03 nov. 2025·8 min
Patrons SaaS multi‑locataire : isolation, mise à l'échelle et conception assistée par IA
Découvrez les patrons courants pour les SaaS multi‑locataires, les compromis liés à l'isolation des locataires et les stratégies de mise à l'échelle. Voyez comment les architectures générées par l'IA accélèrent la conception et les revues.
Ce que signifie multi‑locataire (sans le jargon)
Multi‑locataire signifie qu’un même produit logiciel sert plusieurs clients (locataires) depuis le même système en fonctionnement. Chaque locataire a l'impression d'« avoir sa propre appli », mais en coulisses ils partagent des parties de l'infrastructure — comme les mêmes serveurs web, le même code, et souvent la même base de données.
Un modèle mental utile est celui d'un immeuble d'habitation. Chacun a son propre logement verrouillé (ses données et paramètres), mais vous partagez l'ascenseur, la plomberie et l'équipe de maintenance de l'immeuble (le calcul, le stockage et les opérations de l'application).
Pourquoi les équipes choisissent le multi‑locataire
La plupart des équipes ne choisissent pas un SaaS multi‑locataire parce que c'est à la mode — elles le choisissent parce que c'est efficace :
- Coût par client réduit : l'infrastructure partagée coûte généralement moins cher que de provisionner une pile complète par client.
- Opérations simplifiées : une seule plateforme à surveiller, patcher et sécuriser (plutôt que des centaines de petites instances).
- Livraison plus rapide : les améliorations profitent à tous en même temps, et vous évitez la « dérive de versions » entre clients.
Où cela peut mal tourner
Les deux modes d'échec classiques sont la sécurité et la performance.
Sur la sécurité : si les frontières entre locataires ne sont pas appliquées partout, un bug peut fuir des données entre clients. Ces fuites ne sont rarement des « hacks » spectaculaires — ce sont souvent des erreurs ordinaires comme un filtre oublié, une vérification d'autorisation mal configurée, ou un job d'arrière‑plan qui s'exécute sans contexte de locataire.
Sur la performance : les ressources partagées signifient qu'un locataire occupé peut ralentir les autres. Cet effet de « voisin bruyant » peut se manifester par des requêtes lentes, des charges explosives, ou un client consommant disproportionnellement la capacité d'API.
Aperçu rapide des patrons abordés
Cet article parcourt les blocs de construction que les équipes utilisent pour gérer ces risques : isolation des données (base/schéma/lignes), identité et permissions tenant‑aware, contrôles contre les voisins bruyants, et schémas opérationnels pour la montée en charge et la gestion du changement.
Le compromis central : isolation vs efficacité
Le multi‑locataire est un choix sur un spectre : combien vous partagez entre locataires versus combien vous dédiez par locataire. Chaque patron d'architecture ci‑dessous est simplement un point différent sur cette ligne.
Ressources partagées vs dédiées : le spectre de base
À une extrémité, les locataires partagent presque tout : mêmes instances applicatives, mêmes bases de données, mêmes files, mêmes caches — séparés logiquement par des identifiants de locataire et des règles d'accès. C'est généralement l'option la moins chère et la plus facile à exploiter parce que vous mutualisez la capacité.
À l'autre extrémité, les locataires obtiennent leur propre « tranche » du système : bases de données séparées, calcul séparé, parfois même déploiements distincts. Cela augmente la sécurité et le contrôle, mais accroît aussi la charge opérationnelle et les coûts.
Pourquoi isolation et coût tirent dans des directions opposées
L'isolation réduit la probabilité qu'un locataire accède aux données d'un autre, consomme son budget de performance ou soit affecté par des usages inhabituels. Elle facilite aussi certaines audits et exigences de conformité.
L'efficacité s'améliore quand vous amortissez la capacité inactive entre de nombreux locataires. L'infrastructure partagée vous permet de réduire le nombre de serveurs, de garder des pipelines de déploiement plus simples, et de scaler sur la demande agrégée plutôt que sur le pire scénario par locataire.
