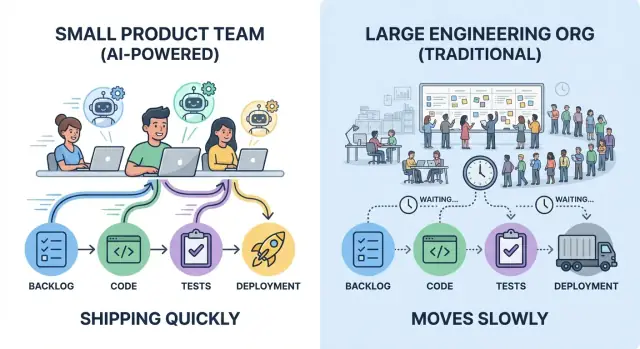
Ce que « vitesse » signifie dans la livraison produit réelle
« Livrer plus vite » ne se résume pas à taper du code rapidement. La vraie vitesse de livraison, c'est le temps entre une idée qui devient une amélioration fiable perceptible par les utilisateurs — et l'équipe apprenant si cela a fonctionné.
Les métriques qui décrivent vraiment la vitesse
Les équipes débattent de la vitesse parce qu'elles mesurent des choses différentes. Une vue pratique repose sur un petit ensemble de métriques de livraison :
- Lead time : combien de temps pour passer de « on a décidé de faire ça » à « c'est en ligne pour les utilisateurs ».
- Cycle time : combien de temps un travail reste « en cours » une fois quelqu'un l'a démarré.
- Fréquence de déploiement : à quelle fréquence vous pouvez publier en toute sécurité (quotidien, hebdo, à la demande).
- Time-to-learning : la rapidité à obtenir un signal fiable (utilisation, tickets support, rétention, revenu) qui indique la suite.
Une petite équipe qui déploie cinq petits changements par semaine apprend souvent plus vite qu'une plus grosse org qui publie une grosse release par mois — même si la release mensuelle contient plus de code.
Ce que signifie « utiliser l'IA » (et ce que ça ne signifie pas)
Concrètement, « IA pour l'ingénierie » ressemble souvent à un ensemble d'assistants intégrés au travail existant :
- copilotes pour rédiger du code, des refactors et de la documentation
- génération et maintenance de tests
- aide à la revue de code (repérer des cas limites, suggérer des simplifications)
- bots support et ops (résumés d'incidents, ébauches de runbooks, réponses « où c'est implémenté ? »)
L'IA aide surtout sur le débit par personne et la réduction du retravail — mais elle ne remplace pas le bon jugement produit, des exigences claires ni la responsabilité.
Idée centrale : surcharge vs boucles d'itération
La vitesse est surtout contrainte par deux forces : la surcharge de coordination (hand-offs, approbations, attentes) et les boucles d'itération (construire → déployer → observer → ajuster). L'IA amplifie les équipes qui gardent déjà le travail petit, les décisions claires et le feedback serré.
Sans habitudes et garde-fous — tests, revue de code et discipline de release — l'IA peut aussi accélérer le mauvais travail tout aussi efficacement.
La taxe cachée de la taille : la surcharge de coordination
Les grandes équipes n'ajoutent pas seulement des personnes — elles ajoutent des connexions. Chaque frontière d'équipe introduit du travail de coordination qui ne livre pas de fonctionnalités : synchroniser les priorités, aligner les designs, négocier la propriété, et faire transiter les changements par les bons canaux.
Où passe réellement le temps
La surcharge de coordination apparaît dans des endroits familiers :
- Réunions pour « mettre tout le monde sur la même longueur d'onde » (status, planification, alignement roadmap)
- Revues demandant plusieurs parties prenantes (sécurité, confidentialité, architecture, marque)
- Hand-offs entre rôles ou équipes (produit → design → engineering → plateforme → SRE)
- Documentation rédigée pour permettre ces transferts et justifier les décisions plus tard
Rien de tout cela n'est intrinsèquement mauvais. Le problème, c'est que ça se cumule — et ça croît plus vite que les effectifs.
