Ce que « Distributed SQL » signifie (sans le battage médiatique)
« Distributed SQL » désigne une base de données qui ressemble et se comporte comme une base relationnelle traditionnelle — tables, lignes, jointures, transactions et SQL — mais conçue pour s'exécuter en cluster sur plusieurs machines (et souvent sur plusieurs régions) tout en se comportant comme une seule base logique.
Cette combinaison est importante parce qu'elle cherche à fournir trois choses à la fois :
- SQL et modélisation relationnelle : schémas familiers, contraintes et outils de requête.
- Mise à l'échelle horizontale : ajouter des nœuds pour augmenter la capacité, plutôt que « acheter un serveur plus puissant ».
- Cohérence forte : lectures et écritures suivent des règles transactionnelles claires, même lorsque les données sont réparties.
Entre les SGBDR classiques et le NoSQL
Un SGBDR classique (comme PostgreSQL ou MySQL) est généralement le plus simple à exploiter lorsque tout vit sur un nœud primaire. On peut mettre à l'échelle les lectures avec des réplicas, mais mettre à l'échelle les écritures et survivre à des pannes régionales requiert souvent une architecture additionnelle (sharding, basculement manuel et logique applicative soigneuse).
De nombreux systèmes NoSQL ont pris l'approche opposée : d'abord l'échelle et la haute disponibilité, parfois en relâchant les garanties de cohérence ou en offrant des modèles de requête plus simples.
Distributed SQL vise une voie médiane : conserver le modèle relationnel et les transactions ACID, mais distribuer automatiquement les données pour gérer la croissance et les pannes.
Ce qu'il essaye de résoudre
Les bases de données Distributed SQL sont conçues pour des problèmes comme :
- Applications globales avec des utilisateurs dans plusieurs régions, où latence et disponibilité comptent.
- Haute disponibilité sans procédures de basculement manuelles complexes.
- Croissance dans le temps, où vous voulez étendre la capacité progressivement et garder une interface de base de données unique.
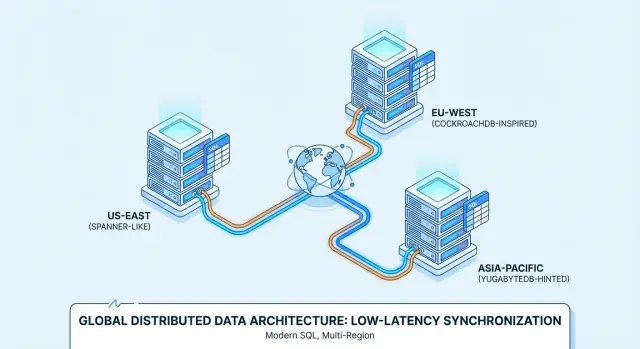
C'est pourquoi des produits comme Google Spanner, CockroachDB et YugabyteDB sont souvent évalués pour des déploiements multi‑régions et des services toujours disponibles.
Fixez les attentes (ce n'est pas la norme)
Distributed SQL n'est pas automatiquement « meilleur ». Vous acceptez plus de composants en mouvement et des réalités de performance différentes (sauts réseau, consensus, latence inter‑régions) en échange de résilience et d'échelle.
Si votre charge tient sur une seule base bien gérée avec une réplication simple, un SGBDR conventionnel peut être plus simple et moins coûteux. Distributed SQL rentabilise son coût quand l'alternative est le sharding personnalisé, un basculement complexe ou des exigences métiers demandant cohérence multi‑régions et disponibilité.
Distributed SQL vise à donner l'impression d'une base SQL familière tout en stockant les données sur plusieurs machines (et souvent plusieurs régions). La difficulté consiste à coordonner de nombreux ordinateurs pour qu'ils se comportent comme un système unique et fiable.
Chaque morceau de données est typiquement copié sur plusieurs nœuds (réplication). Si un nœud échoue, une autre copie peut toujours servir les lectures et accepter des écritures.
Pour éviter que les réplicas divergent, les systèmes Distributed SQL utilisent des protocoles de consensus — le plus souvent Raft (CockroachDB, YugabyteDB) ou Paxos (Spanner). En bref, le consensus signifie :
- Un replica agit comme « leader » pour un groupe de réplicas.
