Kafka en langage clair
Apache Kafka est une plateforme distribuée de streaming d'événements. En termes simples, c'est un « tuyau » partagé et durable qui permet à de nombreux systèmes de publier des faits sur ce qui s'est passé et à d'autres systèmes de lire ces faits — rapidement, à grande échelle et dans l'ordre.
Les équipes utilisent Kafka lorsque les données doivent circuler fiablement entre des systèmes sans couplage fort. Plutôt qu'une application n'appelle une autre directement (et échoue si elle est en panne ou lente), les producteurs écrivent des événements dans Kafka. Les consommateurs les lisent quand ils sont prêts. Kafka stocke les événements pour une durée configurable, de sorte que les systèmes peuvent se remettre des pannes et même retraiter l'historique.
Quelques termes que vous verrez
- Événement / Message : Un enregistrement de quelque chose qui s'est produit (par exemple, « OrderPlaced » ou « PaymentFailed »). Les utilisateurs de Kafka disent souvent « message », mais « événement » met l'accent sur le fait qu'il représente un changement réel.
- Flux (Stream) : Un flot continu d'événements dans le temps.
- Log : Kafka organise les événements comme un log append-only — les nouveaux événements sont ajoutés à la fin, et les lecteurs avancent à leur rythme.
À qui s'adresse ce guide (et ce que vous apprendrez)
Ce guide s'adresse aux ingénieurs orientés produit, aux équipes données et aux responsables techniques qui veulent un modèle mental pratique de Kafka.
Vous apprendrez les blocs de construction essentiels (producteurs, consommateurs, topics, brokers), comment Kafka scale avec les partitions, comment il stocke et rejoue les événements, et où il s'insère dans une architecture pilotée par événements. Nous couvrirons aussi les cas d'usage courants, les garanties de livraison, les bases de la sécurité, la planification opérationnelle et quand Kafka est (ou n'est pas) l'outil adapté.
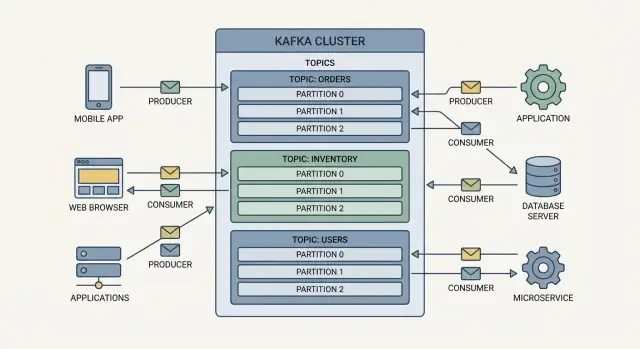
Concepts centraux : Producteurs, Consommateurs, Topics, Brokers
Kafka se comprend le plus facilement comme un log d'événements partagé : des applications y écrivent des événements, et d'autres applications les lisent plus tard — souvent en temps réel, parfois des heures ou des jours plus tard.
Producteurs et consommateurs
Producteurs = les écrivains. Un producteur peut publier un événement comme « commande passée », « paiement confirmé » ou « relevé de température ». Les producteurs n'envoient pas les événements directement à des applications spécifiques — ils les envoient à Kafka.
Consommateurs = les lecteurs. Un consommateur peut alimenter un tableau de bord, déclencher un workflow d'expédition ou charger des données dans l'analytics. Les consommateurs décident quoi faire des événements et peuvent lire à leur propre rythme.
Topics : organiser les événements
Les événements dans Kafka sont regroupés en topics, qui sont essentiellement des catégories nommées. Par exemple :
orders pour les événements liés aux commandespayments pour les événements de paiementinventory pour les changements de stock
Un topic devient le flux « source de vérité » pour ce type d'événement, ce qui facilite la réutilisation des mêmes données par plusieurs équipes sans créer des intégrations ad hoc.
Brokers et clusters
Un broker est un serveur Kafka qui stocke les événements et les sert aux consommateurs. En pratique, Kafka fonctionne comme un cluster (plusieurs brokers collaborant) pour gérer plus de trafic et continuer à fonctionner même si une machine tombe en panne.
