14 mai 2025·8 min
Pourquoi les charges OLTP et OLAP n'ont généralement pas leur place dans une même base de données
Comprenez pourquoi mélanger les charges transactionnelles (OLTP) et analytiques (OLAP) dans une même base ralentit les applis, augmente les coûts et complexifie l'exploitation — et quelles architectures privilégier.
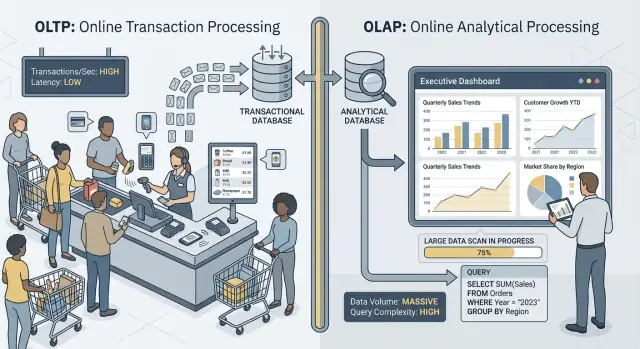
OLTP vs OLAP : ce que c'est (sans le jargon)
Quand on parle d’« OLTP » et d’« OLAP », on décrit deux usages très différents d’une base de données.
OLTP : la base qui fait tourner l’activité
OLTP (Online Transaction Processing) est la charge derrière les actions quotidiennes qui doivent être rapides et correctes à chaque fois. Pensez : « enregistrer ce changement tout de suite ».
Les tâches OLTP typiques incluent la création d’une commande, la mise à jour d’un stock, l’enregistrement d’un paiement ou la modification d’une adresse client. Ces opérations sont en général petites (quelques lignes), fréquentes, et doivent répondre en millisecondes parce qu’une personne ou un autre système attend.
OLAP : la base qui explique l’activité
OLAP (Online Analytical Processing) est la charge utilisée pour comprendre ce qui s’est passé et pourquoi. Pensez : « scanner beaucoup de données et les résumer ».
Les tâches OLAP typiques incluent les tableaux de bord, les rapports de tendance, l’analyse de cohortes, les prévisions et les questions « slice-and-dice » comme : « Comment le revenu a-t-il évolué par région et catégorie produit sur les 18 derniers mois ? » Ces requêtes lisent souvent beaucoup de lignes, effectuent des agrégations lourdes, et peuvent durer des secondes (voire des minutes) sans être « fausses ».
Même donnée, objectifs différents — et besoins différents
L’idée principale est simple : l’OLTP s’optimise pour des écritures rapides et consistantes et des lectures petites, tandis que l’OLAP s’optimise pour de larges lectures et des calculs complexes. Parce que les objectifs diffèrent, les meilleurs réglages de base, index, disposition du stockage et approche de montée en charge diffèrent souvent aussi.
Notez aussi le mot : rarement, pas jamais. Certaines petites équipes peuvent partager une seule base pendant un temps, surtout avec un volume modeste et une discipline de requêtes stricte. Les sections suivantes expliquent ce qui casse en premier, les motifs courants de séparation et comment déplacer le reporting hors de la production en toute sécurité.
Exemples rapides
- Checkout (OLTP) : un client clique sur « Payer », et votre appli écrit une commande, le statut du paiement et met à jour le stock.
- Tableau de bord (OLAP) : un manager ouvre un dashboard qui agrège des milliers (ou millions) de commandes pour montrer le taux de conversion, la valeur moyenne des commandes et les tendances hebdomadaires.
Objectifs différents, métriques de succès différentes
OLTP et OLAP « utilisent du SQL », mais ils sont optimisés pour des tâches distinctes — et cela se voit dans ce que chacun considère comme un succès.
OLTP : rapidité, concurrence et exactitude
Les systèmes OLTP (transactionnels) alimentent les opérations quotidiennes : parcours de paiement, mises à jour de compte, réservations, outils de support. Les priorités sont simples :
- Temps de réponse rapides pour de petites lectures/écritures (penser millisecondes)
- Beaucoup d’utilisateurs concurrents sans ralentissements
- Exactitude et cohérence, parce qu’un solde erroné ou une commande en double est un vrai problème métier
Le succès se mesure souvent par des métriques de latence comme p95/p99, le taux d’erreur et le comportement du système sous forte concurrence.