Les dépendances créent de l'attente, pas du travail
Dans une grande org, un changement simple traverse souvent plusieurs lignes de dépendance : une équipe possède l'UI, une autre l'API, une équipe plateforme gère le déploiement et une équipe infosec valide. Même si chaque groupe est efficace, le temps en file d'attente domine.
Les ralentissements courants ressemblent à :
- Une fonctionnalité bloquée par un comité d'architecture trimestriel
- Un petit ajustement d'API qui attend deux semaines dans le backlog plateforme
- Une release retenue jusqu'à une fenêtre centrale QA/compliance
- « On a besoin d'un accord de l'équipe X » qui devient une série de trois réunions
Le lead time n'est pas que du temps de codage ; c'est le temps écoulé de l'idée à la production. Chaque poignée de mains supplémentaire ajoute de la latence : attente de la prochaine réunion, du prochain relecteur, du prochain sprint, de la prochaine place dans la file d'attente de quelqu'un d'autre.
Les petites équipes gagnent souvent parce qu'elles maintiennent une responsabilité serrée et des décisions locales. Cela n'élimine pas les revues — cela réduit le nombre d'étapes entre « prêt » et « livré », où les grandes orgs perdent des jours et des semaines sans le dire.
Les petites équipes gagnent avec une ownership claire et moins de handoffs
La vitesse ne consiste pas uniquement à taper plus vite — elle consiste à faire attendre moins de monde. Les petites équipes livrent rapidement quand le travail a une ownership single-threaded : une personne (ou paire) clairement responsable qui pilote une fonctionnalité de l'idée à la production, avec un décideur nommé qui peut trancher.
L'ownership single-threaded rend les décisions bon marché
Quand un propriétaire unique est responsable des résultats, les décisions ne rebondissent pas en boucle entre produit, design, ingénierie et « l'équipe plateforme ». Le propriétaire recueille les avis, prend la décision et avance.
Cela ne signifie pas travailler seul. Cela signifie que tout le monde sait qui pilote, qui approuve et ce que « fini » veut dire.
Moins de handoffs = moins de retravail
Chaque handoff ajoute deux types de coût :
- Perte de contexte : des détails sont simplifiés, des hypothèses restent implicites et des cas limites disparaissent.
- Retravail : la personne suivante découvre des contraintes trop tard et renvoie le travail en amont.
Les petites équipes évitent cela en gardant le problème dans une boucle serrée : le même propriétaire participe aux exigences, à l'implémentation, au déploiement et au suivi. Résultat : moins de moments « attends, ce n'est pas ce que je voulais ».
Comment l'IA aide un propriétaire à couvrir plus de domaines
L'IA n'enlève pas la responsabilité — elle la prolonge. Un propriétaire unique peut rester efficace sur plus de tâches en utilisant l'IA pour :
- Rédiger des specs de premier jet, des notes de version et des communications client
- Résumer de longs fils, l'historique d'incidents ou des décisions antérieures en un bref résumé
- Esquisser l'implémentation : générer du boilerplate, des plans de tests, des scripts de migration ou des stubs clients d'API
Le propriétaire valide et décide toujours, mais le temps nécessaire pour passer d'une page blanche à un brouillon exploitable diminue fortement.
Si vous utilisez un workflow vibe-coding (par exemple Koder.ai), ce modèle « un propriétaire couvre toute la tranche » devient encore plus simple : vous pouvez rédiger un plan, générer une UI React plus un backend Go/PostgreSQL, itérer sur de petits changements dans le même flux de chat — puis exporter le code source quand vous voulez un contrôle plus strict.
Signaux d'une ownership forte
Repérez ces signes opérationnels :
- Un backlog par initiative (pas dispersé entre plusieurs outils ou équipes)
- Une définition de fini, incluant tests et rollout (pas « fini en dev »)
- Un décideur unique pour la priorité et le périmètre
- Interfaces claires avec les autres équipes : les demandes sont explicites, limitées dans le temps et documentées
Quand ces signaux sont présents, une petite équipe peut avancer avec confiance — et l'IA facilite le maintien de cet élan.
