Ce que couvre cet article (et pourquoi c’est important)
Snowflake a rendu populaire une idée simple mais puissante pour les entrepôts de données cloud : séparer le stockage et le calcul. Cette séparation change deux points douloureux quotidiens pour les équipes data—comment les entrepôts évoluent et comment vous les payez.
Plutôt que de considérer l’entrepôt comme une unique « boîte » fixe (où plus d’utilisateurs, plus de données ou des requêtes plus complexes se disputent les mêmes ressources), le modèle de Snowflake vous permet de stocker les données une fois et de lancer la quantité de calcul adaptée quand vous en avez besoin. Le résultat : souvent un temps de réponse plus rapide, moins de goulets d’étranglement pendant les pics d’utilisation et un meilleur contrôle sur ce qui coûte de l’argent (et quand).
Cet article explique, en termes simples, ce que signifie réellement séparer le stockage et le calcul—et comment cela affecte :
- La concurrence (beaucoup de personnes exécutant des requêtes en même temps)
- La scalabilité élastique (augmenter ou diminuer le calcul)
- Le comportement des coûts (payer le calcul seulement lorsqu’il tourne, plus le stockage continu)
Nous indiquerons aussi là où le modèle ne résout pas automatiquement tout—car certaines surprises en matière de coût et de performance viennent de la façon dont les charges sont conçues, pas de la plateforme elle-même.
Une plateforme rapide n’est pas toute l’histoire. Pour beaucoup d’équipes, le time-to-value dépend de la facilité avec laquelle vous pouvez connecter l’entrepôt aux outils que vous utilisez déjà—pipelines ETL/ELT, tableaux de bord BI, outils de catalogue/gouvernance, contrôles de sécurité et sources partenaires.
L’écosystème Snowflake (incluant les patterns de partage et la distribution de type marketplace) peut raccourcir les délais d’implémentation et réduire l’ingénierie sur mesure. Cet article couvre ce à quoi ressemble la « profondeur d’écosystème » en pratique, et comment l’évaluer pour votre organisation.
Pour qui
Ce guide s’adresse aux leaders data, analystes et décideurs non spécialistes—toute personne qui doit comprendre les compromis derrière l’architecture Snowflake, la scalabilité, les coûts et les choix d’intégration sans se perdre dans le jargon fournisseur.
Avant la séparation : pourquoi les entrepôts traditionnels atteignent leurs limites
Les entrepôts traditionnels étaient construits sur une hypothèse simple : vous achetez (ou louez) une quantité fixe de matériel, puis vous exécutez tout sur la même boîte ou le même cluster. Cela fonctionnait bien lorsque les charges étaient prévisibles et la croissance progressive—mais cela a créé des limites structurelles lorsque les volumes de données et le nombre d’utilisateurs se sont accélérés.
Le modèle classique : clusters fixes et capacity planning
Les déploiements sur site (et les premières migrations « lift-and-shift » vers le cloud) ressemblaient typiquement à ceci :
- Un seul cluster MPP (traitement massif parallèle) gérait stockage, CPU et mémoire ensemble.
- Vous dimensionniez le cluster pour la demande de pointe, parce que redimensionner était lent, risqué ou nécessitait une indisponibilité.
- Le capacity planning devenait un projet récurrent : prévoir la croissance, justifier le budget, commander le matériel, installer, migrer.
Même quand des fournisseurs proposaient des « nœuds », le schéma restait le même : l’augmentation signifiait généralement ajouter des nœuds plus gros ou plus nombreux dans un environnement partagé.
Les douleurs : montée en charge lente, dépenses gaspillées et files d’attente
Ce design crée quelques problèmes récurrents :
- Montée en charge lente : Si un pic lié à la clôture mensuelle requiert soudainement plus de puissance, vous ne pouvez pas toujours l’obtenir rapidement. Soit vous attendez, soit vous surprovisionnez « juste au cas où ».
- Capacité inactive : Des clusters dimensionnés pour les pics restent sous-utilisés la plupart du temps—pourtant vous les payez (coût du matériel, licences, temps d’exploitation).
- Files d’attente sous charge : Quand plusieurs équipes exécutent des requêtes en même temps, elles se disputent les mêmes ressources. Les tâches lourdes peuvent bloquer des tableaux de bord interactifs, entraînant des timeouts, des parties prenantes frustrées et des règles du type « ne lancez pas cette requête pendant les heures ouvrées ».
