La gestion de la mémoire est l'ensemble des règles et mécanismes qu'un programme utilise pour demander de la mémoire, l'utiliser et la restituer. Tout programme en cours d'exécution a besoin de mémoire pour des variables, des données utilisateur, des tampons réseau, des images et des résultats intermédiaires. Comme la mémoire est limitée et partagée avec le système d'exploitation et d'autres applications, les langages doivent décider qui est responsable de la libérer et quand cela se produit.
Ces décisions façonnent deux résultats que la plupart des gens recherchent : la sensation de rapidité d'un programme, et sa fiabilité sous charge.
La performance n'est pas un seul chiffre. La gestion de la mémoire peut affecter :
- Le débit : combien de travail vous pouvez accomplir par seconde (requêtes traitées, images rendues, fichiers traités).
- La latence : combien de temps prend une opération individuelle, en particulier les pics de latence de queue causés par des pauses ou des allocations lentes.
- L'empreinte mémoire : combien de RAM le programme garde pendant son exécution, ce qui influence le coût, la durée de batterie et la fréquence du swap par l'OS.
Un langage qui alloue très vite mais marque parfois des pauses pour nettoyer peut briller dans les benchmarks tout en donnant une impression de saccades dans une app interactive. Un autre modèle qui évite les pauses peut demander une conception plus prudente pour prévenir les fuites et les erreurs de durée de vie.
Ce que signifie « sécurité » ici
La sécurité consiste à prévenir les défaillances liées à la mémoire, comme :
- Les plantages (accès à une mémoire invalide)
- La corruption de données (écrire là où il ne faut pas)
- Les vulnérabilités de sécurité (bugs que des attaquants peuvent transformer en exploit)
Beaucoup d'incidents de sécurité très médiatisés remontent à des erreurs mémoire comme l'utilisation après libération ou les débordements de tampon.
Ce guide est un tour non technique des principaux modèles mémoire utilisés par les langages populaires, ce qu'ils optimisent et les compromis que vous acceptez en en choisissant un.
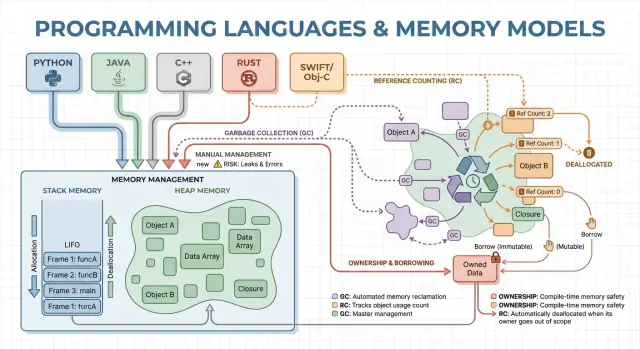
Concepts de base : pile, tas et durées de vie
La mémoire est l'endroit où votre programme conserve des données pendant son exécution. La plupart des langages l'organisent autour de deux zones principales : la pile et le tas.
Pile : stockage rapide et temporaire
Pensez à la pile comme une pile bien rangée de notes collantes pour la tâche en cours. Lorsqu'une fonction démarre, elle obtient un petit « cadre » sur la pile pour ses variables locales. Quand la fonction se termine, ce cadre est supprimé d'un coup.
C'est rapide et prévisible — mais cela ne fonctionne que pour des valeurs de taille connue et dont la durée de vie se termine avec l'appel de fonction.
Tas : stockage flexible et de plus longue durée
Le tas ressemble davantage à une réserve où l'on peut garder des objets aussi longtemps que nécessaire. Il est idéal pour des listes à taille dynamique, des chaînes ou des objets partagés entre différentes parties d'un programme.
Comme les objets du tas peuvent survivre à l'appel de fonction, la question clé devient : qui est responsable de les libérer, et quand ? Cette responsabilité constitue le « modèle de gestion de la mémoire » d'un langage.