Des boucles de feedback serrées battent les plans importants
Les grands plans semblent efficaces parce qu'ils réduisent les « moments de décision ». Mais ils repoussent souvent l'apprentissage à la fin — après des semaines de construction — quand les changements coûtent cher. Les petites équipes vont plus vite en réduisant la distance entre une idée et le feedback réel.
Les boucles courtes évitent le travail gaspillé
Une boucle de feedback courte est simple : construire la plus petite chose qui peut vous apprendre quelque chose, la mettre devant des utilisateurs et décider de la suite.
Quand le feedback arrive en jours (pas en trimestres), vous arrêtez de polir la mauvaise solution. Vous évitez aussi la sur-ingénierie « au cas où » qui ne se matérialise jamais.
À quoi ressemble un apprentissage rapide
Les petites équipes peuvent exécuter des cycles légers produisant tout de même des signaux forts :
- Prototypes rapides : maquettes cliquables ou flux « happy path » pour valider la compréhension de valeur par l'utilisateur.
- Interviews utilisateurs précoces : 5–8 conversations dévoilent souvent les objections principales et les manques.
- Itérations A/B rapides : petits changements UI ou onboarding mesurés sur une courte période pour révéler la direction qui réduit les frictions.
L'important est de traiter chaque cycle comme une expérience, pas comme un mini-projet.
L'IA accélère l'apprentissage, pas seulement la construction
Le plus gros levier de l'IA ici n'est pas d'écrire plus de code — c'est de comprimer le temps entre « on a entendu quelque chose » et « on sait quoi essayer ensuite ». Par exemple, on peut utiliser l'IA pour :
- Résumer les retours d'interviews, tickets support, avis d'app ou notes de vente en conclusions nettes
- Regrouper les thèmes (points de confusion, fonctionnalités manquantes, problèmes de confiance) pour faire émerger des motifs
- Rédiger des expériences : proposer des hypothèses, des métriques de succès et le plus petit test permettant de les confirmer ou infirmer
Cela réduit le temps passé en réunions de synthèse et augmente le temps consacré au prochain test.
Vitesse de livraison vs vitesse d'apprentissage
Les équipes célèbrent souvent la vélocité de livraison — combien de fonctionnalités sont sorties. Mais la vraie vitesse, c'est la vélocité d'apprentissage : la rapidité pour réduire l'incertitude et prendre de meilleures décisions.
Une grande org peut beaucoup livrer et rester lente si elle apprend tard. Une petite équipe peut livrer moins en volume mais avancer plus vite en apprenant plus tôt, corrigeant plus vite et laissant les preuves façonner la roadmap.
L'IA comme multiplicateur de force, pas comme remplaçant
Restez dans la boucle
Réduisez les changements de contexte en regroupant plan, code et modifications dans un flux de travail guidé.
L'IA n'agrandit pas une petite équipe ; elle permet au jugement et à la responsabilité existants d'aller plus loin. Le gain n'est pas que l'IA écrive du code, mais qu'elle enlève les frottements des parties du flux de livraison qui volent du temps sans améliorer le produit.
Usages à fort levier qui se cumulent
Les petites équipes obtiennent des gains disproportionnés quand elles ciblent l'IA sur les travaux nécessaires mais peu différenciants :
- Génération de boilerplate : scaffolding d'endpoints, fichiers de tests, templates de migration, config CI, ou composants UI répétitifs
- Refactors avec plan : renommage, extraction d'helpers, conversion de patterns et mise à jour des points d'appel — surtout avec contraintes claires (« ne change pas le comportement », « API publique stable »)
- Brouillons de documentation : notes de version, outlines ADR, docs d'API, guides d'onboarding et « comment lancer en local »
Le pattern est constant : l'IA accélère les 80% initiaux pour que les humains consacrent plus de temps aux 20% finaux — la partie qui nécessite du sens produit.
