Ce qu'est le sharding (et ce que ce n'est pas)
Le sharding (appelé aussi partitionnement horizontal) consiste à présenter à votre application ce qui ressemble à une seule base de données tout en répartissant ses données sur plusieurs machines, appelées shards. Chaque shard contient seulement un sous-ensemble des lignes, mais ensemble ils représentent l'intégralité du jeu de données.
Une table logique, plusieurs emplacements physiques
Un modèle mental utile distingue structure logique et placement physique.
- Logique : vous avez toujours une table “Users” (mêmes colonnes, même sens).
- Physique : les lignes de cette table sont stockées à différents endroits — par exemple, les utilisateurs avec les IDs 1–1 000 000 sont sur le shard A, les suivants sur le shard B.
Du point de vue de l'application, on souhaite exécuter des requêtes comme s'il n'y avait qu'une table. En coulisses, le système doit décider vers quel(s) shard(s) diriger la requête.
Ce n'est pas de la réplication ni « acheter une machine plus grosse »
Le sharding diffère de la réplication. La réplication crée des copies des mêmes données sur plusieurs nœuds, principalement pour la haute disponibilité et le scaling des lectures. Le sharding divise les données : chaque nœud tient des enregistrements différents.
C'est aussi différent du scale vertical, où vous conservez une seule base et la migrez sur une machine plus puissante (plus de CPU/RAM/disques). Le scale vertical peut être plus simple, mais a des limites pratiques et coûte vite cher.
Ce que le sharding ne règle pas magiquement
Le sharding augmente la capacité, mais n'améliore pas automatiquement tous les aspects de performance :
- Les jointures peuvent devenir coûteuses si les lignes liées vivent sur des shards différents.
- Les transactions multi-shards sont plus difficiles ; les mises à jour « tout ou rien » nécessitent de la coordination.
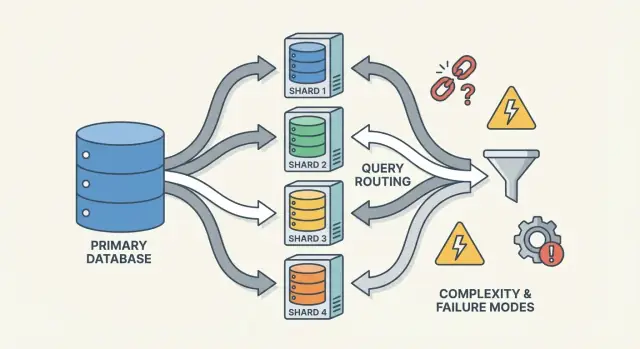
- La complexité opérationnelle augmente : routage, rééquilibrage, débogage et gestion des pannes deviennent partie intégrante du système.
Le sharding doit donc être compris comme un moyen de scaler le stockage et le débit — pas une mise à niveau gratuite de tous les comportements de la base.
Pourquoi les équipes shardent : les problèmes qu'on cherche à résoudre
Le sharding est rarement le premier choix. Les équipes y recourent généralement après qu'un système réussi ait atteint des limites physiques — ou quand la douleur opérationnelle devient fréquente. La motivation est moins « on veut sharder » que « il faut continuer à croître sans qu'une base unique soit un point de défaillance et de coût ».
Les douleurs qui poussent vers le sharding
Un nœud unique peut manquer de capacité de plusieurs façons :
- Limites de stockage : tables et index grossissent, le disque se remplit, les sauvegardes ralentissent et les opérations de maintenance deviennent risquées.
- Limites de débit d'écriture : CPU, WAL/redo ou contention sur les verrous plafonnent le nombre d'écritures par seconde.
- Limites de débit de lecture : même avec cache et réplicas, certains workloads peuvent submerger le primaire (ou les réplicas deviennent coûteux à scaler).
- Noisy neighbors : un locataire, client ou pattern d'utilisation monopolise les ressources et dégrade les autres.
Quand ces symptômes réapparaissent, le problème n'est souvent pas une requête isolée mais qu'une machine porte trop de responsabilité.