OLAP : scans, agrégations et flexibilité
Les systèmes OLAP répondent à des questions comme « Qu’est‑ce qui a changé ce trimestre ? » ou « Quel segment a churné après la nouvelle tarification ? ». Ces requêtes :
- Scannent de grandes quantités de données sur de nombreuses lignes
- Effectuent des agrégations (SUM, COUNT, percentiles) et des jointures
- Changent fréquemment au fur et à mesure que les analystes explorent et affinent leurs questions
Le succès ressemble plutôt à débit de requêtes, temps pour obtenir des insights et la capacité d’exécuter des requêtes complexes sans tuner chaque rapport à la main.
Pourquoi « un système pour tout » crée des compromis
Quand on force les deux charges dans une même base, on lui demande d’être excellente à la fois pour des transactions minuscules à fort volume et pour de grands scans exploratoires. Le résultat est souvent un compromis : l’OLTP obtient une latence imprévisible, l’OLAP se fait brider pour protéger la production, et les équipes se disputent sur les requêtes « autorisées ». Des objectifs séparés méritent des métriques de succès séparées — et généralement des systèmes séparés.
Contention des ressources : quand l’analytique vole aux transactions
Quand OLTP (les transactions de votre appli) et OLAP (reporting et analyse) tournent sur la même base, ils se disputent les mêmes ressources finies. Le résultat n’est pas juste un « reporting plus lent ». C’est souvent des checkouts plus lents, des connexions bloquées et des incidents applicatifs imprévisibles.
CPU et mémoire : longues requêtes vs courtes requêtes
Les requêtes analytiques sont souvent longues et lourdes : jointures sur de grosses tables, agrégations, tris et groupements. Elles peuvent monopoliser les cœurs CPU et, tout aussi important, la mémoire pour les hash joins et tampons de tri.
Pendant ce temps, les requêtes transactionnelles sont petites mais sensibles à la latence. Si le CPU est saturé ou que la pression mémoire force des évictions fréquentes, ces petites requêtes commencent à attendre derrière les grosses — même si chaque transaction n’a que quelques millisecondes de travail réel.
E/S disque : gros scans vs nombreuses petites lectures/écritures
L’analytique déclenche souvent des scans de table et lit beaucoup de pages de façon séquentielle. Les charges OLTP font l’inverse : beaucoup de petites lectures aléatoires plus des écritures constantes dans les index et les journaux.
En les mettant ensemble, le sous‑système de stockage doit jongler entre des patrons d’accès incompatibles. Les caches qui aidaient l’OLTP peuvent être « lavés » par les scans analytiques, et la latence d’écriture peut grimper quand le disque stream des données pour des rapports.
Pression sur le pool de connexions et mise en file
Quelques analystes lançant des requêtes larges peuvent occuper des connexions pendant des minutes. Si votre application utilise un pool de taille fixe, les requêtes se mettent en file en attendant une connexion libre. Cet effet de mise en file peut faire paraître un système sain cassé : la latence moyenne peut sembler acceptable, mais les latences aux extrêmes (p95/p99) deviennent douloureuses.
Ce que les utilisateurs remarquent réellement
De l’extérieur, cela se manifeste par des timeouts, des checkouts lents, des résultats de recherche retardés et un comportement globalement instable — souvent « seulement pendant le reporting » ou « seulement en fin de mois ». L’équipe applicative voit des erreurs ; l’équipe analytique voit des requêtes lentes ; le vrai problème est la contention partagée en dessous.
Disposition des données et besoins d’indexation tirent dans des directions opposées
OLTP et OLAP n’utilisent pas la base de la même façon — ils récompensent des conceptions physiques opposées. Quand vous essayez de satisfaire les deux dans un seul endroit, vous finissez par un compromis coûteux et souvent sous‑optimal.
OLTP : optimisé pour des recherches rapides et sélectives
La charge transactionnelle est dominée par des requêtes courtes qui touchent une petite tranche de données : récupérer une commande, mettre à jour une ligne de stock, lister les 20 derniers événements d’un utilisateur.
Cela pousse les schémas OLTP vers un stockage orienté ligne et des index qui supportent les recherches ponctuelles et les petits parcours (souvent sur clés primaires, clés étrangères et quelques index secondaires à haute valeur). L’objectif est une latence prévisible et faible — surtout pour les écritures.
OLAP : optimisé pour le scan, le groupement et la synthèse
La charge analytique doit souvent lire beaucoup de lignes mais peu de colonnes : « chiffre d’affaires par semaine et par région », « taux de conversion par campagne », « top produits par marge ».
Les systèmes OLAP tirent parti du stockage colonne (pour ne lire que les colonnes nécessaires), du partitionnement (pour éliminer rapidement les données anciennes ou non pertinentes) et des pré‑agrégations (vues matérialisées, rollups, tables de synthèse) pour que les rapports ne recomputent pas sans cesse les mêmes totaux.
