sur un seul serveur avec quelques services, Docker Compose peut largement suffire. L'orchestration devient intéressante quand vous avez besoin de haute disponibilité, de déploiements fréquents, d'auto‑scaling ou de plusieurs serveurs pour la capacité et la résilience.
Les conteneurs ne rendent pas une application automatiquement sécurisée — ils facilitent surtout la standardisation et l'automatisation des tâches de sécurité que vous devriez déjà faire. L'avantage est que Docker vous donne des points répétés et vérifiables où ajouter des contrôles utiles pour les auditeurs et les équipes sécurité.
Scannage d'images (et pourquoi c'est important)
Une image de conteneur est un bundle de votre app plus ses dépendances, donc les vulnérabilités proviennent souvent d'images de base ou de paquets système externes. Le scannage d'images vérifie la présence de CVE connues avant le déploiement.
Faites du scannage une étape bloquante dans votre pipeline : si une vulnérabilité critique est trouvée, échouez le build et reconstruisez avec une image de base patchée. Conservez les résultats de scan comme artefacts pour montrer ce que vous avez expédié lors des revues de conformité.
Principe du moindre privilège par défaut
Exécutez en tant qu'utilisateur non root quand c'est possible. Beaucoup d'attaques tirent parti d'un accès root dans le conteneur pour s'échapper ou altérer le système de fichiers.
Envisagez aussi un système de fichiers en lecture seule pour le conteneur et ne montez que les chemins en écriture nécessaires (logs, uploads). Cela limite ce qu'un attaquant peut modifier s'il parvient à pénétrer.
Gestion des secrets : ne pas intégrer les secrets dans les images
Ne copiez jamais de clés API, mots de passe ou certificats privés dans votre image Docker ou dans Git. Les images sont mises en cache, partagées et poussées vers des registres — les secrets peuvent se diffuser largement.
Injectez plutôt les secrets à l'exécution via le store de secrets de votre plateforme (Kubernetes Secrets, gestionnaire de secrets cloud), et restreignez l'accès uniquement aux services qui en ont besoin.
Mises à jour et patching : reconstruire régulièrement
Contrairement aux serveurs traditionnels, les conteneurs ne se patchent pas eux‑mêmes en cours d'exécution. L'approche standard : reconstruire l'image avec des dépendances mises à jour, puis redéployer.
Fixez une cadence (hebdomadaire ou mensuelle) pour reconstruire même si votre code n'a pas changé, et reconstruisez immédiatement lorsque des CVE de haute gravité affectent votre image de base. Cette habitude facilite les audits et réduit les risques dans le temps.
Publiez avec des instantanés
Enregistrez un instantané avant les déploiements pour pouvoir revenir en arrière en toute confiance.
Même les équipes qui « utilisent Docker » peuvent livrer des déploiements cloud peu fiables si quelques mauvaises habitudes s'installent. Voici les erreurs qui causent le plus de douleur — et des moyens pratiques de les éviter.
1) Traiter les conteneurs comme des animaux de compagnie (modifs manuelles en prod)
Un anti‑pattern fréquent est « SSHer sur le serveur et bidouiller quelque chose », ou faire un exec dans un conteneur en cours pour corriger une config à chaud. Ça marche une fois, puis ça casse parce que personne ne peut recréer l'état exact.
Traitez les conteneurs comme du bétail : jetables et remplaçables. Faites chaque changement via la chaîne de build et de déploiement. Pour déboguer, faites‑le dans un environnement temporaire puis codifiez le correctif dans le Dockerfile, la config ou l'infrastructure.
2) Images surdimensionnées et builds lents dus à un Dockerfile désordonné
Des images énormes ralentissent CI/CD, augmentent les coûts de stockage et élargissent la surface d'attaque.
Évitez‑le en soignant la structure du Dockerfile :
- utilisez une image de base plus petite quand raisonnable ;
- copiez d'abord les fichiers de dépendances (pour que le cache fonctionne), puis le code applicatif ;
- utilisez des builds multi‑étapes pour les apps compilées afin que l'image finale ne contienne que l'essentiel ;
- ajoutez un
.dockerignore pour ne pas embarquer node_modules, artefacts de build ou secrets locaux.
L'objectif est un build reproductible et rapide — même sur une machine propre.
3) Ignorer les logs et métriques (l'observabilité compte toujours)
Les conteneurs n'enlèvent pas le besoin de comprendre ce que fait votre app. Sans logs, métriques et traces, vous ne verrez les problèmes que quand les utilisateurs râlent.
Au minimum, faites en sorte que votre app écrive les logs vers stdout/stderr (plutôt que dans des fichiers locaux), ait des endpoints de santé basiques et émette quelques métriques clés (taux d'erreur, latence, profondeur des queues). Connectez ensuite ces signaux à la supervision de votre stack cloud.
4) Ne pas planifier tôt les services stateful (bases, queues, fichiers)
Les conteneurs sans état sont faciles à remplacer ; les données d'état ne le sont pas. Les équipes découvrent souvent trop tard qu'une base de données dans un conteneur « fonctionnait » jusqu'à ce qu'un redémarrage efface les données.
Décidez tôt où vit l'état :
- utilisez des bases/queues managées quand c'est possible ;
- si vous devez gérer vous‑même des services stateful, concevez le stockage, les backups et les mises à jour dès le jour 1.
Docker est excellent pour empaqueter des apps — mais la fiabilité vient de la délibération sur la façon dont ces conteneurs sont construits, observés et connectés au stockage persistant.
Checklist pratique pour démarrer
Si vous découvrez Docker, le moyen le plus rapide d'obtenir de la valeur est de containeriser un service réel de bout en bout : construire, exécuter localement, pousser vers un registre et déployer. Utilisez cette checklist pour rester focalisé et obtenir des résultats utilisables.
1) Commencez par un service (bout en bout)
Choisissez un service stateless simple (une API, un worker ou une petite app web). Définissez ce qu'il lui faut pour démarrer : le port d'écoute, les variables d'environnement requises et les dépendances externes (comme une DB que vous pouvez exécuter séparément).
Gardez l'objectif clair : « je peux exécuter la même app localement et dans le cloud à partir de la même image ».
2) Créez un Dockerfile minimal + un Compose pour l'usage local
Rédigez le Dockerfile le plus petit possible qui puisse construire et exécuter votre app de façon fiable. Préférez :
- une image de base légère
- ne copier que ce qui est nécessaire
- une commande de démarrage claire
Ajoutez ensuite un docker-compose.yml pour le développement local qui connecte variables d'environnement et dépendances (comme une DB) sans rien installer sur votre portable à part Docker.
Si vous voulez un setup local plus profond plus tard, vous pourrez l'étendre — commencez simple.
3) Choisissez un registre et une convention de tagging
Décidez où les images vivront (Docker Hub, GHCR, ECR, GCR, etc.). Adoptez des tags qui rendent les déploiements prévisibles :
:dev pour les tests locaux (optionnel):<git-sha> (immutables, mieux pour les déploiements):v1.2.3 pour les releases
Évitez :latest en production.
4) Ajoutez la CI pour builder + publier automatiquement
Configurez la CI pour que chaque merge sur la branche principale construise l'image et la pousse dans le registre. Votre pipeline devrait :
- build l'image
- exécuter une vérification basique (tests ou smoke run)
- push avec les tags convenus
Une fois cela en place, vous êtes prêt à relier l'image publiée à l'étape de déploiement cloud et à itérer à partir de là.