Bases SQL vs NoSQL : différences clés et cas d'usage
Comprenez les différences clés entre bases SQL et NoSQL : modèles de données, scalabilité, cohérence et cas d'usage pour choisir la meilleure option selon votre projet.
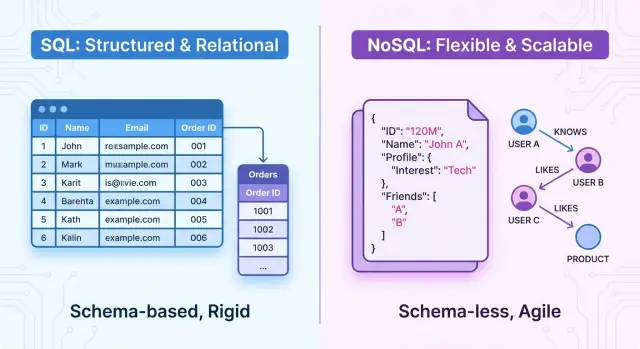
Aperçu : SQL et NoSQL en un coup d'œil
Le choix entre bases SQL et NoSQL influence la façon dont vous concevez, construisez et scalez votre application. Le modèle de données impacte tout : structures de données, patterns de requête, performances, fiabilité et la rapidité avec laquelle votre équipe peut faire évoluer le produit.
À un niveau élevé, les bases SQL sont des systèmes relationnels. Les données sont organisées en tables avec des schémas fixes, des lignes et des colonnes. Les relations entre entités sont explicites (via des clés étrangères), et vous interrogez les données avec SQL, un langage déclaratif puissant. Ces systèmes mettent l'accent sur les transactions ACID, la cohérence forte et une structure bien définie.
Les bases NoSQL sont des systèmes non relationnels. Plutôt qu'un modèle tabulaire rigide, elles proposent plusieurs modèles de données adaptés à des besoins différents, tels que :
- Stores clé‑valeur
- Bases de documents
- Stockages en colonnes larges
- Bases de graphe
Autrement dit, « NoSQL » n'est pas une seule technologie mais un terme fourre‑tout pour plusieurs approches, chacune avec ses compromis en flexibilité, performances et modélisation. Beaucoup de systèmes NoSQL assouplissent les garanties de cohérence stricte au profit d'une grande scalabilité, disponibilité ou d'une latence réduite.
Cet article se concentre sur la différence entre SQL et NoSQL : modèles de données, langages de requête, performances, scalabilité et cohérence (ACID vs cohérence éventuelle). L'objectif est de vous aider à choisir entre SQL et NoSQL selon votre projet et à comprendre quand chaque type est le plus adapté.
Vous n'avez pas à choisir un seul type pour toute l'architecture. Beaucoup d'architectures modernes utilisent la persistance polygotte, où SQL et NoSQL coexistent dans un même système, chacun gérant les charges pour lesquelles il est optimal.
Qu'est‑ce qu'une base SQL (relationnelle) ?
Une base SQL (relationnelle) stocke les données sous forme tabulaire structurée et utilise Structured Query Language (SQL) pour définir, interroger et manipuler ces données. Elle repose sur le concept mathématique de relations, que l'on peut percevoir comme des tables bien organisées.
Structure centrale : tables, lignes, colonnes et schémas
Les données sont organisées en tables. Chaque table représente un type d'entité, comme customers, orders ou products.
- Une ligne (enregistrement) est une instance de cette entité, par exemple un client.\n- Une colonne (champ) est un attribut précis, tel que
emailouorder_date.
Chaque table suit un schéma fixe : une structure prédéfinie qui précise :
- quelles colonnes existent\n- leurs types (ex.
INTEGER,VARCHAR,DATE)\n- les contraintes (ex.NOT NULL,UNIQUE)
Le schéma est appliqué par la base, ce qui aide à maintenir des données cohérentes et prévisibles.
Clés et relations
Les bases relationnelles excellent pour modéliser les relations entre entités.
- Une clé primaire identifie de façon unique chaque ligne d'une table (par exemple
customer_id).\n- Une clé étrangère est une colonne qui fait référence à une clé primaire dans une autre table, liant des lignes connexes.
Ces clés permettent de définir des relations telles que :
- Un‑à‑plusieurs (un client, plusieurs commandes)\n- Plusieurs‑à‑plusieurs (produits présents dans plusieurs commandes, commandes contenant plusieurs produits)
Transactions et propriétés ACID
Les bases relationnelles prennent en charge les transactions — groupes d'opérations qui se comportent comme une seule unité. Les transactions respectent les propriétés ACID :
- Atomicité : toutes les opérations réussissent ou aucune ne s'applique.
- Cohérence : les transactions font passer la base d'un état valide à un autre.
- Isolation : les transactions concurrentes ne se perturbent pas mutuellement.
- Durabilité : une fois commit, les données sont durablement stockées.
Ces garanties sont cruciales pour les systèmes financiers, la gestion d'inventaire et toute application où la correction est primordiale.