Parce que ces entrepôts étaient étroitement couplés à leur environnement, les intégrations ont souvent grandi de manière organique : scripts ETL sur mesure, connecteurs bricolés et pipelines one-off. Ils fonctionnaient—jusqu’à ce qu’un schéma change, qu’un système en amont bouge, ou qu’un nouvel outil soit introduit. Maintenir l’ensemble pouvait ressembler à une maintenance constante plus qu’à un progrès régulier.
L’idée centrale : séparer stockage et calcul
Les entrepôts traditionnels lient souvent deux fonctions très différentes : le stockage (où résident vos données) et le calcul (la puissance qui lit, joint, agrège et écrit ces données).
Stockage vs calcul (en clair)
Stockage est comme un garde-manger à long terme : tables, fichiers et métadonnées sont conservés de manière durable et économique, conçus pour être durables et toujours disponibles.
Calcul est comme l’équipe en cuisine : c’est l’ensemble des CPUs et de la mémoire qui « cuisinent » vos requêtes—exécutent le SQL, trient, scannent, assemblent les résultats et gèrent plusieurs utilisateurs simultanément.
Le changement clé : les faire évoluer indépendamment
Snowflake sépare ces deux fonctions afin que vous puissiez ajuster chacune sans forcer l’autre à changer.
- Si le volume de données augmente, vous ajoutez plus de stockage (souvent incrémental et prévisible).
- Si le trafic de rapports explose, vous ajoutez plus de calcul (en redimensionnant ou en ajoutant des entrepôts virtuels) sans déplacer ni dupliquer les données.
Concrètement, cela change les opérations quotidiennes : vous n’avez plus à « suracheter » du calcul parce que le stockage croît, et vous pouvez isoler les charges (par ex. analystes vs jobs ETL) pour éviter qu’elles ne se ralentissent mutuellement.
Ce que ce n’est pas
Cette séparation est puissante, mais ce n’est pas magique.
- Ce n’est pas une mise à l’échelle gratuite. Des entrepôts plus grands ou plus nombreux signifient généralement une dépense de calcul plus élevée.
- Ce n’est pas une économie automatique. Du SQL mal écrit, des calendriers de refresh inutiles ou des entrepôts toujours actifs peuvent toujours engendrer des coûts.
- Ce n’est pas une excuse pour ignorer la planification. Il faut choisir des tailles d’entrepôts, définir des règles d’auto-suspension et aligner le calcul sur les usages métier.
La valeur réside dans le contrôle : payer stockage et calcul selon leurs règles propres, et les assortir aux besoins réels des équipes.
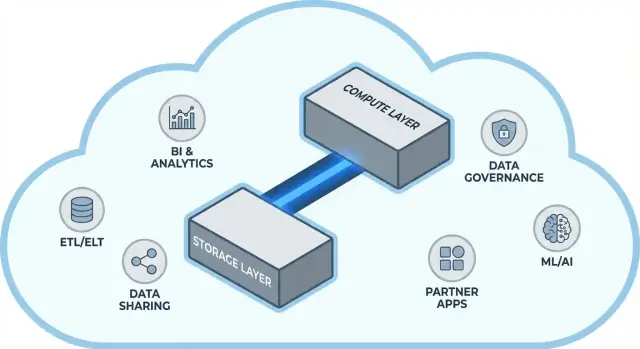
L’architecture Snowflake en termes simples
Snowflake se comprend facilement comme trois couches qui coopèrent, mais peuvent monter en charge indépendamment.
1) Stockage : stockage objet du cloud
Vos tables résident finalement sous forme de fichiers de données dans le stockage objet de votre fournisseur cloud (S3, Azure Blob, ou GCS). Snowflake gère les formats de fichiers, la compression et l’organisation pour vous. Vous n’« attachez » pas de disques ni ne dimensionnez de volumes—le stockage croît avec vos données.
2) Calcul : entrepôts virtuels
Le calcul est emballé sous forme d’entrepôts virtuels : clusters indépendants de CPU/mémoire qui exécutent les requêtes. Vous pouvez faire tourner plusieurs entrepôts en même temps contre les mêmes données. C’est la différence clé par rapport aux anciens systèmes où les charges lourdes se disputaient la même piscine de ressources.
