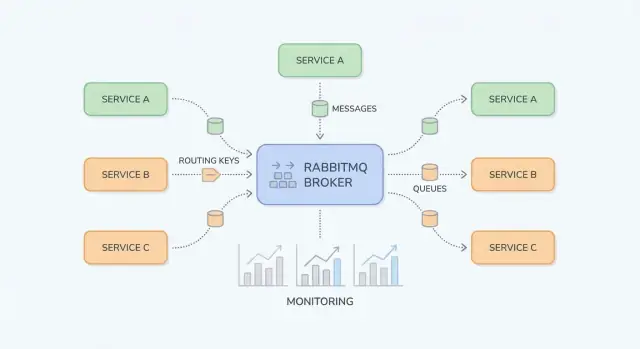
Pourquoi RabbitMQ compte pour les équipes applicatives
RabbitMQ est un broker de messages : il s'intercale entre des parties de votre système et déplace de façon fiable le « travail » (messages) des producteurs vers les consommateurs. Les équipes applicatives y recourent généralement lorsque des appels synchrones directs (HTTP service-à-service, bases de données partagées, cron) commencent à créer des dépendances fragiles, des charges inégales et des chaînes de panne difficiles à déboguer.
Quels problèmes RabbitMQ résout
Pics de trafic et charges inégales. Si votre application reçoit 10× plus d'inscriptions ou de commandes sur une courte période, tout traiter immédiatement peut submerger les services en aval. Avec RabbitMQ, les producteurs mettent rapidement des tâches en file et les consommateurs les traitent à un rythme contrôlé.
Couplage fort entre services. Quand le Service A doit appeler le Service B et attendre, les pannes et la latence se propagent. Le messaging découple : A publie un message et continue ; B le traite quand il est disponible.
Gestion des échecs plus sûre. Tous les échecs ne doivent pas devenir une erreur visible pour l'utilisateur. RabbitMQ vous aide à retenter le traitement en arrière-plan, isoler les messages « poison » et éviter de perdre du travail lors de pannes temporaires.
Résultats typiques observés par les équipes
Les équipes obtiennent généralement des charges plus lisses (buffer des pics), des services découplés (moins de dépendances à l'exécution) et des retries contrôlés (moins de retraitements manuels). Autre point important : il devient plus simple de comprendre où le travail est bloqué — chez le producteur, dans une queue ou chez le consommateur.
Ce que couvre ce guide (et ce qu’il ne couvre pas)
Ce guide se concentre sur RabbitMQ pragmatique pour les équipes applicatives : concepts de base, patterns courants (pub/sub, work queues, retries et dead-letter queues) et préoccupations opérationnelles (sécurité, montée en charge, observabilité, dépannage).
Il ne vise pas à être une spécification complète d'AMQP ni une plongée dans tous les plugins RabbitMQ. L'objectif est de vous aider à concevoir des flux de messages maintenables en production.
Petit glossaire
- Producteur : composant d'application qui envoie des messages.
- Consommateur : composant d'application qui reçoit et traite des messages.
- Queue : tampon qui contient les messages jusqu'à ce qu'un consommateur les traite.
- Exchange : point d'entrée qui route les messages vers une ou plusieurs queues.
- Routing key : étiquette utilisée par les exchanges pour décider où envoyer un message.
Bases de RabbitMQ : ce que c'est et quand l'utiliser
RabbitMQ est un broker de messages qui route des messages entre des parties de votre système, afin que les producteurs puissent déléguer du travail et que les consommateurs le traitent quand ils sont prêts.
Messaging AMQP vs appels HTTP directs
Avec un appel HTTP direct, le Service A envoie une requête au Service B et attend généralement une réponse. Si B est lent ou indisponible, A échoue ou patiente, et vous devez gérer timeouts, retries et backpressure dans chaque appelant.
