Objectifs, utilisateurs et définition des niveaux de compte
Avant de construire des tableaux de bord ou d’instrumenter des événements, clarifiez l’objectif de l’application, ses bénéficiaires et la définition des niveaux de compte. La plupart des projets de « suivi d’adoption » échouent parce qu’ils démarrent par les données et aboutissent à des désaccords.
Règle pratique : si deux équipes ne peuvent pas définir « adoption » dans la même phrase, elles ne feront pas confiance au tableau de bord plus tard.
Qui utilisera cette application ?
Nommez les publics principaux et ce que chacun doit pouvoir faire après avoir lu les données :
- Produit : comprendre si les nouvelles fonctionnalités sont découvertes, utilisées de façon récurrente et conservées.
- Customer Success (CS) : repérer les lacunes d’onboarding, les risques d’adoption et les comptes nécessitant de l’accompagnement.
- Ventes / Account Management : identifier des signaux d’expansion (usage élevé, largeur de fonctionnalités) et le risque de renouvellement.
- Direction : suivre la santé globale de l’adoption et si les initiatives stratégiques font bouger les lignes.
Un bon test : chaque public doit pouvoir répondre au « et alors ? » en moins d’une minute.
Définir « adoption » pour votre produit
L’adoption n’est pas une seule métrique. Rédigez une définition concertée—souvent sous forme de séquence :
- Activation : premier succès significatif (ex. invités, premier projet créé, configuration terminée).
- Utilisation de fonctionnalités : usages répétés des fonctionnalités clés corrélées à la valeur (pas des clics de façade).
- Rétention : l’usage se poursuit semaine après semaine / mois après mois.
Ancrez tout dans la valeur client : quels actions signalent qu’ils obtiennent des résultats, pas seulement qu’ils explorent.
Niveaux de compte et règles d’affectation
Listez vos niveaux et rendez l’affectation déterministe. Niveaux courants : PME / Mid-Market / Entreprise, Free / Trial / Paid, ou Bronze / Silver / Gold.
Documentez les règles en clair (et plus tard, en code) :
- Quelle source de vérité décide du niveau (système de facturation, CRM, table interne) ?
- Le niveau dépend-il de l’ARR, du nombre de sièges, du plan, du secteur, ou du niveau de support ?
- Que faire en cas de conflit de données (ex. CRM dit Entreprise, facturation dit Pro) ?
- Quand un changement de niveau prend-il effet, et avez-vous besoin d’un historique des niveaux pour le reporting ?
Décisions que vous voulez supporter
Rédigez les décisions que l’application doit permettre. Par exemple :
- Onboarding : qui n’a pas activé sous 7 jours ?
- Risque : quels comptes à forte valeur montrent une baisse d’usage ?
- Expansion : quels comptes atteignent des limites ou adoptent plusieurs fonctionnalités avancées ?
3–5 questions clés pour le tableau de bord
Utilisez-les comme critères d’acceptation :
- Quels niveaux s’améliorent ou déclinent en adoption ce mois-ci ?
- Pour chaque niveau, quel pourcentage de comptes est activé et quel pourcentage est retenu ?
- Quelles fonctionnalités expliquent le plus la différence entre comptes sains et comptes à risque par niveau ?
- Quels sont les comptes top dans chaque niveau qui nécessitent une intervention, et pourquoi (gap d’activation, faible largeur, baisse de fréquence) ?
- Après une release ou un changement d’onboarding, l’adoption a-t-elle augmenté pour le niveau ciblé ?
Métriques d’adoption pertinentes par niveau
Les niveaux de compte se comportent différemment ; une métrique unique pénalisera soit les petits clients, soit masquera le risque chez les plus gros. Commencez par définir le succès par niveau, puis choisissez des métriques qui reflètent cette réalité.
