Clarifiez le problème de dépendance que vous résolvez
Avant de concevoir des écrans ou de choisir une stack technique, précisez ce que « dépendance » signifie dans votre organisation. Si le terme désigne tout et n'importe quoi, votre appli finira par ne rien suivre correctement.
Définir « dépendance » en termes simples
Rédigez une définition d'une phrase que tout le monde pourra répéter, puis listez ce qui est éligible. Catégories communes :
- Élément de travail : une autre équipe doit implémenter une fonctionnalité, corriger un bug ou livrer un ticket.
- Livrable : un document, jeu de données, design ou actif nécessaire pour avancer.
- Décision : un accord ou un sign-off qui débloque l'implémentation.
- Environnement/accès : identifiants, infrastructure, environnements de test ou autorisations.
Définissez aussi ce qui n'est pas une dépendance (par ex. améliorations agréables à avoir, risques généraux ou tâches internes qui ne bloquent pas une autre équipe). Cela garde le système propre.
Identifiez pour qui l'appli est destinée
Le suivi des dépendances échoue s'il est conçu uniquement pour des PMs ou uniquement pour des ingénieurs. Nommez vos utilisateurs principaux et ce dont chacun a besoin en 30 secondes :
- Chefs d'équipe / managers ingénierie : ce qui bloque la livraison et qui est responsable de la prochaine action.
- PMs / program managers : dates de transfert, engagements et voies d'escalade.
- Ingénieurs : la demande précise, le contexte et les critères d'acceptation.
- Direction / ops : livraisons prévisibles, moins de surprises et reporting au niveau des tendances.
Choisissez des métriques de succès mesurables
Sélectionnez un petit ensemble de résultats, par exemple :
- Moins de bloqueurs découverts en dernière minute pendant un sprint ou une release
- Temps plus court entre création de dépendance → attribution d'un propriétaire
- Plus de transferts à l'heure par rapport aux dates convenues
- Propriété claire (moins d'items avec propriétaire « TBD »)
Listez les points douloureux que vous éliminerez
Recensez les problèmes que votre appli doit résoudre dès le premier jour : feuilles de calcul obsolètes, propriétaires flous, dates manquées, risques cachés et mises à jour dispersées dans les threads de chat.
Cartographiez dépendances, états et définitions
Une fois alignés sur ce que vous suivez et pour qui, verrouillez le vocabulaire et le cycle de vie. Des définitions partagées transforment une liste de tickets en un système qui réduit les bloqueurs.
Commencez par les types de dépendances que vous supporterez
Choisissez un petit ensemble de types couvrant la plupart des cas réels, et facilitez la reconnaissance de chaque type :
- Blocked-by : l'équipe A ne peut pas livrer tant que l'équipe B n'a pas fait quelque chose.
- Provides-to : l'équipe B fournit un artefact/service que l'équipe A consommera.
- Waiting-on : similaire à blocked-by, mais souvent limité dans le temps (approbation, accès, décision).
- Ressource partagée : des équipes se disputent les mêmes personnes, environnements, budget ou fournisseur.
- Contrainte de séquence : le travail doit se dérouler dans un ordre spécifique même s'il n'y a pas de blocage explicite.
L'objectif est la cohérence : deux personnes doivent classifier de la même manière la même dépendance.
Définissez les attributs minimaux (et faites-les respecter)
Un enregistrement de dépendance doit rester compact mais complet pour être géré :
- Équipe propriétaire (responsable de la livraison)
- Équipe demandeuse (qui a besoin du résultat)
- Date d'échéance (quand la demandeuse en a besoin)
- Statut (voir cycle ci-dessous)
- Niveau de risque (par ex. Faible/Moyen/Élevé)
- Notes (contexte, hypothèses)
- Liens vers le travail source (ticket Jira, doc, PR, incident, etc.)
Si vous permettez de créer une dépendance sans équipe propriétaire ni date, vous construisez un « tracker de préoccupations » et non un outil de coordination.
Mettez-vous d'accord sur les états du cycle de vie et les déclencheurs
Utilisez un modèle d'état simple qui reflète la manière dont les équipes travaillent :
Proposed → Accepted → In progress → Ready → Delivered/Closed, plus Rejected.