Avec RabbitMQ (souvent via AMQP), le Service A publie un message au broker. RabbitMQ le stocke et le route vers la/les queue(s) appropriée(s), et le Service B le consomme de manière asynchrone. Le changement clé est que vous communiquez via une couche durable qui tamponne les pics et lisse les charges inégales.
Quand le messaging est adapté (et quand ce n’est pas le cas)
Le messaging est adapté quand vous :
- Voulez découpler équipes/services pour qu'ils déploient et scalent indépendamment.
- Avez du travail asynchrone (envoi d'email, génération de PDF, contrôles anti-fraude) sans bloquer une requête utilisateur.
- Attendez un trafic rafales et souhaitez absorber les pics avec des queues.
- Besoin d'une livraison fiable avec acks, retries et dead-letter queues.
Le messaging est mal adapté quand :
- Vous avez vraiment besoin d'une réponse immédiate pour servir la requête (ex. « ce mot de passe est-il valide ?»).
- Vous faites des lectures synchrones simples où un appel direct est plus clair et plus facile à déboguer.
- Vous n'avez pas de plan pour le versioning des messages, les retries et le monitoring — vous déplacerez la complexité au lieu de la réduire.
Request/response vs workflow asynchrone (exemple simple)
Synchrone (HTTP) :
Un service de checkout appelle un service de facturation via HTTP : « Create invoice. » L'utilisateur attend pendant que la facturation s'exécute. Si la facturation est lente ou indisponible, la latence du checkout augmente ; si elle est en panne, le checkout échoue.
Asynchrone (RabbitMQ) :
Le checkout publie invoice.requested avec l'ID de commande. L'utilisateur reçoit une confirmation immédiate que la commande a été reçue. La facturation consomme le message, génère la facture, puis publie invoice.created pour que l'email/les notifications s'en chargent. Chaque étape peut retenter indépendamment ; les pannes temporaires ne cassent pas automatiquement tout le flux.
Briques fondamentales : exchanges, queues et routage
RabbitMQ est plus simple à comprendre si vous séparez « où les messages sont publiés » de « où ils sont stockés ». Les producteurs publient vers des exchanges ; les exchanges routent vers des queues ; les consommateurs lisent des queues.
Un exchange ne stocke pas les messages. Il évalue des règles et transfère les messages vers une ou plusieurs queues.
- Direct exchange : route par correspondance exacte sur la routing key. À utiliser pour des destinations explicites (ex.
billing ou email).
- Topic exchange : route via des motifs dans les routing keys. À utiliser pour du pub/sub flexible et « s'abonner à une catégorie ».
- Fanout exchange : diffuse vers toutes les queues liées, en ignorant la routing key. À utiliser quand chaque consommateur doit recevoir chaque événement (ex. invalidation de cache).
- Headers exchange : route en fonction des headers du message plutôt que de la routing key. À réserver aux cas spéciaux (ex.
region=eu ET tier=premium) car c’est plus difficile à raisonner.
Une queue est l'endroit où les messages attendent qu'un consommateur les traite. Une queue peut avoir un ou plusieurs consommateurs (consommateurs concurrents) ; les messages sont typiquement délivrés à un consommateur à la fois.
Un binding relie un exchange à une queue et définit la règle de routage. Pensez-y comme : « Quand un message arrive sur l'exchange X avec la routing key Y, livre-le à la queue Q. » Vous pouvez binder plusieurs queues au même exchange (pub/sub) ou binder une même queue plusieurs fois pour différentes routing keys.
Routing keys et motifs (topic exchanges)
Pour les direct exchanges, le routage est exact. Pour les topic exchanges, les routing keys ressemblent à des mots séparés par des points, par exemple :
orders.createdorders.eu.refunded
Les bindings peuvent inclure des wildcards :
* correspond exactement à un mot (ex. orders.* correspond à orders.created)# correspond à zéro ou plusieurs mots (ex. orders.# correspond à orders.created et orders.eu.refunded)
Cela vous permet d'ajouter de nouveaux consommateurs sans changer les producteurs : créez une nouvelle queue et liez-la avec le pattern nécessaire.
