Ce que le reporting SLA centralisé doit résoudre
Le reporting SLA centralisé existe parce que les preuves d'un SLA ne résident rarement en un seul endroit. La disponibilité peut se trouver dans un outil de monitoring, les incidents sur une page de statut, les tickets dans un helpdesk, et les notes d'escalade dans des emails ou chats. Quand chaque client utilise une pile légèrement différente (ou des conventions de nommage distinctes), le reporting mensuel devient un travail manuel sur tableur — et les débats sur « ce qui s'est réellement passé » deviennent fréquents.
Qui l'utilise (et ce dont ils ont besoin)
Une bonne application de reporting SLA sert plusieurs publics avec des objectifs différents :
- Les responsables de compte ont besoin de résumés prêts pour le client, fiables, et d'exports pour les QBR.
- Les responsables support et propriétaires de service ont besoin de drill‑downs pour valider les calculs et trouver les causes racines.
- Les parties prenantes clients ont besoin de métriques claires et lisibles avec des définitions sans ambiguïté — et d'un moyen d'auditer les incidents et tickets inclus.
L'application doit présenter la même vérité sous-jacente à différents niveaux de détail, selon le rôle.
Résultats principaux à viser
Un tableau de bord SLA centralisé doit fournir :
- Une source unique de vérité pour les métriques SLA, les incidents et les preuves associées.
- Un reporting plus rapide (minutes, pas jours) grâce à des calculs cohérents et des modèles réutilisables.
- Moins de disputes en montrant exactement comment chaque métrique a été calculée et quels événements y ont contribué.
En pratique, chaque chiffre SLA doit être traçable jusqu'aux événements bruts (alertes, tickets, chronologies d'incidents) avec horodatages et responsabilité.
Définir les limites : qu'est‑ce qui compte comme « SLA » ici
Avant de construire quoi que ce soit, définissez ce qui est dans le périmètre et hors périmètre. Par exemple :
- La « disponibilité » exclut‑elle les maintenances planifiées ?
- Les pannes tierces sont‑elles comptées ou rapportées séparément ?
- Quelle horloge est officielle : heure locale client, UTC, ou fuseau contractuel ?
Des limites claires évitent les débats ultérieurs et garantissent un reporting cohérent entre clients.
Flux de travail principaux que l'application doit supporter
Au minimum, le reporting SLA centralisé doit supporter cinq workflows :
- Consulter la performance SLA d'un client pour une période sélectionnée.
- Filtrer par client, service, région, contrat ou sévérité.
- Exporter (PDF/CSV) pour partager et archiver.
- Planifier l'envoi automatique de rapports aux parties prenantes.
- Auditer toute métrique jusqu'aux événements et règles qui la sous‑tendent.
Concevez autour de ces workflows dès le premier jour pour que le reste du système (modèle de données, intégrations et UX) reste aligné sur les besoins réels de reporting.
Définir les métriques SLA, règles et périodes de reporting
Avant de construire des écrans ou des pipelines, décidez ce que votre application mesurera et comment ces chiffres doivent être interprétés. L'objectif est la cohérence : deux personnes lisant le même rapport doivent arriver à la même conclusion.
Choisir les métriques SLA à supporter
Commencez par un petit ensemble que la plupart des clients reconnaissent :
- Disponibilité / uptime (ex. 99,9 % par mois)
- Temps de réponse (temps jusqu'à la première réponse humaine ou la première mise à jour significative)
- Temps de résolution (temps jusqu'à ce que le problème soit résolu et confirmé)
Soyez explicite sur ce que mesure chaque métrique et ce qu'elle n'est pas. Un panneau de définitions court dans l'UI (et un lien vers /help/sla-definitions) évite les malentendus.
Rédiger les règles de calcul en langage clair
Les règles sont souvent l'endroit où le reporting SLA casse. Documentez‑les en phrases que votre client pourrait valider, puis traduisez‑les en logique.