- Les écritures vont au leader.
- Le leader confirme l'écriture seulement après qu'une majorité de réplicas l'ait acquittée.
Ce « vote de majorité » est ce qui vous donne la cohérence forte : une fois une transaction validée, les autres clients ne verront pas une version plus ancienne des données.
Sharding/partitionnement : où vivent les données
Aucune machine unique ne peut tout contenir, donc les tables sont divisées en morceaux plus petits appelés shards/partitions (Spanner les appelle splits ; CockroachDB les appelle ranges ; YugabyteDB les appelle tablets).
Chaque partition est répliquée (via consensus) et placée sur des nœuds spécifiques. Le placement n'est pas aléatoire : vous pouvez l'influencer par des politiques (par exemple, garder les enregistrements clients EU dans les régions EU, ou placer les partitions « chaudes » sur des nœuds plus rapides). Un bon placement réduit les voyages réseau et rend la performance plus prévisible.
Transactions à travers les nœuds (et pourquoi ça ajoute de la latence)
Avec une base de données mono‑nœud, une transaction peut souvent valider avec du travail disque local. En Distributed SQL, une transaction peut toucher plusieurs partitions — potentiellement sur différents nœuds.
Valider en toute sécurité exige généralement une coordination supplémentaire :
- Verrouiller ou valider les données sur les partitions impliquées
- Répliquer les écritures via consensus (accusés de majorité)
- Finaliser une décision de commit pour que tous les participants s'accordent
Ces étapes introduisent des allers‑retours réseau, d'où la latence supplémentaire des transactions distribuées — particulièrement quand les données traversent des régions.
Comportement multi‑régions : lectures/écritures conscientes de la localité
Quand les déploiements s'étendent sur des régions, les systèmes tentent de garder les opérations « proches » des utilisateurs :
- Lectures conscientes de la localité peuvent être servies depuis des réplicas proches quand c'est sûr.
- Écritures conscientes de la localité peuvent router vers des leaders dans une région choisie, ou placer des leaders près des principaux rédacteurs.
C'est l'équilibre central en multi‑régions : vous pouvez optimiser la réactivité locale, mais la cohérence forte à grande distance paie toujours un coût réseau.
Quand vous en avez réellement besoin (et quand non)
Avant d'adopter le distributed SQL, vérifiez vos besoins de base. Si vous avez une région primaire unique, une charge prévisible et une petite équipe d'ops, un SGBDR conventionnel (ou un Postgres/MySQL managé) est généralement la façon la plus simple de livrer rapidement des fonctionnalités. Vous pouvez souvent pousser une architecture mono‑région loin avec des réplicas en lecture, du cache et une bonne conception de schéma/index.
Déclencheurs clairs : quand Distributed SQL en vaut la peine
Distributed SQL mérite une vraie considération quand une (ou plusieurs) de ces conditions est vraie :
- Vous avez de vrais utilisateurs dans plusieurs régions et vous voulez que la base soit proche d'eux sans sharding applicatif complexe.
- Les exigences d'uptime sont élevées (p.ex. résister à la perte de zone/région) et une région primaire unique est un risque inacceptable.
- Le volume de données ou le débit d'écriture dépasse l'échelle verticale, et vous voulez une montée en charge horizontale tout en conservant la sémantique SQL.
- Vous avez besoin de cohérence forte entre nœuds/régions pour des transactions critiques (commandes, soldes, réservations) sans assembler plusieurs systèmes.
- La conformité impose un placement géographique (résidence des données) tout en nécessitant une base logique unique.
Anti‑déclencheurs : quand ce n'est généralement pas la bonne solution
Les systèmes distribués ajoutent complexité et coût. Soyez prudent si :
- Votre équipe est réduite et n'a pas le temps d'apprendre de nouveaux modes de défaillance et patterns opérationnels.
- Le trafic est faible ou sporadique et vous ne dépasserez probablement pas une base mono‑région bientôt.
- Vous avez des budgets de latence très serrés pour des écritures sur clé unique et ne pouvez pas tolérer la surcharge de coordination de la cohérence forte.
