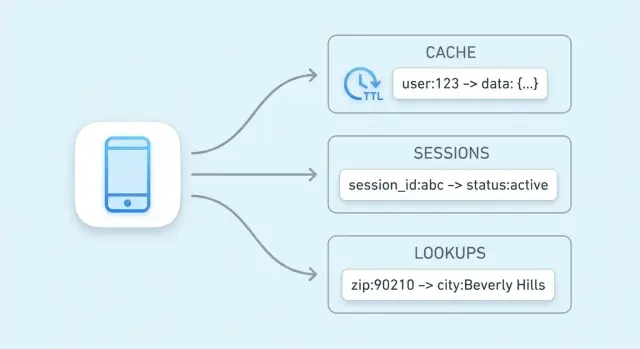
Pourquoi les magasins clé-valeur sont utilisés pour la rapidité
L'objectif principal d'un magasin clé-valeur est simple : réduire la latence pour les utilisateurs finaux et alléger la charge sur votre base de données principale. Plutôt que d'exécuter la même requête coûteuse ou de recalculer le même résultat, votre application peut récupérer une valeur précalculée en une seule étape prévisible.
Rapide parce que le chemin d'accès est simple
Un magasin clé-valeur est optimisé autour d'une seule opération : « donnée cette clé, renvoie la valeur. » Cette focalisation permet un chemin critique très court.
Dans de nombreux systèmes, une recherche peut souvent être traitée avec :
- un index en mémoire (pas de recherche disque)
- un hachage direct clé → emplacement (peu de recherche)
- moins de fonctionnalités coûteuses en CPU qu'un moteur de requête généraliste
Le résultat est des temps de réponse faibles et cohérents — exactement ce qu'il faut pour la mise en cache, le stockage de sessions et d'autres recherches ultra-rapides.
Rapide parce que cela évite du travail ailleurs
Même si votre base est bien optimisée, elle doit toujours parser les requêtes, planifier, lire des index et coordonner la concurrence. Si des milliers de requêtes demandent la même liste « top products », ce travail répété s'accumule.
Un cache clé-valeur déplace ce trafic de lectures répétées hors de la base. Votre base peut se concentrer sur ce qui la nécessite vraiment : écritures, jointures complexes, reporting et lectures sensibles à la cohérence.
Tous les workloads ne conviennent pas
La rapidité n'est pas gratuite. Les magasins clé-valeur sacrifient généralement les requêtes riches (filtres, jointures) et peuvent offrir des garanties différentes de persistance et de cohérence selon la configuration.
Ils excellent quand vous pouvez nommer les données par une clé claire (par exemple user:123, cart:abc) et que vous voulez une récupération rapide. Si vous devez souvent « trouver tous les éléments où X », une base relationnelle ou orientée document est généralement un meilleur stockage primaire.
Fondamentaux : clés, valeurs et recherches
Un magasin clé-valeur est le type de base de données le plus simple : vous stockez une valeur (des données) sous une clé unique (un libellé), et plus tard vous récupérez la valeur en fournissant la clé.
Ce que sont réellement une « clé » et une « valeur »
Considérez une clé comme un identifiant facile à reproduire exactement, et une valeur comme l'objet que vous voulez récupérer.
- Consigne à manteaux : votre ticket est la clé ; votre manteau est la valeur.
- Carnet d'adresses : « Alice Chen » (ou un ID de contact) est la clé ; le numéro et les détails sont la valeur.
- Sessions : un token de session aléatoire est la clé ; l'ID utilisateur et l'état de connexion sont la valeur.
Les clés sont généralement des chaînes courtes (comme user:1234 ou session:9f2a...). Les valeurs peuvent être petites (un compteur) ou plus volumineuses (un blob JSON).
Les magasins clé-valeur sont construits pour des requêtes « donnez-moi la valeur pour cette clé ». En interne, beaucoup utilisent une structure proche d'une table de hachage : la clé est transformée en un emplacement où la valeur se trouve rapidement.
