Pourquoi les équipes butent contre les intégrations traditionnelles
La plupart des produits commencent par des intégrations simples point à point : le système A appelle le système B, ou un petit script copie des données d'un endroit à un autre. Ça marche jusqu'à ce que le produit grandisse, que les équipes se séparent et que le nombre de connexions se multiplie. Bientôt, chaque changement nécessite une coordination entre plusieurs services, parce qu'un petit champ ou une mise à jour de statut peut se répercuter dans une chaîne de dépendances.
La rapidité est généralement la première chose qui casse. Ajouter une nouvelle fonctionnalité signifie mettre à jour plusieurs intégrations, redéployer plusieurs services et espérer que personne ne dépendait de l'ancien comportement.
Ensuite, le débogage devient pénible. Quand quelque chose semble erroné dans l'interface, il est difficile de répondre à des questions basiques : que s'est‑il passé, dans quel ordre, et quel système a écrit la valeur que vous voyez ?
La pièce manquante est souvent une piste d'audit. Si des données sont poussées directement d'une base à une autre (ou transformées en chemin), vous perdez l'historique. Vous pouvez voir l'état final, mais pas la séquence d'événements qui y a conduit. Les revues d'incidents et le support client en souffrent parce que vous ne pouvez pas rejouer le passé pour confirmer ce qui a changé et pourquoi.
C'est aussi là que l'argument « qui possède la vérité » commence. Une équipe dit « le service facturation est la source de vérité ». Une autre dit « le service commande l'est ». En réalité, chaque système a une vue partielle, et les intégrations point à point transforment ce désaccord en friction quotidienne.
Un exemple simple : une commande est créée, puis payée, puis remboursée. Si trois systèmes se mettent à jour directement, chacun peut finir avec une histoire différente quand des retries, des timeouts ou des corrections manuelles se produisent.
Cela mène à la question centrale de conception derrière le streaming d'événements Kafka : avez‑vous juste besoin de déplacer du travail d'un endroit à un autre (une file), ou avez‑vous besoin d'un enregistrement partagé et durable de ce qui s'est passé, que beaucoup de systèmes peuvent lire, rembobiner et croire (un journal) ? La réponse change la manière dont vous construisez, déboguez et faites évoluer votre système.
Jay Kreps, Kafka et l'idée du journal
Jay Kreps a contribué à façonner Kafka et, plus important, la façon dont beaucoup d'équipes pensent le déplacement des données. Le changement d'état d'esprit utile est simple : cessez de traiter les messages comme des livraisons ponctuelles et commencez à considérer l'activité système comme un enregistrement.
L'idée centrale est simple. Modélisez les changements importants comme un flux de faits immuables :
- Une commande a été créée.
- Un paiement a été autorisé.
- Un utilisateur a changé son email.
Chaque événement est un fait qu'on ne devrait pas modifier après coup. Si quelque chose change plus tard, vous ajoutez un nouvel événement qui énonce la nouvelle vérité. Au fil du temps, ces faits forment un journal : un historique append‑only de votre système.
C'est là que le streaming d'événements Kafka diffère de beaucoup d'architectures de messagerie basiques. Beaucoup de files sont construites autour du principe « envoie, traite, supprime ». C'est correct quand le travail est purement un transfert. La vision du journal dit : « conservez l'historique pour que de nombreux consommateurs puissent l'utiliser, maintenant et plus tard. »
La capacité de rejouer l'historique est la superpuissance pratique.
Si un rapport est faux, vous pouvez relancer le même historique d'événements à travers un job analytique corrigé et voir où les chiffres ont changé. Si un bug a causé l'envoi de mauvais emails, vous pouvez rejouer les événements dans un environnement de test et reproduire la chronologie exacte. Si une nouvelle fonctionnalité a besoin de données passées, vous pouvez créer un nouveau consommateur qui commence depuis le début et se met à jour à son propre rythme.
