Ce qu'est (et n'est pas) une réplique de lecture
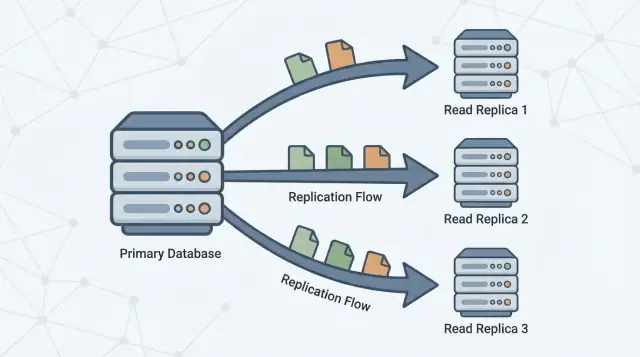
Une réplique de lecture est une copie de votre base de données principale (souvent appelée primaire) qui se met à jour en continu en recevant les changements venant de celle-ci. Votre application peut envoyer des requêtes en lecture seule (comme SELECT) vers la réplique, tandis que la primaire continue de traiter toutes les écritures (comme INSERT, UPDATE et DELETE).
La promesse de base
La promesse est simple : plus de capacité de lecture sans augmenter la pression sur la primaire.
Si votre appli a beaucoup de trafic de « lecture » — pages d'accueil, fiches produit, profils utilisateurs, tableaux de bord — déplacer une partie de ces lectures vers une ou plusieurs répliques peut dégager la primaire pour se concentrer sur les écritures et les lectures critiques. Dans de nombreux cas, cela se fait avec des changements minimes côté application : vous conservez une base comme source de vérité et ajoutez des réplicas comme endroits supplémentaires pour interroger les données.
Ce qu'une réplique de lecture n'est pas
Les réplicas sont utiles, mais ce n'est pas un bouton magique. Ils ne font pas :
- Augmenter la capacité d'écriture. Toutes les écritures arrivent toujours sur la primaire.
- Corriger des requêtes lentes. Si une requête est inefficace (index manquants, scan massif, mauvaises jointures), elle sera probablement lente sur les réplicas aussi — juste lente ailleurs.
- Remplacer une bonne conception de schéma ou de données. Les réplicas ne résolvent pas les points chauds, les lignes surdimensionnées ou une table « tout-en-un » qui a grandi sans contrôle.
- Supprimer le besoin de surveillance. Les réplicas ajoutent des éléments mobiles : décalage, limites de connexion et comportement de basculement.
À quoi vous attendre dans la suite du guide
Considérez les réplicas comme un outil de montée en charge des lectures avec des compromis. Le reste de cet article explique quand ils aident vraiment, les façons courantes dont ils peuvent échouer, et comment des concepts comme le décalage de réplication et la cohérence éventuelle affectent ce que voient les utilisateurs quand vous lisez depuis une copie au lieu de la primaire.
Pourquoi les réplicas de lecture existent
Un seul serveur de base de données primaire commence souvent par sembler « assez grand ». Il gère les écritures (inserts, updates, deletes) et répond aussi à toutes les requêtes de lecture (SELECT) provenant de votre appli, de vos tableaux de bord et des outils internes.
À mesure que l'utilisation croît, les lectures se multiplient généralement plus vite que les écritures : chaque vue de page peut déclencher plusieurs requêtes, les écrans de recherche canalisent de nombreuses recherches, et les requêtes analytiques peuvent scanner beaucoup de lignes. Même si le volume d'écriture est modéré, la primaire peut devenir un goulot d'étranglement parce qu'elle doit faire deux métiers à la fois : accepter les changements de façon sûre et rapide, et servir un trafic croissant de lectures avec une faible latence.
Séparer les lectures des écritures
Les réplicas de lecture existent pour séparer cette charge. La primaire reste concentrée sur le traitement des écritures et le maintien de la « source de vérité », tandis qu'une ou plusieurs répliques gèrent les requêtes en lecture seule. Quand votre application peut diriger certaines requêtes vers les réplicas, vous réduisez la pression CPU, mémoire et I/O sur la primaire. Cela améliore généralement la réactivité globale et laisse plus de marge pour les pics d'écriture.