Pourquoi « indexer pour tout » se retourne contre vous
Réagir en ajoutant des index jusqu’à ce que chaque dashboard soit rapide se casse la figure parce que chaque index supplémentaire augmente le coût des écritures. Cela accroît aussi le stockage et peut ralentir les tâches de maintenance comme le vacuum, le reindex et les sauvegardes.
Planners de requêtes et dérive des statistiques (en clair)
Les bases choisissent des plans en se basant sur des statistiques — estimations du nombre de lignes qui correspondent à un filtre, la sélectivité d’un index, et la distribution des données. L’OLTP change les données constamment. Quand les distributions bougent, les statistiques dérivent, et le planner peut choisir un plan qui marchait hier mais qui est lent aujourd’hui.
Ajoutez des requêtes OLAP lourdes qui scannent et joignent de grandes tables, et vous obtenez plus de variabilité : le « meilleur plan » devient plus difficile à prévoir, et tuner pour une charge dégrade souvent l’autre.
Verrous, MVCC et effets secondaires de maintenance
Même si votre base « supporte la concurrence », mélanger reporting lourd et transactions live crée des ralentissements subtils difficiles à prévoir — et encore plus difficiles à expliquer à un client devant un checkout qui tourne en rond.
Les longues requêtes causent toujours des problèmes de verrou
Les requêtes de type OLAP scannent souvent beaucoup de lignes, joignent plusieurs tables et tournent pendant des secondes ou des minutes. Pendant ce temps elles peuvent tenir des verrous (par exemple sur des objets de schéma, ou lorsqu’elles doivent trier/agréger dans des structures temporaires) et elles augmentent fréquemment la contention indirectement en gardant de nombreuses lignes « en jeu ».
Même avec MVCC (contrôle de concurrence multi‑version), la base doit suivre plusieurs versions d’une même ligne pour que lecteurs et rédacteurs ne se bloquent pas. Cela aide, mais n’élimine pas la contention — surtout lorsque les requêtes touchent des tables « chaudes » mises à jour constamment.
MVCC a un coût caché : le nettoyage devient plus difficile
MVCC signifie que les anciennes versions de lignes persistent jusqu’à ce que la base puisse les supprimer en toute sécurité. Un rapport longue durée peut garder un vieux snapshot ouvert, empêchant le nettoyage de récupérer l’espace.
Cela impacte :
- Vacuum / garbage collection : le nettoyage ne peut pas supprimer les tuples morts aussi vite.
- Bloat / fragmentation : le stockage croît, les index deviennent moins efficaces et les caches sont moins utiles.
- Pression de compaction : certains moteurs réagissent en effectuant plus de travail en arrière‑plan, qui vole des E/S et du CPU aux transactions.
Le résultat est un double effet : le reporting fait travailler la base davantage et rend le système plus lent au fil du temps.
Les niveaux d’isolation amplifient la variabilité de latence
Les outils de reporting demandent souvent une isolation plus forte (ou lancent accidentellement une longue transaction). Des isolations plus élevées peuvent augmenter l’attente sur les verrous et la quantité de versioning que le moteur doit gérer. Côté OLTP, on voit cela comme des pics imprévisibles : la plupart des commandes s’écrivent rapidement, puis quelques‑unes se bloquent soudainement.
Exemple concret : le reporting de fin de mois ralentit les commandes
En fin de mois, la finance lance une requête « chiffre d’affaires par produit » qui scanne commandes et lignes de facturation pour tout le mois. Pendant qu’elle tourne, de nouvelles écritures de commande sont encore acceptées, mais le vacuum ne peut pas récupérer les vieilles versions et les index s’épuisent. L’API de commande commence à voir des timeouts — pas parce qu’elle est en panne, mais parce que la contention et le coût de nettoyage poussent silencieusement la latence au‑dessus de vos limites.
Pics de charge et latence imprévisible
Gagnez des crédits pour votre article
Publiez sur votre projet et gagnez des crédits Koder.ai pour continuer à livrer.
Les systèmes OLTP vivent ou meurent par la prévisibilité. Un checkout ou une mise à jour n’est pas « globalement correct » s’il est rapide 95 % du temps — les utilisateurs remarquent les moments lents. L’OLAP, en revanche, est souvent par à coup : quelques requêtes lourdes peuvent rester silencieuses pendant des heures puis consommer beaucoup de CPU, mémoire et E/S.
Les pics arrivent pour des raisons commerciales normales
Le trafic analytique tend à se regrouper autour de routines :
- Dashboards du matin où beaucoup de monde rafraîchit les mêmes graphiques
- Rapports programmés qui démarrent pile à l’heure
- Clôtures de fin de mois et revues trimestrielles qui déclenchent de longs scans et jointures
Pendant ce temps, le trafic OLTP est généralement plus stable. Quand les deux partagent une base, ces pics analytiques se traduisent en latence imprévisible pour les transactions — timeouts, pages lentes et retentatives qui ajoutent encore de la charge.