1) Choisissez un outcome north-star par niveau
Choisissez un résultat principal représentant la valeur réelle :
- Starter/PME : « comptes activés » (atteignent la première valeur rapidement)
- Mid-market : « comptes actifs hebdomadairement avec usage des features clés »
- Entreprise : « comptes avec adoption multi-équipes » ou « comptes atteignant les jalons de déploiement »
Votre north-star doit être mesurable, segmentée par niveau et difficile à biaiser.
2) Définissez les étapes du funnel avec des qualifications claires
Formulez l’entonnoir d’adoption en étapes avec règles explicites—ainsi une réponse de tableau de bord ne dépendra pas d’interprétations.
Exemples d’étapes :
- Invited → Signed up : au moins un utilisateur créé
- Activated : checklist de setup complétée et première action clé réalisée
- Integrated : au moins une intégration clé connectée
- Adopting : actions clés répétées sur plusieurs jours/semaines
Les différences par niveau comptent : l’« Activated » enterprise peut exiger une action admin et au moins une action d’utilisateur final.
3) Choisissez indicateurs leaders vs retardés
Utilisez des indicateurs leaders pour repérer l’élan :
- Setup complété
- Intégration clé connectée
- Premier workflow publié/partagé
Utilisez des indicateurs retardés pour confirmer une adoption durable :
- Rétention par niveau (ex. taux actif sur 4 semaines)
- Profondeur d’usage (actions par utilisateur actif, projets créés, sièges actifs)
- Proxies de renouvellement (signaux de santé contractuelle, événements d’expansion)
4) Fixez des objectifs réalistes par niveau
Les objectifs doivent refléter le temps attendu pour obtenir de la valeur et la complexité organisationnelle. Exemple : SME cible activation sous 7 jours ; Enterprise cible intégration sous 30–60 jours.
Documentez les objectifs pour que les alertes et scorecards restent cohérentes entre équipes.
Modèle de données pour Accounts, Users et historique de niveaux
Un modèle clair évite la « maths mystère » plus tard. Vous devez pouvoir répondre à : qui a utilisé quoi, dans quel compte, sous quel niveau, à quel moment — sans bricoler la logique dans chaque tableau de bord.
Entités cœur à modéliser
Commencez par un petit ensemble d’entités reflétant la façon dont les clients achètent et utilisent :
- Account : l’entité cliente (entreprise/organisation). Stockez identifiants (
account_id), nom, statut, et champs de cycle de vie (created_at, churned_at).
- User : personne. Incluez
user_id, domaine d’email (utile pour le matching), created_at, last_seen_at.
- Workspace / Project (optionnel) : si le produit a des espaces multiples sous un Account, modélisez-les explicitement avec
workspace_id et une clé étrangère vers account_id.
- Subscription : objet de facturation. Stockez plan, période, sièges, MRR et timestamps.
- Tier : table normalisée (ex. Free, Team, Business, Enterprise) pour garder les noms cohérents.
Décidez du grain de tracking
Soyez explicite sur le « grain » analytique :
- Événements au niveau user répondent : Quelles personas ont adopté la feature X ?
- Rollups au niveau account répondent : Ce client est-il sain ?
Un choix pratique : tracker les événements au niveau utilisateur (avec account_id attaché), puis agréger au niveau compte. Évitez les événements account-only sauf si aucun user n’existe (ex. imports système).
Modéliser le temps : événements vs snapshots
Les événements disent ce qui s’est passé ; les snapshots disent ce qui était vrai.
- Conservez une table d’événements comme source de vérité.
- Ajoutez des snapshots quotidiens d’account (une ligne par compte/jour) pour des tableaux de bord rapides : utilisateurs actifs, comptes d’utilisation de features, score d’adoption, et le
tier du jour.
Capturer l’historique des niveaux (les niveaux changent)
Ne pas écraser le « niveau courant » au risque de perdre le contexte. Créez une table account_tier_history :
account_id, tier_idvalid_from, valid_to (nullable pour le courant)source (billing, sales override)
Cela permet de calculer l’adoption quand le compte était Team, même s’il a ensuite monté en gamme.