C'est pourquoi vous entendrez souvent parler de recherches en temps constant (notées O(1)). Les performances dépendent plus du nombre de requêtes que du nombre total d'enregistrements. Ce n'est pas magique — collisions et limites mémoire comptent — mais pour les usages de cache/session, c'est très rapide.
Déploiements typiques : en mémoire, sur disque ou hybride
- En mémoire : lectures/écritures les plus rapides ; les données peuvent être perdues au redémarrage sauf si elles sont persistées.
- Sur disque : plus lent que la RAM mais stocke plus de données et survit aux redémarrages.
- Hybride : conserve les données chaudes en mémoire tout en écrivant sur disque pour la récupération.
Ce que signifie « données chaudes » (et pourquoi c'est important)
Données chaudes = la petite portion d'informations demandée de manière répétée (pages produits populaires, sessions actives, compteurs de limitation de débit). Garder ces données dans un magasin clé-valeur — surtout en mémoire — évite des requêtes plus lentes vers la base et maintient des temps de réponse prévisibles sous charge.
Mise en cache 101 : quoi mettre en cache et pourquoi
La mise en cache consiste à garder une copie de données souvent nécessaires dans un endroit plus rapide que la source originale. Un magasin clé-valeur est un endroit courant pour faire cela car il peut retourner une valeur en une seule lecture par clé, souvent en quelques millisecondes.
Quand la mise en cache est la plus utile
La mise en cache brille quand les mêmes questions sont posées encore et encore : pages populaires, recherches répétées, appels d'API courants ou calculs coûteux. Elle est aussi utile quand la source réelle est plus lente ou limitée en taux — par exemple une base surchargée ou une API tierce payante.
Exemples pratiques à mettre en cache
Bons candidats : résultats fréquemment lus et non nécessitant une fraîcheur absolue :
- Résumés de profil utilisateur (nom, URL d'avatar, préférences)
- Listes de produits et pages de catégorie
- Résultats calculés (recommandations, totaux)
- Configuration et flags de fonctionnalité lus à chaque requête
- Réponses d'API externes utilisables temporairement
Règle simple : mettez en cache des sorties que vous pouvez régénérer si nécessaire. Évitez de mettre en cache des données qui changent constamment ou qui doivent être cohérentes sur toutes les lectures (par ex. un solde bancaire).
Pourquoi la mise en cache réduit la pression sur bases et APIs
Sans cache, chaque vue de page peut déclencher plusieurs requêtes ou appels d'API. Avec un cache, l'application peut servir de nombreuses requêtes depuis le magasin clé-valeur et ne « retomber » sur la base ou l'API qu'en cas de miss. Cela baisse le volume de requêtes, réduit la contention de connexions et peut améliorer la fiabilité lors des pics de trafic.
Risques : données périmées et lectures incohérentes
La mise en cache échange fraîcheur contre vitesse. Si les valeurs en cache ne sont pas mises à jour rapidement, les utilisateurs peuvent voir des informations périmées. Dans les systèmes distribués, deux requêtes peuvent brièvement lire des versions différentes de la même donnée.
Gérez ces risques en choisissant des TTL adaptés, en décidant quelles données peuvent être « légèrement anciennes » et en concevant votre application pour tolérer des misses ou des délais de rafraîchissement occasionnels.
Patterns de cache courants et quand les utiliser
Un pattern de cache est un flux répétable pour lire et écrire quand un cache est impliqué. Le choix dépend moins de l'outil (Redis, Memcached, etc.) que de la fréquence de changement des données sous-jacentes et de la tolérance au stale.
Cache-aside (chargement paresseux)
Avec cache-aside, votre application contrôle explicitement le cache :
- Lire depuis le cache par clé.
- Si miss, lire depuis la base/source de vérité.
- Mettre le résultat dans le cache avec un TTL.
- Retourner le résultat.
Idéal pour : données lues souvent mais changées rarement (pages produits, configurations). Bon choix par défaut car les défaillances dégradent gracieusement : si le cache est vide, on peut toujours lire la base.