- Votre charge est orientée analytique (gros scans, rapports complexes). Il est souvent préférable de séparer OLTP et analytique.
Checklist rapide de décision
Si vous pouvez répondre “oui” à deux ou plus, le distributed SQL mérite d'être évalué :
- Avez‑vous besoin de multi‑région avec des données cohérentes ?
- Avez‑vous besoin d'un basculement automatique entre zones/régions ?
- La montée en charge devient‑elle une crise récurrente ?
- Le sharding ajouterait‑il plus de surcharge d'ingénierie que la base elle‑même ?
- Devez‑vous faire respecter la résidence des données avec un modèle opérationnel unique ?
Cohérence, disponibilité et latence : les compromis essentiels
Distributed SQL semble promettre « tout avoir », mais les systèmes réels imposent des choix — surtout quand les régions ne peuvent pas communiquer de façon fiable.
CAP, expliqué pour les décisions produit
Considérez une partition réseau comme « le lien entre régions est instable ou coupé ». À ce moment, une base peut prioriser :
- Cohérence : tout le monde voit la même réponse à jour (ou l'opération échoue).
- Disponibilité : l'application continue d'accepter lectures/écritures dans chaque région (même si les réponses divergent temporairement).
Les systèmes Distributed SQL sont généralement conçus pour favoriser la cohérence pour les transactions. C'est souvent ce que les équipes veulent — jusqu'à ce qu'une partition rende certaines opérations bloquantes ou échouantes.
Cohérence forte (et pourquoi l'argent et l'inventaire s'en soucient)
La cohérence forte signifie qu'une fois une transaction validée, toute lecture ultérieure renverra cette valeur validée — pas de « ça a marché dans une région mais pas dans une autre ». C'est critique pour :
- Paiements et soldes (évite la double‑dépense ou des totaux incorrects)
- Inventaire / réservations (préserve contre la survente du dernier article)
Si votre promesse produit est « quand nous confirmons, c'est réel », la cohérence forte est une fonctionnalité, pas un luxe.
Read‑your‑writes et isolation dans les applications réelles
Deux comportements pratiques importent :
- Read‑your‑writes : après qu'un utilisateur a mis à jour son profil (ou passé une commande), l'écran suivant doit afficher le nouvel état, pas un ancien réplique.
- Isolation des transactions : définit comment les actions concurrentes interagissent. Avec une isolation plus forte, vous évitez des bogues subtils comme deux clients réservant simultanément le même siège.
Le coût en latence du consensus inter‑régions
La cohérence forte entre régions nécessite généralement du consensus (plusieurs réplicas doivent s'accorder avant le commit). Si les réplicas sont répartis entre continents, la vitesse de la lumière devient une contrainte produit : chaque écriture cross‑région peut ajouter des dizaines à des centaines de millisecondes.
Le compromis est simple : plus de sécurité géographique et de correction implique souvent une latence d'écriture plus élevée, à moins de choisir soigneusement où résident les données et où les transactions peuvent être validées.
Spanner vs CockroachDB vs YugabyteDB : un aperçu pratique
Google Spanner est une base Distributed SQL proposée principalement comme service managé sur Google Cloud. Elle est conçue pour des déploiements multi‑régions où vous voulez une seule base logique avec des données répliquées entre nœuds et régions. Spanner propose deux options de dialecte SQL — GoogleSQL (son dialecte natif) et un dialecte compatible PostgreSQL — donc la portabilité varie selon votre choix.
CockroachDB est une base Distributed SQL qui vise à être familière pour les équipes habituées à PostgreSQL. Elle utilise le protocole wire PostgreSQL et supporte une large partie du SQL de style Postgres, mais ce n'est pas un remplaçant byte‑pour‑byte de Postgres (certaines extensions et comportements limites diffèrent). Vous pouvez l'utiliser en service managé (CockroachDB Cloud) ou l'auto‑héberger.
YugabyteDB est une base distribuée avec une API SQL compatible PostgreSQL (YSQL) et une API additionnelle compatible Cassandra (YCQL). Comme CockroachDB, elle est souvent évaluée par des équipes qui veulent l'ergonomie Postgres tout en s'étendant sur nœuds et régions. Elle est disponible en auto‑hébergement et en offre managée (YugabyteDB Managed).