Durées de vie, et pourquoi pointeurs/références comptent
Un pointeur ou une référence est un moyen d'accéder à un objet indirectement — comme connaître l'étagère d'une boîte dans la réserve. Si la boîte est jetée mais que vous avez encore le numéro d'étagère, vous pouvez lire des données indésirables ou provoquer un crash (classique bug d'utilisation après libération).
Un scénario simple
Imaginez une boucle qui crée un enregistrement client, formate un message, puis le jette :
- Sur la pile : petites variables temporaires utilisées pour le formatage.
- Sur le tas : l'enregistrement client et le texte du message (tailles variables).
Certains langages cachent ces détails (nettoyage automatique), d'autres les exposent (vous libérez explicitement, ou vous devez suivre des règles d'ownership). Le reste de cet article explore comment ces choix affectent vitesse, pauses et sécurité.
Gestion manuelle : contrôle avec risque accru
La gestion manuelle signifie que le programme (et donc le développeur) demande explicitement de la mémoire puis la libère plus tard. Concrètement, cela ressemble à malloc/free en C ou new/delete en C++. C'est encore courant en programmation système quand on a besoin d'un contrôle précis du moment d'acquisition et de restitution de la mémoire.
À quoi sert l'allocation explicite
On alloue typiquement quand un objet doit survivre à l'appel courant, croître dynamiquement (par ex. tampon redimensionnable) ou nécessiter une mise en page spécifique pour l'interopérabilité avec le matériel, l'OS ou des protocoles réseau.
Sans collecteur GC en arrière-plan, il y a moins de pauses surprises. L'allocation et la désallocation peuvent devenir très prévisibles, surtout avec des allocateurs personnalisés, des pools ou des tampons à taille fixe.
Le contrôle manuel peut également réduire la surcharge : pas de phase de traçage, pas de barrières d'écriture, et souvent moins de métadonnées par objet. Bien conçu, le code peut atteindre des objectifs de latence serrés et garder l'utilisation mémoire dans des limites strictes.
Risques pour la sécurité : modes d'échec classiques
Le compromis, c'est que le programme peut faire des erreurs que le runtime ne préviendra pas automatiquement :
- Fuites mémoire (oublier de libérer)
- Double-free (libérer deux fois)
- Use-after-free (accéder après libération)
Ces bugs peuvent provoquer crashes, corruption et vulnérabilités de sécurité.
Atténuations courantes
Les équipes réduisent les risques en limitant les endroits où l'allocation brute est autorisée et en s'appuyant sur des schémas comme :
- RAII en C++ (ressources libérées quand les objets sortent de portée)
- Smart pointers (ex.
std::unique_ptr) pour encoder la propriété
- Normes de codage, revues, sanitizers et analyses statiques
Quand c'est adapté
La gestion manuelle est souvent un bon choix pour le logiciel embarqué, les systèmes temps réel, les composants OS et les bibliothèques critiques pour la performance — des contextes où le contrôle fin et la latence prévisible priment sur la commodité du développeur.
Garbage collection : productivité et sécurité prévisible
La garbage collection (GC) est un nettoyage automatique de la mémoire : au lieu d'exiger que vous fassiez free, le runtime suit les objets et récupère ceux qui ne sont plus atteignables. Concrètement, cela permet de se concentrer sur le comportement et le flux de données tandis que le système gère la majorité des décisions d'allocation/désallocation.
La plupart des collecteurs identifient d'abord les objets vivants, puis récupèrent le reste.
La GC par traçage commence à partir des « racines » (variables de pile, références globales, registres), suit les références pour marquer tout ce qui est atteignable, puis balaie le tas pour libérer les objets non marqués. Si rien ne pointe vers un objet, il devient éligible à la collecte.
Styles de GC courants (haut niveau)
La GC générationnelle part du constat que beaucoup d'objets meurent jeunes. Elle sépare le tas en générations et collecte souvent la zone jeune, ce qui est généralement moins coûteux et améliore l'efficacité globale.
La GC concurrente exécute des parties de la collecte en parallèle des threads applicatifs pour réduire les longues pauses. Elle peut nécessiter plus de mécanismes pour garder une vue cohérente de la mémoire pendant que le programme continue de tourner.