Là où l'IA est la plus utile (et là où elle l'est moins)
L'IA excelle sur les tâches routinières, les « problèmes connus » et tout ce qui part d'un pattern existant dans le code. Elle est aussi utile pour explorer des options rapidement : proposer deux implémentations, lister des compromis ou dévoiler des cas limites manqués.
Elle aide le moins quand les exigences sont floues, quand une décision d'architecture a des conséquences long terme, ou quand le problème est très spécifique au domaine avec peu de contexte écrit. Si l'équipe ne peut pas expliquer ce que « fini » veut dire, l'IA ne fera que générer du plausible plus vite.
Vitesse sans raccourcis : la validation est non négociable
Considérez l'IA comme un collaborateur junior : utile, rapide et parfois faux. Les humains gardent la propriété du résultat.
Cela signifie que tout changement assisté par l'IA doit toujours avoir une revue, des tests et des contrôles de base. Règle pratique : utilisez l'IA pour rédiger et transformer ; utilisez des humains pour décider et vérifier. C'est ainsi que les petites équipes livrent plus vite sans transformer la vélocité en dette future.
Réduire le switching de contexte avec l'assistance IA
Le changement de contexte est l'un des tueurs silencieux de la vitesse dans les petites équipes. Ce n'est pas juste être interrompu — c'est le redémarrage mental à chaque basculement entre code, tickets, docs, fils Slack et parties du système inconnues. L'IA aide principalement en transformant ces redémarrages en courtes haltes.
Au lieu de perdre 20 minutes à chercher une réponse, vous pouvez demander un résumé rapide, un pointeur vers les fichiers probables ou une explication en langage simple de ce que vous regardez. Bien utilisée, l'IA devient un générateur de « premier jet » pour la compréhension : résumer une PR longue, transformer un bug vague en hypothèses, ou traduire une stack trace en causes probables.
Le gain n'est pas que l'IA ait toujours raison — c'est qu'elle vous oriente plus vite pour prendre des décisions réelles.
Tactiques pratiques qui fonctionnent dans les équipes réelles
Quelques patterns de prompts réduisent régulièrement le thrash :
- Demander des options : « Donne-moi 3 approches pour corriger ça, avec compromis et risques. »
- Expliquer ce code : « Explique ce que fait cette fonction, les cas limites et ce qui casserait si on change X. »
- Générer un plan : « Crée un plan pas-à-pas pour livrer ça en deux petites PRs, incluant les tests. »
- Écrire une checklist : « Checklist pour publier ça en sécurité (monitoring, rollback, validation). »
Ces prompts vous font passer de l'errance à l'exécution.
Rendre les prompts réutilisables, pas héroïques
La vitesse se cumule quand les prompts deviennent des templates utilisés par toute l'équipe. Gardez un petit « kit de prompts » interne pour tâches courantes : revues de PR, notes d'incident, plans de migration, checklists QA et runbooks de release. La cohérence compte : incluez l'objectif, les contraintes (temps, périmètre, risque) et le format attendu de sortie.
Limites et garde-fous
Ne collez pas de secrets, données clients ou quoi que ce soit que vous ne mettriez pas dans un ticket. Traitez les sorties comme des suggestions : vérifiez les affirmations critiques, lancez les tests et revérifiez le code généré — surtout autour de l'auth, des paiements et des suppressions de données. L'IA réduit les switchs ; elle ne doit pas remplacer le jugement d'ingénierie.
Livrer petit, livrer souvent : pratiques amplifiées par l'IA
Livrer plus vite n'est pas une course héroïque ; c'est réduire la taille de chaque changement jusqu'à ce que la livraison devienne routinière. Les petites équipes ont déjà un avantage ici : moins de dépendances facilite le découpage fin. L'IA amplifie cet avantage en réduisant le temps entre « idée » et « changement sûr et livrable ».