Documenter les définitions de métriques
Rédigez les définitions une fois et traitez-les comme des exigences produit : qu’est-ce qu’un « utilisateur actif », comment on attribue les événements aux comptes, comment gérer les changements de niveau en milieu de mois. Cela évite deux tableaux de bord qui retournent deux vérités différentes.
Plan de tracking d’événements et principes d’instrumentation
Vos analytics d’adoption ne valent que par la qualité des événements collectés. Commencez par cartographier un petit set d’actions « chemin critique » indiquant un vrai progrès par niveau, puis instrumentez-les de manière cohérente sur web, mobile et backend.
Événements critiques à tracker
Concentrez-vous sur des événements qui représentent des étapes significatives — pas chaque clic. Set de départ pratique :
signup_completed (compte créé)user_invited et invite_accepted (croissance équipe)first_value_received (votre moment « aha » ; définissez-le explicitement)key_feature_used (action de valeur répétable ; peut être multiple par fonctionnalité)integration_connected (si les intégrations apportent de la rétention)
Propriétés d’événement (rendre consultables)
Chaque événement doit porter assez de contexte pour découper par niveau et par rôle :
account_id (requis)user_id (requis quand une personne est impliquée)tier (capturer au moment de l’événement)plan (SKU de facturation si pertinent)role (ex. owner/admin/member)- Optionnel mais utile :
workspace_id, feature_name, source (web/mobile/api), timestamp
Conventions de nommage à faire respecter
Utilisez un schéma prévisible pour éviter un dictionnaire d’événements :
- Événements : verbes en
snake_case, passé (ex. report_exported, dashboard_shared)
- Propriétés : noms consistants (
account_id, pas acctId)
- Événements feature : soit événements dédiés (
invoice_sent) soit un événement unique avec feature_name ; choisissez une approche et conservez-la.
Identité : cross-device et multi-workspace
Supportez activité anonyme et authentifiée :
- Assignez un
anonymous_id à la première visite, puis reliez à user_id au login.
- Dans les produits multi-workspace, incluez toujours
workspace_id et mappez-le à account_id côté serveur pour éviter les bugs clients.
Événements côté serveur pour la fiabilité
Instrumentez les actions système côté backend pour que les métriques clés ne dépendent pas des navigateurs ou bloqueurs de pub. Exemples : subscription_started, payment_failed, seat_limit_reached, audit_log_exported.
Ces événements server-side sont aussi des bons déclencheurs pour alertes et workflows.
Pipeline d’ingestion, stockage et agrégations
C’est ici que le tracking devient un système : les événements arrivent, sont nettoyés, stockés en sécurité, puis transformés en métriques exploitables.
Choisissez une voie d’ingestion adaptée
La plupart des équipes utilisent un mix :
- SDK (client/server) : meilleur pour un tracking produit structuré et cohérent.
- API HTTP : adaptée aux services backend, partenaires ou imports.
- Logs applicatifs : utile si vous avez déjà des logs riches ; nécessitera parsing et schémas stricts.
- Message queue (Kafka/SQS/PubSub) : idéal pour gros volumes ou besoin de résilience et replay.
Quelque soit le choix, traitez l’ingestion comme un contrat : si un événement est inexploitable, il doit être mis en quarantaine — pas accepté silencieusement.
Normalisez tôt : timestamps, IDs et propriétés
À l’ingestion, standardisez les quelques champs qui rendent le reporting fiable :
- Convertissez tous les timestamps en UTC et conservez le timestamp source original quand pertinent.
- Mappez les identifiants à des formes canoniques :
account_id, user_id, et (si besoin) workspace_id.
- Validez les propriétés requises (ex.
event_name, tier, plan, feature_key) et n’ajoutez des valeurs par défaut que quand c’est explicite.
