Ce qu'est GraphQL (et ce qu'il n'est pas)
GraphQL est un langage de requête et un runtime pour les API. En bref : c'est un moyen pour une application (web, mobile ou un autre service) de demander des données à une API via une requête claire et structurée — et pour le serveur de renvoyer une réponse qui correspond à cette requête.
Le problème qu'il résout
Beaucoup d'API obligent les clients à accepter ce qu'un endpoint fixe retourne. Cela mène souvent à deux problèmes :
- Sur-récupération : télécharger des champs que vous n'utilisez pas.
- Sous-récupération : faire plusieurs requêtes pour assembler un seul écran.
Avec GraphQL, le client peut demander exactement les champs dont il a besoin, ni plus ni moins. C'est particulièrement utile quand différents écrans (ou différentes applis) ont besoin de « tranches » différentes des mêmes données sous-jacentes.
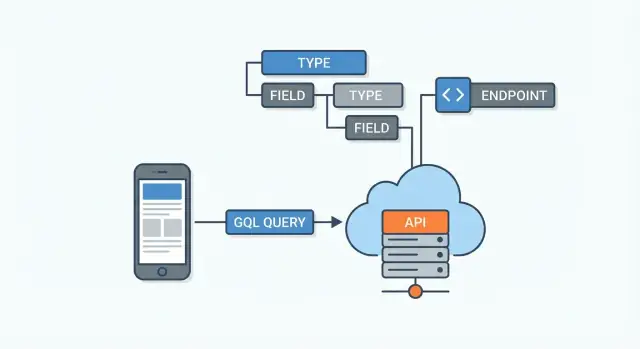
Où "vit" GraphQL
GraphQL se place généralement entre les applications clientes et vos sources de données. Ces sources peuvent être :
- des bases de données
- des services REST existants
- des APIs tierces
- des microservices
Le serveur GraphQL reçoit une requête, détermine comment récupérer chaque champ demandé depuis la bonne source, puis assemble la réponse JSON finale.
Un modèle mental rapide
Considérez GraphQL comme commander une réponse sur mesure :
- Le client décrit la forme des données qu'il veut.
- Le serveur renvoie des données dans cette forme exacte (quand c'est possible).
Ce que GraphQL n'est pas
GraphQL est souvent mal compris, donc quelques clarifications :
- Ce n'est pas une base de données (il ne stocke pas vos données).
- Ce n'est pas automatiquement plus rapide (il peut réduire le transfert inutile de données, mais le travail côté serveur compte toujours).
- Ce n'est pas le "REST 2.0" (c'est une approche alternative d'API avec des forces et des compromis différents).
Si vous retenez cette définition de base — langage de requête + runtime pour les API — vous aurez la bonne fondation pour la suite.
Pourquoi GraphQL a été créé
GraphQL a été créé pour résoudre un problème produit concret : les équipes passaient trop de temps à adapter les APIs aux écrans UI.
Les APIs traditionnelles basées sur des endpoints forcent souvent un choix entre envoyer des données inutiles ou faire des appels supplémentaires pour obtenir ce dont on a besoin. Avec la croissance des produits, cette friction se traduit par des pages plus lentes, un code client plus complexe et une coordination pénible entre frontend et backend.
Les points de douleur visés par GraphQL
La sur-récupération survient quand un endpoint retourne un objet « complet » alors qu'un écran n'a besoin que de quelques champs. Une vue de profil mobile peut n'avoir besoin que d'un nom et d'un avatar, mais l'API renvoie adresses, préférences, champs d'audit, etc. Cela gaspille de la bande passante et peut nuire à l'expérience.
La sous-récupération est l'inverse : aucun endpoint unique ne contient tout ce dont une vue a besoin, le client doit donc faire plusieurs requêtes et assembler les résultats. Cela ajoute de la latence et augmente le risque d'erreurs partielles.
Faire évoluer les APIs sans multiplier les versions
Beaucoup d'APIs REST réagissent au changement en ajoutant des endpoints ou des versions (v1, v2, v3). Le versioning peut être nécessaire, mais il crée une charge de maintenance : les vieux clients continuent d'utiliser d'anciennes versions tandis que les nouvelles fonctionnalités s'empilent ailleurs.