Voici un exemple concret. Imaginez que vous ajoutez des contrôles anti‑fraude après avoir déjà traité des mois de paiements. Avec un journal d'événements de paiements et de comptes, vous pouvez rejouer le passé pour entraîner ou calibrer des règles sur des séquences réelles, calculer des scores de risque pour d'anciennes transactions et backfiller des événements fraud_review_requested sans réécrire votre base de données.
Remarquez ce que cela vous force à faire. Une approche basée sur le journal vous pousse à nommer clairement les événements, à les garder stables et à accepter que plusieurs équipes et services dépendront d'eux. Elle amène aussi des questions utiles : Quelle est la source de vérité ? Que signifie cet événement sur le long terme ? Que fait‑on quand on s'est trompé ?
La valeur n'est pas dans la personnalité. C'est de réaliser qu'un journal partagé peut devenir la mémoire de votre système, et la mémoire est ce qui permet aux systèmes de grandir sans se casser chaque fois que vous ajoutez un nouveau consommateur.
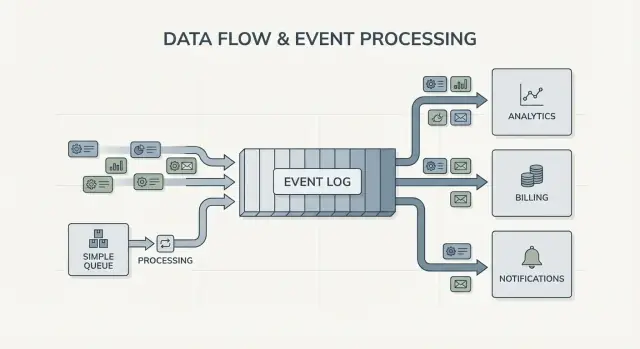
File vs journal : le modèle mental le plus simple
Une file de messages est comme une file de tâches pour votre logiciel. Les producteurs mettent du travail dans la file, les consommateurs prennent l'élément suivant, effectuent le travail, et l'élément disparaît. Le système vise principalement à faire traiter chaque tâche une fois, le plus rapidement possible.
Un journal est différent. C'est un enregistrement ordonné de faits qui se sont produits, conservé dans une séquence durable. Les consommateurs ne « prennent » pas les événements. Ils lisent le journal à leur rythme, et ils peuvent le relire plus tard. Dans le streaming d'événements Kafka, ce journal est l'idée centrale.
Une façon pratique de retenir la différence :
- File = travail à faire. Une fois confirmé par un worker, il disparaît.
- Journal = historique de ce qui s'est passé. Les événements restent disponibles pendant une période de rétention.
La rétention change la conception. Avec une file, si vous avez plus tard besoin d'une nouvelle fonctionnalité qui dépend d'anciens messages (analytique, fraude, rejouements après un bug), vous devez souvent ajouter une base séparée ou commencer à capturer des copies ailleurs. Avec un journal, le replay est normal : vous pouvez reconstruire une vue dérivée en lisant depuis le début (ou depuis un checkpoint connu).
Le fan‑out est une autre grande différence. Imaginez qu'un service de checkout émet OrderPlaced. Avec une file, vous choisissez généralement un seul groupe de workers pour le traiter, ou vous dupliquez le travail sur plusieurs files. Avec un journal, la facturation, les emails, l'inventaire, l'indexation de recherche et l'analytique peuvent tous lire le même flux d'événements indépendamment. Chaque équipe peut évoluer à son rythme, et ajouter un nouveau consommateur plus tard ne nécessite pas de changer le producteur.
Ainsi, le modèle mental est simple : utilisez une file quand vous déplacez des tâches ; utilisez un journal quand vous enregistrez des événements que plusieurs parties de l'entreprise voudront lire, maintenant ou plus tard.
Ce que le streaming d'événements change dans la conception des systèmes
Le streaming d'événements renverse la question par défaut. Au lieu de demander « À qui dois‑je envoyer ce message ? », vous commencez par enregistrer « Que vient‑il de se passer ? » Cela paraît petit, mais ça change votre façon de modéliser le système.