Couvrez l'essentiel :
- Heures ouvrées vs 24/7 : quel calendrier s'applique à chaque service/client ?
- Jours fériés : quel calendrier régional s'applique, et comment est‑il maintenu ?
- Exclusions : maintenance planifiée, délais causés par le client, attente client, pannes tierces
- Événements de démarrage/arrêt : quel horodatage démarre le chronomètre ; quel événement l'arrête
Décider des périodes de reporting et des seuils de violation
Choisissez des périodes par défaut (mensuel et trimestriel sont courants) et si vous supporterez des plages personnalisées. Clarifiez le fuseau horaire utilisé pour les coupures.
Pour les violations, définissez :
- Seuils par service (ex. l'objectif d'uptime varie selon le niveau)
- Dérogations par client (contrats personnalisés)
- Si les violations déclenchent sur incidents uniques, résultats agrégés, ou les deux
Documenter les sources de données par métrique
Pour chaque métrique, listez les entrées requises (événements de monitoring, enregistrements d'incidents, horodatages de tickets, fenêtres de maintenance). Cela devient votre plan pour les intégrations et les contrôles de qualité des données.
Cartographier vos sources de données et options d'intégration
Avant de concevoir tableaux de bord ou KPI, clarifiez où se trouvent réellement les preuves SLA. La plupart des équipes découvrent que leurs « données SLA » sont réparties entre des outils, détenues par des groupes différents, et enregistrées avec des significations légèrement différentes.
Systèmes sources courants à inventorier
Commencez par une liste simple par client (et par service) :
- Monitoring/observabilité (tests ping, monitors synthétiques, APM) : signaux d'uptime et horodatages
- Gestion des incidents (équivalents PagerDuty/Opsgenie) : cycle de vie de l'incident, sévérité, accusés de réception
- Ticketing/helpdesk (Jira Service Management, Zendesk, ServiceNow) : temps de réponse/résolution, champs d'impact client
- Pages de statut (publiques ou internes) : incidents déclarés et fenêtres de maintenance planifiée
- Logs cloud/fournisseur (optionnel) : santé des load balancers, trails d'audit pour pannes
Pour chaque système, notez le propriétaire, la période de rétention, les limites d'API, la résolution temporelle (secondes vs minutes), et si les données sont scellées au client ou partagées.
Choisir les méthodes d'intégration (et les combiner)
La plupart des apps de reporting SLA utilisent une combinaison :
- Appels API pour les backfills historiques et les réconciliations nocturnes
- Webhooks/flux d'événements pour des mises à jour quasi‑temps réel et une détection plus rapide des violations
- Imports CSV pour les petits clients, outils legacy, ou migrations ponctuelles
Règle pratique : utilisez webhooks quand la fraîcheur importe, et API pulls quand la complétude importe.
Différents outils décrivent la même chose différemment. Normalisez vers un petit ensemble d'événements sur lesquels votre application peut compter, tels que :
incident_opened / incident_closeddowntime_started / downtime_endedticket_created / first_response / resolved
Incluez des champs cohérents : client_id, service_id, source_system, external_id, severity, et des horodatages.
Fuseaux horaires et couverture manquante
Stockez tous les horodatages en UTC, et convertissez à l'affichage selon le fuseau horaire préféré du client (surtout pour les coupures de reporting mensuelles).
Prévoyez aussi les lacunes : certains clients n'auront pas de page de statut, certains services ne seront pas monitorés 24/7, et certains outils peuvent perdre des événements. Rendez la « couverture partielle » visible dans les rapports (ex. « données de monitoring indisponibles pendant 3 heures ») afin que les résultats SLA ne soient pas trompeurs.
Concevoir une architecture multi-client et multi‑tenant
Si votre application rapporte des SLA pour plusieurs clients, les choix d'architecture déterminent si vous pouvez monter en charge sans fuites de données entre clients.