3) Services cloud : métadonnées et coordination
Une couche de services séparée gère le « cerveau » du système : authentification, parsing et optimisation des requêtes, gestion des transactions/métadonnées et coordination. Cette couche décide comment exécuter une requête efficacement avant que le calcul touche les données.
Le chemin d’une requête
Quand vous soumettez du SQL, la couche services de Snowflake le parse, construit un plan d’exécution, puis confie ce plan à un entrepôt virtuel choisi. L’entrepôt lit seulement les fichiers de données nécessaires depuis le stockage objet (et profite du cache quand possible), les traite et renvoie les résultats—sans déplacer de manière permanente vos données de base dans l’entrepôt.
Concurrence et isolation (sans jargon)
Si beaucoup de personnes exécutent des requêtes simultanément, vous pouvez :
- utiliser des entrepôts séparés pour différentes équipes/charges (isolation des workloads), ou
- activer des entrepôts multi-clusters pour que Snowflake ajoute des clusters de calcul lors des pics, puis redescende.
C’est le fondement architectural derrière la performance de Snowflake et le contrôle des « voisins bruyants ».
Montée en charge et concurrence : ce qui change réellement
Le grand changement pratique de Snowflake est que vous faites évoluer le calcul indépendamment des données. Plutôt que « l’entrepôt grossit », vous pouvez ajuster les ressources par charge—sans copier de tables, repartitionner des disques ou planifier des fenêtres d’indisponibilité.
Élasticité : redimensionner le calcul sans déplacer les données
Dans Snowflake, un entrepôt virtuel est le moteur de calcul qui exécute les requêtes. Vous pouvez le redimensionner (par ex. de Small à Large) en quelques secondes, et les données restent dans le stockage partagé. Ainsi, l’optimisation des performances devient souvent une question simple : « cette charge a-t-elle besoin de plus de puissance maintenant ? »
Cela permet aussi des poussées temporaires : montez en puissance pour une clôture de fin de mois, puis redescendez quand le pic est passé.
Concurrence : moins de files d’attente
Les systèmes traditionnels obligent souvent différentes équipes à partager le même calcul, ce qui transforme les heures chargées en file d’attente.
Snowflake vous permet d’exécuter des entrepôts séparés par équipe ou par workload—par exemple, un pour les analystes, un pour les tableaux de bord et un pour l’ETL. Puisque ces entrepôts lisent les mêmes données sous-jacentes, vous réduisez le problème du type « mon dashboard a ralenti ton rapport » et rendez la performance plus prévisible.
Compromis à prévoir
Le calcul élastique n’est pas un succès automatique. Les pièges courants comprennent :
- Cold starts : les entrepôts suspendus peuvent prendre un instant à redémarrer, ajoutant de la latence pour les tâches peu fréquentes.
- Choix de dimensionnement : surdimensionner gaspille de l’argent ; sous-dimensionner engendre des requêtes lentes et de la frustration.
- Garde-fous nécessaires : utiliser auto-suspend/auto-resume, resource monitors et une responsabilité claire pour éviter que les entrepôts ne tournent à vide ou ne prolifèrent.
Le changement net : la montée en charge et la concurrence passent de projets d’infrastructure à des décisions d’exploitation quotidiennes.
Modèle de coûts : où se réalisent les économies (et où non)
Déployez un tableau de bord opérationnel
Créez un portail interne opérationnel qui lit les données Snowflake sans construire toute la stack à la main.
Le « pay for what you use » de Snowflake équivaut à deux compteurs qui tournent en parallèle :
- Calcul : facturé pour le temps où votre entrepôt virtuel fonctionne (en crédits).
- Stockage : facturé pour la quantité de données stockées (plus le stockage additionnel pour des fonctionnalités comme Time Travel/Fail-safe).
C’est cette séparation qui permet des économies potentielles : garder beaucoup de données relativement bon marché tout en n’activant le calcul que quand nécessaire.