Un pipeline de livraison léger (qui se réduit bien)
Un pipeline simple bat un pipeline élaboré :
- Développement trunk-based : intégrer fréquemment dans main plutôt que garder des branches longues.
- Petites PRs : changements relus en minutes, pas en heures.
- Déploiements fréquents : publier quand un changement est prêt, pas quand un lot est « assez grand ».
L'IA aide en rédigeant des notes de release, suggérant des commits plus petits et signalant des fichiers souvent touchés ensemble — vous poussant vers des PRs plus propres et concises.
Tests accélérés par l'IA : couverture sans frein
Les tests sont souvent là où « livrer souvent » casse. L'IA peut réduire cette friction en :
- Générant des tests unitaires/intégration de départ à partir de patterns existants
- Brainstormant des cas limites (zones horaires, états vides, retries, limites de débit)
- Proposant des données de test et des mocks correspondant aux shapes d'API réelles
Considérez les tests générés par l'IA comme un premier jet : révisez pour la justesse, puis conservez ceux qui protègent réellement le comportement.
Confiance au déploiement : monitoring, alertes, rollback
Les déploiements fréquents exigent détection rapide et rétablissement rapide. Mettez en place :
- Des health checks et dashboards pour les parcours utilisateurs clés
- Des alertes liées aux symptômes (taux d'erreur, latence, jobs échoués), pas aux métriques de vanité
- Un rollback en une commande (ou rollback automatisé) pour que mauvaise release rime avec petit incident
Si vos fondamentaux de livraison ont besoin d'un rappel, liez cela dans la lecture partagée de l'équipe : /blog/continuous-delivery-basics.
Avec ces pratiques, l'IA ne vous « rend pas plus rapide » par magie — elle supprime les petits retards qui s'accumulent en cycles de plusieurs semaines.
Latence décisionnelle : approbations vs garde-fous
Réduisez la latence décisionnelle
Utilisez le mode Planification pour définir la portée, les risques et les critères d'acceptation avant de générer le code.
Les grandes organisations n'avancent pas lentement parce que les gens sont paresseux. Elles ralentissent parce que les décisions s'alignent en file d'attente. Les comités d'architecture se réunissent mensuellement. Les revues sécurité/confidentialité restent dans des backlogs. Un changement « simple » peut nécessiter revue tech lead, puis staff engineer, puis approbation plateforme, puis approbation release manager. Chaque étape ajoute du temps d'attente, pas seulement du temps de travail.
Les petites équipes ne peuvent pas se permettre cette latence décisionnelle ; elles devraient viser un autre modèle : moins d'approbations, des garde-fous plus robustes.
Ce que cherchent à résoudre les approbations (et pourquoi elles coincent)
Les chaînes d'approbation sont un outil de gestion des risques. Elles réduisent la probabilité de mauvais changements, mais elles centralisent la prise de décision. Quand le même petit groupe doit bénir chaque changement significatif, le débit s'effondre et les ingénieurs optimisent pour « obtenir l'approbation » plutôt que pour améliorer le produit.
Garde-fous : l'alternative pour les petites équipes
Les garde-fous déplacent les vérifications qualité des réunions vers des valeurs par défaut :
- Standards de code clairs et définitions de Done
- Checklists légères pour les zones risquées (auth, paiements, suppression de données)
- Vérifications automatisées : tests, linting, type checking, scanning de dépendances
Au lieu de « qui a approuvé ? », la question devient « est-ce que ça a passé les gates convenues ? »
L'IA peut standardiser la qualité sans ajouter d'humains à la boucle :
- Suggestions de lint et refactor pour aligner le code sur les standards de l'équipe
- Résumés de PR expliquant l'intention, le périmètre et le risque en langage clair
- Checklists de revue générées depuis le diff (par ex. « touche des PII : confirmer la politique de rétention ») pour que les relecteurs ne comptent pas sur la mémoire
Cela améliore la consistance et accélère les revues, car le relecteur part d'un brief structuré plutôt que d'un écran vide.