L'approche de GraphQL consiste à faire évoluer le schéma en ajoutant champs et types au fil du temps, tout en maintenant la stabilité des champs existants. Cela réduit souvent la pression de créer de « nouvelles versions » juste pour supporter de nouveaux besoins UI.
Une API, plusieurs clients
Les produits modernes ont rarement un unique consommateur. Web, iOS, Android et les intégrations partenaires ont tous besoin de formes de données différentes.
GraphQL a été conçu pour que chaque client puisse demander exactement les champs dont il a besoin — sans que le backend crée un endpoint séparé pour chaque écran ou appareil.
Le schéma GraphQL : le contrat de l'API
Une API GraphQL est définie par son schéma. Pensez-y comme l'accord entre le serveur et tous les clients : il liste quelles données existent, comment elles sont connectées et ce qu'il est possible de demander ou de modifier. Les clients ne devinent pas les endpoints — ils lisent le schéma et demandent des champs précis.
Bases du schéma : types, champs, relations
Le schéma est composé de types (comme User ou Post) et de champs (comme name ou title). Les champs peuvent pointer vers d'autres types, c'est ainsi que GraphQL modélise les relations.
Voici un exemple simple en SDL (Schema Definition Language) :
type User {
id: ID!
name: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
body: String
author: User!
comments: [Comment!]!
}
type Comment {
id: ID!
text: String!
author: User!
post: Post!
}
Typage fort = validation avant exécution
Parce que le schéma est fortement typé, GraphQL peut valider une requête avant de l'exécuter. Si un client demande un champ qui n'existe pas (par ex. Post.publishDate alors que le schéma n'a pas ce champ), le serveur peut refuser ou partiellement satisfaire la requête avec des erreurs claires — sans comportement ambigu.
Évoluer en toute sécurité
Les schémas sont pensés pour grandir. Vous pouvez généralement ajouter de nouveaux champs (par ex. User.bio) sans casser les clients existants, parce que les clients ne reçoivent que ce qu'ils demandent. Supprimer ou modifier des champs est plus délicat : les équipes déprécient souvent d'abord les champs et migrent les clients progressivement.
Requêtes : demander exactement ce dont vous avez besoin
Une API GraphQL est typiquement exposée via un endpoint unique (par exemple /graphql). Plutôt que d'avoir de nombreuses URLs pour différentes ressources (comme /users, /users/123, /users/123/posts), vous envoyez une query en un seul point et décrivez les données exactes que vous voulez.
Choisir les champs (y compris les données imbriquées)
Une requête est essentiellement une « liste de courses » de champs. Vous pouvez demander des champs simples (comme id et name) et aussi des données imbriquées (comme les posts récents d'un utilisateur) dans la même requête — sans télécharger des champs supplémentaires inutiles.
Voici un petit exemple :
query GetUserWithPosts {
user(id: "123") {
id
name
posts(limit: 2) {
id
title
}
}
}
Les réponses GraphQL sont prévisibles : le JSON renvoyé reflète la structure de votre requête. Cela facilite le travail côté frontend, car vous n'avez pas à deviner où apparaîtront les données ni à parser des formats différents.
Un exemple simplifié de réponse pourrait ressembler à :
{
"data": {
"user": {
"id": "123",
"name": "Sam",
"posts": [
{ "id": "p1", "title": "Hello GraphQL" },
{ "id": "p2", "title": "Queries in Practice" }
]
}
}
}
Si vous ne demandez pas un champ, il ne sera pas inclus. Si vous le demandez, vous pouvez vous attendre à le trouver à l'emplacement correspondant — ce qui fait des requêtes GraphQL un moyen propre de récupérer exactement ce dont chaque écran ou fonctionnalité a besoin.
Mutations : écrire des données en toute sécurité
Les queries servent à lire ; les mutations servent à modifier des données dans une API GraphQL — créer, mettre à jour ou supprimer des enregistrements.