Définir ce que « client » signifie dans votre système
Commencez par nommer les couches que vous devez supporter. Un « client » peut être :
- Tenant (entreprise/compte) : la frontière client principale
- Sous‑comptes : départements ou marques sous un même tenant
- Environnements : prod/stage/régions
- Services : API, application web, base de données, file d'attente support
Consignez‑les tôt, car elles affectent les permissions, les filtres et la manière dont vous stockez la configuration.
Choisir un modèle de multi‑tenancy
La plupart des applications de reporting SLA choisissent l'une des options :
- Base partagée + tenant IDs : un jeu de tables, chaque ligne taggée par
tenant_id. Rentable et plus simple à opérer, mais exige une discipline stricte des requêtes.
- Bases séparées par tenant : isolation renforcée et rétentions par tenant plus simples, mais overhead opérationnel plus élevé (migrations, monitoring, backups) et vues cross‑tenant plus difficiles.
Un compromis courant est une DB partagée pour la majorité des tenants et des DB dédiées pour les clients « enterprise ».
Appliquer une isolation stricte partout
L'isolation doit tenir sur :
- Requêtes et dashboards : scopez toujours par tenant, pas seulement par filtres UI
- Exports et emails planifiés : le job d'export doit s'exécuter avec un contexte tenant
- Jobs en arrière‑plan : les retries et queues doivent porter
tenant_id pour éviter d'écrire dans le mauvais tenant
Utilisez des garde‑fous comme la sécurité ligne par ligne, des scopes de requête obligatoires et des tests automatisés pour les frontières tenant.
Supporter des configurations SLA spécifiques au client
Des clients différents auront des objectifs et définitions distinctes. Prévoyez des réglages par tenant tels que :
- Cibles SLA (ex. 99,9 % uptime, 1h de réponse)
- Services et endpoints inclus
- Heures ouvrées, jours fériés et fuseaux
- Mappages de sévérité et règles d'exclusion (fenêtres de maintenance)
Changement de client sécurisé pour utilisateurs internes
Les utilisateurs internes doivent souvent « impersonifier » une vue client. Implémentez un changement délibéré (pas un filtre libre), affichez le tenant actif de manière proéminente, loggez les changements pour audit, et empêchez les liens qui contourneraient les contrôles tenant.
Construire un modèle de données pour événements bruts et résultats SLA
Une application de reporting SLA centralisée vit ou meurt par son modèle de données. Si vous ne modélisez que le « % SLA par mois », vous aurez du mal à expliquer les résultats, gérer les litiges ou modifier les calculs plus tard. Si vous ne modélisez que les événements bruts, le reporting devient lent et coûteux. L'objectif : supporter les deux — preuves brutes traçables et rollups prêts pour le client.
Entités principales à modéliser
Gardez une séparation claire entre qui est rapporté, quoi est mesuré et comment c'est calculé :
- Client : l'organisation recevant les rapports.
- Service : un système ou composant (API, site web, file d'attente support).
- Définition SLA : règles comme objectif d'uptime, cible de temps de réponse, heures ouvrées, exclusions et méthode de mesure.
- Incident / ticket : enregistrements suivis par l'humain (outils ITSM) qui peuvent expliquer un downtime ou des retards de réponse.
- Mesure / événement : événements machine (checks monitoring, changements de statut, signaux dérivés des logs).
Stocker événements bruts et résultats dérivés
Concevez des tables (ou collections) pour :
- Événements bruts : enregistrements immuables provenant des systèmes sources (alertes monitoring, incidents page de statut, transitions de tickets). Conservez les IDs originaux et des snapshots de payload quand possible.
- Faits normalisés : votre représentation standardisée (ex. « service_down started_at/ended_at »).
- Résultats SLA : sorties calculées à différents grains — par incident, journalier, hebdomadaire, mensuel.
- Rollups : totaux pré-agrégés (minutes d'indisponibilité, minutes valides, minutes exclues) pour rendre le tableau de bord rapide.