Rédigez des règles de changement d'état. Par exemple : Accepted exige une équipe propriétaire et une date cible initiale, ou Ready exige une preuve.
Rendre le « fait » non ambigu
Pour la clôture, exigez tout ce qui suit :
- Critères d'acceptation : ce qui compte comme terminé
- Sign-off : qui confirme (nom/équipe)
- Preuve/lien : PR, note de release, capture d'écran, doc ou ticket
- Horodatage : quand cela a été accepté/clôturé
Ces définitions deviennent la colonne vertébrale de vos filtres, rappels et revues d'état plus tard.
Concevez un modèle de données simple et scalable
Un tracker de dépendances réussit si les gens peuvent décrire la réalité sans se battre avec l'outil. Commencez par un petit nombre d'objets qui correspondent au langage des équipes, puis ajoutez de la structure là où elle prévient la confusion.
Objets principaux (gardez-les basiques)
Utilisez quelques enregistrements primaires :
- Team : le groupe qui possède le travail ou fournit une dépendance.
- Project/Initiative : conteneur pour un travail avec un objectif clair.
- Work item : unité d'exécution (feature, tâche, epic, lien de ticket).
- Dependency : promesse entre une équipe demandeuse et une équipe fournisseuse.
- Milestone/Release : point de contrôle lié à une date que les dépendances peuvent bloquer.
Évitez de créer des types séparés pour chaque cas limite. Mieux vaut ajouter quelques champs (par ex. type: data/API/approval) que de fragmenter le modèle trop tôt.
Relations qui reflètent la coordination réelle
Les dépendances impliquent souvent plusieurs groupes et plusieurs tâches. Modélisez cela explicitement :
- Teams ↔ Dependencies : many-to-many (une dépendance peut avoir plusieurs équipes fournisseuses ; une équipe peut être impliquée dans de nombreuses dépendances).
- Dependencies ↔ Work items : many-to-many (une dépendance peut bloquer plusieurs work items ; un work item peut dépendre de plusieurs dépendances).
Cela évite la pensée fragile du type une dépendance = un ticket et rend possible des rapports consolidés.
Traçabilité : rendez les modifications fiables
Chaque objet principal doit inclure des champs d'audit :
- Créé par / créé le, modifié par / modifié le
- Historique des changements (qui a changé quoi et quand)
- Commentaires (décisions et contexte)
- Pièces jointes/liens (specs, docs, tickets Jira, notes de réunion)
Support léger pour les dépendances externes
Toutes les dépendances n'ont pas une équipe dans votre organigramme. Ajoutez un enregistrement Owner/Contact (nom, organisation, email/Slack, notes) et autorisez les dépendances à le référencer. Ainsi les blocages fournisseurs ou d'autres départements restent visibles sans les forcer dans la structure d'équipes interne.
Définissez rôles, propriété et permissions
Si les rôles ne sont pas explicites, le suivi devient un fil de commentaires : chacun suppose que quelqu'un d'autre est responsable et les dates sont modifiées sans contexte. Un modèle de rôles clair rend l'appli fiable et rend l'escalade prévisible.
Rôles principaux (restez simples)
Commencez avec quatre rôles quotidiens et un rôle administratif :
- Requester : crée une demande de dépendance et fournit le pourquoi, la date requise et les critères d'acceptation.
- Owner : la personne unique redevable de la livraison (ou du rejet formel) de la dépendance.
- Approver : confirme l'engagement lorsqu'une dépendance affecte la capacité, le périmètre ou la planification de release.
- Viewer : peut suivre l'avancement et commenter, mais ne peut pas modifier les engagements.
- Admin : gère la configuration (équipes, permissions, modèles), pas les décisions quotidiennes.
Règles de propriété qui empêchent l'ambiguïté
Rendez l'Owner requis et unique : une dépendance, un propriétaire redevable. Vous pouvez toujours supporter des collaborateurs (contributeurs d'autres équipes), mais les collaborateurs ne doivent jamais remplacer la responsabilité.
Ajoutez une voie d'escalade quand un Owner ne répond pas : d'abord relancer l'Owner, puis son manager (ou chef d'équipe), puis un responsable programme/release selon la structure de votre org.