Bases SQL courantes
Parmi les systèmes relationnels populaires :
- MySQL et MariaDB\n- PostgreSQL\n- Microsoft SQL Server\n- Oracle Database
Ils implémentent tous SQL, en ajoutant chacun des extensions et des outils pour l'administration, l'optimisation et la sécurité.
Qu'est‑ce qu'une base NoSQL (non relationnelle) ?
Les bases NoSQL sont des stockages non relationnels qui n'utilisent pas le modèle table–ligne–colonne traditionnel des systèmes SQL. Elles mettent l'accent sur des modèles de données flexibles, la scalabilité horizontale et la haute disponibilité, souvent au prix de garanties transactionnelles strictes.
Modèles de données flexibles
Beaucoup de bases NoSQL sont qualifiées de sans schéma ou à schéma flexible. Plutôt que de définir un schéma rigide à l'avance, vous pouvez stocker des enregistrements ayant des champs ou structures différents dans la même collection ou le même bucket.
Ceci est particulièrement utile pour :
- Des exigences applicatives en évolution\n- Traiter des données semi‑structurées (logs, événements, profils utilisateur)\n- Stocker des données imbriquées comme des documents JSON
Comme les champs peuvent être ajoutés ou omis par enregistrement, les développeurs itèrent rapidement sans migrations pour chaque changement structurel.
Principaux types de NoSQL
NoSQL couvre plusieurs modèles distincts :
- Bases de documents : stockent les données sous forme de documents similaires à JSON avec champs imbriqués. Ex. : MongoDB, Couchbase.\n- Stores clé‑valeur : tableaux associatifs simples où chaque clé pointe vers une valeur. Idéal pour le cache et les sessions. Ex. : Redis, Amazon DynamoDB (mode clé‑valeur).\n- Stores en colonnes larges : organisent les données par familles de colonnes pour un débit d'écriture élevé. Ex. : Apache Cassandra, HBase.\n- Bases de graphe : centrées sur les nœuds et relations, idéales pour des données fortement connectées. Ex. : Neo4j, Amazon Neptune.
Modèles de cohérence
Beaucoup de systèmes NoSQL privilégient la disponibilité et la tolérance aux partitions, offrant une cohérence éventuelle plutôt que des transactions ACID strictes sur l'ensemble des données. Certains proposent des niveaux de cohérence ajustables ou des fonctions transactionnelles limitées (par document, partition ou plage de clés), permettant de choisir entre garanties fortes et performances élevées pour certaines opérations.
Modèles de données : structure, schémas et relations
La modélisation des données est le point où SQL et NoSQL divergent le plus. Elle influence la conception des fonctionnalités, les requêtes et l'évolution de l'application.
Structure et schémas
Les bases SQL utilisent des schémas prédéfinis et structurés. Vous concevez des tables et des colonnes à l'avance, avec des types stricts et des contraintes :
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT NOT NULL,
total DECIMAL(10, 2) NOT NULL,
FOREIGN KEY (user_id) REFERENCES users(id)
);
Chaque ligne doit respecter le schéma. Le modifier plus tard implique généralement des migrations (ALTER TABLE, backfill, etc.).
Les bases NoSQL supportent en général des schémas flexibles. Un store de documents peut autoriser chaque document à avoir des champs différents :
{
"_id": 1,
"name": "Alice",
"orders": [
{ "id": 101, "total": 49.99 },
{ "id": 102, "total": 15.50 }
]
}
Les champs peuvent être ajoutés par document sans migration centrale. Certains systèmes NoSQL proposent toutefois des schémas optionnels ou applicables.
Normalisation vs dénormalisation
Les modèles relationnels encouragent la normalisation : scinder les données en tables liées pour éviter la duplication et préserver l'intégrité. Cela favorise des écritures cohérentes et un stockage optimisé, mais les lectures peuvent nécessiter de nombreuses jointures.
Les modèles NoSQL favorisent souvent la dénormalisation : intégrer des données liées pour optimiser les lectures. Cela accélère les lectures et simplifie les requêtes, mais les écritures peuvent être plus lentes ou complexes car la même information peut exister à plusieurs endroits.
Modéliser les relations
En SQL, les relations sont explicites et appliquées :
- Un‑à‑plusieurs : clés étrangères (users → orders)\n- Plusieurs‑à‑plusieurs : tables de jointure (users_roles)
En NoSQL, les relations se modélisent par :
- Imbrication (le document utilisateur contient un tableau d'orders) pour des données fortement couplées\n- Références (user_id dans un document order) pour des collections volumineuses ou peu couplées
Le choix dépend des patterns d'accès :
- Si vous récupérez toujours un utilisateur et ses 10 dernières commandes ensemble, l'imbrication est souvent idéale.\n- Si les commandes sont volumineuses, fréquemment mises à jour ou accédées indépendamment, les références et requêtes séparées sont préférable.
Impact sur l'évolution des exigences
Avec SQL, les changements de schéma demandent plus de planification mais donnent des garanties fortes. Les refactors sont explicites : migrations, backfills, mise à jour des contraintes.