Groupes de consommateurs : monter en charge sans dupliquer le travail
Les consommateurs s'exécutent souvent dans un groupe de consommateurs. Kafka répartit la lecture entre les membres du groupe, de sorte que vous pouvez ajouter des instances consommantes pour scaler le traitement — sans que chaque instance fasse le même travail.
Kafka scale en divisant le travail en topics (flux d'événements liés) puis en scindant chaque topic en partitions (tranches plus petites et indépendantes de ce flux).
Partitions = parallélisme et débit
Un topic avec une seule partition ne peut être lu que par un seul consommateur à la fois au sein d'un groupe de consommateurs. Ajoutez des partitions, et vous pouvez ajouter des consommateurs pour traiter les événements en parallèle. C'est ainsi que Kafka supporte des débits élevés pour le streaming d'événements et les pipelines de données temps réel sans transformer chaque système en goulot d'étranglement.
Les partitions aident aussi à répartir la charge sur plusieurs brokers. Plutôt qu'une seule machine qui gère toutes les écritures et lectures d'un topic, plusieurs brokers peuvent héberger différentes partitions et partager le trafic.
Ordre : ce que Kafka garantit (et ce qu'il ne garantit pas)
Kafka garantit l'ordre au sein d'une même partition. Si les événements A, B et C sont écrits dans cet ordre dans une partition, les consommateurs les liront A → B → C.
L'ordre entre partitions n'est pas garanti. Si vous avez besoin d'un ordre strict pour une entité spécifique (comme un client ou une commande), vous devez généralement faire en sorte que tous les événements de cette entité aillent dans la même partition.
Les clés décident où vont les événements
Lorsque les producteurs envoient un événement, ils peuvent inclure une clé (par exemple order_id). Kafka utilise la clé pour router de manière cohérente les événements liés vers la même partition. Cela vous donne un ordre prévisible pour cette clé tout en permettant au topic de se répartir sur de nombreuses partitions.
Les réplicas maintiennent la disponibilité des données
Chaque partition peut être répliquée sur d'autres brokers. Si un broker tombe, un autre broker ayant une réplique peut prendre le relais. La réplication est une des raisons pour lesquelles Kafka est adopté pour la messagerie pub-sub critique : elle améliore la disponibilité et la tolérance aux pannes sans que chaque application doive implémenter sa propre logique de basculement.
Stockage, rétention et rejouement des événements
Une idée clé dans Apache Kafka est que les événements ne sont pas juste transmis puis oubliés. Ils sont écrits sur disque dans un log ordonné, de sorte que les consommateurs peuvent les lire maintenant — ou plus tard. Cela rend Kafka utile non seulement pour déplacer des données, mais aussi pour garder un historique durable de ce qui s'est passé.
Les événements sont persistés, pas juste « en transit »
Quand un producteur envoie un événement à un topic, Kafka l'ajoute au stockage du broker. Les consommateurs lisent ensuite ce log stocké à leur propre rythme. Si un consommateur est hors ligne pendant une heure, les événements existent toujours et peuvent être traités lors de sa reprise.
Rétention : combien de temps Kafka conserve les données
Kafka conserve les événements selon des politiques de rétention :
- Rétention basée sur le temps : conserver les événements pendant une durée définie (par exemple 7 jours).
- Rétention basée sur la taille : conserver les événements jusqu'à ce que le log atteigne une taille configurée, puis supprimer les données les plus anciennes.
La rétention se configure par topic, ce qui permet de traiter différemment les topics « piste d'audit » des topics de télémétrie très volumineux.
Compaction : garder la dernière valeur par clé
Certains topics ressemblent plus à un changelog qu'à une archive historique — par exemple, « paramètres clients courants ». La compaction de log conserve au moins le dernier événement pour chaque clé, tandis que les anciens enregistrements peut-être remplacés. Vous obtenez ainsi une source de vérité durable pour l'état le plus récent, sans une croissance non maîtrisée.