Acknowledgements de message : ack, nack, requeue
Après livraison d'un message, le consommateur indique le résultat :
- ack : « Traitement réussi. » RabbitMQ supprime le message de la queue.
- nack (ou reject) : « Échec. » Vous pouvez choisir de le supprimer ou de le requeue.
- requeue : remet le message dans la queue pour une nouvelle tentative (souvent immédiate).
Attention au requeue : un message qui échoue systématiquement peut boucler indéfiniment et bloquer la queue. Beaucoup d'équipes associent les nacks à une stratégie de retry et une dead-letter queue (voir plus loin) pour gérer les échecs de façon prévisible.
Cas d'usage courants dans des applications réelles
RabbitMQ excelle lorsque vous devez déplacer du travail ou des notifications entre parties du système sans tout faire dépendre d'une étape lente. Voici des patterns pratiques rencontrés au quotidien.
Publish/subscribe de notifications (fanout/topic)
Lorsque plusieurs consommateurs doivent réagir au même événement — sans que l'éditeur sache qui ils sont — le pub/sub est adapté.
Exemple : lorsqu'un utilisateur met à jour son profil, vous pouvez notifier l'indexation de recherche, l'analytics et la synchronisation CRM en parallèle. Avec un fanout vous diffusez à toutes les queues liées ; avec un topic vous routez sélectivement (ex. user.updated, user.deleted). Cela évite le couplage fort et permet d'ajouter des abonnés sans modifier le producteur.
Work queues pour les jobs en arrière-plan
Si une tâche prend du temps, poussez-la dans une queue et laissez des workers la traiter de manière asynchrone :
- traitement d'images/vidéos
- envoi d'emails transactionnels
- génération de PDFs ou rapports
- import/export de données
Cela garde les requêtes web rapides et vous permet de scaler les workers indépendamment. La queue devient la « liste de choses à faire » et le nombre de workers devient le « bouton de débit ».
Intégration orientée événements entre services
Beaucoup de workflows traversent plusieurs services : order → billing → shipping. Plutôt que d'avoir un service appelant le suivant et bloquant, chaque service peut publier un événement après avoir terminé son étape. Les services en aval consomment ces événements et poursuivent le workflow.
Cela améliore la résilience (une panne temporaire du shipping ne casse pas le checkout) et clarifie la propriété : chaque service réagit aux événements qui l'intéressent.
Faire le pont avec des dépendances lentes ou peu fiables
RabbitMQ sert aussi de tampon entre votre appli et des dépendances lentes ou instables (API tierces, systèmes legacy, bases batch). Vous empilez les requêtes rapidement, puis les traitez avec des retries contrôlés. Si la dépendance est down, le travail s'accumule de façon sûre et se videra plus tard — au lieu de provoquer des timeouts sur toute l'application.
Si vous introduisez les queues progressivement, un petit « async outbox » ou une queue de background unique est souvent un bon premier pas (voir /blog/next-steps-rollout-plan).
Concevoir des flux de messages maintenables
Un déploiement RabbitMQ reste agréable à utiliser quand les routes sont prévisibles, les noms cohérents et les payloads évoluent sans casser les anciens consommateurs. Avant d'ajouter une queue, assurez-vous que l'histoire d'un message est claire : où il naît, comment il est routé et comment un coéquipier peut le déboguer de bout en bout.
Choisir l'exchange qui correspond à vos besoins de routage
Choisir le bon exchange réduit les bindings ad hoc et les fan-outs surprises :
- Direct exchange : quand une routing key mappe à une queue spécifique (ex.
billing.invoice.created).
- Topic exchange : pour du pub/sub flexible (ex.
billing.*.created, *.invoice.*). C'est le choix le plus courant pour un routage événementiel maintenable.