Avec NoSQL, les exigences qui évoluent sont plus faciles à gérer à court terme : vous pouvez commencer à stocker de nouveaux champs immédiatement et mettre à jour progressivement les anciens documents. Le compromis : le code applicatif doit gérer plusieurs formes de documents et les cas limites.
Choisir entre modèles normalisés SQL et modèles dénormalisés NoSQL revient à aligner la structure de données sur vos patterns de requête, votre volume d'écriture et la fréquence de changement du modèle de domaine.
Langages de requête et patterns d'accès
SQL : déclaratif et standardisé
Les bases SQL se requêtent via un langage déclaratif : vous décrivez ce que vous voulez, pas comment le récupérer. Les constructions comme SELECT, WHERE, JOIN, GROUP BY et ORDER BY permettent d'exprimer des questions complexes sur plusieurs tables dans une seule instruction.
Parce que SQL est standardisé (ANSI/ISO), la plupart des systèmes relationnels partagent une syntaxe de base commune. Les fournisseurs ajoutent des extensions, mais les compétences et requêtes se transfèrent bien entre PostgreSQL, MySQL, SQL Server, etc.
Cette standardisation apporte un riche écosystème : ORM, générateurs de requêtes, outils de reporting, BI, frameworks de migration et optimisateurs de requêtes. Vous pouvez intégrer beaucoup de ces outils à n'importe quelle base SQL avec peu de changements, ce qui réduit le verrouillage fournisseur et accélère le développement.
NoSQL : API de requête et patterns
Les systèmes NoSQL offrent des interfaces de requête variées :
- Stores de documents (MongoDB, Couchbase) utilisent des objets de requête proches du JSON et parfois leur propre langage.\n- Stores clé‑valeur (Redis, API type DynamoDB) se concentrent sur les recherches par clé primaire et quelques requêtes via index secondaires.\n- Stores en colonnes larges (Cassandra, HBase) optimisent pour des requêtes suivant une clé primaire et des clés de clustering prédéfinies.\n- Moteurs de recherche (Elasticsearch, Solr) utilisent des DSL orientés texte intégral et pertinence.
Certains NoSQL proposent des pipelines d'agrégation ou des mécanismes MapReduce pour l'analytique, mais les jointures inter‑collections ou inter‑partitions sont limitées ou absentes. Les données liées sont souvent intégrées dans le même document ou dénormalisées.
Patterns d'accès et productivité
Les requêtes relationnelles reposent souvent sur des jointures : normaliser, puis recomposer les entités en lecture via des jointures. C'est puissant pour le reporting ad‑hoc, mais les jointures complexes peuvent être difficiles à optimiser.
Les patterns NoSQL sont plutôt centrés sur la clé ou le document : concevez les données autour des requêtes les plus fréquentes. Les lectures sont rapides et simples — souvent une seule recherche par clé — mais changer les patterns d'accès plus tard peut demander de remodeler les données.
Pour l'apprentissage et la productivité :
- Le modèle déclaratif SQL et la quantité de ressources pédagogiques le rendent accessible et durable.\n- Les requêtes NoSQL peuvent être plus simples pour des patterns prévisibles, mais chaque système a sa syntaxe et ses limites, donc les compétences sont moins transférables.
Les équipes nécessitant des requêtes ad‑hoc riches à travers des relations favorisent le SQL. Les équipes ayant des patterns stables et à très grande échelle trouvent souvent les modèles NoSQL mieux adaptés.
Cohérence, transactions et compromis du théorème CAP
ACID : garanties strictes dans les systèmes SQL
La plupart des bases SQL sont conçues autour des transactions ACID :
- Atomicité : une transaction réussit entièrement ou échoue entièrement.\n- Cohérence : chaque transaction commit laisse la base dans un état valide en respectant les contraintes.\n- Isolation : les transactions concurrentes n'interfèrent pas (via des niveaux d'isolation comme READ COMMITTED, REPEATABLE READ, SERIALIZABLE).\n- Durabilité : une fois commit, les données survivent aux pannes.
Ceci rend les bases SQL adaptées quand la correction prime sur le débit d'écriture brut.
BASE et cohérence éventuelle dans beaucoup de systèmes NoSQL
Beaucoup de bases NoSQL tendent vers les propriétés BASE :
- Basically Available : le système vise à rester disponible et répondre.\n- Soft state : l'état peut être temporairement incohérent entre réplicas.\n- Eventual consistency : si aucune mise à jour n'est effectuée, tous les réplicas convergeront.
Les écritures peuvent être très rapides et distribuées, mais une lecture peut brièvement renvoyer des données obsolètes.
Théorème CAP en pratique
Le CAP stipule qu'un système distribué soumis à une partition réseau doit choisir entre :
- Cohérence (C) : tous les clients voient les mêmes données en même temps.\n- Disponibilité (A) : chaque requête obtient une réponse.
Vous ne pouvez pas garantir simultanément C et A durant une partition.