Pourquoi les limitations et la planification aident — mais ne règlent pas le désaccord
Vous pouvez réduire les dégâts avec des tactiques comme exécuter les rapports la nuit, limiter la concurrence, appliquer des timeouts de statement ou des plafonds de coût de requête. Ce sont des garde‑fous utiles, surtout pour le « reporting sur production ».
Mais ils ne suppriment pas la tension fondamentale : les requêtes OLAP sont conçues pour utiliser beaucoup de ressources pour répondre à de grandes questions, tandis que l’OLTP a besoin de petites tranches de ressources rapides toute la journée. À la première rafraîchissement inattendu de tableau, requête ad hoc ou rapport backfill qui s’infiltre, la base partagée est à nouveau exposée.
Le problème du « voisin bruyant »
Sur une infrastructure partagée, un utilisateur analytique ou un job « bruyant » peut monopoliser le cache, saturer le disque ou mettre la pression sur l’ordonnancement CPU — sans rien faire de mal. La charge OLTP devient dégâts collatéraux, et la partie la plus difficile est que les défaillances ressemblent à des pics de latence aléatoires plutôt qu’à des erreurs reproductibles.
Complexité opérationnelle : sauvegarde, sécurité et planification de capacité
Mixer OLTP (transactions) et OLAP (analytique) complique non seulement les performances — cela rend aussi l’exploitation quotidienne plus dure. La base devient une « boîte à tout faire », et chaque tâche opérationnelle hérite des risques combinés des deux charges.
Sauvegardes, restaurations et reprise après sinistre ralentissent
Les tables analytiques tendent à grossir rapidement (plus d’historique, plus de colonnes, plus d’agrégats). Ce volume supplémentaire change votre récit de récupération.
Une sauvegarde complète prend plus de temps, consomme plus de stockage et accroît le risque de dépasser la fenêtre de sauvegarde. Les restaurations sont pires : lorsque vous devez récupérer rapidement, vous restaurez non seulement les données transactionnelles nécessaires au fonctionnement de l’entreprise, mais aussi de larges jeux de données analytiques qui ne sont pas requis pour redémarrer l’activité. Les tests de reprise prennent aussi plus de temps, et ont donc lieu moins souvent — exactement l’opposé de ce qu’il faudrait.
La planification de capacité devient de la devinette
La croissance transactionnelle est souvent prévisible : plus de clients, plus de commandes, plus de lignes. La croissance analytique est souvent en bosse : un nouveau dashboard, une politique de rétention, ou une équipe qui décide de garder « juste une année de plus » d’événements bruts.
Quand les deux cohabitent, il est difficile de répondre :
- Grandissons‑nous parce que le produit marche, ou parce que les rapports stockent plus d’historique ?
- Avons‑nous besoin d’un stockage plus rapide pour les transactions, ou plus de stockage bon marché pour l’analytique ?
Cette incertitude mène à du sur‑provisionnement (payer une capacité inutile) ou du sous‑provisionnement (pannes surprises).
Les garde‑fous sont plus difficiles à appliquer équitablement
Dans une base partagée, une requête « innocente » peut devenir un incident. Vous finissez par ajouter des garde‑fous : timeouts de requête, quotas, fenêtres de reporting planifiées ou règles de gestion de charge. Ils aident, mais restent fragiles : l’appli et les analystes se disputent maintenant les mêmes limites, et un changement de politique pour un groupe peut casser l’autre.
La sécurité et le contrôle d’accès deviennent compliqués
Les applications ont typiquement besoin de permissions restreintes et ciblées. Les analystes ont souvent besoin d’un accès large en lecture, parfois sur de nombreuses tables, pour explorer et valider. Mettre les deux dans une même base accroît la pression pour accorder des privilèges plus larges « juste pour que le rapport marche », augmentant le périmètre d’erreur et le nombre de personnes pouvant voir des données opérationnelles sensibles.
Mise à l’échelle et coût : vous finissez par payer deux fois (ou pire)
Parrainez un collègue et gagnez
Faites venir des collègues via parrainage et gagnez des crédits à chaque nouvel utilisateur.
Tenter de faire tourner OLTP et OLAP dans la même base semble souvent moins cher — jusqu’à ce que vous mettiez à l’échelle. Le problème n’est pas que la performance souffre. C’est que la « bonne » façon de monter chaque charge vous pousse vers des infrastructures différentes, et les combiner force des compromis coûteux.