Permissions : protégez les engagements, pas la visibilité
Séparez l'édition des détails du changement d'engagement. Un comportement par défaut pratique :
- Requester peut créer, ajouter du contexte et proposer des dates ; ne peut pas marquer Committed sans approbation.
- Owner peut mettre à jour le statut, ajouter des notes de livraison et proposer de nouvelles dates ; peut clore seulement lorsque les critères d'acceptation sont atteints.
- Approver peut définir les états d'engagement (Committed/Rejected) et approuver les changements de date.
- Viewer peut voir et commenter ; pas d'édition.
Si vous supportez des initiatives privées, définissez qui peut les voir (par ex. équipes impliquées + Admin). Évitez les dépendances secrètes qui surprennent les équipes de livraison.
Orientation RACI dans l'UI
Ne cachez pas la responsabilité dans un document de politique. Affichez-la sur chaque dépendance :
- Accountable (A) : Owner
- Responsible (R) : Collaborateurs (optionnel)
- Consulted (C) : Approver et équipes impactées
- Informed (I) : Viewers/watchers
Étiqueter Accountable vs Consulted directement dans le formulaire réduit les erreurs d'acheminement et accélère les revues d'état.
Planifiez l'UX : vues que les équipes utiliseront vraiment
Un tracker de dépendances fonctionne seulement si les gens peuvent trouver leurs éléments en quelques secondes et les mettre à jour sans réfléchir. Concevez autour des questions les plus fréquentes : Qu'est-ce que je bloque ?, Qui me bloque ?, Quelque chose est-il en train de dérailler ?
Écrans principaux à livrer tôt
Commencez par un petit ensemble de vues qui correspondent à la façon dont les équipes parlent du travail :
- Liste des dépendances : table filtrable pour toutes les dépendances ouvertes avec actions rapides.
- Détail de dépendance : un emplacement pour comprendre la demande, le statut, les propriétaires, les dates et l'historique.
- Vue équipe : tout ce que l'équipe doit fournir et ce dont elle dépend, avec des priorités claires.
- Vue initiative : dépendances groupées sous un projet/release pour repérer les risques.
- Timeline : vue date légère pour échéances et transferts attendus (ce n'est pas un outil complet de Gantt).
Rendre la création et les mises à jour sans friction
La plupart des outils échouent sur la mise à jour quotidienne. Optimisez pour la vitesse :
- Modèles et champs par défaut (types courants, règles SLA/date préremplies).
- Édition inline sur les pages liste et détail (pas de formulaires modaux pour les changements simples).
- Contrôles orientés clavier pour les power users (ordre du tab, sauvegarde rapide, raccourcis prévisibles).
Rendre le statut impossible à mal lire
Utilisez couleur + libellé textuel (jamais la couleur seule) et gardez le vocabulaire cohérent. Ajoutez un indicateur Last updated sur chaque dépendance et un avertissement de stale quand il n'a pas été touché pendant une période définie (par ex. 7–14 jours). Cela incite aux mises à jour sans forcer des réunions.
Réduire les réunions en capturant le contexte
Chaque dépendance doit contenir un fil unique regroupant :
- Commentaires et mises à jour d'avancement
- Décisions (avec date et qui a convenu)
- Liens vers le travail support (tickets, docs)
Quand la page détail raconte l'histoire complète, les revues d'état sont plus rapides et beaucoup de synchronisations rapides disparaissent parce que la réponse est déjà écrite.
Construisez des workflows pour demandes, mises à jour et clôture
Transformez vos exigences en application
Décrivez votre outil de suivi des dépendances dans le chat et générez une application de démarrage React, Go et Postgres.
Un tracker de dépendances réussit ou échoue sur les actions quotidiennes qu'il supporte. Si les équipes ne peuvent pas rapidement demander, répondre par un engagement clair et boucler la boucle avec une preuve, votre appli devient un panneau d'information au lieu d'un outil d'exécution.
Workflow central : demande → décision → engagement
Commencez par un flux Create request qui capture ce que l'équipe fournisseuse doit livrer, pourquoi c'est important et quand c'est nécessaire. Restez structuré : date demandée, critères d'acceptation et lien vers l'epic/spec.