Le flux typique d'une mutation
La plupart des mutations suivent le même schéma :
- Entrées : le client envoie un objet d'entrée structuré (souvent un type
input) contenant les champs à modifier.
- Validation & autorisation : le serveur vérifie les champs requis, les formats, l'unicité et si l'utilisateur est autorisé.
- Écriture : le serveur effectue la modification en base (ou appelle un autre service).
- Payload/type de retour : le serveur retourne un résultat prévisible pour que l'UI puisse se mettre à jour.
Pourquoi les mutations retournent des données
Les mutations GraphQL retournent généralement des données à dessein, plutôt que simplement "success: true". Retourner l'objet mis à jour (ou au moins son id et ses champs clés) aide l'UI à :
- mettre à jour l'écran immédiatement sans aller chercher à nouveau
- rafraîchir le cache en toute sécurité (utile avec des clients comme Apollo Client)
- afficher des erreurs au niveau des champs dans leur contexte
Un design courant est un type de "payload" qui inclut à la fois l'entité mise à jour et d'éventuelles erreurs.
Un exemple de mutation basique
mutation UpdateEmail($input: UpdateUserEmailInput!) {
updateUserEmail(input: $input) {
user {
id
email
}
errors {
field
message
}
}
}
Pour des APIs orientées UI, une bonne règle est : retourner ce dont vous avez besoin pour rendre l'état suivant (par ex. l'user mis à jour plus les errors). Cela simplifie le client, évite de deviner ce qui a changé et rend les échecs plus faciles à gérer.
Déployez votre app GraphQL
Passez d'une idée locale à une application hébergée sans jongler entre plusieurs outils.
Un schéma GraphQL décrit ce qu'on peut demander. Les résolveurs décrivent comment l'obtenir réellement. Un résolveur est une fonction attachée à un champ spécifique du schéma. Quand un client demande ce champ, GraphQL appelle le résolveur pour récupérer ou calculer la valeur.
Les résolveurs sont des fonctions "au niveau du champ"
GraphQL exécute une requête en parcourant la forme demandée. Pour chaque champ, il trouve le résolveur correspondant et l'exécute. Certains résolveurs retournent simplement une propriété d'un objet en mémoire ; d'autres appellent une base de données, un autre service, ou combinent plusieurs sources.
Par exemple, si votre schéma a User.posts, le résolveur posts peut interroger la table posts par userId, ou appeler un service Posts séparé.
Mapper les champs du schéma aux sources de données
Les résolveurs sont la colle entre le schéma et vos systèmes réels :
- Bases de données : requêtes SQL/NoSQL, procédures stockées, ORM
- Services : appels REST/gRPC, microservices internes, APIs tierces
- Champs calculés : totaux, formatage, valeurs dérivées
Ce mappage est flexible : vous pouvez changer l'implémentation backend sans modifier la forme des requêtes clients — tant que le schéma reste cohérent.
Parce que les résolveurs peuvent s'exécuter par champ et par élément d'une liste, il est facile de déclencher involontairement de nombreux petits appels (par ex. récupérer les posts pour 100 utilisateurs via 100 requêtes séparées). Ce pattern N+1 peut ralentir les réponses.
Les solutions courantes incluent le batching et le caching (par ex. regrouper les IDs et tout récupérer en une seule requête) et être intentionnel sur les champs imbriqués que vous incitez les clients à demander.
Où placer l'autorisation et la validation
L'autorisation s'applique souvent dans les résolveurs (ou via un middleware partagé) car les résolveurs connaissent qui fait la requête (via le context) et quelles données sont demandées. La validation se fait à deux niveaux : GraphQL gère la validation de type/forme automatiquement, tandis que les résolveurs appliquent les règles métiers (par ex. "seuls les admins peuvent définir ce champ").
Erreurs et résultats partiels
Une chose qui surprend les débutants est qu'une requête peut "réussir" tout en incluant des erreurs. C'est parce que GraphQL est orienté champ : si certains champs peuvent être résolus et d'autres non, vous pouvez obtenir des données partielles.