La réplication en une phrase
La réplication est le mécanisme qui maintient les réplicas à jour en copiant les changements de la primaire vers d'autres serveurs. La primaire enregistre les changements, et les réplicas appliquent ces changements afin de pouvoir répondre aux requêtes avec des données quasiment identiques.
Ce schéma est courant dans de nombreux systèmes de bases de données et services managés (PostgreSQL, MySQL et variantes cloud). L'implémentation exacte diffère, mais l'objectif est le même : augmenter la capacité de lecture sans forcer la montée en puissance verticale de la primaire indéfiniment.
Pensez à une base primaire comme la « source de vérité ». Elle accepte chaque écriture — création de commandes, mise à jour de profils, enregistrement de paiements — et assigne un ordre définitif à ces changements.
Une ou plusieurs répliques de lecture suivent la primaire, copiant ces changements pour pouvoir répondre aux requêtes de lecture (comme « afficher mon historique de commandes ») sans mettre plus de charge sur la primaire.
Le flux de base
- La primaire accepte les écritures et les enregistre dans un journal durable (le nom exact varie selon la base).
- Les réplicas récupèrent ou streament ces entrées de log depuis la primaire.
- Les réplicas rejouent les mêmes changements dans le même ordre, en rattrapant progressivement leur retard.
Les lectures peuvent être servies depuis les réplicas, mais les écritures vont toujours à la primaire.
Réplication synchrone vs asynchrone (haut niveau)
La réplication peut se produire dans deux grands modes :
- Synchrone : la primaire attend qu'une réplique (ou un quorum) confirme la réception du changement avant que l'écriture ne soit considérée comme « commit ». Cela réduit les lectures obsolètes, mais peut augmenter la latence des écritures et les rendre sensibles aux problèmes réseau ou de réplique.
- Asynchrone : la primaire commit l'écriture immédiatement, et les réplicas rattrapent leur retard ensuite. Cela garde les écritures rapides et résilientes, mais les réplicas peuvent être temporairement en retard.
Décalage de réplication et « cohérence éventuelle »
Ce délai — le fait que les réplicas soient en retard sur la primaire — s'appelle le décalage de réplication. Ce n'est pas automatiquement une panne ; c'est souvent le compromis normal qu'on accepte pour monter en charge les lectures.
Pour les utilisateurs, le décalage se manifeste comme une cohérence éventuelle : après avoir modifié quelque chose, le système deviendra cohérent partout, mais pas forcément instantanément.
Exemple : vous mettez à jour votre adresse e-mail et rafraîchissez votre page de profil. Si la page est servie par une réplique qui a quelques secondes de retard, vous verrez peut‑être brièvement l'ancienne adresse — jusqu'à ce que la réplique applique la mise à jour et « rattrape » la primaire.
Quand les réplicas de lecture aident réellement
Les réplicas aident lorsque votre base primaire est saine pour les écritures mais saturée par les lectures. Ils sont particulièrement efficaces quand vous pouvez déléguer une part significative de la charge SELECT sans changer la manière dont vous écrivez les données.
Signes indiquant que vous êtes limité par les lectures (pas par les écritures)
Cherchez des schémas comme :
- CPU élevé sur la primaire lors des pics, alors que le débit d'écriture n'est pas inhabituel
- Très fort ratio de requêtes
SELECT comparé à INSERT/UPDATE/DELETE
- Requêtes de lecture qui ralentissent pendant les pics alors que les écritures restent stables
- Saturation des pools de connexions provoquée par des points de terminaison à forte lecture (pages produit, flux, résultats de recherche)
Avant d'ajouter des réplicas, validez avec quelques signaux concrets :
- CPU vs I/O : la CPU de la primaire est-elle saturée quand la latence des lectures augmente ? Ou le goulot est-il le I/O disque ?
- Mix des requêtes : pourcentage du temps passé sur les
SELECT (depuis votre slow query log/APM).
- Latence p95/p99 des lectures : suivez les endpoints de lecture et la latence des requêtes séparément.
- Taux de cache/Buffer hit : un faible taux peut indiquer que les lectures forcent l'accès disque.
- Top des requêtes par temps total : une requête coûteuse peut dominer la charge de lecture.