Patrons typiques :
- Beaucoup de déploiements SQL favorisent la cohérence forte : pertinent pour paiements, inventaires, soldes, réservations, et tout flux où une lecture obsolète peut coûter de l'argent ou enfreindre des règles.\n- Beaucoup de solutions NoSQL favorisent disponibilité et cohérence éventuelle : acceptable pour analytique, fils d'actualité, catalogues produits, logs, cache, où de petites incohérences temporaires sont tolérables et la rapidité/la disponibilité sont cruciales.
Les systèmes modernes mélangent souvent les modes (par ex. cohérence ajustable par opération) pour que différentes parties d'une application choisissent les garanties nécessaires.
Scalabilité et différences de performance
Comment les bases SQL évoluent généralement
Les bases relationnelles classiques sont conçues pour un nœud unique puissant.
On commence typiquement par scaler verticalement : ajouter CPU, RAM et disques plus rapides à une seule machine. Beaucoup d'architectures utilisent aussi des réplicas de lecture : nœuds supplémentaires prenant en charge les lectures pendant que toutes les écritures vont sur le primaire. Ce schéma convient pour :
- Volume d'écriture modéré\n- Requêtes analytiques/reporting lourdes\n- Workloads où la cohérence forte est critique
Cependant, la montée verticale a des limites matérielles et financières, et les réplicas de lecture peuvent introduire un retard de réplication pour les lectures.
NoSQL et scalabilité horizontale
Les systèmes NoSQL sont souvent conçus pour la scalabilité horizontale : répartir les données entre de nombreux nœuds via sharding ou partitionnement. Chaque shard contient un sous‑ensemble des données, si bien que lectures et écritures se distribuent, augmentant le débit.
Cela convient pour :
- Débits d'écriture massifs\n- Jeux de données dépassant la capacité d'une seule machine\n- Applications globales nécessitant des données proches des utilisateurs
Le compromis est une complexité opérationnelle plus élevée : choix des clés de shard, rebalancing, et gestion des requêtes inter‑shards.
Patterns de performance et indexation
Pour des workloads à lecture intensive avec jointures et agrégations complexes, une base SQL bien indexée peut être extrêmement rapide, l'optimiseur utilisant statistiques et plans d'exécution.
Beaucoup de systèmes NoSQL favorisent des patterns d'accès simples basés sur la clé. Ils excellent pour des recherches à faible latence et un débit élevé quand les requêtes sont prévisibles et le modèle aligné sur ces accès.
La latence dans les clusters NoSQL peut être très basse, mais les requêtes inter‑partitions, les index secondaires et les opérations multi‑document peuvent être plus lentes ou limitées. Opérationnellement, scaler NoSQL implique souvent plus de gestion de cluster, tandis que scaler SQL implique davantage d'optimisation matérielle et d'index sur moins de nœuds.
Quand une base SQL est‑elle généralement préférable ?
Workloads transactionnels et critiques
Les bases relationnelles excellent quand vous avez besoin d'un OLTP (online transaction processing) fiable :
- Systèmes financiers (paiements, comptabilité, trading)\n- Gestion des commandes et inventaires\n- ERP, CRM et plateformes de facturation
Ces systèmes reposent sur des transactions ACID, une cohérence stricte et des comportements de rollback clairs. Si un transfert ne doit jamais facturer deux fois ou perdre de l'argent entre deux comptes, SQL est généralement plus sûr que la plupart des options NoSQL.
Données structurées et relations complexes
Quand votre modèle de données est bien compris et stable, et que les entités sont fortement liées, une base relationnelle est souvent naturelle. Exemples :
- Clients, commandes, factures, produits et expéditions\n- Dossiers médicaux avec patients, consultations, prescriptions et analyses
Les schémas normalisés, clés étrangères et jointures facilitent l'application de l'intégrité des données sans duplication.
Analytique sur schémas bien définis
Pour le reporting et la BI sur des données clairement structurées (schémas en étoile/snowflake, data marts), SQL et entrepôts compatibles SQL sont habituellement préférés. Les équipes analytiques maîtrisent SQL, et les outils existants s'intègrent directement aux systèmes relationnels.
Maturité, compétences et conformité
Les débats relationnel vs non relationnel oublient souvent la maturité opérationnelle. Les bases SQL offrent :
- Fiabilité et outils éprouvés\n- Un grand vivier d'ingénieurs, DBA et analystes compétents en SQL\n- Des fonctionnalités d'audit, contrôle d'accès, chiffrement et sauvegarde répondant aux cadres réglementaires (finance, gouvernement, santé)
Quand les audits, certifications ou risques légaux sont importants, une base SQL est souvent le choix le plus simple et défendable dans le compromis SQL vs NoSQL.
Quand une base NoSQL est‑elle généralement préférable ?
NoSQL est souvent mieux adaptée lorsque la scalabilité, la flexibilité et la disponibilité continue priment sur les jointures complexes et les garanties transactionnelles strictes.
Systèmes à fort trafic et large échelle
Si vous attendez un volume d'écritures massif, des pics de trafic imprévisibles ou des datasets en téraoctets, les systèmes NoSQL (clé‑valeur, colonnes larges) sont souvent plus faciles à scaler horizontalement. Le sharding et la réplication sont fréquemment intégrés, permettant d'ajouter de la capacité en ajoutant des nœuds.