Où les coûts grimpent
La plupart des dépenses « inattendues » proviennent des comportements de calcul plutôt que du stockage brut. Les facteurs courants :
- Entrepôts surdimensionnés
- Charges toujours actives (entrepôts laissés allumés la nuit ou le week-end)
- Requêtes inefficaces (scans non filtrés, jointures inutiles, transformations lourdes exécutées en boucle)
- Schémas à haute concurrence (petits tableaux de bord qui se raffraichissent constamment)
Séparer stockage et calcul ne rend pas automatiquement les requêtes efficaces—un mauvais SQL peut encore consommer rapidement des crédits.
Contrôles pratiques qui fonctionnent en vrai
Vous n’avez pas besoin d’un département finance pour gérer cela—juste quelques garde-fous :
- Auto-suspend / auto-resume pour ne pas payer le temps inactif
- Resource monitors pour alerter ou plafonner l’usage de crédits par entrepôt/équipe
- Planification (exécuter les jobs batch dans des fenêtres définies ; mettre en pause dev/test hors heures)
- Right-sizing et tests avec des entrepôts plus petits avant de monter en taille
Bien utilisés, ces contrôles récompensent la discipline : des calculs courts et dimensionnés à la demande associés à une croissance de stockage prévisible.
Le partage et la collaboration comme fonctionnalité de première classe
Snowflake conçoit le partage comme une fonctionnalité intégrée—pas un bricolage ajouté après coup (exports, dépôts de fichiers, ETL one-off).
Partager sans copier (dans de nombreux cas)
Au lieu d’envoyer des extraits, Snowflake peut permettre à un autre compte d’interroger les mêmes données via un « share » sécurisé. Dans beaucoup de scénarios, les données n’ont pas besoin d’être dupliquées dans un deuxième entrepôt ni poussées vers le stockage objet pour téléchargement. Le consommateur voit la base/table partagée comme si elle était locale, tandis que le fournisseur garde le contrôle de ce qui est exposé.
Cette approche découplée réduit la prolifération des données, accélère l’accès et diminue le nombre de pipelines à construire et maintenir.
Patterns de collaboration courants
Partage avec partenaires et clients : un fournisseur peut publier des jeux de données curatés aux clients (par ex. analytics d’usage ou données de référence) avec des périmètres clairs—seuls les schémas, tables ou vues autorisés.
Partage interne par domaine : des équipes centrales peuvent exposer des jeux de données certifiés à produit, finance et opérations sans obliger chaque équipe à créer ses propres copies. Cela soutient une culture de « chiffres uniques » tout en laissant les équipes exécuter leur propre calcul.
Collaboration gouvernée : des projets conjoints (avec une agence, un fournisseur ou une filiale) peuvent travailler sur un dataset partagé tout en masquant les colonnes sensibles et en journalisant les accès.
Limitations à prévoir
Le partage n’est pas « configurez et oubliez ». Il faut :
- Gouvernance : propriété claire, revues d’accès et politiques pour les données PII/réglementées.
- Contrats et attentes : qui paie le calcul, SLAs, rétention et ce qui arrive si les définitions changent.
- Découvrabilité : sans catalogue et une bonne nomenclature, les gens ne trouveront pas (ou ne feront pas confiance à) la bonne donnée. Alignez les shares avec la documentation et votre catalogue de données si vous en avez un.
Un entrepôt rapide est utile, mais la vitesse seule détermine rarement si un projet arrive à échéance. Ce qui fait souvent la différence, c’est l’écosystème autour de la plateforme : les connexions prêtes à l’emploi, les outils et le savoir-faire qui réduisent le travail personnalisé.
Concrètement, un écosystème inclut :
- Connecteurs vers sources/destinations (apps SaaS, bases, outils de streaming)
- Partenaires outils pour ingestion, transformation, BI, qualité des données et observabilité
- Apps et intégrations natives qui tournent près des données
- Templates et architectures de référence (modèles communs, patterns, guides de déploiement)
- Connaissance communautaire : exemples, forums, meetups et disponibilité de talents
Pourquoi l’écosystème bat souvent les benchs pour la vitesse de livraison
Les benchmarks mesurent une tranche étroite de performance sous conditions contrôlées. Les vrais projets passent la plupart du temps sur :
- Faire entrer les données de façon fiable et incrémentale
- Modéliser, tester et documenter les datasets
- Tâches opérationnelles (monitoring, alerting, contrôle des coûts)
- Revues de sécurité, contrôles d’accès et audits
Si votre plateforme a des intégrations matures pour ces étapes, vous évitez de construire et maintenir du code de colle. Cela raccourcit typiquement les délais d’implémentation, améliore la fiabilité et facilite le remplacement d’équipes ou de fournisseurs sans tout réécrire.