Ne négligez pas les correctifs moins coûteux
Souvent, la meilleure première action est la tuning : ajouter le bon index, réécrire une requête, réduire les appels N+1 ou mettre en cache des lectures chaudes. Ces modifications peuvent être plus rapides et moins coûteuses que d'opérer des réplicas.
Checklist rapide : réplicas vs tuning
Choisissez réplicas si :
- La majeure partie de la charge est en lecture et les lectures sont déjà raisonnablement optimisées
- Vous pouvez tolérer des lectures occasionnellement obsolètes pour les requêtes déléguées
- Vous avez besoin de capacité supplémentaire rapidement sans changements risqués de schéma/requêtes
Choisissez tuning en premier si :
- Quelques requêtes dominent le temps de lecture total
- Index manquants ou jointures inefficaces sont évidents
- Les lectures sont lentes même à faible trafic (signe de problèmes de conception de requêtes)
Cas d'utilisation les mieux adaptés
Les réplicas de lecture sont particulièrement utiles quand la primaire est occupée à gérer des écritures (paiements, inscriptions, mises à jour), mais qu'une large part du trafic est en lecture. Dans une architecture primaire–réplique, acheminer les bonnes requêtes vers les réplicas améliore les performances sans modifier les fonctionnalités applicatives.
1) Tableaux de bord et analyses qui ne doivent pas ralentir les transactions
Les tableaux de bord lancent souvent des requêtes longues : groupements, filtres sur de larges plages de dates, ou jointures multiples. Ces requêtes peuvent concurrencer les opérations transactionnelles pour la CPU, la mémoire et le cache.
Une réplique est un bon endroit pour :
- Les charges de reporting internes
- Les tableaux de bord d'administration
- Les vues « quotidiennes/hebdomadaires » de métriques
Vous gardez la primaire concentrée sur des transactions rapides et prévisibles pendant que les lectures analytiques montent en charge à part.
2) Pages de recherche et de navigation à fort volume de lecture
La navigation dans un catalogue, les profils utilisateurs et les flux de contenu peuvent générer un fort volume de requêtes similaires. Quand cette pression de lecture est le goulot, les réplicas peuvent absorber le trafic et réduire les pics de latence.
C'est particulièrement efficace si les lectures provoquent beaucoup de misses de cache (beaucoup de requêtes uniques) ou si vous ne pouvez pas vous reposer uniquement sur un cache applicatif.
3) Jobs en arrière-plan qui scannent beaucoup de données
Exports, backfills, recomputations et jobs du type « trouver tous les enregistrements qui correspondent à X » peuvent malmener la primaire. Exécuter ces scans contre une réplique est souvent plus sûr.
Assurez-vous juste que le job tolère la cohérence éventuelle : avec le décalage, il peut ne pas voir les mises à jour les plus récentes.
4) Lectures multi-régions pour réduire la latence (avec réserve sur la staleness)
Si vous servez des utilisateurs à l'international, placer des réplicas plus proches d'eux peut réduire le temps de trajet réseau. Le compromis est une exposition accrue aux lectures obsolètes lors de la latence ou d'incidents réseau, donc c'est adapté aux pages où « presque à jour » est acceptable (navigation, recommandations, contenu public).
Où les réplicas peuvent se retourner contre vous
Déployer et itérer rapidement
Lancez votre application avec hébergement et déploiement, puis itérez au fur et à mesure que le trafic augmente.
Les réplicas fonctionnent bien quand « assez proche » est suffisant. Ils posent problème quand votre produit suppose silencieusement que chaque lecture reflète la dernière écriture.
Le symptôme classique : « Je viens de modifier, pourquoi ça n'a pas changé ? »
Un utilisateur édite son profil, soumet un formulaire ou change des paramètres — et le chargement suivant est servi par une réplique qui a quelques secondes de retard. L'opération a réussi, mais l'utilisateur voit des données anciennes, réessaie, double‑soumet ou perd confiance.
C'est particulièrement gênant dans les flux où l'utilisateur attend une confirmation immédiate : changement d'email, modification de préférences, upload de document ou publication de commentaire avec redirection.