- Fanout exchange : quand chaque consommateur doit recevoir chaque message (rare pour des événements métier).
Règle pratique : si vous inventez une logique de routage complexe dans le code, elle appartient probablement à un topic exchange.
Bases de schéma de message : versioning et compatibilité
Traitez les corps de message comme des API publiques. Utilisez un versioning explicite (par ex. un champ racine schema_version: 2) et visez la compatibilité arrière :
- Ajoutez des champs ; ne renommez/supprimez pas.
- Préférez des champs optionnels avec des valeurs par défaut sûres.
- Si un changement cassant est inévitable, publiez un nouveau type de message / routing key plutôt que de modifier silencieusement l'ancien.
Ainsi, les anciens consommateurs continuent de fonctionner pendant que les nouveaux migrent à leur rythme.
Correlation IDs et trace IDs pour le debug cross-service
Facilitez le dépannage en standardisant les métadonnées :
correlation_id : lie des commandes/événements appartenant à la même action métier.trace_id (ou traceparent W3C) : relie les messages à la traçabilité distribuée entre HTTP et flux asynchrones.
Quand chaque éditeur renseigne ces champs de façon cohérente, vous pouvez suivre une transaction unique à travers plusieurs services sans deviner.
Conventions de nommage qui tiennent à l'échelle
Utilisez des noms prédictibles et recherchables. Un schéma courant :
- Exchanges :
<domaine>.<type> (ex. billing.events)
- Routing keys :
<domaine>.<entité>.<verbe> (ex. billing.invoice.created)
- Queues :
<service>.<but> (ex. reporting.invoice_created.worker)
La cohérence prime sur l'originalité : le futur vous (et la rota on-call) vous remerciera.
Patterns de fiabilité : retries, DLQ et idempotence
Modifiez en toute confiance
Expérimentez des modifications de routage et revenez en arrière rapidement si un binding ou un handler pose problème.
La messagerie fiable consiste surtout à planifier les pannes : les consommateurs plantent, les APIs en aval timeoutent, et certains événements sont mal formés. RabbitMQ donne les outils ; votre code doit coopérer.
Livraison au moins une fois (et ce que cela implique pour votre code)
Une configuration courante est la livraison au moins une fois : un message peut être livré plusieurs fois, mais il ne doit pas être perdu silencieusement. Cela arrive lorsque le consommateur reçoit un message, commence le travail puis échoue avant d'ack : RabbitMQ le requeue et le redélivre.
Conséquence pratique : les doublons sont normaux, donc votre handler doit supporter des exécutions multiples sans effet secondaire indésirable.
Stratégies d'idempotence pour les consommateurs
Idempotence : « traiter le même message deux fois a le même effet que le traiter une fois. » Approches utiles :
- Clés de déduplication : incluez un
message_id stable (ou une clé métier comme order_id + event_type + version) et stockez-le dans une table/cache « déjà traité » avec TTL.
- Mises à jour sûres : utilisez des écritures conditionnelles (ex. mise à jour seulement si le statut est toujours
PENDING) ou des contraintes d'unicité en base.
- Patterns outbox/inbox : persistez d'abord la réception de l'événement, puis traitez-le pour que les retries ne répètent pas des effets de bord.
Retries avec TTL + DLX/DLQ
Traitez les retries comme un flux séparé, pas comme une boucle serrée dans le consommateur.
Pattern courant :
- En cas d'échec transitoire, rejetez et routez vers une queue de retry avec un TTL.
- Quand le TTL expire, le message est dead-lettered vers la queue d'origine via un dead-letter exchange (DLX).
- Suivez le nombre de tentatives via un header (ou dans la routing key) et arrêtez après N essais.
Cela crée un backoff sans laisser les messages « stuck » comme non ackés.