Managé vs auto‑hébergé : ce qui change
Les offres managées réduisent typiquement le travail opérationnel (mises à jour, sauvegardes, intégrations de monitoring), tandis que l'auto‑hébergement donne plus de contrôle sur le réseau, les types d'instances et l'emplacement des données. Spanner est principalement consommé en mode managé sur GCP ; CockroachDB et YugabyteDB sont souvent vus dans des modèles managés et auto‑hébergés, y compris multi‑cloud et sur site.
Compatibilité SQL en pratique
Tous les trois parlent « SQL », mais la compatibilité quotidienne dépend du choix de dialecte (Spanner), de la couverture des fonctionnalités Postgres (CockroachDB/YugabyteDB) et de votre dépendance à des extensions, fonctions ou sémantiques transactionnelles spécifiques de Postgres.
Tester vos requêtes, migrations et le comportement de l'ORM tôt paie : ne supposez pas une équivalence immédiate.
Cas d'utilisation : SaaS global avec utilisateurs régionaux
Planifiez votre topologie
Cartographiez les régions, les tenants et les règles de résidence des données avant d'écrire les migrations.
Un cas classique pour Distributed SQL est un produit SaaS B2B avec des clients en Amérique du Nord, Europe et APAC — outils de support, plateformes RH, tableaux de bord analytiques ou marketplaces.
L'exigence métier est simple : les utilisateurs veulent une réactivité « locale », tandis que l'entreprise souhaite une seule base logique toujours disponible.
Résidence des données et placement par client
Beaucoup d'équipes SaaS se retrouvent avec un mélange d'exigences :
- Les clients EU s'attendent à ce que leurs données restent dans l'UE (RGPD, engagements contractuels).
- Certains clients exigent un stockage dans le pays (p.ex. Allemagne, Australie, Singapour).
- D'autres ne s'en soucient pas, mais veulent une faible latence.
Distributed SQL peut modéliser cela proprement avec une localité par client : placez les données primaires de chaque client dans une région spécifique (ou ensemble de régions) tout en conservant le même schéma et modèle de requête sur l'ensemble du système. Vous évitez ainsi la prolifération de « une base par région » tout en respectant les exigences de résidence.
Minimiser la latence : lectures régionales et placement des écritures
Pour garder l'application rapide, on vise typiquement :
- Lectures régionales : servir les requêtes majoritairement en lecture depuis des réplicas proches de l'utilisateur.
- Placement des écritures : positionner le leader d'écriture (ou le jeu principal de réplicas) dans la région d'où proviennent le plus souvent les écritures du tenant.
Cela compte car les allers‑retours inter‑régions dominent la latence perçue par l'utilisateur. Même avec cohérence forte, une bonne conception de localité garantit que la plupart des requêtes n'assument pas un coût intercontinental.
Réalités opérationnelles
Les gains techniques ne comptent que si l'exploitation reste gérable. Pour un SaaS global, prévoyez :
- Changements de schéma en ligne qui n'empêchent pas les opérations entre régions.
- Migrations de tenants (déplacer un client d'une région à une autre avec un minimum d'interruption).
- Monitoring et alerting pour la latence de réplication, les hotspots, les requêtes lentes et les incidents régionaux.
Bien fait, le distributed SQL vous donne une expérience produit unique qui reste locale — sans diviser l'équipe d'ingénierie en « stack EU » et « stack APAC ».
Cas d'utilisation : flux financiers et grands‑livres
Les systèmes financiers sont l'endroit où l'« eventual consistency » peut se traduire par de vraies pertes d'argent. Si un client passe une commande, une autorisation est demandée et un solde est mis à jour, ces étapes doivent s'accorder sur une vérité unique — immédiatement.
La cohérence forte est essentielle car elle évite que deux régions (ou deux services) prennent chacune une décision « raisonnable » qui aboutit à un grand‑livre incorrect.