Les objectifs : scaler, isoler, maîtriser les coûts
Le sharding répartit données et trafic sur plusieurs nœuds pour que la capacité augmente en ajoutant des machines plutôt qu'en améliorant verticalement une seule. Bien fait, il peut aussi isoler les workloads (pour qu'un pic d'un locataire n'empêche pas les autres) et maîtriser les coûts en évitant des instances monolithiques très onéreuses.
Signes précurseurs que vous approcheZ du plafond
Des motifs récurrents : latences p95/p99 qui montent aux pics, lag de réplication plus long, sauvegardes/restaurations dépassant la fenêtre acceptable, et des petits changements de schéma devenant des événements majeurs.
Pourquoi le sharding est souvent l'ultime recours
Avant de s'engager, on épuise généralement les options plus simples : indexation et optimisation des requêtes, cache, réplicas en lecture, partitionnement de tables sur une seule instance, archivage des données anciennes, et upgrades matériels. Le sharding résout la montée en charge, mais ajoute coordination, complexité opérationnelle et nouveaux modes de panne — le seuil d'acceptation doit donc être élevé.
Les pièces centrales : shards, routeurs et métadonnées
Une base shardée n'est pas une seule chose — c'est un petit système de pièces coopérantes. Le sharding paraît « difficile à raisonner » parce que la correction et la performance dépendent de l'interaction de ces pièces, pas seulement du moteur de base.
Shards : partitions indépendantes (avec leurs propres index)
Un shard est un sous-ensemble des données, généralement stocké sur son propre serveur ou cluster. Chaque shard a typiquement :
- son propre stockage (fichiers de données)
- ses index (pour accélérer les requêtes dans ce shard)
- des limites locales (CPU, mémoire, disque, connexions)
Pour l'application, une configuration shardée tente souvent de ressembler à une base logique unique. Mais une requête qui serait « un seul lookup d'index » sur une base monoposte peut devenir « trouver le bon shard, puis faire le lookup ».
Un routeur (parfois appelé coordonnateur, query router ou proxy) est le chef d'orchestre. Il répond à la question pratique : pour cette requête, quel shard doit la traiter ?
Deux patterns courants :
- Routage côté client : la bibliothèque de l'application connaît la carte des shards et se connecte directement au shard approprié.
- Routage par proxy : l'app se connecte à un service routeur qui transfère la requête.
Les routeurs réduisent la complexité dans l'app, mais peuvent devenir un goulot d'étranglement ou un nouveau point de panne s'ils ne sont pas conçus avec soin.
Service de métadonnées/config : carte des shards, propriété et santé
Le sharding s'appuie sur des métadonnées — une source de vérité décrivant :
- la carte des shards (quel shard possède quelles plages/buckets/IDs)
- la propriété (surtout pendant les migrations, où la propriété peut se chevaucher temporairement)
- la santé et l'adhésion (quels nœuds sont up, rôles primaire/réplica, état de draining)
Ces informations vivent souvent dans un service de config (ou un petit « plan de contrôle »). Si les métadonnées sont périmées ou incohérentes, les routeurs peuvent envoyer du trafic au mauvais endroit — même si tous les shards sont sains.
Jobs en arrière-plan : équilibrage, migrations et sauvegardes
Le sharding dépend aussi de processus en arrière-plan qui maintiennent le système :
- rééquilibrage quand un shard croît plus vite que les autres
- migrations pour déplacer la propriété entre shards
- sauvegardes/restaurations qui fonctionnent sur de nombreux shards et respectent vos objectifs de récupération
Ces tâches sont faciles à ignorer tôt, mais elles provoquent beaucoup de surprises en production — car elles changent la topologie pendant que le service répond au trafic.
Choisir une clé de shard : le premier grand compromis
La clé de shard est le champ (ou la combinaison de champs) que votre système utilise pour déterminer quel shard stocke une ligne/document. Ce choix unique détermine silencieusement la performance, le coût, et même quelles fonctionnalités seront faciles plus tard — car il contrôle si les requêtes peuvent être routées vers un seul shard ou doivent se fan-out.
Qu'est-ce qui fait une bonne clé ?