Ensuite, imposez un état de réponse explicite :
- Accept (engagé sur une date)
- Decline (avec raison requise)
- Propose new date (contre-proposition avec explication)
Cela évite le mode d'échec le plus courant : des dépendances silencieuses en mode peut-être qui semblent valides jusqu'à la catastrophe.
Expectatives type SLA pour éviter la staleness
Définissez des attentes légères dans le workflow lui-même. Exemples :
- Réponse sous X jours ouvrés après création d'une demande
- Cadence de mise à jour (par ex. hebdomadaire ou à chaque changement de statut)
- Marquer comme stale s'il n'y a pas de mise à jour pendant Y jours et si la date d'échéance est dans Z jours
Le but n'est pas de contrôler, mais de garder les engagements à jour pour que la planification reste honnête.
Mises à jour avec contrôle de changement (sans bureaucratie)
Autorisez les équipes à marquer une dépendance comme At risk avec une courte note et l'étape suivante. Lorsqu'une date ou un statut change, exigez une raison (un menu + texte libre). Cette règle unique crée une piste d'audit qui rend les rétrospectives et escalades factuelles, pas émotionnelles.
Clôture qui prouve que le travail est réellement fait
Clore signifie que la dépendance est satisfaite. Exigez une preuve : lien vers PR fusionnée, ticket released, document ou note d'approbation. Si la clôture est floue, les équipes mettront les éléments en vert trop tôt pour réduire le bruit.
Actions en masse pour la planification hebdomadaire
Supportez les mises à jour groupées pendant les revues : sélectionner plusieurs dépendances et définir le même statut, ajouter une note commune (par ex. replanning après reset Q1) ou demander des mises à jour. Cela rend l'appli assez rapide pour être utilisée pendant les réunions, pas seulement après.
Ajoutez des alertes et notifications sans créer de bruit
Les notifications doivent protéger la livraison, pas distraire. La meilleure façon de générer du bruit est d'alerter tout le monde sur tout. Concentrez-vous sur les déclencheurs de décision et les signaux de risque.
Commencez avec un petit ensemble de triggers à haute valeur
Focalisez la première version sur les événements qui modifient le plan ou nécessitent une réponse explicite :
- Nouvelle demande créée (l'équipe propriétaire est notifiée)
- Acceptation nécessaire (une dépendance est assignée et attend confirmation)
- Date modifiée (une des parties ajuste une date promise/besoin)
- Statut à risque / bloqué (flag de risque levé)
- Mises à jour stale (pas de mise à jour en X jours pour une dépendance active)
Chaque trigger doit pointer vers une action claire : accepter/decliner, proposer une nouvelle date, ajouter du contexte ou escalader.
Diffusez via les canaux que les équipes consultent déjà
Par défaut, privilégiez les notifications in-app (pour lier l'alerte à l'enregistrement) plus email pour ce qui ne peut pas attendre.
Proposez des intégrations chat optionnelles — Slack ou Microsoft Teams — mais traitez-les comme un mécanisme de livraison, pas le système de référence. Les messages de chat doivent deep-linker vers l'item (par ex. /dependencies/123) et inclure le minimum de contexte : qui doit agir, ce qui a changé et pour quand.
Réduisez le bruit avec préférences et digests
Fournissez des contrôles au niveau équipe et utilisateur :
- Alertes immédiates pour acceptation, bloqué, en retard
- Mode digest (quotidien/hebdo) pour les mises à jour peu urgentes comme de petits décalages de date ou des commentaires
- Regroupement et déduplication (un résumé par dépendance par fenêtre temporelle)
C'est aussi là que les watchers comptent : notifier le requester, l'équipe propriétaire et les parties prenantes explicitement ajoutées — évitez les diffusions larges.
Escaladez seulement quand des motifs indiquent un risque
L'escalade doit être automatisée mais conservative : alerter lorsqu'une dépendance est en retard, lorsque la date est repoussée à plusieurs reprises ou lorsqu'un statut bloqué n'a pas évolué pendant une période définie.
Orientez les escalades vers le bon niveau (chef d'équipe, program manager) et incluez l'historique pour que le destinataire puisse agir rapidement sans courir après le contexte.
Choisissez des intégrations qui suppriment les doubles saisies
Maîtrisez votre base de code
Exportez le code source complet lorsque vous souhaitez assurer le développement en interne.