Stockez les événements bruts séparément des agrégats
Décidez où résident les événements bruts selon coût et patterns de requêtes :
- Entrepôt (Snowflake/BigQuery/Redshift) : le plus simple pour analytics et requêtes ad-hoc.
- Object storage (S3/GCS) + moteur de requête : moins cher à grande échelle, configuration un peu plus lourde.
- Base opérationnelle : seulement pour faibles volumes ; surveillez les performances.
Rollups : jobs planifiés qui servent les décisions
Construisez des jobs d’agrégation quotidiens/horaires produisant des tables comme :
- Accounts actifs journaliers par niveau
- Comptes d’adoption de fonctionnalités par niveau
- Inputs du score d’adoption au niveau account
Rendez les rollups déterministes pour pouvoir les relancer lors de changements de définition de niveau ou de backfills.
Règles de rétention
Fixez des rétentions claires pour :
- Événements bruts : plus longs (ex. 12–36 mois) pour audit et reprocessing
- Agrégats : plus longs ou indéfinis, car compacts et utiles pour tableaux de bord et alertes
Scoring d’adoption et agrégations par niveau
Lancez un outil interne
Déployez et hébergez votre application interne d'adoption, avec des domaines personnalisés lorsque vous êtes prêt.
Un score d’adoption donne un numéro simple à suivre, mais il fonctionne seulement s’il reste simple et explicable. Visez 0–100 qui reflète des comportements signifiants (pas de la vanité) et qui peut être décomposé en pourquoi il a bougé.
Un score 0–100 simple et explicable
Commencez par une checklist pondérée, plafonnée à 100 points. Gardez les poids stables le temps d’un trimestre pour comparer les tendances.
Exemple de pondération (à ajuster) :
- Activation (40 pts) : checklist d’onboarding complétée, premier projet créé, invitation d’un collègue.
- Usage core (40 pts) : utilisation de la feature principale sur 3+ jours distincts dans les 14 derniers jours.
- Expansion (20 pts) : adoption d’une fonctionnalité secondaire (intégrations, exports, approvals).
Chaque comportement doit correspondre à une règle d’événement claire (ex. « used core feature » = core_action sur 3 jours distincts). Quand le score change, conservez les facteurs contributeurs pour afficher : « +15 parce que vous avez invité 2 utilisateurs » ou « -10 parce que l’usage core est tombé sous 3 jours ».
Agrégations par compte et par niveau
Calculez le score par compte (snapshot journalier ou hebdomadaire), puis agrégerez par niveau en utilisant des distributions, pas seulement des moyennes :
- Médiane du score par niveau
- 25e/75e percentiles (et optionnellement 10e/90e)
- % de comptes au-dessus de seuils (ex. 60+ = « adoption saine »)
Tendances sans comparaisons trompeuses
Suivez variation hebdo et variation 30 jours par niveau, mais évitez de mélanger les tailles de niveau :
- Affichez les counts (ex. 38 comptes se sont améliorés) en plus des pourcentages (ex. 12% se sont améliorés).
Cela rend les petits niveaux lisibles sans laisser les grands niveaux dominer le récit.
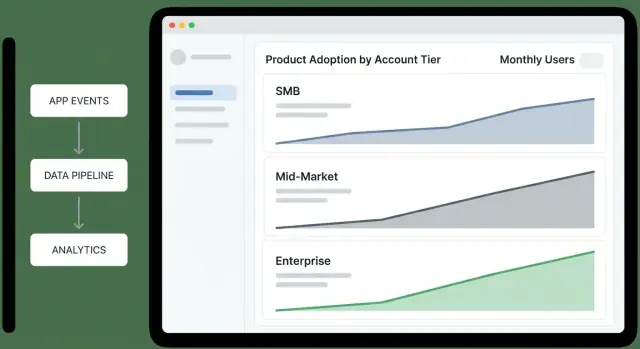
Tableaux de bord : Vue d’ensemble par niveau et résumé exécutif
Un tableau de bord d’ensemble par niveau doit permettre à un dirigeant de répondre en moins d’une minute : « Quels niveaux s’améliorent, lesquels déclinent, et pourquoi ? » Traitez-le comme un écran de décision, pas comme un scrap-book de rapports.