L’échelle OLTP est pilotée par les écritures (et souvent douloureuse)
Les systèmes transactionnels sont contraints par les écritures : beaucoup de petites mises à jour, latence stricte, et des pics à absorber immédiatement. Monter l’OLTP implique souvent du scaling vertical (CPU plus gros, disques plus rapides, plus de mémoire) parce que les charges orientées écriture ne se distribuent pas facilement.
Quand les limites verticales sont atteintes, vous regardez vers le sharding ou d’autres patterns d’échelle d’écriture. Cela ajoute une complexité d’ingénierie et requiert souvent des changements applicatifs.
L’échelle OLAP est pilotée par le calcul (et souvent élastique)
Les charges analytiques montent différemment : longs scans, lourdes agrégations et beaucoup de débit en lecture. Les systèmes OLAP se dimensionnent typiquement en ajoutant du compute distribué, et beaucoup de solutions modernes séparent compute et storage pour monter la puissance de requête sans déplacer/doubler les données.
Si l’OLAP partage la base OLTP, vous ne pouvez pas monter l’analytique indépendamment. Vous montez toute la base — même si les transactions vont bien.
La facture cachée : payer du matériel OLTP pour de l’analytique
Pour garder les transactions rapides pendant l’exécution de rapports, les équipes sur‑provisionnent la base de production : CPU de réserve, stockage haut de gamme et instances plus grandes « au cas où ». Cela signifie que vous payez un prix OLTP pour supporter un comportement OLAP.
La séparation réduit le sur‑provisionnement parce que chaque système peut être dimensionné pour sa tâche : OLTP pour des écritures bas‑latence, OLAP pour des lectures massives. Le résultat est souvent moins cher au global — même si c’est « deux systèmes » — parce que vous arrêtez d’acheter de la capacité transactionnelle premium pour exécuter le reporting en production.
Architectures courantes qui séparent OLTP et OLAP
La plupart des équipes séparent la charge transactionnelle (OLTP) de la charge analytique (OLAP) en ajoutant un second système « orienté lecture » plutôt que de forcer une seule base à tout servir.
Pattern 1 : réplique de lecture pour le reporting
Un premier pas commun est une réplique de lecture (ou follower) de la base OLTP, où les outils BI exécutent des requêtes.
Pros : configuration minimale côté appli, SQL familier, mise en place rapide.
Cons : c’est toujours le même moteur et le même schéma, donc des rapports lourds peuvent saturer le CPU/E/S de la réplique ; certains rapports exigent des fonctionnalités non disponibles sur les répliques ; et le lag de réplication signifie que les chiffres peuvent être en retard de plusieurs minutes. Le lag crée aussi des conversations confuses « pourquoi ça ne correspond pas à la production ? » lors d'incidents.
Meilleur usage : petites équipes, volume modeste, « quasi‑temps réel » appréciable mais non critique, et requêtes de reporting contrôlées.
Pattern 2 : entrepôt dédié / base analytique
Ici, l’OLTP reste optimisé pour les écritures et lectures ponctuelles, tandis que l’analytique va dans un entrepôt de données (ou base analytique colonne) conçu pour les scans, la compression et les agrégations.
Pros : performance OLTP prévisible, dashboards plus rapides, meilleure concurrence pour les analystes, et tuning/coût plus clair.
Cons : vous opérez un système supplémentaire et avez besoin d’un modèle de données (souvent en étoile) ami de l’analytique.
Meilleur usage : données en croissance, nombreux acteurs, reporting complexe ou contraintes strictes de latence OLTP.
Pattern 3 : pipeline CDC vers l’analytique
Au lieu d’ETL périodiques, vous streammez les changements via CDC (change data capture) depuis le log OLTP vers l’entrepôt (souvent avec ELT).
Pros : données plus fraîches sans surcharge sur l’OLTP, traitement incrémental plus facile, meilleure traçabilité.
Cons : plus de pièces en mouvement et gestion prudente des changements de schéma.
Meilleur usage : gros volumes, besoin fort de fraîcheur, équipes prêtes à gérer des pipelines de données.
Faire passer les données d’OLTP à OLAP en toute sécurité
Déplacer les données de votre base transactionnelle vers un système analytique consiste moins à « copier des tables » qu’à construire un pipeline fiable et peu intrusif. Le but est simple : l’analytique obtient ce dont elle a besoin sans mettre le trafic de production en danger.
ETL vs ELT (version en clair)
ETL (Extract, Transform, Load) signifie que vous nettoyez et transformez les données avant de les charger dans l’entrepôt. Utile quand le calcul dans l’entrepôt est coûteux ou quand vous voulez un contrôle strict sur ce qui est stocké.