Cas courants :
- Applications web et mobiles à fort trafic\n- Backends de jeux et tableaux de leaderboards en temps réel\n- Ad tech, moteurs de recommandation et services de personnalisation
Données flexibles durant l'itération produit
Quand votre modèle évolue rapidement, un design flexible ou sans schéma est précieux. Les bases de documents permettent d'ajouter des champs sans migrations systématiques.
Bien adaptés pour :
- CMS et catalogues produits\n- Profils utilisateur et préférences\n- Feeds d'activité et logs où de nouveaux types d'événements apparaissent régulièrement
IoT, cache et séries temporelles
Les stores NoSQL sont aussi forts pour les workloads append‑only et temporels :
- Télémétrie IoT et données capteurs\n- Métriques, logs et monitoring\n- Caches pour données lues fréquemment (sessions, tokens, feature flags)
Les bases clé‑valeur et spécialisées séries temporelles sont optimisées pour des écritures très rapides et des lectures simples.
Distribution globale et expérience toujours disponible
Certaines plateformes NoSQL priorisent la géo‑réplication et les écritures multi‑régions, permettant des lectures/écritures locales à faible latence. Utile quand :
- L'application doit rester disponible lors d'une panne régionale\n- Des utilisateurs répartis mondialement exigent des temps de réponse locaux
Le compromis est d'accepter souvent une cohérence éventuelle plutôt qu'un ACID strict sur plusieurs régions.
Contraintes et limites
Choisir NoSQL signifie souvent renoncer à certaines fonctionnalités familières de SQL :
- Cohérence plus faible ou configurable ; les lectures ne voient pas toujours la dernière écriture\n- Requêtes ad‑hoc et jointures limitées ; il faut modéliser les requêtes en amont\n- Plus de responsabilités pour l'application afin d'imposer l'intégrité des données
Quand ces compromis sont acceptables, NoSQL offre meilleure scalabilité, flexibilité et portée globale que des bases relationnelles traditionnelles.
Patterns hybrides et persistance polygotte
La persistance polygotte consiste à utiliser volontairement plusieurs technologies de bases de données dans un même système, en choisissant l'outil le plus adapté pour chaque besoin plutôt que de forcer tout dans un seul magasin.
Configuration hybride typique
Un pattern courant :
- SQL pour les données cœur : commandes, paiements, profils utilisateurs, configurations. Ici la cohérence et les transactions sont nécessaires.\n- NoSQL pour sessions et cache : un store clé‑valeur (style Redis) pour sessions utilisateur, quotas, flags, ou agrégats chauds ; parfois un store de documents pour préférences ou flux.
Ainsi, le « système de référence » reste relationnel, tandis que les charges volatiles ou intensives en lectures sont déchargées sur NoSQL.
Combiner différents types de NoSQL
On peut aussi combiner plusieurs NoSQL :
- Clé‑valeur pour le cache et les sessions.\n- Document pour le contenu ou les données utilisateur à schéma flexible.\n- Colonnes larges / séries temporelles pour métriques et logs.\n- Moteur de recherche (Lucene‑based) pour texte intégral et requêtes analytiques.
L'objectif : aligner chaque magasin sur un pattern d'accès spécifique : lookup simple, agrégat, recherche ou lecture temporelle.
Intégration et coûts opérationnels
Les architectures hybrides requièrent des points d'intégration :
- ETL ou streaming pour synchroniser les magasins ou construire des modèles en lecture.\n- Streaming d'événements pour propager les changements (ex. : de SQL vers caches ou stores analytiques).\n- APIs masquant les bases pour que les services ignorent où résident les données.
Le compromis est un surcoût opérationnel : plus de technologies à maîtriser, monitorer, sécuriser, sauvegarder et dépanner. La persistance polygotte est pertinente quand chaque magasin additionnel résout un problème mesurable et concret — pas seulement par effet de mode.
Comment choisir entre SQL et NoSQL pour un projet
Choisir SQL ou NoSQL consiste à faire correspondre vos données et patterns d'accès à l'outil adapté, pas à suivre une mode.
1. Commencez par vos données et leurs relations
Demandez‑vous :
- Mes données sont‑elles naturellement tabulaires avec des entités claires (utilisateurs, commandes, factures) ?\n- Ai‑je beaucoup de jointures et des relations riches (1‑à‑n, n‑à‑n) ?
Si oui, une base relationnelle est en général le choix par défaut. Si les données ressemblent à des documents, sont imbriquées ou très variables, un modèle document ou autre NoSQL peut mieux convenir.
2. Clarifiez les besoins de cohérence et transactionnels
- Ai‑je besoin de transactions ACID multi‑lignes/multi‑tables pour la correction (paiements, inventaires) ?\n- Est‑il acceptable que certaines lectures soient légèrement obsolètes ?
La cohérence stricte et les transactions complexes favorisent SQL. Un débit d'écriture élevé avec cohérence relâchée favorise NoSQL.