À quoi ressemblent les erreurs
Une réponse GraphQL typique peut contenir à la fois data et un tableau errors :
{
"data": {
"user": {
"id": "123",
"email": null
}
},
"errors": [
{
"message": "Not authorized to read email",
"path": ["user", "email"],
"extensions": { "code": "FORBIDDEN" }
}
]
}
C'est utile : le client peut toujours afficher ce qu'il a (par ex. le profil utilisateur) tout en gérant le champ manquant.
Erreurs au niveau du champ vs échecs globaux
- Erreurs au niveau du champ : surviennent pendant l'exécution (un résolveur lève une exception, un contrôle d'autorisation échoue, un service en aval timeoute). D'autres champs peuvent toujours se résoudre.
- Échecs au niveau de la requête : empêchent l'exécution (JSON invalide, requête malformée, erreurs de validation contre le schéma). Dans ces cas,
data est souvent null.
Rédigez des messages d'erreur pour l'utilisateur final, pas pour le débogage. Évitez d'exposer des traces de pile, des noms de base de données ou des IDs internes. Un bon schéma :
- Un
message court et sûr
- Un
extensions.code stable et lisible par machine
- Métadonnées optionnelles sûres (par ex.
retryable: true)
Consignez l'erreur détaillée côté serveur avec un ID de requête pour enquêter sans exposer les détails internes.
Conseils pour une gestion cohérente côté client
Définissez un petit « contrat » d'erreur partagé entre web et mobile : valeurs extensions.code communes (ex. UNAUTHENTICATED, FORBIDDEN, BAD_USER_INPUT), quand afficher un toast vs une erreur inline, et comment traiter les données partielles. La cohérence évite à chaque client d'inventer ses propres règles d'erreur.
Subscriptions pour les mises à jour en temps réel
Testez GraphQL sur une fonctionnalité
Validez GraphQL vs REST pour une fonctionnalité en construisant un petit MVP de bout en bout.
Les subscriptions sont la façon dont GraphQL pousse des données vers les clients lorsqu'elles changent, au lieu que le client interroge en permanence. Elles passent généralement par une connexion persistante (le plus souvent WebSockets), pour que le serveur envoie des événements dès qu'ils surviennent.
Une subscription ressemble beaucoup à une query, mais le résultat n'est pas unique : c'est un flux de résultats — chacun représentant un événement.
En pratique, un client "s'abonne" à un topic (par ex. messageAdded dans une application de chat). Quand le serveur publie un événement, les abonnés connectés reçoivent une payload correspondant à la sélection demandée par la subscription.
Cas d'usage courants
Les subscriptions excellent quand les utilisateurs attendent des changements instantanés :
- Messages de chat apparaissant dans une salle sans rafraîchir
- Notifications (mentions, changements de statut de commande, alertes)
- Dashboards en direct (santé système, logistique, trading, scores sportifs)
Subscriptions vs polling
Avec le polling, le client demande "Y a-t-il du nouveau ?" toutes les N secondes. C'est simple, mais cela peut gaspiller des requêtes (surtout quand rien ne change) et reste perçu comme moins réactif.
Avec les subscriptions, le serveur envoie l'update immédiatement. Cela réduit le trafic inutile et améliore la réactivité — au prix de connexions ouvertes et d'une infrastructure temps réel à gérer.
Quand les subscriptions sont une complexité inutile
Les subscriptions ne sont pas toujours nécessaires. Si les mises à jour sont rares, non critiques en temps réel ou faciles à regrouper, le polling (ou le refetch après action utilisateur) suffit souvent.
Elles ajoutent aussi une charge opérationnelle : montée en charge des connexions, auth sur sessions longue durée, retries et monitoring. Règle pratique : utilisez les subscriptions seulement lorsque le temps réel est une exigence produit, pas simplement un plus agréable.
Avantages, inconvénients et compromis pratiques
GraphQL est souvent décrit comme "donner du pouvoir au client", mais ce pouvoir a un coût. Connaître les compromis permet de décider quand GraphQL est adapté — et quand il serait excessif.