La GC échange typiquement le contrôle manuel contre du travail à l'exécution. Certains systèmes privilégient un débit élevé (beaucoup de travail par seconde) mais peuvent introduire des pauses stop-the-world. D'autres minimisent les pauses pour les applications sensibles à la latence mais ajoutent une surcharge en exécution normale.
Pourquoi les développeurs l'aiment
La GC élimine toute une classe de bugs de durée de vie (notamment use-after-free) car les objets ne sont pas récupérés tant qu'ils sont atteignables. Elle réduit aussi les fuites causées par des désallocations manquées (même si on peut toujours « fuir » en conservant des références trop longtemps). Dans de grands codebases où la propriété est difficile à suivre manuellement, cela accélère souvent l'itération.
Où on la trouve
Les runtimes avec GC sont courants sur la JVM (Java, Kotlin), .NET (C#, F#), Go et les moteurs JavaScript dans les navigateurs et Node.js.
Comptage de références : nettoyage immédiat avec compromis
Le comptage de références est une stratégie où chaque objet suit combien de « propriétaires » (références) pointent vers lui. Quand le compteur tombe à zéro, l'objet est libéré immédiatement. Cette immédiateté est intuitive : dès que rien ne peut atteindre un objet, sa mémoire est récupérée.
Chaque fois que vous copiez ou stockez une référence, le runtime incrémente son compteur ; quand une référence disparaît, il le décrémente. Atteindre zéro déclenche le nettoyage sur le champ.
Cela rend la gestion des ressources simple : les objets libèrent souvent la mémoire près du moment où vous avez cessé de les utiliser, ce qui peut réduire le pic de mémoire et éviter une récupération retardée.
Le comptage de références tend à générer une surcharge constante et régulière : opérations d'incrément/décrément à de nombreuses affectations et appels de fonction. Cette surcharge est généralement faible, mais omniprésente.
L'avantage est l'absence typique de grosses pauses stop-the-world comme certains traceurs. La latence est souvent plus régulière, bien que des rafales de désallocation puissent survenir lorsqu'un grand graphe d'objets perd son dernier propriétaire.
Gros piège : les cycles
Le comptage de références ne peut pas récupérer les objets impliqués dans un cycle. Si A référence B et B référence A, les deux compteurs restent supérieurs à zéro même si rien d'autre ne peut atteindre ces objets — créant une fuite mémoire.
Les écosystèmes gèrent cela de plusieurs façons :
- Références faibles pour casser les cycles dans les motifs communs (délégués, liens parent/enfant).
- Détection de cycles en complément du comptage (une passe de traçage qui trouve les cycles inaccessibles).
Où on le voit
- Swift / Objective-C utilisent ARC (Automatic Reference Counting), avec des références « strong/weak/unowned » pour gérer les cycles.
- Python utilise le comptage de références pour un nettoyage immédiat, plus un détecteur de cycles pour collecter les cycles.
Ownership et borrowing : sécurité à la compilation
Comparez GC et pooling
Démarrez une démo par requête pour comparer l'ajustement du GC et les approches de pooling.
L'ownership et le borrowing sont un modèle mémoire surtout associé à Rust. L'idée : le compilateur applique des règles qui rendent difficile la création de pointeurs pendants, de doubles libérations et de nombreuses races de données — sans s'appuyer sur un ramasse-miettes à l'exécution.
Ownership : un propriétaire clair, nettoyage déterministe
Chaque valeur a exactement un « propriétaire » à la fois. Quand le propriétaire sort de portée, la valeur est nettoyée immédiatement et de manière prévisible. Cela donne une gestion déterministe des ressources (mémoire, descripteurs de fichiers, sockets) semblable à la désallocation manuelle, mais avec bien moins de façons d'erreur.
L'ownership peut aussi se déplacer : assigner une valeur à une nouvelle variable ou la passer à une fonction peut transférer la responsabilité. Après un move, l'ancien identifiant ne peut plus être utilisé, ce qui empêche par construction l'utilisation après libération.