3. Comprenez l'échelle et les performances attendues
- Volume de lectures/écritures aujourd'hui et dans 2–3 ans ?\n- Ai‑je besoin d'une faible latence dans plusieurs régions ?
La plupart des projets peuvent beaucoup scaler avec SQL via bon index et matériel. Si vous anticipez une énorme échelle avec des patterns simples (lookup par clé, séries temporelles, logs), certains NoSQL sont plus économiques.
4. Patterns de requêtes et reporting
- Aurai‑je besoin d'analyses ad‑hoc, jointures et reporting flexible ?\n- Qui interrogera les données (uniquement des ingénieurs, ou aussi des analystes/business) ?
SQL excelle pour les requêtes complexes, les outils BI et l'exploration ad‑hoc. Beaucoup de NoSQL sont optimisés pour des chemins d'accès prédéfinis et rendent les nouvelles requêtes plus coûteuses.
5. Compétences, outils et hébergement de l'équipe
- Quelle est l'expertise de l'équipe : SQL, conception de schéma ou systèmes NoSQL spécifiques ?\n- Quelles options sont disponibles dans votre hébergement (PostgreSQL managé, MongoDB managé, DynamoDB, etc.) ?\n- Quel écosystème offre les librairies, drivers et monitoring adaptés à votre stack ?
Favorisez les technologies que votre équipe sait exploiter, surtout pour le support production et les migrations.
6. Coût et complexité opérationnelle
- Pouvons‑nous gérer des clusters NoSQL distribués, ou une instance SQL managée suffit‑elle ?\n- Comment se comparent les coûts de stockage et lecture/écriture pour notre charge prévue ?
Une base SQL managée unique est souvent moins coûteuse et plus simple jusqu'à ce que vous atteigniez réellement ses limites.
7. Testez avec des charges réalistes
Avant de trancher :
- Modelez un sous‑ensemble représentatif des données en SQL et dans le modèle NoSQL candidat.\n2. Implémentez quelques requêtes et écritures critiques.\n3. Exécutez des tests de charge avec des volumes et patterns réalistes.\n4. Mesurez latence, débit, taux d'erreur et effort opérationnel.
Basez votre décision sur ces mesures, pas sur des suppositions. Pour beaucoup de projets, commencer par SQL est la voie la plus sûre, avec l'option d'ajouter du NoSQL pour des cas d'utilisation spécifiques à très forte échelle.
Mythes courants à propos de SQL et NoSQL
Mythe 1 : NoSQL va remplacer SQL
NoSQL n'est pas arrivé pour tuer les bases relationnelles, mais pour les compléter.
Les bases relationnelles dominent encore les systèmes de référence : finance, RH, ERP, inventaire et tout flux où la cohérence et les transactions sont essentielles. NoSQL brille là où les schémas flexibles, un débit d'écriture énorme ou les lectures globales sont plus importants que les jointures complexes.
La plupart des organisations utilisent les deux, en choisissant l'outil adapté à chaque charge.
Mythe 2 : Les bases SQL ne peuvent pas scaler horizontalement
Historiquement, les bases relationnelles montaient en puissance verticalement, mais les moteurs modernes offrent :
- Réplicas de lecture\n- Sharding/partitionnement\n- SQL distribué / NewSQL
Scaler un système relationnel peut être plus impliqué que d'ajouter des nœuds à certains clusters NoSQL, mais l'échelle horizontale est possible avec une conception et des outils appropriés.
Mythe 3 : NoSQL n'a pas de schéma ni de règles
« Sans schéma » signifie souvent « le schéma est appliqué par l'application, pas par la base ». Les stores de documents, clé‑valeur et colonnes larges ont toujours une structure. Cette flexibilité est puissante, mais sans contrats clairs et validation, les données deviennent rapidement inconsistantes.
Mythe 4 : Un type est toujours plus rapide
La performance dépend surtout du modèle de données, des index et des patterns d'accès, pas de la seule catégorie. Une collection NoSQL mal indexée sera plus lente qu'une table relationnelle bien optimisée pour certaines requêtes, et vice versa.
Mythe 5 : SQL est toujours plus sûr et fiable que NoSQL
Beaucoup de bases NoSQL offrent durabilité forte, chiffrement, audit et contrôle d'accès. Inversement, une base relationnelle mal configurée peut être fragile et peu sûre. La sécurité et la fiabilité dépendent du produit, du déploiement, de la configuration et de la maturité opérationnelle — pas uniquement de « SQL » ou « NoSQL ».
Stratégies de migration et de coexistence
Les équipes migrent entre SQL et NoSQL pour deux raisons : montée en charge et flexibilité. Un produit à fort trafic peut conserver une base relationnelle comme système de référence, puis ajouter du NoSQL pour gérer des lectures à grande échelle ou supporter de nouvelles fonctionnalités avec des schémas flexibles.