Ce qu’il faut montrer (et la question répondue)
Entonnoir par niveau (Awareness → Activation → Habit) : « Où les comptes se coincent-ils par niveau ? » Gardez les étapes cohérentes avec votre produit (ex. « Invited users » → « Completed first key action » → « Weekly active »).
Taux d’activation par niveau : « Les comptes nouveaux ou réactivés atteignent-ils la première valeur ? » Montrez le taux avec le dénominateur (comptes éligibles) pour éviter le bruit des petits échantillons.
Rétention par niveau (ex. 7/28/90 jours) : « Les comptes continuent-ils d’utiliser après le premier succès ? » Affichez une ligne simple par niveau ; évitez le sur-segmentation sur l’overview.
Profondeur d’usage (feature breadth) : « Adoptent-ils plusieurs zones produit ou restent-ils superficiels ? » Un stacked bar par niveau fonctionne bien : % utilisant 1 zone, 2–3 zones, 4+ zones.
Comparaisons qui poussent à l’action
Ajoutez deux comparaisons partout :
- Cette semaine vs la semaine dernière (ou derniers 7 vs 7 précédents) pour un feedback rapide.
- Niveau vs niveau pour détecter les écarts (ex. PME surpassant Entreprise sur l’activation).
Utilisez des deltas cohérents (points de pourcentage absolus) pour permettre un scan rapide par les dirigeants.
Filtres qui ne cassent pas l’histoire
Limitez les filtres, qu’ils soient globaux et persistants :
- Plage temporelle (présets + personnalisée)
- Aire produit (pour le contexte de profondeur d’usage)
- Région (pour révéler effets de rollout ou marché)
- Propriétaire de compte (pour responsabilité GTM)
Si un filtre changerait la définition d’une métrique, ne l’offrez pas ici — renvoyez vers des vues de drill-down.
« Principaux moteurs » par niveau
Incluez un petit panneau pour chaque niveau : « Qu’est-ce qui est le plus associé à une meilleure adoption cette période ? » Exemples :
- Top 3 features/événements corrélés à un score d’adoption élevé
- Étape du funnel la plus problématique
- Comptes avec la plus grande variation hebdo (positive et négative)
Restez explicable : préférez « Les comptes qui configurent X dans les 3 premiers jours retiennent 18pp de plus » plutôt que des sorties de modèles opaques.
Mise en page utile
Placez en haut des cartes KPI par niveau (activation, rétention, profondeur), une vue tendance au milieu, et drivers + actions suivantes en bas. Chaque widget doit répondre à une seule question — sinon il n’a pas sa place dans le résumé exécutif.
Vues de drill-down : du niveau au compte individuel
Le dashboard par niveau sert à prioriser, mais le travail réel commence quand on peut cliquer pour comprendre pourquoi un niveau a bougé et qui nécessite de l’attention. Concevez les drills comme un chemin guidé : niveau → segment → compte → utilisateur.
Niveau → Segment : restreindre la question
Commencez par une table d’aperçu du niveau, puis laissez les utilisateurs la découper en segments utiles sans construire des rapports ad-hoc. Filtres communs :
- Statut d’onboarding (not started / in progress / complete)
- Industrie, plan, région, stade du cycle de vie
- « À risque » vs « sain » basé sur le score d’adoption
Chaque page de segment doit répondre : « Quels comptes poussent le score d’adoption de ce niveau vers le haut ou le bas ? » Incluez une liste classée des comptes avec variation de score et features contributrices.