La conformité n'a pas besoin d'un comité. Rendez-la répétable :
- Définir des triggers « requièrent revue » (PII, mouvements d'argent, permissions)
- Utiliser des templates pour les preuves (résumé PR + checklist + résultats des tests)
- Stocker les décisions dans le fil de la PR pour que les audits soient retrouvables
Les approbations deviennent l'exception pour les travaux à haut risque ; les garde-fous gèrent le reste. C'est ainsi que les petites équipes restent rapides sans être imprudentes.
Le design en tranches fines pour maintenir l'élan
Les grandes équipes « designent souvent tout le système » avant que quelqu'un ne livre. Les petites équipes vont plus vite en concevant des thin slices : la plus petite unité end-to-end de valeur qui puisse passer de l'idée au code et être utilisée (même par une petite cohorte).
Ce qu'est vraiment une thin slice
Une thin slice est ownership verticale, pas une phase horizontale. Elle inclut ce qui est nécessaire à travers design, backend, frontend et ops pour rendre un résultat réel.
Plutôt que « refondre l'onboarding », une thin slice peut être « collecter un champ d'inscription supplémentaire, le valider, le stocker, l'afficher dans le profil et suivre la complétion ». C'est assez petit pour finir vite, mais assez complet pour apprendre.
L'IA sert de partenaire de réflexion structuré :
- Proposer 2–4 options de jalons (minimum viable, moyen, complet)
- Générer une découpe des tâches par couche (UI, API, données, analytics, rollout)
- Signaler des dépendances cachées (migrations, permissions, cas limites)
- Suggérer un plan de déploiement (feature flag, cohorte limitée, fallback)
L'objectif n'est pas plus de tâches, mais une frontière claire et livrable.
Définir le « done » pour chaque tranche
L'élan meurt quand le « presque fini » traîne. Pour chaque slice, écrivez des éléments explicites de Definition of Done :
- Comportement visible par l'utilisateur (ce qui change, pour qui)
- Critères d'acceptation (happy path + cas limites clés)
- Instrumentation (noms d'événements, dashboards, alertes si nécessaire)
- Étapes de déploiement/rollback (ou règles de feature flag)
Exemples de thin slices
- Un endpoint :
POST /checkout/quote retournant prix + taxes
- Un écran : une page de paramètres pour préférences de notification
- Un workflow : réinitialisation de mot de passe de la requête → email → nouveau mot de passe → confirmation
Les thin slices gardent le design honnête : vous concevez ce que vous pouvez livrer maintenant, apprenez vite et laissez la tranche suivante gagner sa complexité.
Optimisez votre budget
Obtenez des crédits en créant du contenu sur Koder.ai ou en parrainant des collègues qui s'inscrivent.
L'IA peut aider une petite équipe à aller vite, mais elle modifie aussi les modes de défaillance. Le but n'est pas de « ralentir pour être sûr » — c'est d'ajouter des garde-fous légers pour continuer à livrer sans accumuler une dette invisible.
Risques courants lorsque l'IA intervient
En allant plus vite, les coins rugueux risquent d'atteindre la production. Avec l'aide de l'IA, quelques risques reviennent souvent :
- Code et style incohérents : les patchs générés par l'IA peuvent varier en patterns, noms et architecture, rendant la base plus difficile à maintenir.
- Problèmes de sécurité : des suggestions peuvent introduire des paramètres par défaut non sécurisés (auth faible, validation manquante, désérialisation dangereuse).
- Logique hallucinaire : le code peut sembler plausible mais être subtilement erroné (cas limites, mauvaises hypothèses d'API, gestion d'erreurs incorrecte).
- Prolifération de dépendances : l'IA peut ajouter des librairies « pour faciliter », augmentant la surface d'attaque et le coût de maintenance.