Une bonne clé a tendance à avoir :
- Haute cardinalité : beaucoup de valeurs possibles (ex.
user_id plutôt que country).
- Distribution homogène : les valeurs répartissent lectures et écritures au lieu de tout concentrer.
- Patrons d'accès stables : elle correspond à la façon dont vous interrogez le plus aujourd'hui et à l'évolution prévue.
Exemple courant : sharder par tenant_id dans une app multi-tenant : la plupart des lectures/écritures d'un locataire restent sur un même shard, et les locataires sont assez nombreux pour répartir la charge.
Qu'est-ce qui fait une mauvaise clé (et pourquoi ça coûte cher)
Certaines clés garantissent presque la douleur :
- Clés monotones basées sur le temps (timestamps, IDs auto-incrémentés) : les nouvelles données s'accumulent sur le shard « le plus récent », créant un hotspot d'écriture.
- Champs basse cardinalité (status, plan_tier, pays) : trop peu de valeurs signifie que quelques shards font la majorité du travail.
- Identifiants mutables (email, pseudo modifiable) : si la clé change, déplacer les données entre shards devient coûteux et risqué.
Même si une clé basse cardinalité semble pratique pour filtrer, elle transforme souvent des requêtes routables en scatter-gather parce que les lignes correspondantes vivent partout.
Le vrai compromis : commodité des requêtes vs qualité de distribution
La meilleure clé pour équilibrer la charge n'est pas toujours la meilleure pour les requêtes produit.
- Choisir une clé alignée sur le pattern d'accès principal (ex.
user_id) et certaines requêtes globales (reporting admin) deviennent plus lentes ou nécessitent des pipelines séparés.
- Choisir une clé alignée pour le reporting (ex.
region) peut créer des hotspots et une capacité inégale.
La majorité des équipes optimisent la clé pour les opérations fréquentes et sensibles à la latence — et traitent le reste avec des index, de la dénormalisation, des réplicas ou des tables analytiques dédiées.
Stratégies courantes de sharding (Range, Hash, Directory)
Il n'y a pas une seule « meilleure » façon de shard-er. La stratégie choisie façonne la facilité de routage, l'uniformité de la répartition des données, et les types d'accès qui seront pénalisés.
Range sharding
Avec le range sharding, chaque shard possède une tranche contiguë d'un espace de clés — par exemple :
- Shard A : customer_id 1–1 000 000
- Shard B : customer_id 1 000 001–2 000 000
Le routage est simple : regardez la clé, choisissez le shard.
Le défaut : les hotspots. Si les nouveaux utilisateurs reçoivent des IDs croissants, le shard « dernier » devient le goulot d'écriture. Le range sharding est aussi sensible à la croissance inégale. L'avantage : les requêtes de type intervalle (« toutes les commandes du 1er au 31 octobre ») peuvent être efficaces car les données sont physiquement groupées.
Hash sharding
Le hash sharding applique une fonction de hachage sur la clé de shard et utilise le résultat pour choisir un shard. Cela répartit généralement les données plus uniformément et évite le problème du shard « le plus récent ».
Compromis : les requêtes par intervalle deviennent coûteuses. Une requête « customers avec ID entre X et Y » ne se limite plus à quelques shards ; elle peut toucher beaucoup d'entre eux.
Détail pratique souvent sous-estimé : le hachage cohérent. Plutôt que de mapper directement sur le nombre de shards (ce qui remapperait tout en ajoutant un shard), beaucoup de systèmes utilisent un anneau de hachage avec des « nœuds virtuels » pour que l'ajout de capacité ne déplace qu'une portion des clés.
Directory (lookup) sharding
Le directory sharding stocke une correspondance explicite (table/service) clé → emplacement du shard. C'est la plus flexible : vous pouvez placer des locataires sur des shards dédiés, déplacer un client sans tout remapper, et supporter des tailles de shards inégales.
Le revers : une dépendance supplémentaire. Si le répertoire est lent, périmé ou indisponible, le routage souffre — même si les shards sont sains.
