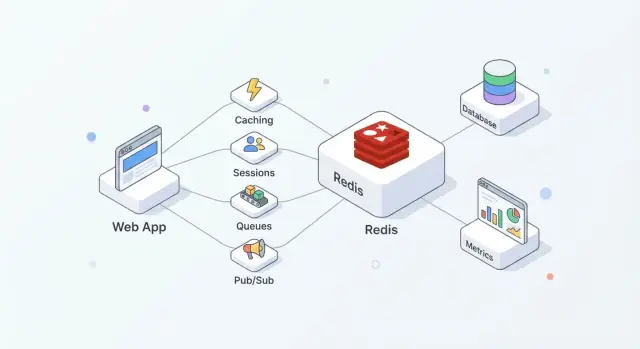
Ce que Redis apporte aux applications modernes
Redis est un magasin de données en mémoire souvent utilisé comme une « couche rapide » partagée pour les applications. Les équipes l'apprécient parce qu'il est simple à adopter, extrêmement rapide pour les opérations courantes, et suffisamment flexible pour remplir plusieurs rôles (cache, sessions, compteurs, files, pub/sub) sans introduire un nouveau système pour chaque besoin.
En pratique, Redis fonctionne mieux si vous le considérez comme vitesse + coordination, tandis que votre base principale reste la source de vérité.
Où s'intègre Redis dans une architecture typique
Une configuration courante ressemble à ceci :
- Base de données : données durables et faisant autorité (commandes, utilisateurs, factures)
- Redis : accès rapide et état éphémère partagé (pages en cache, tokens de session, compteurs de rate-limit)
- App : décide quoi stocker où et quand rafraîchir, invalider ou reconstruire
Cette séparation garde votre base concentrée sur la correction et la durabilité, tandis que Redis absorbe des lectures/écritures à haute fréquence qui augmenteraient la latence ou la charge.
Ce que Redis vous apporte habituellement
Bien utilisé, Redis tend à produire quelques résultats pratiques :
- Lectures plus rapides : servir des données souvent demandées depuis la mémoire au lieu d'interroger la base à chaque fois.
- Pics de trafic mieux gérés : le cache et des compteurs légers vous aident à survivre aux rafales sans que la base devienne le goulot d'étranglement.
- Coordination simplifiée : plusieurs serveurs applicatifs peuvent partager de l'état éphémère (sessions, verrous, clés de déduplication) plutôt que de recréer cette logique par instance.
Quand Redis n'est pas le bon outil
Redis ne remplace pas une base principale. Si vous avez besoin de requêtes complexes, d'une conservation longue durée ou d'analyses/reporting, la base reste le bon emplacement.
Également, ne supposez pas que Redis est « durable par défaut ». Si perdre même quelques secondes de données est inacceptable, vous aurez besoin de réglages de persistance soignés — ou d'un autre système — selon vos exigences de récupération.
Notions de base sur Redis à connaître avant de l'implémenter
On décrit souvent Redis comme un « key-value store », mais il est plus utile de le voir comme un serveur très rapide capable de conserver et manipuler de petits morceaux de données par nom (la clé). Ce modèle encourage des patterns d'accès prévisibles : vous savez typiquement ce que vous voulez (une session, une page en cache, un compteur) et Redis peut le récupérer ou le mettre à jour en un seul aller-retour.
Pourquoi c'est rapide : la mémoire d'abord
Redis conserve les données en RAM, d'où des réponses en microsecondes à faibles millisecondes. Le compromis est que la RAM est limitée et plus chère que le disque.
Décidez tôt si Redis est :
- uniquement une couche de performance (cache pur), ou
- une partie du chemin d'état (sessions, files), où le comportement au redémarrage et les réglages de persistance importent
Redis peut persister sur disque (snapshots RDB et/ou journaux AOF append-only), mais la persistance ajoute un surcoût d'écriture et impose des choix de durabilité (par ex. « rapide mais peut perdre une seconde » vs « plus lent mais plus sûr »). Traitez la persistance comme un réglage à adapter selon l'impact métier, pas comme une case cochée automatiquement.