Facteurs fréquents de décision
Votre point « idéal » sur le spectre est rarement philosophique — il est dicté par des contraintes :
- SLA et attentes clients : des objectifs stricts d'uptime ou de latence poussent vers plus d'isolation.
- Conformité et résidence des données : des exigences peuvent imposer un stockage dédié ou des environnements séparés.
- Phase de croissance : les produits en phase initiale commencent souvent plus partagés pour aller plus vite ; plus tard, on propose des options dédiées aux gros clients.
- Maturité opérationnelle : plus d'isolation signifie généralement plus d'éléments à monitorer, patcher et migrer.
Modèle mental simple pour choisir
Posez deux questions :
-
Quel est le rayon d'explosion (blast radius) si un locataire se comporte mal ou est compromis ?
-
Quel est le coût business pour réduire ce rayon d'explosion ?
Si le rayon d'explosion doit être minime, choisissez des composants plus dédiés. Si le coût et la rapidité importent davantage, partagez plus — et investissez dans des contrôles d'accès solides, des limites de débit et du monitoring par locataire pour sécuriser le partage.
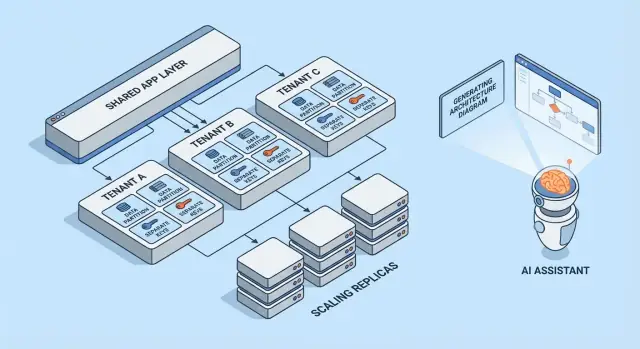
Modèles multi‑locataires en un coup d'œil
Le multi‑locataire n'est pas une architecture unique — ce sont des manières de partager (ou non) l'infrastructure entre clients. Le meilleur modèle dépend du niveau d'isolation requis, du nombre attendu de locataires et de la charge opérationnelle que votre équipe peut assumer.
1) Monosite par client (dédié) — la référence
Chaque client obtient sa propre pile applicative (ou au moins un runtime et une base isolés). C'est le plus simple à raisonner en termes de sécurité et de performance, mais généralement le plus coûteux par locataire et cela peut ralentir l'évolution opérationnelle.
2) Appli partagée + BD partagée — coût le plus bas, vigilance requise
Tous les locataires s'exécutent sur la même application et la même base de données. Les coûts sont souvent les plus faibles car vous maximisez la réutilisation, mais vous devez être méticuleux sur le contexte de locataire partout (requêtes, cache, jobs d'arrière‑plan, exports analytiques). Une seule erreur peut devenir une fuite de données inter‑locataires.
3) Appli partagée + BD séparées — isolation renforcée, plus d'ops
L'application est partagée, mais chaque locataire dispose de sa propre base de données (ou instance). Cela améliore le contrôle du rayon d'explosion pour les incidents, facilite les backups/restores par locataire et peut simplifier la conformité. Le compromis est opérationnel : plus de bases à provisionner, monitorer, migrer et sécuriser.
4) Modèles hybrides pour les « gros » locataires
Beaucoup de produits SaaS mixent les approches : la majorité des clients restent sur l'infrastructure partagée, tandis que les gros comptes ou les clients régulés obtiennent des bases ou du calcul dédiés. L'hybride est souvent l'issue pratique, mais il exige des règles claires : qui est éligible, à quel coût, et comment se déroulent les mises à jour.
Si vous voulez un approfondissement sur les techniques d'isolation dans chaque modèle, voyez /blog/data-isolation-patterns.
Patrons d'isolation des données (BD, schéma, ligne)
L'isolation des données répond à une question simple : « Un client peut‑il voir ou affecter les données d'un autre client ? » Il existe trois patrons courants, chacun avec des implications de sécurité et opérationnelles différentes.