Les intégrations doivent éliminer la ressaisie, pas ajouter une surcharge de configuration. L'approche la plus sûre est de démarrer par les systèmes que les équipes utilisent déjà, garder la première version en lecture seule ou unidirectionnelle, puis étendre après adoption.
Commencez par un tracker d'incidents unique
Choisissez un tracker principal (Jira, Linear ou Azure DevOps) et supportez un flux link-first simple :
- Un enregistrement de dépendance stocke une URL de tracker et une clé (par ex.
PROJ-123).
- Votre appli récupère le statut (Open/In Progress/Done), l'assignee et la date d'échéance sur un calendrier.
- Les mises à jour restent d'abord dans le tracker ; votre appli les reflète.
Cela évite deux sources de vérité tout en apportant de la visibilité. Plus tard, ajoutez une sync bidirectionnelle optionnelle pour un petit ensemble de champs (statut, date) avec des règles claires de conflit.
Ajoutez des jalons calendrier (lecture seule d'abord)
Les jalons sont souvent maintenus dans Google Calendar ou Outlook. Commencez par lire les événements dans votre timeline de dépendances (par ex. Release Cutoff, UAT Window) sans écrire en retour.
La synchro calendrier en lecture seule permet aux équipes de planifier où elles le font déjà, tandis que votre appli montre les impacts et dates à venir en un seul endroit.
Facilitez l'accès avec SSO
Le Single Sign-On réduit la friction d'onboarding et la dérive des permissions. Choisissez selon la réalité du client :
- Google Workspace (fréquent pour les petites structures)
- Microsoft Entra ID (fréquent en entreprise)
- Okta (fréquent pour environnements mixtes)
Si vous êtes en phase précoce, livrez un fournisseur d'abord et documentez comment demander les autres.
Proposez une petite API et des webhooks bien documentés
Même les équipes non techniques gagnent à ce qu'ops internes automatisent des transferts. Fournissez quelques endpoints et hooks avec exemples copy-paste.
curl -X POST /api/dependencies \\
-H "Authorization: Bearer $TOKEN" \\
-d '{"title":"API contract from Payments","trackerUrl":"https://jira/.../PAY-77"}'
Les webhooks comme dependency.created et dependency.status_changed permettent d'intégrer des outils internes sans attendre votre roadmap. Pour plus, pointez vers /docs/integrations.
Créez des tableaux de bord et rapports pour les revues d'état
Les dashboards sont là où une appli de dépendances prouve sa valeur : ils transforment j'ai l'impression qu'on est bloqué en une image partagée et claire de ce qui nécessite attention avant la prochaine revue.
Dashboards selon les audiences
Un dashboard universel échoue souvent. Créez plutôt quelques vues qui collent aux réunions réelles :
- Vue chef d'équipe : dépendances que votre équipe doit fournir et celles qui la bloquent, focalisé sur dates, statut et prochaine action.
- Vue programme : groupes de dépendances par initiative/release et mise en évidence des goulets d'étranglement cross-team.
- Synthèse exécutive : roll-up compact : total de dépendances ouvertes, combien sont à risque, ce qui vient de devenir en retard et les 3 principaux bloqueurs. Restez lisible.
Rapports qui entraînent des décisions (pas du busywork)
Créez un petit ensemble de rapports utilisés en revue :
- Dépendances en retard : triées par jours de retard et sévérité/risque.
- Top équipes bloquantes : qui a le plus de dépendances en attente (et tendances dans le temps).
- Jalons à venir à risque : jalons dans 2–4 semaines avec dépendances ouvertes ou marquées à risque.
Chaque rapport doit répondre : Qui doit faire quoi ensuite ? Incluez propriétaire, date prévue et dernière mise à jour.
Filtres qui comptent
Rendez le filtrage rapide et évident, car la plupart des réunions commencent par Montre-moi juste...
Supportez des filtres tels que équipe, initiative, statut, plage de date d'échéance, niveau de risque et tags (ex. security review, data contract, release train). Sauvegardez des ensembles de filtres fréquents comme vues nommées (ex. Release A — 14 prochains jours).
Export et partage
Tout le monde ne vivra pas dans votre appli. Fournissez :
- Export CSV pour analyses légères et partages ponctuels.