Monothread ne veut pas dire lent
Redis exécute la plupart des commandes dans un seul thread, ce qui semble limitant jusqu'à ce que vous vous rappeliez deux choses : les opérations sont typiquement petites, et il n'y a pas de coût de verrou entre threads travailleurs. Tant que vous évitez les commandes chères et les charges utiles surdimensionnées, ce modèle peut être extrêmement efficace sous forte concurrence.
Clients, connexions et patterns de requêtes
Votre appli parle à Redis sur TCP via des bibliothèques clientes. Utilisez du pooling de connexions, gardez les requêtes petites et préférez le batching/pipelining lorsque vous avez plusieurs opérations.
Préparez des timeouts et des retries : Redis est rapide, mais les réseaux ne le sont pas, et votre application doit se dégrader gracieusement quand Redis est occupé ou temporairement indisponible.
Si vous créez un nouveau service et voulez standardiser ces bases rapidement, une plateforme comme Koder.ai peut vous aider à générer une application React + Go + PostgreSQL et ajouter ensuite des fonctionnalités basées sur Redis (cache, sessions, rate limiting) via un workflow guidé—tout en vous laissant exporter le code source et l'exécuter où vous le souhaitez.
Patterns de cache qui fonctionnent dans les vraies applis
Le cache n'aide que lorsqu'il a une propriété claire : qui le remplit, qui l'invalide, et ce que signifie une fraîcheur « suffisamment bonne ».
Le pattern cache-aside (par défaut pour la plupart des applis)
Cache-aside signifie que votre application — pas Redis — contrôle les lectures et écritures.
Flux typique :
- Lecture : chercher l'élément dans Redis.
- Hit : le retourner immédiatement.
- Miss : récupérer depuis la source primaire (base, API, service).
- Peupler : stocker le résultat dans Redis avec un TTL.
- Retourner : répondre à l'appelant.
Redis est un magasin clé-valeur rapide ; votre appli décide comment sérialiser, versionner et expirer les entrées.
TTLs : choisir l'expiration sans surprendre les utilisateurs
Un TTL est autant une décision produit que technique. Des TTL courts réduisent l'obsolescence mais augmentent la charge sur la base ; des TTL longs évitent du travail mais risquent de renvoyer des résultats périmés.
Conseils pratiques :
- Correspondre au rythme de rafraîchissement naturel des données (ex. prix vs photo de profil).
- Utiliser des clés versionnées pour les changements de schéma (ex.
user:v3:123) afin que d'anciens caches ne cassent pas le nouveau code.
- Gérer l'obsolescence intentionnellement : pour certaines vues, un petit décalage est acceptable ; pour d'autres (inventaire, auth), non.
Éviter le cache stampede
Quand une clé chaude expire, de nombreuses requêtes peuvent rater en même temps.
Défenses communes :
- Coalescence des requêtes : laisser une seule requête reconstruire la valeur pendant que les autres attendent ou servent l'ancienne valeur.
- Jitter sur le TTL : ajouter un petit aléa pour éviter que trop de clés n'expirent simultanément.
- Soft TTL : traiter une valeur comme « obsolète mais utilisable » brièvement pendant qu'un rafraîchissement en arrière-plan met à jour Redis.
Que mettre en cache (et quoi éviter)
Bons candidats : réponses d'API, résultats de requêtes coûteuses, et objets calculés (recommandations, agrégations). Mettre en cache des pages HTML complètes peut fonctionner, mais faites attention à la personnalisation et aux permissions — préférez le cache de fragments quand il y a de la logique spécifique à l'utilisateur.
Stockage de sessions et workflows d'authentification
Redis est un emplacement pratique pour l'état de connexion court : IDs de session, métadonnées de refresh-token, et flags « se souvenir de cet appareil ». L'objectif est d'accélérer l'authentification tout en gardant la durée de vie et la révocation des sessions sous contrôle strict.
Utiliser Redis pour les sessions utilisateur
Pattern courant : l'application émet un ID de session aléatoire, stocke un enregistrement compact dans Redis, et renvoie l'ID au navigateur en cookie HTTP-only. À chaque requête, vous recherchez la clé de session et attachez l'identité et les permissions à la requête.
Redis fonctionne bien ici car les lectures de session sont fréquentes et l'expiration des sessions est native.