Quand GraphQL brille
Le plus grand avantage est la flexibilité de la récupération des données : les clients peuvent demander exactement les champs nécessaires, ce qui réduit la sur-récupération et accélère les itérations UI.
Un autre atout majeur est le contrat fort fourni par le schéma GraphQL. Le schéma devient une source unique de vérité pour les types et opérations disponibles, ce qui améliore la collaboration et les outils.
Les équipes constatent souvent une meilleure productivité côté client : les développeurs frontend itèrent sans attendre de nouveaux endpoints, et des outils comme Apollo Client peuvent générer des types et simplifier la récupération des données.
Inconvénients courants à anticiper
GraphQL peut rendre la mise en cache plus complexe. Avec REST, le caching est souvent "par URL". Avec GraphQL, beaucoup de requêtes partagent le même endpoint, donc le caching repose sur la forme des requêtes, des caches normalisés et une configuration soignée côté serveur/client.
Côté serveur, il existe des pièges de performance. Une requête apparemment légère peut déclencher de nombreux appels en cascade à moins de concevoir les résolveurs avec soin (batching, éviter les N+1, contrôler les champs coûteux).
Il y a aussi une courbe d'apprentissage : schémas, résolveurs et patterns clients peuvent être nouveaux pour des équipes habituées aux APIs par endpoint.
Sécurité et exploitation
Comme les clients peuvent demander beaucoup, les APIs GraphQL doivent appliquer des limites de profondeur et de complexité de requête pour prévenir les requêtes trop lourdes ou abusives.
L'authentification et l'autorisation doivent être appliquées par champ, pas seulement au niveau de la route, car différents champs peuvent avoir des règles d'accès différentes.
Opérationnellement, investissez dans le logging, le tracing et le monitoring adaptés à GraphQL : suivre les noms d'opération, les variables (avec prudence), les temps de résolveurs et les taux d'erreur pour repérer rapidement les requêtes lentes et les régressions.
GraphQL vs REST : en quoi diffèrent-ils ?
GraphQL et REST permettent tous deux aux applications de communiquer avec des serveurs, mais ils structurent cette conversation très différemment.
Le fonctionnement typique de REST
REST est basé sur les ressources. Vous récupérez des données en appelant plusieurs endpoints (URLs) qui représentent des "choses" comme /users/123 ou /orders?userId=123. Chaque endpoint retourne une forme de données fixe décidée par le serveur.
REST s'appuie aussi sur les sémantiques HTTP : méthodes GET/POST/PUT/DELETE, codes de statut et règles de cache. Cela peut rendre REST naturel pour du CRUD simple ou pour tirer parti des caches navigateur/proxy.
Le fonctionnement de GraphQL
GraphQL est basé sur un schéma. Au lieu de nombreux endpoints, vous avez généralement un endpoint, et le client envoie une requête décrivant les champs exacts qu'il veut. Le serveur valide cette requête contre le schéma GraphQL et renvoie une réponse correspondant à la forme demandée.
Cette sélection pilotée par le client est la raison pour laquelle GraphQL peut réduire la sur- et la sous-récupération, surtout pour des écrans UI qui demandent des données issues de plusieurs modèles liés.
Quand REST peut être plus simple
REST est souvent préférable quand :
- Vous gérez des téléchargements/téléversements de fichiers (streaming, types de contenu, requêtes range).
- Votre API est surtout du CRUD simple avec des payloads prévisibles.
- Vous comptez beaucoup sur le caching HTTP en périphérie et voulez une compatibilité maximale avec les outils existants.
Les approches hybrides sont courantes
Beaucoup d'équipes mixent les deux :
- Utiliser GraphQL pour la récupération de données orientée UI (écrans web/mobile).
- Conserver REST pour des services spécifiques comme callbacks d'auth, webhooks, gestion de fichiers ou endpoints internes de microservices.
La question pratique n'est pas "Lequel est meilleur ?" mais "Qu'est-ce qui convient à ce cas d'utilisation avec le moins de complexité ?".
Des types aux résolveurs
Décrivez types et relations, et laissez Koder.ai générer le schéma et le code des résolveurs.