Pourquoi la cohérence forte est non négociable
Dans un flux typique — créer commande → réserver fonds → capturer paiement → mettre à jour grand‑livre/solde — vous voulez des garanties comme :
- Une commande ne peut pas être marquée « payée » si la capture de paiement n'a pas eu lieu.
- Un solde ne peut pas devenir négatif parce que deux transactions se sont chevauchées.
- Un remboursement ne peut pas être appliqué deux fois à cause de retraits.
Distributed SQL convient ici car il fournit des transactions ACID et des contraintes à travers les nœuds (et souvent les régions), donc vos invariants comptables tiennent même en cas de défaillances.
Idempotence et modèles « pas de double facturation »
Les intégrations de paiement provoquent souvent des réessais : timeouts, webhooks répétés et re‑traitements de jobs sont normaux. La base doit vous aider à rendre ces réessais sûrs.
Une approche pratique est d'associer des clés d'idempotence applicatives à des contraintes de base :
- Stocker un
idempotency_key par client/tentative de paiement.
- Ajouter une contrainte unique sur
(account_id, idempotency_key).
- Enrober « créer l'enregistrement de paiement + appliquer les entrées du grand‑livre » dans une transaction unique.
Ainsi, la seconde tentative devient une no‑op inoffensive plutôt qu'une double facturation.
Gérer les pics sans rompre la correction
Les événements commerciaux et les paies peuvent provoquer des pics d'écritures soudains (autorisations, captures, transferts). Avec Distributed SQL, vous pouvez monter en charge en ajoutant des nœuds pour augmenter le débit d'écriture tout en conservant le même modèle de cohérence.
L'important est d'anticiper les clés « chaudes » (p.ex. un compte marchand recevant tout le trafic) et d'utiliser des schémas qui répartissent la charge.
Les flux financiers exigent souvent des pistes d'audit immuables, une traçabilité (qui/quoi/quand) et des politiques de rétention prévisibles. Sans cibler une réglementation précise, supposez que vous aurez besoin : d'entrées de grand‑livre append‑only, d'enregistrements horodatés, d'un contrôle d'accès et de règles de rétention/archivage qui ne compromettent pas l'auditabilité.
Cas d'utilisation : inventaire, réservations et bookings
Conservez le contrôle de votre stack
Gardez le code source pour pouvoir continuer dans votre dépôt lorsque le prototype est prêt.
L'inventaire et les réservations semblent simples jusqu'à ce que plusieurs régions desservent la même ressource rare : le dernier siège, un produit en quantité limitée ou une chambre d'hôtel pour une nuit précise.
Le problème n'est pas de lire la disponibilité — c'est d'empêcher deux personnes de réclamer le même article presque simultanément.
D'où viennent les conflits
Dans un déploiement multi‑régions sans cohérence forte, chaque région peut temporairement croire que l'inventaire est disponible en se basant sur des données légèrement périmées. Si deux utilisateurs finalisent l'achat dans différentes régions pendant cette fenêtre, les deux transactions peuvent être acceptées localement puis entrer en conflit lors de la réconciliation.
C'est ainsi que survient la survente inter‑régions : pas parce que le système est « faux », mais parce qu'il a autorisé des vérités divergentes pendant un instant.
Distributed SQL est souvent choisi ici car il peut imposer un résultat unique et autoritatif pour les allocations d'écritures — ainsi « le dernier siège » n'est réellement attribué qu'une seule fois, même si les requêtes viennent de continents différents.
Exemples concrets
- Réservation de siège : Deux utilisateurs cliquent sur la même place. Avec la cohérence forte, une seule transaction commit ; l'autre échoue immédiatement et l'UI peut demander un rafraîchissement.
- Drops limités : 500 articles sont mis en vente et des milliers tentent de payer. Vous voulez un décrément‑et‑allocation atomique, pas un « best effort » suivi de remboursements.
- Réservations d'hôtel : l'unité d'inventaire est la room‑night. La double‑réservation d'une plage de dates coûte cher et est difficile à corriger.
Patterns courants qui vont bien avec Distributed SQL
Hold + confirm : placer un hold temporaire (un enregistrement de réservation) dans une transaction, puis confirmer le paiement en deuxième étape.