Écrans « doivent être à jour » (à ne pas jouer avec)
Certaines lectures ne tolèrent pas d'être obsolètes, même brièvement :
- Paniers et totaux de commande
- Soldes de portefeuille, points de fidélité, comptes de stock
- Écrans « Mon paiement est-il passé ? »
Si une réplique est en retard, vous pouvez afficher un mauvais total, sur-vendre du stock ou montrer un solde périmé. Même si le système se corrige ensuite, l'expérience utilisateur (et le volume support) en pâtit.
Outils d'administration et opérations ont besoin de la vérité la plus fraîche
Les tableaux de bord internes pilotent souvent des décisions : fraude, support client, fulfilment, modération, réponse incident. Si un outil admin lit depuis une réplique, vous risquez d'agir sur des données incomplètes — par ex. rembourser une commande déjà remboursée ou manquer un changement de statut récent.
Correctif pratique : router les lectures « read-your-writes » vers la primaire
Un pattern courant est le routage conditionnel :
- Après qu'un utilisateur écrit, envoyez ses lectures de confirmation vers la primaire pendant une courte période (secondes à minutes).
- Gardez les lectures de fond, anonymes ou non critiques sur les réplicas.
Cela préserve les bénéfices des réplicas sans transformer la cohérence en jeu de hasard.
Comprendre le décalage de réplication et les lectures obsolètes
Le décalage de réplication est le délai entre le commit d'une écriture sur la primaire et le moment où ce changement devient visible sur une réplique. Si votre appli lit depuis une réplique pendant ce délai, elle peut retourner des résultats « obsolètes » — des données vraies il y a un instant, mais plus maintenant.
Pourquoi le décalage arrive
Le décalage est normal et augmente souvent sous stress. Causes courantes :
- Pics de charge sur la primaire : beaucoup d'écritures signifie plus de changements à transférer et appliquer.
- Réplique sous-dimensionnée ou occupée : la réplique n'arrive pas à appliquer les changements aussi vite qu'ils arrivent (CPU, I/O disque).
- Latence/réseau instable : délais dans le flux de réplication.
- Transactions volumineuses / mises à jour en masse : un gros changement peut prendre du temps à sérialiser, transférer et rejouer.
Le décalage n'affecte pas seulement la « fraîcheur » : il impacte la justesse perçue par l'utilisateur :
- Un utilisateur met à jour son profil, puis rafraîchit et voit l'ancienne valeur.
- Les badges « messages non lus » ou les compteurs dérivent parce que les totaux sont calculés depuis des lignes légèrement anciennes.
- Les écrans d'admin/reporting manquent les dernières commandes, remboursements ou changements d'état.
Manières pratiques de gérer ça
Commencez par décider ce que votre fonctionnalité peut tolérer :
- Fenêtre de tolérance : « Les données peuvent dater de 30 secondes » convient pour beaucoup de tableaux de bord.
- Routage read-after-write vers la primaire : après une écriture utilisateur, lisez cette entité depuis la primaire pour une courte période.
- Messages UI : gérer les attentes (« Mise à jour… », « Peut prendre quelques secondes »).
- Logique de retry : si une lecture critique ne trouve pas un enregistrement fraîchement écrit, retentez sur la primaire ou après un court délai.
Que surveiller et alerter
Suivez le décalage des réplicas (temps/octets derrière), le taux d'application, les erreurs de réplication et l'utilisation CPU/disque. Alertez quand le décalage dépasse votre tolérance (par ex. 5s, 30s, 2m) et quand il continue d'augmenter dans le temps (signe que la réplique ne rattrapera pas sans intervention).
Montée en charge des lectures vs des écritures (compromis clés)
Commencez avec Go et Postgres
Générez un backend Go + PostgreSQL et commencez tôt à définir les parcours lecture/écriture.
Les réplicas de lecture sont un outil pour la montée en charge des lectures : ajouter des endroits pour servir des SELECT. Ils ne sont pas un outil pour la montée en charge des écritures : augmenter le nombre d'INSERT/UPDATE/DELETE que le système peut accepter.
Monter les lectures : ce pour quoi les réplicas sont bons
Quand vous ajoutez des réplicas, vous ajoutez de la capacité de lecture. Si votre appli est limitée par des endpoints à forte lecture (pages produit, flux, lookups), vous pouvez répartir ces requêtes sur plusieurs machines.