Versionner vos calculs
La logique SLA évolue : heures ouvrées modifiées, exclusions clarifiées, règles d'arrondi changent. Ajoutez un calculation_version (et idéalement une référence de « jeu de règles ») à chaque résultat calculé. Ainsi, d'anciens rapports peuvent être reproduits exactement après amélioration.
Champs d'audit pour confiance et dépannage
Incluez des champs d'audit là où ils comptent :
- source_system, source_record_id, et import_job_id
- horodatages comme ingested_at, normalized_at, calculated_at
- created_by/updated_by pour les modifications manuelles (avec un journal des changements)
Preuves et pièces jointes
Les clients demandent souvent « montrez pourquoi ». Prévoyez un schéma pour les preuves :
- liens vers postmortems, pages de statut ou fils de tickets
- métadonnées des pièces jointes (nom, type, clef de stockage)
- liaison des preuves aux incidents et aux périodes SLA spécifiques
Cette structure rend l'application explicable, reproductible et performante — sans perdre la preuve sous‑jacente.
Créer un pipeline de données fiable et une couche de normalisation
Conservez la pleine propriété du code
Exportez le code source pour que votre équipe puisse étendre la logique et prendre en main la stack.
Si vos entrées sont bruitées, votre tableau de bord SLA le sera aussi. Un pipeline fiable convertit les données d'incidents et tickets de multiples outils en résultats SLA cohérents et auditables — sans double comptage, lacunes ou échecs silencieux.
Scinder le pipeline en étapes claires
Traitez ingestion, normalisation et rollups comme des étapes séparées. Exécutez‑les en jobs d'arrière‑plan pour que l'UI reste rapide et que vous puissiez relancer sans risque.
- Jobs d'ingestion remontent les événements bruts (tickets, incidents, changements de statut) et les stockent inchangés.
- Jobs de normalisation standardisent les champs et les mapent à votre vocabulaire SLA.
- Jobs de rollup calculent les métriques journalières/hebdomadaires/mensuelles et mettent en cache les résultats pour tableaux de bord et exports.
Cette séparation aide aussi quand la source d'un client est en panne : l'ingestion peut échouer sans corrompre les calculs existants.
Rendre les retries sûrs avec l'idempotence
Les APIs externes expirent. Les webhooks peuvent être livrés deux fois. Votre pipeline doit être idempotent : re‑traiter la même entrée plusieurs fois ne doit pas changer le résultat.
Approches courantes :
- Utiliser un ID d'événement source (ou un hash des champs clés) comme clé unique.
- Conserver un registre de traitement (event_id + client + source + timestamp) pour détecter les doublons.
- Concevoir les rollups pour être reconstruisables sur une fenêtre temporelle (ex. « recompute last 14 days ») au lieu d'incrémenter aveuglément.
Normaliser les noms pour que les métriques valent la même chose
Entre clients et outils, « P1 », « Critique » et « Urgent » peuvent vouloir dire la même chose — ou pas. Construisez une couche de normalisation qui standardise :
- Noms de services (ex. « Payments API » vs « Payments »)
- Priorités / sévérités
- Statuts de tickets (ex. « Résolu » vs « Fait » vs « Fermé »)
Conservez la valeur originale et la valeur normalisée pour la traçabilité.
Valider les entrées et mettre en quarantaine les enregistrements suspects
Ajoutez des règles de validation (horodatages manquants, durées négatives, transitions de statut impossibles). Ne supprimez pas les données erronées silencieusement — routez‑les dans une file de quarantaine avec une raison et un workflow « corriger ou mapper ».
Afficher un indicateur de fraîcheur des données
Pour chaque client et source, calculez « dernière synchronisation réussie », « ancienneté du plus ancien événement non traité », et « rollup à jour jusqu'à ». Affichez ceci comme un indicateur simple de fraîcheur des données pour que les clients aient confiance et que votre équipe repère les problèmes tôt.