Read-through vs write-through
Read-through : la couche cache charge depuis la base en cas de miss (l'app lit « depuis le cache » et le cache sait comment charger). Simplifie le code applicatif mais complique la couche cache (intégration d'un loader).
Write-through : chaque écriture va au cache et à la base de manière synchrone. Les lectures sont souvent chaudes et cohérentes, mais les écritures sont plus lentes.
Convient quand on veut moins de misses et une simplicité de lecture, et que la latence d'écriture est acceptable.
Write-back / write-behind
Avec write-back, l'app écrit d'abord dans le cache et le cache pousse les changements vers la base plus tard (souvent en lots).
Avantages : écritures très rapides et charge base réduite.
Risque : si le nœud cache tombe avant le flush, vous pouvez perdre des données. À n'utiliser que si la perte est tolérable ou si vous avez des mécanismes de durabilité robustes.
Choisir selon la fréquence de changement
Si les données changent rarement, cache-aside avec un TTL sensé suffit généralement. Si les données changent fréquemment et que les lectures obsolètes sont problématiques, envisagez write-through (ou des TTL très courts + invalidation explicite). Si le volume d'écriture est extrême et que la perte occasionnelle est acceptable, write-behind peut valoir le compromis.
Contrôles de fraîcheur : TTLs, expiration et invalidation
Conserver les caches « assez frais » consiste surtout à choisir la bonne stratégie d'expiration pour chaque clé. L'objectif n'est pas l'exactitude parfaite, mais d'éviter que des résultats obsolètes surprennent les utilisateurs tout en conservant les bénéfices de vitesse.
TTLs et expirations : rôle et choix
Un TTL (time to live) définit une expiration automatique : la clé disparaît après la durée. Les TTL courts réduisent l'obsolescence mais augmentent les misses et la charge sur la source ; les TTL longs améliorent le hit rate mais risquent de servir des valeurs dépassées.
Façon pratique de choisir :
- Alignez avec la fréquence de changement des données sous-jacentes. Les prix produits peuvent nécessiter des minutes ; un profil utilisateur, des heures.
- Considérez l'impact métier. Un compteur de « likes » peut être légèrement périmé ; un solde, non.
- Ajoutez du jitter pour éviter des expirations massives simultanées.
Invalidation active : supprimer ou mettre à jour quand les données changent
Le TTL est passif. Quand vous savez qu'une donnée a changé, mieux vaut souvent invalider activement : supprimer l'ancienne clé ou écrire la nouvelle valeur immédiatement.
Exemple : après qu'un utilisateur change son e‑mail, supprimez user:123:profile ou mettez-la à jour dans le cache immédiatement. L'invalidation active réduit la fenêtre d'obsolescence, mais exige que l'application réalise ces mises à jour de façon fiable.
Clés versionnées : invalidation simple et à faible risque
Au lieu de supprimer, incluez une version dans le nom de clé, par ex. product:987:v42. Quand le produit change, incrémentez la version et commencez à lire/écrire v43. Les anciennes versions expirent naturellement. Cela évite les races où un serveur supprime pendant qu'un autre écrit.
Gérer les stampedes
Un stampede arrive quand une clé populaire expire et que beaucoup de requêtes la régénèrent en même temps.
Correctifs courants :
- Coalescence/locking : une requête reconstruit, les autres attendent.
- Servir du stale pendant revalidation : renvoyer l'ancienne valeur brièvement tout en la rafraîchissant en arrière-plan.
- Rafraîchissement anticipé : renouveler avant la fin du TTL pour les clés chaudes.
Stockage de sessions avec un magasin clé-valeur
Conserver le contrôle total du code
Exportez le code source quand vous êtes prêt à l'exécuter dans votre propre pipeline.