Vous publiez des faits comme OrderPlaced ou PaymentFailed, et d'autres parties décident si, quand et comment elles réagissent.
Avec le streaming d'événements Kafka, les producteurs n'ont plus besoin d'une liste d'intégrations directes. Un service de checkout peut publier un seul événement, et il n'a pas besoin de savoir si l'analytique, l'email, les contrôles anti‑fraude ou un futur service de recommandations l'utiliseront. De nouveaux consommateurs peuvent apparaître plus tard, les anciens peuvent être mis en pause, et le producteur se comporte toujours de la même manière.
Cela change aussi la manière de récupérer d'erreurs. Dans un monde basé uniquement sur les messages, dès qu'un consommateur manque quelque chose ou a un bug, les données sont souvent « perdues » sauf si vous avez construit des sauvegardes personnalisées. Avec un journal, vous pouvez corriger le code et rejouer l'historique pour reconstruire l'état correct. Souvent, c'est mieux que des modifications manuelles de bases ou des scripts ponctuels que personne ne fait confiance.
En pratique, le changement se voit de plusieurs manières : vous traitez les événements comme un enregistrement durable, vous ajoutez des fonctionnalités en vous abonnant plutôt qu'en modifiant les producteurs, vous pouvez reconstruire des read models (index de recherche, tableaux de bord) depuis zéro, et vous obtenez des chronologies plus claires de ce qui s'est passé entre les services.
L'observabilité s'améliore parce que le journal d'événements devient une référence partagée. Quand quelque chose tourne mal, vous pouvez suivre une séquence métier : commande créée, inventaire réservé, paiement retenté, expédition planifiée. Cette chronologie est souvent plus facile à comprendre que des logs applicatifs dispersés car elle se concentre sur des faits métier.
Un exemple concret : si un bug de réduction a mal tarifié les commandes pendant deux heures, vous pouvez publier un correctif et rejouer les événements concernés pour recalculer les totaux, mettre à jour les factures et rafraîchir l'analytique. Vous corrigez les résultats en retraitant les données, pas en devinant quelles tables patcher à la main.
Quand une simple file suffit
Une simple file est l'outil adapté quand vous déplacez du travail, pas quand vous construisez un enregistrement à long terme. L'objectif est de confier une tâche à un worker, l'exécuter, puis l'oublier. Si personne n'a besoin de rejouer le passé, d'inspecter d'anciens événements ou d'ajouter de nouveaux consommateurs plus tard, une file garde les choses plus simples.
Les files excellent pour les jobs en arrière‑plan : envoi d'emails de bienvenue, redimensionnement d'images après upload, génération d'un rapport nocturne, ou appel à une API externe lente. Dans ces cas, le message n'est qu'un ticket de travail. Une fois que le worker a fini, le ticket a rempli sa fonction.
Une file convient aussi au modèle habituel de propriété : un groupe de consommateurs est responsable du travail, et les autres services ne sont pas censés lire le même message indépendamment.
Une file suffit généralement quand la plupart des éléments suivants sont vrais :
- Les données ont une valeur éphémère.
- Une seule équipe ou un seul service possède le job de bout en bout.
- Les replays et une longue rétention ne sont pas requis.
- Le débogage ne dépend pas de la réexécution de l'historique.
Exemple : un produit permet aux utilisateurs d'uploader des photos. L'app écrit une tâche « redimensionner l'image » dans une file. Le worker A la récupère, crée des vignettes, les stocke et marque la tâche comme terminée. Si la tâche s'exécute deux fois, le résultat est identique (idempotent), donc une livraison au moins une fois est acceptable. Aucun autre service n'a besoin de lire cette tâche plus tard.
Si vos besoins commencent à dériver vers des faits partagés (plusieurs consommateurs), du replay, de l'audit, ou « que croyait le système la semaine dernière ? », c'est là que Kafka event streaming et une approche basée sur le journal commencent à payer.