Authentification, rôles et contrôle d'accès
Si les clients utilisent votre portail pour revoir la performance SLA, l'authentification et les permissions doivent être conçues aussi soigneusement que les calculs SLA. L'objectif est simple : chaque utilisateur ne voit que ce qu'il doit voir — et vous pouvez le prouver plus tard.
Rôles qui correspondent aux workflows réels
Commencez avec un petit ensemble clair de rôles et étendez seulement si nécessaire :
- Admin : gère tenants/clients, intégrations, utilisateurs et paramètres globaux.
- Analyste interne : consulte toutes les données clients, enquête sur les incidents, construit des rapports, mais ne peut pas changer les paramètres de sécurité.
- Viewer client : accès en lecture seule à leurs dashboards et exports.
- Éditeur client : peut gérer les utilisateurs de son organisation, les préférences de notification et (optionnel) les modèles de rapport.
Favorisez le principe du moindre privilège : les nouveaux comptes commencent en mode viewer sauf promotion explicite.
SSO d'abord, mot de passe ensuite
Pour les équipes internes, le SSO réduit la prolifération de comptes et le risque lié aux départs. Supportez OIDC (Google Workspace/Azure AD/Okta) et, si nécessaire, SAML.
Pour les clients, proposez le SSO comme option premium, mais laissez un accès email/mot de passe avec MFA pour les petites organisations.
Isolation par client et contrôles fins
Appliquez les frontières tenant à tous les niveaux :
- Chaque requête et export doit être scoped à un client ID.
- Ajoutez des permissions projet/service si un client a plusieurs unités business.
- Restreignez l'accès aux artefacts sensibles (tickets bruts, notes, pièces jointes) séparément des résumés SLA.
Journaux d'audit et onboarding sécurisé
Loggez l'accès aux pages sensibles et aux téléchargements : qui a accédé à quoi, quand et d'où. Cela aide pour la conformité et la confiance client.
Construisez un flux d'onboarding où les admins ou éditeurs client peuvent inviter des utilisateurs, définir des rôles, exiger une vérification email et révoquer l'accès instantanément.
UX du tableau de bord : filtres, drill‑downs et définitions claires
Définissez les SLA avec le mode Planification
Définissez les locataires, services, métriques et règles avant de générer le code.
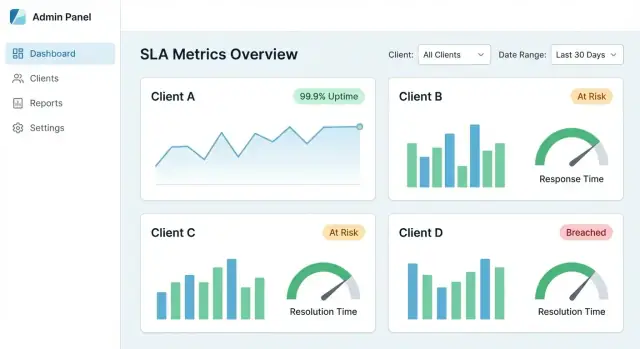
Un tableau de bord SLA centralisé réussit quand un client peut répondre à trois questions en moins d'une minute : Respectons‑nous les SLA ? Qu'est‑ce qui a changé ? Qu'est‑ce qui a causé les manquements ? Votre UX doit les guider d'une vue globale vers la preuve — sans les forcer à apprendre votre modèle de données interne.
La « vue principale » qui inspire confiance
Commencez par un petit ensemble de tuiles et graphiques qui correspondent aux conversations SLA courantes :
- Conformité SLA (%) pour la période sélectionnée (actuel vs précédent)
- Courbe de tendance (quotidienne/hebdo) pour montrer l'amélioration ou la dérive
- Principales violations classées par impact (minutes hors SLO, pénalités, utilisateurs affectés)
Faites chaque carte cliquable pour qu'elle devienne une porte vers le détail, pas une impasse.
Filtres qui paraissent prévisibles
Les filtres doivent être cohérents sur toutes les pages et « rester » lors de la navigation.