Les sessions sont un petit ensemble d'informations permettant à votre application de reconnaître un client. Au minimum : un ID/session (token) qui pointe vers un état côté serveur. Selon le produit, cela peut inclure l'ID utilisateur, des flags de connexion, des rôles, un nonce CSRF, préférences temporaires ou le contenu du panier.
Pourquoi les magasins clé-valeur conviennent aux sessions
Les accès de session sont simples : lookup par token, fetch de la valeur, mise à jour et expiration. Ils facilitent aussi l'application de TTLs pour que les sessions inactives disparaissent automatiquement, ce qui maintient le stockage propre et réduit le risque en cas de fuite de token.
Flux typique :
- À la connexion : créer un token aléatoire et stocker les données de session sous cette clé.
- À chaque requête : lire par token, rafraîchir le TTL si vous utilisez une expiration glissante.
- Au logout (ou suspicion) : supprimer la clé immédiatement.
Conception des clés de session
Utilisez des clés claires et gardez les valeurs petites :
- Nommage :
sess:<token> ou sess:v2:<token> (le versioning aide pour les évolutions).
- Scoping utilisateur : maintenir
user_sess:<userId> -> <token> pour forcer « une session active par utilisateur » ou révoquer les sessions par utilisateur.
- Limites de taille : n'entassez pas tout le profil dans la session. Stockez l'essentiel ; conservez les données volumineuses dans la base et référencez-les.
Logout et rotation
Le logout doit supprimer la clé de session et les index liés (par ex. user_sess:<userId>). Pour la rotation (recommandée après connexion, changement de privilèges ou périodiquement), créez un nouveau token, écrivez la nouvelle session, puis supprimez l'ancienne. Cela réduit la fenêtre pendant laquelle un token volé est utile.
Recherches haute-vitesse au-delà du caching
Le caching est l'usage le plus courant, mais ce n'est pas la seule façon dont un magasin clé-valeur accélère un système. De nombreuses applications ont besoin de lectures rapides pour de petits états référencés fréquemment — des données « proches de la source de vérité » qui doivent être vérifiées rapidement à presque chaque requête.
Données d'autorisation : permissions et droits
Les vérifications d'autorisation sont souvent sur le chemin critique : chaque appel d'API peut devoir répondre « cet utilisateur peut‑il faire ça ? ». Aller lire les permissions dans une base relationnelle à chaque requête ajoute de la latence et de la charge.
Un magasin clé-valeur peut contenir des données d'autorisation compactes pour des lectures rapides, par exemple :
perm:user:123 → liste/ensemble de codes de permissionentitlement:org:45 → fonctionnalités activées par plan
Utile quand le modèle de permissions est fortement en lecture et change peu. Lors des modifications (rôles, upgrades), mettez à jour ou invalidez un petit ensemble de clés pour que la prochaine requête respecte les nouvelles règles.
Feature flags et lectures de configuration
Les feature flags sont des petites valeurs lues fréquemment et qui doivent être disponibles rapidement et de manière cohérente.
Pattern courant :
flag:new-checkout → true/falseconfig:tax:region:EU → blob JSON ou configuration versionnée
Les magasins clé-valeur conviennent car les lectures sont simples et très rapides. Versionner les valeurs (par ex. config:v27:...) rend les déploiements plus sûrs et facilite le rollback.
Limitation de débit et throttling avec compteurs
La limitation se ramène souvent à des compteurs par utilisateur, clé API ou IP. Les magasins offrent des opérations atomiques pour incrémenter un compteur en toute sécurité malgré de nombreuses requêtes simultanées.
Exemples :
rl:user:123:minute → incrément par requête, expire après 60srl:ip:203.0.113.10:second → contrôle de rafales sur fenêtres courtes
Avec un TTL, les compteurs se réinitialisent automatiquement, sans jobs en arrière-plan. C'est une base pratique pour protéger les points coûteux ou appliquer des quotas par plan.