Vue profil compte : timeline, score, jalons
La fiche compte doit ressembler à un dossier :
- Timeline d’usage (30/90 jours) : événements clés, jours actifs, points de contact majeurs
- Score d’adoption avec une décomposition simple (activation, largeur, profondeur)
- Jalons : première action clé, feature X adoptée, invitations, seuil Y atteint
Rendez-la lisible : montrez les deltas (« +12 cette semaine ») et annotez les pics avec l’événement/feature déclencheur.
Drill-down utilisateur et vues cohortes
Depuis la page compte, listez les utilisateurs par activité récente et rôle. Cliquer un utilisateur montre son usage de fonctionnalités et son dernier accès.
Ajoutez des vues de cohortes pour expliquer des motifs : mois d’inscription, programme d’onboarding, et niveau au moment de l’inscription. Cela aide le CS à comparer des éléments comparables plutôt que de mélanger nouveaux comptes et comptes matures.
Adoption features par niveau + export pour workflows
Incluez une vue « Qui utilise quoi » par niveau : taux d’adoption, fréquence, tendances, avec une liste cliquable des comptes utilisant (ou n’utilisant pas) chaque feature.
Pour CS et Ventes, ajoutez options d’export/partage : export CSV, vues sauvegardées et liens internes partageables (ex. /accounts/{id}) qui s’ouvrent avec les filtres appliqués.
Alertes et workflows actionnables par niveau
Validez rapidement les définitions d'adoption
Itérez rapidement au fur et à mesure que les parties prenantes affinent les définitions d'activation et de rétention.
Les dashboards aident à comprendre, mais les équipes agissent quand elles sont notifiées au bon moment. Les alertes doivent être liées au niveau pour éviter le bruit à faible valeur — ou pire, rater un problème critique sur vos plus gros comptes.
Définir des signaux de risque par niveau
Commencez par un petit ensemble de signaux « quelque chose va mal » :
- Baisse d’usage : baisse significative des utilisateurs hebdomadaires, événements clés ou sessions vs baseline du compte.
- Onboarding bloqué : aucun progrès après activation dans la fenêtre attendue (ex. pas de projet créé, pas d’intégration connectée).
- Faible activation : le compte n’atteint jamais le seuil minimum « aha » après signup ou achat.
Rendez ces signaux sensibles au niveau. Ex. : Entreprise alertera sur une baisse de 15% week-over-week d’un workflow core, tandis que PME demandera 40% pour éviter le bruit dû à l’usage sporadique.
Définir des signaux d’expansion par niveau
Les alertes d’expansion doivent mettre en avant les comptes qui montent en valeur :
- Emergence de power users : plusieurs utilisateurs répétant des workflows de haute valeur.
- Largeur de features : adoption sur plusieurs zones clés (pas juste une).
- Forte croissance : augmentation des sièges, invitations envoyées, ou hausse régulière des utilisateurs actifs.
Les seuils diffèrent : un power user suffit pour une PME ; l’expansion Enterprise requiert une adoption multi-équipes.
Notifications qui poussent à l’action
Routez les alertes vers les outils d’exécution :
- Slack/email pour signaux temps réel (ex. onboarding bloqué pour un compte top-tier).
- Digest hebdo pour insights moins urgents (ex. comptes en hausse de feature breadth).
Le payload doit être actionnable : nom du compte, niveau, ce qui a changé, fenêtre de comparaison, et un lien de drill-down (ex. /accounts/{account_id}).
Playbooks : que faire quand une alerte se déclenche
Chaque alerte a un propriétaire et un playbook court : qui répond, les 2–3 vérifications initiales (fraîcheur des données, récentes releases, changements admin), et l’action recommandée (contact, guide in-app, etc.).
Documentez les playbooks près des définitions métriques pour garder la cohérence des réponses et la confiance dans les alertes.