Valeurs par défaut recommandées :
- Client → Service → Environnement (prod/stage)
- Plage de dates avec choix rapides (7/30/90 derniers jours, Ce mois)
- Sévérité / priorité (utile quand on mélange incidents et tickets)
Affichez des chips de filtres actifs en haut pour que l'utilisateur comprenne toujours ce qu'il voit.
Drill‑down du résumé vers la preuve
Chaque métrique doit offrir un chemin vers le « pourquoi ». Un bon flux de drill‑down :
- Graphique de conformité → cliquer sur un point bas
- Liste des incidents/tickets contributeurs pour cette tranche
- Page de détail montrant horodatages, changements de statut, liens vers enregistrements sources et notes
Si un chiffre ne peut pas être expliqué par des preuves, il sera contesté — surtout en QBR.
Définitions claires (sans ambiguïté)
Ajoutez des tooltips ou un panneau d'info pour chaque KPI : comment il est calculé, exclusions, fuseau horaire, et fraîcheur des données. Incluez des exemples comme « fenêtres de maintenance exclues » ou « disponibilité mesurée au niveau du gateway API ».
Vues partageables avec liens stables
Rendez les vues filtrées partageables via des URLs stables (ex. /reports/sla?client=acme&service=api&range=30d). Cela transforme votre tableau de bord SLA centralisé en portail prêt pour le client qui supporte les points de contrôle récurrents et les pistes d'audit.
Rapports automatisés, exports et résumés prêts pour le client
Un tableau de bord SLA centralisé est utile au quotidien, mais les clients veulent souvent quelque chose à transmettre en interne : un PDF pour la direction, un CSV pour les analystes, et un lien à garder en favori.
Supportez trois sorties à partir des mêmes résultats SLA :
- PDF : résumé propre et brandé pour les décideurs
- CSV : données ligne par ligne (par service, région ou contrat) pour analyses approfondies
- Lien live : URL sécurisée vers la même vue dans votre portail, toujours à jour
Pour les rapports par lien, rendez les filtres explicites (plage, service, sévérité) afin que le client sache exactement ce que représentent les chiffres.
Livraison planifiée par client et cadence
Ajoutez la planification pour que chaque client reçoive automatiquement des rapports — hebdo, mensuel, trimestriel — envoyés à une liste client spécifique ou à une boîte partagée. Conservez les plannings scoped au tenant et auditables (qui l'a créé, dernier envoi, prochaine exécution).
Si vous voulez démarrer simplement, lancez avec un « résumé mensuel » plus un téléchargement en un clic depuis /reports.
Modèles prêts QBR/MBR
Construisez des templates qui se lisent comme des slides QBR/MBR sous forme écrite :
- Faits marquants (uptime, principales améliorations)
- Violations (ce qui s'est passé, durée, impact)
- Notes (maintenances planifiées, actions de suivi)
Les SLA réels incluent des exceptions (fenêtres de maintenance, pannes tierces). Permettez aux utilisateurs d'attacher des notes de conformité et de marquer des exceptions nécessitant approbation, avec une piste d'approbation.
Isolation tenant et permissions
Les exports doivent respecter l'isolation tenant et les permissions. Un utilisateur ne doit exporter que les clients, services et périodes qu'il est autorisé à voir — et l'export doit refléter exactement la vue du portail (pas de colonnes supplémentaires qui fuiraient des données cachées).
Alertes et notifications pour les violations SLA
Les alertes transforment une application de reporting SLA d'un « joli tableau » en un outil opérationnel. L'objectif n'est pas d'envoyer plus de messages — c'est d'aider les bonnes personnes à réagir tôt, documenter ce qui s'est passé et tenir les clients informés.