Clés composites et sub-sharding
Les systèmes réels combinent souvent des approches. Une clé composite (ex. tenant_id + user_id) garde les locataires isolés tout en répartissant la charge à l'intérieur d'un locataire. Le sub-sharding fait de même : routez d'abord par locataire, puis hachez à l'intérieur du groupe pour éviter qu'un « gros locataire » n'occupe un seul shard.
Emportez le code
Conservez la pleine propriété en exportant le code source une fois le design satisfaisant.
Une base shardée a deux chemins de requête très différents. Comprendre lequel s'applique explique la plupart des surprises de performance — et pourquoi le sharding peut sembler imprévisible.
Requêtes sur un seul shard : le chemin rapide
Le résultat idéal est de router une requête vers exactement un shard. Si la requête contient la clé de shard (ou quelque chose que le routeur peut mapper), le système l'envoie directement au bon shard.
C'est pourquoi les équipes cherchent à rendre les lectures courantes « shard-key aware ». Un seul shard implique moins d'aller-retours réseau, une exécution plus simple, moins de verrous et beaucoup moins de coordination. La latence dépend surtout du travail de la base, pas du cluster qui discute.
Lectures scatter-gather : fan-out et latence tail
Quand une requête ne peut être routée avec précision (ex. filtre sur un champ non-clé), le système peut la diffuser à plusieurs ou tous les shards. Chaque shard exécute la requête localement, puis le routeur/coordonnateur fusionne les résultats — tri, déduplication, application de LIMIT, agrégats partiels.
Ce fan-out amplifie la latence tail : même si 9 shards répondent vite, un shard lent peut retenir la requête entière. Cela multiplie aussi la charge : une requête utilisateur devient N requêtes shard.
Joins et agrégations inter-shards
Les joins entre shards sont coûteux car des données qui se trouveraient « à l'intérieur » d'une base unique doivent maintenant circuler entre shards (ou vers un coordonnateur). Même des agrégations simples (COUNT, SUM, GROUP BY) peuvent nécessiter un plan en deux phases : calculer des résultats partiels sur chaque shard, puis les fusionner.
Limites d'indexation : local vs global
La plupart des systèmes utilisent par défaut des index locaux : chaque shard n'indexe que ses propres données. Ils sont peu coûteux à maintenir, mais n'aident pas le routage — les requêtes peuvent toujours scatter.
Des index globaux peuvent permettre le routage ciblé sur des champs non-clés, mais ils ajoutent un surcoût d'écriture, de la coordination et leurs propres problèmes de scalabilité et de cohérence.
Écritures et transactions multi-shards
C'est sur les écritures que le sharding cesse d'être « juste du scale » et commence à changer la conception des fonctionnalités. Une écriture qui touche un shard peut être rapide ; une écriture qui en touche plusieurs devient lente, sujette aux pannes et difficile à garantir correcte.
Écritures sur un seul shard : le chemin heureux
Si chaque requête peut être routée vers un seul shard (via la clé de shard), la base utilise sa machinerie transactionnelle normale. On obtient atomicité et isolation dans ce shard, et la plupart des problèmes opérationnels ressemblent à ceux d'une base monoposte — multipliée par N.
Écritures multi-shards : la complexité monte en flèche
Quand une action logique doit mettre à jour plusieurs shards (ex. transfert d'argent, déplacement d'une commande), on entre dans le domaine des transactions distribuées.
Les transactions distribuées sont difficiles car elles requièrent une coordination entre machines qui peuvent être lentes, partitionnées ou redémarrées. Les protocoles de type two-phase commit ajoutent des allers-retours, peuvent se bloquer sur des timeouts et rendent les échecs ambigus : le shard B a-t-il appliqué le changement avant que le coordinateur ne meure ? Si le client réessaie, double-applique-t-on l'écriture ? Si on n'essaie pas, perd-on l'opération ?
Patterns pour éviter les écritures inter-shards
Quelques tactiques réduisent la fréquence des transactions multi-shards :
- Localité des données : co-localiser les enregistrements liés sur le même shard (tout pour un client sur le même shard).
- Routage des requêtes : faire en sorte qu'une opération soit possédée par un seul shard et considérer les autres comme sources en lecture.