Messages poison : quarantaine et rejouer
Certains messages ne réussiront jamais (schéma invalide, données référencées manquantes, bug de code). Détectez-les par :
- atteinte du nombre max de retries
- échecs répétés avec la même signature d'erreur
Routez-les vers une DLQ pour quarantaine. Traitez la DLQ comme une boîte opérationnelle : inspectez les payloads, corrigez le problème sous-jacent, puis rejouez manuellement les messages sélectionnés (idéalement via un outil/script contrôlé) plutôt que de tout repousser dans la queue principale.
Les limites de performance de RabbitMQ viennent souvent de quelques facteurs pratiques : gestion des connexions, vitesse de traitement des consommateurs, et usage des queues comme stockage. L'objectif est un débit stable sans accumulation croissante.
Connexions vs channels (réutilisation et limites)
Une erreur fréquente est d'ouvrir une nouvelle connexion TCP pour chaque éditeur ou consommateur. Les connexions sont plus coûteuses qu'on le pense (handshakes, heartbeats, TLS) : conservez-les et réutilisez-les.
Utilisez des channels pour multiplexeur le travail sur un nombre réduit de connexions. Règle pratique : peu de connexions, beaucoup de channels. Néanmoins, ne créez pas des milliers de channels sans raison — chaque channel a un coût et votre bibliothèque cliente peut imposer des limites. Préférez un petit pool de channels par service et réutilisez-les pour publier.
Prefetch et concurrence (débit sans surcharge)
Si les consommateurs récupèrent trop de messages à la fois, vous verrez des pics de mémoire, des temps de traitement longs et une latence inégale. Définissez une prefetch (QoS) pour que chaque consommateur n'ait qu'un nombre contrôlé de messages non ackés.
Guidance pratique :
- Pour des jobs lents (appels API, traitement fichiers), commencez avec une prefetch 1–10 par consommateur.
- Pour des handlers rapides et peu lourds CPU, augmentez la prefetch progressivement en surveillant le taux d'acks et les ressources hôtes.
- Scalez en ajoutant plus d'instances de consumers (ou threads) avant d'augmenter fortement la prefetch.
Taille des messages : garder les payloads légers
Les gros messages réduisent le débit et augmentent la pression mémoire (éditeurs, broker et consommateurs). Si votre payload est volumineux (documents, images, JSON large), stockez-le ailleurs (objet storage ou base) et envoyez seulement un ID + métadonnées via RabbitMQ.
Heuristique utile : visez des messages en kilooctets (KB), pas en mégaoctets (MB).
Backpressure : prévenir la croissance infinie des queues
La croissance des queues est un symptôme, pas une stratégie. Ajoutez du backpressure pour que les producteurs ralentissent quand les consommateurs n'arrivent pas à suivre :
- Limiter le travail consommateur : plafonnez la concurrence et ajustez la prefetch pour que le travail en vol reste prévisible.
- Détecter et réagir à la croissance : alertez sur la profondeur des queues et sur le rapport publish/ack.
- Élagage de charge : pour des événements non critiques, supprimer ou échantillonner les messages avant publication lors des pics.
Quand vous doutez, changez un seul paramètre à la fois et mesurez : taux de publication, taux d'ack, longueur des queues et latence bout en bout.
Checklist de sécurité pour les déploiements RabbitMQ
Déployez rapidement une file de travail
Démarrez des workers en arrière-plan avec des paramètres de prélecture et de concurrence que vous pouvez ajuster à mesure que vous montez en charge.
La sécurité RabbitMQ consiste surtout à durcir les « bords » : comment les clients se connectent, qui peut faire quoi et comment protéger les identifiants. Adaptez cette checklist à vos besoins de conformité.
Chiffrer les connexions avec TLS
- Activez TLS pour toutes les connexions clientes (AMQP over TLS sur 5671, ou le port choisi) et préférez des versions et suites de chiffrement modernes.
- Utilisez des certificats correspondant au nom d'hôte du broker que les clients contactent.