Isolation au niveau des lignes (tables partagées + tenant_id)
Tous les locataires partagent les mêmes tables, et chaque ligne inclut une colonne tenant_id. C'est le modèle le plus efficace pour les petits à moyens locataires car il minimise l'infrastructure et facilite les rapports et l'analytics.
Le risque est simple : si une requête oublie de filtrer par tenant_id, vous pouvez exposer des données. Même un seul endpoint d'administration ou un job cron peut devenir un point faible. Les atténuations incluent :
- Faire appliquer le filtre de locataire dans une couche d'accès aux données partagée (pour éviter que les développeurs n'écrivent des filtres manuellement)
- Utiliser des fonctionnalités de la base comme la row‑level security (RLS) quand disponible
- Ajouter des tests automatisés qui tentent volontairement un accès inter‑locataire
- Indexer pour les chemins d'accès courants (souvent
(tenant_id, created_at)ou(tenant_id, id)) afin que les requêtes scoped au locataire restent rapides
Schéma par locataire (même BD, schémas séparés)
Chaque locataire obtient son propre schéma (namespaces comme tenant_123.users, tenant_456.users). Cela améliore l'isolation comparée au partage par ligne et peut faciliter l'export ou l'optimisation spécifique à un locataire.
Le compromis est opérationnel. Les migrations doivent s'exécuter sur de nombreux schémas, et les échecs deviennent plus compliqués : vous pouvez migrer 9 900 locataires et rester bloqué sur 100. Le monitoring et les outils comptent ici — votre processus de migration doit prévoir des retry et un reporting clair.
Base de données par locataire (BD séparée)
Chaque locataire dispose d'une base de données séparée. L'isolation est forte : les frontières d'accès sont plus nettes, les requêtes bruyantes d'un locataire affectent moins les autres, et restaurer un seul locataire depuis une sauvegarde est beaucoup plus propre.
Les coûts et l'échelle sont les principaux inconvénients : plus de bases à gérer, plus de pools de connexion, et potentiellement plus de travail de migration/mise à jour. Beaucoup d'équipes réservent ce modèle aux locataires à forte valeur ou régulés, tandis que les petits restent sur l'infrastructure partagée.
Sharding et stratégies de placement au fur et à mesure de la croissance
Les systèmes réels mélangent souvent ces patrons. Un chemin commun est l'isolation par ligne en phase initiale, puis « faire monter » les gros locataires vers des schémas ou des bases séparées.
Le sharding ajoute une couche de placement : décider sur quel cluster de bases un locataire vit (par région, par palier de taille, ou par hachage). L'important est de rendre le placement explicite et modifiable — pour pouvoir déplacer un locataire sans réécrire l'application, et scaler en ajoutant des shards plutôt qu'en repensant tout.
Identité, accès et contexte du locataire
Le multi‑locataire échoue de façons étonnamment ordinaires : un filtre oublié, un objet mis en cache partagé entre locataires, ou une fonctionnalité d'admin qui « oublie » pour quel locataire la requête est faite. La solution n'est pas une grosse fonctionnalité de sécurité unique — c'est un contexte de locataire cohérent du premier octet de la requête jusqu'à la dernière requête SQL.
Identification du locataire (comment savoir « qui »)
La plupart des produits SaaS choisissent un identifiant principal et traitent le reste comme des commodités :
- Sous‑domaine :
acme.votreapp.comest simple pour les utilisateurs et fonctionne bien pour des expériences brandées par locataire. - Header : utile pour les clients API et services internes (mais doit être authentifié).
- Claim dans un token : un JWT signé (ou la session) inclut
tenant_id, ce qui rend la falsification difficile.
Choisissez une source de vérité et consignez‑la partout. Si vous supportez plusieurs signaux (sous‑domaine + token), définissez une priorité et rejetez les requêtes ambiguës.
Scoping de la requête (comment chaque requête reste dans le locataire)
Une bonne règle : une fois que vous résolvez tenant_id, tout ce qui suit doit le lire depuis un seul endroit (contexte de requête), et non le re‑dériver.