Patterns de migration
Une migration « tout ou rien » est risquée. Des options plus sûres :
- Migration incrémentale : isoler un contexte borné (ex. : catalogue produit) et ne migrer que ces données vers NoSQL.\n- Écritures doubles : pendant une période, écrire dans SQL et NoSQL. Une fois le nouveau magasin validé, retirer progressivement l'ancien chemin.\n- Pipelines de synchronisation : garder une base primaire et streamer les changements vers l'autre via CDC, queues ou jobs ETL.
Pièges de schéma et modèle
Passer de SQL à NoSQL peut pousser les équipes à reproduire tables→documents, menant à :
- Sur‑normalisation dans NoSQL et trop de jointures côté applicatif\n- Documents qui gonflent sans contrôle
Concevez le nouveau schéma autour des patterns d'accès avant de migrer.
Coexistence et filets de sécurité
Un pattern répandu : SQL pour les données de référence (facturation, comptes) et NoSQL pour les vues en lecture (feeds, recherche, cache). Quelle que soit la combinaison, investissez dans :
- Backfills et rollbacks reproductibles\n- Validation des données entre magasins\n- Tests de charge reflétant les patterns réels
Cela rend les migrations SQL vs NoSQL contrôlées plutôt que risquées et irréversibles.
Résumé et recommandations pratiques
SQL et NoSQL diffèrent principalement sur quatre axes :
- Modèle de données – SQL utilise tables, lignes et schémas définis ; NoSQL favorise documents, paires clé‑valeur, colonnes larges ou graphes, avec une structure plus flexible.\n- Requêtes – SQL offre un langage expressif unique ; NoSQL utilise généralement des API ou syntaxes propres à chaque base.\n- Cohérence & transactions – SQL mise sur ACID et cohérence forte ; beaucoup de NoSQL échangent certaines garanties contre disponibilité, scalabilité ou latence.\n- Scalabilité – SQL évolue historiquement verticalement (et de plus en plus horizontalement via clustering) ; NoSQL est souvent conçu pour sharder et répliquer sur de nombreux nœuds.
Aucune catégorie n'est universellement meilleure. Le bon choix dépend de vos besoins réels, pas des tendances.
Comment choisir en pratique
-
Écrivez vos besoins :
- Structure des données et relations\n - Patterns de requête et besoins de reporting\n - Attentes en matière de cohérence vs disponibilité\n - Trafic maximal, volume de données et objectifs de latence\n - Compétences opérationnelles et outils de l'équipe
-
Choisissez sensément par défaut :
- Préférez SQL pour les systèmes transactionnels, l'analytics et les données métier structurées.\n - Envisagez NoSQL pour des débits d'écriture très élevés, une très grande échelle ou des données semi‑structurées.
-
Commencez petit et mesurez :
- Construisez un vertical slice ou POC.\n - Collectez des métriques : latence, débit, erreurs, effort opérationnel.\n - Itérez sur schéma, index et partitionnement selon l'usage réel.
-
Restez ouvert aux architectures hybrides :
- Utilisez plusieurs bases si différentes parties du système ont des besoins très différents.\n - Documentez décisions, compromis et patterns dans votre base de connaissances interne (par exemple sous
/docs/architecture/datastores).
- Utilisez plusieurs bases si différentes parties du système ont des besoins très différents.\n - Documentez décisions, compromis et patterns dans votre base de connaissances interne (par exemple sous
Pour des approfondissements, complétez cet aperçu par des standards internes, checklists de migration et lectures complémentaires dans votre handbook d'ingénierie ou /blog.
FAQ
Quelle est la différence fondamentale entre les bases SQL et NoSQL ?
Bases SQL (relationnelles) :
- Utilisent des tables avec lignes et colonnes.
- Imposent un schéma fixe (colonnes définies, types, contraintes).
- S'appuient sur SQL comme langage de requête normalisé.
- Mettent l'accent sur les transactions ACID et la cohérence forte.
Bases NoSQL (non relationnelles) :
- Utilisent des modèles flexibles (documents, clé‑valeur, colonnes larges, graphe).
- Permettent souvent des données à schéma flexible ou sans schéma.
- Utilisent des API ou DSL propres à chaque base.
- Échangent souvent certaines garanties de cohérence contre la scalabilité et la disponibilité.
Quand une base SQL est‑elle généralement le meilleur choix ?
Utilisez une base SQL quand :
- Vos données sont bien structurées et relationnelles (utilisateurs, commandes, factures).\n- Vous avez besoin de transactions ACID multi‑lignes ou multi‑tables.\n- La cohérence et la correction priment sur le débit brut.\n- Vous attendez de nombreuses requêtes ad‑hoc, des jointures et des besoins de reporting.\n- La conformité, l'audit et la maintenabilité à long terme sont critiques.
Pour la plupart des nouveaux systèmes de référence métier, SQL est un choix par défaut raisonnable.
Quand une base NoSQL est‑elle généralement le meilleur choix ?
NoSQL convient le mieux quand :
- Vous devez répartir écritures et stockage horizontalement sur de nombreux nœuds.\n- Vos données sont semi‑structurées, imbriquées ou changent souvent de forme.\n- Les schémas d'accès sont bien connus et peuvent s'appuyer sur des recherches par clé ou document.\n- Des incohérences temporaires sont acceptables (ex. : flux d'actualités, logs, vues analytiques).\n- Vous traitez de la télémétrie IoT, des séries temporelles, du cache ou du contenu utilisateur à grande échelle.