ELT (Extract, Load, Transform) charge des données brutes puis transforme dans l’entrepôt. Plus rapide à mettre en place et plus facile à faire évoluer : vous conservez l’historique « source of truth » et pouvez ajuster les transformations quand les besoins changent.
Règle pratique : si la logique métier change souvent, l’ELT réduit la ré‑ingénierie ; si la gouvernance exige des données strictement curées, l’ETL peut mieux convenir.
Basics du CDC : capturer le changement sans grosses requêtes
Le Change Data Capture (CDC) stream les insert/update/delete depuis l’OLTP (souvent depuis le journal de la base) vers votre système analytique. Au lieu de rescanner de grosses tables, le CDC vous permet de déplacer seulement ce qui a changé.
Ce que cela permet :
- Reporting quasi‑temps réel sans gros reads sur la production
- Replays et backfills pour reconstruire des tables analytiques
- Traçabilité (qui a changé quoi et quand), si vous stockez les événements de changement
Fraîcheur des données : temps réel vs quasi‑temps réel vs quotidien
La fraîcheur est une décision métier avec un coût technique.
- Temps réel (secondes) : parfait pour des tableaux de bord opérationnels, mais le plus difficile à maintenir ; les petits incidents de pipeline apparaissent immédiatement.
- Quasi‑temps réel (minutes) : un compromis courant — bon pour la prise de décision sans complexité extrême.
- Batches journaliers : le plus simple et le moins cher, parfait pour des rapports finance où « hier » suffit.
Définissez un SLA clair (par exemple : « les données ont au maximum 15 minutes de retard ») pour que les parties prenantes sachent ce que « frais » signifie.
Contrôles qualité qui évitent les pannes silencieuses
Les pipelines tombent souvent en rade silencieusement — jusqu’à ce que quelqu’un remarque que les chiffres sont faux. Ajoutez des contrôles légers pour :
- Les changements de schéma : nouvelles colonnes, renommages ou changements de type qui peuvent annuler des données.
- Les événements arrivant en retard : commandes ou paiements qui arrivent des heures plus tard ; gérez‑les avec une fenêtre de rattrapage.
- La déduplication : retries et replays peuvent double‑compter ; utilisez des IDs stables et des chargements idempotents.
Ces gardes‑fous maintiennent la confiance dans l’OLAP tout en protégeant l’OLTP.
Quand partager une base peut être acceptable
Démarrez rapidement une application transactionnelle
Générez depuis le chat une application React avec backend Go, prête pour des charges transactionnelles.
Conserver OLTP et OLAP ensemble n’est pas automatiquement « faux ». Cela peut être un choix sensé temporairement quand l’application est petite, les besoins analytiques étroits, et que vous pouvez imposer des limites strictes pour que l’analytique n’étonne pas vos clients par des checkouts lents, des paiements ratés ou des timeouts.
Situations où cela peut fonctionner
Petites applis avec une analytique légère et des limites strictes s’en sortent souvent avec une seule base — surtout au démarrage. L’important est d’être honnête sur ce que « léger » signifie : quelques dashboards, un nombre de lignes modéré, et un plafond clair sur le temps d’exécution et la concurrence.
Pour un ensemble restreint de rapports récurrents, vues matérialisées ou tables de synthèse peuvent réduire le coût analytique. Au lieu de scanner les transactions brutes, vous précomputez des totaux quotidiens, des rollups par catégorie ou par client. Cela garde la plupart des requêtes courtes et prévisibles.
Si les utilisateurs métier acceptent des chiffres décalés, fenêtres de reporting hors pointe aident : exécutez les jobs lourds la nuit ou pendant les périodes creuses, et attribuez un rôle de reporting avec permissions et limites plus strictes.
Garde‑fous à ajouter
- Définir des timeouts de statement et annuler les requêtes qui s’emballent.
- Limiter la concurrence des utilisateurs analytiques.
- Surveiller p95/p99 de latence pour les transactions critiques séparément du reporting.
Signes clairs qu’il est temps de séparer
Si vous observez une latence transactionnelle en hausse, des incidents récurrents pendant les runs de rapport, l’épuisement du pool de connexions, ou des histoires du type « une requête a fait tomber la production », vous avez dépassé la zone sûre. À ce stade, séparer les bases (ou au moins utiliser des répliques) cesse d’être une optimisation et devient une hygiène opérationnelle essentielle.
Checklist pratique de migration : du partagé au séparé
Déplacer l’analytique hors de la base de production est moins une grosse réécriture qu’un travail de visibilité, de définition d’objectifs et de migration par étapes contrôlées.