Quand une approche basée sur le journal est rentable
Un système basé sur un journal devient rentable quand les événements cessent d'être des messages ponctuels et deviennent un historique partagé. Plutôt que « envoyer et oublier », vous conservez un enregistrement ordonné que plusieurs équipes peuvent lire, maintenant ou plus tard, à leur rythme.
Le signal le plus clair est la multiplicité des consommateurs. Un seul événement comme OrderPlaced peut alimenter la facturation, l'email, les contrôles anti‑fraude, l'indexation de recherche et l'analytique. Avec un journal, chaque consommateur lit le même flux indépendamment. Vous n'avez pas besoin de construire un pipeline de fan‑out personnalisé ou de coordonner qui reçoit le message en premier.
Un autre avantage est de pouvoir répondre à « Que savions‑nous à ce moment ? ». Si un client conteste un prélèvement, ou qu'une recommandation paraissait erronée, un historique append‑only permet de rejouer les faits tels qu'ils sont arrivés. Cette piste d'audit est difficile à greffer sur une simple file plus tard.
Vous obtenez aussi un moyen pratique d'ajouter de nouvelles fonctionnalités sans réécrire les anciennes. Si vous ajoutez plus tard une nouvelle page « statut de livraison », un nouveau service peut s'abonner et backfiller à partir de l'historique existant pour construire son état, plutôt que de demander à tous les systèmes en amont des exports.
Une approche basée sur le journal vaut souvent le coup quand vous reconnaissez un ou plusieurs besoins suivants :
- Les mêmes événements doivent alimenter plusieurs systèmes (analytique, recherche, facturation, outils support).
- Vous avez besoin de replay, d'audit ou d'enquêtes basées sur des faits passés.
- De nouveaux services doivent backfiller depuis l'historique sans jobs ponctuels.
- L'ordonnancement importe par entité (par commande, par utilisateur).
- Les formats d'événements vont évoluer et vous avez besoin d'une manière contrôlée de gérer la versioning.
Un schéma courant : un produit commence avec des commandes et des emails. Plus tard, la finance veut des rapports de revenus, le produit veut des funnels et l'opérations veut un dashboard live. Si chaque nouveau besoin vous force à copier des données via un nouveau pipeline, les coûts apparaissent vite. Un journal d'événements partagé permet aux équipes de s'appuyer sur la même source, même si le système grandit et que les formes d'événements changent.
Choisir entre une file simple et une approche basée sur le journal est plus facile si vous le traitez comme une décision produit. Commencez par ce qui doit être vrai dans un an, pas seulement ce qui marche cette semaine.
Une méthode pratique en 5 étapes
-
Cartographiez éditeurs et lecteurs. Notez qui crée des événements et qui les lit aujourd'hui, puis ajoutez les consommateurs probables (analytique, indexation, anti‑fraude, notifications). Si vous prévoyez que plusieurs équipes liront les mêmes événements indépendamment, un journal devient pertinent.
-
Demandez‑vous si vous aurez besoin de relire l'historique. Soyez précis sur le pourquoi : replay après un bug, backfills, ou consommateurs qui lisent à des vitesses différentes. Les files sont parfaites pour un transfert unique. Les journaux sont meilleurs quand vous voulez un enregistrement rejouable.
-
Définissez ce que « terminé » signifie. Pour certains workflows, terminé veut dire « le job a été exécuté » (envoyer un email, redimensionner une image). Pour d'autres, terminé veut dire « l'événement est un fait durable » (une commande a été passée, un paiement a été autorisé). Les faits durables vous poussent vers un journal.
-
Choisissez les attentes de livraison et décidez comment gérer les doublons. La livraison au moins une fois est courante, ce qui implique que des doublons peuvent survenir. Si un doublon peut causer des dégâts (double facturation), prévoyez l'idempotence : stocker un ID d'événement traité, utiliser des contraintes uniques, ou rendre les mises à jour sûres à répéter.