Conception des clés et gestion des TTL
Concevez les clés pour faciliter l'inspection et la révocation :
sess:{sessionId} → payload de session (userId, issuedAt, deviceId)user:sessions:{userId} → Set d'IDs de sessions actives (optionnel, pour « déconnecter partout »)
Utilisez un TTL sur sess:{sessionId} qui correspond à la durée de la session. Si vous faites des rotations de sessions (recommandé), créez un nouvel ID et supprimez l'ancien immédiatement.
Faites attention au « sliding expiration » (étendre le TTL à chaque requête) : cela peut maintenir des sessions actives indéfiniment pour les utilisateurs fréquents. Un compromis plus sûr consiste à n'étendre le TTL que lorsqu'il est proche de son expiration.
Révocation et déconnexion multi-appareils
Pour déconnecter un appareil, supprimez sess:{sessionId}.
Pour déconnecter sur tous les appareils, soit :
- supprimez tous les IDs de session trouvés dans
user:sessions:{userId}, soit
- conservez un timestamp
user:revoked_after:{userId} et considérez toute session émise avant comme invalide
La méthode du timestamp évite des suppressions massives (fan-out).
Confidentialité et sécurité
Stockez le minimum nécessaire dans Redis — préférez des IDs aux données personnelles. Ne stockez jamais de mots de passe en clair ni de secrets longue durée. Si vous devez stocker des données liées à des tokens, stockez des hashes et utilisez des TTL serrés.
Limitez qui peut se connecter à Redis, exigez une authentification et gardez des IDs de session à haute entropie pour éviter les attaques par devinette.
Limitation de débit et prévention des abus
La limitation de débit (rate limiting) est un domaine où Redis excelle : rapide, partagé entre instances, et offrant des opérations atomiques qui gardent les compteurs cohérents sous fort trafic. Utile pour protéger les endpoints de connexion, les recherches coûteuses, les réinitialisations de mot de passe, et toute API susceptible d'être aspirée ou brute-forcée.
Modèles de limitation courants
Fenêtre fixe : simple (« 100 requêtes par minute »). Compte les requêtes dans le bucket minute courant. Facile, mais permet des rafales aux frontières temporelles.
Fenêtre glissante : lisse les frontières en regardant les dernières N secondes/minutes. Plus juste, mais coûte généralement plus en traitement (sorted sets ou plus de bookkeeping).
Token bucket : gère bien les rafales. Les utilisateurs « gagnent » des tokens avec le temps jusqu'à un plafond ; chaque requête dépense un token. Permet des rafales courtes tout en appliquant un taux moyen.
Briques sûres : INCR/EXPIRE et atomicité
Pattern fixe courant :
INCR key pour incrémenter un compteurEXPIRE key window_seconds pour définir/réinitialiser le TTL
Le piège est de le faire en deux appels séparés : un crash entre INCR et EXPIRE peut laisser des clés sans expiration.
Approches plus sûres :
- Utiliser un script Lua pour faire
INCR et définir EXPIRE seulement à la première création du compteur.
- Ou utiliser
SET key 1 EX <ttl> NX pour initialiser, puis INCR ensuite (souvent encapsulé dans un script pour éviter les courses).
L'atomicité est cruciale lors des pics : sans elle, deux requêtes peuvent voir le même quota restant et passer toutes les deux.
Portée : par utilisateur, par IP, par route (et rafales)
La plupart des applis ont besoin de plusieurs couches :
- Par utilisateur pour les appels authentifiés (
rl:user:{userId}:{route})
- Par IP pour les endpoints anonymes (tentatives de sign-in)
- Par route pour protéger les points chauds (search, exports)
Pour les endpoints rafales, token bucket (ou une fenêtre fixe généreuse plus une petite fenêtre de rafale) évite de pénaliser des pics légitimes comme le chargement d'une page.
Quand Redis est indisponible : fail-open vs fail-closed
Décidez à l'avance ce que signifie « sûr » :
- Fail-open : autoriser les requêtes si Redis est injoignable. Meilleure expérience et disponibilité, mais protection contre les abus affaiblie.
- Fail-closed : refuser les requêtes lorsque Redis est en panne. Protection renforcée, mais risque de rendre votre appli partiellement indisponible.