Choisir des types d'alertes qui correspondent aux modes de défaillance des SLA
Commencez par trois catégories :
- Violation imminente : vous êtes en tendance pour manquer l'objectif (ex. burn rate suggère que l'uptime tombera sous 99,9 % avant la fin de la période)
- Violation confirmée : le SLA est définitivement manqué pour la période définie
- Échec du pipeline de données : données manquantes, imports retardés, ou erreurs d'intégration qui peuvent invalider le reporting
Reliez chaque alerte à une définition claire (métrique, fenêtre temporelle, seuil, périmètre client) pour que les destinataires leur fassent confiance.
Choisir des canaux — et les rendre spécifiques au client
Proposez plusieurs options de livraison pour rencontrer les équipes là où elles travaillent déjà :
- Email pour les directions et équipes client-facing
- Slack / MS Teams pour l'on-call et les opérations
- Webhook pour déclencher des systèmes internes (PagerDuty, ServiceNow, outils incidents personnalisés)
Pour le reporting multi-client, routez les notifications en fonction de règles tenant (ex. « Violations Client A → Channel A ; violations internes → on-call »). Évitez d'envoyer des détails client‑spécifiques vers des channels partagés.
Réduire le bruit : déduplication, plages de silence et escalade
La fatigue d'alerte tue l'adoption. Implémentez :
- Déduplication (regrouper les déclenchements répétés en une alerte active)
- Plages de silence (retarder les notifications non urgentes hors heures ouvrées)
- Escalade (si non accusé de réception en X minutes, prévenir un groupe élargi)
Rendre les alertes actionnables avec accusé de réception et notes
Chaque alerte doit supporter :
- Accusé de réception (qui en est responsable)
- Notes de résolution (ce qui s'est passé, lien vers incident/ticket, résumé des communications client)
Cela crée une piste d'audit légère réutilisable dans les résumés clients.
Éditeur de règles simple par client
Fournissez un éditeur de règles basique pour les seuils et le routage par client (sans exposer une logique de requête complexe). Des garde‑fous aident : valeurs par défaut, validations, et aperçu (« cette règle aurait déclenché 3 fois le mois dernier »).
Créez des rapports prêts pour les clients
Générez des fichiers PDF et CSV à partir des mêmes résultats SLA affichés dans votre portail.
Une application de reporting SLA centralisée devient rapidement critique car les clients s'en servent pour juger la qualité de service. Cela rend la vitesse, la sécurité et les preuves (pour audits) aussi importantes que les graphiques eux‑mêmes.
Les grands clients peuvent générer des millions de tickets, incidents et événements monitoring. Pour garder des pages réactives :
- Pagination partout (tables, listes d'événements, vues détaillées). Évitez de charger tous les résultats par défaut.
- Cachez les requêtes communes comme « dernier mois d'uptime par service » ou « principales raisons de violation ». Un cache temporel (5–15 minutes) garde la donnée fraîche tout en réduisant la charge DB.
- Pré‑agrégez les résultats SLA pour les vues lourdes (résumés mensuels, uptime par service, compteurs de violations). Calculez‑les sur un planning ou après ingestion pour éviter de recalculer depuis les événements bruts à chaque page.
Rétention des données et archivage
Les événements bruts sont utiles pour les enquêtes, mais tout conserver augmente le coût et le risque.
Définissez des règles claires :
- Conserver les événements normalisés pour une période plus courte (ex. 90–180 jours).
- Conserver les résultats et résumés SLA plus longtemps (ex. 2–7 ans) pour le reporting de tendance et contrats.
- Archiver les anciens événements bruts vers un stockage moins coûteux (object storage ou cold tiers) avec un processus de récupération documenté.
Fondamentaux de sécurité attendus par les clients
Pour un portail de reporting client, présumez du contenu sensible : noms clients, horodatages, notes de tickets, et parfois des PII.
- Chiffrez les données en transit (HTTPS/TLS) et au repos (base et backups). Traitez les tokens d'API et identifiants d'intégration comme des secrets dans un vault ou service de gestion des secrets.