1) Inventoriez ce qui se passe aujourd’hui
Commencez par des preuves, pas des hypothèses. Récupérez :
- Les endpoints/requêtes OLTP principaux par fréquence et p95/p99 (checkout, login, create order, etc.)
- Les rapports/dashboards OLAP principaux par temps d’exécution, volume de scan et importance métier
Incluez l’analytique « cachée » : SQL ad hoc des outils BI, exports programmés et téléchargements CSV.
2) Définissez des cibles : SLOs OLTP et fraîcheur analytique
Écrivez les cibles que vous optimiserez :
- SLOs OLTP : latence p95/p99, taux d’erreur et débit de pointe à soutenir
- Fraîcheur analytique : combien de retard est acceptable (5 minutes, 1 heure, le lendemain), plus le temps de reconstruction si un pipeline casse
Cela évite les débats du type « c’est lent » vs « ça va » et aide à choisir l’architecture.
3) Choisissez une voie de séparation
Choisissez l’option la plus simple qui atteint les cibles :
- Réplique de lecture : adoption la plus rapide pour du reporting en lecture, mais peut rester stressée par des requêtes coûteuses et par le lag
- Entrepôt : meilleur pour de larges scans, nombreuses jointures et longue histoire ; souvent la bonne maison pour la BI
- Pipeline CDC (ETL/ELT) : idéal quand vous voulez de la fraîcheur quasi‑temps réel sans toucher la production
4) Déroulez prudemment (parallèle d’abord)
- Validez les définitions (fuseaux, remboursements, « utilisateur actif », etc.) pour que les chiffres correspondent.
- Faites tourner anciens et nouveaux dashboards en parallèle pendant un cycle métier complet.
- Basculez rapport par rapport, en commençant par les requêtes les plus pénibles.
- Restreignez l’accès direct au « reporting en production » une fois que les stakeholders font confiance à la nouvelle source.
5) Ajoutez des garde‑fous pour éviter la régression
Surveillez le lag de réplique / les délais du pipeline, les temps d’exécution des dashboards et la dépense dans l’entrepôt. Ajoutez des budgets de requêtes (timeouts, limites de concurrence), et gardez un playbook d’incident : quoi faire quand la fraîcheur tombe, la charge augmente ou les métriques divergent.
Note pratique si vous construisez l’appli elle‑même
Si vous êtes tôt dans le produit et avancez vite, le plus grand risque est de construire par inadvertance l’analytique directement dans le même chemin que les transactions critiques (par exemple des requêtes de dashboard qui deviennent « critiques pour la production »). Une façon d’éviter ça est d’anticiper la séparation dès le départ — même en commençant par une réplique modeste — et de l’intégrer dans votre checklist d’architecture.
Des plateformes comme Koder.ai peuvent aider ici parce que vous pouvez prototyper la partie OLTP (React app + Go services + PostgreSQL) et esquisser la frontière reporting/entrepôt en mode planning avant de livrer. À mesure que le produit grandit, vous pouvez exporter le code source, faire évoluer le schéma et ajouter des composants CDC/ELT sans transformer le « reporting en production » en habitude permanente.
FAQ
Quelle est la façon la plus simple d'expliquer OLTP vs OLAP ?
OLTP (Online Transaction Processing) gère les opérations quotidiennes comme la création de commandes, la mise à jour des stocks et l'enregistrement des paiements. Il privilégie la faible latence, la haute concurrence et la cohérence.
OLAP (Online Analytical Processing) répond aux questions métier via de grands scans et des agrégations (tableaux de bord, tendances, cohortes). Il privilégie le débit, la flexibilité des requêtes et la rapidité de synthèse plutôt que des temps de réponse en millisecondes.
Pourquoi l'exécution d'analyses sur la même base de données nuisent-elles aux performances transactionnelles ?
Parce que les charges de travail se disputent les mêmes ressources :
- CPU & mémoire : les longues agrégations et jointures peuvent écraser les petites requêtes transactionnelles.
- Entrées/sorties disque : les scans analytiques perturbent les petits accès aléatoires et les écritures de journaux/index des OLTP.
- Basculement du cache : les gros scans peuvent expulser des pages chaudes OLTP, ralentissant soudainement l'application.
- Pression sur le pool de connexions : quelques longues requêtes BI peuvent monopoliser les connexions et provoquer des files d'attente côté application.
Ne peut-on pas juste ajouter plus d'index pour rendre OLTP et OLAP rapides ?
En général non. Ajouter des index pour accélérer des tableaux de bord aboutit souvent à des effets inverses parce que :
- Chaque index supplémentaire augmente le coût des écritures (insert/update/delete doit maintenir plus de structures).