Cela améliore souvent :
- Latence des requêtes sous charge (moins de contention sur la primaire)
- Débit pour les lectures (plus de CPU/mémoire/I/O disponible pour les
SELECT)
- Isolation des lectures lourdes, comme le reporting, pour qu'elles n'interfèrent pas avec le trafic transactionnel
Monter les écritures : ce que les réplicas ne font pas
Une idée reçue est que « plus de réplicas = plus de débit d'écriture ». Dans un setup primaire–réplique classique, toutes les écritures vont toujours à la primaire. D'ailleurs, plus de réplicas peuvent légèrement augmenter le travail de la primaire, puisque celle-ci doit générer et expédier les données de réplication à chaque réplique.
Si votre douleur est le débit d'écriture, les réplicas n'aideront pas. Vous regardez généralement d'autres approches (tuning des requêtes/index, batch, partitionnement/sharding ou changement de modèle de données).
Limites de connexion et pooling : le goulot caché
Même si les réplicas vous apportent plus de CPU pour les lectures, vous pouvez toujours toucher les limites de connexions en premier. Chaque nœud a un nombre maximum de connexions concurrentes, et ajouter des réplicas peut multiplier les endroits où votre appli peut se connecter — sans réduire la demande totale.
Règle pratique : utilisez un pool de connexions (ou un pooler) et gardez vos nombres de connexions par service intentionnels. Sinon, les réplicas deviennent « plus de bases à surcharger ».
Coût : la capacité n'est pas gratuite
Les réplicas ajoutent des coûts réels :
- Plus de nœuds (coût compute)
- Plus de stockage (chaque réplique stocke typiquement une copie complète)
- Plus d'effort opérationnel (surveillance du décalage, stratégie de sauvegarde/restauration, changements de schéma, réponse aux incidents)
Le compromis est simple : les réplicas vous achètent de la marge pour les lectures et de l'isolation, mais ajoutent de la complexité et ne déplacent pas le plafond d'écriture.
Haute disponibilité et basculement : ce que les réplicas peuvent faire
Les réplicas peuvent améliorer la disponibilité en lecture : si votre primaire est surchargée ou indisponible, vous pouvez encore servir du trafic en lecture depuis des réplicas. Cela peut garder des pages orientées client réactives (pour du contenu tolérant une légère obsolescence) et réduire l'impact d'un incident sur la primaire.
Ce que les réplicas ne fournissent pas à eux seuls, c'est un plan complet de haute disponibilité. Une réplique n'est généralement pas prête à accepter des écritures automatiquement, et « une copie lisible existe » n'est pas la même chose que « le système peut accepter à nouveau des écritures en toute sécurité et rapidement ».
Le basculement signifie typiquement : détecter la panne de la primaire → choisir une réplique → la promouvoir en nouvelle primaire → rediriger les écritures (et souvent les lectures) vers le nœud promu.
Certains services managés automatisent cela, mais l'idée de base reste : vous changez qui est autorisé à accepter des écritures.
Risques clés à planifier
- Données obsolètes sur la réplique : la réplique peut être en retard. Si vous la promouvez, vous risquez de perdre les écritures les plus récentes qui n'ont pas été répliquées.
- Éviter le split-brain : il faut empêcher deux nœuds d'accepter des écritures en même temps. C'est pourquoi les promotions sont généralement contrôlées par une seule autorité (plan de contrôle managé, quorum ou procédures opérationnelles strictes).
- Routage et caches : votre appli doit pouvoir basculer de manière fiable — chaînes de connexion, DNS, proxies ou routeur DB. Assurez-vous que le trafic d'écriture ne continue pas d'aller vers l'ancienne primaire.
Testez-le comme une fonctionnalité
Considérez le basculement comme quelque chose à pratiquer. Faites des tests game‑day en staging (et prudemment en production) : simulez la perte de la primaire, mesurez le temps de récupération, vérifiez le routage et confirmez que votre appli gère les périodes en lecture seule et les reconnexions proprement.