- Ajoutez limitation de débit et validation d'entrée sur les endpoints publics (login, exports, API). Cela réduit les abus, les surcharges accidentelles et les attaques d'injection courantes.
Même si vous ne visez pas une norme spécifique, de bonnes preuves opérationnelles renforcent la confiance.
Maintenez :
- Journaux d'audit immuables (logins, exports, changements de permissions, modifications d'intégration).
- Backups avec tests de restauration (pas seulement « on sauvegarde »). Planifiez des drills de restauration périodiques et consignez les résultats.
- Politiques de contrôle d'accès aux données : qui peut voir quoi, durée de conservation, et gestion des demandes de suppression.
Plan de lancement, monitoring et feuille de route d'itération
Lancer une application de reporting SLA consiste moins en une sortie massive qu'en prouver l'exactitude, puis monter en charge de façon répétable. Un plan de lancement solide réduit les litiges en rendant les résultats faciles à vérifier et à reproduire.
1) Démarrer avec un client pilote (valider l'exactitude)
Choisissez un client avec un ensemble gérable de services et de sources. Exécutez les calculs SLA de votre application en parallèle avec leurs tableurs actuels, exports de tickets ou rapports fournisseurs.
Concentrez‑vous sur les zones de divergence courantes :
- Fuseaux horaires et coupures de période (fin de mois)
- Ce qui compte comme downtime vs service dégradé
- Traitement des fenêtres de maintenance
Documentez les différences et décidez si l'application doit matcher l'approche actuelle du client ou la remplacer par une norme plus claire.
2) Opérationnaliser l'onboarding avec une checklist
Créez une checklist répétable pour que chaque onboarding client soit prévisible :
- Accès aux sources de données (API keys, scopes, allowlists IP)
- Règles de mapping (noms de services, catégories de tickets, sévérité d'incidents)
- Confirmation de la définition SLA (objectifs, exclusions, arrondis)
- Test run + validation (période d'échantillon, incidents connus)
- Assignation d'un propriétaire (qui approuve les changements)
Une checklist aide aussi à estimer l'effort et à structurer les discussions tarifaires sur /pricing.
3) Ajouter du monitoring pour la confiance et le support
Les dashboards SLA sont crédibles seulement s'ils sont frais et complets. Ajoutez du monitoring pour :
- Échecs et retries de jobs planifiés
- Erreurs de rate‑limit et d'authentification API
- Données obsolètes (aucun événement ingéré depuis X heures)
- Chutes/creux inattendus du volume d'incidents
Envoyez d'abord des alertes internes ; une fois stable, vous pouvez introduire des notes visibles côté client.
4) Itérer en fonction de la clarté, pas seulement des fonctionnalités
Recueillez des retours sur les points de confusion : définitions, litiges ("pourquoi est‑ce une violation ?"), et « ce qui a changé » depuis le mois dernier. Priorisez des petites améliorations UX : tooltips, journaux de changements, et notes d'exclusions claires.
5) Accélérer le développement avec un workflow moderne
Si vous voulez livrer un MVP interne rapidement (modèle tenant, intégrations, dashboards, exports) sans passer des semaines sur la plomberie, une approche de type « vibe‑coding » peut aider. Par exemple, Koder.ai permet aux équipes de concevoir et itérer une application multi‑tenant via chat — puis d'exporter le code source et de déployer. C'est adapté au reporting SLA, où la complexité centrale est les règles métiers et la normalisation des données plutôt que la scaffold UI.
Vous pouvez utiliser le mode planning de Koder.ai pour décrire les entités (tenants, services, définitions SLA, événements, rollups), puis générer une UI React et une base backend Go/PostgreSQL que vous étendez avec vos intégrations et la logique de calcul.
6) Publier une feuille de route courte
Conservez un document vivant avec les prochaines étapes : nouvelles intégrations, formats d'export, pistes d'audit. Liez‑le aux guides relatifs sur /blog pour que clients et collègues puissent s'auto‑servir.