Des garde‑fous courants :
- Middleware qui attache
tenant_idau contexte de la requête - Helpers d'accès aux données qui exigent
tenant_idcomme paramètre - Application d'enforcements côté base (comme des politiques RLS) pour que les erreurs échouent en mode fermé
handleRequest(req):
tenantId = resolveTenant(req) // subdomain/header/token
req.context.tenantId = tenantId
return next(req)
Notions basiques d'autorisation (rôles au sein d'un locataire)
Séparez authentification (qui est l'utilisateur) de autorisation (ce qu'il peut faire).
Les rôles typiques sont Owner / Admin / Member / Read‑only, mais l'important est la portée : un utilisateur peut être Admin dans le Locataire A et Member dans le Locataire B. Stockez les permissions par locataire, pas globalement.
Prévenir les fuites inter‑locataires (tests et garde‑fous)
Traitez l'accès inter‑locataire comme un incident de premier ordre et prévenez‑le proactivement :
- Ajoutez des tests automatisés qui tentent de lire les données du Locataire B tout en étant authentifié comme Locataire A
- Rendre les bugs de filtre de locataire plus difficiles à livrer (linters, builders de requêtes, paramètres tenant obligatoires)
- Logger et alerter sur des patterns suspects (par ex. mismatch tenant entre le token et le sous‑domaine)
Si vous voulez une checklist opérationnelle plus complète, reliez ces règles à vos runbooks d'ingénierie sur /security et gardez‑les versionnées avec votre code.
Isolation au‑delà de la base de données
Prototypez la multi‑tenancy rapidement
Générez un squelette React + Go + PostgreSQL pour tester dès le départ le périmètre des locataires.
L'isolation de la base n'est que la moitié de l'histoire. De nombreux incidents multi‑locataires réels surviennent dans la tuyauterie partagée autour de l'appli : caches, files, et stockage. Ces couches sont rapides, pratiques et faciles à rendre globales accidentellement.
Caches partagés : éviter les collisions de clés et les fuites de données
Si plusieurs locataires partagent Redis ou Memcached, la règle principale est simple : ne jamais stocker de clés agnostiques au locataire.
Un patron pratique est de préfixer chaque clé par un identifiant stable du locataire (pas un domaine email, pas un nom d'affichage). Par exemple : t:{tenant_id}:user:{user_id}. Cela fait deux choses :
- Évite les collisions quand deux locataires ont les mêmes IDs internes
- Rend la suppression en masse faisable (delete par préfixe) lors d'incidents de support ou de migrations
Décidez aussi ce qui peut être partagé globalement (par ex. feature flags publics, métadonnées statiques) et documentez‑le — les globals accidentels sont une source courante d'exposition inter‑locataires.
Limites de débit et quotas tenant‑aware
Même si les données sont isolées, les locataires peuvent encore s'impacter via le calcul partagé. Ajoutez des limites tenant‑aware aux frontières :
- Limites de débit API par locataire (et souvent par utilisateur au sein d'un locataire)
- Quotas pour opérations coûteuses (exports, génération de rapports, appels IA)
Rendez la limite visible (headers, notifications UI) pour que les clients comprennent que le throttling est une politique, pas une instabilité.
Jobs d'arrière‑plan : partitionner les files par locataire
Une seule file partagée peut laisser un locataire occupé dominer le temps des workers.
Corrections communes :
- Files séparées par palier/plan (ex.
free,pro,enterprise) - Files partitionnées par bucket de locataire (hachage de tenant_id en N files)
- Scheduling tenant‑aware pour garantir une part équitable pour chaque locataire
Propagez toujours le contexte de locataire dans la charge du job et les logs pour éviter des effets secondaires sur le mauvais locataire.