-
Commencez par une tranche fine. Choisissez un flux d'événements facile à raisonner et développez‑le. Si vous optez pour Kafka event streaming, gardez le premier topic focalisé, nommez clairement les événements et évitez de mélanger des types d'événements sans rapport.
Un exemple concret : si OrderPlaced alimentera plus tard expédition, facturation, support et analytique, un journal permet à chaque équipe de lire à son rythme et de rejouer après des erreurs. Si vous n'avez besoin que d'un worker en arrière‑plan pour envoyer un reçu, une simple file suffit généralement.
Exemple : événements de commande dans un produit en croissance
Imaginez une petite boutique en ligne. Au début, il suffit de prendre les commandes, débiter une carte et créer une demande d'expédition. La version la plus simple est un job en arrière‑plan qui s'exécute après le checkout : « traiter la commande ». Il appelle l'API de paiement, met à jour la ligne de commande en base, puis appelle l'expédition.
Ce style file marche bien quand il y a un seul workflow clair, un seul consommateur et que les retries et dead letters couvrent la plupart des erreurs.
Ça commence à poser problème à mesure que la boutique grandit. Le support veut des mises à jour automatiques « où est ma commande ? ». La finance veut des nombres de revenus quotidiens. L'équipe produit veut envoyer des emails clients. Un contrôle anti‑fraude devrait se produire avant l'expédition. Avec un unique job « process order », vous finissez par éditer sans cesse le même worker, ajouter des branches et risquer de nouveaux bugs dans le flux principal.
Avec une approche basée sur le journal, le checkout produit de petits faits sous forme d'événements, et chaque équipe peut s'en appuyer. Les événements typiques pourraient ressembler à :
OrderPlacedPaymentConfirmedItemShippedRefundIssued
Le changement clé est la propriété. Le service checkout possède OrderPlaced. Le service paiements possède PaymentConfirmed. L'expédition possède ItemShipped. Plus tard, de nouveaux consommateurs peuvent apparaître sans modifier le producteur : un service anti‑fraude lit OrderPlaced et PaymentConfirmed pour scorer le risque, un service email envoie des reçus, l'analytique construit des funnels et le support garde une timeline de ce qui s'est passé.
C'est là que Kafka event streaming apporte sa valeur : le journal conserve l'historique, donc de nouveaux consommateurs peuvent rembobiner et se rattraper depuis le début (ou depuis un point connu) au lieu de demander à chaque équipe en amont d'ajouter un webhook.
Le journal ne remplace pas votre base de données. Vous avez toujours besoin d'une base pour l'état courant : le dernier statut d'une commande, le profil client, les comptes d'inventaire et les règles transactionnelles (comme « ne pas expédier si le paiement n'est pas confirmé »). Considérez le journal comme l'enregistrement des changements et la base comme l'endroit où l'on interroge « qu'est‑ce qui est vrai maintenant ».
Erreurs et pièges fréquents
Le streaming d'événements peut rendre les systèmes plus propres, mais quelques erreurs communes peuvent effacer les bénéfices rapidement. La plupart viennent du fait de traiter le journal comme une télécommande plutôt que comme un enregistrement.
Un piège fréquent est d'écrire des événements comme des commandes, par exemple « SendWelcomeEmail » ou « ChargeCardNow ». Cela couple fortement les consommateurs à votre intention. Les événements fonctionnent mieux comme des faits : UserSignedUp ou PaymentAuthorized. Les faits vieillissent bien. De nouvelles équipes peuvent les réutiliser plus tard sans deviner ce que vous vouliez dire.
Les doublons et les retries sont une autre grande source de douleur. Dans des systèmes réels, les producteurs réessayent et les consommateurs retraitent. Si vous ne prévoyez rien, vous obtenez des doubles prélèvements, des doubles emails et des tickets support en colère. La solution n'est pas exotique, mais elle doit être délibérée : handlers idempotents, IDs d'événements stables et règles métier qui détectent « déjà appliqué ».