Concevoir une API GraphQL est plus simple si vous la traitez comme un produit pour les auteurs d'écrans, pas comme un reflet de votre base de données. Commencez petit, validez avec des cas réels et étendez au fur et à mesure.
1) Partir des écrans UI (pas des tables)
Listez vos écrans clés (ex. « Liste produits », « Détails produit », « Paiement »). Pour chaque écran, notez les champs exacts dont il a besoin et les interactions qu'il supporte.
Cela aide à éviter les "god queries", réduit la sur-récupération et clarifie où vous aurez besoin de filtrage, tri et pagination.
2) Modéliser les types métier, puis ajouter les opérations progressivement
Définissez d'abord vos types cœur (ex. User, Product, Order) et leurs relations. Puis ajoutez :
- un petit ensemble de queries correspondant aux écrans réels
- un petit ensemble de mutations correspondant aux actions utilisateurs ("addToCart", "placeOrder")
Préférez des noms exprimant le langage métier plutôt que le nommage base de données. "placeOrder" communique mieux l'intention que "createOrderRecord".
Gardez un nommage cohérent : singulier pour un item (product), pluriel pour les collections (products). Pour la pagination, choisissez l'un :
- Basée sur un curseur : meilleure pour les listes changeantes et le "infinite scroll" (plus stable)
- Basée sur un offset : plus simple, mais peut sauter/dupliquer des éléments quand les données changent
Décidez tôt, car cela façonnera la structure de la réponse de votre API.
4) Documenter au fur et à mesure
GraphQL supporte les descriptions directement dans le schéma — utilisez-les pour les champs, arguments et cas limites. Ajoutez ensuite quelques exemples copiable-collable dans vos docs (pagination et scénarios d'erreur courants). Un schéma bien décrit rend l'introspection et les explorateurs d'API bien plus utiles.
Pour démarrer : outils, tests et prochaines étapes
Commencer avec GraphQL consiste surtout à choisir quelques outils bien supportés et à mettre en place un workflow fiable. Vous n'avez pas à tout adopter d'un coup : faites fonctionner une requête de bout en bout, puis élargissez.
Choisir un framework serveur
Choisissez un serveur selon votre stack et le niveau de fonctionnalités souhaité :
- Apollo Server : choix populaire avec un large écosystème et de bonnes docs.
- GraphQL Yoga : léger, bonnes valeurs par défaut modernes et bonne expérience développeur.
- NestJS : idéal si vous utilisez déjà Nest et voulez intégrer GraphQL avec ses modules, DI et patterns.
Une première étape pratique : définir un petit schéma (quelques types + une query), implémenter des résolveurs et connecter une source de données réelle (même une liste en mémoire simulée).
Si vous voulez passer plus vite de l'idée à une API fonctionnelle, une plateforme d'accélération comme Koder.ai peut vous aider à générer un petit app full-stack (React frontend, Go + PostgreSQL backend) et itérer sur schéma/resolvers via chat — puis exporter le code source quand vous voulez reprendre la main.
Choisir une approche client
Côté frontend, le choix dépend souvent de votre préférence entre convention et flexibilité :
- Apollo Client : largement utilisé, bon cache et outils de dev.
- Relay : patterns plus stricts, souvent pour les grandes applis voulant de la cohérence.
- urql : plus léger, composable, bon pour les équipes voulant du contrôle.
Si vous migrez depuis REST, commencez par utiliser GraphQL pour un écran ou une fonctionnalité, et conservez REST pour le reste jusqu'à ce que l'approche soit validée.
Tests : schéma + résolveurs + intégration
Traitez votre schéma comme un contrat d'API. Couches de tests utiles :
- Validation du schéma (construire le schéma en CI ; échouer tôt sur types invalides)
- Tests unitaires des résolveurs (moquer les sources de données et vérifier règles métier et auth)
- Tests d'intégration (exécuter des opérations GraphQL réelles contre un serveur de test et une base test)
Prochaines étapes
Pour approfondir :
- /blog/graphql-vs-rest
- /blog/graphql-schema-design