Expirations : les holds doivent expirer automatiquement (p.ex. après 10 minutes) pour éviter que l'inventaire soit bloqué par des abandons de checkout.
Outbox transactionnelle : quand une réservation est confirmée, écrire une ligne « événement à envoyer » dans la même transaction, puis livrer asynchronement vers l'email, la logistique, l'analytics ou un bus de messages — sans risquer un écart « réservé mais pas de confirmation envoyée ».
Conclusion : si votre activité ne peut pas tolérer la double allocation entre régions, les garanties transactionnelles fortes deviennent une fonctionnalité produit, pas un détail technique.
Cas d'utilisation : haute disponibilité et reprise après sinistre
La haute disponibilité (HA) est un bon usage pour Distributed SQL quand l'indisponibilité coûte cher, que les pannes imprévisibles sont inacceptables et que vous voulez rendre les maintenances sans incident.
L'objectif n'est pas « ne jamais tomber » — c'est atteindre des SLO mesurables (p.ex. 99.9% ou 99.99% uptime) même quand des nœuds meurent, des zones tombent ou vous appliquez des mises à jour.
« Toujours disponible » en pratique : SLO, maintenance, pannes
Commencez par traduire « toujours disponible » en attentes mesurables : temps d'indisponibilité maximal par mois, RTO et RPO.
Les systèmes Distributed SQL peuvent continuer à servir lectures/écritures face à de nombreuses pannes courantes, mais seulement si votre topologie correspond à vos SLO et si votre application gère proprement les erreurs transitoires (retries, idempotence).
La maintenance planifiée compte aussi. Les upgrades rolling et les remplacements d'instances sont plus simples quand la base peut déplacer leadership/réplicas loin des nœuds impactés sans arrêter tout le cluster.
Redondance multi‑zone vs multi‑région
Multi‑zone protège d'une panne d'AZ/zone et de nombreuses pannes matérielles, généralement avec une latence et un coût moindres. C'est souvent suffisant si la conformité et la base d'utilisateurs restent dans une région.
Multi‑région protège d'une panne région complète et supporte le basculement régional. Le compromis : latence d'écriture plus élevée pour les transactions fortement cohérentes qui traversent des régions, et une planification de capacité plus complexe.
Attentes de basculement (et tests avec game days)
Ne supposez pas que le basculement est instantané ou invisible. Définissez ce que « basculer » signifie pour votre service : pics d'erreurs brefs ? périodes en lecture seule ? quelques secondes de latence élevée ?
Faites des « game days » pour le prouver :
- Tuez un nœud, puis une zone ; vérifiez vos dashboards SLO et le budget d'erreurs client.
- Simulez des partitions réseau et vérifiez le comportement leader/réplicas.
- Entraînez‑vous à l'évacuation d'une région et mesurez le RTO réel.
La réplication n'est pas une sauvegarde
Même avec réplication synchrone, maintenez des sauvegardes et répétez des restaurations. Les sauvegardes protègent contre les erreurs humaines (mauvaises migrations, suppressions accidentelles), les bugs applicatifs et la corruption qui pourrait se répliquer.
Validez la récupération temporelle (PITR si disponible), la vitesse de restauration et la capacité à récupérer dans un environnement propre sans toucher la production.
Les exigences de résidence apparaissent quand des régulations, contrats ou politiques internes indiquent que certains enregistrements doivent être stockés (et parfois traités) dans un pays ou une région spécifique.
Cela peut concerner les données personnelles, soins de santé, données de paiement, charges gouvernementales ou jeux de données « détenus par le client » où le contrat impose l'emplacement.
Distributed SQL est souvent envisagé car il permet d'avoir une seule base logique tout en plaçant physiquement les données dans différentes régions — sans vous forcer à exécuter des stacks applicatifs complètement séparés par géographie.
Pourquoi les règles de résidence modifient la conception de la base
Si un régulateur ou un client exige « les données restent dans la région », il ne suffit pas d'avoir des réplicas proches. Vous devrez peut‑être garantir que :
- La copie primaire (ou toutes les copies) de certaines données est stockée uniquement dans des régions approuvées
- Les sauvegardes et snapshots suivent les mêmes règles
- Les opérateurs et services hors région ne peuvent pas accéder aux données brutes
Cela pousse les équipes vers des architectures où la localisation est une préoccupation de première classe, pas une réflexion après coup.