- Planifiez la rotation des certificats : suivez les dates d'expiration, automatisez le renouvellement si possible et répétez la procédure pour éviter une coupure lors d'une rotation.
- Si possible, validez aussi les clients via mTLS pour les services internes sensibles.
Authentification et autorisation
Les permissions RabbitMQ sont puissantes si vous les utilisez de manière cohérente.
- Créez des utilisateurs séparés pour chaque application (évitez les comptes "partagés").
- Utilisez des vhosts pour partitionner tenants ou systèmes (ex. un vhost par produit/équipe).
- Appliquez le principe du moindre privilège par vhost : configure (créer/modifier ressources), write (publier), read (consommer).
Séparer dev/staging/prod en toute sécurité
- Exécutez des clusters séparés par environnement si possible. Si l'infrastructure doit être partagée, isolez via des vhosts stricts et des identifiants séparés.
- Empêchez qu'une appli dev pointe sur un broker prod pour des tests via des politiques réseau et des noms DNS dédiés.
Gérer correctement les secrets dans les applications
- Ne codez pas d'identifiants en dur dans le code, dans des configs commités ou dans des images containers.
- Injectez les secrets au runtime via la plateforme (secrets Kubernetes, gestionnaire de secrets, variables CI chiffrées).
- Faites tourner les identifiants régulièrement et supprimez les utilisateurs inutilisés.
Pour le durcissement opérationnel (ports, firewalls, audit), gardez un runbook interne court et liez-le depuis /docs/security pour que les équipes suivent le même standard.
Monitoring et observabilité : quoi mesurer
Quand RabbitMQ déconne, les symptômes apparaissent souvent d'abord côté applicatif : endpoints lents, timeouts, mises à jour manquantes ou jobs qui « ne se terminent jamais ». Une bonne observabilité permet de confirmer si le broker est en cause, d'identifier le goulot (publisher, broker ou consumer) et d'agir avant que les utilisateurs ne remarquent.
Principales métriques du broker à suivre
Commencez par un petit jeu de signaux qui indique si les messages circulent :
- Profondeur des queues (messages ready + unacked) : une profondeur qui augmente indique que les consommateurs n'arrivent pas à suivre ou sont bloqués.
- Taux de publication et taux d'ack : la publication augmente tandis que les acks stagnent = backlog.
- Utilisation des consumers : sont-ils inactifs, saturés ou en redémarrage fréquent ? Croisez cela avec la prefetch et la concurrence.
- Redeliveries / requeues : indicateur fort d'erreurs de traitement, mauvaise politique de retry ou messages poison.
Signaux d'alerte pour attraper les incidents tôt
Alertez sur des tendances, pas seulement sur des seuils absolus.
- Backlog croissant pendant N minutes : la profondeur en hausse constante est plus exploitable que « depth > X ».
- Requeues/redeliveries répétées : indique une boucle d'échec qui consomme du CPU et bloque la queue.
- Churn de connexions et channels : des déconnexions fréquentes peuvent signifier des crashes d'app, des soucis réseau ou des heartbeats mal configurés.
- Unacked élevé longtemps : suggère des consumers bloqués ou des traitements trop longs.
Logs et traçage des messages en incident
Les logs du broker aident à distinguer « RabbitMQ est tombé » de « les clients l'utilisent mal ». Cherchez les échecs d'authentification, les connexions bloquées (resource alarms) et les erreurs de channel fréquentes. Côté application, assurez-vous que chaque tentative de traitement logge un correlation ID, le nom de la queue et l'issue (acked, rejected, retried).
Si vous utilisez du tracing distribué, propagez les headers de trace dans les propriétés du message pour relier « requête API → message publié → travail consommateur ».
Dashboards et runbooks internes
Construisez un dashboard par flux critique : taux de publication, taux d'ack, profondeur, unacked, requeues et nombre de consumers. Ajoutez des liens directs vers votre runbook interne, par ex. /docs/monitoring, et une checklist « quoi vérifier en premier » pour les on-call.