Compromis courant : fail-open pour les routes à faible risque et fail-closed pour les sensibles (connexion, reset de mot de passe, OTP), avec du monitoring pour détecter immédiatement la panne du rate limiting.
Files et jobs en arrière-plan avec Redis
Développez plus vite avec Redis
Créez une application prête pour Redis depuis le chat, puis exportez le code une fois satisfait.
Redis peut alimenter des jobs en arrière-plan pour envoyer des e-mails, redimensionner des images, synchroniser des données ou exécuter des tâches périodiques. L'important est de choisir la bonne structure et de définir des règles claires pour les retries et la gestion des échecs.
Lists, sorted sets et streams : pourquoi choisir l'un plutôt que l'autre
Lists : les plus simples — producteurs LPUSH, workers BRPOP. Faciles, mais vous devrez ajouter la logique pour les jobs « in-flight », les retries et les visibility timeouts.
Sorted sets : excellents quand la planification importe. Utilisez le score comme timestamp (ou priorité) et les workers récupèrent le job suivant dû. Idéal pour tâches différées et priorités.
Streams : souvent le meilleur choix par défaut pour une distribution de travail durable. Ils supportent les consumer groups, conservent un historique et permettent à plusieurs workers de coordonner sans inventer votre propre liste de traitement.
Accusés, retries et dead-letter
Avec les consumer groups Streams, un worker lit un message puis l'ACK. Si un worker plante, le message reste pending et peut être réclamé par un autre worker.
Pour les retries, suivez le nombre de tentatives (dans le payload du message ou dans une clé annexe) et appliquez un backoff exponentiel (souvent via un sorted set de « schedule »). Après un nombre max d'essais, déplacez le job vers une dead-letter queue (autre stream ou liste) pour revue manuelle.
Stratégies d'idempotence pour les workers
Partons du principe qu'un job peut s'exécuter deux fois. Rendez les handlers idempotents en :
- Utilisant une clé d'idempotence (ex.
job:{id}:done) avec SET ... NX avant tout effet de bord
- Concevant les opérations comme des upserts plutôt que des créations aveugles
- Enregistrant les IDs de requête externes lors d'appels à des API tierces
Garder les jobs petits et appliquer du backpressure
Gardez les payloads réduits (stockez les gros fichiers ailleurs et passez des références). Ajoutez du backpressure en limitant la longueur des files, en ralentissant les producteurs quand le backlog augmente, et en scaleant les workers en fonction de la profondeur en attente et du temps de traitement.
Pub/Sub et distribution d'événements
Redis Pub/Sub est le moyen le plus simple de diffuser des événements : un éditeur envoie sur un canal, et chaque abonné connecté reçoit immédiatement le message. Pas de polling — juste un push léger qui convient aux mises à jour temps réel.
Cas d'usage adaptés à Pub/Sub
Pub/Sub est adapté quand la rapidité et le fan-out priment sur la livraison garantie :
- notifications côté utilisateur ("votre rapport est prêt")
- mises à jour UI en direct (présence, indicateurs de saisie, dashboards)
- fan-out interne d'événements (un événement déclenche plusieurs services)
Modèle mental utile : Pub/Sub, c'est comme une station de radio. Quiconque est à l'écoute entend la diffusion, mais personne n'obtient d'enregistrement automatiquement.
Limites clés à anticiper
Pub/Sub a des compromis importants :
- Pas de persistance : si personne n'écoute au moment de la publication, le message est perdu.
- Fiabilité des abonnés : une déconnexion ou une surcharge peut faire manquer des messages.
- Pas de replay ni d'ack : impossible de demander la redelivery jusqu'à confirmation.
Pour ces raisons, Pub/Sub n'est pas adapté aux workflows où chaque événement doit être traité.
Quand préférer Redis Streams
Si vous avez besoin de durabilité, retries, consumer groups ou gestion du backpressure, les Streams sont généralement un meilleur choix. Ils permettent de stocker les événements, les traiter avec accusés et récupérer après redémarrage — bien plus proche d'une file légère durable.
Patterns pour applications multi-instance
En production vous aurez plusieurs instances abonnées. Conseils pratiques :
- Namespacer les canaux pour éviter les collisions :
app:{env}:{domain}:{event} (ex. shop:prod:orders:created).