Une grille d’évaluation simple : couverture, qualité, maintenabilité
Quand vous évaluez un écosystème, regardez :
- Couverture : supporte-t-il vos sources clés, outils BI, orchestration et besoins de gouvernance ?
- Qualité : les connecteurs sont-ils maintenus activement, bien documentés et éprouvés à votre échelle ?
- Maintenabilité : quel effort continu requiert-il—mises à jour, ruptures, debug et support ?
La performance vous donne la capacité ; l’écosystème détermine souvent la rapidité à transformer cette capacité en résultats métier.
Écosystème d’intégration : faire entrer, sortir et exploiter les données
Passez de la démo au déploiement
Déployez votre prototype et itérez avec des snapshots et des rollback au fur et à mesure des changements.
Snowflake peut exécuter des requêtes rapides, mais la valeur apparaît quand les données circulent de façon fiable dans votre stack : des sources vers Snowflake, puis vers les outils que les utilisateurs utilisent au quotidien. La « dernière étape » est souvent ce qui fait que la plateforme semble sans effort—ou constamment fragile.
Les catégories d’intégration à planifier
La plupart des équipes ont besoin d’un mix de :
- ELT/ETL pour ingérer depuis bases, apps SaaS, fichiers et stockage objet.
- BI et analytics pour dashboards, exploration en self-service et couches sémantiques.
- Reverse ETL pour pousser des données préparées vers CRM, marketing et systèmes support.
- Orchestration pour la planification, les dépendances, les backfills et la promotion d’environnements.
- Streaming pour événements quasi temps réel et capture de changement (CDC).
- Outils ML pour pipelines de features, workflows de training et monitoring de modèles.
Questions à poser avant de choisir des connecteurs
Tous les outils « compatibles Snowflake » ne se valent pas. Lors de l’évaluation, concentrez-vous sur des détails pratiques :
- Le connecteur est-il certifié/supporté (par qui) ? Quel est le chemin d’escalade ?
- Gère-t-il proprement les chargements incrémentaux (CDC, timestamps, high-water marks) ?
- Comment gère-t-il la dérive de schéma—nouvelles colonnes, changements de types, champs supprimés ?
- Quelles garanties sur retries, déduplication, exactly-once vs at-least-once ?
N’ignorez pas l’exploitation
Les intégrations ont aussi besoin d’une préparation pour le day‑2 : monitoring et alerting, hooks de lineage/catalogue et workflows d’incident response (ticketing, on-call, runbooks). Un écosystème solide, ce n’est pas juste plus de logos—c’est moins de surprises quand un pipeline casse à 2 h du matin.
Gouvernance, sécurité et confiance à l’échelle
Quand les équipes grandissent, la partie la plus difficile de l’analytics n’est souvent pas la vitesse—c’est de s’assurer que les bonnes personnes ont accès aux bonnes données, pour les bonnes raisons, avec la preuve que les contrôles fonctionnent. Les fonctionnalités de gouvernance de Snowflake sont conçues pour cette réalité : beaucoup d’utilisateurs, beaucoup de produits data et du partage fréquent.
Bases de gouvernance qui tiennent la route
Commencez avec des rôles clairs et une approche least-privilege. Plutôt que d’accorder l’accès directement aux individus, définissez des rôles comme ANALYST_FINANCE ou ETL_MARKETING, puis accordez ces rôles à des bases, schémas, tables et, si nécessaire, des vues.
Pour les champs sensibles (PII, identifiants financiers), utilisez des politiques de masquage pour que les personnes puissent interroger les datasets sans voir les valeurs brutes sauf si leur rôle le permet. Associez cela à l’audit : tracez qui a interrogé quoi et quand, afin que les équipes de sécurité et de conformité puissent répondre sans deviner.
Pourquoi la gouvernance change le partage et l’auto‑service
Une bonne gouvernance rend le partage plus sûr et plus scalable. Quand votre modèle de partage est basé sur des rôles, des politiques et des accès audités, vous pouvez activer en confiance l’auto-service (plus d’utilisateurs explorant les données) sans ouvrir la porte aux expositions accidentelles.