Stockage d'objets/fichiers : chemins, politiques et clés séparés
Pour le stockage style S3/GCS, l'isolation est généralement basée sur le chemin et les politiques :
- Bucket par locataire pour une séparation stricte (frontières plus fortes, overhead plus important)
- Bucket partagé avec préfixes par locataire (plus simple, nécessite une IAM et des URLs signées soignées)
Quelle que soit l'approche, validez que les uploads/downloads confirment la propriété du locataire à chaque requête, pas seulement dans l'UI.
Gérer les voisins bruyants et l'utilisation équitable des ressources
Les systèmes multi‑locataires partagent l'infrastructure, ce qui signifie qu'un locataire peut accidentellement (ou intentionnellement) consommer plus que sa part. C'est le problème du voisin bruyant : une seule charge bruyante dégrade les performances pour tout le monde.
À quoi ressemble un « voisin bruyant »
Imaginez une fonctionnalité d'export qui extrait une année de données en CSV. Le Locataire A planifie 20 exports à 9h00. Ces exports saturent la CPU et le I/O BD, si bien que les écrans habituels du Locataire B commencent à timeouter — malgré que B ne fasse rien d'inhabituel.
Contrôles de ressource : limites, quotas et façonnage de charge
La prévention commence par des frontières de ressource explicites :
- Limites de débit (req/s) par locataire et par endpoint, pour éviter le spam des API coûteuses.
- Quotas (quotidien/mensuel) pour exports, emails, appels IA, ou jobs d'arrière‑plan.
- Façonnage des charges : placer les tâches lourdes (exports, imports, re‑indexing) dans des files avec des caps de concurrence par locataire et des règles de priorité.
Un patron pratique est de séparer le trafic interactif du travail batch : garder les requêtes utilisateurs sur une voie rapide et pousser le reste vers des files contrôlées.
Disjoncteurs par locataire et bulkheads
Ajoutez des soupapes de sécurité qui se déclenchent quand un locataire dépasse un seuil :
- Disjoncteurs : rejeter temporairement ou différer les opérations coûteuses quand les taux d'erreur, la latence ou la profondeur des files dépassent les limites pour ce locataire.
- Bulkheads : isoler des pools partagés (connexions BD, threads worker, cache) pour qu'un locataire ne puisse pas épuiser la capacité globale.
Bien fait, le Locataire A peut réduire sa propre vitesse d'export sans faire tomber le Locataire B.
Quand migrer un locataire vers des ressources dédiées
Déplacez un locataire vers des ressources dédiées quand il dépasse régulièrement les hypothèses du partage : débit soutenu élevé, pics imprévisibles liés à des événements business, besoins stricts de conformité, ou workload nécessitant un tuning spécifique. Une règle simple : si protéger les autres locataires exige de brider en permanence un client payant, il est temps d'offrir une capacité dédiée (ou un palier supérieur) plutôt que de lutter constamment.
Schémas de mise à l'échelle qui fonctionnent en SaaS multi‑locataire
Configurez le routage des locataires
Testez le routage par sous-domaine ou domaine personnalisé pour les locataires sans reconstruire votre stack.
La mise à l'échelle multi‑locataire relève moins de « plus de serveurs » que d'empêcher la croissance d'un locataire de surprendre tout le monde. Les meilleurs patrons rendent l'échelle prévisible, mesurable et réversible.
Mise à l'échelle horizontale pour les services sans état
Commencez par rendre la couche web/API sans état : stockez les sessions dans un cache partagé (ou utilisez l'authentification token), placez les uploads dans le stockage objet, et poussez le travail long dans des jobs d'arrière‑plan. Une fois que les requêtes ne dépendent plus de la mémoire ou du disque local, vous pouvez ajouter des instances derrière un load balancer et scaler rapidement.
Un conseil pratique : conservez le contexte du locataire en périphérie (dérivé du sous‑domaine ou des headers) et transmettez‑le à chaque handler. Sans‑état ne veut pas dire ignorant du locataire — cela signifie aware du locataire sans serveurs « collants ».