Rejouer les événements : reconstruire l'état et récupérer d'un bug
Parce que les événements restent stockés, vous pouvez les rejouer pour reconstruire l'état :
- Reconstituer un index de recherche ou une vue matérialisée depuis zéro
- Récupérer un service après un déploiement défectueux en retraitant depuis un point antérieur
- Intégrer un nouveau consommateur et le laisser lire les données historiques
En pratique, le rejouement est contrôlé par le point de départ d'un consommateur (son offset), donnant aux équipes un filet de sécurité puissant lors de l'évolution des systèmes.
Fiabilité et bases de la tolérance aux pannes
Kafka est conçu pour maintenir le flux de données même lorsque certaines parties du système tombent en panne. Il y parvient grâce à la réplication, des règles claires sur qui est « en charge » d'une partition, et des accusés de réception configurables.
Réplication : leader et followers (niveau élevé)
Chaque partition de topic a un broker leader et un ou plusieurs followers répliques sur d'autres brokers. Les producteurs et consommateurs s'adressent au leader de la partition.
Les followers copient continuellement les données du leader. Si le leader tombe, Kafka peut promouvoir un follower à jour en tant que nouveau leader, de sorte que la partition reste disponible.
Que se passe-t-il lors d'une panne de broker (bref)
Si un broker échoue, les partitions dont il était leader deviennent indisponibles momentanément. Le contrôleur de Kafka détecte la panne et déclenche une élection de leader pour ces partitions.
Si au moins un follower répliqué est suffisamment à jour, il peut prendre la relève et les clients reprennent la production/consommation. Si aucune réplique en-synchro n'est disponible, Kafka peut suspendre les écritures (selon la configuration) pour éviter de perdre des données déjà reconnues.
Durabilité : acks et facteur de réplication
Deux réglages principaux influencent la durabilité :
- Facteur de réplication : combien de copies de chaque partition existent (par exemple 3 copies sur 3 brokers).
- Accusés de réception (acks) : quand le producteur considère une écriture comme réussie.
Conceptuellement :
- acks=0 : le producteur n'attend pas — rapide, mais risque de perte de messages.
- acks=1 : le leader confirme l'écriture — mieux, mais si le leader échoue avant que les followers n'aient copié, on peut perdre des messages récents.
- acks=all (ou -1) : le leader attend la confirmation des répliques « en-synchro » — plus sûr, généralement un peu plus lent.
Pour réduire les duplications lors des réessais, on combine souvent des acks plus sûrs avec des producteurs idempotents et une gestion robuste côté consommateur.
Latence vs sécurité
Plus de sécurité implique généralement d'attendre davantage de confirmations et de maintenir davantage de réplicas en synchro, ce qui peut ajouter de la latence et réduire le débit maximal.
Des réglages plus permissifs conviennent pour la télémétrie ou le clickstream où une perte occasionnelle est acceptable, alors que les paiements, l'inventaire et les logs d'audit justifient souvent une sécurité accrue.
Le rôle de Kafka dans une architecture pilotée par événements
Ajoutez un workflow DLQ
Créez une petite application pour gérer les messages empoisonnés et examiner les échecs sans bloquer les consommateurs.
L'architecture pilotée par événements (EDA) consiste à concevoir des systèmes où les faits métier — une commande passée, un paiement confirmé, un colis expédié — sont représentés par des événements que d'autres parties du système peuvent consommer et auxquels elles peuvent réagir.
Publier des événements, réagir avec des consommateurs
Kafka se place souvent au centre d'une EDA comme le « flux d'événements » partagé. Plutôt que le Service A n'appelle le Service B directement, le Service A publie un événement (par ex. OrderCreated) dans un topic Kafka. N'importe quel nombre d'autres services peuvent consommer cet événement et agir — envoyer un email, réserver du stock, lancer des contrôles anti-fraude — sans que le producteur ait à les connaître.