Borrowing : accès temporaire sans prendre la propriété
Le borrowing permet d'utiliser une valeur sans en devenir propriétaire.
Un emprunt partagé autorise l'accès en lecture seule et peut être copié librement.
Un emprunt mutable permet des modifications, mais doit être exclusif : tant qu'il existe, rien d'autre ne peut lire ou écrire la même valeur. Cette règle « un écrivain ou plusieurs lecteurs » est vérifiée à la compilation.
Bénéfices de sécurité — et coûts
Comme les durées de vie sont suivies, le compilateur peut rejeter du code qui ferait survivre une référence au-delà des données qu'elle référence, éliminant de nombreux bugs de pointeur pendant la compilation. Les mêmes règles empêchent une grande classe de conditions de course en code concurrent.
Le compromis est une courbe d'apprentissage et certaines contraintes de conception. Il peut être nécessaire de restructurer les flux de données, introduire des frontières de propriété plus claires ou utiliser des types spécialisés pour l'état partagé mutable.
Où ça brille
Ce modèle convient bien au code système — services, embarqué, réseau et composants sensibles à la performance — quand on veut un nettoyage prévisible et une faible latence sans pauses GC.
Arenas, régions et pools : schémas d'allocation rapides
Quand vous créez beaucoup d'objets de courte durée — nœuds AST dans un parseur, entités par frame dans un jeu, données temporaires lors d'une requête web — le coût d'allouer et libérer chaque objet individuellement peut dominer l'exécution. Les arenas (régions) et pools échangent des libérations fines contre une gestion rapide en masse.
Qu'est-ce qu'une arena/region
Une arena est une « zone » mémoire où vous allouez beaucoup d'objets puis libérez tous d'un coup en réinitialisant l'arène.
Plutôt que de suivre la durée de vie de chaque objet individuellement, vous attachez les durées de vie à une frontière claire : « tout ce qui est alloué pour cette requête » ou « tout ce qui est alloué pendant la compilation de cette fonction ».
Pourquoi c'est rapide
Les arenas sont souvent rapides car elles :
- réduisent les appels à l'allocateur (souvent simple incrément d'un pointeur)
- évitent le coût de libération par objet
- améliorent la localité de cache en gardant des objets liés proches
Cela peut améliorer le débit et réduire les pics de latence causés par des frees fréquents ou la contention de l'allocateur.
Cas d'utilisation typiques
Arenas et pools apparaissent dans :
- parseurs et compilateurs (arbres syntaxiques, tables des symboles)
- données limitées à une requête côté serveur
- jeux (allocations par frame réinitialisées à chaque frame)
- simulations et traitements par lots
Considérations de sécurité
La règle principale : ne laissez pas des références s'échapper de la région qui possède la mémoire. Si quelque chose alloué dans une arena est stocké globalement ou retourné au-delà de la vie de l'arène, vous risquez un use-after-free.
Les langages et bibliothèques gèrent cela différemment : certains comptent sur la discipline et les API, d'autres encodent la frontière de région dans les types.
Les arenas/pools ne sont pas une alternative à la GC ou à l'ownership — elles sont souvent complémentaires. Les langages GC utilisent fréquemment des pools pour les chemins chauds ; les langages basés sur l'ownership peuvent employer des arenas pour grouper les allocations et rendre les durées de vie explicites. Bien utilisés, ils offrent une allocation « rapide par défaut » sans sacrifier la clarté du moment où la mémoire est libérée.
Optimisations du compilateur et du runtime qui changent la donne
Planifiez les durées de vie dès le départ
Cartographiez les durées de vie des objets et les frontières de propriété avant de générer du code.
Le modèle mémoire d'un langage n'est qu'une partie de l'histoire de performance et de sécurité. Les compilateurs et runtimes modernes réécrivent votre programme pour allouer moins, libérer plus tôt et éviter la surcharge. C'est pourquoi des idées reçues comme « la GC est lente » ou « la mémoire manuelle est la plus rapide » se brisent souvent dans des applications réelles.