Dépannage des problèmes courants RabbitMQ
Quand quelque chose « cesse de bouger », résistez à l'envie de redémarrer en premier. La plupart des problèmes se révèlent en regardant (1) bindings et routage, (2) santé des consumers, et (3) alarms de ressources.
Messages non consommés
Si les éditeurs signalent « envoyé avec succès » mais que les queues restent vides (ou qu'une mauvaise queue se remplit), vérifiez le routage avant le code.
Commencez par l'UI Management :
- Vérifiez le type d'exchange et que la queue a le binding attendu.
- Confirmez que la routing key du producteur correspond au pattern du binding (surtout avec
topic).
- Assurez-vous que vous publiez sur le bon vhost.
Si la queue contient des messages mais que rien ne consomme :
- Un consommateur est-il connecté et abonné à la bonne queue ?
- Le consommateur n'est-il pas bloqué à cause d'une prefetch mal réglée ou d'un travail lent en aval ?
- Les acks ont-ils lieu (une augmentation de l'unacked signifie souvent que le consommateur n'ack pas ou est surchargé) ?
Doublons et messages hors d'ordre
Les doublons viennent souvent des retries (consumer planté après traitement mais avant ack), des interruptions réseau ou d'un requeue manuel. Mitigez par des handlers idempotents (dédup via message ID en base).
Un ordre hors séquence est attendu avec plusieurs consommateurs ou des requeues. Si l'ordre est crucial, utilisez un seul consommateur pour cette queue ou partitionnez par clé en plusieurs queues.
Alarms mémoire/disque
Les alarms signifient que RabbitMQ se protège :
- Disk alarm : libérez de l'espace disque, déplacez des logs ou augmentez le volume ; vérifiez ensuite que l'alarme s'efface.
- Memory alarm : réduisez les messages en vol (baissez prefetch, limitez la concurrence), et vérifiez la présence de messages surdimensionnés.
Rejouer en toute sécurité depuis une DLQ
Avant de rejouer, corrigez la cause racine pour éviter des boucles de poison. Requeuez par petits lots, ajoutez un plafond de retries et marquez les échecs avec du metadata (count, dernière erreur). Envisagez d'envoyer les messages rejoués vers une file séparée pour pouvoir interrompre rapidement si l'erreur se répète.
RabbitMQ vs alternatives : choisir le bon outil
Passez aux workflows asynchrones
Élaborez un workflow événementiel et gardez les services découplés sans chaînes HTTP complexes.
Choisir un outil de messaging, c'est trouver l'adéquation entre pattern de trafic, tolérance aux pannes et confort opérationnel.
Quand RabbitMQ est adapté
RabbitMQ brille quand vous avez besoin d'une livraison fiable des messages et d'un routage flexible entre composants applicatifs. C'est un bon choix pour les workflows asynchrones classiques — commandes, jobs en arrière-plan, fan-out notifications, patterns request/response — surtout si vous voulez :
- Ack par message et backpressure (les consommateurs lents ne font pas disparaître le travail)
- Routage riche (topics, headers, direct) sans le réimplémenter
- Montée en charge opérationnelle simple (ajoutez des consumers, ajustez la prefetch, gérez les queues)
Si votre objectif principal est de déplacer du travail plutôt que de conserver un long historique d'événements, RabbitMQ est souvent un choix par défaut confortable.
RabbitMQ vs systèmes de streaming genre Kafka
Kafka et similaires sont conçus pour le streaming haute performance et des logs d'événements longue durée. Choisissez un système de type Kafka quand vous avez besoin :
- de replayabilité (les consommateurs peuvent retraiter l'historique)
- un très haut débit avec scalabilité par partitions
- d'un flux unique comme « source de vérité » pour l'analytics et les services
En échange, les systèmes de type Kafka peuvent demander plus d'opérations et orienter vers des designs axés sur le débit (batching, stratégie de partition). RabbitMQ est souvent plus simple pour des débits faibles à modérés avec une latence finale plus basse et un routage sophistiqué.