Points chauds par locataire : les identifier et les lisser
La plupart des problèmes de montée en charge sont « un locataire est différent ». Surveillez les hotspots comme :
- Un locataire générant un trafic disproportionné
- Quelques locataires avec des jeux de données très larges
- Usages batch (rapports de fin de mois, imports nocturnes)
Les tactiques pour lisser incluent des limites par locataire, ingestion queue‑based, cache pour les chemins de lecture propres à un locataire, et sharding des gros locataires dans des pools de workers séparés.
Réplicas de lecture, partitionnement et workloads asynchrones
Utilisez des réplicas de lecture pour les charges en lecture (dashboards, recherche, analytics) et gardez les écritures sur le primaire. Le partitionnement (par locataire, par date, ou les deux) aide à garder les index plus petits et les requêtes plus rapides. Pour les tâches coûteuses — exports, scoring ML, webhooks — privilégiez les jobs asynchrones avec idempotence pour que les retries n'amplifient pas la charge.
Signaux de capacity planning et seuils simples
Gardez les signaux simples et tenant‑aware : latence p95, taux d'erreur, profondeur des files, CPU BD, et taux de requêtes par locataire. Fixez des seuils simples (ex. « profondeur de file > N pendant 10 minutes » ou « p95 > X ms ») qui déclenchent de l'autoscaling ou des caps temporaires par locataire — avant que les autres locataires ne le ressentent.
Observabilité et opérations par locataire
Les systèmes multi‑locataires ne tombent pas d'abord globalement — ils échouent souvent pour un locataire, un palier, ou une charge bruyante. Si vos logs et dashboards ne peuvent pas répondre en secondes à « quel locataire est affecté ? », le temps de garde tourne en enquête.
Logs, métriques et traces tenant‑aware
Commencez par un contexte de locataire cohérent dans toute la télémétrie :
- Logs : incluez
tenant_id,request_idet unactor_idstable (utilisateur/service) sur chaque requête et job d'arrière‑plan. - Métriques : émettez compteurs et histogrammes de latence ventilés par palier de locataire au minimum (ex.
tier=basic|premium) et par endpoint macro (pas les URLs brutes). - Traces : propagez le contexte de locataire en attributs de trace pour pouvoir filtrer une trace lente vers un locataire spécifique et voir où le temps est passé (BD, cache, appels tiers).
Gardez la cardinalité sous contrôle : des métriques par locataire pour tous les locataires peuvent devenir chères. Un compromis courant est les métriques par palier par défaut, plus un drill‑down par locataire à la demande (ex. échantillonnage des traces pour les « top 20 » locataires par trafic ou les locataires en dépassement SLO).
Éviter les fuites de données sensibles dans la télémétrie
La télémétrie est un canal d'export de données. Traitez‑la comme des données de production.
Privilégiez les IDs plutôt que le contenu : loggez customer_id=123 plutôt que noms, emails, tokens ou payloads de requêtes. Ajoutez de la redaction au niveau du logger/SDK, et maintenez une blocklist des secrets courants (Authorization headers, clés API). Pour les workflows de support, stockez les payloads de debug dans un système séparé et contrôlé — pas dans des logs partagés.
SLOs par palier de locataire (sans survendre)
Définissez des SLOs qui correspondent à ce que vous pouvez réellement faire respecter. Les locataires premium peuvent obtenir des budgets d'erreur/latence plus stricts, mais seulement si vous avez aussi des contrôles (rate limits, isolation des charges, queues prioritaires). Publiez les SLOs par palier comme cibles, et suivez‑les par palier et pour un ensemble choisi de locataires à haute valeur.
Runbooks on‑call : incidents fréquents en SaaS multi‑locataire
Vos runbooks doivent commencer par « identifier le(s) locataire(s) affecté(s) » puis l'action d'isolation la plus rapide :
- Voisin bruyant : brider le locataire, mettre en pause les jobs lourds, ou le déplacer vers une file de moindre priorité.
- Hotspots BD/requêtes runaway : activer des timeouts de requête, inspecter les requêtes en tête par locataire, appliquer un index ou limiter l'endpoint.
- Bugs de contexte de locataire (mixage de données) : désactiver immédiatement le feature flag ou l'endpoint et vérifier le scoping des accès.