Analyse d'évasion : quand le tas n'est pas nécessaire
Beaucoup d'allocations existent uniquement pour passer des données entre fonctions. Avec l'analyse d'évasion, un compilateur peut prouver qu'un objet ne survit pas à la portée courante et le garder sur la pile plutôt que sur le tas.
Cela peut supprimer une allocation sur le tas, ainsi que ses coûts associés (suivi GC, mises à jour de compteurs, verrous d'allocateur). Dans les langages managés, c'est une raison majeure pour laquelle de petits objets peuvent coûter moins cher qu'on pourrait le penser.
Inlining et suppression d'allocations
Quand un compilateur inline une fonction (remplace l'appel par le corps), il peut « voir à travers » des couches d'abstraction. Cette visibilité permet des optimisations comme :
- éliminer des objets temporaires
- remplacer un objet par quelques variables locales (scalar replacement)
- supprimer le trafic de comptage de références quand les durées de vie deviennent évidentes
Des API bien conçues peuvent devenir « sans coût » après optimisation, même si elles semblent gourmandes en allocations dans le code source.
JIT vs compilation ahead-of-time
Un JIT (just-in-time) peut optimiser en se basant sur des données de production : chemins chauds, tailles d'objets typiques, schémas d'allocation. Cela améliore souvent le débit, mais peut ajouter du temps de warm-up et des pauses occasionnelles pour la recompilation ou la GC.
La compilation ahead-of-time doit deviner davantage, mais offre un démarrage prévisible et une latence plus stable.
Leviers de réglage runtime (et quand s'en servir)
Les runtimes GC exposent des réglages comme la taille du heap, les cibles de pause et les seuils générationnels. Ajustez-les quand vous avez des preuves mesurées (pics de latence, pression mémoire), pas en premier réflexe.
Pourquoi le même algorithme se comporte différemment
Deux implémentations d'un même algorithme peuvent diverger en nombre d'allocations temporaires, objets intermédiaires et accessions de pointeurs. Ces différences interagissent avec les optimiseurs, l'allocateur et le comportement du cache — les comparaisons de performance nécessitent donc du profiling, pas des suppositions.
Les choix de gestion mémoire ne changent pas seulement comment vous écrivez du code — ils modifient quand le travail est fait, combien de mémoire il vous faut réserver et la consistance perçue des performances.
Débit vs latence (un exemple concret)
Le débit mesure « combien de travail par unité de temps ». Pensez à un job nocturne qui traite 10 millions d'enregistrements : si la GC ou le comptage de références ajoute une petite surcharge mais accélère le développement, vous pourriez tout de même finir le plus rapidement.
La latence mesure « combien de temps prend une opération ». Pour une requête web, une seule réponse lente nuit à l'expérience utilisateur même si le débit moyen est élevé. Un runtime qui pause occasionnellement pour récupérer la mémoire peut convenir pour du batch, mais sera gênant pour une application interactive.
Empreinte mémoire : coût et vitesse
Une empreinte mémoire plus grande augmente les coûts cloud et peut ralentir les programmes. Quand le working set ne tient pas bien dans les caches CPU, le processeur attend plus souvent la RAM. Certaines stratégies échangent mémoire supplémentaire contre vitesse (conserver des objets libérés dans des pools), d'autres réduisent la mémoire au prix d'une surcharge de gestion.
Fragmentation et localité de cache (en termes simples)
La fragmentation survient quand la mémoire libre est éclatée en petits morceaux — comme essayer de garer un van dans un parking avec des places minuscules. Les allocateurs passent plus de temps à chercher de l'espace et la mémoire peut grossir même quand il y a « assez » de mémoire libre.
La localité de cache signifie que les données liées sont proches. L'allocation par pool/arène améliore souvent la localité, tandis que des heaps mixtes d'objets de longue durée peuvent perdre en proximité et en efficacité cache.