Schémas pratiques de routage (séparation lecture/écriture)
Les réplicas n'aident que si votre trafic y parvient réellement. Le « read/write splitting » est l'ensemble des règles qui envoient les écritures à la primaire et les lectures éligibles aux réplicas — sans casser la cohérence.
Schéma 1 : séparation dans l'application
L'approche la plus simple est le routage explicite dans votre couche d'accès aux données :
- Toutes les écritures (
INSERT/UPDATE/DELETE, changements de schéma) vont à la primaire.
- Seules certaines lectures sélectionnées peuvent utiliser une réplique.
C'est facile à raisonner et à revenir en arrière. C'est aussi l'endroit où vous encodez des règles métier comme « après le checkout, toujours lire le statut de la commande depuis la primaire pendant un moment ».
Schéma 2 : séparation via un proxy ou un driver
Certaines équipes préfèrent un proxy de base de données ou un driver intelligent qui comprend les endpoints primaire vs réplique et route selon le type de requête ou les settings de connexion. Cela réduit les changements applicatifs, mais attention : les proxies ne peuvent pas savoir de façon fiable quelles lectures sont « sûres » du point de vue produit.
Choisir quelles requêtes envoyer aux réplicas
Bons candidats :
- Analytique, reporting, charges de tableaux de bord
- Pages de recherche/navigation où une légère obsolescence est acceptable
- Jobs en arrière-plan qui retentent et n'ont pas besoin de la dernière valeur
Évitez d'envoyer aux réplicas les lectures qui suivent immédiatement une écriture utilisateur (p.ex. « mise à jour profil → recharger profil ») sauf si vous avez une stratégie de cohérence.
Transactions et cohérence de session
Dans une transaction, gardez toutes les lectures sur la primaire.
Hors transaction, considérez des sessions « read-your-writes » : après une écriture, épinglez cet utilisateur/session sur la primaire pour un TTL court, ou routez des requêtes de suivi spécifiques vers la primaire.
Commencez petit et mesurez
Ajoutez une réplique, routez un ensemble limité d'endpoints/requêtes et comparez avant/après :
- CPU primaire et IOPS de lecture
- Utilisation des réplicas
- Taux d'erreur et percentiles de latence
- Incidents liés aux lectures obsolètes
Étendez le routage seulement quand l'impact est clair et sûr.
Surveillance et opérations de base
Anticipez la latence dès le départ
Modélisez dès maintenant les comportements de cohérence éventuelle pour éviter que les utilisateurs rencontrent des messages du type 'je viens de le mettre à jour' plus tard.
Les réplicas ne sont pas « configurés et oubliés ». Ce sont des serveurs de base de données supplémentaires avec leurs propres limites de performance, modes de panne et tâches opérationnelles. Un peu de discipline de surveillance fait souvent la différence entre « les réplicas ont aidé » et « les réplicas ont ajouté de la confusion ».
Ce qu'il faut surveiller (les quelques métriques importantes)
Concentrez-vous sur des indicateurs qui expliquent les symptômes visibles par les utilisateurs :
- Décalage de réplication : combien la réplique est-elle en retard sur la primaire (secondes, octets ou position WAL/LSN selon la DB) ? C'est votre alerte précoce pour les lectures obsolètes.
- Erreurs de réplication : connexions rompues, échecs d'auth, disque plein, problèmes de slot. Traitez-les comme des incidents.
- Latence des requêtes (p50/p95) sur réplique vs primaire : les réplicas peuvent être lents même si la primaire va bien (état du cache différent, matériel différent, rapports longs).
- Taux de cache : une réplique qui manque constamment le cache montrera une latence plus élevée après redémarrage ou basculement de trafic.
Planification de capacité : combien de réplicas ?
Commencez par une réplique si votre objectif est d'alléger les lectures. Ajoutez-en quand vous avez une contrainte claire :
- Débit de lecture : une réplique ne suffira pas si le QPS de pointe ou les requêtes analytiques sont trop volumineux.
- Isolation : dédier une réplique au reporting pour éviter que les tableaux de bord ne volent des ressources au trafic utilisateur.
- Géographie : une réplique par région peut réduire la latence de lecture, mais augmente l'overhead opérationnel.
Règle pratique : ne scalez les réplicas qu'après avoir confirmé que les lectures sont le goulot (et non les index, requêtes lentes ou cache applicatif).