Ceci réduit aussi la friction pour la conformité : les politiques deviennent des contrôles répétables plutôt que des exceptions one-off. Cela compte quand des datasets sont réutilisés à travers projets, départements ou partenaires externes.
Astuces pratiques pour éviter la douleur future
- Conventions de nommage : standardisez les noms de bases/schémas pour signaler finalité et sensibilité (ex.
PROD_FINANCE, DEV_MARKETING, SHARED_PARTNER_X). La cohérence accélère les revues et réduit les erreurs.
- Séparation d’environnements : gardez DEV/TEST/PROD séparés logiquement, avec des contrôles plus stricts en PROD. Traitez les données de production comme l’exception, pas la norme.
- Revues d’accès : fixez un rythme (mensuel pour les données à haut risque, trimestriel autrement). Revoyez l’appartenance aux rôles, les utilisateurs inactifs et les rôles privilégiés.
La confiance à l’échelle tient moins à un contrôle « parfait » qu’à un système d’habitudes petites et fiables qui rendent les accès intentionnels et traçables.
Charges de travail et patterns recommandés
Affichez les KPI sur mobile
Créez une application Flutter pour vérifier les KPI et recevoir des alertes en utilisant votre modèle de données existant.
Snowflake brille quand beaucoup de personnes et d’outils doivent interroger les mêmes données pour des raisons différentes. Puisque le calcul est empaqueté en « entrepôts » indépendants, vous pouvez mapper chaque charge à une forme et un calendrier adaptés.
Mappage de charges courant
Analytics & dashboards : placez les outils BI sur un entrepôt dédié dimensionné pour un volume de requêtes stable et prévisible. Cela empêche les raffraîchissements de dashboards d’être ralentis par l’exploration ad hoc.
Analyse ad hoc : donnez aux analystes un entrepôt séparé (souvent plus petit) avec auto-suspend activé. Vous obtenez une itération rapide sans payer pour du temps inactif.
Data science & expérimentation : utilisez un entrepôt dimensionné pour des scans lourds et des pics occasionnels. Si les expériences montent en charge, scalez temporairement cet entrepôt sans affecter les utilisateurs BI.
Applications de données & analytique embarquée : traitez le trafic applicatif comme un service en production—entrepôt séparé, timeouts conservateurs et resource monitors pour éviter des dépenses surprises.
Si vous construisez des applications internes légères (par ex. un portail ops qui interroge Snowflake et affiche des KPIs), une voie rapide consiste à générer un scaffold React + API fonctionnel et itérer avec les parties prenantes. Des plateformes comme Koder.ai (une plateforme de vibe-coding qui construit des apps web/serveur/mobile depuis une conversation) peuvent aider les équipes à prototyper rapidement ces apps connectées à Snowflake, puis à exporter le code source quand vous êtes prêts à industrialiser.
Patterns recommandés qui tiennent dans le temps
Une règle simple : séparez les entrepôts par audience et par usage (BI, ELT, ad hoc, ML, app). Associez cela à de bonnes pratiques de requête—évitez les SELECT * larges, filtrez tôt et surveillez les jointures inefficaces. Côté modélisation, privilégiez des structures qui correspondent aux requêtes réelles (souvent une couche sémantique propre ou des marts bien définis), plutôt que d’over‑optimiser la disposition physique.
Quand envisager des alternatives ou des compléments
Snowflake n’est pas un remplaçant de tout. Pour des charges transactionnelles à très haut débit et faible latence (OLTP), une base spécialisée convient généralement mieux, avec Snowflake utilisé pour l’analytics, le reporting, le partage et les produits data en aval. Les architectures hybrides sont courantes—et souvent les plus pragmatiques.
Considérations de migration : quoi planifier avant de bouger
Une migration vers Snowflake est rarement un « lift and shift ». La séparation stockage/ calcul change la façon dont vous dimensionnez, optimisez et payez les charges—donc planifier en amont évite les surprises.
Séquence de migration pratique
Commencez par un inventaire : quelles sources alimentent l’entrepôt, quels pipelines le transforment, quels dashboards en dépendent et qui possède chaque élément. Priorisez ensuite par impact métier et complexité (par ex. reporting finance critique en premier, sandboxes expérimentaux plus tard).