Placement par client et contrôles d'accès (haut niveau)
Un pattern courant en SaaS est le placement des données par tenant. Par exemple : les clients EU voient leurs lignes/partitions épinglées aux régions EU, les clients US aux régions US.
À haut niveau, on combine :
- Règles de placement des données (où les données d'un client peuvent résider)
- Contrôles d'identité et d'accès (quels services et personnes peuvent lire)
- Chiffrement et gestion des clés (parfois avec des clés liées à la région)
Le but est de rendre difficile la violation accidentelle de résidence via l'accès opérationnel, les restaurations de sauvegarde ou la réplication cross‑région.
Les exigences légales varient — impliquez le juridique
La résidence et la conformité diffèrent selon les pays, l'industrie et les contrats. Elles évoluent aussi dans le temps.
Considérez la topologie de la base comme partie de votre programme de conformité, et validez les hypothèses avec un conseil juridique qualifié (et, si pertinent, vos auditeurs).
Les topologies « respectueuses de la résidence » peuvent compliquer une vue globale. Si les données clients sont délibérément conservées dans des régions séparées, l'analytics et le reporting peuvent :
- Avoir des pipelines de reporting régionaux (le calcul s'exécute là où résident les données)
- Utiliser des exports agrégés (seuls les métriques autorisées sortent de la région)
- Accepter une latence plus élevée pour les dashboards globaux, car les requêtes globales peuvent traverser des régions ou s'appuyer sur des datasets dérivés/répliqués
En pratique, beaucoup d'équipes séparent les workloads opérationnels (cohérence forte, conscience de la résidence) de l'analytique (entrepôts régionaux ou jeux de données agrégés gouvernés) pour garder la conformité sous contrôle sans ralentir le reporting produit quotidien.
Expérimentez sans crainte
Testez des modifications de schéma risquées avec des instantanés et revenez en arrière si les tests échouent.
Distributed SQL peut vous éviter des pannes douloureuses et des limites régionales, mais il n'économise généralement pas l'argent par défaut. Une planification en amont vous évite de payer pour une "assurance" inutile.
Principaux postes de coût
La plupart des budgets se répartissent en quatre rubriques :
- Nœuds (compute) : vous payez pour garder plusieurs réplicas en ligne — souvent 3+ par région — plus de la capacité supplémentaire pour le basculement. Les designs multi‑régions nécessitent généralement plus de marge qu'un Postgres mono‑région.
- Stockage : la réplication multiplie la taille des données. Un dataset de 2 To avec trois réplicas devient ~6 To avant backups, index et overhead.
- Trafic inter‑régions : la réplication cross‑région, les lectures et le trafic client peuvent devenir un poste significatif.
- Temps d'ops : même les offres managées demandent du travail : tuning de schéma/requêtes, réponse aux incidents, planification de capacité, tests de mise à jour et gouvernance (surtout autour de la résidence).
Estimer l'impact en latence sur des parcours utilisateur réels
Distributed SQL ajoute de la coordination — surtout pour les écritures à cohérence forte qui exigent l'accord d'un quorum.
Une façon pratique d'estimer l'impact :
- Choisissez 2–3 parcours clés (checkout, réservation, « sauvegarder les changements »).
- Comptez le nombre d'écritures transactionnelles et d'étapes lecture‑après‑écriture sur le chemin critique.
- Pour chaque étape, supposez un aller‑retour multi‑région quand la coordination est nécessaire. Si le RTT cross‑région est 80–120 ms, deux étapes d'écriture séquentielles peuvent ajouter 160–240 ms au temps applicatif.
Cela ne signifie pas « n'en faites pas », mais cela vous pousse à concevoir des parcours pour réduire les écritures séquentielles (batching, retries idempotents, transactions moins bavardes).
Complexité vs alternatives plus simples
Si vos utilisateurs sont majoritairement dans une région, un Postgres mono‑région avec réplicas en lecture, de bonnes sauvegardes et un plan de basculement testé peut être moins cher, plus simple — et rapide.