Garde-fous pour préserver la vitesse sans chaos
Rendez les règles explicites et simples à suivre. Quelques pratiques rapportent vite :
- Guides de code sécurisé : une checklist courte pour zones communes (auth, permissions, validation, logs, chiffrement)
- Scan de secrets en CI et hooks pre-commit, plus règles claires sur l'endroit où stocker les secrets
- Politiques de dépendances : liste de libs approuvées, verrouillage des versions, et principe « nouvelle dépendance = justification »
Vérifications humaines les plus utiles
L'IA peut écrire du code ; les humains doivent en assumer les conséquences.
- Threat modeling pour les changements touchant données, auth, paiements ou flux admin. Même 10 minutes peuvent repérer des risques majeurs.
- Revue de code axée sur le comportement : inputs/outputs, chemins d'erreur, permissions et manipulation des données.
- Stratégie de tests : exiger tests unitaires pour la logique, tests d'intégration pour les flux critiques et un petit ensemble de checks end-to-end à fort signal.
Utiliser l'IA en sécurité au quotidien
Traitez les prompts comme du texte public : ne collez pas de secrets, tokens ou données clients. Demandez au modèle d'expliquer ses hypothèses, puis vérifiez avec les sources primaires (docs) et par des tests. Quand quelque chose semble « trop facile », il faut y regarder de plus près.
Si vous utilisez un environnement de build piloté par IA comme Koder.ai, appliquez les mêmes règles : garder les données sensibles hors des prompts, exiger tests et revues, et vous appuyer sur des workflows de snapshot/rollback pour que « rapide » rime aussi avec « récupérable ».
Mesurer les gains et construire un système reproductible
La vitesse n'a d'importance que si vous pouvez la voir, l'expliquer et la reproduire. Le but n'est pas « utiliser plus d'IA » — c'est un système simple où les pratiques assistées par l'IA réduisent de façon fiable le time-to-value sans augmenter le risque.
Métriques qui montrent la vraie vitesse de livraison (pas l'activité)
Choisissez un petit ensemble à suivre chaque semaine :
- Cycle time : du début du travail à la production
- Taille des PR : lignes/fichiers modifiés (plus petit = revues plus faciles et releases plus sûres)
- Temps de revue : temps médian d'attente pour la première revue et pour le merge
- Incidents/régressions : problèmes en prod par semaine (et gravité), plus le temps moyen de rétablissement
- Temps réponse client : du feedback utilisateur au changement livré
Ajoutez un signal qualitatif : « Qu'est-ce qui nous a le plus ralenti cette semaine ? » pour repérer les goulots invisibles.
Un rythme opérationnel léger
Restez cohérent et adapté aux petites équipes :
- Objectifs hebdomadaires (30 minutes) : 1–3 résultats, pas une longue liste de tâches
- Mises à jour quotidiennes asynchrones : hier/aujourd'hui/bloqueurs dans Slack/Linear/GitHub
- Rythme de démo (hebdo ou bihebdo) : montrer le travail livré, pas des slides. Cela renforce l'idée que « fini » signifie dans les mains des utilisateurs.
Plan de déploiement sur 30 jours pour les workflows IA
Semaine 1 : Baseline. Mesurez les métriques ci-dessus pendant 5–10 jours ouvrés. Aucun changement.
Semaines 2–3 : Choisir 2–3 workflows IA. Exemples : génération de description de PR + checklist de risque, assistance à l'écriture de tests, rédaction automatique de notes de release.
Semaine 4 : Comparer avant/après et stabiliser les habitudes. Si la taille des PR diminue et le temps de revue s'améliore sans plus d'incidents, conservez-les. Si les incidents augmentent, ajoutez des garde-fous (rollouts plus petits, meilleurs tests, ownership clair).
Checklist : commencez cette semaine
- Choisissez 3 métriques à poster dans un fil hebdomadaire.
- Fixez une cible par défaut pour la taille des PR (et imposez-la par des normes sociales, pas de la bureaucratie).
- Ajoutez une étape « pré-revue » assistée par IA : résumer les changements, les risques et la couverture de tests.
- Planifiez une démo.
- Lancez une rétro « goulot » : qu'est-ce qui a causé le plus de retard, et que changeons-nous la semaine prochaine ?