- Accumulation de jobs d'arrière‑plan : vider les files par locataire, limiter la concurrence, et rejouer avec des garanties d'idempotence.
Opérationnellement, l'objectif est simple : détecter par locataire, contenir par locataire, et récupérer sans impacter tout le monde.
Déploiements, migrations et releases par locataire
Le SaaS multi‑locataire change le rythme du shipping. Vous ne déployez pas « une appli » ; vous déployez un runtime partagé et des chemins de données partagés dont dépendent de nombreux clients. L'objectif est de livrer de nouvelles fonctionnalités sans forcer une mise à jour synchronisée pour tous les locataires.
Déploiements progressifs et migrations à faible downtime
Privilégiez des patterns de déploiement qui tolèrent des versions mixtes pour une courte fenêtre (blue/green, canary, rolling). Cela ne fonctionne que si vos changements de base de données sont eux aussi étagés.
Une règle pratique est expand → migrate → contract :
- Expand : ajouter de nouvelles colonnes/tables/index sans casser le code existant.
- Migrate : backfiller les données par lots (souvent par locataire) et vérifier.
- Contract : supprimer les anciens champs uniquement après que toutes les instances d'app ne les utilisent plus.
Pour les tables chaudes, faites les backfills de manière incrémentale (et throttlez), sinon vous créez votre propre événement de voisin bruyant pendant une migration.
Feature flags par locataire pour des rollouts plus sûrs
Les feature flags au niveau locataire vous permettent de livrer du code globalement tout en activant le comportement de façon sélective.
Cela permet :
- Programmes d'accès anticipé pour quelques locataires
- Rétablissement rapide en désactivant une fonctionnalité uniquement pour les locataires affectés
- Expérimentations A/B sans forker les déploiements
Gardez le système de flags auditable : qui a activé quoi, pour quel locataire, et quand.
Versioning et attentes en matière de compatibilité
Supposez que certains locataires puissent être en retard sur la configuration, les intégrations ou les patterns d'usage. Concevez les API et événements avec un versioning clair pour que de nouveaux producteurs ne cassent pas d'anciens consommateurs.
Attentes communes à fixer en interne :
- Les nouvelles versions doivent lire à la fois les anciens et nouveaux formats pendant les fenêtres de migration.
- Les dépréciations exigent un calendrier publié (même s'il s'agit seulement de notes internes et d'un template d'email client).
Gestion de la configuration spécifique aux locataires
Traitez la config par locataire comme une surface produit : elle nécessite validation, valeurs par défaut et historique des modifications.
Stockez la configuration séparément du code (et idéalement séparément des secrets runtime), et fournissez un mode safe‑fallback quand la config est invalide. Une page interne légère comme /settings/tenants peut vous faire gagner des heures pendant l'investigation d'incident et les rollouts étagés.
Comment les architectures générées par IA aident (et leurs limites)
Déployez votre prototype SaaS
Mettez en ligne votre prototype avec hébergement quand vous êtes prêt à le partager.
L'IA peut accélérer la réflexion architecturale initiale pour un SaaS multi‑locataire, mais ce n'est pas un substitut au jugement d'ingénierie, aux tests ou à la revue sécurité. Traitez‑la comme un partenaire de brainstorming de qualité qui produit des brouillons — puis vérifiez chaque hypothèse.
Ce que devrait (et ne devrait pas) faire une architecture générée par IA
L'IA est utile pour générer des options et mettre en lumière des modes d'échec typiques (où le contexte de locataire peut être perdu, ou où les ressources partagées peuvent créer des surprises). Elle ne doit pas décider de votre modèle, garantir la conformité, ni valider les performances. Elle ne voit pas votre trafic réel, les forces de votre équipe ou les cas limites cachés dans des intégrations legacy.