- Séparer broadcast et canaux ciblés : broadcast sur
notifications:global, et ciblez les utilisateurs avec notifications:user:{id}.
- Garder les payloads petits et auto-suffisants : inclure un ID et des métadonnées minimales ; récupérer les détails ailleurs seulement si nécessaire.
De cette façon, Pub/Sub sert de signal rapide, tandis que Streams (ou une autre queue) gère les événements critiques.
Choisir les bonnes structures de données Redis
Transformez les patterns en produit
Allez au-delà d'une démo et construisez une véritable intégration Redis que votre équipe pourra étendre.
Le choix d'une structure n'affecte pas que le fonctionnement : il influence l'utilisation mémoire, la vitesse des requêtes et la simplicité du code à long terme. Règle simple : choisissez la structure qui correspond aux questions que vous poserez plus tard (patterns de lecture), pas seulement à la façon de stocker aujourd'hui.
Guide rapide de sélection (strings, hashes, sets, sorted sets)
- Strings : pour une seule valeur (blob JSON, feature flag, HTML en cache). Idéal pour les compteurs atomiques avec
INCR/DECR.
- Hashes : pour « un objet avec des champs » (champs de profil, totaux de panier). Pratique quand on met souvent à jour des propriétés individuelles.
- Sets : unicité et tests d'appartenance (l'utilisateur a-t-il déjà réclamé le coupon X ?). Opérations rapides
SISMEMBER et opérations d'ensemble faciles.
- Sorted sets (ZSETs) : classement et requêtes « top N » (leaderboards, listes de priorité, score temporel).
Mises à jour atomiques, compteurs et leaderboards
Les opérations Redis sont atomiques au niveau commande, vous pouvez donc incrémenter des compteurs sans conditions de course. Pages vues et compteurs de rate-limit utilisent typiquement des strings avec INCR plus une expiry.
Les leaderboards tirent parti des sorted sets : ZINCRBY pour mettre à jour des scores et ZREVRANGE pour obtenir les meilleurs joueurs efficacement.
Utiliser les hashes pour réduire le nombre de clés
Créer beaucoup de clés petites (user:123:name, user:123:email) augmente l'overhead par clé et complique la gestion. Un hash user:123 avec des champs (name, email, plan) garde les données liées ensemble et réduit souvent le nombre de clés. Il rend aussi les mises à jour partielles plus simples (modifier un champ sans réécrire un JSON entier).
Considérations mémoire qui affectent le coût
- Beaucoup de petites clés peuvent coûter plus de mémoire que prévu à cause de l'overhead par clé.
- Les hashes sont souvent plus économes pour des objets petits à moyens sous une même clé.
- Les sorted sets sont puissants mais plus lourds que sets/strings : utilisez-les quand le classement ou les requêtes basées sur un score sont réellement nécessaires.
En cas de doute, modélisez un petit échantillon et mesurez l'usage mémoire avant de vous engager pour des données à fort volume.
Persistance, réplication et sécurité des données
On décrit souvent Redis comme « en mémoire », mais vous avez des choix sur ce qui arrive lors d'un redémarrage, d'un disque plein ou d'un serveur disparu. Le bon paramétrage dépend de la quantité de données que vous pouvez vous permettre de perdre et de la rapidité de récupération souhaitée.
RDB vs AOF : ce que chacun apporte
RDB snapshots sauvegardent un dump ponctuel du dataset. Ils sont compacts et rapides à charger au démarrage, ce qui accélère le redémarrage. Inconvénient : perte possible des écritures récentes depuis le dernier snapshot.
AOF (append-only file) journalise les opérations d'écriture au fur et à mesure. Cela réduit typiquement la perte potentielle de données car les changements sont enregistrés plus continuellement. Les fichiers AOF peuvent grossir et les replays au démarrage peuvent prendre plus de temps — Redis peut toutefois réécrire/compacter l'AOF.
Beaucoup d'équipes exécutent les deux : snapshots pour des redémarrages rapides et AOF pour une meilleure durabilité des écritures.