Exigences de temps prévisible
Si vous avez besoin de temps de réponse constants — jeux, applications audio, systèmes de trading, contrôleurs embarqués ou temps réel — « généralement rapide mais parfois lent » peut être pire que « un peu moins rapide mais constant ». C'est là que des schémas de désallocation prédictibles et un contrôle strict des allocations comptent.
Checklist de mesure
- Mesurer débit (jobs/sec) et latence de queue (p95/p99)
- Profiler les allocations : taux d'allocation, temps de pause, temps passé en alloc/free
- Utiliser des charges représentatives (formes de trafic réelles, tailles de données, concurrence)
- Suivre la mémoire : RSS au pic, taille du heap dans le temps, métriques de fragmentation (si dispo)
- Répéter les exécutions pour capter la variabilité (effets de warm-up, cycles GC en arrière-plan)
Les erreurs mémoire ne sont pas que des « erreurs de programmation ». Dans de nombreux systèmes réels, elles deviennent des problèmes de sécurité : plantages (DoS), exposition de données (lecture de mémoire libérée ou non initialisée) ou conditions exploitables où un attaquant guide le programme vers l'exécution de code non prévu.
Différentes stratégies de gestion de mémoire échouent généralement de manières différentes :
- Gestion manuelle (C/C++) : souvent sujette à use-after-free, double free et buffer overflows — issues qui corrompent la mémoire et peuvent être exploitables.
- Garbage collection : élimine la plupart des erreurs de type UAF car les objets ne sont pas libérés tant qu'ils sont atteignables, mais on peut toujours avoir des fuites mémoire (références gardées trop longtemps) et des risques lors d'interop natif non sûr.
- Comptage de références : nettoyage immédiat mais susceptible de fuites par cycles et d'effets subtils de durée de vie avec l'état partagé.
- Ownership/borrowing (Rust) : prévient beaucoup de classes d'UAF et de races à la compilation en rendant difficiles les références pendantes ou la mutation partagée non synchronisée.
Sécurité des threads et concurrence
La concurrence change le modèle de menace : une mémoire « correcte » dans un thread peut devenir dangereuse lorsqu'un autre thread la libère ou la modifie. Les modèles qui imposent des règles de partage (ou qui exigent une synchronisation explicite) réduisent le risque de conditions de course menant à la corruption d'état, à des fuites de données et à des crashes intermittents.
La défense en profondeur reste nécessaire
Aucun modèle mémoire n'élimine tous les risques — les bugs de logique (mauvaise authentification, défauts de validation) subsistent. Les bonnes équipes multiplient les protections : sanitizers en tests, bibliothèques standard sûres, revues de code strictes, fuzzing, et frontières serrées autour du code unsafe/FFI. La sécurité mémoire réduit fortement la surface d'attaque, mais n'offre pas une garantie absolue.
Outils et techniques pour détecter tôt les problèmes mémoire
Créez un prototype mesurable
Transformez votre idée d'architecture en une application React + Go + Postgres depuis une seule conversation.
Les problèmes mémoire sont plus faciles à corriger quand on les attrape près du commit qui les a introduits. L'idée clé est de mesurer d'abord, puis de réduire le problème avec l'outil adapté.
Bases du profiling : quoi mesurer (et quand)
Commencez par décider si vous poursuivez la vitesse ou la croissance mémoire.
Pour la performance, mesurez le temps mur, le temps CPU, le taux d'allocation (octets/sec) et le temps passé en GC ou allocateur. Pour la mémoire, suivez le RSS au pic, le RSS en régime et le nombre d'objets dans le temps. Exécutez la même charge avec des entrées constantes ; de petites variations peuvent masquer le churn d'allocation.
Catégories d'outils (ce que chacun trouve)
- Profileurs CPU + allocation : indiquent où le temps est passé et quelles voies allouent le plus. Idéal pour repérer « la mort par mille petites allocations ».
- Détecteurs de fuite : signalent la mémoire allouée mais jamais libérée (ou jamais rendue inatteignable pour la GC).
- Sanitizers : détectent use-after-free, débordements, conditions de course et comportements indéfinis en tests.
- Fuzzing : injecte des entrées inattendues pour déclencher crashes et corruptions que les tests normaux ratent.