Clés d'idempotence pour endpoints sûrs aux retries
Les opérations « faire exactement une fois » (paiements, etc.) nécessitent une protection contre les retries. Un magasin clé-valeur peut enregistrer des clés d'idempotence :
idem:pay:order_789:clientKey_abc → résultat ou statut stocké
Au premier passage, traitez et stockez l'issue avec un TTL. Aux retries, retournez le résultat stocké au lieu de réexécuter l'opération. Le TTL empêche une croissance infinie tout en couvrant la fenêtre réaliste de retry.
Ces usages ne sont pas du caching classique ; ils visent à garder une latence basse pour des lectures fréquentes et des primitives de coordination nécessitant vitesse et atomicité.
Structures de données utiles et opérations atomiques
Prototyper un endpoint mis en cache
Prototyper un endpoint avec cache depuis le chat et mesurer les améliorations de latence dès le début.
Un « magasin clé-valeur » n'est pas forcément « chaîne → chaîne ». Beaucoup de systèmes offrent des structures riches pour modéliser des besoins courants directement dans le store — souvent plus vite et avec moins de pièces mobiles que d'implémenter tout dans l'application.
Hashes / maps : plusieurs champs sous une même clé
Les hashes (maps) conviennent quand une entité a plusieurs attributs. Plutôt que d'avoir user:123:name, user:123:plan, user:123:last_seen, regroupez-les sous user:123 avec des champs.
Moins d'explosion de clés et possibilité de ne lire/écrire qu'un champ spécifique — utile pour profils, flags ou petites configurations.
Sets et sorted sets : appartenance et classement
Les sets sont pratiques pour « X appartient-il au groupe ? » :
- L'utilisateur a‑t‑il déjà utilisé un coupon ?
- Quels IDs produits sont dans la collection « soldes ? »
Les sorted sets ajoutent un ordre par score : leaderboards, top N, classement par popularité ou date. Stockez des scores (compteurs, timestamps) et lisez rapidement les premiers éléments.
Incréments atomiques et écritures conditionnelles
Les problèmes de concurrence apparaissent souvent sur des petites fonctionnalités : compteurs, quotas, actions uniques. Si deux requêtes font « lire → ajouter 1 → écrire », vous pouvez perdre des mises à jour.
Les opérations atomiques effectuent le changement comme une étape indivisible :
- Incrément atomique pour compteurs
- Écriture conditionnelle (set if missing, update si la version correspond)
Pourquoi les opérations atomiques simplifient compteurs et limites
Avec des incréments atomiques, plus besoin de verrous ou de coordination entre serveurs. Moins de races, du code plus simple et un comportement plus prévisible sous charge — essentiel pour la limitation et les quotas où « presque correct » devient rapidement problématique côté utilisateur.
Scalabilité face au trafic : réplication, sharding et disponibilité
Quand un magasin clé-valeur supporte un vrai trafic, « le rendre plus rapide » revient souvent à « le rendre plus large » : répartir lectures et écritures sur plusieurs nœuds tout en conservant un comportement prévisible en cas de panne.
Monter en charge : réplication vs sharding
Réplication : plusieurs copies des mêmes données.
- Utile pour les lectures intensives : les réplicas peuvent servir en parallèle.
- Les écritures vont souvent vers un primaire, puis répliquent — ce qui peut introduire un petit délai avant que les réplicas reflètent la dernière valeur.
Sharding : partitionner l'espace de clés entre nœuds.
- Chaque nœud possède un sous-ensemble de clés (par hash de clé).
- Le sharding augmente le débit en lecture et écriture car le travail est réparti, mais ajoute de la complexité opérationnelle (rééquilibrage, gestion des hot keys, suivi de la propriété des clés).
Beaucoup de déploiements combinent les deux : shards pour le débit, réplicas par shard pour la disponibilité.
Haute disponibilité et basculement
La haute disponibilité signifie que la couche cache/sessions continue de servir même quand un nœud échoue.
- Basculement (failover) : promotion automatique d'un réplica en primaire quand le primaire meurt.
- En pratique, l'app doit tolérer de brèves erreurs/retentatives pendant le basculement, et accepter que des écritures récentes puissent être perdues si elles n'étaient pas répliquées.