Entrées qui comptent : besoins, contraintes, risques, croissance
La qualité de la sortie dépend de ce que vous lui fournissez. Les entrées utiles incluent :
- Nombre de locataires aujourd'hui vs dans 12–24 mois, et volume de données attendu par locataire
- Exigences d'isolation (contractuelles, réglementaires, attentes clients)
- Budget et capacité opérationnelle (maturité on‑call, support SRE, outils)
- Objectifs de latence, patterns de pic et burst par locataire
- Tolérance au risque : que se passe‑t‑il si un locataire impacte un autre ?
Utiliser l'IA pour proposer des options de pattern avec compromis
Demandez 2–4 designs candidats (par ex. base par locataire vs schéma par locataire vs isolation par ligne) et réclamez un tableau clair des compromis : coût, complexité opérationnelle, rayon d'explosion, effort de migration et limites de montée en charge. L'IA est bonne pour lister les pièges que vous pouvez transformer en questions de conception pour votre équipe.
Si vous voulez passer du « brouillon d'architecture » à un prototype fonctionnel plus vite, une plateforme vibe‑coding comme Koder.ai peut vous aider à transformer ces choix en un squelette d'appli via chat — souvent avec un frontend React et un backend Go + PostgreSQL — pour valider tôt la propagation du contexte de locataire, les limites de débit et les workflows de migration. Des fonctionnalités comme un mode planning et des snapshots/rollback sont particulièrement utiles quand vous itérez sur des modèles de données multi‑locataires.
Utiliser l'IA pour générer des modèles de menace et des checklists
L'IA peut rédiger un modèle de menace simple : points d'entrée, frontières de confiance, propagation du contexte de locataire, et erreurs courantes (comme des checks d'autorisation manquants sur des jobs d'arrière‑plan). Servez‑vous‑en pour produire des checklists de revue pour les PRs et les runbooks — mais validez avec une expertise réelle en sécurité et votre historique d'incidents.
Une checklist pratique pour votre équipe
Choisir une approche multi‑locataire relève moins du « best practice » que de l'adéquation : sensibilité de vos données, taux de croissance et charge opérationnelle que vous pouvez porter.
Checklist pas à pas (utilisable en atelier de 30 minutes)
-
Données : quelles données sont partagées entre locataires (si nécessaire) ? Qu'est‑ce qui ne doit jamais être co‑localisé ?
-
Identité : où vit l'identité du locataire (liens d'invitation, domaines, claims SSO) ? Comment le contexte de locataire est‑il établi sur chaque requête ?
-
Isolation : décidez du niveau d'isolation par défaut (ligne/schéma/base) et identifiez les exceptions (ex. clients enterprise nécessitant une séparation plus forte).
-
Mise à l'échelle : identifiez la première pression de montée en charge attendue (stockage, trafic en lecture, jobs d'arrière‑plan, analytics) et choisissez le pattern le plus simple qui la résout.
Questions à valider avec les ingénieurs et les reviewers sécurité
- Comment empêchons‑nous l'accès inter‑locataire si un développeur oublie un filtre ?
- Quelle est notre histoire d'audit par locataire (qui a fait quoi, quand) ?
- Comment gérons‑nous la suppression/retention des données par locataire ?
- Quel est le rayon d'explosion d'une mauvaise migration ou d'une requête runaway ?
- Pouvons‑nous brider, limiter et budgétiser les ressources par locataire ?
Signaux d'alerte qui nécessitent une conception plus approfondie
- « On ajoutera les checks de locataire plus tard. »
- Outils d'admin partagés pouvant tout voir sans contrôles stricts.
- Pas de plan pour les sauvegardes/restores par locataire ou la réponse aux incidents.
- Une seule file/worker pool sans équité par locataire.
Extrait de « prochaine action recommandée »
Recommandation : Commencez par l'isolation au niveau des lignes + enforcement strict du contexte de locataire, ajoutez des throttles par locataire, et définissez une trajectoire de montée vers schéma/BD séparée pour les locataires à risque élevé.
Actions suivantes (2 semaines) : threat‑modeler les frontières des locataires, prototyper l'enforcement sur un endpoint, et faire une répétition de migration sur une copie staging. Pour des conseils de déploiement, voyez /blog/tenant-release-strategies.