- Liens partageables vers un dashboard ou rapport filtré (ex. /reports/overdue?team=payments). Gardez les liens internes et stables.
Si vous proposez un palier payant, conservez des contrôles de partage administrateur et renvoyez vers /pricing pour les détails.
Choisissez une stack technique pratique et une architecture
Vous n'avez pas besoin d'une plateforme complexe pour livrer un tracker de dépendances. Un MVP peut être un système en trois parties : UI web pour les humains, API pour les règles et intégrations, base de données comme source de vérité. Optimisez pour Facile à modifier plutôt que Parfait. Vous apprendrez plus de l'usage réel que de mois d'architecture en amont.
Stack MVP simple
Un démarrage pragmatique ressemble à :
- Web UI : React, Vue ou pages rendues côté serveur (Rails/Django) pour des écrans CRUD rapides.
- API : Node (Express/Nest), Python (FastAPI/Django) ou Rails — choisissez selon les compétences de l'équipe.
- Base : Postgres, généralement le meilleur choix pour des données relationnelles comme dépendances, propriétaires, statuts et horodatages.
Si vous prévoyez des intégrations Slack/Jira rapidement, gardez-les en modules séparés/jobs qui parlent à l'API plutôt que de laisser les outils externes écrire directement dans la base.
Si vous voulez un produit utilisable rapidement sans tout construire from scratch, un workflow vibe-coding peut aider : par exemple, Koder.ai peut générer une UI React et un backend Go + PostgreSQL depuis un spec conversationnel, puis vous permettre d'itérer avec snapshots et rollback. Vous gardez la propriété des décisions d'architecture tout en raccourcissant le chemin des exigences au pilote exploitable.
Principes techniques utiles
- Authentification : SSO (SAML/OIDC) si possible ; sinon login email sécurisé.
- Logs : logs structurés de requêtes et suivi d'erreurs pour déboguer pourquoi une modification a eu lieu.
- Rate limits : protégez l'API des intégrations bruyantes et des boucles accidentelles.
- Backups : sauvegardes quotidiennes automatiques et tests de restauration.
La plupart des écrans sont des vues listes : dépendances ouvertes, bloqueurs par équipe, changements de la semaine. Concevez pour cela :
- Ajoutez index pour les filtres fréquents (statut, équipe propriétaire, date d'échéance, updated_at).
- Utilisez pagination partout.
- Proposez recherche (le full-text Postgres suffit souvent).
Confidentialité et confiance
Les données de dépendance peuvent contenir des informations sensibles. Appliquez le principe du moindre privilège (visibilité par équipe quand pertinent) et conservez des journaux d'audit pour les modifications — qui a changé quoi et quand. Cette piste d'audit réduit les débats en revue et rend l'outil fiable.
Plan de déploiement : pilote, migration et adoption
Allez au-delà du web
Ajoutez une application mobile Flutter pour des mises à jour et validations rapides en déplacement.
Déployer un tracker de dépendances, c'est moins une question de fonctionnalités que d'habitude. Traitez le déploiement comme un lancement produit : commencez petit, prouvez la valeur, puis montez avec un rythme opérationnel clair.
1) Démarrez par un pilote ciblé
Choisissez 2–4 équipes travaillant sur une initiative partagée (par ex. un release train ou un programme client). Définissez des critères de succès mesurables en quelques semaines :
- Moins de bloqueurs inconnus lors des revues d'état
- Temps plus court entre levée de dépendance et attribution d'un propriétaire
- Meilleure livraison à l'heure pour l'initiative pilote
Gardez la config du pilote minimale : seulement les champs et vues nécessaires pour répondre à Que bloque, par qui et pour quand ?
2) Migrez depuis les spreadsheets sans importer le chaos
La plupart des équipes utilisent déjà des feuilles. Importez-les, mais prudemment :
- Mappez les colonnes vers les champs (description, équipe demandeuse, équipe propriétaire, date d'échéance, statut, raison du blocage)
- Nettoyez les doublons et normalisez les noms d'équipe avant import
- Décidez quoi faire des lignes historiques (souvent mieux archivées que migrées)
Faites une courte passe QA données avec les pilotes pour confirmer définitions et corriger les entrées ambiguës.