Pièges communs :
- Utiliser des événements style commande qui disent aux services quoi faire au lieu d'enregistrer ce qui est arrivé.
- Construire des consommateurs qui cassent s'ils voient le même événement deux fois.
- Fragmenter les flux trop tôt, de sorte qu'un seul flux métier soit dispersé sur trop de topics.
- Ignorer les règles de schéma jusqu'à ce qu'un petit changement casse des consommateurs plus anciens.
- Considérer le streaming comme un substitut à une bonne conception de base de données.
Le schéma et la gestion des versions méritent une attention spéciale. Même si vous commencez avec du JSON, vous avez toujours besoin d'un contrat clair : champs requis, champs optionnels et comment les changements sont déployés. Un petit changement comme renommer un champ peut silencieusement casser l'analytique, la facturation ou des apps mobiles qui mettent plus de temps à se mettre à jour.
Un autre piège est la création excessive de flux. Les équipes créent parfois un nouveau stream pour chaque fonctionnalité. Un mois plus tard, personne ne peut répondre à « Quel est l'état courant d'une commande ? » parce que l'histoire est éparpillée.
Le streaming d'événements n'élimine pas le besoin de modèles de données solides. Vous avez toujours besoin d'une base qui représente la vérité courante. Le journal est l'historique, pas toute votre application.
Checklist rapide et prochaines étapes
Si vous hésitez entre une file et Kafka event streaming, commencez par quelques vérifications rapides. Elles vous diront si vous avez besoin d'un simple transfert entre workers ou d'un journal réutilisable pendant des années.
Vérifications rapides
- Avez‑vous besoin de replay (pour backfills, corrections de bugs ou nouvelles fonctionnalités), et sur quelle période ?
- Plus d'un consommateur aura‑t‑il besoin des mêmes événements maintenant ou bientôt (analytique, recherche, emails, fraude, facturation) ?
- Avez‑vous besoin d'une rétention pour que les équipes puissent relire l'historique sans demander au producteur de renvoyer ?
- Quelle est l'importance de l'ordre, et à quel niveau : par entité (par commande, par utilisateur) ou vraiment global ?
- Les consommateurs peuvent‑ils être idempotents (sécurisés pour retraiter le même événement sans double facturation, double email ou double mise à jour) ?
Si vous avez répondu « non » à replay, « un seul consommateur » et « messages à courte durée de vie », une file basique suffit généralement. Si vous avez répondu « oui » à replay, multiples consommateurs ou plus longue rétention, une approche basée sur le journal a tendance à être plus rentable car elle transforme un flux de faits en une source partagée sur laquelle les autres systèmes peuvent s'appuyer.
Prochaines étapes
Transformez les réponses en un petit plan testable.
- Listez 5–10 événements principaux en langage clair (exemple :
OrderPlaced, PaymentAuthorized, OrderShipped) et notez qui publie et qui consomme chacun.
- Décidez de la clé d'ordonnancement (souvent par entité, comme
orderId) et documentez ce que signifie « ordre correct ».
- Définissez une règle d'idempotence par consommateur (par exemple : stocker le dernier ID d'événement traité par commande).
- Choisissez une cible de rétention qui correspond à vos besoins (jours pour un workflow type file, semaines/mois quand le replay importe).
- Exécutez une tranche de bout en bout dans un sandbox avant d'engager tout le système.
Si vous prototypez rapidement, vous pouvez esquisser le flux d'événements en mode planning de Koder.ai et itérer le design avant de verrouiller les noms d'événements et règles de retry. Puisque Koder.ai supporte l'export de code, les snapshots et le rollback, c'est aussi un moyen pratique de tester une seule tranche producteur-consommateur et d'ajuster la forme des événements sans transformer des expérimentations initiales en dette de production.