- Les index augmentent l'espace de stockage et ralentissent les opérations de maintenance (vacuum/reindex/sauvegardes).
- On finit par tuner pour un rapport et détériorer d'autres requêtes (ou les écritures OLTP).
Pour l'analytique, on obtient souvent de meilleurs résultats avec la , le stockage colonne ou les pré-agrégations** dans un système orienté OLAP.
Comment MVCC et les requêtes longue durée ralentissent-ils, avec le temps, les bases de données partagées ?
MVCC aide lecteurs et rédacteurs à éviter le blocage, mais cela ne rend pas les charges mixtes « gratuites ». Problèmes pratiques :
- Les rapports longue durée gardent des snapshots anciens ouverts, retardant le nettoyage des versions de lignes.
- Les délais de nettoyage causent de la bloat / fragmentation, ce qui ralentit les requêtes et gaspille le cache.
- Le nettoyage/compactage en arrière-plan peut voler du CPU et des E/S aux transactions.
Donc, même sans blocages évidents, l'analytique lourde peut dégrader les performances au fil du temps.
Quels sont les signes d'alerte indiquant qu'il est temps de séparer OLTP et OLAP ?
Vous voyez souvent des signes tels que :
- Pics de latence p95/p99 pour les endpoints checkout/login/update
- Timeouts ou retentatives accrues pendant les fenêtres de reporting
- Épuisement du pool de connexions (requêtes applicatives en attente d'une connexion DB libre)
- Incidents corrélés avec la clôture de fin de mois / trimestre
Si le système paraît « aléatoirement lent » lors des rafraîchissements de dashboards, c'est un symptôme classique d'une charge mixte.
Quand une read replica a-t-elle du sens pour le reporting ?
Un read replica est souvent le premier pas :
- Avantages : changements minimaux côté application, schéma/SQL familiers, isole les écritures de production.
- Inconvénients : les rapports lourds peuvent toujours saturer le CPU/E/S de la réplique ; le lag de réplication peut embrouiller les comparaisons de métriques ; c'est toujours une technologie orientée ligne/OLTP.
C'est une bonne solution transitoire quand le volume de données est modeste et qu'un retard de quelques minutes est acceptable.
Quand doit-on utiliser un entrepôt de données dédié plutôt qu'une réplique ?
Une warehouse convient mieux quand vous avez besoin de :
- Performances rapides sur grands scans, jointures et agrégations
- Plusieurs analystes exécutant des requêtes en parallèle
- Une conservation longue de l'historique sans pénaliser l'OLTP
- Une séparation claire de l'optimisation et des coûts (OLTP pour latence, OLAP pour débit)
Elle demande généralement un modèle adapté à l'analytique (souvent en étoile) et une pipeline pour charger les données.
Qu'est-ce que le CDC, et pourquoi est-il souvent meilleur que d'exécuter de gros ETL sur la production ?
CDC (Change Data Capture) diffuse les insert/update/delete depuis la base OLTP (souvent via son journal) vers l'analytique.
Pourquoi c'est souvent préférable à de grosses requêtes ETL sur la production :
- Vous déplacez seulement ce qui a changé, au lieu de rescanner de grandes tables.
- Vous obtenez une fraîcheur près du temps réel avec un moindre impact sur l'OLTP.
- Les replays/backfills sont plus simples quand vous disposez d'un flux de changements.
Comment choisir entre ETL et ELT pour déplacer les données OLTP vers OLAP ?
Choisissez selon la fréquence des changements de logique métier et ce que vous voulez stocker :
- ELT : chargez d'abord des données brutes, transformez ensuite dans l'entrepôt. Plus facile à faire évoluer quand les définitions changent.
- ETL : transformez avant de charger. Utile quand il faut stocker uniquement des sorties soigneusement curées ou appliquer un contrôle strict en amont.
Approche pratique : commencer par ELT pour la vitesse, puis ajouter gouvernance (tests, modèles curatoriaux) quand les métriques critiques sont stabilisées.
Est-il acceptable de garder OLTP et OLAP dans la même base ?
Oui — temporairement — si vous maintenez l'analytique vraiment légère et que vous appliquez des garde-fous :
- Timeouts de requêtes et annulation des requêtes qui s'emballent
- Limites de concurrence pour les utilisateurs de reporting
- Pré-agrégations (vues matérialisées / tables de synthèse)
- Surveillance séparée de la p95/p99 pour l'OLTP et des temps d'exécution des rapports
Cela devient inacceptable dès que le reporting provoque régulièrement des pics de latence, l'épuisement des pools ou des incidents de production.