Couplage lâche (moins de dépendances directes)
Parce que les services communiquent via des événements, ils n'ont pas à coordonner des APIs request/response pour chaque interaction. Cela réduit le couplage entre équipes et facilite l'ajout de fonctionnalités : vous pouvez introduire un nouveau consommateur pour un événement existant sans changer le producteur.
Workflows asynchrones et résistance aux pics
L'EDA est naturellement asynchrone : les producteurs écrivent rapidement et les consommateurs traitent à leur rythme. Lors de pics de trafic, Kafka aide à tamponner la surcharge pour que les systèmes en aval ne tombent pas immédiatement. Les consommateurs peuvent monter en charge pour rattraper le retard, et si un consommateur tombe temporairement, il reprend depuis où il s'était arrêté.
Modèle mental pratique
Considérez Kafka comme le « fil d'activité » du système. Les producteurs publient des faits ; les consommateurs s'abonnent aux faits qui les intéressent. Ce modèle permet des pipelines de données temps réel et des workflows pilotés par événements tout en gardant les services plus simples et indépendants.
Cas d'utilisation courants de Kafka dans les systèmes modernes
Kafka apparaît lorsque les équipes doivent déplacer beaucoup de petits « faits qui sont arrivés » (événements) entre systèmes — rapidement, de manière fiable et de façon réutilisable par plusieurs consommateurs.
Suivi d'activité et logs d'audit
Les applications ont souvent besoin d'un historique append-only : connexions utilisateurs, changements de permissions, mises à jour d'enregistrements ou actions admin. Kafka fonctionne bien comme flux central pour ces événements, afin que les outils de sécurité, le reporting et les exports de conformité lisent la même source sans surcharger la base de production. Comme les événements sont conservés, on peut aussi les rejouer pour reconstruire une vue d'audit après un bug ou un changement de schéma.
Communication entre microservices via des événements
Plutôt que des appels directs, les services peuvent publier des événements comme « order created » ou « payment received ». D'autres services s'abonnent et réagissent à leur rythme. Cela réduit le couplage fort, aide à la résilience lors de pannes partielles et facilite l'ajout de capacités (par ex. contrôles anti-fraude) simplement en consommant le flux existant.
Pipelines de données vers l'analytics et les entrepôts
Kafka est souvent l'épine dorsale pour déplacer les données des systèmes opérationnels vers des plateformes analytiques. Les équipes peuvent streamer les changements depuis des bases applicatives et les livrer dans un entrepôt ou un lac avec une faible latence, en séparant les requêtes analytiques lourdes de l'application de production.
IoT et télémétrie avec trafic en rafale
Capteurs, appareils et télémétrie arrivent souvent en rafales. Kafka peut absorber ces pics, les tamponner en sécurité et laisser le traitement en aval rattraper le retard — utile pour la supervision, l'alerte et l'analyse à long terme.
Écosystème Kafka : Connect, Streams et outils
Kafka n'est pas que des brokers et des topics. La plupart des équipes s'appuient sur des outils complémentaires qui rendent Kafka pratique pour le déplacement quotidien de données, le traitement de flux et les opérations.
Kafka Connect : déplacer des données sans écrire de code
Kafka Connect est le framework d'intégration de Kafka pour faire entrer des données dans Kafka (sources) et hors de Kafka (sinks). Plutôt que de développer et maintenir des pipelines sur mesure, on exécute Connect et on configure des connecteurs.
Exemples courants : extraire des changements depuis des bases, ingérer des événements SaaS ou livrer des données Kafka vers un entrepôt ou un stockage objet. Connect standardise aussi les préoccupations opérationnelles comme les réessais, les offsets et le parallélisme.
Kafka Streams : traitement temps réel dans vos apps
Si Connect sert l'intégration, Kafka Streams sert le calcul. C'est une bibliothèque que vous ajoutez à votre application pour transformer des flux en temps réel — filtrer, enrichir, joindre des flux et construire des agrégats (par ex. « commandes par minute »).
Les applications Streams lisent des topics et écrivent dans des topics, s'intégrant naturellement aux systèmes pilotés par événements et pouvant monter en charge en ajoutant des instances.