- Dénormalisation : dupliquer de petits fragments de données pour éviter des mises à jour en fan-out.
Idempotence et sécurité des retries
Dans les systèmes shardés, les retries sont inévitables. Rendez les écritures idempotentes en utilisant des IDs d'opération stables (ex. clé d'idempotence) et en stockant des marqueurs « déjà appliqué ». Ainsi, si un timeout survient et que le client réessaie, la seconde tentative devient un no-op au lieu d'une double facturation ou d'un doublon.
Cohérence et réplication : garder les données correctes
Tester les écritures inter-shards
Testez les clés d'idempotence et les écritures résistantes aux retries dans un petit service jetable.
Le sharding répartit les données, mais n'enlève pas le besoin de redondance. La réplication maintient un shard disponible quand un nœud meurt — et rend plus difficile la réponse à « que reflète la vérité maintenant ? ».
Réplication à l'intérieur de chaque shard
La plupart des systèmes répliquent à l'intérieur de chaque shard : un primaire accepte les écritures, un ou plusieurs réplicas copient ces changements. Si le primaire échoue, on promeut un réplique. Les réplicas peuvent aussi servir des lectures.
Le compromis est temporel : un réplica peut être en retard de quelques millisecondes — voire secondes. Cet écart est normal, mais il compte quand l'utilisateur attend de voir immédiatement sa mise à jour.
Modèles de cohérence, en termes simples
- Cohérence forte : après qu'une écriture a réussi, les lectures la reflètent (selon les garanties du système). Souvent cela implique de lire depuis le leader ou d'attendre les réplicas.
- Cohérence éventuelle : le système converge, mais une lecture peut temporairement retourner d'anciennes données.
Dans les architectures shardées, on obtient souvent une cohérence forte au sein d'un shard et des garanties plus faibles entre shards, en particulier pour les opérations multi-shards.
« Source unique de vérité » quand les données sont réparties
Avec le sharding, « source unique de vérité » signifie généralement : pour chaque morceau de données, il existe un lieu d'écriture autoritaire (souvent le leader du shard). Mais globalement, il n'y a pas de machine capable de confirmer instantanément l'état de tout. On a plusieurs vérités locales à synchroniser via la réplication.
Contraintes globales : unicité, clés étrangères, compteurs
Les contraintes globales sont difficiles lorsque les données à vérifier résident sur différents shards :
- Unicité globale (ex. username) : imposer « pas de doublons partout » peut nécessiter un index centralisé, un shard de contrainte dédié, ou un workflow applicatif de réservation.
- Clés étrangères : si parent/enfant sont sur des shards différents, la base ne peut pas facilement imposer l'intégrité référentielle sans coordination.
- Compteurs (totaux globaux, IDs séquentiels) : les approches naïves créent un goulot. Solutions courantes : plages par shard, batching, ou accepter des approximations.
Ces choix ne sont pas de simples détails d'implémentation — ils définissent ce que « correct » signifie pour votre produit.
Rééquilibrage et resharding sans interruption
Le rééquilibrage maintient la viabilité d'une base shardée à mesure que la réalité change : croissance inégale, dérive du bon équilibrage, ajout de nœuds, retraite de matériel. N'importe lequel de ces événements peut transformer un shard parfait en nouveau goulot.
Pourquoi c'est difficile
Contrairement à une base unique, le sharding intègre la localisation des données dans la logique de routage. Déplacer des données ne copie pas que des octets — on change aussi où les requêtes doivent aller. Le rééquilibrage concerne donc autant les métadonnées et les clients que le stockage.
Pattern de migration en ligne (copier → chevauchement → cutover)
Le flux en ligne typique vise à éviter une fenêtre « stop the world » :
- Copie : backfiller la/les shard(s) cible(s) depuis la source pendant que le système est en ligne.
- Écriture double (parfois lecture double) : pendant la transition, écrire les nouvelles modifications sur les emplacements ancien et nouveau. Les lectures peuvent consulter les deux (ou appliquer une règle « new wins ») jusqu'à stabilisation.
- Cutover : mettre à jour la shard map pour que routers/clients envoient le trafic vers le nouvel emplacement.