Qualité des données, monitoring et gouvernance des métriques
Si les métriques d’adoption dirigent des décisions (outreach CS, pricing, roadmap), les données doivent avoir des garde-fous. Un petit ensemble de vérifications et d’habitudes de gouvernance évite les « chutes mystères » et aligne les parties prenantes.
Validation en périphérie
Validez les événements dès que possible (SDK client, gateway API ou worker d’ingestion). Rejetez ou mettez en quarantaine les événements non fiables.
Implémentez des contrôles tels que :
account_id ou user_id manquants (ou valeurs inexistantes dans la table accounts)- Valeurs de
tier invalides (hors enum approuvé)
- Timestamps impossibles (futurs/anciens) et propriétés requises manquantes pour les événements clés
Conservez une table de quarantaine pour inspecter les événements invalides sans polluer l’analytics.
Monitoring du volume et de la fraîcheur
Le suivi d’adoption est sensible au temps ; les événements tardifs déforment les actifs hebdomadaires et les rollups de niveau. Monitorisez :
- Volume d’événements par type et par niveau (pics/chutes brusques)
- Fraîcheur et distribution des délais (ex. p95 ingestion lag)
- Santé du pipeline (jobs échoués, backfills en cours, dépendances cassées)
Routez ces monitors vers un canal on-call, pas vers tout le monde.
Duplicatas, retries et idempotence
Les retries sont normaux (réseaux mobiles, redelivery webhook, replays batch). Rendre l’ingestion idempotente via un idempotency_key ou un event_id stable et dédupliquez sur une fenêtre temporelle.
Les agrégations doivent être ré-exécutables sans double comptage.
Gouvernance des métriques : une signification, un propriétaire
Créez un glossaire définissant chaque métrique (inputs, filtres, fenêtre temporelle, règles d’attribution de niveau) et traitez-le comme source de vérité. Liez les tableaux de bord et docs à ce glossaire (ex. /docs/metrics).
Ajoutez des logs d’audit pour les changements de définitions métriques et des règles de scoring — qui a changé quoi, quand et pourquoi — pour expliquer rapidement les variations.
Confidentialité, sécurité et contrôle d’accès
Transformez les métriques en workflows
Configurez des alertes de risque et d'expansion sensibles au palier, actionnables par vos équipes CS et Sales.
Les analytics d’adoption sont utiles si on y fait confiance. Conception la plus sûre : répondre aux questions d’adoption en collectant le moins de données sensibles possible, et faire du « qui voit quoi » une fonctionnalité de premier ordre.
Minimiser les données personnelles (par conception)
Commencez avec les identifiants suffisants pour l’insight : account_id, user_id (ou id pseudonyme), timestamp, feature, et un petit set de propriétés comportementales (plan, tier, plateforme). Évitez noms, adresses email, champs texte libre ou tout ce qui pourrait contenir des secrets.
Si l’analyse user-level est nécessaire, stockez les identifiants utilisateurs séparément des PII et joignez-les uniquement quand nécessaire. Traitez IP et identifiants device comme sensibles ; si inutiles pour le scoring, ne les conservez pas.
Rôles, permissions et choix par défaut sûrs
Définissez des rôles clairs :
- Exec/Leadership : rollups par compte et par niveau uniquement
- CS/Sales : détails au niveau compte ; vues user-level limitées si requis
- Produit/Analytics : exploration user-level plus profonde avec trails d’audit
- Admin : configuration, rétention et controls de suppression
Par défaut, privilégiez les vues agrégées. Faites du drill-down user-level une permission explicite et masquez les champs sensibles sauf si le rôle l’exige.
Rétention, suppression et consentement
Supportez les demandes de suppression en pouvant retirer l’historique d’événements d’un utilisateur (ou l’anonymiser) et supprimer les données account en fin de contrat.
Implémentez des règles de rétention (ex. garder événements bruts N jours, agrégats plus longtemps) et documentez-les dans votre politique. Enregistrez consentement et responsabilités de traitement quand applicable.