Gestion des schémas : garder les événements cohérents
Quand plusieurs équipes publient des événements, la cohérence importe. La gestion des schémas (souvent via un schema registry) définit quels champs un événement doit contenir et comment ils évoluent. Cela évite des ruptures comme la renommée d'un champ dont dépend un consommateur.
Outils : surveiller ce qui compte
Kafka est sensible opérationnellement, donc la surveillance de base est essentielle :
- Lag des consommateurs : les consommateurs prennent-ils du retard ?
- Débit : combien d'événements par seconde circulent ?
- Erreurs : fetchs échoués, erreurs de production, échecs des tâches de connecteurs
La plupart des équipes utilisent aussi des UIs de gestion et de l'automatisation pour les déploiements, la configuration des topics et les politiques d'accès (voir /blog/kafka-security-governance).
Garanties de livraison et schémas de traitement
Planifiez votre pipeline Kafka
Cartographiez topics, clés, partitions et consommateurs avant d'écrire quoi que ce soit avec le mode de planification.
Kafka se décrit souvent comme « log durable + consommateurs », mais ce qui importe vraiment aux équipes est : vais-je traiter chaque événement une fois, et que se passe-t-il en cas d'échec ? Kafka fournit les blocs de construction ; c'est à vous de choisir les compromis.
Garanties de livraison (niveau élevé)
Au plus une fois : vous pouvez perdre des événements, mais vous ne traiterez pas de doublons. Cela se produit si un consommateur commit son offset puis tombe en panne avant d'avoir fini le travail.
Au moins une fois : vous ne perdrez pas d'événements, mais des duplications sont possibles (par ex. le consommateur traite un événement, plante, puis le retraitera au redémarrage). C'est le modèle par défaut le plus courant.
Exactement une fois vise à éviter à la fois la perte et les doublons de bout en bout. Dans Kafka, cela implique typiquement des producteurs transactionnels et un traitement compatible (souvent via Kafka Streams). C'est puissant, mais plus contraint et nécessite une configuration soignée.
Idempotence et déduplication
En pratique, beaucoup de systèmes adoptent l'au-moins-une-fois et ajoutent des protections :
- Écritures idempotentes : rendre l'application d'un événement sûre à répéter (ex. upserts, mises à jour conditionnelles, clés uniques).
- Déduplication : stocker un id d'événement (ou une clé métier) et ignorer les répétitions sur une fenêtre donnée.
Offsets consommateurs : votre « marque-page »
Un offset est la position du dernier enregistrement traité dans une partition. Quand vous committez un offset, vous dites « j'ai fini jusqu'ici ». Committer trop tôt risque des pertes ; trop tard augmente les duplications après panne.
Réessais et messages poison
Les réessais doivent être bornés et visibles. Un schéma courant :
- réessayer avec backoff pour les erreurs transitoires,
- puis envoyer l'enregistrement fautif dans un dead-letter topic pour inspection et rejouement.
Cela empêche qu'un message poison bloque un groupe entier tout en préservant les données pour correction ultérieure.
Sécurité et gouvernance
Kafka transporte souvent des événements critiques (commandes, paiements, activité utilisateur). La sécurité et la gouvernance doivent faire partie de la conception, pas être ajoutées après.
Authentification et autorisation
L'authentification répond à « qui êtes-vous ? » L'autorisation répond à « que pouvez-vous faire ? » Dans Kafka, l'authentification se fait couramment avec SASL (ex. SCRAM ou Kerberos), et l'autorisation via des ACLs au niveau des topics, groupes de consommateurs et du cluster.
Un modèle pratique : moindre privilège — les producteurs écrivent uniquement dans leurs topics, et les consommateurs lisent seulement les topics nécessaires. Cela réduit l'exposition accidentelle des données et limite la surface d'attaque si des identifiants sont compromis.
Chiffrement en transit (TLS)
TLS chiffre les données entre les applications, les brokers et les outils. Sans TLS, les événements peuvent être interceptés sur les réseaux internes comme sur Internet. TLS permet aussi de valider l'identité des brokers et d'éviter les attaques de type « man-in-the-middle ».