La persistance n'est pas gratuite. Les écritures disque, les politiques fsync AOF et les opérations de rewrite en arrière-plan peuvent provoquer des pics de latence si le stockage est lent ou saturé. En revanche, la persistance rend les redémarrages moins inquiétants : sans persistance, un redémarrage imprévu signifie un Redis vide.
Réplication et objectifs de basculement
La réplication conserve des copies sur des replicas pour pouvoir basculer si le primaire tombe. L'objectif est généralement disponibilité avant tout, pas cohérence parfaite. En cas de panne, les replicas peuvent être légèrement en retard et un basculement peut perdre les dernières écritures confirmées dans certains scénarios.
Définissez votre perte acceptable et votre temps de récupération
Avant d'ajuster quoi que ce soit, notez deux chiffres :
- RPO (Recovery Point Objective) : « Nous pouvons perdre jusqu'à X secondes/minutes de données. »
- RTO (Recovery Time Objective) : « Nous devons revenir en Y secondes/minutes. »
Utilisez ces cibles pour choisir la fréquence des RDB, les réglages AOF et si vous avez besoin de replicas (et d'un basculement automatisé) selon le rôle de Redis — cache, store de sessions, file, ou datastore primaire.
Monter Redis : de l'instance unique au cluster
Une instance Redis peut suffire bien plus loin qu'on ne le pense : simple à opérer, facile à raisonner et souvent assez rapide pour beaucoup de workloads de cache, de session ou de file.
Le besoin de scaler survient quand vous atteignez des limites dures — typiquement plafond mémoire, CPU saturé, ou un point unique de défaillance inacceptable.
Quand passer d'une instance à plusieurs
Envisagez d'ajouter des nœuds quand :
- votre dataset ne tient plus en RAM avec une marge de sécurité raisonnable,
- des pics de latence apparaissent car le nœud est CPU-bound,
- vous avez besoin d'une disponibilité supérieure à « redémarrage et récupération »,
- vous avez plusieurs workloads concurrents (cache + files) et voulez les isoler.
Un premier pas pratique est souvent de séparer les workloads (deux instances Redis) avant d'adopter un cluster.
Sharding et Redis Cluster en termes simples
Le sharding signifie répartir vos clés sur plusieurs nœuds pour que chaque nœud stocke une portion des données. Redis Cluster est la solution intégrée : l'espace de clés est divisé en slots, et chaque nœud possède certains slots.
Le bénéfice : plus de mémoire totale et de débit. Le coût : complexité accrue — les opérations multi-clés sont contraintes (les clés doivent être sur le même shard) et le dépannage implique plus d'éléments en mouvement.
Clés chaudes et distribution inégale du trafic
Même avec un sharding « uniforme », le trafic réel peut être déséquilibré. Une clé populaire (« hot key ») peut surcharger un nœud tandis que d'autres restent au repos.
Moyens d'atténuation : TTL courts avec jitter, fractionner la valeur sur plusieurs clés (hashing de clé), ou repenser le pattern d'accès pour répartir les lectures.
Considérations client : drivers cluster-aware et routage
Un Redis Cluster exige un client aware du cluster capable de découvrir la topologie, router les requêtes au bon nœud et suivre les redirections lors des mouvements de slots.
Avant de migrer, confirmez :
- que votre driver dans le langage choisi supporte Redis Cluster,
- que votre stratégie de pooling fonctionne avec plusieurs nœuds,
- que votre code évite les commandes multi-clés à travers des shards différents (ou utilise des hash tags pour grouper les clés liées).
Le scaling fonctionne mieux quand c'est une évolution planifiée : validez par des tests de charge, instrumentez la latence par clé, et migrez le trafic progressivement.
Principes de sécurité pour les déploiements Redis
Conservez la maîtrise de votre implémentation
Conservez la pleine propriété en exportant le code source et en l'exécutant où vous le souhaitez.
Redis est souvent traité comme de la « plomberie interne », ce qui en fait une cible fréquente : un port exposé peut entraîner une fuite de données ou un contrôle de cache par un attaquant. Considérez Redis comme une infrastructure sensible, même si vous n'y stockez que des données temporaires.