Quand une queue simple suffit
Si vous avez une seule app qui produit des jobs et une pool de workers qui les consomme — et que vous vous contentez de sémantiques plus simples — une queue basée sur Redis (ou un service géré) peut suffire. Les équipes la dépassent typiquement quand elles ont besoin de garanties fortes de livraison, dead-lettering, multiples patterns de routage ou d'une séparation claire producteurs/consommateurs.
Considérations de migration si vos besoins changent
Concevez vos contrats de message comme si vous pouviez migrer plus tard :
- Gardez les schémas versionnés et compatibles arrière.
- Évitez les fonctionnalités spécifiques au broker dans les payloads (mettez le routage dans les headers/métadonnées, pas dans le corps).
- Construisez producteurs/consommateurs capables de fonctionner en parallèle pendant une migration.
Si vous avez besoin plus tard d'un flux ré-exécutable, vous pouvez souvent pontifier les événements RabbitMQ vers un système de logs tout en gardant RabbitMQ pour les workflows opérationnels. Pour un plan de déploiement pratique, voir /blog/rabbitmq-rollout-plan-and-checklist.
Prochaines étapes : plan de déploiement et checklist équipe
Le déploiement de RabbitMQ réussit mieux si vous le traitez comme un produit : démarrez petit, définissez la propriété et prouvez la fiabilité avant d'autoriser plus de services.
Checklist démarrage (adoption par un service)
Choisissez un workflow unique qui bénéficie de l'asynchronisme (ex. envoi d'emails, génération de rapports, sync vers une API tierce).
- Définissez le contrat de message : champs requis, version et ce que signifie « succès ».
- Créez un exchange + une queue avec une convention de noms claire.
- Réglez la concurrence consommateur et la prefetch pour ne pas surcharger les systèmes en aval.
- Ajoutez le comportement de retry (avec backoff) et une dead-letter queue dès le départ.
- Rendez les handlers idempotents (sécures à double exécution).
- Documentez les étapes opérationnelles « stop the bleeding » (pause consumer, vider la queue, rejouer la DLQ).
Si vous avez besoin d'un modèle de référence pour le nommage, les paliers de retry et les policies de base, centralisez-le dans /docs.
À mesure que vous implémentez ces patterns, standardisez le scaffolding entre équipes. Par exemple, des équipes utilisant Koder.ai génèrent souvent un squelette producteur/consommateur (noms, wiring retry/DLQ, headers trace/corrélation), puis exportent le code pour revue avant déploiement.
Propriété opérationnelle (rendre explicite)
RabbitMQ fonctionne quand « quelqu'un possède la queue ». Décidez-en avant la production :
- Qui surveille : typiquement l'équipe plateforme/SRE pour la santé du broker ; les équipes de service pour leurs queues et comportements consommateurs.
- Qui gère la DLQ : l'équipe de service on-call (avec chemin d'escalade clair).
- Runbooks : un runbook au niveau broker et un runbook par service pour chaque queue critique.
Si vous formalisez un support ou un hébergement managé, alignez les attentes tôt (voir /pricing) et définissez un contact pour incidents/onboarding via /contact.
Expériences suivantes (prouver avant d'étendre)
Exécutez de petits exercices limités dans le temps pour prendre confiance :
- Load test : validez le throughput, la concurrence des consumers et la latence sous conditions de pics.
- Drills de panne : tuez des consumers, simulez des redémarrages de broker, forcez de la latence réseau, vérifiez retries et comportement DLQ.
- Versioning de schéma : introduisez un message v2 pendant que des consommateurs v1 tournent encore ; vérifiez la compatibilité et le plan de déploiement.
Quand un service est stable pendant quelques semaines, reproduisez les mêmes patterns — ne les réinventez pas à chaque équipe.