Distributed SQL justifie son coût quand vous avez vraiment besoin d'écritures multi‑régions, de RPO/RTO stricts ou d'un placement respectueux de la résidence.
Un encadrement ROI simple
Considérez la dépense comme un choix :
- Risque évité : moins d'interruptions impactant le revenu, moins d'exposition à la perte de données, moins de week‑ends d'incident global.
- Revenu protégé : meilleure conversion grâce à une latence régionale plus faible, posture entreprise renforcée (SLA, conformité).
- Dépense : cluster de base + overhead de réplication + trafic + temps d'ingénierie.
Si la perte évitée (downtime + churn + risque de conformité) dépasse la prime continue, le design multi‑région est justifié. Sinon, commencez plus simplement — avec un chemin clair pour évoluer.
Checklist d'adoption et prochaines étapes
Adopter le distributed SQL, ce n'est pas « déplacer » une base : c'est prouver que votre workload se comporte bien quand données et consensus sont répartis sur des nœuds (et éventuellement des régions). Un plan léger vous évite des surprises.
Un PoC ciblé
Choisissez un workload qui reflète une vraie douleur : p.ex. checkout/réservation, provisioning de compte ou post d'un grand‑livre.
Définissez les métriques de succès en amont :
- Correction : pas de double‑réservation, pas de mises à jour perdues, comportement transactionnel prévisible
- SLO de latence : p50/p95 pour les 3 requêtes principales (incluez les cibles cross‑régions si pertinentes)
- Débit : QPS soutenu au pic + marge de sécurité (souvent 2–3×)
- Résilience : comportement lors d'une perte de nœud et (si pertinent) d'une perte de région
- Effort opérationnel : temps pour détecter, diagnostiquer et récupérer d'un incident simulé
Pour aller plus vite en PoC, il est utile de construire une petite surface applicative « réaliste » (API + UI) plutôt que des benchmarks uniquement synthétiques. Par exemple, des équipes utilisent parfois Koder.ai pour lancer rapidement une app React + Go + PostgreSQL de base via chat, puis remplacer la couche BD par CockroachDB/YugabyteDB (ou connecter Spanner) pour tester les patterns de transaction, les retries et le comportement de bout en bout.
Le but n'est pas l'outil starter — c'est raccourcir la boucle entre « idée » et « workload mesurable ».
Checklist de conception (les pièges ultérieurs)
- Schéma : choisissez des clés primaires qui répartissent les écritures ; évitez les clés séquentielles « hotes »
- Indexes : gardez seulement l'essentiel ; comprenez l'amplification d'écriture des index secondaires
- Partitionnement/placement : décidez des clés de partition (et règles geo/zone) selon les patterns d'accès
- Hot spots : identifiez les « celebrity rows » (compteurs globaux, tables mono‑tenant) et repensez‑les tôt
- Migrations : planifiez les changements de schéma en ligne et les backfills ; testez les chemins de rollback
Les basiques opérationnels à avoir dès le jour 1
Le monitoring et les runbooks comptent autant que le SQL :
- Dashboards pour latence, retries, contention, santé de réplication/consensus, disque et compactions
- Runbooks d'incident : requêtes lentes, redémarrages de nœuds, réplicas défaillants, charge inégale
- Tests de charge qui imitent la production (mix lecture/écriture, bursts, transactions longues)
- Sauvegardes + exercices de restauration (PITR si dispo)
Étapes suivantes
Commencez par un sprint PoC, puis budgétez du temps pour une revue de readiness production et une bascule progressive (écritures doubles ou lectures en shadow quand possible).
Si vous avez besoin d'aide pour estimer les coûts ou les niveaux, voir /pricing. Pour des guides pratiques et des patterns de migration, parcourez /blog.
Si vous documentez vos résultats de PoC, vos compromis d'architecture ou vos leçons de migration, envisagez de les partager avec votre équipe (et publiquement si possible) : des plateformes comme Koder.ai offrent parfois des crédits pour créer du contenu éducatif ou référer d'autres équipes, ce qui peut compenser les coûts d'expérimentation pendant votre évaluation.