Authentification et contrôle d'accès
Commencez par activer l'authentification et utilisez des ACLs (Redis 6+). Les ACLs vous permettent de :
- créer des utilisateurs distincts pour les apps, workers et admins
- restreindre les commandes (ex. autoriser GET/SET mais interdire CONFIG)
- limiter les clés par préfixe (utile en multi-tenant)
Évitez un mot de passe partagé pour tous les composants. Délivrez des identifiants par service et donnez des permissions minimales.
Isolation réseau et TLS
Le contrôle le plus efficace est de ne pas être accessible. Lie Redis à une interface privée, placez-le sur un subnet privé et restreignez l'accès via security groups/firewalls seulement aux services qui en ont besoin.
Utilisez TLS quand le trafic Redis traverse des frontières d'hôtes non contrôlées (multi-AZ, réseaux partagés, nœuds Kubernetes ou environnements hybrides). TLS empêche l'écoute clandestine et le vol de credentials ; c'est souvent un petit coût acceptable pour des sessions, tokens ou toute donnée utilisateur.
Commandes dangereuses et mauvaise configuration
Verrouillez les commandes pouvant causer de gros dégâts si abusées. Exemples courants à désactiver ou restreindre via ACLs : FLUSHALL, FLUSHDB, CONFIG, SAVE, DEBUG, et EVAL (ou du moins contrôler strictement le scripting). Protégez aussi l'approche rename-command avec prudence — les ACLs sont en général plus claires et faciles à auditer.
Gestion des secrets et rotation
Stockez les credentials Redis dans un gestionnaire de secrets (pas dans le code ni les images d'containers) et planifiez la rotation. La rotation est plus simple quand les clients peuvent recharger des credentials sans redeploy, ou quand vous autorisez deux identifiants valides pendant une fenêtre de transition.
Si vous voulez une checklist pratique, conservez-la dans vos runbooks aux côtés de /blog/monitoring-troubleshooting-redis.
Monitoring, dépannage et hygiène opérationnelle
Redis « a souvent l'air en forme »… jusqu'à ce que le trafic change, la mémoire augmente ou qu'une commande lente bloque tout. Une routine de monitoring légère et une checklist d'incident évitent la plupart des surprises.
Les métriques qui comptent vraiment
Commencez par un petit ensemble compréhensible par tous :
- Mémoire utilisée vs maxmemory : surveillez les tendances, pas seulement l'instantané.
- Taux de hit du cache (si vous mettez en cache) : des hits faibles indiquent souvent un mauvais design de clés, des TTL trop courts ou des lectures contournant le cache.
- Latence : surveillez p95/p99 ; les pics importent plus que la moyenne.
- Evictions : des évictions soutenues signifient généralement un sous-dimensionnement ou des TTL inadaptés.
- Lag de réplication (si vous avez des replicas) : un lag croissant nuit à l'usage en lecture et à la confiance dans le basculement.
Dépannage rapide : slowlog et stats de commandes
Quand c'est « lent », vérifiez avec les outils Redis :
- SLOWLOG identifie les commandes chères (requêtes de large gamme, fetchs de grosses valeurs, scans accidentels).
- Les stats de commandes (
INFO) montrent quelles commandes dominent. Une montée soudaine de KEYS, SMEMBERS ou de gros LRANGE est un signal d'alarme.
Si la latence monte alors que le CPU est normal, pensez aussi au réseau saturé, aux payloads surdimensionnés ou aux clients bloqués.
Capacity planning et marge de sécurité
Préparez la croissance en gardant de la marge (communément 20–30% de mémoire libre) et revoyez les hypothèses après des lancements ou feature flags. Traitez les « évictions continues » comme une panne, pas comme un avertissement.
Un runbook d'incident simple
En cas d'incident, vérifiez (dans l'ordre) : mémoire/evictions, latence, connexions clients, slowlog, lag de réplication et déploiements récents. Notez les causes récurrentes et corrigez-les définitivement — des alertes seules ne suffiront pas.
Si votre équipe itère vite, intégrez ces attentes opérationnelles dans votre workflow de développement. Par exemple, avec le mode planning et les snapshots/rollbacks de Koder.ai, vous pouvez prototyper des fonctionnalités Redis (cache, rate limiting), les tester sous charge et revenir en arrière en toute sécurité — tout en conservant l'implémentation dans votre code via l'export source.