Kafka multi-tenant et conventions de nommage
Quand plusieurs équipes partagent un cluster, des garde-fous sont nécessaires. Des conventions claires de nommage de topics (par ex. <equipe>.<domaine>.<evenement>.<version>) rendent la propriété évidente et aident les outils à appliquer des politiques.
Associez le nommage à des quotas et à des modèles d'ACL afin qu'une charge bruyante ne prive pas les autres ressources, et que les nouveaux services démarrent avec des paramètres sûrs.
Considérez Kafka comme un système d'archive d'événements seulement si c'est intentionnel. Si les événements contiennent des données personnelles identifiables (PII), appliquez la minimisation des données (envoyer des identifiants plutôt que des profils complets), envisagez le chiffrement au niveau des champs et documentez quels topics sont sensibles.
Les réglages de rétention doivent correspondre aux exigences légales et métier. Si la politique exige « suppression après 30 jours », ne conservez pas 6 mois d'événements « au cas où ». Des revues et audits réguliers maintiennent la configuration alignée à mesure que le système évolue.
Exploitation de Kafka : ce que les équipes doivent prévoir
Créez rapidement une démo Kafka
Transformez votre modèle Kafka en une application producteur/consommateur fonctionnelle en une seule session guidée par chat.
Déployer Apache Kafka n'est pas un processus « installer et oublier ». Il fonctionne comme un service partagé : de nombreuses équipes en dépendent, et de petites erreurs peuvent impacter massivement les consommateurs.
Bases de la planification de capacité
La capacité Kafka est surtout un problème mathématique à réévaluer régulièrement. Les leviers principaux sont les partitions (parallélisme), le débit (Mo/s entrant et sortant) et la croissance du stockage (durée de rétention).
Si le trafic double, vous devrez peut-être ajouter des partitions pour répartir la charge, plus de disque pour la rétention et davantage de bande passante pour la réplication. Une bonne habitude est de prévoir le débit d'écriture maximal et de le multiplier par la rétention pour estimer la croissance du disque, puis d'ajouter une marge pour la réplication et le « succès inattendu ».
Tâches opérationnelles quotidiennes
Attendez-vous à du travail de routine au-delà du maintien des serveurs :
- Mises à jour : planifier des rolling upgrades, tester la compatibilité client et programmer les changements aux heures creuses.
- Rebalancements : les rebalances de groupes de consommateurs peuvent entraîner de brèves pauses ; adoptez des patterns de déploiement sûrs et une répartition claire des responsabilités.
- Gestion d'incidents : avoir des playbooks pour pannes de brokers, disques pleins et producteurs mal configurés qui inondent un topic.
Facteurs de coût et options de déploiement
Les coûts sont portés par les disques, la sortie réseau et le nombre/taille des brokers. Un Kafka managé réduit la charge d'exploitation et simplifie les mises à jour, tandis que l'auto-hébergement peut être moins coûteux à grande échelle si vous avez des opérateurs expérimentés. Le compromis porte sur le temps de reprise et la charge d'astreinte.
Que mesurer (pour ne pas deviner)
Les équipes surveillent typiquement :
- Latence bout en bout (production → consommation)
- Lag des consommateurs (à quel point ils sont en retard)
- Santé des brokers (utilisation disque, partitions sous-répliquées, taux d'erreurs de requêtes)
De bons tableaux de bord et des alertes transforment Kafka d'une « boîte noire » en un service compréhensible.
Quand utiliser Kafka (et quand s'en abstenir)
Kafka convient bien quand vous devez déplacer beaucoup d'événements de façon fiable, les conserver un temps et permettre à plusieurs systèmes de réagir au même flux à leur rythme. Il est particulièrement utile lorsque les données doivent être rejouables (backfills, audits, reconstruction d'un service) et lorsque vous attendez l'ajout progressif de producteurs/consommateurs.