- Nettoyage : arrêter les écritures doubles, supprimer l'ancienne copie, compacter/récupérer l'espace.
Cartes de shards et comportement client
Un changement de shard map casse si les clients cachent leurs décisions de routage. Les bons systèmes traitent les métadonnées de routage comme de la configuration : les versionner, les rafraîchir fréquemment, et définir explicitement le comportement lorsqu'un client adresse une clé déplacée (redirect, retry, ou proxy).
Risques opérationnels à planifier
Le rééquilibrage provoque souvent des baisses temporaires de perf (écritures additionnelles, churn de cache, charge de copie en arrière-plan). Les migrations partielles sont courantes — certaines plages migrent avant d'autres — donc prévoyez une observabilité claire et un plan de rollback avant le cutover.
Le sharding suppose que la charge va se répartir. La surprise est qu'un cluster peut paraître « équilibré » en nombre de lignes tout en se comportant de façon très inégale en production.
Partitions chaudes (hot keys)
Un hotspot survient quand une petite portion de l'espace de clés concentre la majorité du trafic — compte célèbre, produit viral, un locataire qui lance un job, ou une clé temporelle où « aujourd'hui » attire tout. Si ces clés mappent à un seul shard, ce shard devient le goulot même si les autres sont au repos.
Skew : taille des données vs trafic
Le « skew » n'est pas unique :
- Skew de données : un shard contient davantage d'octets/lignes (pression de stockage, sauvegardes longues, scans lents).
- Skew de trafic : un shard reçoit plus de QPS ou des requêtes plus lourdes (saturation CPU, files d'attente, latence).
Ils ne concordent pas forcément : un shard moins volumineux peut être le plus chaud s'il possède les clés les plus demandées.
Détection rapide
Commencez par des dashboards par shard :
- p95 par shard (si un shard diverge, c'est un indicateur)
- QPS total / QPS d'écriture par shard
- Espace de stockage / taille des tables par shard
Si la latence d'un shard monte avec son QPS pendant que les autres restent stables, vous avez probablement un hotspot.
Mitigations
Les remèdes échangent simplicité contre équilibre :
- Choisir une clé qui répartit le trafic, pas seulement les enregistrements.
- Ajouter du bucketing/salting pour les clés chaudes (diviser une clé logique sur plusieurs buckets physiques).
- Mettre en cache les objets très lus.
- Appliquer des quotas ou rate limits pour protéger le cluster.
- Scinder ou déplacer les shards chauds quand on ne parvient pas à les refroidir.
Modes de panne et débogage dans un système shardé
Gagnez des crédits pour du contenu
Gagnez des crédits en partageant ce que vous avez appris en construisant sur Koder.ai.
Le sharding ajoute non seulement des serveurs, mais aussi des façons supplémentaires de casser des choses, et des lieux supplémentaires à inspecter. Beaucoup d'incidents ne sont pas « la base est down » mais « un shard est down » ou « le système ne sait plus où résident les données ».
Modes de panne fréquents
- Shard indisponible (crash, disque plein, pauses GC longues) → pannes partielles : certains clients fonctionnent, d'autres échouent.
- Mauvais routage par les routeurs, souvent après un changement de config ou un déploiement : des lectures peuvent renvoyer des résultats vides si elles sont envoyées au mauvais shard.
- Métadonnées périmées ou incohérentes (shard map, table de directory) : pendant des moves/splits, différents composants peuvent router une même clé différemment.
- Problèmes réseau partiels : timeouts entre routeurs et sous-ensemble de shards → erreurs aléatoires et retries qui amplifient la charge.
Sur une base monoposte, on suit un seul log et des métriques. Dans un système shardé, il faut l'observabilité qui suit une requête à travers les shards.
- Utilisez des correlation IDs dans chaque requête et propagez-les depuis l'API jusqu'aux shards.
- Ajoutez du tracing distribué pour voir quel shard a été lent ou a échoué dans une requête scatter-gather.
- Décomposez les métriques par shard (latence, profondeur de file, taux d'erreur) — sinon un shard chaud est masqué par des moyennes sur la flotte.