Choix d’architecture et feuille de route pragmatique
Le moyen le plus rapide d’obtenir de la valeur est de choisir une architecture qui correspond à l’endroit où vos données vivent déjà. Vous pouvez évoluer ensuite — l’important est de fournir des insights tiers fiables rapidement.
Deux approches de construction courantes
Warehouse-first analytics : les événements arrivent dans un entrepôt (BigQuery/Snowflake/Postgres), puis vous calculez les métriques d’adoption et les servez à une web app légère. Idéal si vous travaillez déjà en SQL, avez des analystes, ou voulez une source unique de vérité.
App-first analytics : votre appli écrit des événements dans sa propre base et calcule les métriques côté application. Plus rapide pour un petit produit, mais difficile à faire évoluer quand le volume augmente et que le reprocessing historique devient nécessaire.
Par défaut pratique pour la plupart des équipes SaaS : warehouse-first avec une petite base opérationnelle pour la conf (tiers, définitions métriques, règles d’alerte).
Composants cœur (restez simple)
- UI Web : vue d’ensemble par niveau + pages de drill-down.
- API : sert des métriques pré-agrégées, listes de comptes et filtres.
- Warehouse / DB analytics : événements bruts + tables modélisées pour métriques journalières d’adoption.
- Job runner : transformations planifiées (quotidien/horaires), backfills et scoring.
Décisions buy vs build qui vous font gagner des semaines
- Charts : commencez par une librairie de charts éprouvée (ou embedez un outil BI) plutôt que de recréer des primitives.
- Auth : utilisez un provider établi (SSO, roles) pour éviter les pièges de sécurité.
- Collecte d’événements : utilisez un SDK ou une gateway de confiance ; ne construisez un collecteur custom que si besoin strict.
Roadmap MVP (2–4 semaines)
Expédiez une première version avec :
- 3–5 métriques (ex. accounts actifs, usage feature clé, score d’adoption, rétention hebdo, time-to-first-value).
- Une page d’overview par niveau : score d’adoption par niveau + tendance.
- Une fiche compte : niveau courant, dernière activité, features principales utilisées, et un simple “pourquoi le score vaut ce qu’il vaut.”
Itérer sans casser la confiance
Ajoutez des boucles de feedback tôt : laissez Sales/CS signaler « ça a l’air faux » depuis le dashboard. Versionnez les définitions métriques pour pouvoir changer les formules sans réécrire l’historique en silence.
Déployez progressivement (une équipe → toute l’organisation) et gardez un changelog des mises à jour métriques dans l’app (ex. /docs/metrics) pour que les parties prenantes sachent toujours ce qu’elles regardent.
Où Koder.ai intervient (prototypage rapide sans lock-in)
Si vous voulez passer du « spec » à une app interne fonctionnelle rapidement, une approche vibe-coding peut aider — surtout pour un MVP où vous validez des définitions, pas l’infra parfaite.
Avec Koder.ai, les équipes peuvent prototyper une app d’adoption via une interface de chat tout en générant du code éditable. C’est adapté ici car le périmètre croise React UI, une API, un modèle Postgres et des rollups planifiés, et évolue rapidement à mesure que les parties prenantes convergent.
Flux courant :
- Utilisez le Planning Mode pour cartographier le modèle de tiers, le schéma d’événements et les questions de dashboard en plan d’implémentation.
- Générez un UI React + backend Go soutenu par PostgreSQL pour les tables de configuration (tiers, définitions métriques, règles d’alerte).
- Exportez le code source quand vous êtes prêt à confier au dev, et utilisez snapshots/rollback pour itérer en sécurité quand les définitions changent.
Parce que Koder.ai supporte déploiement/hosting, domaines custom et export de code, c’est une manière pratique d’obtenir un MVP interne crédible tout en gardant ouvertes vos décisions d’architecture long terme (warehouse-first vs app-first).