Moments où Kafka brille
Kafka est efficace quand vous avez :
- Des flux à haut débit (clics, commandes, données de capteurs)
- De nombreux consommateurs ayant besoin des mêmes événements (analytics, monitoring, fraude, notifications)
- Le besoin de rejouabilité et d'un historique durable, pas seulement « livrer puis oublier »
- Des besoins d'intégration où découpler équipes et services est important
Quand Kafka peut être trop lourd
Kafka peut être excessif si vos besoins sont simples :
- Une file faible volume entre deux services
- Des tâches éphémères (jobs en arrière-plan) où le rejouement n'a pas de valeur
- Des équipes sans capacité d'exploiter et surveiller un système distribué
Dans ces cas, le surcoût opérationnel (dimensionnement du cluster, mises à jour, monitoring, astreinte) peut dépasser les bénéfices.
Alternatives et compléments
- RabbitMQ : excellent pour des files de travaux classiques et des patterns de routage.
- NATS : messagerie légère avec faible latence.
- Services pub/sub cloud : bien si vous voulez de l'infrastructure managée et des opérations simplifiées.
Kafka complète — il ne remplace pas — les bases de données (système de référence), les caches (lectures rapides) et les outils ETL batch (transformations périodiques importantes).
Checklist de décision rapide
Posez-vous :
- Avons-nous besoin de plusieurs consommateurs et du rejouement ?
- Le débit va-t-il croître significativement ?
- Avons-nous besoin de l'historique/ de la rétention comme fonctionnalité ?
- Pouvons-nous assurer la propriété opérationnelle (ou utiliser Kafka managé) ?
- Streamons-nous des événements, plutôt qu'envoyer des commandes/tâches ?
Si vous répondez « oui » à la plupart, Kafka est en général un bon choix.
Pour commencer : un chemin d'adoption simple
Kafka s'intègre le mieux quand vous avez besoin d'une « source de vérité » partagée pour des flux d'événements temps réel : de nombreux producteurs publiant des faits (commande créée, paiement autorisé, stock modifié) et de nombreux consommateurs utilisant ces faits pour alimenter des pipelines, de l'analytics et des fonctionnalités réactives.
Étape 1 : choisir un cas d'usage concret et limité
Commencez par un flux étroit et à forte valeur — par exemple publier des événements « OrderPlaced » pour les services aval (email, anti-fraude, fulfillment). Évitez de transformer Kafka en une file universelle dès le premier jour.
Étape 2 : définir vos événements et topics
Rédigez :
- Événements : ce qui s'est produit, en termes métiers clairs
- Topics : où vivent ces événements (souvent un topic par type d'événement ou domaine)
- Consommateurs : quelles équipes/services ont besoin des événements et pourquoi
Gardez les schémas initiaux simples et cohérents (timestamps, IDs, nom d'événement clair). Décidez si vous appliquerez des schémas dès le départ ou si vous les ferez évoluer prudemment.
Étape 3 : établir la propriété et les bases opérationnelles
Kafka réussit quand quelqu'un est responsable de :
- La création et la convention de nommage des topics
- Les politiques de rétention et d'accès
- Les responsabilités d'astreinte et les runbooks
Ajoutez la surveillance immédiatement (lag des consommateurs, santé des brokers, débit, taux d'erreurs). Si vous n'avez pas d'équipe plateforme, commencez par une offre managée et des limites claires.
Étape 4 : construire un pipeline « mince » d'abord
Produisez des événements depuis un système, consommez-les en un endroit et validez la boucle de bout en bout. Ensuite, étendez aux autres consommateurs, partitions et intégrations.
Si vous voulez prototyper rapidement l'application autour de Kafka (UI React, backend Go, PostgreSQL), des outils comme Koder.ai peuvent aider à générer l'application et ajouter des producteurs/consommateurs via un flux guidé. Ils sont utiles pour construire des tableaux de bord internes et des services légers qui consomment des topics, avec des fonctionnalités de mode planning, export de code, déploiement et snapshots avec rollback.
Si vous cartographiez cela dans une approche pilotée par événements, voyez /blog/event-driven-architecture. Pour estimer les coûts et les environnements, consultez /pricing.