3) Favorisez l'adoption avec un playbook léger
L'adoption tient quand l'appli soutient une cadence existante. Fournissez :
- Une formation de 15–20 minutes avec 2–3 dépendances réalistes
- Une routine hebdomadaire de mise à jour (ex. chaque mardi avant le sync cross-team)
- Une règle claire : les dépendances sans propriétaire ou date sont incomplètes
Si vous itérez rapidement (par ex. en utilisant Koder.ai), utilisez des environnements/snapshots pour tester les changements de champs requis, d'états et de dashboards avec les équipes pilotes avant de déployer.
4) Créez une boucle de feedback et itérez
Suivez où les utilisateurs butent : champs confus, statuts manquants ou vues qui n'aident pas les revues. Revuez les retours chaque semaine pendant le pilote et ajustez champs et vues par défaut avant d'inviter plus d'équipes. Un simple lien Report an issue vers /support aide à garder la boucle serrée.
Évitez les pièges et planifiez l'itération suivante
Une fois en production, les plus grands risques sont comportementaux, pas techniques. Les équipes n'abandonnent pas un outil parce qu'il « ne marche pas », mais parce que le mettre à jour semble optionnel, confus ou bruyant.
Trop de champs. Si créer une dépendance ressemble à remplir un formulaire, les gens repousseront ou sauteront l'enregistrement. Commencez avec un ensemble minimal de champs requis : titre, équipe demandeuse, équipe propriétaire, prochaine action, date d'échéance et statut.
Propriété floue. Si ce n'est pas évident qui doit agir ensuite, les dépendances deviennent des fils de statut. Affichez Owner et next action owner explicitement et de façon proéminente.
Pas d'habitude de mise à jour. Même une UI excellente échoue si les items deviennent stale. Ajoutez des nudges : mettez en évidence les items stale, envoyez des rappels uniquement quand une date approche ou que la dernière mise à jour est ancienne, et facilitez les mises à jour (changement de statut en un clic + courte note).
Saturation de notifications. Si chaque commentaire ping tout le monde, les utilisateurs mettront le système en sourdine. Par défaut, privilégiez les watchers qui s'abonnent et envoyez des résumés pour les urgences faibles.
Gardes-fous pour maintenir la santé du système
Considérez next action comme un champ de première classe : chaque dépendance ouverte doit toujours avoir une étape suivante claire et une personne redevable. Si elle manque, l'item ne doit pas apparaître comme « complet » dans les vues clés.
Définissez aussi ce que signifie done (résolu, plus nécessaire, ou migré vers un autre tracker) et exigez une courte raison de clôture pour éviter les items zombies.
Gouvernance : évitez la dérive de la taxonomie
Décidez qui gère les tags, la liste des équipes et les catégories. Typiquement un program manager ou rôle ops avec un contrôle de changement léger. Définissez une politique de retraite simple : archivez automatiquement les initiatives fermées après X jours et révisez les tags inutilisés trimestriellement.
Idées de roadmap pour l'itération suivante
Quand l'adoption stagne, envisagez des améliorations apportant de la valeur sans friction :
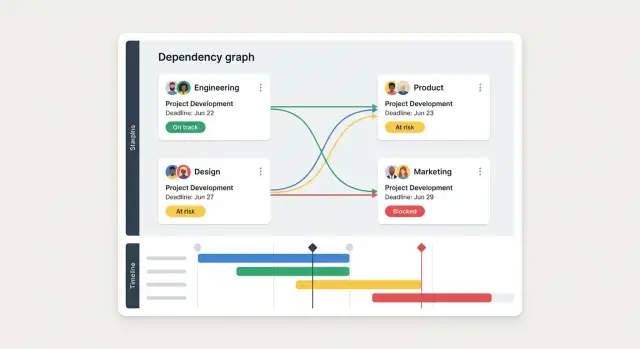
- Vue graphe de dépendances pour releases complexes
- Scoring de risque (vieillissement, délais manqués, tags à fort impact)
- Analytique SLA pour repérer les goulets chroniques
- Modèles par département pour créer des dépendances en un clic
Si vous priorisez les améliorations, liez chaque idée à un rituel de revue (revue hebdo, planning de release, rétro d'incident) pour que les évolutions soient guidées par l'usage réel, pas des suppositions.