Repérer les hotspots d'allocation et réduire le churn
Signes courants : une requête alloue beaucoup plus que prévu, ou la mémoire monte avec le trafic même si le débit reste stable. Les corrections typiques incluent la réutilisation de tampons, le passage à une allocation par arène/pool pour les objets temporaires, et la simplification des graphes d'objets pour que moins d'objets survivent entre cycles.
Workflow pratique pour fuites et crashes
Reproduisez avec une entrée minimale, activez les vérifications runtime les plus strictes (sanitizers/vérification GC), puis capturez :
- un profil (CPU + allocations), 2) un snapshot heap ou rapport de fuite, 3) une trace de pile au point de défaillance.
Considérez la première correction comme une expérimentation ; relancez les mesures pour confirmer que le changement a réduit les allocations ou stabilisé la mémoire — sans déplacer le problème ailleurs. Pour plus d'interprétation des compromis, voir /blog/performance-trade-offs-throughput-latency-memory-use.
Choisir un langage : aligner le modèle mémoire sur vos objectifs
Choisir un langage ne concerne pas que la syntaxe ou l'écosystème — son modèle mémoire façonne la vitesse de développement quotidienne, le risque opérationnel et la prévisibilité des performances sous trafic réel.
Commencez par vos exigences (pas vos préférences)
Cartographiez vos besoins produit à une stratégie mémoire en répondant à quelques questions pratiques :
- Compétences de l'équipe et tolérance à la complexité : la plupart des contributeurs seront-ils à l'aise pour raisonner sur les durées de vie et l'ownership, ou préférez-vous que le runtime s'en charge ?
- Latence vs débit : avez-vous besoin d'une latence de queue cohérente (trading, audio, contrôle temps réel) ou le débit moyen est‑il prioritaire (backends web, batch) ?
- Contraintes de déploiement : exécutez-vous dans un environnement très restreint en mémoire (embarqué, mobile) ou avez-vous de la marge pour un runtime et des heaps plus gros ?
Correspondances courantes
- Garbage collection (GC) : souvent adapté aux services backend et applications produit où la vélocité des développeurs et la sécurité importent plus que des pauses d'ordre microsecondes.
- Ownership/borrowing (ex. Rust) : adapté au logiciel système, composants critiques en performance et code sensible à la sécurité où les bugs mémoire sont inacceptables.
- Comptage de références (RC) : fonctionne bien pour les applications desktop/mobile et UI où un nettoyage incrémental prévisible est apprécié, en acceptant la gestion des cycles et la surcharge par affectation.
Migration et interopérabilité
Si vous changez de modèle, prévoyez des frictions : appels aux bibliothèques existantes (FFI), conventions mémoire mixtes, outils et marché du recrutement. Des prototypes permettent de révéler les coûts cachés (pauses, croissance mémoire, overhead CPU) tôt.
Une approche pratique : prototyper la même fonctionnalité dans les environnements envisagés et comparer taux d'allocation, latence de queue et mémoire maximale sous une charge représentative. Les équipes font parfois ce type d'évaluation « pomme pour pomme » dans Koder.ai : vous pouvez rapidement monter un front React léger plus un backend Go + PostgreSQL, itérer sur les formes de requêtes et structures de données pour voir comment un service GC se comporte en trafic réaliste (et exporter le code source quand vous êtes prêt à aller plus loin).
Cadre décisionnel léger
Définissez les 3–5 contraintes principales, construisez un prototype léger et mesurez mémoire, latence de queue et modes de défaillance.
| Modèle | Sécurité par défaut | Prévisibilité de la latence | Vélocité des développeurs | Pièges typiques |
|---|
| Manuel | Faible–Moyenne | Élevée | Moyenne | fuites, use-after-free |
| GC | Élevée | Moyenne | Élevée | pauses, croissance du heap |
| RC | Moyenne–Élevée | Élevée | Moyenne | cycles, surcharge |
| Ownership | Élevée | Élevée | Moyenne | courbe d'apprentissage |