Convertissez ensuite le SQL et la logique ETL. Une grande partie du SQL standard se transfère, mais des détails comme les fonctions, la gestion des dates, le code procédural et les patterns de tables temporaires nécessitent souvent des réécritures. Validez tôt : exécutez des sorties parallèles, comparez comptes de lignes et agrégats, et confirmez les cas limites (nulls, fuseaux horaires, logique de déduplication). Enfin, planifiez le cutover : fenêtre de gel, chemin de rollback et une définition claire de « done » pour chaque dataset et rapport.
Risques typiques à surveiller
Les dépendances cachées sont les plus courantes : un extract Excel, une chaîne de connexion codée en dur, un job aval dont plus personne ne se souvient. Des surprises de performance peuvent survenir lorsque les anciennes hypothèses d’optimisation ne s’appliquent plus (ex. surutiliser des entrepôts minces, ou exécuter beaucoup de petites requêtes sans tenir compte de la concurrence). Les pics de coût viennent souvent d’entrepôts laissés actifs, de retries incontrôlés ou de duplications dev/test. Les écarts d’autorisation apparaissent en migrant d’un modèle à rôles grossiers vers une gouvernance plus fine—les tests doivent inclure des parcours d’utilisateurs en « least privilege ».
Gestion du changement (ne la sautez pas)
Définissez un modèle de propriété (qui possède les données, les pipelines et les coûts), fournissez une formation par rôle pour analystes et ingénieurs, et définissez un plan de support pour les premières semaines après le cutover (rotation on-call, runbook d’incident et un canal pour remonter les problèmes).
Choisir une plateforme moderne de données ne se limite pas à la vitesse de pointe d’un benchmark. Il s’agit de savoir si la plateforme convient à vos charges réelles, à vos modes de travail et aux outils dont vous dépendez.
Checklist d’évaluation pratique
Utilisez ces questions pour guider votre short-list et vos conversations fournisseurs :
- Charges : exécutez-vous principalement des dashboards planifiés, de l’analyse ad hoc, de la data science, de l’ELT/ETL ou des apps orientées client ? Avez-vous besoin de fenêtres batch prévisibles ou d’une capacité élastique en rafales ?
- Besoins en concurrence : combien de personnes (ou d’applications) interrogeront simultanément, et à quel point l’usage est-il « en rafales » pendant les heures ouvrées ?
- Partage de données : devez-vous partager des données en direct avec des partenaires, business units ou clients sans expédier de fichiers ? Prévoyez-vous consommer des datasets tiers ?
- Compatibilité tooling : vos outils BI, d’orchestration, catalogue et CI/CD s’intègrent‑ils proprement ? Que se passe-t-il si vous migrez ?
- Gouvernance et sécurité : avez-vous besoin de contrôle d’accès fin, trails d’audit, masquage, politiques de rétention et séparation claire des tâches ?
- Contraintes de coût : quels coûts importent le plus—dépense en régime permanent, pics, ou capacité à éteindre le calcul ? Comment éviterez‑vous le gaspillage « always-on » ?
Plan pilote court (2–4 semaines)
Choisissez deux ou trois datasets représentatifs (pas des échantillons toys) : une grande table de faits, une source semi-structurée « sale » et un domaine critique métier.
Ensuite, exécutez des requêtes réelles : dashboards au pic du matin, exploration analyste, chargements planifiés et quelques jointures pires‑cas. Suivez : temps de requête, comportement en concurrence, temps d’ingestion, effort opérationnel et coût par charge.
Si votre évaluation inclut « à quelle vitesse pouvons‑nous livrer quelque chose d’utilisable », ajoutez une petite livraison au pilote—comme une appli interne de metrics ou un workflow gouverné de demandes de données qui requête Snowflake. Construire cette fine couche révèle souvent plus vite les réalités d’intégration et de sécurité qu’un benchmark seul, et des outils comme Koder.ai peuvent accélérer le passage du prototype à la production en générant la structure de l’app via le chat et en permettant d’exporter le code.
Étapes suggérées suivantes
Si vous voulez de l’aide pour estimer les coûts et comparer les options, commencez par /pricing.
Pour des conseils sur migration et gouvernance, consultez les articles associés dans /blog.