Tâches opérationnelles courantes
- Sauvegardes : décidez où les sauvegardes s'exécutent. Les prendre depuis une réplique peut réduire la charge sur la primaire, mais vérifiez les exigences de cohérence et que la réplique est saine.
- Changements de schéma : testez les migrations en tenant compte de la réplication (les DDL longue durée peuvent augmenter le décalage). Coordonnez les déploiements pour que l'appli et le schéma restent compatibles pendant la propagation.
- Fenêtres de maintenance : patcher ou redémarrer des réplicas réduit temporairement la capacité de lecture. Planifiez une rotation pour ne pas tomber sous le seuil requis.
Checklist dépannage : « les réplicas sont lents »
- Vérifiez le décalage de réplication : s'il est élevé, les utilisateurs peuvent retenter ou voir des données obsolètes.
- Comparez les logs de requêtes lentes réplique vs primaire : les requêtes de reporting apparaissent souvent là.
- Vérifiez CPU, mémoire, I/O disque et réseau sur l'hôte réplique.
- Cherchez contention de locks ou transactions longues sur la primaire qui retardent la réplication.
- Confirmez que votre routage de lecture n'écrase pas une seule réplique (load balancing inégal).
- Validez que les index existent sur les réplicas (ils doivent refléter la primaire) et que les statistiques sont à jour.
Alternatives et un cadre de décision simple
Les réplicas sont un outil parmi d'autres pour monter en charge les lectures, mais rarement le premier levier à actionner. Avant d'ajouter de la complexité opérationnelle, vérifiez si une solution plus simple atteint le même objectif.
Alternatives à essayer d'abord
Cache peut retirer des classes entières de lectures de votre base. Pour les pages majoritairement en lecture (détails produit, profils publics, configuration), un cache applicatif ou un CDN peut réduire drastiquement la charge — sans introduire de décalage de réplication.
Indexation et optimisation des requêtes battent souvent les réplicas pour le cas courant : quelques requêtes coûteuses brûlant la CPU. Ajouter l'index adapté, réduire les colonnes sélectionnées, éviter les N+1 et corriger les jointures peut transformer un besoin de réplicas en « il nous fallait juste un meilleur plan ».
Vues matérialisées / pré-agrégation aident quand la charge est intrinsèquement lourde (analytique, tableaux de bord). Au lieu de relancer des requêtes complexes, stockez les résultats calculés et rafraîchissez-les selon un calendrier.
Quand considérer le sharding/partitionnement
Si vos écritures sont le goulot (lignes chaudes, contention de verrous, limites I/O d'écriture), les réplicas n'aideront pas beaucoup. C'est alors que le partitionnement des tables par temps/tenant, ou le sharding par ID client, peut répartir la charge d'écriture et réduire la contention. C'est une étape architecturale plus lourde, mais qui cible la vraie contrainte.
Cadre de décision simple
Posez-vous quatre questions :
- Quel est l'objectif ? Réduire la latence de lecture, délester le reporting, ou améliorer la disponibilité ?
- À quel point les lectures doivent-elles être fraîches ? Si vous ne pouvez pas tolérer d'obsolescence, les réplicas peuvent poser problème.
- Quel est votre budget ? Les réplicas ajoutent coût infra et opérations.
- Quelle complexité pouvez-vous absorber ? Séparation lecture/écriture, gestion de la cohérence éventuelle et tests de basculement sont non triviaux.
Si vous prototypez un produit ou lancez un service rapidement, intégrez ces contraintes dès le départ. Par exemple, les équipes qui construisent sur Koder.ai (une plateforme vibe-coding qui génère des apps React avec backends Go + PostgreSQL depuis une interface chat) commencent souvent avec une seule primaire pour la simplicité, puis ajoutent des réplicas dès que les tableaux de bord, les flux ou le reporting interne commencent à concurrencer le trafic transactionnel. Un workflow « planification d'abord » facilite la décision en amont : quels endpoints peuvent tolérer la cohérence éventuelle et lesquels doivent rester en « lecture après écriture » sur la primaire.
Si vous voulez de l'aide pour choisir une voie, consultez /pricing pour les options, ou parcourez les guides liés dans /blog.