Incidents d'intégrité des données
Les échecs liés au sharding apparaissent souvent comme des bugs de correction :
- Doublons après retries non idempotents
- Lignes manquantes quand une migration a déplacé des données mais le routage pointe encore vers l'ancien emplacement
- Écritures split-brain si deux vues de métadonnées acceptent des écritures sur la même plage
Sauvegarde, restauration et DR
« Restaurer la base » devient « restaurer plusieurs pièces dans le bon ordre ». Il peut être nécessaire de restaurer d'abord les métadonnées, puis chaque shard, et vérifier que les frontières et règles de routage correspondent au point de restauration. Les plans DR doivent inclure des répétitions pour prouver qu'on peut réassembler un cluster cohérent, pas seulement récupérer des machines individuelles.
Quand ne pas shard-er : alternatives pratiques et checklist de décision
Le sharding est souvent présenté comme l'interrupteur de montée en charge, mais c'est aussi une augmentation permanente de la complexité. Si vous pouvez atteindre vos objectifs de perf et de fiabilité sans répartir les données, vous aurez généralement une architecture plus simple, un débogage plus facile et moins de cas limites opérationnels.
Alternatives pratiques qui donnent souvent beaucoup de marge
Avant de shard-er, essayez :
- Meilleurs index + tuning des requêtes : corriger d'abord les chemins lents — indexes manquants, requêtes non bornées, joins coûteux, patterns N+1.
- Caching : mettre les réponses stables et lourdes derrière un cache (cache applicatif, CDN pour du contenu public, ou cache en mémoire pour clés chaudes).
- Réplicas en lecture : décharger les lectures sans changer le chemin d'écriture (en acceptant le lag des réplicas là où il est tolérable).
- Partitionnement de tables sur une seule instance : beaucoup de SGBD supportent le partitionnement qui améliore maintenance et requêtes sans routage cross-node.
Prototyper des services shard-aware sans tout engager
Une manière pratique de réduire les risques est de prototyper le plumbing (bornes de routage, idempotence, workflows de migration, observabilité) avant d'engager la prod.
Par exemple, avec Koder.ai vous pouvez rapidement déployer un petit service réaliste depuis un chat — souvent une UI d'administration React plus un backend Go et PostgreSQL — et expérimenter des APIs conscience de la clé de shard, des clés d'idempotence et des comportements de cutover dans un bac à sable. Grâce au mode planning, aux snapshots/rollback et à l'export du code source, on peut itérer sur les décisions de sharding (routage, forme des métadonnées) puis reprendre le code et les runbooks dans la stack principale.
Quand le sharding convient (et quand non)
Le sharding convient mieux quand votre dataset ou votre débit d'écriture dépasse clairement les limites d'un nœud et que vos patrons de requêtes peuvent majoritairement être routés par une clé de shard (peu de joins cross-shard, peu de scatter-gather).
Il est inadapté quand le produit nécessite beaucoup de requêtes ad hoc, des transactions multi-entités fréquentes, des contraintes d'unicité globale, ou quand l'équipe ne peut pas assumer la charge opérationnelle (resharding, rééquilibrage, gestion d'incidents).
Checklist rapide de décision
Demandez-vous :
- Workload : le goulot est-il CPU, I/O, mémoire ou contention de locks — et peut-il être levé sans sharding ?
- Patrons de requêtes : est-ce que 90%+ des requêtes critiques peuvent être routées par une clé de shard ?
- Capacité de l'équipe : qui gère la shard map, les runbooks on-call et le comportement des transactions cross-shard ?
- SLOs : pouvez-vous tolérer des dégradations partielles (un shard down) et des latences tail plus longues ?
Concevoir pour la croissance, pas seulement pour le diagramme
Même si vous retardez le sharding, planifiez une voie de migration : choisissez des identifiants qui ne bloqueront pas une clé de shard future, évitez d'encapsuler des hypothèses monocœur, et répétez comment vous déplaceriez les données avec un downtime minimal. Le meilleur moment pour préparer le resharding est avant d'en avoir besoin.