Routage côté client vs côté serveur
Avec le routage côté client, l'application (ou sa bibliothèque) calcule quel nœud possède une clé (hashing consistant). Très rapide, mais les clients doivent connaître la topologie.
Avec le routage côté serveur, vous envoyez les requêtes à un proxy/endpoint de cluster qui les achemine. Simplicité client et déploiement, au prix d'un saut réseau supplémentaire.
Planification de capacité : mémoire, marge et croissance
Planifiez la mémoire depuis le sommet :
- Estimez la taille du working-set (ce que vous gardez chaud), plus l'overhead métadonnées.
- Ajoutez de la marge (souvent 20–50%) pour pics, rééquilibrage et distribution inégale des clés.
- Validez le comportement d'éviction sous charge pour que le système dégénère progressivement au lieu de thrashing.
Fiabilité et compromis à comprendre
Les magasins clé-valeur semblent instantanés parce qu'ils gardent les données chaudes en mémoire et optimisent les accès. Cette rapidité a un coût : vous choisissez souvent entre performance, durabilité et cohérence. Comprendre ces compromis évite des surprises douloureuses.
Persistance : combien de données pouvez-vous vous permettre de perdre ?
Modes de persistance typiques :
- Aucune (purement en mémoire) : plus rapide et simple — jusqu'au prochain redémarrage qui efface tout. Idéal pour les caches recomputables.
- Snapshots : sauvegardes périodiques sur disque ; en cas de crash, vous perdez les changements depuis le dernier snapshot.
- Journaux append-only : écritures enregistrées séquentiellement. La récupération est plus lente que la mémoire pure, mais les pertes sont généralement limitées.
Choisissez le mode en fonction du rôle des données : le cache tolère la perte ; le stockage de sessions mérite plus d'attention.
Attentes de cohérence : mon écriture est‑elle bien persistée ?
En distribution, vous pouvez observer une cohérence éventuelle : une lecture peut brièvement renvoyer une ancienne valeur après une écriture, surtout lors d'un basculement ou d'un lag de réplication. Une cohérence plus forte (exiger des acks de plusieurs nœuds) réduit ces anomalies mais augmente la latence et peut réduire la disponibilité en cas de partition.
Quand la mémoire est pleine : éviction et comportement sous pression
Les caches se remplissent. Une politique d'éviction décide quoi supprimer : least-recently-used, least-frequently-used, aléatoire, ou « pas d'éviction » (ce qui transforme la mémoire pleine en échecs d'écriture). Décidez si vous préférez des entrées manquantes ou des erreurs sous pression.
Si le store est down : prévoir un mode dégradé
Supposez des pannes. Repliements typiques :
- Contourner le cache et lire depuis la base (avec limites)
- Servir des données légèrement périmées quand c'est sûr
- Echouer fermé sur les opérations sensibles (auth), laisser les fonctionnalités non critiques se dégrader
Concevoir ces comportements intentionnellement rend le système plus fiable côté utilisateur.
Sécurité, supervision et coûts
Tester les changements avec rollback
Expérimentez des patterns de cache en toute sécurité avec des snapshots et des rollbacks si nécessaire.
Un magasin clé-valeur se trouve souvent sur le « chemin chaud ». Il est donc à la fois sensible (tokens de session, identifiants) et coûteux (mémoire). Bien faire les bases dès le départ évite des incidents.
Sécurité : restreindre l'accès
Commencez par des frontières réseau claires : placez le store dans un sous‑réseau privé/VPC et n'autorisez que les services applicatifs qui en ont vraiment besoin.
Utilisez l'authentification si le produit le permet, appliquez le principe du moindre privilège (identifiants séparés pour apps, admins, automatisation), pivotez les secrets et évitez les tokens « root » partagés.
Chiffrez en transit (TLS) dès que possible — surtout si le trafic traverse des hôtes ou zones. Le chiffrement au repos dépend du produit/déploiement ; s'il est disponible, activez‑le et vérifiez aussi le chiffrement des sauvegardes.