En quoi les schémas et la modélisation des données diffèrent‑ils entre SQL et NoSQL ?
Bases SQL :
- Utilisent des schémas prédéfinis ; chaque ligne doit respecter la définition de la table.\n- Encouragent la normalisation pour réduire la duplication et garantir l'intégrité.\n- Utilisent des clés étrangères et des contraintes pour gérer les relations.
Bases NoSQL :
- Permettent à des documents/enregistrements d'avoir des champs différents dans une même collection.\n- Encouragent souvent la dénormalisation et l'imbriquement des données liées.\n- Requièrent davantage que l'application fasse respecter certaines règles de données.
Cela signifie que le contrôle du schéma passe de la base (SQL) à l'application (NoSQL).
Comment SQL et NoSQL diffèrent‑ils en matière de cohérence et de transactions ?
Bases SQL :
- Placées autour de transactions ACID avec une cohérence forte.\n- Idéales quand chaque lecture doit voir un état valide et à jour.
Beaucoup de systèmes NoSQL :
- Priorisent la disponibilité et la tolérance aux partitions.\n- Utilisent les principes BASE et la cohérence éventuelle : les réplicas convergent avec le temps.\n- Peuvent proposer une cohérence réglable par opération ou par partition.
Choisissez SQL quand les lectures obsolètes sont dangereuses ; choisissez NoSQL quand une légère obsolescence est acceptable en échange d'échelle et de disponibilité.
Comment SQL et NoSQL évoluent‑ils généralement pour monter en charge ?
Les bases SQL typiquement :
- Démarrent par une montée en puissance verticale (serveurs plus puissants).\n- Ajoutent des réplicas de lecture pour scaler les lectures.\n- Utilisent parfois le sharding ou des produits SQL distribués pour le scale‑out.
Les bases NoSQL :
- Sont conçues dès le départ pour le scale horizontal.\n- Fragmentent ou partitionnent les données sur plusieurs nœuds.\n- Facilitent l'ajout de capacité en ajoutant des serveurs bon marché.
Le compromis est que les clusters NoSQL sont souvent plus complexes à exploiter, alors que SQL peut atteindre des limites sur une seule instance plus rapidement.
Puis‑je utiliser SQL et NoSQL ensemble dans le même système ?
Oui. La persistance polygotte est courante :
- Utilisez SQL comme système d'enregistrement (paiements, comptes, entités cœur).\n- Ajoutez NoSQL pour les sessions, caches, flux, logs ou la recherche.
Les modèles d'intégration comprennent :
- Capture de données de changement ou flux d'événements de SQL vers NoSQL.\n- Jobs ETL périodiques pour construire des vues optimisées en lecture.\n- Services masquant les magasins sous-jacents derrière des API stables.
L'important est d'ajouter chaque magasin supplémentaire seulement s'il résout un problème clair.
Comment devrais‑je aborder la migration entre SQL et NoSQL ?
Pour migrer progressivement et en sécurité :
- Identifiez un contexte borné (ex. : catalogue produit) à migrer.\n2. Modelez les données autour des nouveaux schémas d'accès, pas table‑par‑table.\n3. Utilisez des écritures doubles ou la CDC pour synchroniser temporairement les deux magasins.\n4. Validez les données entre les stockages et planifiez des backfills reproductibles.\n5. Basculer le trafic par étapes, avec possibilités de retour arrière.
Évitez les migrations en une fois ; préférez des étapes incrémentales et bien surveillées.
Quels facteurs devrais‑je évaluer pour choisir entre SQL et NoSQL ?
Considérez :
- Structure des données : tabulaire avec relations claires vs documents/événements flexibles.\n- Besoins de cohérence : ACID strict vs tolérance à l'obsolescence.\n- Scalabilité et latence : volume d'écriture attendu, taille des données, utilisateurs globaux.\n- Schémas de requêtes : jointures ad‑hoc et analytics vs recherches par clé/documents prévisibles.\n- Compétences et outils de l'équipe : ce que l'équipe sait exploiter.\n- Coût et exploitation : options managées vs gestion de clusters distribués.
Prototyperez les deux options pour les flux critiques et mesurez latence, débit et complexité avant de décider.
Quels sont les mythes courants au sujet des bases SQL vs NoSQL ?
Idées reçues courantes :
- "NoSQL va remplacer SQL" – en pratique, ils se complètent.\n- "SQL ne peut pas se scaler horizontalement" – les systèmes modernes supportent réplicas, sharding et SQL distribué.\n- "NoSQL n'a pas de schéma" – le schéma existe toujours, mais il est souvent imposé par l'application ou des validateurs.\n- "Un type est toujours plus rapide" – la performance dépend surtout du modèle de données, des index et de la charge.
Évaluez des produits et architectures spécifiques plutôt que de vous fier aux mythes de catégories.