Supervision : quoi surveiller au quotidien
Quelques métriques clefs :
- Hit rate : une baisse signale de mauvaises clés, TTLs trop courts ou churn à cause d'évictions.
- Latence (p95/p99) : des pics indiquent saturation, problèmes réseau ou valeurs volumineuses.
- Utilisation mémoire & évictions : mémoire élevée et évictions soutenues signifient que les données ne tiennent pas ou que la politique est inadaptée.
- Erreurs/timeouts : même de brèves indisponibilités peuvent entraîner une cascade vers la base.
Ajoutez des alertes sur les changements soudains et loggez les opérations importantes (sans divulguer de valeurs sensibles).
Coût : ce qui influence la facture
Principaux facteurs :
- Empreinte mémoire : valeurs volumineuses, trop de clés, données « agréables à avoir ».
- Trafic : volumes de lecture/écriture et transferts inter‑zones.
- Réplicas & haute disponibilité : plus de nœuds = plus de coût.
- Rétention : TTLs longs gardent les données plus longtemps et augmentent la mémoire nécessaire.
Un levier pratique : réduire la taille des valeurs et fixer des TTLs réalistes pour ne garder que l'actif utile.
Checklist d'implémentation et prochaines étapes
Checklist de déploiement pratique
Standardisez le naming des clés pour que les clés de cache et de session soient prévisibles, recherchables et sûres à opérer en masse. Une convention comme app:env:feature:id (ex. shop:prod:cart:USER123) évite les collisions et facilite le debug.
Définissez une stratégie de TTL avant le lancement. Décidez ce qui peut expirer vite (secondes/minutes), ce qui doit vivre plus longtemps (heures) et ce qui ne doit jamais être mis en cache. Si vous cachez des lignes de base de données, alignez les TTLs avec la fréquence de changement des données.
Rédigez un plan d'invalidation par type d'élément en cache :
- Expiration temporelle (TTL-only) pour la fraîcheur « suffisante »
- Invalidation événementielle quand vous savez exactement ce qui a changé (ex. mise à jour produit)
- Clés versionnées (ex.
product:v3:123) pour une invalidation globale simple
Mesurer le succès
Choisissez quelques métriques et suivez‑les dès le début :
- Taux de hit visé par endpoint (70–95% est souvent une fourchette réaliste)
- Réduction de la charge DB (queries/sec, CPU, utilisation des replicas)
- Changement de latence sur p95/p99, pas seulement la moyenne
Surveillez aussi les évictions et l'utilisation mémoire pour valider la taille du cache.
Pièges courants à éviter
Les valeurs surdimensionnées augmentent la latence réseau et la pression mémoire — préférez des fragments pré-calculés. Évitez les clés sans TTL (données périmées et fuites mémoire) et la croissance illimitée des clés (ex. mettre en cache chaque requête de recherche pour toujours). Méfiez-vous de mettre des données utilisateurs sous des clés partagées.
Prochaines étapes
Si vous évaluez des options, comparez un cache local en mémoire (in-process) et un cache distribué, et décidez où la cohérence est cruciale. Pour des détails d'implémentation et d'exploitation, consultez /docs. Si vous planifiez la capacité ou cherchez des estimations de coût, voyez /pricing.
Si vous construisez un nouveau produit ou modernisez un existant, il est utile de traiter le caching et le stockage de sessions comme des préoccupations de premier plan. Sur Koder, les équipes prototypent souvent une application complète (React côté web, services Go avec PostgreSQL, et éventuellement Flutter pour mobile) puis itèrent sur la performance avec des patterns comme cache-aside, TTLs et compteurs de rate-limiting. Des fonctionnalités de mode planning, snapshots et rollback facilitent l'expérimentation sûre des designs de clés et des stratégies d'invalidation, et vous pouvez exporter le code source lorsque vous êtes prêt à l'intégrer dans votre pipeline.